23. 데이터 그룹화#
import numpy as np
import pandas as pd
PREVIOUS_MAX_ROWS = pd.options.display.max_rows
pd.options.display.max_columns = 20
pd.options.display.max_rows = 20
pd.options.display.max_colwidth = 80
np.random.seed(12345)
import matplotlib.pyplot as plt
plt.rc("figure", figsize=(10, 6))
np.set_printoptions(precision=4, suppress=True)
23.1. 시리즈와 데이터프레임 그룹화#
groupby() 메서드는 지정된 키를 기준으로 데이터를 그룹으로 쪼갠 다음에
특정 집계 함수를 그룹별로 적용해서 그룹별로 하나의 값을 계산한다.
그리고 생성된 그룹과 그룹별로 계산된 값을 조합해서 새로운 데이터프레임 또는 시리즈를 생성한다.
이 과정을 간략하게 쪼개고, 적용하고, 조합하기split-apply-combine라 부른다.
집계 함수
집계 함수는 리스트 또는 1차원 어레이가 주어졌을 때 항목들을 대상으로 하나의 값을 계산하는 함수를 가리킨다. 예를 들어, 평균값을 계산하거나, 항목의 개수 등을 계산하는 함수 등이 대표적인 집계 함수다.
23.1.1. 쪼개고, 적용하고, 조합하기#
다음 데이터프레임을 이용하여 쪼개고, 적용하고, 조합하기 과정을 설명한다.
df = pd.DataFrame({"Key" : ["A", "B", "C", "A", "B", "C", "A", "B", "C"],
"Data" : [0, 5, 10, 5, 10, 15, 10, 15, 20]})
df
| Key | Data | |
|---|---|---|
| 0 | A | 0 |
| 1 | B | 5 |
| 2 | C | 10 |
| 3 | A | 5 |
| 4 | B | 10 |
| 5 | C | 15 |
| 6 | A | 10 |
| 7 | B | 15 |
| 8 | C | 20 |
아래 코드는 Key 열에 속한 "A", "B", "C" 세 값을 기준으로
3 개의 그룹으로 쪼갠 후 각 그룹에 속합 값들을 열별로 더한 결과를
이용하애 새로운 데이터프레임을 생성한다.
df.groupby("Key").sum()
| Data | |
|---|---|
| Key | |
| A | 15 |
| B | 30 |
| C | 45 |
위 코드의 실행 과정에 포함된 쪼개고, 적용하고, 조합하기를 잘 묘사하면 다음과 같다.
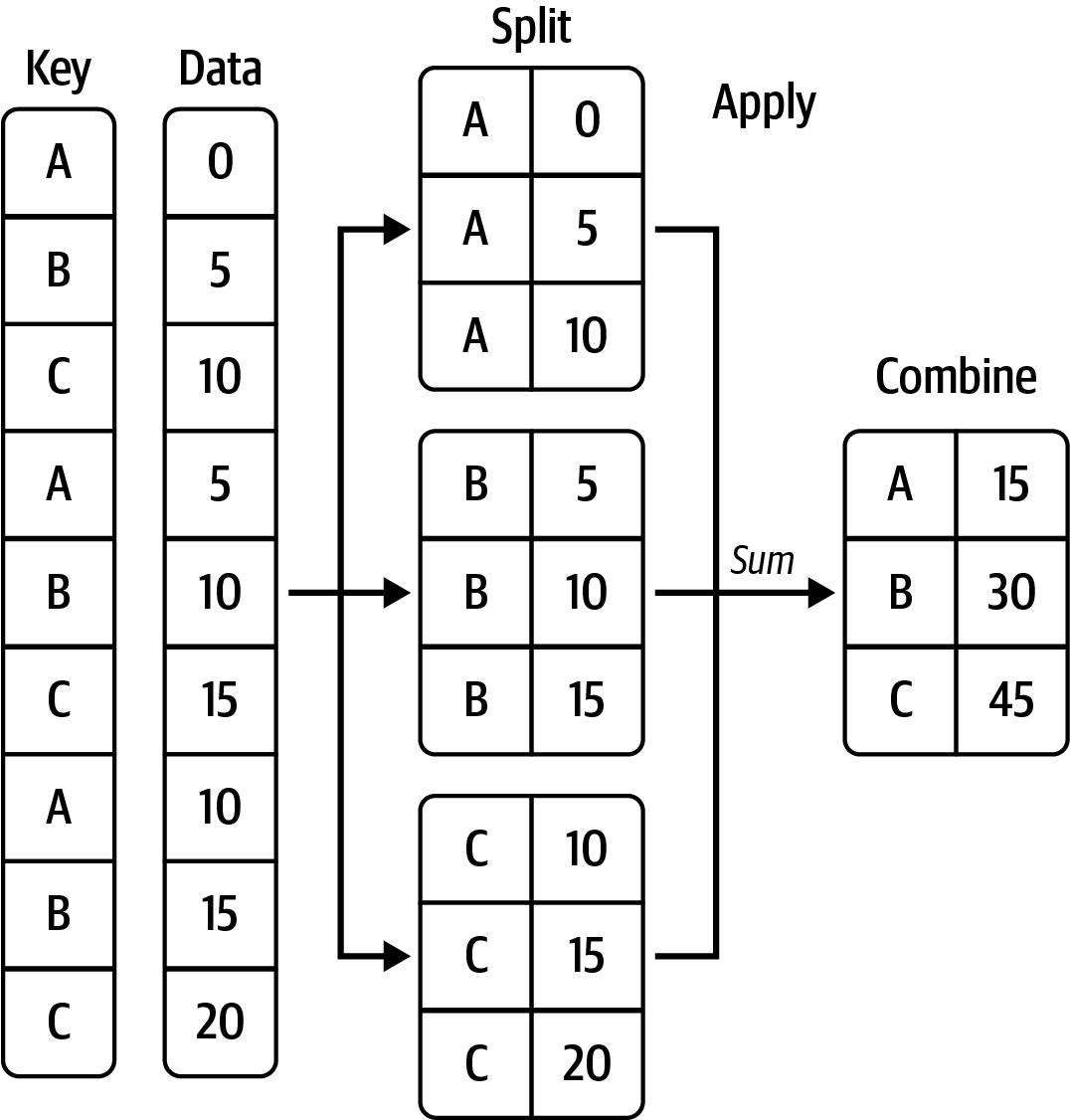
다음 데이터프레임을 활용한다.
df = pd.DataFrame({"key1" : ["a", "a", None, "b", "b", "a", None],
"key2" : pd.Series(["one", "two", "one", "two", "one", None, "one"]),
"data1" : np.random.standard_normal(7),
"data2" : np.random.standard_normal(7)})
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | -0.204708 | 0.281746 |
| 1 | a | two | 0.478943 | 0.769023 |
| 2 | None | one | -0.519439 | 1.246435 |
| 3 | b | two | -0.555730 | 1.007189 |
| 4 | b | one | 1.965781 | -1.296221 |
| 5 | a | None | 1.393406 | 0.274992 |
| 6 | None | one | 0.092908 | 0.228913 |
시리즈 그룹화
아래 시리즈를 이용하여 먼저 시리즈 그룹화를 설명한다.
s = df["data1"]
s
0 -0.204708
1 0.478943
2 -0.519439
3 -0.555730
4 1.965781
5 1.393406
6 0.092908
Name: data1, dtype: float64
아래 코드는 df["key1"] 시리즈의 항목을 기준으로 그룹화를 진행하며, 동일한 행에 위치한 값들을 그룹화 한다.
하지만 groupby() 메서드는 GroupBy 객체를 생성하며
실제로 그룹화를 진행하지는 않고 그룹화에 필요한 정보만 계산해 놓는다.
k1 = df["key1"]
s.groupby(k1)
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000001D3F460F5E0>
실제 그룹화는 집계 메서드를 실행할 때 이뤄진다.
valut_counts()메서드: 그룹별 항목 및 항목 수 확인
s.groupby(k1).value_counts()
key1 data1
a -0.204708 1
0.478943 1
1.393406 1
b -0.555730 1
1.965781 1
Name: data1, dtype: int64
mean()메서드: 그룹별 평균값 계산
grouped = s.groupby(k1).mean()
grouped
key1
a 0.555881
b 0.705025
Name: data1, dtype: float64
두 개 이상의 키를 기준으로 그룹화 진행 가능.
아래 코드는 df["key1"]와 df["key2"] 열에 속한 값들을 기준으로 그룹화 진행.
k2 = df["key2"]
means = s.groupby([k1, k2]).mean()
means
key1 key2
a one -0.204708
two 0.478943
b one 1.965781
two -0.555730
Name: data1, dtype: float64
여러 개의 키를 이용하여 그룹화를 한 경우 언스택을 활용하면 보다 보기 좋은 데이터프레임을 생성한다.
means.unstack()
| key2 | one | two |
|---|---|---|
| key1 | ||
| a | -0.204708 | 0.478943 |
| b | 1.965781 | -0.555730 |
어레이 또는 리스트를 키로 활용하는 것도 가능하다. 시리즈와 마찬가지로 각 값의 인덱스에 맞춰 그룹화가 이뤄진다.
states = np.array(["OH", "CA", "CA", "OH", "OH", "CA", "OH"])
years = [2005, 2005, 2006, 2005, 2006, 2005, 2006]
s.groupby([states, years]).mean()
CA 2005 0.936175
2006 -0.519439
OH 2005 -0.380219
2006 1.029344
Name: data1, dtype: float64
데이터프레임 그룹화
그룹별 집계 연산은 열 별로 독립적으로 적용된다.
numeric_only=True키워드 인자:key1열을 기준으로 그룹화 하면key2열에 대해서는mean()함수를 적용할 수 없기에 수치형 데이터를 담고 있는 열에 대해서만 평균값을 구하라고 지정한다.
df.groupby("key1").mean(numeric_only=True)
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 0.555881 | 0.441920 |
| b | 0.705025 | -0.144516 |
다중 키 활용 그룹화
여러 개의 키를 이용한 그룹화도 동일하게 작동한다.
df.groupby(["key1", "key2"]).mean()
| data1 | data2 | ||
|---|---|---|---|
| key1 | key2 | ||
| a | one | -0.204708 | 0.281746 |
| two | 0.478943 | 0.769023 | |
| b | one | 1.965781 | -1.296221 |
| two | -0.555730 | 1.007189 |
dropna=True키워드 인자: 결측치 자동 제거
df.groupby("key1", dropna=True).size()
key1
a 3
b 2
dtype: int64
df.groupby(["key1", "key2"]).size() # dropna = True 가 기본값
key1 key2
a one 1
two 1
b one 1
two 1
dtype: int64
dropna=False로 지정하면 결측치를 그대로 둚
df.groupby("key1", dropna=False).size()
key1
a 3
b 2
NaN 2
dtype: int64
df.groupby(["key1", "key2"], dropna=False).size()
key1 key2
a one 1
two 1
NaN 1
b one 1
two 1
NaN one 2
dtype: int64
count()집계 함수: 그룹별 항목 수 계산
df.groupby("key1").count()
| key2 | data1 | data2 | |
|---|---|---|---|
| key1 | |||
| a | 2 | 3 | 3 |
| b | 2 | 2 | 2 |
23.1.2. 그룹 확인#
for 반복문 활용
집계 함수를 적용하기 이전의 그룹들의 상태를 확인하기 위해 for 반복문을 이용할 수 있다.
for name, group in df.groupby("key1"):
print(name)
print("---")
print(group)
print() # 한 칸 띄우기 용도
a
---
key1 key2 data1 data2
0 a one -0.204708 0.281746
1 a two 0.478943 0.769023
5 a None 1.393406 0.274992
b
---
key1 key2 data1 data2
3 b two -0.555730 1.007189
4 b one 1.965781 -1.296221
for (k1, k2), group in df.groupby(["key1", "key2"]):
print((k1, k2))
print("---")
print(group)
print() # 한 칸 띄우기 용도
('a', 'one')
---
key1 key2 data1 data2
0 a one -0.204708 0.281746
('a', 'two')
---
key1 key2 data1 data2
1 a two 0.478943 0.769023
('b', 'one')
---
key1 key2 data1 data2
4 b one 1.965781 -1.296221
('b', 'two')
---
key1 key2 data1 data2
3 b two -0.55573 1.007189
사전 활용
사전 형식으로 저장하면 쉽게 그룹 단위로 확인할 수 있다.
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | -0.204708 | 0.281746 |
| 1 | a | two | 0.478943 | 0.769023 |
| 2 | None | one | -0.519439 | 1.246435 |
| 3 | b | two | -0.555730 | 1.007189 |
| 4 | b | one | 1.965781 | -1.296221 |
| 5 | a | None | 1.393406 | 0.274992 |
| 6 | None | one | 0.092908 | 0.228913 |
pieces = {name: group for name, group in df.groupby("key1")}
pieces["b"]
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 3 | b | two | -0.555730 | 1.007189 |
| 4 | b | one | 1.965781 | -1.296221 |
pieces = {name: group for name, group in df.groupby(["key1", "key2"])}
pieces[("b", "two")]
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 3 | b | two | -0.55573 | 1.007189 |
23.1.3. 열 선택#
그룹화 후 집계를 진행하기 전에 열 라벨을 선택하면 해당 열에 대해서만 집계 함수가 적용된다.
열 라벨의 리스트를 이용할 때: 데이터프레임 생성
df.groupby(["key1", "key2"])[["data2"]].mean()
| data2 | ||
|---|---|---|
| key1 | key2 | |
| a | one | 0.281746 |
| two | 0.769023 | |
| b | one | -1.296221 |
| two | 1.007189 |
열 라벨을 하나만 지정할 때: 시리즈 생성
df.groupby(["key1", "key2"])["data2"].mean()
key1 key2
a one 0.281746
two 0.769023
b one -1.296221
two 1.007189
Name: data2, dtype: float64
23.1.4. 열 기준 그룹화#
people = pd.DataFrame(np.random.standard_normal((5, 5)),
columns=["a", "b", "c", "d", "e"],
index=["Joe", "Steve", "Wanda", "Jill", "Trey"])
people
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 |
| Steve | -0.438570 | -0.539741 | 0.476985 | 3.248944 | -1.021228 |
| Wanda | -0.577087 | 0.124121 | 0.302614 | 0.523772 | 0.000940 |
| Jill | 1.343810 | -0.713544 | -0.831154 | -2.370232 | -1.860761 |
| Trey | -0.860757 | 0.560145 | -1.265934 | 0.119827 | -1.063512 |
연습을 위해 결측치 두 개를 의도적으로 추가한다.
people.iloc[2:3, [1, 2]] = np.nan
people
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 |
| Steve | -0.438570 | -0.539741 | 0.476985 | 3.248944 | -1.021228 |
| Wanda | -0.577087 | NaN | NaN | 0.523772 | 0.000940 |
| Jill | 1.343810 | -0.713544 | -0.831154 | -2.370232 | -1.860761 |
| Trey | -0.860757 | 0.560145 | -1.265934 | 0.119827 | -1.063512 |
사전 활용 열 기준 그룹화
사전을 이용하여 열 인덱스의 라벨을 "red", "blue" 로 구분한다.
즉, 키는 열 인덱스의 라벨을, 키의 값은 그룹을 지정한다.
단, "f" 라벨은 존재하지 않기에 무시된다.
mapping = {"a": "red", "b": "red", "c": "blue",
"d": "blue", "e": "red", "f" : "orange"}
아래 코드는 지정된 열로 구성된 그룹별로 sum() 메서드를 각 행에 대해 적용한다.
by_column = people.groupby(mapping, axis="columns")
by_column.sum()
| blue | red | |
|---|---|---|
| Joe | -2.373480 | 3.908371 |
| Steve | 3.725929 | -1.999539 |
| Wanda | 0.523772 | -0.576147 |
| Jill | -3.201385 | -1.230495 |
| Trey | -1.146107 | -1.364125 |
다음은 그룹별, 행별 평균값을 계산한다.
by_column.mean()
| blue | red | |
|---|---|---|
| Joe | -1.186740 | 1.302790 |
| Steve | 1.862964 | -0.666513 |
| Wanda | 0.523772 | -0.288074 |
| Jill | -1.600693 | -0.410165 |
| Trey | -0.573054 | -0.454708 |
시리즈 활용 열 기준 그룹화
map_series = pd.Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
시리즈를 활용하면 행의 라벨이 해당 값에 따라 그룹화된다.
people.groupby(map_series, axis="columns").count()
| blue | red | |
|---|---|---|
| Joe | 2 | 3 |
| Steve | 2 | 3 |
| Wanda | 1 | 2 |
| Jill | 2 | 3 |
| Trey | 2 | 3 |
23.1.5. 함수 활용 그룹화#
groupby() 메서드의 첫째 인자는 by 키워드 인자로 지정된다.
by 키워드의 인자가 함수이면 지정된 축에 따라
행 또는 열 인덱스 라벨에 해당 함수를 적용한 결과를
기준으로 그룹화한다.
예를 들어 아래 코드는 행 인덱스의 라벨의 길이를 기준으로 그룹화한다.
people
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 |
| Steve | -0.438570 | -0.539741 | 0.476985 | 3.248944 | -1.021228 |
| Wanda | -0.577087 | NaN | NaN | 0.523772 | 0.000940 |
| Jill | 1.343810 | -0.713544 | -0.831154 | -2.370232 | -1.860761 |
| Trey | -0.860757 | 0.560145 | -1.265934 | 0.119827 | -1.063512 |
people.groupby(len).sum()
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 3 | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 |
| 4 | 0.483052 | -0.153399 | -2.097088 | -2.250405 | -2.924273 |
| 5 | -1.015657 | -0.539741 | 0.476985 | 3.772716 | -1.020287 |
그룹화의 기준으로 함수와 함께 어레이, 사전, 시리즈, 또는 열 인덱스 라벨 등을 함께 사용할 수 있다. 연습을 위해 먼저 새로운 열을 추가한다.
people["School"] = ["A", "B", "C", "A", "B"]
people
| a | b | c | d | e | School | |
|---|---|---|---|---|---|---|
| Joe | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 | A |
| Steve | -0.438570 | -0.539741 | 0.476985 | 3.248944 | -1.021228 | B |
| Wanda | -0.577087 | NaN | NaN | 0.523772 | 0.000940 | C |
| Jill | 1.343810 | -0.713544 | -0.831154 | -2.370232 | -1.860761 | A |
| Trey | -0.860757 | 0.560145 | -1.265934 | 0.119827 | -1.063512 | B |
아래 리스트도 그룹화에 사용한다.
key_list = ["one", "one", "two", "three", "two"]
아래 코드는 행 인덱스의 라벨의 길이, key_list, "School" 열을 기준으로 그룹하를 진행한
다음에 그룹별 최소값을 계산한다.
people.groupby([len, key_list, "School"]).min()
| a | b | c | d | e | |||
|---|---|---|---|---|---|---|---|
| School | |||||||
| 3 | one | A | 1.352917 | 0.886429 | -2.001637 | -0.371843 | 1.669025 |
| 4 | three | A | 1.343810 | -0.713544 | -0.831154 | -2.370232 | -1.860761 |
| two | B | -0.860757 | 0.560145 | -1.265934 | 0.119827 | -1.063512 | |
| 5 | one | B | -0.438570 | -0.539741 | 0.476985 | 3.248944 | -1.021228 |
| two | C | -0.577087 | NaN | NaN | 0.523772 | 0.000940 |
23.1.6. 멀티 인덱스 레벨 활용#
인덱스의 레벨에 포함된 라벨을 기준으로 그룹화를 진행할 수 있다.
행 인덱스 레벨 활용
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | -0.204708 | 0.281746 |
| 1 | a | two | 0.478943 | 0.769023 |
| 2 | None | one | -0.519439 | 1.246435 |
| 3 | b | two | -0.555730 | 1.007189 |
| 4 | b | one | 1.965781 | -1.296221 |
| 5 | a | None | 1.393406 | 0.274992 |
| 6 | None | one | 0.092908 | 0.228913 |
df2 = df.set_index(["key1", "key2"])
df2
| data1 | data2 | ||
|---|---|---|---|
| key1 | key2 | ||
| a | one | -0.204708 | 0.281746 |
| two | 0.478943 | 0.769023 | |
| NaN | one | -0.519439 | 1.246435 |
| b | two | -0.555730 | 1.007189 |
| one | 1.965781 | -1.296221 | |
| a | NaN | 1.393406 | 0.274992 |
| NaN | one | 0.092908 | 0.228913 |
행 인덱스의 0-레벨 기준 그룹화
df2.groupby(level=0, axis="index").count()
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 3 | 3 |
| b | 2 | 2 |
행 인덱스의 1-레벨 기준 그룹화
df2.groupby(level=1).count() # axis="index" 가 기본값
| data1 | data2 | |
|---|---|---|
| key2 | ||
| one | 4 | 4 |
| two | 2 | 2 |
df2.groupby(level=1).mean() # axis="index" 가 기본값
| data1 | data2 | |
|---|---|---|
| key2 | ||
| one | 0.333636 | 0.115218 |
| two | -0.038393 | 0.888106 |
열 인덱스 레벨 활용
columns = pd.MultiIndex.from_arrays([["Foo", "Foo", "Foo", "Bar", "Bar"],
[1, 3, 5, 1, 3]])
hier_df = pd.DataFrame(np.random.standard_normal((4, 5)), columns=columns)
hier_df
| Foo | Bar | ||||
|---|---|---|---|---|---|
| 1 | 3 | 5 | 1 | 3 | |
| 0 | 0.332883 | -2.359419 | -0.199543 | -1.541996 | -0.970736 |
| 1 | -1.307030 | 0.286350 | 0.377984 | -0.753887 | 0.331286 |
| 2 | 1.349742 | 0.069877 | 0.246674 | -0.011862 | 1.004812 |
| 3 | 1.327195 | -0.919262 | -1.549106 | 0.022185 | 0.758363 |
열 인덱스의 0-레벨 기준 그룹화
hier_df.groupby(level=0, axis="columns").count()
| Bar | Foo | |
|---|---|---|
| 0 | 2 | 3 |
| 1 | 2 | 3 |
| 2 | 2 | 3 |
| 3 | 2 | 3 |
열 인덱스의 1-레벨 기준 그룹화
hier_df.groupby(level=1, axis="columns").mean()
| 1 | 3 | 5 | |
|---|---|---|---|
| 0 | -0.604556 | -1.665077 | -0.199543 |
| 1 | -1.030458 | 0.308818 | 0.377984 |
| 2 | 0.668940 | 0.537344 | 0.246674 |
| 3 | 0.674690 | -0.080449 | -1.549106 |
23.2. 데이터 집계#
23.2.1. 집계 함수#
그룹화 집계 메서드
아래 함수가 GroupBy 객체의 집계 메서드로 최적화되어 있다.
집계 메서드 |
기능 |
|---|---|
any, all |
최소 하나의 항목이 또는 모든 항목이 참인지 여부 확인 |
count |
그룹별 항목 수. NaN 제외. |
cummin, cummax |
누적 최소값 또는 최대값. NaN 제외 |
cumsum |
누적합. NaN 제외 |
cumprod |
누적곱, NaN 제외 |
first, last |
처음 또는 마지막 항목. NaN 제외 |
mean |
평균값. NaN 제외 |
median |
중앙값. NaN 제외 |
min, max |
최소값 또는 최대값. NaN 제외 |
nth |
정렬했을 때 n 번째 값 |
ohlc |
시계열 데이터의 “open-high-low-close” 값 네 개 계산 |
prod |
모든 항목의 곱. NaN 제외 |
quantile |
백분위수 계산 |
rank |
오름차순으로 정렬했을 때의 항목별 순서. NaN 제외 |
size |
그룹 크기 |
sum |
모든 항목의 합. NaN 제외 |
std, var |
표준편차 또는 분산 |
기타 시리즈 집계 메서드
언급된 집계 메서드 이외에 시리즈의 메서드를 모두 집계 함수로 사용할 수 있다. 단, 속도가 좀 느릴 수 있다.
df
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | -0.204708 | 0.281746 |
| 1 | a | two | 0.478943 | 0.769023 |
| 2 | None | one | -0.519439 | 1.246435 |
| 3 | b | two | -0.555730 | 1.007189 |
| 4 | b | one | 1.965781 | -1.296221 |
| 5 | a | None | 1.393406 | 0.274992 |
| 6 | None | one | 0.092908 | 0.228913 |
Series.nsmallest(n=5)메서드: 가장 작은 n 개의 항목 반환.n=5가 기본값.
grouped = df.groupby("key1")
grouped["data1"].nsmallest(2)
key1
a 0 -0.204708
1 0.478943
b 3 -0.555730
4 1.965781
Name: data1, dtype: float64
사용자 정의 집계 함수
1차원 어레이를 집계하는 임의의 함수를 그룹화 집계 함수로 이용할 수 있다. 예를 들어, 아래 함수는 어레이에 포함된 최대값과 최소값의 차이, 즉, 값들의 범위를 계산한다.
def peak_to_peak(arr):
return arr.max() - arr.min()
agg()메서드: 사용자 정의 집계 함수를 그룹화 집계 함수로 사용하려면agg()메서드의 인자로 지정한다.
grouped[["data1", "data2"]].agg(peak_to_peak)
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 1.598113 | 0.494031 |
| b | 2.521511 | 2.303410 |
비집계 함수
DataFrame.describe() 처럼 집계 함수가 아닌 경우도 작동하기도 한다.
DataFrame.describe()메서드: 수치 데이터셋의 분포를 요약한다. 여기서는 그룹별로 작동한다.
이와같은 비집계 함수가 작동하는 원리를 이해하려면 먼저 apply() 메서드를 이해해야 한다.
grouped.describe()
| data1 | data2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | |
| key1 | ||||||||||||||||
| a | 3.0 | 0.555881 | 0.801830 | -0.204708 | 0.137118 | 0.478943 | 0.936175 | 1.393406 | 3.0 | 0.441920 | 0.283299 | 0.274992 | 0.278369 | 0.281746 | 0.525384 | 0.769023 |
| b | 2.0 | 0.705025 | 1.782977 | -0.555730 | 0.074647 | 0.705025 | 1.335403 | 1.965781 | 2.0 | -0.144516 | 1.628757 | -1.296221 | -0.720368 | -0.144516 | 0.431337 | 1.007189 |
23.2.2. 열별로 여러 함수 적용하기#
팁 데이터를 다시 이용한다.
base_url = "https://raw.githubusercontent.com/codingalzi/datapy/master/jupyter-book/examples/"
file = "tips.csv"
tips = pd.read_csv(base_url + file)
tips.head()
| total_bill | tip | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 |
전체 수입에 대한 팁이 비율을 새로운 열로 추가한다.
열의 라벨은 "tip_pct"이다.
tips["tip_pct"] = tips["tip"] / tips["total_bill"]
tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
"day"와 "smoker" 기준으로 그룹을 짓는다.
grouped = tips.groupby(["day", "smoker"])
그룹별 팁 비율의 평균값을 계산한다.
agg() 메서드에 GroupBy 객체의 집계 메서드를 인자로 사용할 수 있으며
이때 함수의 이름을 문자열로 지정한다.
grouped_pct = grouped["tip_pct"]
grouped_pct.agg("mean")
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
여러 개의 집계 함수를 사용하면 사용된 집계 함수별로 열이 생성된다. 아래 코드는 그룹별로 팁 비율의 평균값, 표준편차, 최대-최소 오차 값을 계산한다.
grouped_pct.agg(["mean", "std", peak_to_peak])
| mean | std | peak_to_peak | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 0.151650 | 0.028123 | 0.067349 |
| Yes | 0.174783 | 0.051293 | 0.159925 | |
| Sat | No | 0.158048 | 0.039767 | 0.235193 |
| Yes | 0.147906 | 0.061375 | 0.290095 | |
| Sun | No | 0.160113 | 0.042347 | 0.193226 |
| Yes | 0.187250 | 0.154134 | 0.644685 | |
| Thur | No | 0.160298 | 0.038774 | 0.193350 |
| Yes | 0.163863 | 0.039389 | 0.151240 |
집계 함수와 생성되는 열의 라벨을 쌍으로 구성하면 지정된 라벨이 사용된다.
np.std()함수: 집계 함수"std"대신 사용됨
grouped_pct.agg([("average", "mean"), ("stdev", np.std)])
| average | stdev | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 0.151650 | 0.028123 |
| Yes | 0.174783 | 0.051293 | |
| Sat | No | 0.158048 | 0.039767 |
| Yes | 0.147906 | 0.061375 | |
| Sun | No | 0.160113 | 0.042347 |
| Yes | 0.187250 | 0.154134 | |
| Thur | No | 0.160298 | 0.038774 |
| Yes | 0.163863 | 0.039389 |
여러 개의 함수를 여러 개의 열에 적용하면 멀티 인덱스가 열의 인덱스로 사용된다.
functions = ["count", "mean", "max"]
result = grouped[["tip_pct", "total_bill"]].agg(functions)
result
| tip_pct | total_bill | ||||||
|---|---|---|---|---|---|---|---|
| count | mean | max | count | mean | max | ||
| day | smoker | ||||||
| Fri | No | 4 | 0.151650 | 0.187735 | 4 | 18.420000 | 22.75 |
| Yes | 15 | 0.174783 | 0.263480 | 15 | 16.813333 | 40.17 | |
| Sat | No | 45 | 0.158048 | 0.291990 | 45 | 19.661778 | 48.33 |
| Yes | 42 | 0.147906 | 0.325733 | 42 | 21.276667 | 50.81 | |
| Sun | No | 57 | 0.160113 | 0.252672 | 57 | 20.506667 | 48.17 |
| Yes | 19 | 0.187250 | 0.710345 | 19 | 24.120000 | 45.35 | |
| Thur | No | 45 | 0.160298 | 0.266312 | 45 | 17.113111 | 41.19 |
| Yes | 17 | 0.163863 | 0.241255 | 17 | 19.190588 | 43.11 | |
열의 라벨을 지정하는 방식도 동일하게 작동한다.
ftuples = [("Average", "mean"), ("Variance", np.var)]
grouped[["tip_pct", "total_bill"]].agg(ftuples)
| tip_pct | total_bill | ||||
|---|---|---|---|---|---|
| Average | Variance | Average | Variance | ||
| day | smoker | ||||
| Fri | No | 0.151650 | 0.000791 | 18.420000 | 25.596333 |
| Yes | 0.174783 | 0.002631 | 16.813333 | 82.562438 | |
| Sat | No | 0.158048 | 0.001581 | 19.661778 | 79.908965 |
| Yes | 0.147906 | 0.003767 | 21.276667 | 101.387535 | |
| Sun | No | 0.160113 | 0.001793 | 20.506667 | 66.099980 |
| Yes | 0.187250 | 0.023757 | 24.120000 | 109.046044 | |
| Thur | No | 0.160298 | 0.001503 | 17.113111 | 59.625081 |
| Yes | 0.163863 | 0.001551 | 19.190588 | 69.808518 | |
열별로 다른 집계 함수를 적용하려면 사전을 이용한다.
grouped.agg({"tip" : np.max, "size" : "sum"})
| tip | size | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 3.50 | 9 |
| Yes | 4.73 | 31 | |
| Sat | No | 9.00 | 115 |
| Yes | 10.00 | 104 | |
| Sun | No | 6.00 | 167 |
| Yes | 6.50 | 49 | |
| Thur | No | 6.70 | 112 |
| Yes | 5.00 | 40 |
열별로 여러 함수를 적용할 수도 있다.
grouped.agg({"tip_pct" : ["min", "max", "mean", "std"],
"size" : "sum"})
| tip_pct | size | |||||
|---|---|---|---|---|---|---|
| min | max | mean | std | sum | ||
| day | smoker | |||||
| Fri | No | 0.120385 | 0.187735 | 0.151650 | 0.028123 | 9 |
| Yes | 0.103555 | 0.263480 | 0.174783 | 0.051293 | 31 | |
| Sat | No | 0.056797 | 0.291990 | 0.158048 | 0.039767 | 115 |
| Yes | 0.035638 | 0.325733 | 0.147906 | 0.061375 | 104 | |
| Sun | No | 0.059447 | 0.252672 | 0.160113 | 0.042347 | 167 |
| Yes | 0.065660 | 0.710345 | 0.187250 | 0.154134 | 49 | |
| Thur | No | 0.072961 | 0.266312 | 0.160298 | 0.038774 | 112 |
| Yes | 0.090014 | 0.241255 | 0.163863 | 0.039389 | 40 | |
23.3. Apply: 다목적 데이터 집계#
지금까지 groupby를 이용한 그룹화 이후에 사용한 집계 함수는
모두 그룹별로 하나의 값만 생성하였다.
반면에 apply() 메서드를 이용하면 그런 제한 없이 임의의 함수를
그룹별로 적용할 수 있다.
실행 결과는 그룹별 결과를 합친 데이터프레임이다.
서빙 팁 데이터 활용
tips
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | No | Sat | Dinner | 3 | 0.203927 |
| 240 | 27.18 | 2.00 | Yes | Sat | Dinner | 2 | 0.073584 |
| 241 | 22.67 | 2.00 | Yes | Sat | Dinner | 2 | 0.088222 |
| 242 | 17.82 | 1.75 | No | Sat | Dinner | 2 | 0.098204 |
| 243 | 18.78 | 3.00 | No | Thur | Dinner | 2 | 0.159744 |
244 rows × 7 columns
아래 top() 함수는 지정된 데이터프레임을 특정 열을 기준으로 내림차순으로 정렬한 다음에
처음 n 개의 행을 반환한다.
def top(df, n=5, column="tip_pct"):
return df.sort_values(column, ascending=False)[:n]
서빙팁을 가장 많이 받은 6일에 대한 정보는 다음과 같다.
top(tips, n=6)
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
흡연 여부를 기준으로 그룹을 나눈 뒤 흡연 그룹과 비흡연 그룹에 대해
서빙팁이 가장 많았던 5일에 대한 정보를
top() 함수를 이용하여 구한다.
tips.groupby("smoker").apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | ||
|---|---|---|---|---|---|---|---|---|
| smoker | ||||||||
| No | 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 | |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 | |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 | |
| 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 | |
| Yes | 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 | |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 | |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 | |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
top() 함수의 키워드 인자를 변경하려면 apply() 함수의 키워드 인자로 지정하면 된다.
아래 코드는 흡연 여부와 요일 기준에 따른 그룹화 후에 그룹별로 가장 많은 수입을 올린 날에 대한 정보를 보여준다.
tips.groupby(["smoker", "day"]).apply(top, n=1, column="total_bill")
| total_bill | tip | smoker | day | time | size | tip_pct | |||
|---|---|---|---|---|---|---|---|---|---|
| smoker | day | ||||||||
| No | Fri | 94 | 22.75 | 3.25 | No | Fri | Dinner | 2 | 0.142857 |
| Sat | 212 | 48.33 | 9.00 | No | Sat | Dinner | 4 | 0.186220 | |
| Sun | 156 | 48.17 | 5.00 | No | Sun | Dinner | 6 | 0.103799 | |
| Thur | 142 | 41.19 | 5.00 | No | Thur | Lunch | 5 | 0.121389 | |
| Yes | Fri | 95 | 40.17 | 4.73 | Yes | Fri | Dinner | 4 | 0.117750 |
| Sat | 170 | 50.81 | 10.00 | Yes | Sat | Dinner | 3 | 0.196812 | |
| Sun | 182 | 45.35 | 3.50 | Yes | Sun | Dinner | 3 | 0.077178 | |
| Thur | 197 | 43.11 | 5.00 | Yes | Thur | Lunch | 4 | 0.115982 |
result = tips.groupby("smoker")["tip_pct"].describe()
result
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| smoker | ||||||||
| No | 151.0 | 0.159328 | 0.039910 | 0.056797 | 0.136906 | 0.155625 | 0.185014 | 0.291990 |
| Yes | 93.0 | 0.163196 | 0.085119 | 0.035638 | 0.106771 | 0.153846 | 0.195059 | 0.710345 |
result.unstack("smoker")
smoker
count No 151.000000
Yes 93.000000
mean No 0.159328
Yes 0.163196
std No 0.039910
Yes 0.085119
min No 0.056797
Yes 0.035638
25% No 0.136906
Yes 0.106771
50% No 0.155625
Yes 0.153846
75% No 0.185014
Yes 0.195059
max No 0.291990
Yes 0.710345
dtype: float64
23.3.1. 그룹 키 제거#
tips.groupby("smoker", group_keys=False).apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 |
| 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 |
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
tips.groupby("smoker").apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | ||
|---|---|---|---|---|---|---|---|---|
| smoker | ||||||||
| No | 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 | |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 | |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 | |
| 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 | |
| Yes | 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 | |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 | |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 | |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
tips.groupby("smoker", as_index=False).apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 | |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 | |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 | |
| 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 | |
| 1 | 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 | |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 | |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 | |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
23.3.2. 분위/구간 분석#
frame = pd.DataFrame({"data1": np.random.standard_normal(1000),
"data2": np.random.standard_normal(1000)})
frame.head()
| data1 | data2 | |
|---|---|---|
| 0 | -0.660524 | -0.612905 |
| 1 | 0.862580 | 0.316447 |
| 2 | -0.010032 | 0.838295 |
| 3 | 0.050009 | -1.034423 |
| 4 | 0.670216 | 0.434304 |
quartiles = pd.cut(frame["data1"], 4)
quartiles.head(10)
0 (-1.23, 0.489]
1 (0.489, 2.208]
2 (-1.23, 0.489]
3 (-1.23, 0.489]
4 (0.489, 2.208]
5 (0.489, 2.208]
6 (-1.23, 0.489]
7 (-1.23, 0.489]
8 (-2.956, -1.23]
9 (-1.23, 0.489]
Name: data1, dtype: category
Categories (4, interval[float64, right]): [(-2.956, -1.23] < (-1.23, 0.489] < (0.489, 2.208] < (2.208, 3.928]]
def get_stats(group):
return pd.DataFrame(
{"min": group.min(), "max": group.max(),
"count": group.count(), "mean": group.mean()}
)
grouped = frame.groupby(quartiles)
grouped.apply(get_stats)
| min | max | count | mean | ||
|---|---|---|---|---|---|
| data1 | |||||
| (-2.956, -1.23] | data1 | -2.949343 | -1.230179 | 94 | -1.658818 |
| data2 | -3.399312 | 1.670835 | 94 | -0.033333 | |
| (-1.23, 0.489] | data1 | -1.228918 | 0.488675 | 598 | -0.329524 |
| data2 | -2.989741 | 3.260383 | 598 | -0.002622 | |
| (0.489, 2.208] | data1 | 0.489965 | 2.200997 | 298 | 1.065727 |
| data2 | -3.745356 | 2.954439 | 298 | 0.078249 | |
| (2.208, 3.928] | data1 | 2.212303 | 3.927528 | 10 | 2.644253 |
| data2 | -1.929776 | 1.765640 | 10 | 0.024750 |
grouped.agg(["min", "max", "count", "mean"])
| data1 | data2 | |||||||
|---|---|---|---|---|---|---|---|---|
| min | max | count | mean | min | max | count | mean | |
| data1 | ||||||||
| (-2.956, -1.23] | -2.949343 | -1.230179 | 94 | -1.658818 | -3.399312 | 1.670835 | 94 | -0.033333 |
| (-1.23, 0.489] | -1.228918 | 0.488675 | 598 | -0.329524 | -2.989741 | 3.260383 | 598 | -0.002622 |
| (0.489, 2.208] | 0.489965 | 2.200997 | 298 | 1.065727 | -3.745356 | 2.954439 | 298 | 0.078249 |
| (2.208, 3.928] | 2.212303 | 3.927528 | 10 | 2.644253 | -1.929776 | 1.765640 | 10 | 0.024750 |
quartiles_samp = pd.qcut(frame["data1"], 4, labels=False)
quartiles_samp.head()
0 1
1 3
2 2
3 2
4 3
Name: data1, dtype: int64
grouped = frame.groupby(quartiles_samp)
grouped.apply(get_stats)
| min | max | count | mean | ||
|---|---|---|---|---|---|
| data1 | |||||
| 0 | data1 | -2.949343 | -0.685484 | 250 | -1.212173 |
| data2 | -3.399312 | 2.628441 | 250 | -0.027045 | |
| 1 | data1 | -0.683066 | -0.030280 | 250 | -0.368334 |
| data2 | -2.630247 | 3.260383 | 250 | -0.027845 | |
| 2 | data1 | -0.027734 | 0.618965 | 250 | 0.295812 |
| data2 | -3.056990 | 2.458842 | 250 | 0.014450 | |
| 3 | data1 | 0.623587 | 3.927528 | 250 | 1.248875 |
| data2 | -3.745356 | 2.954439 | 250 | 0.115899 |
23.3.3. 예제: 그룹별 결측치 채우기#
s = pd.Series(np.random.standard_normal(6))
s[::2] = np.nan
s
0 NaN
1 0.227290
2 NaN
3 -2.153545
4 NaN
5 -0.375842
dtype: float64
s.fillna(s.mean())
0 -0.767366
1 0.227290
2 -0.767366
3 -2.153545
4 -0.767366
5 -0.375842
dtype: float64
states = ["Ohio", "New York", "Vermont", "Florida",
"Oregon", "Nevada", "California", "Idaho"]
group_key = ["East", "East", "East", "East",
"West", "West", "West", "West"]
data = pd.Series(np.random.standard_normal(8), index=states)
data
Ohio 0.329939
New York 0.981994
Vermont 1.105913
Florida -1.613716
Oregon 1.561587
Nevada 0.406510
California 0.359244
Idaho -0.614436
dtype: float64
data[["Vermont", "Nevada", "Idaho"]] = np.nan
data
Ohio 0.329939
New York 0.981994
Vermont NaN
Florida -1.613716
Oregon 1.561587
Nevada NaN
California 0.359244
Idaho NaN
dtype: float64
data.groupby(group_key).size()
East 4
West 4
dtype: int64
data.groupby(group_key).count()
East 3
West 2
dtype: int64
data.groupby(group_key).mean()
East -0.100594
West 0.960416
dtype: float64
def fill_mean(group):
return group.fillna(group.mean())
data.groupby(group_key, group_keys=False).apply(fill_mean)
Ohio 0.329939
New York 0.981994
Vermont -0.100594
Florida -1.613716
Oregon 1.561587
Nevada 0.960416
California 0.359244
Idaho 0.960416
dtype: float64
data.groupby(group_key, group_keys=True).apply(fill_mean)
East Ohio 0.329939
New York 0.981994
Vermont -0.100594
Florida -1.613716
West Oregon 1.561587
Nevada 0.960416
California 0.359244
Idaho 0.960416
dtype: float64
fill_values = {"East": 0.5, "West": -1}
def fill_func(group):
return group.fillna(fill_values[group.name])
data.groupby(group_key, group_keys=False).apply(fill_func)
Ohio 0.329939
New York 0.981994
Vermont 0.500000
Florida -1.613716
Oregon 1.561587
Nevada -1.000000
California 0.359244
Idaho -1.000000
dtype: float64
23.3.4. 예제: 무작위 샘플링#
suits = ["H", "S", "C", "D"] # Hearts, Spades, Clubs, Diamonds
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ["A"] + list(range(2, 11)) + ["J", "K", "Q"]
cards = []
for suit in suits:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
deck.head(13)
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
dtype: int64
def draw(deck, n=5):
return deck.sample(n)
draw(deck)
4D 4
QH 10
8S 8
7D 7
9C 9
dtype: int64
def get_suit(card):
# last letter is suit
return card[-1]
deck.groupby(get_suit).apply(draw, n=2)
C 6C 6
KC 10
D 7D 7
3D 3
H 7H 7
9H 9
S 2S 2
QS 10
dtype: int64
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
AC 1
3C 3
5D 5
4D 4
10H 10
7H 7
QS 10
7S 7
dtype: int64
23.3.5. 그룹별 가중치 합#
df = pd.DataFrame({"category": ["a", "a", "a", "a",
"b", "b", "b", "b"],
"data": np.random.standard_normal(8),
"weights": np.random.uniform(size=8)})
df
| category | data | weights | |
|---|---|---|---|
| 0 | a | -1.691656 | 0.955905 |
| 1 | a | 0.511622 | 0.012745 |
| 2 | a | -0.401675 | 0.137009 |
| 3 | a | 0.968578 | 0.763037 |
| 4 | b | -1.818215 | 0.492472 |
| 5 | b | 0.279963 | 0.832908 |
| 6 | b | -0.200819 | 0.658331 |
| 7 | b | -0.217221 | 0.612009 |
grouped = df.groupby("category")
def get_wavg(group):
return np.average(group["data"], weights=group["weights"])
grouped.apply(get_wavg)
category
a -0.495807
b -0.357273
dtype: float64
base_url = "https://raw.githubusercontent.com/codingalzi/datapy/master/jupyter-book/examples/"
file = "stock_px.csv"
close_px = pd.read_csv(base_url+file, parse_dates=True,
index_col=0)
close_px.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 5472 entries, 1990-02-01 to 2011-10-14
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AA 5472 non-null float64
1 AAPL 5472 non-null float64
2 GE 5472 non-null float64
3 IBM 5472 non-null float64
4 JNJ 5472 non-null float64
5 MSFT 5472 non-null float64
6 PEP 5471 non-null float64
7 SPX 5472 non-null float64
8 XOM 5472 non-null float64
dtypes: float64(9)
memory usage: 427.5 KB
close_px.tail(4)
| AA | AAPL | GE | IBM | JNJ | MSFT | PEP | SPX | XOM | |
|---|---|---|---|---|---|---|---|---|---|
| 2011-10-11 | 10.30 | 400.29 | 16.14 | 185.00 | 63.96 | 27.00 | 60.95 | 1195.54 | 76.27 |
| 2011-10-12 | 10.05 | 402.19 | 16.40 | 186.12 | 64.33 | 26.96 | 62.70 | 1207.25 | 77.16 |
| 2011-10-13 | 10.10 | 408.43 | 16.22 | 186.82 | 64.23 | 27.18 | 62.36 | 1203.66 | 76.37 |
| 2011-10-14 | 10.26 | 422.00 | 16.60 | 190.53 | 64.72 | 27.27 | 62.24 | 1224.58 | 78.11 |
def spx_corr(group):
return group.corrwith(group["SPX"])
rets = close_px.pct_change().dropna()
def get_year(x):
return x.year
by_year = rets.groupby(get_year)
by_year.apply(spx_corr)
| AA | AAPL | GE | IBM | JNJ | MSFT | PEP | SPX | XOM | |
|---|---|---|---|---|---|---|---|---|---|
| 1990 | 0.595024 | 0.545067 | 0.752187 | 0.738361 | 0.801145 | 0.586691 | 0.783168 | 1.0 | 0.517586 |
| 1991 | 0.453574 | 0.365315 | 0.759607 | 0.557046 | 0.646401 | 0.524225 | 0.641775 | 1.0 | 0.569335 |
| 1992 | 0.398180 | 0.498732 | 0.632685 | 0.262232 | 0.515740 | 0.492345 | 0.473871 | 1.0 | 0.318408 |
| 1993 | 0.259069 | 0.238578 | 0.447257 | 0.211269 | 0.451503 | 0.425377 | 0.385089 | 1.0 | 0.318952 |
| 1994 | 0.428549 | 0.268420 | 0.572996 | 0.385162 | 0.372962 | 0.436585 | 0.450516 | 1.0 | 0.395078 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2007 | 0.642427 | 0.508118 | 0.796945 | 0.603906 | 0.568423 | 0.658770 | 0.651911 | 1.0 | 0.786264 |
| 2008 | 0.781057 | 0.681434 | 0.777337 | 0.833074 | 0.801005 | 0.804626 | 0.709264 | 1.0 | 0.828303 |
| 2009 | 0.735642 | 0.707103 | 0.713086 | 0.684513 | 0.603146 | 0.654902 | 0.541474 | 1.0 | 0.797921 |
| 2010 | 0.745700 | 0.710105 | 0.822285 | 0.783638 | 0.689896 | 0.730118 | 0.626655 | 1.0 | 0.839057 |
| 2011 | 0.882045 | 0.691931 | 0.864595 | 0.802730 | 0.752379 | 0.800996 | 0.592029 | 1.0 | 0.859975 |
22 rows × 9 columns
def corr_aapl_msft(group):
return group["AAPL"].corr(group["MSFT"])
by_year.apply(corr_aapl_msft)
1990 0.408271
1991 0.266807
1992 0.450592
1993 0.236917
1994 0.361638
...
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
Length: 22, dtype: float64
23.3.6. 예제: 그룹 단위 선형 회귀#
import statsmodels.api as sm
def regress(data, yvar=None, xvars=None):
Y = data[yvar]
X = data[xvars]
X["intercept"] = 1.
result = sm.OLS(Y, X).fit()
return result.params
by_year.apply(regress, yvar="AAPL", xvars=["SPX"])
| SPX | intercept | |
|---|---|---|
| 1990 | 1.512772 | 0.001395 |
| 1991 | 1.187351 | 0.000396 |
| 1992 | 1.832427 | 0.000164 |
| 1993 | 1.390470 | -0.002657 |
| 1994 | 1.190277 | 0.001617 |
| ... | ... | ... |
| 2007 | 1.198761 | 0.003438 |
| 2008 | 0.968016 | -0.001110 |
| 2009 | 0.879103 | 0.002954 |
| 2010 | 1.052608 | 0.001261 |
| 2011 | 0.806605 | 0.001514 |
22 rows × 2 columns
23.4. 그룹 변환#
df = pd.DataFrame({'key': ['a', 'b', 'c'] * 4,
'value': np.arange(12.)})
df
| key | value | |
|---|---|---|
| 0 | a | 0.0 |
| 1 | b | 1.0 |
| 2 | c | 2.0 |
| 3 | a | 3.0 |
| 4 | b | 4.0 |
| 5 | c | 5.0 |
| 6 | a | 6.0 |
| 7 | b | 7.0 |
| 8 | c | 8.0 |
| 9 | a | 9.0 |
| 10 | b | 10.0 |
| 11 | c | 11.0 |
g = df.groupby('key', group_keys=False)['value']
g.mean()
key
a 4.5
b 5.5
c 6.5
Name: value, dtype: float64
def get_mean(group):
return group.mean()
g.transform(get_mean)
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
g.transform('mean')
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
def times_two(group):
return group * 2
g.transform(times_two)
0 0.0
1 2.0
2 4.0
3 6.0
4 8.0
5 10.0
6 12.0
7 14.0
8 16.0
9 18.0
10 20.0
11 22.0
Name: value, dtype: float64
def get_ranks(group):
return group.rank(ascending=False)
g.transform(get_ranks)
0 4.0
1 4.0
2 4.0
3 3.0
4 3.0
5 3.0
6 2.0
7 2.0
8 2.0
9 1.0
10 1.0
11 1.0
Name: value, dtype: float64
def normalize(x):
return (x - x.mean()) / x.std()
g.transform(normalize)
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
g.apply(normalize)
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
g.transform('mean')
0 4.5
1 5.5
2 6.5
3 4.5
4 5.5
5 6.5
6 4.5
7 5.5
8 6.5
9 4.5
10 5.5
11 6.5
Name: value, dtype: float64
normalized = (df['value'] - g.transform('mean')) / g.transform('std')
normalized
0 -1.161895
1 -1.161895
2 -1.161895
3 -0.387298
4 -0.387298
5 -0.387298
6 0.387298
7 0.387298
8 0.387298
9 1.161895
10 1.161895
11 1.161895
Name: value, dtype: float64
23.5. 피벗 테이블#
tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
tips.pivot_table(index=["day", "smoker"], values=["size", "tip", "tip_pct", "total_bill"])
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 2.250000 | 2.812500 | 0.151650 | 18.420000 |
| Yes | 2.066667 | 2.714000 | 0.174783 | 16.813333 | |
| Sat | No | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
| Yes | 2.476190 | 2.875476 | 0.147906 | 21.276667 | |
| Sun | No | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
| Yes | 2.578947 | 3.516842 | 0.187250 | 24.120000 | |
| Thur | No | 2.488889 | 2.673778 | 0.160298 | 17.113111 |
| Yes | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
tips.pivot_table(index=["day", "smoker", "time"])
| size | tip | tip_pct | total_bill | |||
|---|---|---|---|---|---|---|
| day | smoker | time | ||||
| Fri | No | Dinner | 2.000000 | 2.750000 | 0.139622 | 19.233333 |
| Lunch | 3.000000 | 3.000000 | 0.187735 | 15.980000 | ||
| Yes | Dinner | 2.222222 | 3.003333 | 0.165347 | 19.806667 | |
| Lunch | 1.833333 | 2.280000 | 0.188937 | 12.323333 | ||
| Sat | No | Dinner | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
| Yes | Dinner | 2.476190 | 2.875476 | 0.147906 | 21.276667 | |
| Sun | No | Dinner | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
| Yes | Dinner | 2.578947 | 3.516842 | 0.187250 | 24.120000 | |
| Thur | No | Dinner | 2.000000 | 3.000000 | 0.159744 | 18.780000 |
| Lunch | 2.500000 | 2.666364 | 0.160311 | 17.075227 | ||
| Yes | Lunch | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
tips.pivot_table(index=["time", "day"], columns="smoker",
values=["tip_pct", "size"])
| size | tip_pct | ||||
|---|---|---|---|---|---|
| smoker | No | Yes | No | Yes | |
| time | day | ||||
| Dinner | Fri | 2.000000 | 2.222222 | 0.139622 | 0.165347 |
| Sat | 2.555556 | 2.476190 | 0.158048 | 0.147906 | |
| Sun | 2.929825 | 2.578947 | 0.160113 | 0.187250 | |
| Thur | 2.000000 | NaN | 0.159744 | NaN | |
| Lunch | Fri | 3.000000 | 1.833333 | 0.187735 | 0.188937 |
| Thur | 2.500000 | 2.352941 | 0.160311 | 0.163863 | |
tips.pivot_table(index=["time", "day"], columns="smoker",
values=["tip_pct", "size"], margins=True)
| size | tip_pct | ||||||
|---|---|---|---|---|---|---|---|
| smoker | No | Yes | All | No | Yes | All | |
| time | day | ||||||
| Dinner | Fri | 2.000000 | 2.222222 | 2.166667 | 0.139622 | 0.165347 | 0.158916 |
| Sat | 2.555556 | 2.476190 | 2.517241 | 0.158048 | 0.147906 | 0.153152 | |
| Sun | 2.929825 | 2.578947 | 2.842105 | 0.160113 | 0.187250 | 0.166897 | |
| Thur | 2.000000 | NaN | 2.000000 | 0.159744 | NaN | 0.159744 | |
| Lunch | Fri | 3.000000 | 1.833333 | 2.000000 | 0.187735 | 0.188937 | 0.188765 |
| Thur | 2.500000 | 2.352941 | 2.459016 | 0.160311 | 0.163863 | 0.161301 | |
| All | 2.668874 | 2.408602 | 2.569672 | 0.159328 | 0.163196 | 0.160803 | |
tips.pivot_table(index=["time", "smoker"], columns="day",
values="tip_pct", aggfunc=len, margins=True)
| day | Fri | Sat | Sun | Thur | All | |
|---|---|---|---|---|---|---|
| time | smoker | |||||
| Dinner | No | 3.0 | 45.0 | 57.0 | 1.0 | 106 |
| Yes | 9.0 | 42.0 | 19.0 | NaN | 70 | |
| Lunch | No | 1.0 | NaN | NaN | 44.0 | 45 |
| Yes | 6.0 | NaN | NaN | 17.0 | 23 | |
| All | 19.0 | 87.0 | 76.0 | 62.0 | 244 |
tips.pivot_table(index=["time", "size", "smoker"], columns="day",
values="tip_pct", fill_value=0)
| day | Fri | Sat | Sun | Thur | ||
|---|---|---|---|---|---|---|
| time | size | smoker | ||||
| Dinner | 1 | No | 0.000000 | 0.137931 | 0.000000 | 0.000000 |
| Yes | 0.000000 | 0.325733 | 0.000000 | 0.000000 | ||
| 2 | No | 0.139622 | 0.162705 | 0.168859 | 0.159744 | |
| Yes | 0.171297 | 0.148668 | 0.207893 | 0.000000 | ||
| 3 | No | 0.000000 | 0.154661 | 0.152663 | 0.000000 | |
| ... | ... | ... | ... | ... | ... | ... |
| Lunch | 3 | Yes | 0.000000 | 0.000000 | 0.000000 | 0.204952 |
| 4 | No | 0.000000 | 0.000000 | 0.000000 | 0.138919 | |
| Yes | 0.000000 | 0.000000 | 0.000000 | 0.155410 | ||
| 5 | No | 0.000000 | 0.000000 | 0.000000 | 0.121389 | |
| 6 | No | 0.000000 | 0.000000 | 0.000000 | 0.173706 |
21 rows × 4 columns
23.5.1. Cross-Tabulations: Crosstab#
from io import StringIO
data = """Sample Nationality Handedness
1 USA Right-handed
2 Japan Left-handed
3 USA Right-handed
4 Japan Right-handed
5 Japan Left-handed
6 Japan Right-handed
7 USA Right-handed
8 USA Left-handed
9 Japan Right-handed
10 USA Right-handed"""
data = pd.read_table(StringIO(data), sep="\s+")
data
| Sample | Nationality | Handedness | |
|---|---|---|---|
| 0 | 1 | USA | Right-handed |
| 1 | 2 | Japan | Left-handed |
| 2 | 3 | USA | Right-handed |
| 3 | 4 | Japan | Right-handed |
| 4 | 5 | Japan | Left-handed |
| 5 | 6 | Japan | Right-handed |
| 6 | 7 | USA | Right-handed |
| 7 | 8 | USA | Left-handed |
| 8 | 9 | Japan | Right-handed |
| 9 | 10 | USA | Right-handed |
pd.crosstab(data["Nationality"], data["Handedness"], margins=True)
| Handedness | Left-handed | Right-handed | All |
|---|---|---|---|
| Nationality | |||
| Japan | 2 | 3 | 5 |
| USA | 1 | 4 | 5 |
| All | 3 | 7 | 10 |
pd.crosstab([tips["time"], tips["day"]], tips["smoker"], margins=True)
| smoker | No | Yes | All | |
|---|---|---|---|---|
| time | day | |||
| Dinner | Fri | 3 | 9 | 12 |
| Sat | 45 | 42 | 87 | |
| Sun | 57 | 19 | 76 | |
| Thur | 1 | 0 | 1 | |
| Lunch | Fri | 1 | 6 | 7 |
| Thur | 44 | 17 | 61 | |
| All | 151 | 93 | 244 |
23.6. 연습문제#
참고: (실습) 데이터 그룹화