14. 어레이 중심 프로그래밍#
주어진 어레이를 조작하여 새로운 어레이를 생성하는 함수를 효율적으로 활용하는 것이 어레이 중심 프로그래밍array-oriented programming의 핵심이다. 여기서는 어레이 중심 프로그래밍에 가중 중요한 넘파이 함수와 어레이 메서드를 소개한다.
주요 내용
유니버설 함수
기초 통계 함수
부울 어레이 활용
어레이 정렬
기초 선형대수 함수
난수 생성 함수
기본 설정
numpy 모듈과 시각화 도구 모듈인 matplotlib.pyplot에 대한 기본 설정을 지정한다.
# 넘파이
import numpy as np
# 램덤 시드
np.random.seed(12345)
# 어레이 사용되는 부동소수점들의 정확도 지정
np.set_printoptions(precision=4, suppress=True)
# 파이플롯
import matplotlib.pyplot as plt
# # 도표 크기 지정
# plt.rc('figure', figsize=(10, 6))
14.1. 유니버설 함수#
유니버설 함수universal function는 어레이의 항목 각각에 대해 적용되는 함수이며, ufunc로도 불린다. 60개 이상의 유니버설 함수가 존재한다. 보다 자세한 내용은 유니버설 함수 공식문서에서 확인할 수 있다.
여기서는 예제를 통해 유니버설 함수의 기초 활용법을 살펴본다. 먼저 (2, 5) 모양의 어레이를 하나 생성하자.
arr = np.arange(10).reshape((2,5))
arr
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
np.sqrt() 함수
주어진 어레이 각 항목의 제곱근으로 이루어진 어레이가 반환된다.
np.sqrt(arr)
array([[0. , 1. , 1.4142, 1.7321, 2. ],
[2.2361, 2.4495, 2.6458, 2.8284, 3. ]])
np.exp() 함수
주어진 어레이 각 항목에 대해 \(e^x\) 함수를 적용한다. \(e\)는 오일러 상수를 가리키며 2.17128 정도의 무리수다.
np.exp(arr)
array([[ 1. , 2.7183, 7.3891, 20.0855, 54.5982],
[ 148.4132, 403.4288, 1096.6332, 2980.958 , 8103.0839]])
np.maximum()/np.minimum() 함수
동일한 모양의 두 어레이를 대상으로 항목별 최댓값/최솟값으로 이루어진 어레이를 반환한다.
x = np.random.randn(8).reshape((4, 2))
y = np.random.randn(8).reshape((4, 2))
x
array([[-0.2047, 0.4789],
[-0.5194, -0.5557],
[ 1.9658, 1.3934],
[ 0.0929, 0.2817]])
y
array([[ 0.769 , 1.2464],
[ 1.0072, -1.2962],
[ 0.275 , 0.2289],
[ 1.3529, 0.8864]])
np.maximum(x, y)
array([[ 0.769 , 1.2464],
[ 1.0072, -0.5557],
[ 1.9658, 1.3934],
[ 1.3529, 0.8864]])
np.minimum(x, y)
array([[-0.2047, 0.4789],
[-0.5194, -1.2962],
[ 0.275 , 0.2289],
[ 0.0929, 0.2817]])
np.divmod() 함수
여러 개의 어레이를 반환하는 유니버설 함수도 있다.
예를 들어, divmod() 함수는 어레이 나눗셈 실행 결과를 항목별 나눗셈의 몫으로 이루어진 어레이와
나머지로 이루어진 어레이의 튜플을 반환한다.
먼저 (2,4) 모양의 어레이를 하나 만들자.
arr = np.arange(10,32, 3).reshape((2,4))
arr
array([[10, 13, 16, 19],
[22, 25, 28, 31]])
위 어레이를 3으로 나누면 모든 항목 각각에 대한 몫과 나머지를 각각 따로 모아 두 개의 어레이로 이루어진 튜플을 반환한다.
np.divmod(arr, 3)
(array([[ 3, 4, 5, 6],
[ 7, 8, 9, 10]]),
array([[1, 1, 1, 1],
[1, 1, 1, 1]]))
두 어레이의 나눗셈도 가능하다.
arr2 = np.arange(2, 10).reshape((2,4))
arr2
array([[2, 3, 4, 5],
[6, 7, 8, 9]])
np.divmod(arr, arr2)
(array([[5, 4, 4, 3],
[3, 3, 3, 3]]),
array([[0, 1, 0, 4],
[4, 4, 4, 4]]))
부동소수점의 나눗셈에 대해서도 몫과 나머지를 구한다.
arr3 = np.arange(10,30, 2.5).reshape((2,4))
arr3
array([[10. , 12.5, 15. , 17.5],
[20. , 22.5, 25. , 27.5]])
arr4 = np.arange(2, 4.3, 0.3).reshape((2,4))
arr4
array([[2. , 2.3, 2.6, 2.9],
[3.2, 3.5, 3.8, 4.1]])
np.divmod(arr3, arr4)
(array([[5., 5., 5., 6.],
[6., 6., 6., 6.]]),
array([[0. , 1. , 2. , 0.1],
[0.8, 1.5, 2.2, 2.9]]))
유니버설 함수 생성: np.vectorize()
np.vectorize() 함수를 이용하여 임의의 함수를 유이버설 함수처럼 작동하게 만들 수 있다.
예를 들어 아래 함수는 인자가 0보다 크거나 같으면 0을, 작으면 1을 반환한다.
def pos_neg(x):
return int(x >= 0)
위 함수를 임의의 어레이에 항목별로 적용하도록 하기 위해서 먼저 유니버설 함수로 변환한다.
pos_neg_ufunc = np.vectorize(pos_neg)
이제 pos_neg_unfuc() 함수를 아래 어레이에 적용하면 0과 1로 구성된 어레이가 생성된다.
np.random.seed(17)
randn_x = np.random.randn(8).reshape((4, 2))
randn_x
array([[ 0.2763, -1.8546],
[ 0.6239, 1.1453],
[ 1.0372, 1.8866],
[-0.1117, -0.3621]])
pos_neg_ufunc(randn_x)
array([[1, 0],
[1, 1],
[1, 1],
[0, 0]])
14.2. 기초 통계 함수#
넘파이 어레이에 사용된 항목들의 합(sum), 평균값(mean), 표준편차(std) 등 기본 통계를 계산하는 어레이 메서드가 지원된다. 연습을 위해 먼저 (2, 3) 모양의 어레이를 무작위로 생성한다.
arr = np.arange(1, 7).reshape(2, 3)
arr
array([[1, 2, 3],
[4, 5, 6]])
mean() 메서드
어레이에 포함된 모든 값들의 평균값을 계산한다.
arr.mean()
3.5
sum() 메서드
어레이에 포함된 모든 값들의 합을 계산한다.
arr.sum()
21
cumsum() 메서드
어레이에 포함된 모든 값들의 누적합을 계산한다.
arr.cumsum()
array([ 1, 3, 6, 10, 15, 21])
cumprod() 메서드
어레이에 포함된 모든 값들의 누적곱을 계산한다.
arr.cumprod()
array([ 1, 2, 6, 24, 120, 720])
축axis 활용
앞서 언급된 모든 함수는 축(axis)을 이용하는 기능도 지원한다.
축 지정은 axis 키워드 인자를 사용한다.
axis=0: 행을 기준으로 함수 적용axis=1: 열을 기준으로 함수 적용
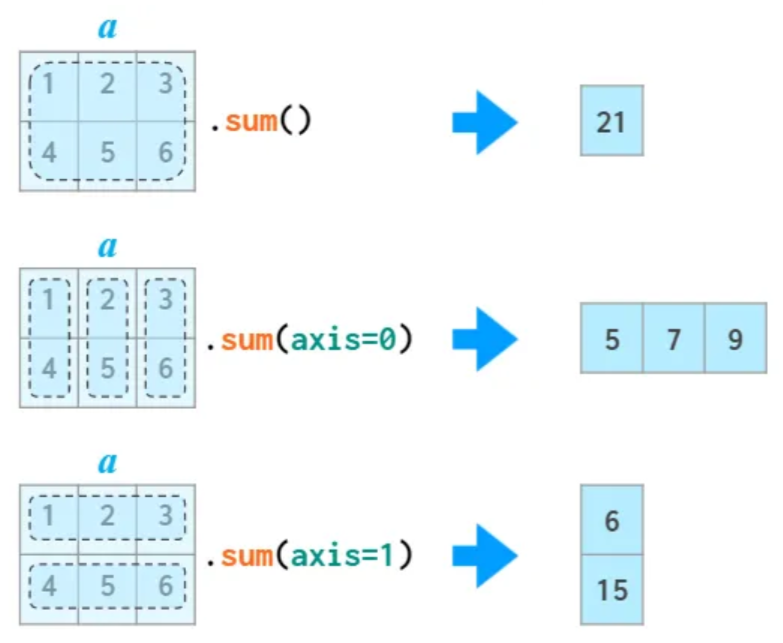
평균값
열별 평균값 계산: 행을 따라 평균값을 계산해야 하기에
axis=0지정.
arr.mean(axis=0)
array([2.5, 3.5, 4.5])
행별 평균값 계산: 열을 따라 평균값을 계산해야 하기에
axis=1지정.
arr.mean(axis=1)
array([2., 5.])
합
열별 항목의 합 계산: 행을 따라 항목들의 합을 계산해야 하기에
axis=0지정.
arr.sum(axis=0)
array([5, 7, 9])
행별 항목의 합 계산: 열을 따라 항목들의 합을 계산해야 하기에
axis=1지정.
arr.sum(axis=1)
array([ 6, 15])
누적합
열별 항목의 누적합 계산: 행을 따라 항목들의 누적합을 계산해야 하기에
axis=0지정.
arr.cumsum(axis=0)
array([[1, 2, 3],
[5, 7, 9]])
행별 항목의 누적합 계산: 열을 따라 항목들의 누적합을 계산해야 하기에
axis=1지정.
arr.cumsum(axis=1)
array([[ 1, 3, 6],
[ 4, 9, 15]])
누적곱
열별 항목의 누적곱 계산: 행을 따라 항목들의 누적곱을 계산해야 하기에
axis=0지정.
arr.cumprod(axis=0)
array([[ 1, 2, 3],
[ 4, 10, 18]])
행별 항목의 누적곱 계산: 열을 따라 항목들의 누적곱을 계산해야 하기에
axis=1지정.
arr.cumprod(axis=1)
array([[ 1, 2, 6],
[ 4, 20, 120]])
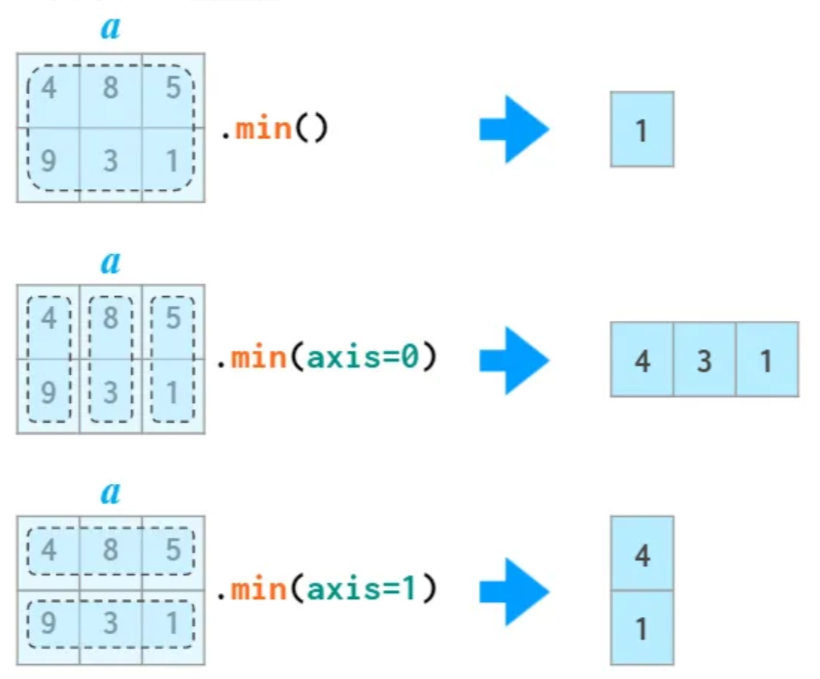
min()/max() 메서드 vs. argmin()/argmax() 메서드
min()/max()메서드: 항목 중에서 최솟값/최댓값 확인. 축 활용 가능.
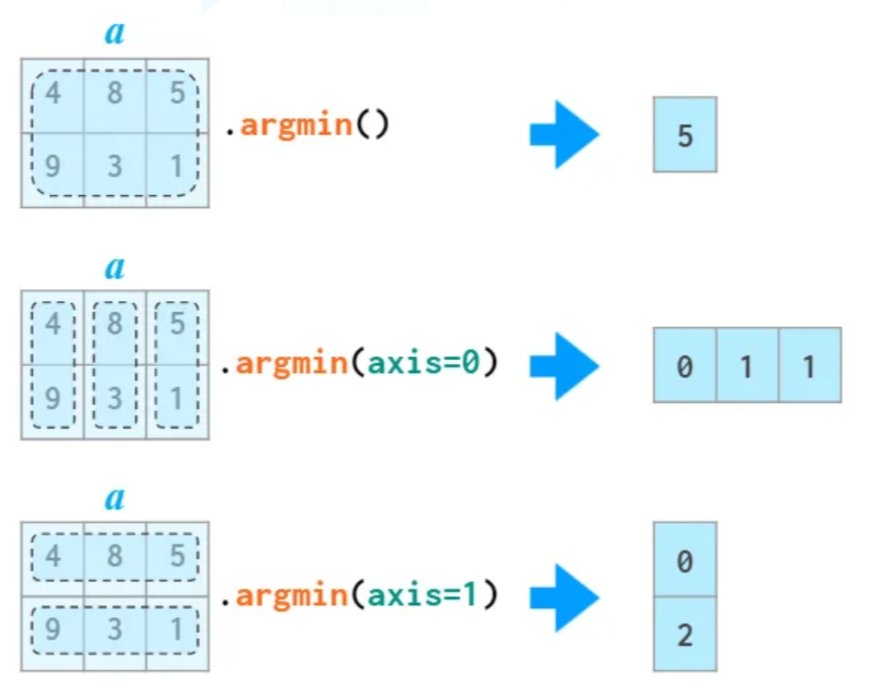
argmin()/argmax()메서드: 최소 항목/최대 항목이 위치한 곳의 인덱스 확인. 축 활용 가능.
설명을 위해 아래 어레이를 이용한다.
arr= np.array([[4, 8, 5], [9, 3, 1]])
arr
array([[4, 8, 5],
[9, 3, 1]])
min()/max() 메서드는
지정된 축을 기준으로 가장 작은 또는 가장 큰 값을 반환한다.
축을 지정하지 않으면 전체 항목을 대상으로 한다.
arr.min()
1
arr.max()
9
축을 지정하면 열별 또는 행별로 최대값/최소값으로 이루어진 어레이를 반환한다.
arr.min(axis=0)
array([4, 3, 1])
arr.max(axis=0)
array([9, 8, 5])
arr.min(axis=1)
array([4, 1])
arr.max(axis=1)
array([8, 9])
argmin()/argmax() 메서드는
지정된 축을 기준으로 가장 작은 또는 가장 큰 값의 항목이 위치한 인덱스를 반환한다.
축을 지정하지 않으면 전체 항목을 대상으로 하며,
반환된 값은 어레이를 1차원으로 변환했을 때의 인덱스를 보여준다.
arr.argmin()
5
arr.argmax()
3
축을 지정하면 축별로 인덱스를 반환한다.
arr.argmin(axis=0)
array([0, 1, 1])
arr.argmax(axis=0)
array([1, 0, 0])
arr.argmin(axis=1)
array([0, 2])
arr.argmax(axis=1)
array([1, 0])
14.3. 부울 어레이 활용#
어레이를 이용한 논리식 또한 항목별로 작동하여 부울 어레이가 생성된다.
arr2 = np.arange(1, 7).reshape(2, 3)
arr2
array([[1, 2, 3],
[4, 5, 6]])
아래 논리식은 각각의 항목에 대해 5보다 큰지 여부를 판단한다.
arr2 > 5
array([[False, False, False],
[False, False, True]])
np.any() 함수
한 개 이상의 어레이 항목이 참인지 여부를 판단하며, 축을 기준으로 참, 거짓 여부를 판단할 수도 있다.
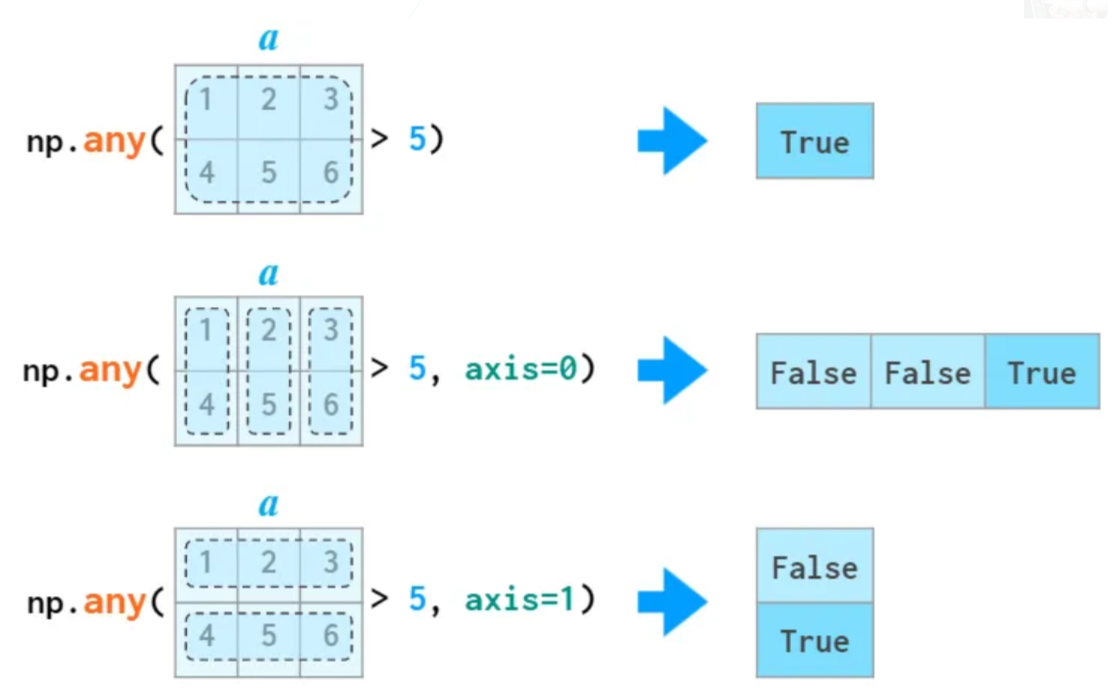
np.any(arr2 > 5)
True
np.any(arr2 > 5, axis=0)
array([False, False, True])
np.any(arr2 > 5, axis=1)
array([False, True])
np.all() 함수
어레이의 모든 항목이 참인지 여부를 판단하며, 축을 기준으로 참, 거짓 여부를 판단할 수도 있다.
np.all(arr2 > 5)
False
np.all(arr2 > 5, axis=0)
array([False, False, False])
np.all(arr2 > 5, axis=1)
array([False, False])
any()/all() 메서드
np.any()/np.all() 함수 대신에 any()/all() 메서드를 활용할 수도 있다.
아래 코드는 모든 항목이 짝수인지 여부를 판단한다.
(arr2 % 2 == 0).all()
False
짝수가 하나라도 있는지를 알고 싶으면 any()를 사용한다.
(arr2 % 2 == 0).any()
True
축 별로 확인할 수도 있다.
(arr2 % 2 == 0).all(axis=0)
array([False, False, False])
(arr2 % 2 == 0).all(axis=1)
array([False, False])
(arr2 % 2 == 0).any(axis=0)
array([ True, True, True])
(arr2 % 2 == 0).any(axis=1)
array([ True, True])
참인 항목의 개수: sum() 메서드 활용
sum() 메서드를 이용하여 특정 조건을 만족하는 항목들의 개수를 확인할 수 있다.
이유는 True는 1, False는 0으로 간주되기 때문이다.
아래 코드는 1부터 6까지의 정수 중에서 짝수가 3개임을 확인해준다.
(arr2 % 2 == 0).sum()
3
14.4. 어레이 정렬#
sort() 메서드
정해진 축을 기준으로 오름차순으로 정열할 때 사용한다. 1차원 어레이는 축을 지정할 필요가 없다.
arr = np.random.randn(6)
arr
array([-2.0016, -0.3718, 1.669 , -0.4386, -0.5397, 0.477 ])
arr.sort()
arr
array([-2.0016, -0.5397, -0.4386, -0.3718, 0.477 , 1.669 ])
다차원 어레이는 축을 이용하여 행 또는 열 기준으로 정렬할 수 있다.
arr = np.random.randn(5, 3)
arr
array([[ 3.2489, -1.0212, -0.5771],
[ 0.1241, 0.3026, 0.5238],
[ 0.0009, 1.3438, -0.7135],
[-0.8312, -2.3702, -1.8608],
[-0.8608, 0.5601, -1.2659]])
행을 따라 정렬하려면 인자 0을 사용한다.
arr.sort(0)
arr
array([[-0.8608, -2.3702, -1.8608],
[-0.8312, -1.0212, -1.2659],
[ 0.0009, 0.3026, -0.7135],
[ 0.1241, 0.5601, -0.5771],
[ 3.2489, 1.3438, 0.5238]])
주의사항: sort() 메서드는 기존의 어레이를 직접 변환한다.
즉, arr이 직접 변경된다.
arr
array([[-0.8608, -2.3702, -1.8608],
[-0.8312, -1.0212, -1.2659],
[ 0.0009, 0.3026, -0.7135],
[ 0.1241, 0.5601, -0.5771],
[ 3.2489, 1.3438, 0.5238]])
열을 따라 정렬하려면 인자 1을 사용한다.
arr.sort(1)
arr
array([[-2.3702, -1.8608, -0.8608],
[-1.2659, -1.0212, -0.8312],
[-0.7135, 0.0009, 0.3026],
[-0.5771, 0.1241, 0.5601],
[ 0.5238, 1.3438, 3.2489]])
예제
어레이에 사용된 값들의 백분위수를 정렬을 이용하여 쉽게 구할 수 있다. 예를 들어, 임의로 생성된 1,000개의 부동 소수점들 중에서 하위 5%에 해당하는 수를 구해보자.
large_arr = np.random.randn(1000)
먼저 정렬 한 다음에 하위 5%에 해당하는 위치를 구하여 인덱싱하면 바로 답이 나온다.
large_arr.sort()
하위 5%의 위치는 어레이의 길이에 0.05를 곱해준 값에 해당한다. 인덱스로 사용해야 하기에 정수로 형변환해주면 되며, 예상한 대로 50번 인덱스의 값을 가리킨다.
five_from_bottom = int(0.05 * len(large_arr))
five_from_bottom
50
따라서 하위 5%에 해당하는 값은 아래와 같다.
large_arr[five_from_bottom]
-1.551714991950571
argsort() 메서드
argsort() 메서드는 지정된 축에 따라 정렬했을 때의 각 항목이 자리잡는 위치의 인덱스로
구성된 어레이를 생성한다.
np.random.seed(1235)
arr = np.random.randint(0,50,(4, 3))
arr
array([[11, 34, 2],
[47, 3, 7],
[35, 40, 16],
[16, 2, 15]])
열 별로 작은 값에서부터 큰 값이 자리한 위치의 인덱스 확인
arr.argsort(axis=0)
array([[0, 3, 0],
[3, 1, 1],
[2, 0, 3],
[1, 2, 2]])
행 별로 작은 값에서부터 큰 값이 자리한 위치의 인덱스 확인
arr.argsort(axis=1)
array([[2, 0, 1],
[1, 2, 0],
[2, 0, 1],
[1, 2, 0]])
축을 지정하지 않으면 axis=-1, 즉 마지막 축을 기본값으로 이용한다.
arr.argsort() # arr.argsort(axis=-1)
array([[2, 0, 1],
[1, 2, 0],
[2, 0, 1],
[1, 2, 0]])
axis=None을 사용하면 모든 항목을 1차원 어레이로 만든 다음에 적용한다.
arr.argsort(axis=None)
array([ 2, 10, 4, 5, 0, 11, 8, 9, 1, 6, 7, 3])
예제
0번 열에 위치한 값들의 순서대로 행을 재배치하려면 다음과 같이 먼저
argsort() 메서드를 0번 열에 대해 적용한다.
X = arr[:, 0].argsort()
X
array([0, 3, 2, 1])
이제 0번열을 기준으로 정렬하려면 X를 팬시 인덱싱에 활용한다.
arr[X]
array([[11, 34, 2],
[16, 2, 15],
[35, 40, 16],
[47, 3, 7]])
14.5. 기초 선형 대수 함수#
행렬 곱셈, 전치 행렬, 역행렬 등을 2차원 어레이로 계산하는 방식을 간단한 예제를 이용하여 소개한다.
행렬곱
먼저 두 개의 행렬을 2차원 어레이로 구현하자.
행렬 x는 (2, 3) 모양의 2차원 어레이다.
x = np.array([[1., 2., 3.], [4., 5., 6.]])
x
array([[1., 2., 3.],
[4., 5., 6.]])
행렬 y는 (3, 2) 모양의 2차원 어레이다.
y = np.array([[6., 23.], [-1, 7], [8, 9]])
y
array([[ 6., 23.],
[-1., 7.],
[ 8., 9.]])
두 행렬의 곱 x y는 dot() 메서드를 이용하여 구한다.
결과는 (2, 2) 모양의 어레이다.
x.dot(y)
array([[ 28., 64.],
[ 67., 181.]])
np.dot() 함수를 이용해도 동일한 결과를 얻는다.
np.dot(x, y)
array([[ 28., 64.],
[ 67., 181.]])
@ 연산자
np.dot() 함수 대신 @ 기호를 중위 연산자로 사용할 수 있다.
x @ y
array([[ 28., 64.],
[ 67., 181.]])
전치 어레이와 전치 행렬
전치 행렬은 주어진 행렬의 행과 열을 서로 교환해서 얻어진다.
위 전치 행렬에 사용된 2차원 어레이는 아래처럼 생성할 수 있다.
x = np.arange(1, 7).reshape((3, 2))
x
array([[1, 2],
[3, 4],
[5, 6]])
전치 행렬은 전치 어레이로 구현된다. 전치 어레이는 기존 어레이의 축을 교환하며, 뷰view를 이용한다. 즉, 새로운 어레이를 생성하지 않고 기존 어레이의 정보를 활용한다.
x.T
array([[1, 3, 5],
[2, 4, 6]])
y = np.arange(-6, 0).reshape((2, 3))
y
array([[-6, -5, -4],
[-3, -2, -1]])
y.T
array([[-6, -3],
[-5, -2],
[-4, -1]])
x y의 전치 행렬은 y의 전치 행렬과 x의 전치 행렬의 곱이다.
((x @ y).T == y.T @ x.T).all()
True
역행렬
역행렬은 numpy.linalg 모듈에 포함된 inv() 함수를 이용하여 구한다.
from numpy.linalg import inv
X = np.random.randn(5, 5)
X
array([[ 0.5101, -0.2548, -0.0844, 0.9943, -0.8696],
[ 1.6077, 1.5681, 2.8091, -1.0102, 1.598 ],
[ 1.1038, -0.1 , 0.638 , 1.8843, -0.909 ],
[ 0.0082, 0.1794, 0.1683, 0.5103, 1.2377],
[-0.5326, 1.2362, -0.3071, -1.2403, 0.4329]])
inv(X)
array([[ 5.7961, 0.782 , -3.0021, 0.9184, -0.1734],
[-0.3822, -0.0827, 0.7235, 0.06 , 0.8848],
[-4.2766, -0.2465, 2.2227, -0.9669, -0.2486],
[-1.4003, -0.2999, 1.158 , 0.199 , 0.1565],
[ 1.1761, 0.164 , -0.8648, 0.8426, -0.1579]])
X @ (inv(X)) 거의 항등 함수로 계산된다.
참고: 컴퓨터를 이용한 부동소수점 연산은 완벽함과 거리가 아주 멀다.
X @ (inv(X))
array([[ 1., 0., 0., -0., -0.],
[-0., 1., 0., -0., -0.],
[ 0., 0., 1., -0., -0.],
[ 0., 0., -0., 1., -0.],
[-0., -0., 0., 0., 1.]])
numpy.linalg 모듈에서 제공하는 선형대수 관련 함수들은 NumPy: 선형 대수에서
찾아볼 수 있다.
14.6. 난수 생성 함수#
가장 많이 사용된 무작위 수 생성함수 3개와 시드(seed)의 역할을 살펴본다.
np.random.randn()/np.random.normal() 함수
임의의 부동소수점을 표준 정규 분포를 따르면서 지정된 수만큼 생성한다. 예를 들어, 아래 코드는 표준 정규 본포를 따르는 5개의 부동소수점으로 구성된 어레이를 생성한다.
np.random.randn(5)
array([-1.4144, -0.7389, -1.5785, 0.6512, 0.4375])
1천개의 부동소수점을 표준 정규 분포를 따르도록 무작위로 생성한 다음 히스토그램을 그리면 무작위로 선택된 값들이 표준 정규 분포를 따른다는 것을 확인할 수 있다.
np.random.seed(1000)
samples = np.random.randn(1000)
plt.hist(samples, bins=100)
plt.show()
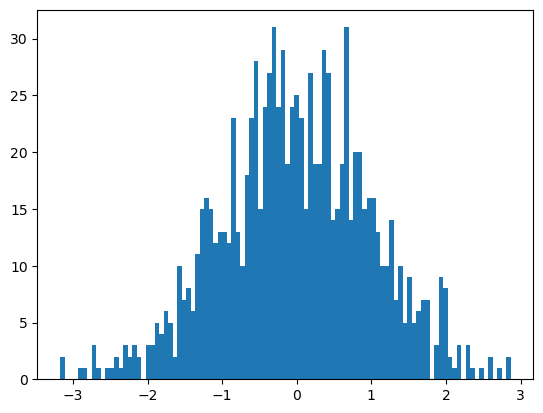
np.random.randn(n)은 np.random.normal(size=n)과 동일하게 작동한다.
np.random.seed(1000)
samples = np.random.normal(size=1000)
plt.hist(samples, bins=100)
plt.show()
np.random.rand()/np.random.uniform() 함수
0과 1사의 임의의 부동소수점을 균등 분포를 따르면서 지정된 수만큼 생성한다. 예를 들어, 아래 코드는 균등 본포를 따르는 5개의 부동소수점으로 구성된 어레이를 생성한다.
np.random.rand(5)
array([0.8388, 0.9598, 0.1309, 0.4877, 0.1036])
1천개의 부동소수점을 균등 분포를 따르도록 무작위로 생성한 다음 히스토그램을 그리면 무작위로 선택된 값들이 0부터 1 사이에서 균등하게 선택되었다는 것을 확인할 수 있다.
np.random.seed(1000)
samples = np.random.rand(10000)
plt.hist(samples, bins=100)
plt.show()
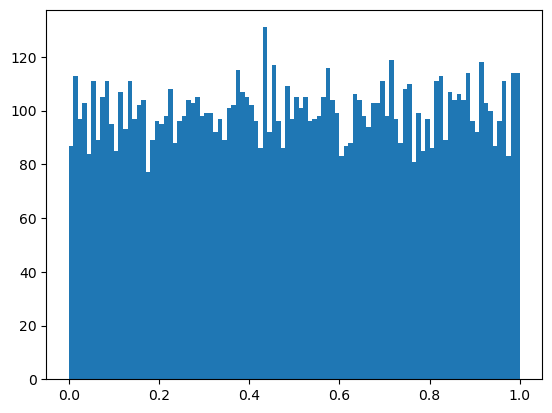
np.random.rand(n)은 np.random.uniform(0, 1, n)과 동일하게 작동한다.
np.random.seed(1000)
samples = np.random.uniform(0, 1, 10000)
plt.hist(samples, bins=100)
plt.show()
np.random.randint() 함수
지정된 구간 사이에서 임의의 정수를 균등 분포를 따르면서 지정된 수만큼 생성한다.
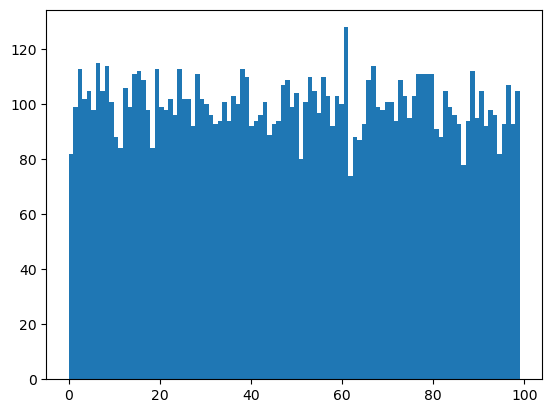
아래 코드는 0부터 100까지의 정수 중에서 1천 개의 정수를 균등 분포를 따르도록 무작위로 생성한 다음 히스토그램을 그린다. 무작위로 선택된 값들이 0부터 100사이에 균등하게 분포되어 있다는 것을 확인할 수 있다.
np.random.seed(1000)
samples = np.random.randint(0,100,10000)
plt.hist(samples, bins=100)
plt.show()
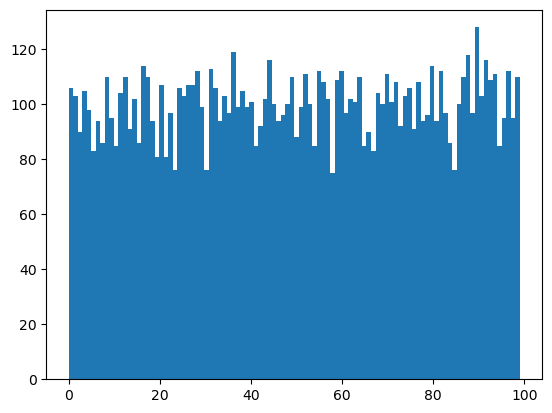
시드(seed)
위에서 살펴본 무작위 함수들은 원래 실행할 때마다 조금씩 다른 무작위수를 생성한다. 하지만 시드를 지정하면 무작위 수도 동일하게 결정된다. 시드는 컴퓨터가 사용하는 난수표(random number table)의 특정 지점을 지정한다. 무작위 함수를 실행할 때마다 시드가 1씩 커진다. 따라서 시드를 지정하면 동일한 시드가 설정되어 난수표에서 항상 동일한 값을 선택하게 된다.
np.random.seed(1234)
samples = np.random.randn(10000)
plt.hist(samples, bins=100)
plt.show()
시드를 달리하면 다른 결과가 나온다.
np.random.seed(17)
samples = np.random.randn(10000)
plt.hist(samples, bins=100)
plt.show()
np.random.seed(1234)
samples = np.random.rand(10000)
plt.hist(samples, bins=100)
plt.show()
np.random.seed(17)
samples = np.random.rand(10000)
plt.hist(samples, bins=100)
plt.show()
np.random.seed(1234)
samples = np.random.randint(0,100,10000)
plt.hist(samples, bins=100)
plt.show()
np.random.seed(17)
samples = np.random.randint(0,100,10000)
plt.hist(samples, bins=100)
plt.show()