17. 판다스 데이터프레임#
주요 내용
판다스 라이브러리가 제공하는 두 개의 모음 자료형을 소개한다.
SeriesDataFrame
기본 설정
pandas 라이브러리는 보통 pd 라는 별칭으로 사용된다.
import pandas as pd
import numpy as np
랜덤 시드, 어레이 내부에 사용되는 부동소수점 정확도, 도표 크기 지정 옵션 등은 이전과 동일하다.
np.random.seed(12345)
np.set_printoptions(precision=4, suppress=True)
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
Series와 DataFrame을 표로 보여줄 때 사용되는 행의 수 60이다.
pd.options.display.max_rows
60
보여지는 행의 수를 20으로 변경한다.
pd.set_option("display.max_rows", 20)
17.1. 시리즈#
판다스Pandas는 넘파이와 함께 데이터 분석 분야에서 가장 많이 활용되는 라이브러리다.
판다스가 제공하는 두 개의 자료형 Series와 DataFrame은
데이터를 다루기 위한 다양한 기능을 제공한다.
넘파이 어레이는 수치형 데이터를 처리하는 데에 특화된 반면에
판다스의 시리즈와 데이터프레임은 표(table) 형식으로 제공되는 모든 종류의 데이터를 다룬다.
먼저 시리즈를 소개한다.
17.1.1. 시리즈 생성과 인덱스#
시리즈는 1차원 어레이와 동일한 구조를 갖는다. 다만 인덱스index를 0, 1, 2 등이 아닌 임의의 값으로 지정할 수 있다. 시리즈를 생성하기 위해 리스트, 넘파이 1차원 어레이, 사전 등을 이용할 수 있다.
리스트와 어레이 활용
1차원 리스트 또는 어레이를 이용하여 간단하게 시리즈를 생성할 수 있다.
dtype은 시리즈에 포함된 항목들의 자료형을 가리키며 모든 항목은 포함하는 자료형을 가리킨다.
아래 코드는 리스트를 이용하여 시리즈를 생성한다. 인덱스를 별도로 지정하지 않으면 리스트, 넘파이 어레이 등에서 사용된 정수 인덱스가 사용된다.
ojb1 = pd.Series([4, 7, -5, 3])
ojb1
0 4
1 7
2 -5
3 3
dtype: int64
1차원 어레이도 이용할 수 있다.
ojb1 = pd.Series(np.array([4, 7, -5, 3]))
ojb1
0 4
1 7
2 -5
3 3
dtype: int64
사전 활용
사전을 이용하여 시리즈를 생성할 수 있다. 이때 키(key)는 인덱스로, 값은 항목으로 지정된다.
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
obj3
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
사전을 이용하더라도 인덱스로 구성된 리스트를 이용하여 따로 지정할 수 있다.
그러면 사전에 키로 사용되지 않은 인덱스는 누락되었다는 의미로 NaN이 표시된다.
또한 인덱스 리스트에 포함되지 않는 (사전의) 키는 시리즈에 포함되지 않는다.
California:sdata사전에 키로 사용되지 않았기에Nan으로 지정Utah:states리스트에 포함되지 않았기에 생성된 시리즈에 사용되지 않음.
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
17.1.2. name 속성과 values 속성#
name 속성
Series 객체와 시리즈의 Index 객체 모두 name 속성을 이용하여
사용되는 값들에 대한 정보를 저장한다.
아래 코드는 시리즈와 시리즈에 사용된 인덱스에 이름 속성을 지정한다.
시리즈 이름은 population(인구):
name='population'시리즈의 인덱스의 이름은 state(주 이름):
Index.name='state'
obj4.name = 'population'
obj4.index.name = 'state'
obj4
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
values 속성
values 속성은 시리즈의 항목으로 구성된 1차원 어레이를 가리킨다.
ojb1.values
array([ 4, 7, -5, 3])
17.1.3. index 속성#
index 속성은 인덱스로 사용된 값들로 구성된 Index 객체를 가리킨다.
자동으로 생성된 경우 정수 인덱스는 range와 유사한 RangeIndex 자료형으로 지정된다.
ojb1
0 4
1 7
2 -5
3 3
dtype: int64
ojb1.index
RangeIndex(start=0, stop=4, step=1)
index 속성을 변경하는 방식으로 기존에 사용된 인덱스를 완전히 새로운 인덱스로 대체할 수도 있다.
ojb1.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
ojb1
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int64
처음부터 인덱스를 지정하면서 시리즈를 생성할 수 있다.
index키워드 인자: 항목의 수와 동일한 길이를 갖는 리스트. 리스트에 포함된 항목 순서대로 인덱스 지정.
인덱스가 인덱스 리스트에 사용된 순서대로 지정됨에 주의하라.
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
d 4
b 7
a -5
c 3
dtype: int64
in 연산자
인덱스 라벨의 사용 사용 여부를 판단한다.
obj2
d 4
b 7
a -5
c 3
dtype: int64
'b' in obj2
True
'e' in obj2
False
Index 객체
index 키워드로 지정된 인덱스는 index 속성이 가리키며 Index 객체로 저장된다.
idx = obj2.index
idx
Index(['d', 'b', 'a', 'c'], dtype='object')
인덱스 객체는 1차원 어레이와 유사하게 동작한다. 예를 들어, 인덱싱과 슬라이싱은 리스트 또는 1차원 어레이의 경우와 동일하게 작동한다.
idx[1]
'b'
idx[1:]
Index(['b', 'a', 'c'], dtype='object')
하지만 시리즈와 데이터프레임의 인덱스로 사용되는
Index, RangeIndex 객체 등은 모두 수정을 허용하지 않는 불변immutable 자료형이다.
아래처럼 인덱싱을 이용하여 항목을 변경하려 하면 TypeError가 발생한다.
idx[1] = 'd'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[21], line 1
----> 1 idx[1] = 'd'
File ~/anaconda3/lib/python3.11/site-packages/pandas/core/indexes/base.py:5157, in Index.__setitem__(self, key, value)
5155 @final
5156 def __setitem__(self, key, value):
-> 5157 raise TypeError("Index does not support mutable operations")
TypeError: Index does not support mutable operations
17.1.4. 시리즈 리인덱싱#
reindex() 메서드를 이용하여 주어진 시리즈의 index를
이용하여 새로운 Index 객체를 갖는 새로운 시리즈를 생성한다.
설명을 위해 obj2를 이용한다.
obj2
d 4
b 7
a -5
c 3
dtype: int64
새로운 인덱스가 추가되면 NaN이 사용된다.
obj2_reindexed = obj2.reindex(['a', 'b', 'c', 'd', 'e'])
obj2_reindexed
a -5.0
b 7.0
c 3.0
d 4.0
e NaN
dtype: float64
지정되지 않은 인덱스는 무시된다.
obj2_reindexed = obj2.reindex(['a', 'c', 'd', 'e'])
obj2_reindexed
a -5.0
c 3.0
d 4.0
e NaN
dtype: float64
중복 인덱스 활용도 가능하다.
obj2_reindexed = obj2.reindex(['a', 'a', 'd', 'e'])
obj2_reindexed
a -5.0
a -5.0
d 4.0
e NaN
dtype: float64
17.1.5. 시리즈 리인덱싱과 결측치#
리인덱싱 과정에서 결측치가 발생할 때 여러 방식으로 채울 수 있다.
method 키워드 인자 활용
인덱스가 오름 또는 내림 차순으로 정렬되어 있는 경우에
method 키워드 인자를 이용하여 결측치를 주변 값으로 채울 수 있다.
설명을 위해 아래 시리즈를 이용한다.
obj5 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 5])
obj5
0 blue
2 purple
5 yellow
dtype: object
method=ffill: 결측치를 위쪽으로 가장 가깝게 위치한 값으로 채운다. 위쪽에 위치한 값이 없으면 결측치가 된다.
obj5.reindex(range(-1, 6), method='ffill')
-1 NaN
0 blue
1 blue
2 purple
3 purple
4 purple
5 yellow
dtype: object
method=bfill: 결측치를 아랫쪽으로 가장 가깝게 위치한 값으로 채운다.
obj5.reindex(range(-1, 6), method='bfill')
-1 blue
0 blue
1 purple
2 purple
3 yellow
4 yellow
5 yellow
dtype: object
method=nearest: 결측치를 가장 가깝게 위치한 값으로 채운다. 1번 인덱스 행의 항목이 0번이 아닌 2번 인덱스 행의 항목으로 채워진 것처럼 아래와 위쪽에 위치한 두 값의 거리가 같으면 아랫쪽에서 선택한다.
obj5.reindex(range(-1, 6), method='nearest')
-1 blue
0 blue
1 purple
2 purple
3 purple
4 yellow
5 yellow
dtype: object
결측치 채우기 2: fill_value 키워드 인자
리인덱싱 과정에서 발생하는 모든 결측치를 지정된 값으로 대체할 수 있다.
기본값은 NaN 이다.
obj5.reindex(range(-1, 6), fill_value='No Color')
-1 No Color
0 blue
1 No Color
2 purple
3 No Color
4 No Color
5 yellow
dtype: object
17.2. 데이터프레임#
데이데프레임DataFrame은 인덱스를 공유하는 여러 개의 시리즈를 다루는 객체다. 아래 그림은 세 개의 시리즈를 하나의 데이터프레임으로 만든 결과를 보여준다.
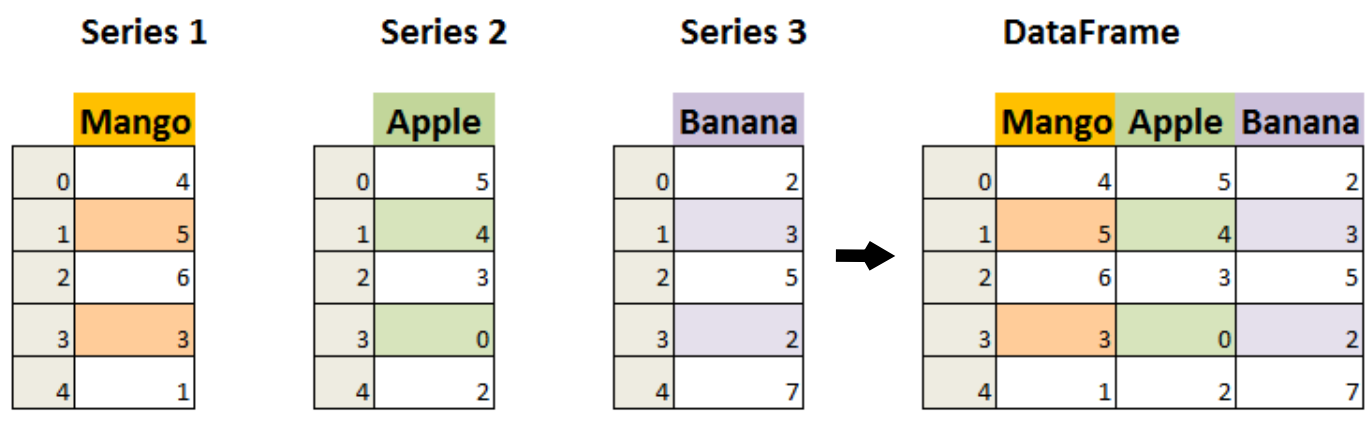
위 이미지에 있는 세 개의 시리즈는 다음과 같으며,
name 속성을 이용하여 각 시리즈의 이름도 함께 지정한다.
series1 = pd.Series([4, 5, 6, 3 , 1], name="Mango")
series1
0 4
1 5
2 6
3 3
4 1
Name: Mango, dtype: int64
series2 = pd.Series([5, 4, 3, 0, 2], name="Apple")
series2
0 5
1 4
2 3
3 0
4 2
Name: Apple, dtype: int64
series3 = pd.Series([2, 3, 5, 2, 7], name="Banana")
series3
0 2
1 3
2 5
3 2
4 7
Name: Banana, dtype: int64
17.2.1. 데이터프레임 생성#
pd.concat() 함수 활용
pd.concat() 함수도 여러 개의 시리즈를 묶어 하나의 데이터프레임을 생성한다.
단, 축을 이용하여 묶는 방식을 지정한다.
위 그림에서처럼 옆으로 묶으려면 열 단위로 묶는다는 의미에서 axis=1로 지정한다.
각 열의 이름은 해당 시리즈의 name이 가리키는 값으로 지정된다.
fruits = pd.concat([series1, series2, series3], axis=1)
fruits
| Mango | Apple | Banana | |
|---|---|---|---|
| 0 | 4 | 5 | 2 |
| 1 | 5 | 4 | 3 |
| 2 | 6 | 3 | 5 |
| 3 | 3 | 0 | 2 |
| 4 | 1 | 2 | 7 |
엑셀 파일로 보면 다음과 같다. 단, 인덱스가 1이 아닌 0부터 출발함에 주의한다.
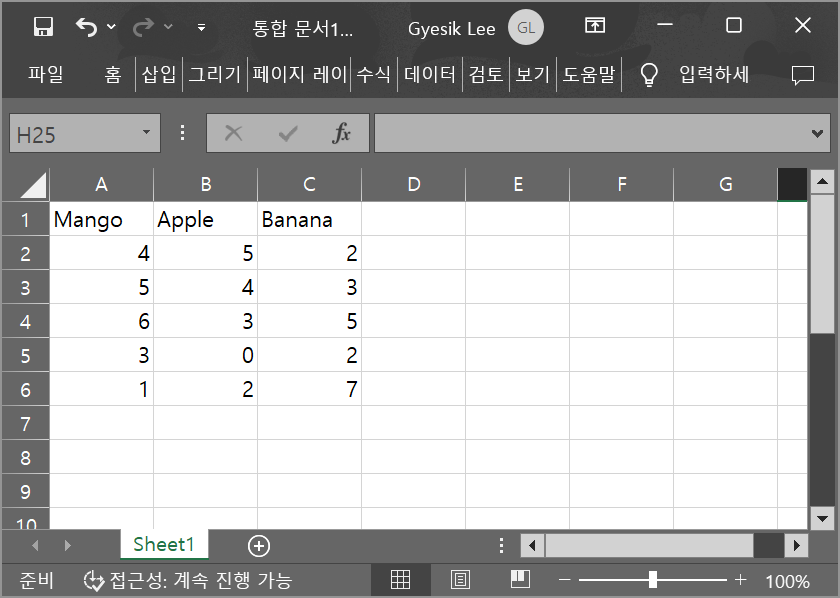
데이터프레임은 행과 열에 각각에 대해 Index 객체를 사용한다.
행 인덱스
fruits.index
RangeIndex(start=0, stop=5, step=1)
열 인덱스
fruits.columns
Index(['Mango', 'Apple', 'Banana'], dtype='object')
2차원 넘파이 어레이 활용
행과 열의 인덱스를 지정하면서 데이터프레임을 선언할 수 있다.
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['year', 'state', 'p', 'four'])
data
| year | state | p | four | |
|---|---|---|---|---|
| Ohio | 0 | 1 | 2 | 3 |
| Colorado | 4 | 5 | 6 | 7 |
| Utah | 8 | 9 | 10 | 11 |
| New York | 12 | 13 | 14 | 15 |
행 인덱스
data.index
Index(['Ohio', 'Colorado', 'Utah', 'New York'], dtype='object')
열 인덱스
data.columns
Index(['year', 'state', 'p', 'four'], dtype='object')
사전 활용
리스트를 값으로 갖는 사전을 이용하여 데이터프레임을 생성할 수 있다.
아래 코드에서 dict2는 state(주 이름), year(년도), pop(인구)을 키(key)로 사용하며,
해당 특성에 해당하는 데이터로 구성된 리스트를 값으로 갖는 사전 객체이다.
dict2 = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada', 'NY', 'NY', 'NY'],
'year': [2000, 2001, 2002, 2001, 2002, 2003, 2002, 2003, 2004],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2, 8.3, 8.4, 8.5]}
위 사전 객체를 데이터프레임으로 변환하면 다음과 같다.
frame2 = pd.DataFrame(dict2)
frame2
| state | year | pop | |
|---|---|---|---|
| 0 | Ohio | 2000 | 1.5 |
| 1 | Ohio | 2001 | 1.7 |
| 2 | Ohio | 2002 | 3.6 |
| 3 | Nevada | 2001 | 2.4 |
| 4 | Nevada | 2002 | 2.9 |
| 5 | Nevada | 2003 | 3.2 |
| 6 | NY | 2002 | 8.3 |
| 7 | NY | 2003 | 8.4 |
| 8 | NY | 2004 | 8.5 |
중첩 사전 활용
데이터프레임을 생성함에 있어서의 핵심은 2차원 행렬 모양을 갖느냐이기에 각 열에 해당하는 값으로 리스트, 어레이, 사전, 시리즈 등이 사용될 수 있다.
따라서 아래 모양의 중첩 사전을 활용하여 데이터프레임을 생성할 수 있다. 그러면 최상위 키는 열의 이름으로, 내부에 사용된 키는 행의 인덱스로 사용된다.
dict3 = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
위 중첩 사전을 이용하여 데이터프레임을 생성하면 다음과 같다. 다만, 두 사전의 키가 다름에 주의하라. 예를 들어, 2000 인덱스 행의 Nevada의 경우는 결측치로 처리된다.
frame3 = pd.DataFrame(dict3)
frame3
| Nevada | Ohio | |
|---|---|---|
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
| 2000 | NaN | 1.5 |
17.2.2. name 속성과 values 속성#
name 속성
시리즈의 경우와 동일한 방식으로 행과 열의 이름을 지정할 수 있다.
frame3.index.name = 'year' # 행 이름 지정
frame3.columns.name = 'state' # 열 이름 지정
frame3
| state | Nevada | Ohio |
|---|---|---|
| year | ||
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
| 2000 | NaN | 1.5 |
values 속성
항목들로 이루어진 2차원 어레이는 values 속성이 가리킨다.
frame3.values
array([[2.4, 1.7],
[2.9, 3.6],
[nan, 1.5]])
frame2.values
array([['Ohio', 2000, 1.5],
['Ohio', 2001, 1.7],
['Ohio', 2002, 3.6],
['Nevada', 2001, 2.4],
['Nevada', 2002, 2.9],
['Nevada', 2003, 3.2],
['NY', 2002, 8.3],
['NY', 2003, 8.4],
['NY', 2004, 8.5]], dtype=object)
17.2.3. columns 속성과 index 속성#
앞서 언급한 대로 데이터프레임은 행과 열 각각에 대해 Index 객체를 사용한다.
columns 속성
columns 속성을 이용하여 열의 순서를 지정할 수 있다.
dict2
{'state': ['Ohio',
'Ohio',
'Ohio',
'Nevada',
'Nevada',
'Nevada',
'NY',
'NY',
'NY'],
'year': [2000, 2001, 2002, 2001, 2002, 2003, 2002, 2003, 2004],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2, 8.3, 8.4, 8.5]}
pd.DataFrame(dict2, columns=['year', 'state', 'pop'])
| year | state | pop | |
|---|---|---|---|
| 0 | 2000 | Ohio | 1.5 |
| 1 | 2001 | Ohio | 1.7 |
| 2 | 2002 | Ohio | 3.6 |
| 3 | 2001 | Nevada | 2.4 |
| 4 | 2002 | Nevada | 2.9 |
| 5 | 2003 | Nevada | 3.2 |
| 6 | 2002 | NY | 8.3 |
| 7 | 2003 | NY | 8.4 |
| 8 | 2004 | NY | 8.5 |
새로운 열을 추가할 수도 있다.
이름만 지정할 경우 항목은 모두 NaN으로 처리된다.
frame2 = pd.DataFrame(dict2, columns=['year', 'state', 'pop', 'debt'])
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| 0 | 2000 | Ohio | 1.5 | NaN |
| 1 | 2001 | Ohio | 1.7 | NaN |
| 2 | 2002 | Ohio | 3.6 | NaN |
| 3 | 2001 | Nevada | 2.4 | NaN |
| 4 | 2002 | Nevada | 2.9 | NaN |
| 5 | 2003 | Nevada | 3.2 | NaN |
| 6 | 2002 | NY | 8.3 | NaN |
| 7 | 2003 | NY | 8.4 | NaN |
| 8 | 2004 | NY | 8.5 | NaN |
columns 속성을 확인하면 다음과 같다.
frame2.columns
Index(['year', 'state', 'pop', 'debt'], dtype='object')
index 속성
인덱스를 지정하려면 index 속성을 이용한다.
frame2 = pd.DataFrame(dict2, index=['one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine'])
frame2
| state | year | pop | |
|---|---|---|---|
| one | Ohio | 2000 | 1.5 |
| two | Ohio | 2001 | 1.7 |
| three | Ohio | 2002 | 3.6 |
| four | Nevada | 2001 | 2.4 |
| five | Nevada | 2002 | 2.9 |
| six | Nevada | 2003 | 3.2 |
| seven | NY | 2002 | 8.3 |
| eight | NY | 2003 | 8.4 |
| nine | NY | 2004 | 8.5 |
물론 columns, index 등 여러 속성을 동시에 지정할 수도 있다.
frame2 = pd.DataFrame(dict2, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine'])
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | NaN |
| three | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
| six | 2003 | Nevada | 3.2 | NaN |
| seven | 2002 | NY | 8.3 | NaN |
| eight | 2003 | NY | 8.4 | NaN |
| nine | 2004 | NY | 8.5 | NaN |
rename() 메서드
행 또는 열 라벨의 이름을 사전 객체를 이용하여 수정할 수 있다.
예를들어, 아래 코드는 행 라벨 'one'과 'three'가 대문자로 시작하는 행 라벨을 사용하는 데이터프레임을 생성한다.
frame2_index = frame2.rename(index={'one':'ONE', 'three':'THREE'})
frame2_index
| year | state | pop | debt | |
|---|---|---|---|---|
| ONE | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | NaN |
| THREE | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
| six | 2003 | Nevada | 3.2 | NaN |
| seven | 2002 | NY | 8.3 | NaN |
| eight | 2003 | NY | 8.4 | NaN |
| nine | 2004 | NY | 8.5 | NaN |
반면에 아래 코드는 대문자만 사용하는 열 라벨을 갖는 데이터프레임을 생성한다.
frame2_columns = frame2.rename(columns={'year':'YEAR', 'state':'STATE', 'pop':'POP', 'debt':'DEBT'})
frame2_columns
| YEAR | STATE | POP | DEBT | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | NaN |
| three | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
| six | 2003 | Nevada | 3.2 | NaN |
| seven | 2002 | NY | 8.3 | NaN |
| eight | 2003 | NY | 8.4 | NaN |
| nine | 2004 | NY | 8.5 | NaN |
행 라벨과 열 라벨이 동시에 수정된 데이터프레임을 생성할 수도 있다.
frame2_renamed = frame2.rename(index={'one':'ONE', 'three':'THREE'},
columns={'year':'YEAR', 'state':'STATE', 'pop':'POP', 'debt':'DEBT'})
frame2_renamed
| YEAR | STATE | POP | DEBT | |
|---|---|---|---|---|
| ONE | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | NaN |
| THREE | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
| six | 2003 | Nevada | 3.2 | NaN |
| seven | 2002 | NY | 8.3 | NaN |
| eight | 2003 | NY | 8.4 | NaN |
| nine | 2004 | NY | 8.5 | NaN |
in 연산자
인덱스와 열에 대한 특정 이름의 사용 여부는 in 연산자를 이용하여 확인한다.
'year' in frame2.columns
True
'ten' in frame2.index
False
Index 객체
시리즈와 데이터프레임의 index 와 columns 속성에
저장된 값은 Index 객체다.
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
index
Index(['a', 'b', 'c'], dtype='object')
frame3.columns
Index(['Nevada', 'Ohio'], dtype='object', name='state')
17.2.4. 데이터프레임 리인덱싱#
reindex() 메서드를 이용하여 주어진 데이터프레임의 index와 columns속성을
이용하여 새로운 Index 객체를 행과 열의 인덱스로 갖는 새로운 데이터프레임을 생성한다.
설명을 위해 아래 데이터프레임을 이용한다.
frame4= pd.DataFrame(np.arange(9).reshape((3, 3)),
index=['a', 'c', 'd'],
columns=['Ohio', 'Texas', 'California'])
frame4
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| c | 3 | 4 | 5 |
| d | 6 | 7 | 8 |
reindex() 메서드는 기본적으로 행의 index 에 대해 작동한다.
frame5 = frame4.reindex(['a', 'b', 'c', 'd'])
frame5
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 |
| b | NaN | NaN | NaN |
| c | 3.0 | 4.0 | 5.0 |
| d | 6.0 | 7.0 | 8.0 |
열의 columns에 대해서는 columns 키워드 인자를 활용한다.
states = ['Texas', 'Utah', 'California']
frame6= frame4.reindex(columns=states)
frame6
| Texas | Utah | California | |
|---|---|---|---|
| a | 1 | NaN | 2 |
| c | 4 | NaN | 5 |
| d | 7 | NaN | 8 |
행과 열 모두 중복 인덱스 사용이 가능하다.
frame7 = frame4.reindex(['a', 'a', 'b', 'c', 'd'])
frame7
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 |
| a | 0.0 | 1.0 | 2.0 |
| b | NaN | NaN | NaN |
| c | 3.0 | 4.0 | 5.0 |
| d | 6.0 | 7.0 | 8.0 |
states = ['Texas', 'Utah', 'California', 'California']
frame8 = frame4.reindex(index=['a', 'a', 'c', 'd'], columns=states)
frame8
| Texas | Utah | California | California | |
|---|---|---|---|---|
| a | 1.0 | NaN | 2.0 | 2.0 |
| a | 1.0 | NaN | 2.0 | 2.0 |
| c | 4.0 | NaN | 5.0 | 5.0 |
| d | 7.0 | NaN | 8.0 | 8.0 |
17.2.5. 데이터프레임 리인덱싱과 결측치#
시리즈 리인덱싱의 경우처럼 리인덱싱 과정에서 결측치가 발생할 경우
method 또는 fill_value 키워드 인자를 이용하여 결측치를 지정한 방식 또는
지정한 값으로 채울 수 있다.
설명을 위해 frame4를 이용한다.
frame4
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| c | 3 | 4 | 5 |
| d | 6 | 7 | 8 |
행 라벨이 정수형이 아니기에 아래 세 종류의 방법으로만 결측치를 채울 수 있음에 주의한다.
method=ffill활용
frame5 = frame4.reindex(['a', 'b', 'c', 'd'], method='ffill')
frame5
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 0 | 1 | 2 |
| c | 3 | 4 | 5 |
| d | 6 | 7 | 8 |
method=bfill활용
frame5 = frame4.reindex(['a', 'b', 'c', 'd'], method='bfill')
frame5
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 3 | 4 | 5 |
| c | 3 | 4 | 5 |
| d | 6 | 7 | 8 |
fill_value키워드 인자 활용
states = ['Texas', 'Utah', 'California']
frame6= frame4.reindex(columns=states, fill_value="No Info")
frame6
| Texas | Utah | California | |
|---|---|---|---|
| a | 1 | No Info | 2 |
| c | 4 | No Info | 5 |
| d | 7 | No Info | 8 |
17.2.6. 인덱스 초기화: reset_index() 메서드#
데이터프레임의 행을 삭제거나 정렬한 후에 인덱스를 재설정할 때 reset_index() 메서드를 활용한다.
예를 들어 frame4는 b 라벨이 없다.
frame4
| Ohio | Texas | California | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| c | 3 | 4 | 5 |
| d | 6 | 7 | 8 |
이런 경우 인덱스 라벨의 연속성을 위해 0, 1, 2 등으로 행의 순서를 정해줄 수도 있다.
reset_index() 메서드를 적용하면 행의 라벨은 하나의 열로 지정된다.
frame9 = frame4.reset_index()
frame9
| index | Ohio | Texas | California | |
|---|---|---|---|---|
| 0 | a | 0 | 1 | 2 |
| 1 | c | 3 | 4 | 5 |
| 2 | d | 6 | 7 | 8 |
drop=True 키워드 인자를 활용하면 사용되었던 행 라벨 인덱스를 버린다.
frame10 = frame4.reset_index(drop=True)
frame10
| Ohio | Texas | California | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
17.3. 문자열 메서드 활용#
시리즈와 Index 자료형은 str 속성을 이용하여 각각의 항목을 문자열로 변환하여 문자열 메서드를 적용해서
새로운 시리즈와 Index 자료형을 생성하는 기능을 제공한다.
시리즈에 문자열 메서드 적용
str 속성은 모든 항목을 문자열로 변환한 벡터를 가리킨다.
s = pd.Series(["A", "B", "C", "Aaba", "Baca", np.nan, "CABA", "dog", "cat"])
s.str
<pandas.core.strings.accessor.StringMethods at 0x7fa65f903390>
변환된 벡터에 문자열 메서드를 적용하면 새로운 시리즈가 생성된다.
s.str.lower()
0 a
1 b
2 c
3 aaba
4 baca
5 NaN
6 caba
7 dog
8 cat
dtype: object
Index 자료형에 문자열 메서드 적용
아래 데이터프레임을 이용한다.
df = pd.DataFrame(np.random.randn(3, 2), columns=[" Column A ", " Column B "], index=range(3))
df
| Column A | Column B | |
|---|---|---|
| 0 | -0.204708 | 0.478943 |
| 1 | -0.519439 | -0.555730 |
| 2 | 1.965781 | 1.393406 |
열 라벨 인덱스에 대해 문자열 메서드를 적용해보자.
소문자화
df.columns.str.lower()
Index([' column a ', ' column b '], dtype='object')
양끝의 공백 제거
df.columns.str.lower().str.strip()
Index(['column a', 'column b'], dtype='object')
중간에 위치한 공백을 밑줄(underscore)로 대체
df.columns.str.strip().str.lower().str.replace(" ", "_")
Index(['column_a', 'column_b'], dtype='object')
열 라벨을 소문자로는 변경하지 않으면서 모든 공백을 제거해보자.
columns1 = df.columns.str.strip().str.replace(" ", "_")
columns1
Index(['Column_A', 'Column_B'], dtype='object')
df.columns=columns1
df
| Column_A | Column_B | |
|---|---|---|
| 0 | -0.204708 | 0.478943 |
| 1 | -0.519439 | -0.555730 |
| 2 | 1.965781 | 1.393406 |
17.4. 데이터셋 불러오기와 저장하기#
csv 파일로 저장하기
frame2.to_csv("frame2.csv")
csv 파일 불러오기
pd.read_csv("frame2.csv")
| Unnamed: 0 | year | state | pop | debt | |
|---|---|---|---|---|---|
| 0 | one | 2000 | Ohio | 1.5 | NaN |
| 1 | two | 2001 | Ohio | 1.7 | NaN |
| 2 | three | 2002 | Ohio | 3.6 | NaN |
| 3 | four | 2001 | Nevada | 2.4 | NaN |
| 4 | five | 2002 | Nevada | 2.9 | NaN |
| 5 | six | 2003 | Nevada | 3.2 | NaN |
| 6 | seven | 2002 | NY | 8.3 | NaN |
| 7 | eight | 2003 | NY | 8.4 | NaN |
| 8 | nine | 2004 | NY | 8.5 | NaN |
엑셀 파일로 저장하기
frame2.to_excel("frame2.xlsx", sheet_name="Sheet1")
엑셀 파일 불러오기
pd.read_excel("frame2.xlsx", "Sheet1", index_col=None, na_values=["NA"])
| Unnamed: 0 | year | state | pop | debt | |
|---|---|---|---|---|---|
| 0 | one | 2000 | Ohio | 1.5 | NaN |
| 1 | two | 2001 | Ohio | 1.7 | NaN |
| 2 | three | 2002 | Ohio | 3.6 | NaN |
| 3 | four | 2001 | Nevada | 2.4 | NaN |
| 4 | five | 2002 | Nevada | 2.9 | NaN |
| 5 | six | 2003 | Nevada | 3.2 | NaN |
| 6 | seven | 2002 | NY | 8.3 | NaN |
| 7 | eight | 2003 | NY | 8.4 | NaN |
| 8 | nine | 2004 | NY | 8.5 | NaN |
17.5. 연습문제#
참고: (실습) 판다스 데이터프레임