17. 맵(Map)#
사전 자료형처럼 작동하는 자료형 일반을 Map 추상 자료형이라 부른다.
Map 객체는 키(key)와 값(value)으로 이루어진 쌍을 저장하며 키(key)를
이용하여 연관된 값(value)를 확인한다.
Map 클래스는 아래 기능을 제공해야 한다.
put(key, val): 키-값 쌍을 항목으로 추가. 키(key)가 이미 존재하는 경우 관련된 값(value)을 얻데이트함.get(key): 키와 연관된 값 확인. 키가 존재하지 않으면None반환.del:del map[key]방식으로 작동하며 지정된 키와 연관된 값을 함께 삭제함.len(): 항목 개수 반환in: 키(key)key in map방식으로 작동하며 키의 존재 여부 확인.
맵(Map) 추상 자료형의 다양한 활용법을 소개한다.
해시 테이블
이진탐색트리
균형 이진탐색트리(AVL 트리)
17.1. 해싱과 해시 테이블#
해싱(hashing) 기법을 적용하여 \(O(1)\) 시간복잡도의 탐색을 허용하는 자료구조를 알아본다. 이 자료구조는 해시 테이블(hash table)을 이용하여 새로운 항목이 저장될 위치가 어디인지 미리 확인한 다음에 저장한다.
해시 테이블의 저장 공간 각각을 슬롯(slot)이라 부르며 탐색 대상 항목이 있어야 하는 슬롯의 위치인 인덱스를 먼저 확인한 후에 실제로 해당 슬롯에 저장되어 있는지 여부만을 확인하기에 시간복잡도가 \(O(1)\)이 될 수 있다.
주의사항: 항목이 위치해야 할 위치를 계산하는 시간은 일정하다는 전제조건이 성립해야 한다.
여기서는 리스트를 이용하여 해시 테이블을 구현한다. 아래 그림은 크기가 11인 비어 있는 해시 테이블을 보여준다.

17.1.1. 해시 함수#
해시 함수(hash function)는 항목이 저정되어야 할 슬롯의 위치를 계산한다. 길이가 \(m\)인 해시 테이블을 사용한다면 해시 함수의 반환값은 \(0\)과 \(m-1\) 사이의 값을 임의의 항목에 대해 계산해야 한다.
해시 알고리즘 1: 나머지 함수
입력값을 해시 테이블의 길이로 나눈 나머지를 항목이 저장되어야 할 슬롯의 위치(인덱스)로 지정한다.
h(item) = item % 11
예를 들어 54, 26, 93, 17, 77, 31 에 대한 해시값(hash value)은 다음과 같다.
항목 |
해시값 |
|---|---|
54 |
10 |
26 |
4 |
93 |
5 |
17 |
6 |
77 |
0 |
31 |
9 |
해시값을 활용하여 각각의 값을 리스트의 해당 인덱스에 저장한 결과는 다음과 같다.

탐색 시간 복잡도
나머지 함수를 활용하여 생성된 해시 테이블에 대한 탐색 알고리즘은 \(O(1)\)이다. 이유는 항목의 나머지를 계산한 다음에 해당 위치의 값을 한 번 확인만하면 되기 때문이다. 나머지 계산에 드는 시간은 해시 테이블의 길이와 무관하게 무관하게 거의 일정하다.
해시 테이블 점유율
점유율(load factor)은 해시 테이블에서 항목이 자리한 슬롯의 비율이며 보통 \(\lambda\)(람다)로 표시한다.
위 해시 테이블의 점유율은 \(\frac{6}{11}\)이다.
참고: 점유율(\(\lambda\))은 해싱 관련 함수들의 시간/공간 복잡도를 계산하는 데에 중요한 역할을 수행한다(9.2.4절 참조).
충돌 문제
앞서 설명한 나머지 방식은 나머지가 동일하면 저장되어야 할 위치가 중복되는 문제를 갖는다. 이런 문제를 충돌(collision)이라 부른다. 예를 들어 44, 77 등은 모두 해시 테이블의 길이인 11로 나누면 나머지가 0이다.
임의의 데이터셋에 대해 충돌이 절대로 발생하지 않는 해시 함수와 해시 테이블을
구현하는 완전한 해시 함수는 존재하지 않는다.
일반적으로 해시 테이블의 길이를 충분히 늘리면 충돌이 발생하지 않는다.
예를 들어 2021280001 등과 같은 10자리 학번을 충돌없이
저장하기 위해 길이가 100억인 해시 테이블을 활용할 수 있다.
하지만 학생 수가 고작 몇 천명이라면 엄청난 양의 메모리를 낭비하게 되는 셈이다.
따라서 해시 테이블의 크기를 최소화하면서 충돌을 방지하는 해시 함수를 고안해야 하는 것이 주요 과제이다. 여기서는 나머지 방식을 개선하는 과정을 통해 충돌이 보다 적게 발생하는 다양한 해시 테이블 구현 기법을 알아본다.
참고: 나머지 계산은 어떤 형태로든 여전히 활용된다.
해시 알고리즘 2: 자릿수 접기 기법
자릿수 접기(digit folding) 기법은 주어지는 수를 일정 크기로 쪼개서 생성된 값들에 나머지 활용 기법을 적용한다. 단, 마지막으로 쪼개진 수의 경우 다른 수들의 자릿수와 다를 수 있다.
방식 1
예를 들어, 전화번호 43-655-5461 이라는 전화번호를 저장하려 할 때 두 자리씩 쪼개면 43, 65, 55, 46, 1이 생성되고, 이 수들을 다 더합면 210을 얻는다.
11개의 슬롯을 갖는 해시 테이블에 위 전화번호를 저장하기 위해 나머지 기법을 적용한다. 즉, 210을 11로 나눈 나머지가 1이기에 전화번호 43-655-5461은 1번 슬롯에 저장된다.
방식 2
일정 길이로 쪼갠 값들을 더해줄 때 두 개 중에 하나는 숫자를 뒤집어서 더하는 방식이다. 이전과 동일한 전화번호를 2자로 끊어서 생성된 번호를 다음처럼 둘 중에 하나는 뒤집어서 더한 후 11로 나눈 나머지를 계산하면 다른 슬롯으로 지정된다.
그리고 219를 11로 나눈 나머지는 10이다.
방식 3
중간제곱법(mid-square method)은 주어진 수를 제곱한 후 중간에 위치한 몇 개의 숫자를 대상으로 나머지 기법을 적용한다. 예를 들어, 44에 대해 먼저 제곱을 계산한다.
이제 중간에 위치한 9와 3을 추출하여 생성된 수 93에 대해 나머지 기법을 적용한다. 해시 테이블의 크기가 11이라면 93을 11로 나눈 나머지 5가 저장될 슬롯의 인덱스가 된다.
아래 테이블은 다양한 항목에 대해 나머지 기법과 중간제곱법을 적용한 결과가 어떻게 다른지를 보여준다. 단, 해시 테이블의 길이는 11이다.
항목 |
나머지 |
중간제곱 |
|---|---|---|
54 |
10 |
3 |
26 |
4 |
7 |
93 |
5 |
9 |
17 |
6 |
8 |
77 |
0 |
4 |
31 |
9 |
6 |
문자열 해싱
문자열에 대한 해시 함수는 각 문자에 대응하는 정수 유니코드를 생성하는
ord() 함수를 이용한다.
예를 들어, 문자열 "cat"에 사용된 세 개의 문자 각각에 대한 정수 유니코드는 다음과 같다.
print(ord("c"))
print(ord("a"))
print(ord("t"))
99
97
116
이제 생성된 수들에 앞서 설명한 해시 알고리즘 중에 한 가지 방식을 적용하면 된다.
방식 1
예를 들어, 얻어진 수를 모두 더해 해시 테이블의 길이로 나눈 나머지를 활용하는 방식을 적용하는 과정은 다음과 같다. 단, 해시 테이블의 길이는 11이라고 가정한다.
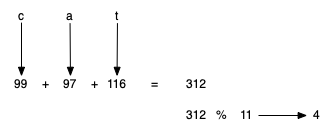
아래 함수 hash_str() 함수가 앞서 설명한 알고리즘을 구현한다.
def hash_str(a_string, table_size):
return sum([ord(c) for c in a_string]) % table_size
방식 2
이전 방식은 서로 어구전철(anagram)인 단어에 대해 동일한 값을 계산한다. 즉, 어구전철 단어를 구별하지 못한다.
hash_str("cat", 11)
4
hash_str("act", 11)
4
이 단점을 해결하기 위해 각 문자의 위치 정보를 해시값을 계산할 때 함께 활용한다.
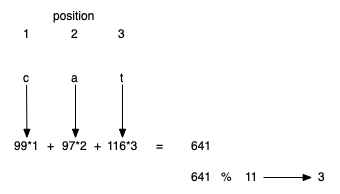
def hash_str(a_string, table_size):
return sum([ord(c)* (i+1) for i, c in enumerate(a_string)]) % table_size
hash_str("cat", 11)
3
hash_str("act", 11)
5
해시 함수의 복잡도
해시값을 계산하는 알고리즘이 너무 복잡하면 별 의미가 없다. 그 대신에 리스트에 임의로 항목을 저장한 후에 순차탐색 또는 정렬 후 이진탐색 등으로 탐색을 진행하는 편이 더 나을 수 있다.
17.1.2. 충돌 해결법#
모든 경우에 완벽한 해시 함수는 존재하지 않는다고 했다. 따라서 서로 다른 항목이 동일한 해시값을 갖는 충돌이 발생했을 때 처리 방법을 항상 고민해야 한다.
충돌 해결법 1: 빈자리 찾기
빈자리 찾기(open addressing)는 해시값으로 지정된 슬롯에 이미 다른 항목이 자리 잡고 있을 때 오른편으로 가장 가까운 빈자리를 선형 탐사(linear probing)하여 찾은 후 해당 자리에 항목을 추가하는 알고리즘이다. 선형 탐사 과정에서 리스트의 오른편 끝에 다다른다면 경우에 따라 리스트의 처음부터 다시 선형 탐사를 시작할 수도 있다.
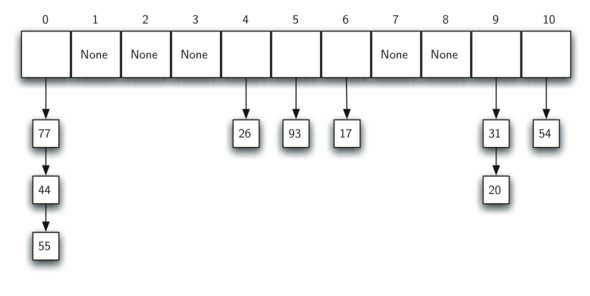
아래 그림은 54, 26, 93, 17, 77, 31을 나머지 기법으로 리스트에 추가한 결과이다.
여기에 44, 55, 20을 빈자리 찾기 기법으로 추가한 결과는 다음과 같다.
44 추가하기: 11로 나눈 나머지 0
0번 이미 채워젔음.
따라서 1번 인덱스에 추가.
55 추가하기: 11로 나눈 나머지 0.
0번, 1번이미 채워젔음.
따라서 2번 인덱스에 추가.
20 추가하기: 11로 나눈 나머지 9.
9번, 10번 이미 채워젔음.
리스트 처음으로 돌아감.
0번, 1번, 2번 이미 채워졌음.
따라서 3번 인덱스에 추가.

빈자리 찾기 방식으로 채워진 해시 테이블에서 탐색하려면 항목 채우기 방식을 그대로 따라가면서 항목을 확인하거나 빈자리가 나올 때까지 선형 탐사를 반복한다. 예를 들어, 20의 포함여부를 확인하려면 아래 과정을 수행한다.
11로 나눈 나머지 9 확인.
9번 슬롯: 20 아님
10번 슬롯: 20 아님
리스트 처음으로 돌아감.
0번, 1번, 2번 모두 20 아님.
3번 슬롯에서 20 확인.
결론: 20 있음.
반면에 27의 포함여부 확인과정은 다음과 같다.
11로 나눈 나머지 5 확인.
5번 슬롯: 27 아님
6번 슬롯: 27 아님
7번 슬롯: 비어 있음.
결론: 27 없음.
군집화와 군집화 해결책
빈자리 찾기 방식은 항목들이 해시 테이블의 한쪽에서 군집(cluster)을 형성할 수 있다는 것이다. 즉, 군집화(clustering) 문제가 발생할 수 있다. 군집화가 발생하면 일부 항목이 원래 위치해야 할 슬롯으로부터 너무 멀리 떨어져 저장되어야 하는 문제가 따라온다. 아래 그림은 군집화로 인해 20이 엉뚱한 슬롯에 저장됨을 잘 보여준다.

리해싱(rehashing)
빈 자리 찾기를 몇 칸씩 슬롯을 건너뛰며 찾으면 군집화를 약화시킬 수 있다. 예를 들어, 아래 그림은 차례대로 44, 55, 20을 충돌이 발생하면 3칸씩 건너 뛰며 빈자리를 찾아 추가한 결과를 보여준다.

충돌이 발생했을 때 한 칸 또는 여러 칸을 주기적으로 건너 뛰며 빈자리를 찾는 방식을 리해싱(rehashing)이라 한다. 리해싱을 사용할 때 해시 테이블의 모든 슬롯이 방문되는 것을 보장해야 한다. 예를 들어 해시 테이블의 길이가 짝수이고 4칸씩 건너뛰면 홀 수 인덱스의 슬롯은 전혀 점유되지 않을 수도 있다. 이런 이유로 해시 테이블의 길이는 11과 같은 소수(prime number)를 사용한다.
제곱 탐사
제곱 탐사(quadratic probing)는 충돌이 발생했을 때
건너 뛰는 슬롯의 수를 제곱수 만큼 늘려가며 찾는다.
예를 들어, 해시값 h에 대해 해당 슬롯이 이미 점유되었을 때
다음 빈칸은 h+1, h+4, h+9, h+16, h+25 등을
대상으로 차례대로 점유 여부를 확인한다.
예를 들어, 아래 그림은 차례대로 44, 55, 20을 충돌이 발생하면
제곱 탐사 방식을 적용하여 추가한 결과를 보여준다.

체이닝
체이닝(chaining)은 충돌이 발생했을 때 다른 빈칸을 찾는 대신 해당 슬롯에 다른 항목들과 함께 모음자료형의 항목으로 저장하는 방식이다. 아래 그림은 54, 26, 93, 17, 77, 31, 44, 55, 20을 체이닝 방식으로 저장한 결과를 보여준다.
해시 테이블 탐색은 먼저 해시값을 계산해서 지정된 슬롯을 확인한 다음에 포함되어 있는 모음 자료형에서 해당 항목을 탐색한다. 체이닝 방식은 각 슬롯마다 저장되는 항목의 수를 평균적으로 훨씬 낮추기에 탐색이 그만큼 빠르게 진행되도록 한다.
퀴즈
길이가 13인 해시 테이블에 27과 130을 항목으로 추가할 때 사용하는 슬롯의 인덱스는 무엇인가?
정답: 1과 0
퀴즈
113 , 117 , 97 , 100 , 114 , 108 , 116 , 105 , 99을 길이가 11인 해시 테이블에 빈자리 찾기 방식으로 입력한 결과를 묘사하라. 빈칸은 밑줄 두개로 표현하며, 건너 뛰는 칸의 수는 1로 한다.
정답: 99, 100, __, 113, 114, __, 116, 117, 105, 97, 108
17.1.3. HashTable 클래스 구현#
해시 테이블(HashTable) 클래스를 이용하여 항목 탐색을 \(O(1)\) 시간으로 실행하는
Map 추상 자료형을 구현한다.
클래스에 포함되는 메서드는 다음과 같다.
생성자
키와 값을 저장하기 위해 두 개의 리스트 활용. 하나의 키-값 쌍은 동일한 인덱스에 저장됨.
첫째 리스트(
slots): 키 저장둘째 리스트(
data): 값 저장
해시 테이블 길이(
size): 11 (소수 사용)
put() 메서드
다음 두 함수 활용
해시 함수(
hash_function()): 나머지 알고리즘리해싱(
rehash()): 선형 탐사. 1칸씩 이동하며 빈자리 찾기.
hash_function() 메서드
항목을 해시 테이블의 길이로 나눈 나머지 값 반환
rehash() 메서드
선형 탐사. 1칸씩 이동하며 빈자리 찾기
get() 메서드
처음 해시값에서 시작하여 선형 탐사 기법 적용.
리스트를 한 바퀴 돌아 제자리로 돌아오면 탐색 중단.
이외에 __getitem__(), __setitem__() 메서드를
지원해서 대괄호([]) 연산자를 사용하도록 해야 한다.
또한 __in__()과 __len__() 메서드를 구현해야 하지만
연습문제로 남겨둔다.
HashTable 클래스
class HashTable:
def __init__(self):
self.size = 11
self.slots = [None] * self.size
self.data = [None] * self.size
def put(self, key, data):
hash_value = self.hash_function(key, len(self.slots))
if self.slots[hash_value] is None:
self.slots[hash_value] = key
self.data[hash_value] = data
else:
if self.slots[hash_value] == key:
self.data[hash_value] = data # replace
else:
next_slot = self.rehash(hash_value, len(self.slots))
while (
self.slots[next_slot] is not None
and self.slots[next_slot] != key
):
next_slot = self.rehash(next_slot, len(self.slots))
if self.slots[next_slot] is None:
self.slots[next_slot] = key
self.data[next_slot] = data
else:
self.data[next_slot] = data
def hash_function(self, key, size):
return key % size
def rehash(self, old_hash, size):
return (old_hash + 1) % size
def get(self, key):
start_slot = self.hash_function(key, len(self.slots))
position = start_slot
while self.slots[position] is not None:
if self.slots[position] == key:
return self.data[position]
else:
position = self.rehash(position, len(self.slots))
if position == start_slot:
return None
def __getitem__(self, key):
return self.get(key)
def __setitem__(self, key, data):
self.put(key, data)
# 사전 형식으로 출력
def __repr__(self):
aDict = {self.slots[i]:self.data[i] for i in range(len(self.slots))}
return aDict.__repr__()
aHash = HashTable()
aHash[54] = "cat"
aHash[26] = "dog"
aHash[93] = "lion"
aHash[17] = "tiger"
aHash[77] = "bird"
aHash[31] = "cow"
aHash[44] = "goat"
aHash[55] = "pig"
aHash[20] = "chicken"
print(aHash)
{77: 'bird', 44: 'goat', 55: 'pig', 20: 'chicken', 26: 'dog', 93: 'lion', 17: 'tiger', None: None, 31: 'cow', 54: 'cat'}
print(aHash[20])
print(aHash[17])
chicken
tiger
aHash[20] = "duck"
print(aHash[20])
print(aHash[99])
duck
None
연습
__in__()과 __len__() 메서드를 구현하라.
17.1.4. 해싱 분석#
충돌이 없는 해시 테이블에 대한 탐색 시간은 \(O(1)\)이다. 하지만 충돌이 발생하는 경우 시간 복잡도 계산은 그리 간단하지 않으며 여기서는 자세히 다루지 않는다. 다만 알려진 결과만 간단하게 정리한다.
점유율(\(\lambda\))과 시간복잡도
점유율(\(\lambda\))이 탐색 시간에 많은 영향을 미친다.
점유율이 0에 가까운 경우
충돌 확률 매우 낮음.
\(O(1)\) 시간에 가깝게 탐색 가능.
점유율이 1에 가까운 경우
충돌 확률 매우 높음.
\(O(1)\) 시간 보다 느리게 탐색 진행됨.
**빈자리 찾기 알고리즘 시간 복잡도 **
선형 탐사를 사용하는 빈자리 찾기 알고리즘에서 충돌이 발생했을 때 실행해야 하는 비교 횟수는 다음과 같다.
항목이 존재하는 경우 평균 비교 횟수: \(\frac{1}{2}\left(1+\frac{1}{1-\lambda}\right)\)
항목이 존재하지 않는 경우 평균 비교 횟수: \(\frac{1}{2}\left(1+\left(\frac{1}{1-\lambda}\right)^2\right)\)
체이닝 기법 시간 복잡도
체이닝 기법에 사용되는 알고리즘에 따라 충돌이 발생했을 때 실행해야 하는 비교 횟수는 다르지만 기본적으로 선형 탐사 방식보다 빠르며, 해싱은 기본적으로 체이닝 기법을 활용한다.
참고: 보다 자세한 내용은 GeeksforGeeks - Hashing | Set 2 (Separate Chaining)를 참조한다.
연습문제
해시 테이블의 점유도가 다음과 같을 때 평균 비교횟수를 계산한 후에 언제 해시 테이블의 슬롯이 부족하다고 느껴지는지를 설명하라.
10%
25%
50%
75%
90%
99%
문자열 해싱에 각 문자의 인덱스를 가중치로 활용하는 다른 방식을 생각한 후에 기존 방식과 비교하여 장단점을 설명하라.
17.2. 이진탐색트리#
이진트리에 값을 저장하여 항목 탐색을 키와 값의 관계로 작동하도록 할 수 있다. 즉, 이진트리를 맵(Map) 추상 자료형으로 활용하여 매우 효율적인 탐색을 실행할 수 있다.
17.2.1. 정의#
이진탐색트리의 마디에 사용되는 키는 모두 아래 특성을 만족한다.
부모 마디보다 작은 키: 부모의 왼쪽 서브트리에 위치
부모 마디보다 큰 키: 부모의 오른쪽 서브트리에 위치
예제
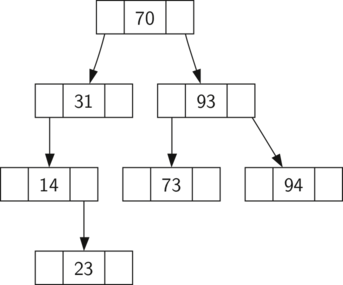
아래 그림은 70, 31, 93, 94, 14, 23, 73를 차례대로 이진탐색트리에 추가한 결과를 보여준다.
70 추가: 루트
31 추가: 루트 왼쪽 자식 마디
93 추가: 루트 오른쪽 자식 마디
94 추가: 93의 오른쪽 자식 마디
14 추가: 31의 왼쪽 자식 마디
23 추가: 14의 오른쪽 자식 마디
73 추가: 93의 왼쪽 자식 마디
17.2.2. 구현#
8장 트리와 힙에서 정의한 BinaryTree 클래스를 이용하여 이진탐색트리를 구현하기에는
다음 두 요소 때문에 매우 어렵다.
트리의 루트 마디를 별도로 기억해야 한다.
각 마디에 저장되는 부모자식 정보가 항목이 추가 또는 삭제될 때마다 수정되어야 한다.
17.2.2.1. BinarySearchTree 클래스와 TreeNode 클래스#
여기서는 아래 두 개의 클래스를 활용하여 이진탐색트리를 구현한다.
BinarySearchTree클래스root속성: 이진탐색트리의 루트 마디 지정.기본값:
None. 즉, 마디가 전혀 없는 이진탐색트리 생성.
지정되는 루트 마디는
TreeNode클래스의 객체예제: 아래 그림의 빨강 화살표.
TreeNode클래스부모 마디와 자식 마디 사이의 관계를 지정함.
parent: 부모 마디left_child: 왼쪽 자식 마디right_child: 오른쪽 자식 마디
예제: 아래 그림 참조
빨강 화살표: 루트 마디 참조
검정 화살표: 자식 참조
파랑 화살표: 부모 참조
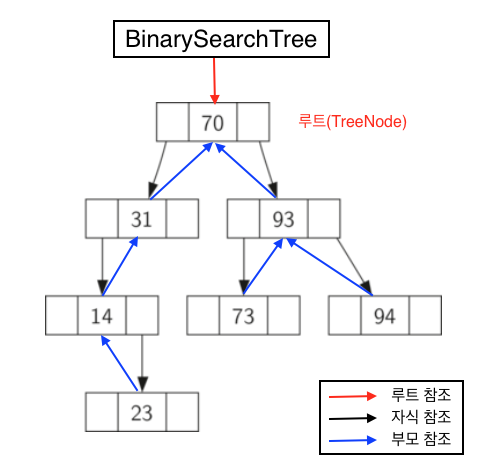
두 클래스의 상호작용
BinarySearchTree 클래스의 객체는 루트가 존재하는지 여부만을 확인하며,
TreeNode 객체를 루트로 사용하는 경우 마디의 추가/삭제와 업데이트,
부모-자식간의 관계 정보 확인 및 업데이트 등을
활용하는 메서드를 제공한다.
반면에 TreeNode 객체는 BinarySearchTree 클래스의 메서드가
수행하는 기능을 지원하는 메서드를 포함한다.
TreeNode 클래스의 메서드
TreeNode 클래스는 기본적으로 자식과 부모 마디에 대한 정보를 저장하고 활용하며,
이를 위해 제공되는 메서드는 다음과 같다.
속성 변수
self.key: 마디의 키self.value: 키와 연관된 값self.left_child: 왼쪽 자식 마디(TreeNode객체)self.right_child: 오른쪽 자식 마디(TreeNode객체)self.parent: 부모 마디(TreeNode객체)
is_left_child(self): 자신이 부모 마디의 왼쪽 자식인지 여부 판단is_right_child(self): 자신이 부모 마디의 오른쪽 자식인지 여부 판단is_root(self): 자신이 루트 마디인지 여부 판단. 즉, 부모 마디가 없는지 여부 판단.is_leaf(self): 자신이 잎루 마디인지 여부 판단. 즉, 자식 마디를 전혀 갖지 않는지 여부 판단.has_a_child(self): 하나 이상의 자식 마디를 갖는지 여부 판단.has_children(self): 왼쪽, 오른쪽 자식 마디 모두 갖는지 여부 판단.replace_valuee(self, key, value, left, right):자신의 키와 값 변경
왼쪽, 오른쪽 자식 마디 지정 후 자신을 해당 마디들의 부모로 지정
find_successor(self): 현재 마디의 계승자 탐색좌우 자식 모두를 갖는 마디를 삭제하고자 할 경우 우측 서브트리의 최소 키(key)를 갖는 마디를 계승자로 지정.
일반적으로 현재 마디의 키 다음으로 큰 키를 갖는 마디를 찾아야 함. 프로그래밍 실습 문제 참조.
계승자는 최대 한 개의 자식 마디를 가지게 됨.
find_min(self): 현재 마디를 루트로 갖는 서브트리에서 사용된 키의 최솟값맨 하단 좌측에 위치한 마디의 키
splice_out(self): 계승자 제거.제거되는 마디의 위치로 계승자를 옮기기 위해 계승자가 원래 있던 자리에서 제거하는 과정
계승자는 최대 하나의 자식 마디를 갖기에 나머지 마디를 계승자의 부모 마디에 연결만 해주면 됨.
__iter__(self): 중위순회방식으로 루트마디에서 연결된 모드 마디의 키(key)를 확인하는 이터레이터
TreeNode 클래스 전체 코드는 다음과 같다.
# 트리의 마디 클래스: 키와 값으로 이루어지며 좌우 자식과 부모 마디 정보 함께 보유
class TreeNode:
def __init__(self, key, value, left=None, right=None, parent=None):
self.key = key # 키
self.value = value # 값
self.left_child = left # 좌측 자식 마디
self.right_child = right # 우측 자식 마디
self.parent = parent # 부모 마디
# 좌측 자식 마디: 부모의 좌측 자식 마디 여부
def is_left_child(self):
return self.parent and self.parent.left_child is self
# 우측 자식 마디: 부모의 우측 자식 마디 여부
def is_right_child(self):
return self.parent and self.parent.right_child is self
# 루트: 부모가 없을 때
def is_root(self):
return not self.parent
# 잎: 자식이 없을 때
def is_leaf(self):
return not (self.right_child or self.left_child)
# 자식 존재 여부
def has_a_child(self):
return self.right_child or self.left_child
# 좌우측 두 자식 모두 존재 여부
def has_children(self):
return self.right_child and self.left_child
# 키, 값, 좌우 자식 지정
def replace_value(self, key, value, left, right):
self.key = key
self.value = value
self.left_child = left
self.right_child = right
# 새 자식의 부모로 자신을 지정
if self.left_child:
self.left_child.parent = self
if self.right_child:
self.right_child.parent = self
# 현재 마디의 계승자 마디 탐색
# 우측 자식이 있는 경우만 다뤄도 여기서는 목적 달성.
# 모든 경우를 다루는 경우는 프로그래밍 실습 과제 참조.
def find_successor(self):
if self.has_children():
successor = self.right_child.find_min()
return successor
# 현재 트리에 사용된 가장 작은 키
def find_min(self):
current = self
while current.left_child:
current = current.left_child
return current
# 계승자 마디 삭제 후 자식 마디들을 부모 마디에 이어 붙이기
# 계승자는 자식을 하나만 갖기에 가능함.
def splice_out(self):
if self.is_leaf():
if self.is_left_child():
self.parent.left_child = None
else:
self.parent.right_child = None
elif self.left_child:
if self.is_left_child():
self.parent.left_child = self.left_child
else:
self.parent.right_child = self.left_child
self.left_child.parent = self.parent
else:
if self.is_left_child():
self.parent.left_child = self.right_child
else:
self.parent.right_child = self.right_child
self.right_child.parent = self.parent
# 이터레이터: 중위순회방식으로 키(key) 확인
def __iter__(self):
if self:
if self.left_child:
for elem in self.left_child:
yield elem
yield self.key
if self.right_child:
for elem in self.right_child:
yield elem
BinarySearchTree 클래스의 메서드
BinarySearchTree 클래스에서 제공하는 기능은 다음과 같다.
기능 1: 항목 추가
지정된 키와 값을 하나의 마디에 추가하거나 업데이트 한다.
put(self, key, value): 적절한 위치의 마디의 키(key)와 값으로 지정.루트가 없는 경우: 루트 마디로 지정
루트가 있는 경우:
_put(self, key, value, current_node)재귀 메서드를 활용하여 적절한 위치의 마디로 지정.키(key)가 이미 존재하는 경우 값(value) 업데이트.
아래 그림은 19를 _put(self, key, value, current_node) 함수가 적절한 위치에 넣는
과정을 보여준다.
19와 비교되는 마디는 회색 마디로 표시되었다.
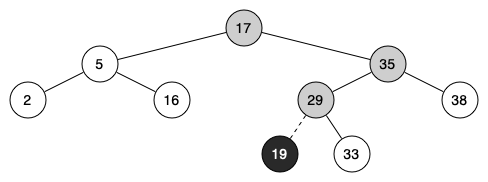
기능 2: 키의 값 확인
지정된 키(key)의 값(value)를 확인하는 일은 put() 메서드와 유사하다.
get(self, key): 지정된 키(key)를 갖는 마디에 저장된 값(value) 확인.루트가 없는 경우:
None반환루트가 있는 경우:
_get(self, key, current_node)재귀 메서드를 활용하여 적절한 위치의 마디에 저장된 값 반환키가 없으면
None반환.
기능 3: 대괄호 연산자([]) 지원
아래 두 메서드가 필요하다.
__setitem__(self, key, value)예제:
my_zip_tree['Plymouth'] = 55446self.put(key, value)활용
__getitem__(self, key)예제:
z = my_zip_tree['Plymouth']self.get(key)활용
기능 4: in 연산자 지원
아래 메서드가 필요하다.
__contains__(self, key)예제:
if Plymouth in my_zip_tree: print(True)반환값:
bool(self._get(key, self.root))
기능 5: 키-값 항목 제거
지정된 키(key)를 사용하는 마디를 제거한다.
delete(self, key):트리의 사이즈가 1, 즉 루트만 존재하는 경우: 루트의 키를 확인한 후 동일하면 루트 제거
트리의 사이즈가 1보다 큰 경우:
self._get(key)를 이용하여 제거해야 할 마디 확인 후_delete()메서드로 해당 마디 제거.제거 대상 키가 존재하지 않는 경우
KeyError오류 발생.
_delete(self, current_node): 지정된 마디 제거 후 자식 마디 재설정자식이 없는 잎 마디: 그냥 삭제. 부모 마디의 해당 자식 마디에 대한 정보 삭제.
자식을 하나 갖는 마디: 해당 마디 삭제 후 자식 마디를 부모 마디에 연결.
좌우 자식 모두 갖는 경우: 해당 마디를 계승자의 키-값으로 교체한 후 계승자 삭제.
__delitem__(self, key):del연산자 지원.
_delete() 메서드가 작동하는 과정을 예를 들어 설명하면 다음과 같다.
잎 마디 제거:
16을 키로 갖는 마디 제거
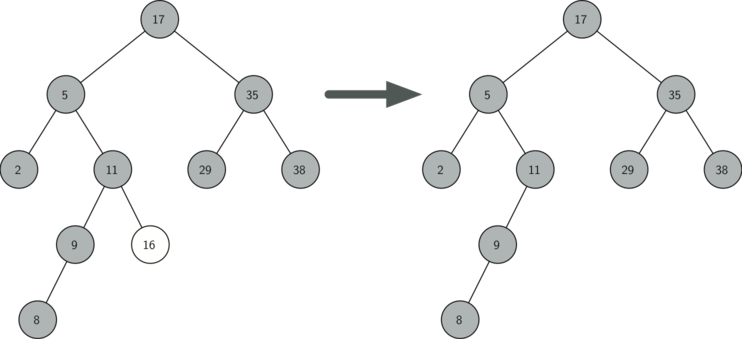
자식을 하나 갖는 마디 제거:
25를 키로 갖는 마디 제거
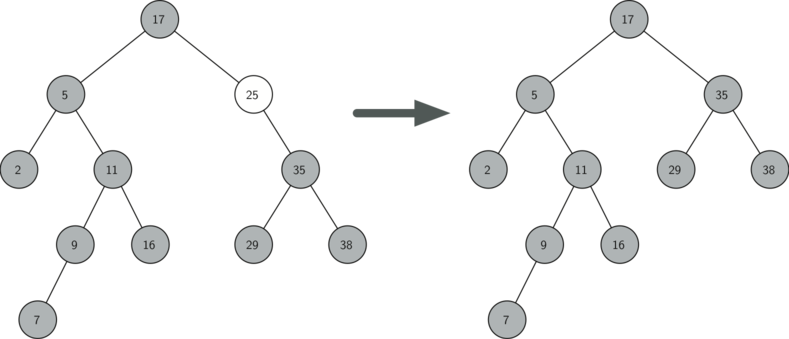
좌우 자식 모두 갖는 마디 제거:
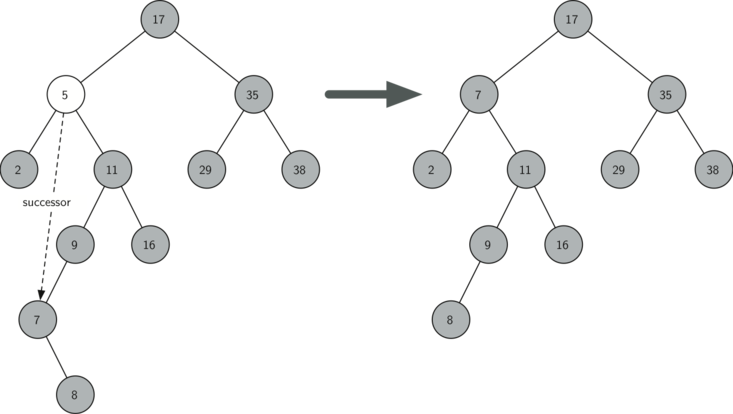
5를 키로 갖는 마디 제거계승자 확인:
find_successor()활용계승자 제거:
splice_out()활용제거된 마디 정보 업데이트
BinarySearchTree 클래스 전체 코드는 다음과 같다.
class BinarySearchTree:
# 생성자: 아무 마디(TreeNode) 없는 이진탐색트리 생성.
# 자식 마디는 TreeNode에서 처리.
def __init__(self):
self.root = None # TreeNode 객체
self.size = 0
# 트리 크기: 마디 개수
def __len__(self):
return self.size
# 이터레이터: 모든 마디의 키를 중위순회방식으로 확인
def __iter__(self):
return self.root.__iter__()
# 항목 추가: 루트 이외의 마디는 TreeNode에서 재귀적으로 처리
def put(self, key, value):
if not self.root:
self.root = TreeNode(key, value)
else:
self._put(key, value, self.root)
self.size = self.size + 1 # size를 1 키우기
# 항목 추가 보조함수: 이진 탐색 트리 특성 유지
def _put(self, key, value, current_node):
if key < current_node.key:
if current_node.left_child:
self._put(key, value, current_node.left_child)
else: # 왼쪽 자식 없는 경우 마디 추가
current_node.left_child = TreeNode(key, value, parent=current_node)
elif key == current_node.key: # value 업데이트
current_node.value = value
self.size = self.size - 1 # 키의 값을 대체하는 경우 size는 그대로 두기 위해
else:
if current_node.right_child:
self._put(key, value, current_node.right_child)
else: # 오른쪽 자식 없는 경우 마디 추가
current_node.right_child = TreeNode(key, value, parent=current_node)
# 사전식 키-값 지정: aBinTree[key] = value
def __setitem__(self, key, value):
self.put(key, value)
# 키의 값 확인
def get(self, key):
if self.root:
result = self._get(key, self.root)
if result:
return result.value
return None
# 키의 값 확인 보조함수: 키가 포함된 마디 반환. 재귀 적용
def _get(self, key, current_node):
if not current_node:
return None
if current_node.key == key:
return current_node
elif key < current_node.key:
return self._get(key, current_node.left_child)
else:
return self._get(key, current_node.right_child)
# 사전식 키의 값 확인: aBinTree[key]
def __getitem__(self, key):
return self.get(key)
# 키 포함 여부 확인(in 연산자): key in aBinTree
def __contains__(self, key):
return bool(self._get(key, self.root))
# 키 삭제: del 연산자에 활용됨
def delete(self, key):
# 하나의 마디만 있는 경우
if self.size == 1 and self.root.key == key:
self.root = None
self.size = self.size - 1
# 여러 마디가 있는 경우
elif self.size > 1:
# 삭제 대상 마디 확인
node_to_remove = self._get(key, self.root)
if node_to_remove:
self._delete(node_to_remove)
self.size = self.size - 1
else:
raise KeyError("키를 찾을 수 없음!")
else:
raise KeyError("키를 찾을 수 없음!")
# 키 삭제 보조함수:
def _delete(self, current_node):
# 잎 마디인 경우
if current_node.is_leaf():
if current_node == current_node.parent.left_child:
current_node.parent.left_child = None
else:
current_node.parent.right_child = None
# 좌우 자식 마디 모두 있는 경우: 계승자를 현재 마디로 옮김.
elif current_node.has_children():
successor = current_node.find_successor()
successor.splice_out()
current_node.key = successor.key
current_node.value = successor.value
# 자식 마디가 하나인 경우
else:
# 왼쪽 자식만 있는 경우
if current_node.left_child:
# 부모의 왼쪽 자식인 경우
if current_node.is_left_child():
current_node.left_child.parent = current_node.parent
current_node.parent.left_child = current_node.left_child
# 부모의 오른쪽 자식인 경우
elif current_node.is_right_child():
current_node.left_child.parent = current_node.parent
current_node.parent.right_child = current_node.left_child
# 루트인 경우
else:
current_node.replace_value(
current_node.left_child.key,
current_node.left_child.value,
current_node.left_child.left_child,
current_node.left_child.right_child,
)
# 오른쪽 자식만 있는 경우
else:
# 부모의 왼쪽 자식인 경우
if current_node.is_left_child():
current_node.right_child.parent = current_node.parent
current_node.parent.left_child = current_node.right_child
# 부모의 왼쪽 자식인 경우
elif current_node.is_right_child():
current_node.right_child.parent = current_node.parent
current_node.parent.right_child = current_node.right_child
# 루트인 경우
else:
current_node.replace_value(
current_node.right_child.key,
current_node.right_child.value,
current_node.right_child.left_child,
current_node.right_child.right_child,
)
# 키-값 쌍 삭제(del 연산자): del aBinTree[key]
def __delitem__(self, key):
self.delete(key)
예제
다음 키-값 쌍으로 이루어진 이진탐색트리를 생성한다.
"a":"art"
"q":"quick"
"b":"brown"
"f":"fox"
"j":"jumps"
"o":"over"
"t":"the"
"l":"lazy"
"d":"dog"
이후 "q"의 값을 "quiet"로 수정한 후에
포함된 항목을 확인한다.
# 9개 항목 추가
my_tree = BinarySearchTree()
my_tree["a"] = "art"
my_tree["q"] = "quick"
my_tree["b"] = "brown"
my_tree["f"] = "fox"
my_tree["j"] = "jumps"
my_tree["o"] = "over"
my_tree["t"] = "the"
my_tree["l"] = "lazy"
my_tree["d"] = "dog"
# 추가된 항목 일부 확인
print("=== 추가된 항목 일부 확인 ===\n")
print("q의 값:", my_tree["q"])
print("l의 값:", my_tree["l"])
# q의 값 업데이트
my_tree["q"] = "quiet"
print("\n=== q의 값 업데이트 ===\n")
print("q의 값:", my_tree["q"])
print("l의 값:", my_tree["l"])
print("\n=== 트리 사이즈 ===\n")
print(f"이진탐색트리에 {len(my_tree)} 개의 항목이 있다.")
# 항목 삭제
my_tree.delete("a")
print(f"키 a를 삭제하면 {len(my_tree)} 개의 항목이 남는다.")
# 남은 항목의 키-값 확인
print("\n=== 트리 항목 ===\n")
print("남은 항목의 키-값은 다음과 같다.\n")
for node in my_tree:
print(f"{node}: {my_tree[node]}")
print()
=== 추가된 항목 일부 확인 ===
q의 값: quick
l의 값: lazy
=== q의 값 업데이트 ===
q의 값: quiet
l의 값: lazy
=== 트리 사이즈 ===
이진탐색트리에 9 개의 항목이 있다.
키 a를 삭제하면 8 개의 항목이 남는다.
=== 트리 항목 ===
남은 항목의 키-값은 다음과 같다.
b: brown
d: dog
f: fox
j: jumps
l: lazy
o: over
q: quiet
t: the
17.2.3. 이진탐색트리 분석#
put()과 get() 메서드, in과 del 연산자 모두
생성된 이진탐색트리의 높이(height)에 의존한다.
트리의 사이즈가 \(n\)일 때
무작위로 생성된 트리의 경우 높이가 대략 \(\log_2{n}\)이다.
그리고 이런 경우 모든 메서드와 연산자의 시간복잡도는 \(O(\log_2{n})\)이다.
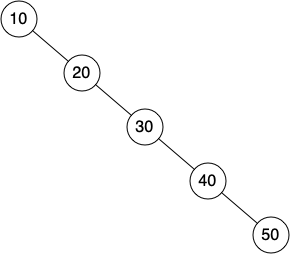
하지만 아래의 경우 또한 발생할 수 있으며 그런 경우 시간복잡도는 최악의 경우
\(O(n)\)이다.
연습문제
리스트
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]의 항목을 차례대로 추가한 이진탐색트리를 그려라.리스트
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]의 항목을 차례대로 추가한 이진탐색트리를 그려라.리스트
[68, 88, 61, 89, 94, 50, 4, 76, 66, 82]의 항목을 차례대로 추가한 이진탐색트리를 그려라.리스트를 무작위로 생성한 후에 해당 리스트의 항목을 차례대로 추가한 이진탐색트리를 그려라.
17.3. 균형 이진탐색트리(AVL 트리)#
앞서 살펴 본 이진탐색트리의 탐색(get()) 및 항목추가(put()) 알고리즘은
최악의 경우 \(O(n)\)의 시간복잡도를 갖는다.
여기서는 이진트리의 좌우 자식 서브트리를 균형이 잡히도록 항목을 추가하여
탐색과 항목추가 모두 \(O(\log n)\)의 시간복잡도를 갖도록 알고리즘을 구현한다.
이와같이 균형 잡힌 이진트리를 AVL 트리(Adelson-Velski 트리)라고 부른다.
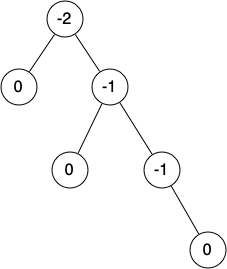
AVL 트리를 구성하려면 모든 마디에 대해 균형인수(balance factor)를 항상 평가해야 한다. 마디의 균형인수는 해당 마디의 왼쪽 서브트리의 높이에서 오른쪽 서브트리의 높이를 뺀 값이다.
마디의 균형인수 = (왼쪽 서브트리의 높이) - (오른쪽 서브트리의 높이)
균형인수 \(>\) 0: 왼쪽으로 치우친 트리
균형인수 \(=\) 0: 균형 잡힌 트리
균형인수 \(<\) 0: 오른쪽으로 치우친 트리
아래 그림은 오른쪽으로 치우친 트리에서 각 마디의 균형인수를 보여준다.
17.3.1. AVL 트리 분석#
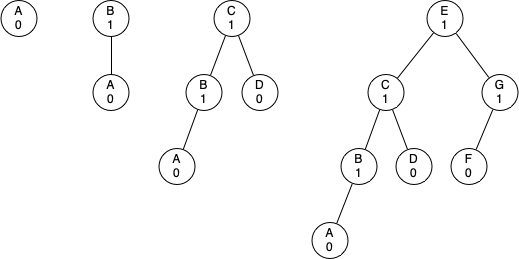
AVL 트리(균형 이진탐색트리)는 모든 마디의 균형인수가 -1, 0, 1 중에 하나이어야 한다. 아래 그림은 높이가 0, 1, 2, 3 인 AVL 트리를 대상으로 했을 때 왼쪽 오른쪽으로 가장 많이 치우친 트리를 보여준다.
위 그림에서 알 수 있듯이 높이가 \(h\)인 AVL 트리의 크기(마디 수) \(N_h\)는 아래 점화식을 만족한다.
\(h\)가 매우 크면 아래 식이 성립한다. \(\Phi\)는 황금비(Golden Ratio)를 나타내며 피보나치 수열과 밀접하게 관련된다. 보다 자세한 설명은 AVL Tree Performance를 참조할 수 있다.
위 식으로부터 다음 결과가 성립하여 AVL 트리의 탐색 알고리즘이 \(O(\log{N})\)임을 증명한다.
17.3.2. AVL 트리 구현#
TreeNode와 BinarySearchTree를 상속한다.
AVLTreeNode 클래스
TreeNode 클래스를 상속하며,
부모 자식 관계뿐만 아니라 균형인수도 저장하도록 한다.
class AVLTreeNode(TreeNode):
def __init__(self, key, value, balance_factor=0, left=None, right=None, parent=None):
super().__init__(key, value, left, right, parent)
self.balance_factor = balance_factor # 균형인수
AVLTree 클래스
BinarySearchTree 클래스를 상속한다.
기능 업데이트 1: _put(self, key, value, current_node) 메서드 재정의(overriding)
새로운 항목은 항상 잎(leaf) 마디로 추가되기에 균형인수는 0이다. 하지만 부모의 균형인수가 변하기에 적절하게 업데이트 해야 한다.
왼쪽 자식으로 추가되는 경우: 부모 마디의 균형인수 1 키울 것
오른쪽 자식으로 추가되는 경우: 부모 마디의 균형인수 1 줄일 것
위 과정을 부모의 부모 등 모든 조상에 대해 재귀적으로 적용해야 한다.
이를 위해 update_balance(self, node) 메서드를 추가한다.
기능 업데이트 2: update_balance(self, node) 메서드 정의
새로운 자식이 추가된 부모의 균형인수를 업데이트 해야 함며, 이를 부모의 부모까지 재귀적으로 적용해야 한다. 단, 업데이트된 부모의 균형인수가 0이라면 더 이상 재귀를 적용할 필요가 없다. 왜냐하면 업데이트된 부모의 균형인수가 0이라면 부모의 부모의 균형인수는 전혀 바뀌지 않기 때문이다.
자식 추가 후 균형인수가 1보가 크거나 -1보다 작아진 경우: 더 이상 AVL 트리가 아니기에 트리 전체를 새롭게 정돈해서 균형을 다시 잡아주어야 한다. 이를 위해
rebalance(self, node)메서드를 추가한다.
기능 업데이트 3: rebalance(self, node) 메서드 정의
추가된 항목으로 인해 균형이 깨진 경우 균형을 다시 잡아주도록 트리의 마디 구조를 바꾼다.
이를 위해 rotate_left(self, rotaiton_root)와 rotate_right(self, rotaiton_root)
메서드를 구현한다.
왼쪽으로 회전
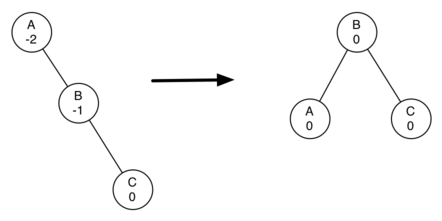
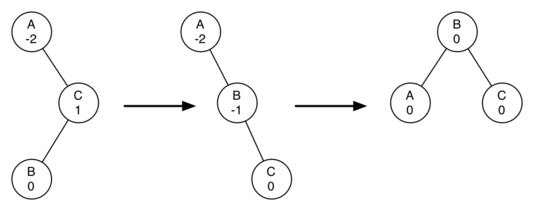
오른쪽으로 회전
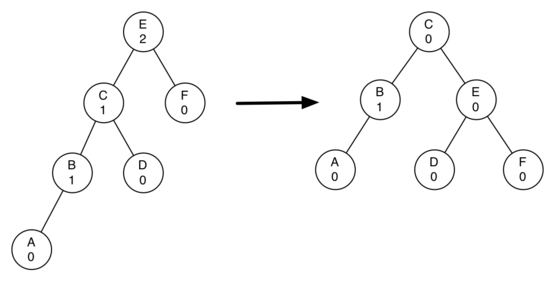
보다 복잡한 경우
주의: 아래 코드는 불완전함.
class AVLTree(BinarySearchTree):
def __init__(self):
super().__init__()
def _put(self, key, value, current_node):
if key < current_node.key:
if current_node.left_child:
self._put(key, value, current_node.left_child)
else:
current_node.left_child = AVLTreeNode(
key, value, 0, parent=current_node
)
self.update_balance(current_node.left_child)
else:
if current_node.right_child:
self._put(key, value, current_node.right_child)
else:
current_node.right_child = AVLTreeNode(
key, value, 0, parent=current_node
)
self.update_balance(current_node.right_child)
def update_balance(self, node):
if node.balance_factor > 1 or node.balance_factor < -1:
self.rebalance(node)
return
if node.parent:
if node.is_left_child():
node.parent.balance_factor += 1
elif node.is_right_child():
node.parent.balance_factor -= 1
# 부모의 균형인수가 0이 아닌경우 재귀 적용
if node.parent.balance_factor != 0:
self.update_balance(node.parent)
def rotate_left(self, rotation_root):
new_root = rotation_root.right_child
rotation_root.right_child = new_root.left_child
if new_root.left_child:
new_root.left_child.parent = rotation_root
new_root.parent = rotation_root.parent
if rotation_root.is_root():
self._root = new_root
else:
if rotation_root.is_left_child():
rotation_root.parent.left_child = new_root
else:
rotation_root.parent.right_child = new_root
new_root.left_child = rotation_root
rotation_root.parent = new_root
rotation_root.balance_factor = (
rotation_root.balance_factor + 1 - min(new_root.balance_factor, 0)
)
new_root.balance_factor = (
new_root.balance_factor + 1 + max(rotation_root.balance_factor, 0)
)
# 수정되어야 함
def rotate_right(self, rotation_root):
new_root = rotation_root.left_child
rotation_root.left_child = new_root.right_child
if new_root.right_child:
new_root.right_child.parent = rotation_root
new_root.parent = rotation_root.parent
if rotation_root.is_root():
self._root = new_root
else:
if rotation_root.is_right_child():
rotation_root.parent.right_child = new_root
else:
rotation_root.parent.left_child = new_root
new_root.right_child = rotation_root
rotation_root.parent = new_root
rotation_root.balance_factor = (
rotation_root.balance_factor + 1 - min(new_root.balance_factor, 0)
)
new_root.balance_factor = (
new_root.balance_factor + 1 + max(rotation_root.balance_factor, 0)
)
def rebalance(self, node):
if node.balance_factor < 0:
if node.right_child.balance_factor > 0:
self.rotate_right(node.right_child)
self.rotate_left(node)
else:
self.rotate_left(node)
elif node.balance_factor > 0:
if node.left_child.balance_factor < 0:
self.rotate_left(node.left_child)
self.rotate_right(node)
else:
self.rotate_right(node)
17.4. 맵 추상자료형 구현 비교#
연산자 |
정렬 리스트 |
해시 테이블 |
이진탐색트리 |
AVL 트리 |
|---|---|---|---|---|
put |
O(n) |
O(1) |
O(n) |
O(log n) |
get |
O(log n) |
O(1) |
O(n) |
O(log n) |
in |
O(log n) |
O(1) |
O(n) |
O(log n) |
del |
O(n) |
O(1) |
O(n) |
O(log n) |
연습문제
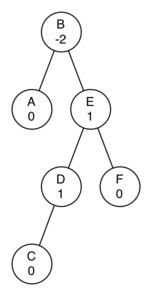
아래 모양의 트리를 균형이진탐색트리로 만들어라.
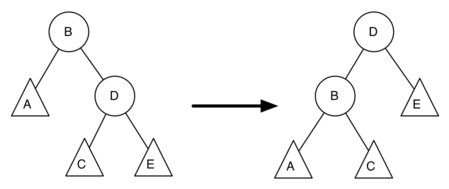
아래 이미지를 이용하여 D 마디의 균형인수를 업데이트 하는 식을 유도하라.
17.5. 프로그래밍 실습 과제#
HashTable클래스에del메서드를 구현하라. 빈자리 찾기, 체이닝 등 충돌 방지에 사용된 기법에 따라 메서드 구현이 달라질 수 있다.해시 테이블의 점유율이 75%가 넘는 순간에 해시 테이블의 크기를 두 배 정도로 늘리는
resize()메서드를 구현하라. 단, 해시 테이블의 길이는 소수가 되도록 함에 주의해야 한다. 참고: Hash table. Dynamic resizing제곱 탐사 기법을 이용하여 리해싱을 구현하라.
HashTable클래스를 체이닝 방식으로 충돌을 지원하도록 하라. 체이닝에 AVL 트리를 활용한다.본문에서
TreeNode의 메섣드로 정의한find_successor()함수는 좌우측 자식을 모두 갖는 경우만 다룬다. 그렇지 않은 일반적인 경우까지 다루도록 하려면 아래와 같이 수정해야 한다.def find_successor(self): successor = None if self.right_child: successor = self.right_child.find_min() else: # 우측 자식 없는 경우 if self.parent: if self.is_left_child(): successor = self.parent else: # 부모의 우측 자식인 경우: 자신을 제외한 부모의 계승자 활용 self.parent.right_child = None successor = self.parent.find_successor() self.parent.right_child = self return successor
일반화된
find_successor()메서드를 이용하여 중위순회(inorder traversal) 방식으로 이진탐색트리를 순회하는 메서드를 구현하라.이진탐색트리 코드를 수정하여 스레드 이진탐색트리 클래스로 만들어라. 그리고 스레드 이진탐색트리의 모든 마디를 순회하는 중위순회 알고리즘을 비재귀(non-recursive) 함수로 구현하라. 스레트 이진트리에 대한 설명은 스레드 이진트리 개념를 참조한다.
AVL 트리에서 항목을 삭제하는 기능을 구현하라. 항목삭제 후에 균형인수 업데이트와 리밸런싱 등을 적절하게 구현해야 한다.