9. 파이썬 모음 자료형 분석#
소스코드
아래 내용을 (구글 코랩) 파이썬 모음 자료형 분석에서 직접 실행할 수 있다.
주요 내용
파이썬 리스트 자료형과 사전 자료형 메서드의 시간복잡도 비교
자료형 클래스 정의 방식에 따른 알고리즘 복잡도 변화
파이썬에서 기본으로 제공하는 두 개의 컨테이너 자료형인 리스트(list)와 사전(dict)
두 자료형과 관련된
알고리즘의 시간복잡도를 Big-O를 이용하여 분석한다.
리스트와 사전은 계속해서 다른 자료구조를 구현할 때 기본적으로 사용되는 요소들이기에
관련된 알고리즘들의 성능을 이해하는 일이 매우 중요하다.
여기서는 성능의 차이가 왜 발생하는가를 설명하진 않으며 단지 어떤 성능 차이가 있는지만을 확인한다. 하지만 나중에 리스트와 사전을 다른 방식으로 직접 구현해 보면서 구현방법에 따른 알고리즘 성능의 차이를 살펴볼 것이다.
9.1. 리스트#
파이썬과 관련된 많은 메서드(함수)들의 성능이 종류에 따라 다르다. 기본적으로 가장 많이 사용되는 메서드일수록 빠르다.
9.1.1. 인덱싱#
예를 들어, 인덱싱과 인덱싱을 활용한 항목 지정이 리스트와 관련되어 가장 많이 사용되는데 이 두 기능을 수행하는 알고리즘은 상수의 시간복잡도인 \(O(1)\)을 갖는다.
9.1.2. 리스트 확장 메서드#
리스트를 확장하기 위해 최소 세 가지 방식을 사용할 수 있다.
append()메서드extend()메서드리스트 연결(concatenation) 연산자(
+)
aList = [1, 2, 3]
aList.append(4)
aList.append(5)
aList
[1, 2, 3, 4, 5]
aList = [1, 2, 3]
aList.extend([4, 5])
aList
[1, 2, 3, 4, 5]
aList = [1, 2, 3]
aList = aList + [4, 5]
aList
[1, 2, 3, 4, 5]
각 알고리즘의 시간복잡도는 다음과 같다.
append(): \(O(1)\)extend(): \(O(1)\)리스트 연결: \(O(k)\): \(k\)는
__add__()를 호출하는 리스트의 길이. 즉,aList + [4, 5]에서aList의 길이.
아래 코드는 길이가 \(n\)인 리스트를 생성하는 5 가지 알고리즘의 실행시간을 계산한다.
앞서 언급한 세 가지 연산자 이외에 비교를 위해 리스트 조건제시법과
range 객체를 이용하는 방법도 함께 살펴본다.
timeit 모듈 활용
알고리즘 실행시간의 공평한 측정을 위해 특정 운영체제나 개발환경에 의존하지 않는
timeit 모듈을 활용한다.
Timer클래스실행되어야 하는 명령문(
stmt)과 실행환경(setup)을 지정하면서 객체 생성예제: 현재 코드가 작성되는 모듈(파일)의
test1()함수를 대상으로 할 때Timer("test1()", "from __main__ import test1")
timeit(number=100000000)메서드지정된 명령문을 (기본값으로 지정된) 1억 번 실행하는 데 걸리는 시간 측정. 단위는 초.
여기서는
number=1000을 사용하여 사용된 연산자들의 실행시간 비교알고리즘의 실행시간은 실행 순간의 컴퓨터 상태에 영향을 받기에 여러 번 실행하여 누적시간을 측정함. 동일한 이유로 평균시간 측정은 별 의미 없음.
먼저, 길이가 1,000인 리스트를 생성해본다.
extend()가append()보다 살짝 느리다. 하지만 이는 리스트를 연결하는 것이 항목 하나를 추가하는 것보다 살짝 더 복잡하기 때문이다.리스트 연결이 다른 두 메서드보다 10배 정도 느리다.
리스트 조건제시법이
append()메서드를 이용하는 것보다 두 배 정도 빠르다.range객체 이용이 가장 빠르다.
n = 1000
# append() 메서드
def test1():
l = []
for i in range(n):
l.append(i)
# extend() 메서드
def test2():
l = []
for i in range(n):
l.extend([i])
# 리스트 연결 연산자
def test3():
l = []
for i in range(n):
l = l + [i]
# 리스트 조건제시법
def test4():
l = [i for i in range(n)]
# range 객체 활용
def test5():
l = list(range(n))
from timeit import Timer
t1 = Timer("test1()", "from __main__ import test1")
print(f"append() 메서드:\t {t1.timeit(number=1000):.2f} 초")
t1_ = Timer("test2()", "from __main__ import test2")
print(f"extend() 메서드:\t {t1_.timeit(number=1000):.2f} 초")
t2 = Timer("test3()", "from __main__ import test3")
print(f"리스트 연결 연산자:\t {t2.timeit(number=1000):.2f} 초")
t3 = Timer("test4()", "from __main__ import test4")
print(f"조건제시법:\t\t {t3.timeit(number=1000):.2f} 초")
t4 = Timer("test5()", "from __main__ import test5")
print(f"range 객체:\t\t {t4.timeit(number=1000):.2f} 초")
append() 메서드: 0.08 초
extend() 메서드: 0.11 초
리스트 연결 연산자: 1.67 초
조건제시법: 0.04 초
range 객체: 0.01 초
이제 길이가 3,000인 리스트를 생성해본다.
리스트의 길이가 세 배가 되어
for반복문이 세 배 돌아간다. 따라서 기본적으로 실행시간이 세 배 더 걸린다.하지만 리스트 연결 연산자(
+)의 경우 아홉 배 걸린다. 이유는 반복문의 횟수 뿐만 아니라 연산자의 실행시간 자체도 세 배 더 걸리기 때문이다.
n = 3000
# append() 메서드
def test1():
l = []
for i in range(n):
l.append(i)
# extend() 메서드
def test2():
l = []
for i in range(n):
l.extend([i])
# 리스트 연결 연산자
def test3():
l = []
for i in range(n):
l = l + [i]
# 리스트 조건제시법
def test4():
l = [i for i in range(n)]
# range 객체 활용
def test5():
l = list(range(n))
from timeit import Timer
t1 = Timer("test1()", "from __main__ import test1")
print(f"append() 메서드:\t {t1.timeit(number=1000):.2f} 초")
t1_ = Timer("test2()", "from __main__ import test2")
print(f"extend() 메서드:\t {t1_.timeit(number=1000):.2f} 초")
t2 = Timer("test3()", "from __main__ import test3")
print(f"리스트 연결 연산자:\t {t2.timeit(number=1000):.2f} 초")
t3 = Timer("test4()", "from __main__ import test4")
print(f"조건제시법:\t\t {t3.timeit(number=1000):.2f} 초")
t4 = Timer("test5()", "from __main__ import test5")
print(f"range 객체:\t\t {t4.timeit(number=1000):.2f} 초")
append() 메서드: 0.22 초
extend() 메서드: 0.33 초
리스트 연결 연산자: 13.71 초
조건제시법: 0.11 초
range 객체: 0.04 초
9.1.3. 리스트 관련 연산자의 평균 시간복잡도#
연산자 |
Big-O |
비고 |
|---|---|---|
인덱싱( |
O(1) |
|
인덱싱 활용 항목 할당 |
O(1) |
|
슬라이싱( |
O(k) |
k는 구간 크기 |
구간 할당 |
O(n+k) |
n은 리스트의 길이, k는 구간 크기 |
연결( |
O(k) |
k는 연결되는 리스트의 길이 |
복제 연결( |
O(nk) |
n은 리스트의 길이, k는 곱해지는 정수 |
|
O(1) |
|
|
O(1) |
|
|
O(n) |
|
|
O(n) |
n은 리스트의 길이 |
|
O(n) |
n은 리스트의 길이 |
|
O(n log n) |
n은 리스트의 길이 |
|
O(n) |
n은 리스트의 길이 |
|
O(n) |
n은 리스트의 길이 |
항목 여부 확인( |
O(n) |
n은 리스트의 길이 |
|
O(n) |
n은 리스트의 길이 |
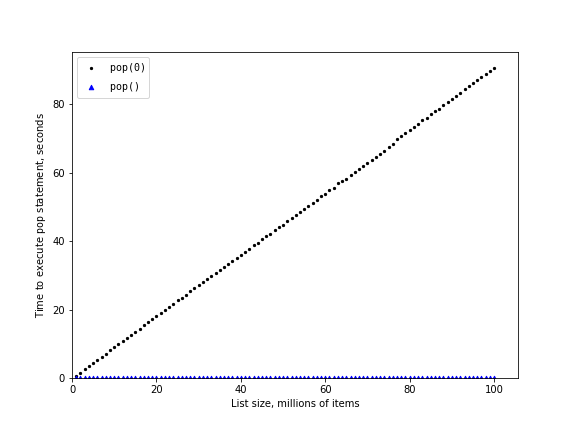
아래 두 코드는 리스트의 길이를 십만에서 천십만으로 백만씩 키우면서
pop()과 pop(0)의 실행시간을 측정한다.
pop()마지막 항목 반환 및 삭제
상수 시간복잡도. 따라서 실행시간 거의 변화 없음.
pop(i)i-번 인덱스 항목 반환 및 삭제.i번 인덱스 이후의 항목 한 칸씩 왼편으로 이동.\(O(n)\). 따라서 리스트의 길이에 선형적 비례해서 증가.
주의사항: 100_100 등 정수에 사용된 밑줄은 읽기 편의성을 위해 사용되며,
임의의 위치에 사용될 수 있다.
즉, 다음이 성립한다.
100_000 = 100000 = 10_00_00
# pop(0) 실행시간
pop_zero = Timer("x.pop(0)", "from __main__ import x")
# pop() 실행시간
pop_end = Timer("x.pop()", "from __main__ import x")
print(f"{'n':>10s}{'pop(0)':>15s}{'pop()':>15s}")
for n in range(100_000, 10_100_001, 1_000_000):
x = list(range(n))
pop_zero_t = pop_zero.timeit(number=1000)
pop_end_t = pop_end.timeit(number=1000)
print(f"{n:>10,}{pop_zero_t:>15.5f}{pop_end_t:>15.5f}")
n pop(0) pop()
100,000 0.02976 0.00007
1,100,000 0.34640 0.00007
2,100,000 0.83097 0.00007
3,100,000 1.70794 0.00007
4,100,000 2.49156 0.00007
5,100,000 3.32505 0.00007
6,100,000 3.99459 0.00007
7,100,000 4.69649 0.00007
8,100,000 5.38836 0.00006
9,100,000 6.17568 0.00007
10,100,000 6.80951 0.00007
두 연산자의 실행시간을 비교하는 그래프는 다음과 같다.
9.2. 사전#
사전 객체는 항목을 위치가 아닌 키(key)로 접근하는데 시간복잡도가 \(O(1)\)이다.
aDict = {j:'1'*j for j in range(10)}
aDict
{0: '',
1: '1',
2: '11',
3: '111',
4: '1111',
5: '11111',
6: '111111',
7: '1111111',
8: '11111111',
9: '111111111'}
aDict[3]
'111'
이와 더불어 사전의 키로 사용되었는지 여부를 확인하는 in 연산자의
시간복잡도 또한 \(O(1)\)이다.
3 in aDict
True
10 in aDict
False
9.2.1. 사전 관련 연산자의 평균 시간복잡도#
사전 객체와 관련된 주요 연산 알고리즘의 (평균) 시간복잡도는 다음과 같다.
연산자 |
Big-O |
|---|---|
항목 확인 |
O(1) |
항목 지정 |
O(1) |
항목 삭제 |
O(1) |
항목 여부 확인( |
O(1) |
복사( |
O(n) |
|
O(n) |
항목 확인과 삭제, 항목 여부 확인 알고리즘의 최악 시간복잡도는 \(O(n)\)이지만 매우 드물게 발생한다. 나중에 사전 객체를 구현하는 다양한 방식을 살펴볼 것이다.
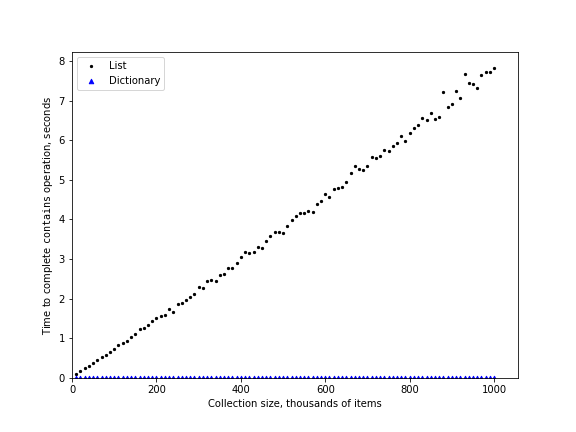
아래 코드는 리스트의 in 연산자와 사전의 in 연산자 사이의 실행시간 차이를 명확하게 보여준다.
길이(
i)가 10,000부터 백일만까지 십만씩 증가할 때 마다 동일한 크기의 리스트와 사전 생성0부터
i-1사이의 임의의 값을 생성한 후에 리스트와 사전에 포함되어 있는지 확인하는 과정을 1000번 반복
코드에 사용된 함수들은 다음과 같다.
random.randrange(i):0부터i-1사이에서 임의의 값 선택
import timeit
import random
print(f"{'n':>9s}{'list':>10s}{'dict':>10s}")
for n in range(10_000, 1_010_001, 100_000):
t = timeit.Timer(f"random.randrange({n}) in x", "from __main__ import random, x")
# 리스트 생성 및 무작위로 생성된 값의 항목 여부 확인
x = list(range(n))
lst_time = t.timeit(number=1000)
# 사전 생성 및 무작위로 생성된 값의 항목 여부 확인
x = {j: True for j in range(n)}
dict_time = t.timeit(number=1000)
print(f"{n:>9,}{lst_time:>10.3f}{dict_time:>10.3f}")
n list dict
10,000 0.067 0.001
110,000 0.698 0.001
210,000 1.356 0.001
310,000 2.009 0.001
410,000 2.699 0.001
510,000 3.466 0.001
610,000 4.071 0.001
710,000 4.884 0.001
810,000 5.462 0.001
910,000 6.057 0.001
1,010,000 6.846 0.001
사전 경우 실행시간의 변화가 거의 없다. 반면에 리스트의 경우 길이에 선형비례하여 실행시간이 증가한다. 이를 그래프로 나타내면 다음과 같다.
9.3. 기타 모음 자료형 시간복잡도#
리스트, 사전, 집합, 덱(deque) 등 파이썬 모음 자료형의 시간복잡도에 대한 최신 정보는 Time Complexity Wiki에서 확인할 수 있다.
참고
deque를 선언할 때 꼬리는 리스트의 시작, 머리는 리스트의 오른편 끝으로 정하며
이에 따라 항목 추가와 삭제 함수를 적절하게 구현하였다.
머리
항목 추가: 리스트의
append(item)활용. 시간복잡도는 \(O(1)\).항목 삭제: 리스트의
pop()활용. 시간복잡도는 \(O(1)\).
꼬리
항목 추가: 리스트의
insert(1, item)활용. 시간복잡도는 \(O(n)\).항목 삭제: 리스트의
pop(0)활용. 시간복잡도는 \(O(n)\).