7. 시간 복잡도#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
알고리즘 복잡도 분석
시간 복잡도와 “Big-O” 표기법
최선, 최악, 평균 시간 복잡도
7.1. 알고리즘 복잡도 분석#
동일한 문제를 해결하는 프로그램 두 개의 성능을 어떻게 비교할 수 있을까? 라는 질문에 대답하려면 먼저 알고리즘과 프로그램의 차이점을 이해해야 한다.
알고리즘
주어진 문제를 해결하기 위한 절차의 단계별 설명서.
주어진 문제의 모든 사례를 해결할 수 있어야 함.
예제: 최대공약수 구하기 문제를 해결하는 알고리즘은 임의의 두 정수의 최대공약수를 계산해야 함.
특정 프로그래밍언어 또는 프로그램 구현 방식과 무관함
주어진 문제를 해결하는 여러 종류의 알고리즘 존재 가능
(컴퓨터) 프로그램
주어진 문제를 해결하기 위해 특정 프로그래밍언어로 작성되어 실행이 가능한 코드
사용하는 프로그래밍언어와 작성자에 따른 여러 종류의 프로그램 존재
프로그램의 핵심은 문제해결을 위한 특정 알고리즘!
동일한 알고리즘을 이용하더라도 다르게 보이는 프로그램 구현 가능
7.1.1. 문제와 알고리즘#
문제 하나, 알고리즘 여러 개
예를 들어, ‘두 정수의 최대공약수 구하기’ 문제를 해결하는 알고리즘은 임의의 두 정수에 대해 동일한 방식으로 최대공약수를 구해야 한다. 즉, 문제를 해결하는 알고리즘은 문제의 특정 사례에 의존하지 않아야 한다.
주어진 문제를 해결하는 여러 개의 알고리즘이 존재할 수 있다. 아래 예제는 최대공약수 구하기 문제를 해결하는 두 개의 알고리즘을 보여준다.
알고리즘 1: 초등학교에서 배운 방식
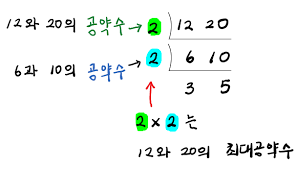
<그림 출처: 아자수학>
알고리즘 2: 유클리드 호제법 방식

<그림 출처: SlidePlayer>
알고리즘 하나, 프로그램 여러 개
동일한 문제를 해결하는 두 개의 프로그램이 다르게 구현되었다고 해서 반드시 다른 알고리즘을 사용한 것이 아닐 수도 있다. 이어지는 예제는 동일한 알고리즘을 사용하는 두 개의 다른 프로그램을 보여준다.
아래 두 개의 프로그램은 모두 양의 정수 n이 주어졌을 때 1부터 n까지를 대상으로 차례대로 더해가는 알고리즘을 구현한다. <프로그램 1>은 매우 명료하게 작성되었다. 반면에 <프로그램 2>는 그렇지 않다. 무엇보다도 변수 이름이 적절하지 않고, 또 굳이 필요하지 않은 변수를 반복과정에서 사용한다.
프로그램 1
def sum_of_n(n):
the_sum = 0
for i in range(1, n + 1):
the_sum = the_sum + i
return the_sum
print(sum_of_n(10))
55
프로그램 2
def foo(tom):
fred = 0
for bill in range(1, tom + 1):
barney = bill
fred = fred + barney
return fred
print(foo(10))
55
두 프로그램 중에서 어떤 프로그램이 보다 좋은 프로그램인가? 가독성, 명료성 등을 기준으로 보면 <프로그램 1>이 보다 좋은 프로그램이다. 가독성, 명료성이 물론 매우 중요한 기준이지만 여기서는 알고리즘 복잡도 분석이라는 다른 기준을 소개한다.
알고리즘 복잡도 분석은 프로그램을 실행할 때 필요한 자원을 가리키는 컴퓨팅 자원computing resources의 양과 활용의 효율성을 측정한다. 이 기준에서 보면 위 두 프로그램은 동등하다. 이유는 두 프로그램 모두 동일한 알고리즘을 사용하기 때문이다.
7.1.2. 컴퓨팅 자원#
컴퓨팅 자원은 보통 다음 두 가지 중에 하나 또는 모두를 가리킨다.
공간량: 알고리즘을 구현한 프로그램이 실행 될 때 요구되는 메모리, 저장 공간 등의 양
실행 시간: 알고리즘을 구현한 프로그램이 특정 결과를 반환할 때까지 걸리는 실행 시간
입력값과 입력 크기
알고리즘을 실행했을 때 요구되는 공간량과 실행 시간은 입력값의 크기에 의존한다.
입력값: 주어진 문제의 사례를 지정하는 값.
예제: 양의 정수 n이 주어지면 1부터 n까지의 합을 계산해야 하는 문제를 해결하는 알고리즘의 입력값은 양의 정수 n이다.
입력 크기: 입력값의 크기.
크기 계산 기준에 따라 지정됨.
예제 1: 1부터 n까지의 합을 계산하는 알고리즘의 입력값인 정수 n의 크기는 n으로 정한다.
예제 2:리스트를 입력값으로 사용하는 알고리즘의 입력 크기는 리스트의 길이로 정한다.
여기서는 알고리즘 실행에 필요한 공간량에 대해서는 거의 다루지 않고 대신 실행 시간에 대한 이야기에 집중한다.
입력 크기에 따라 실행 시간이 선형적으로 달라지는 알고리즘
아래 sum_of_n_2() 함수는 양의 정수 n이 주어졌을 때
1부터 n까지 정수의 합을 계산하기 위해 필요한 실행 시간을 계산한다.
import time
def sum_of_n_time(n):
start = time.time() # 실행 시작
sum_of_n(n) # 1부터 n까지의 합 계산
end = time.time() # 실행 종료
return end - start # 1부터 n까지의 합 계산에 필요한 시간
알고리즘의 실행 시간은 입력값에 의존한다. 아래 코드는 1부터 1만까지의 합을 계산하는 데 필요한 평균 시간을 측정한다. 평균을 계산하기 위해 1부터 1만까지의 합을 10번 실행한다.
n = 10000
m = 10
time_sum = 0
for _ in range(m):
time_sum += sum_of_n_time(n)
print(f"1부터 {n}까지 더하는데 평균적으로 {time_sum/m:7.5f}초 걸림.")
1부터 10000까지 더하는데 평균적으로 0.00023초 걸림.
10만까지의 합은 만까지의 합보다 대략 10배 정도 더 걸린다.
n = 100000
m = 10
time_sum = 0
for _ in range(m):
time_sum += sum_of_n_time(n)
print(f"1부터 {n}까지 더하는데 평균적으로 {time_sum/m:7.5f}초 걸림.")
1부터 100000까지 더하는데 평균적으로 0.00232초 걸림.
100만까지의 합은 만까지의 합보다 100배 정도 더 걸린다.
n = 1000000
m = 10
time_sum = 0
for i in range(m):
time_sum += sum_of_n_time(n)
print(f"1부터 {n}까지 더하는데 평균적으로 {time_sum/m:7.5f}초 걸림.")
1부터 1000000까지 더하는데 평균적으로 0.02509초 걸림.
따라서 1천만까지의 합은 평균적으로 만까지의 합보다 1000배 정도 오래 걸릴 것으로 추정할 수 있다.
n = 10000000
m = 10
time_sum = 0
for i in range(m):
time_sum += sum_of_n_time(n)
print(f"1부터 {n}까지 더하는데 평균적으로 {time_sum/m:7.5f}초 걸림.")
1부터 10000000까지 더하는데 평균적으로 0.24466초 걸림.
sum_of_n() 함수가 실행될 때 사용된 반복 알고리즘의
반복 횟수에 따라 실행 시간이 비례해서 늘어나는 것으로 보인다.
즉, 함수의 입력값의 크기에 실행 시간이 선형적으로 의존한다.
입력 크기에 상관 없이 실행 시간이 일정한 알고리즘
모든 알고리즘이 입력값, 즉 주어진 문제의 사례에 의존해서 실행 시간이 달라지는 것은 아니다. 아래 예제는 1부터 n까지의 합을 입력값 n에 상관없이 거의 동일한 시간 내에 계산하는 알고리즘을 사용한다.
예제: 1 부터 n 까지 합 구하기 (다른 알고리즘)
sum_of_n_2() 함수는 1부터 n까지의 합을 계산하기 위해 아래 식을 이용한다.
def sum_of_n_2(n):
sum = (n * (n + 1)) / 2
return sum
def sum_of_n_2_time(n):
start = time.time() # 실행 시작
sum_of_n_2(n)
end = time.time() # 실행 종료
return end - start
그런데 이 함수의 실행 시간은 입력값에 의존하지 않는 것으로 보인다.
m = 10
for n in [10000, 100000, 1000000, 10000000]:
time_sum = 0
for _ in range(m):
time_sum += sum_of_n_2_time(n)
print(f"1부터 {n:8d}까지 더하는데 평균적으로 {time_sum/m:.16f}초 걸림.")
1부터 10000까지 더하는데 평균적으로 0.0000003337860107초 걸림.
1부터 100000까지 더하는데 평균적으로 0.0000002622604370초 걸림.
1부터 1000000까지 더하는데 평균적으로 0.0000000953674316초 걸림.
1부터 10000000까지 더하는데 평균적으로 0.0000000476837158초 걸림.
7.2. 시간 복잡도#
실행 시간이 sum_of_n_2() 함수의 실행 시간이 입력값 n에 의존하지 않을 뿐더러 sum_of_n() 함수보다 훨씬 빠르다.
그런데 프로그램 실행 시간은 사용되는 컴퓨터, 실행 환경, 컴파일러, 프로그래밍언어 등등에 의존하기 때문에 앞서
확인된 실행 시간을 절대적인 기준으로 삼을 수는 없다.
따라서 이런 요소들에 의존하지 않으면서 객관적으로 프로그램의 실행 시간을 평가하는 기준이 요구되는데
여기서는 시간 복잡도를 사용한다.
주어진 알고리즘의 시간 복잡도를 얘기하려면 먼저 계산 단위 개념을 이해해야 한다.
계산 단위
사용하는 컴퓨터 또는 프로그램에 의존하지 않으면서 알고리즘의 효율성을 실행 시간을 이용하여 측정하기 위해 특정 연산자 또는 특정 명령문 등의 실행 횟수를 이용할 수 있다. 이때 사용되는 연산자 또는 특정 명령문을 계산 단위basic unit of computation라 부른다. 무엇을 계산 단위로 지정할 것인가는 알고리즘에 따라 적절하게 정해야 한다.
예를 들어 앞서 살펴 본 sum_of_n() 함수의 경우에는 ‘변수 할당 명령문’을 계산 단위로 사용할 수 있는데
그러면 sum_of_n(n) 이 호출되어 실행되는 동안 총 (n+1) 번 변수 할당 명령문이 실행된다.
def sum_of_n(n):
the_sum = 0 # 한 번 할당
for i in range(1, n + 1):
the_sum = the_sum + i # n 번 할당
return the_sum
입력 크기와 시간 복잡도
sum_of_n() 함수의 입력값의 크기가 \(n\)일 때,
즉 sum_of_n(n)이 실행될 때 총 \((n + 1)\) 번 변수 할당 명령문이 실행되며,
이를 아래와 같이 나타낸다.
\(T()\) 함수는 크기가 \(n\)인 입력값에 대해 \(T(n)\)의 시간이 지나면 해당 알고리즘이 반환값을 계산하고 종료한다 라는 의미의 일정 시간 복잡도를 계산하는 함수이다.
따라서 sum_of_n() 함수의 일정 시간 복잡도가 \(T(n) = n + 1\) 이라는 것은 다음을 의미한다.
알고리즘과 시간 복잡도
1부터 n까지의 합을 반복문을 이용해서 구하는 문제에서 입력값의 크기가 클 수록 실행 시간도 그에 비례해서 오래 걸린다. 즉, 실행 시간이 입력 크기에 의존한다. 반면에 아래에 사용된 알고리즘은 변수 할당을 딱 한 번 사용한다.
def sum_of_n_2(n):
sum = (n * (n + 1)) / 2
return sum
실제로 위 프로그램의 실행 시간과 입력 크기 사이의 관계는 \(T(n) = 1\)로 표현된다.
예제: 일정 시간 복잡도 계산
아래 별 의미 없는 함수 fun()의 일정 시간 복잡도를 계산해보자.
계산 단위는 변수 할당으로 한다.
def fun(n):
a = 5
b = 6
for i in range(n):
for j in range(n):
x = i * i
y = j * j
z = i * j
for k in range(n):
w = a * k + 45
v = b * b
코드에 주석으로 적혀 있는대로 fun()함수가 입력값 n과 함께
호출되었을 때 실행하는 변수 할당의 총 횟수 \(T(n)\)은 다음과 같다.
7.2.1. Big-O 표기법 직관적 소개#
입력 크기에 의존하는 실행 시간 함수 \(T(n)\)의 정의에 사용되는 수식을 분석할 때 수식에 사용되는 모든 항을 다룰 필요가 없다. 예를 들어 \(T(n) = n + 1\) 에서 \(1\)은 별로 중요하지 않다. 실제로 \(n\)이 커질 수록 \((n + 1)\)에서 \(1\)의 역할은 거의 사라진다. 즉, 변수 할당을 한 번 더 하는 것은 실행 시간에 별 영향을 주지 않기에 핵심은 \(n\)에 집중된다. 위 설명이 Big-O 표기법의 핵심이며 \(T(n)\)과 연관지어 다음과 같이 작성한다.
실행 시간 함수 \(T(n)\)을 Big-O 표기법으로 표현하는 일반적인 방법은 다음과 같다.
입력 크기 \(n\)이 매우 커질 때 가장 중요한 역할을 수행하는 항 지정
그런 항이 \(f(n)\) 이라 할 때 아래처럼 표기:
예제: \(T(n)=3n^{2} + 2n + 2\)
\(3n^{2} + 2n + 2\)에서 \(n\)이 커질 때 \(3 n^{2}\)이 주도적 역할을 수행한다. 그런데 \(3n^{2}\)과 \(n^{2}\) 관계에서처럼 상수 배수는 무시된다. 이유는 동일한 알고리즘을 돌렸을 때 컴퓨터 사양에 따라 발생하는 몇 배 정도의 실행 시간의 차이는 알고리즘 복잡도 분석의 핵심으로 간주되지 않기 때문이다.
결론적으로 다음이 성립한다.
예제: \(T(n)=\frac{1}{1000}n \log n + 3n + 205\)
\(\frac{1}{1000}n \log n + 3n + 205\)에서 \(n\)이 커질 때 가장 중요한 역할은 \(\frac{1}{1000}n \log n\)이 수행한다. 여기서 상수 배수를 무시하면 \(n \log n\) 이 실행 시간 복잡도를 잘 대변하며, 따라서 다음이 성립한다.
예제: \(T(n)=c\)의 시간 복잡도 (\(c\)는 상수)
sum_of_n_2() 함수의 경우처럼 일정 시간 복잡도가 입력 크기에 전혀 의존하지 않을 때
시간 복잡도는 1이라고 말한다.
이유는 임의의 상수 \(c\)는 \(1\)의 상수 배수에 해당하고 앞서 설명하였듯이 상수 배수는
시간 복잡도를 따질 때 무시되기 때문이다.
따라서 다음이 성립한다.
7.2.2. 주요 시간 복잡도 함수#
알고리즘 복잡도 분석에 가장 많이 사용되는 주요 시간 복잡도 함수는 다음과 같다.
시간 복잡도 |
의미 |
|---|---|
\(1\) |
상수 시간 |
\(\log n\) |
로그 시간 |
\(n\) |
선형 시간 |
\(n\log n\) |
로그선형 시간 |
\(n^{2}\) |
2차 시간 |
\(2^{n}\) |
지수 시간 |
\(n!\) |
계승 시간 |
아래 그림은 주요 Big-O 함수들의 그래프를 담고 있다. \(n\)이 커질 때 함수값 변화의 차이를 잘 보여준다.
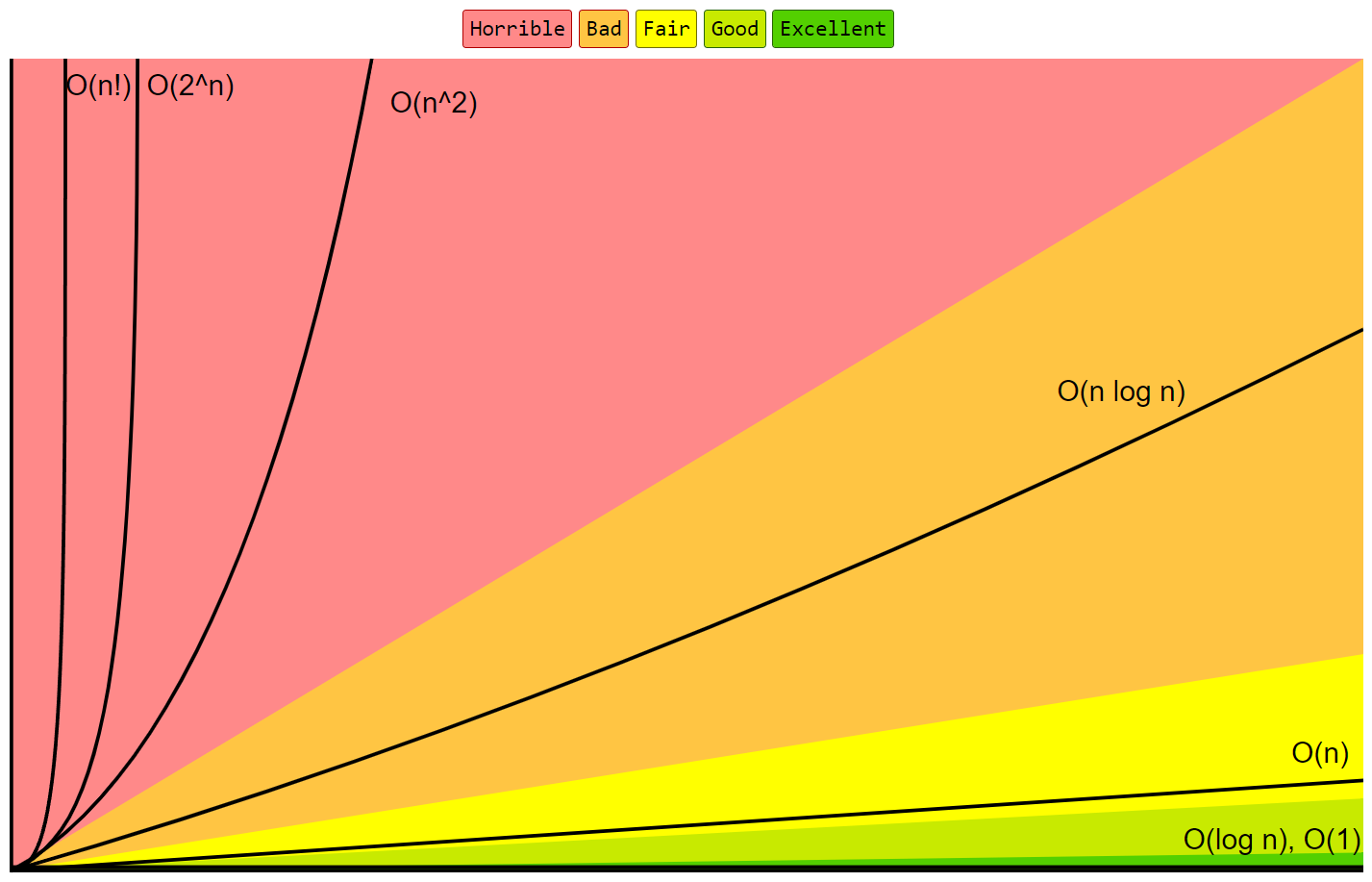
<그림 출처: Big-O Cheat Sheet>
7.2.3. 시간 복잡도와 실행 시간#
가정: 계산 단위 실행 시간 = 1 ns(나노 초, 10억 분의 1 초)
\(\mu\)s(마이크로 초): 100만 분의 1초
ms(밀리 초): 천 분의 1초
\(n\): 입력 크기
\(n\) |
\(\lg n\) |
\(n\) |
\(n\, \lg n\) |
\(n^2\) |
\(2^n\) |
|---|---|---|---|---|---|
\(10\) |
\(0.003\) \(\mu\)s |
\(0.01\) \(\mu\)s |
\(0.033\) \(\mu\)s |
\(0.10\) \(\mu\)s |
\(1\) \(\mu\)s |
\(20\) |
\(0.004\) \(\mu\)s |
\(0.02\) \(\mu\)s |
\(0.086\) \(\mu\)s |
\(0.40\) \(\mu\)s |
\(1\) ms |
\(30\) |
\(0.005\) \(\mu\)s |
\(0.03\) \(\mu\)s |
\(0.147\) \(\mu\)s |
\(0.90\) \(\mu\)s |
\(1\) 초 |
\(40\) |
\(0.005\) \(\mu\)s |
\(0.04\) \(\mu\)s |
\(0.213\) \(\mu\)s |
\(1.60\) \(\mu\)s |
\(18.3\) 분 |
\(50\) |
\(0.006\) \(\mu\)s |
\(0.05\) \(\mu\)s |
\(0.282\) \(\mu\)s |
\(2.50\) \(\mu\)s |
\(13\) 일 |
\(10^2\) |
\(0.007\) \(\mu\)s |
\(0.10\) \(\mu\)s |
\(0.664\) \(\mu\)s |
\(10.00\) \(\mu\)s |
\(4 \times 10^{13}\) 년 |
\(10^3\) |
\(0.010\) \(\mu\)s |
\(1.00\) \(\mu\)s |
\(9.966\) \(\mu\)s |
\(1.00\) ms |
|
\(10^4\) |
\(0.013\) \(\mu\)s |
\(10.00\) \(\mu\)s |
\(130.000\) \(\mu\)s |
\(100.00\) ms |
|
\(10^5\) |
\(0.017\) \(\mu\)s |
\(0.10\) ms |
\(1.670\) ms |
\(10.00\) 초 |
|
\(10^6\) |
\(0.020\) \(\mu\)s |
\(1.00\) ms |
\(19.930\) ms |
\(16.70\) 초 |
|
\(10^7\) |
\(0.023\) \(\mu\)s |
\(0.01\) 초 |
\(0.230\) 초 |
\(1.16\) 일 |
|
\(10^8\) |
\(0.027\) \(\mu\)s |
\(0.10\) 초 |
\(2.660\) 초 |
\(115.70\) 일 |
|
\(10^9\) |
\(0.030\) \(\mu\)s |
\(1.00\) 초 |
\(29.900\) 초 |
\(31.70\) 년 |
<테이블 출처: 알고리즘 기초, Neopolitan 저, 홍릉>
7.3. 최선, 최악, 평균 시간 복잡도#
알고리즘의 시간 복잡도가 입력 크기뿐만 아니라 입력값 자체에 의존하기도 한다. 이런 경우엔 일정 시간 복잡도 \(T(n)\) 계산이 불가능하며, 대신에 최선, 최악, 평균 시간 복잡도를 계산한다.
순차 탐색과 어구전철 확인 두 예제를 이용하여 최선, 최악, 평균 시간 복잡도를 설명한다.
7.3.1. 순차 탐색#
주어진 리스트에서 특정 값의 포함 여부를 판단할 때 인덱스를 따라가면서 해당 항목을 확인할 수 있다. 이를 순차 탐색이라 하며 다음 그림처럼 작동한다.
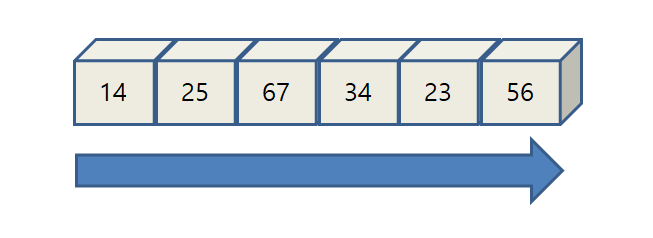
<그림 출처: 탐색 알고리즘 - 순차 탐색(Sequential Search)>
아래 seqSearch() 함수는 순차 탐색 알고리즘을 구현한다.
sequence: 주어진 리스트value: 탐색 대상
def seqSearch(sequence, value):
for item in sequence:
if item == value: # 계산 단위
return True
return found
아래와 같이 활용된다.
seq = [54, 26, 93, 17, 77, 31, 44, 55, 20, 65]
seq_sorted = [17, 20, 26, 31, 44, 54, 55, 65, 77, 93]
print(seqSearch(seq, 93))
print(seqSearch(seq_sorted, 93))
True
True
seqSearch() 함수의 일정 시간 복잡도 \(T(n)\)을 계산해 보자.
입력 크기 \(n\): 첫째 인자에 포함된 항목 개수
계산 단위: 비교 연산
==명령문
그런데 seqSearch(seq, 93)을 실행하면 세 번 비교가 발생한다.
반면에 seqSearch(seq_sorted, 93)을 실행하면 열 번 비교한다.
즉, 동일한 길이의 리스트를 사용하더라도 리스트에 포함된 항목들의 순서에 따라 실행 시간이 달라진다.
이런 경우엔 일정 시간 복잡도 \(T(n)\)을 계산할 수 없으며, 대신 입력 크기 \(n\)에 의존하는 시간 복잡도의 최솟값, 최댓값, 평균값 함수를 구해야 한다. 이를 각각 해당 알고리즘의 최선(best), 최악(worst), 평균(average) 시간 복잡도라 한다.
seqSearch() 함수의 최선, 최악, 평균 시간 복잡도를 리스트의 길이에 대한 함수로
계산하면 다음과 같다.
최선 |
최악 |
평균 |
|
|---|---|---|---|
항목인 경우 |
1 |
n |
n/2 |
항목이 아닌 경우 |
n |
n |
n |
주어진 알고리즘의 최대, 최소, 평균 시간 복잡도를 각각 \(B(n)\), \(W(n)\), \(A(n)\)이라 했을 때 다음이 성립한다.
일정 시간 복잡도 \(T(n)\)이 존재할 때:
\[T(n) = B(n) = A(n) = W(n)\]일정 시간 복잡도 \(T(n)\)이 존재하지 않을 때:
\[B(n) \le A(n) \le W(n)\]
7.3.2. 어구전철#
어구전철은 단어를 구성하는 문자의 순서를 바꾸어 새로운 단어를 생성하는 것을 나타내며, 영어로 애너그램anagram이라 한다. 예를 들어 “국왕” 과 “왕국”, “다들 힘내”와 “힘내 다들” 또는 “내 힘들다”, “heart”와 “earth”, “python”과 “typhon” 등이 어구전철 관계를 갖는다. 여기서는 두 영어 단어의 어구전철 여부를 확인하는 함수를 다양한 알고리즘을 이용하여 구현한다.
알고리즘 1: 일일이 확인하기
첫째 방법은 하나의 문자열에 사용된 모든 문자를 대상으로
해당 문자가 다른 문자열에 나타나는가를 일일이 확인하는 것이다.
그리고 확인된 문자는 None으로 대체해서 더 이상 확인 대상이 되지 않도록 한다.
먼저
s1과s2두 문자열의 길이 비교. 다르면False반환둘째 문자열
s2를 리스트로 변환. 파이썬의 문자열은 수정불가능이기 때문에 리스트를 대신 사용.첫째 문자열
s1에 포함된 문자를 대상으로 둘째 문자열의 리스트s2에 포함되어 있는지 탐색 시작리스트
s2에서 찾았으면 해당 문자를None으로 대체 후 바로 문자열s1의 다음 문자를 대상으로 탐색 반복아니면 해당 문자까지만 탐색하고 실행 종료
def anagram_solution_1(s1, s2):
if len(s1) != len(s2): # 동일 길이 여부 확인
return False
n = len(s1) # 문자열 길이 활용
s2_list = list(s2) # 둘째 문자열을 리스트로 변환
for idx1 in range(n): # 첫째 문자열의 모든 문자 대상 반복
found = False # s2에서 동일 문자가 확인되었는지 여부
for idx2 in range(n): # 둘째 문자열의 모든 문자 대상 비교
if s1[idx1] == s2_list[idx2]: # 계산 단위: 항목 비교
found = True
s2_list[idx2] = None
break
if not found:
return False
return True
print(anagram_solution_1("apple", "pleap")) # True
print(anagram_solution_1("abcd", "dcba")) # True
print(anagram_solution_1("abcd", "dcda")) # False
True
True
False
위 알고리즘 복잡도 분석에 사용되는 계산 단위로
첫째 문자열 s1의 항목과 둘째 문자열로부터 변환된
리스트 s2_list의 항목 사이의 비교연산(==)을 사용한다.
두 문자열의 길이가 \(n\)이라 하자.
다음 세 가지 경우를 고려해야 한다.
두 문자열이 서로 어구전철일 때
문자열
s1의 각 문자에 대해 리스트s2_list의 각 항목을 비교해야 한다. 그리고 문자의 위치에 따라 1번에서 최대 \(n\)번까지 비교연산이 실행되며, 모든 경우가 발생한다.즉, 다음이 성립한다.
두 문자열의 길이가 같지만 서로 어구전철 관계가 아닐 때
최선: 문자열
s1의 첫째 문자가 리스트s2_list에 포함되지 않은 경우에 어구전철이 아니라고 판단된다. 따라서 다음이 성립한다.\[\begin{split} B(n) = n\\ \end{split}\]최악: 첫째 문자열
s1의 마지막 문자가 리스트s2_list에 포함되지 않은 경우에 어구전철이 아니라고 판단된다. 예를 들어 “python”과 “mpytho”의 경우처럼 처음 \((n-1)\)개의 문자를 확인하는데 걸리는 최악 시간은\[ 2 + 3 + \cdots + n \]이며, 마지막 문자(“m”)가
s2_list에 없는 것을 확인하는 데에 \(n\) 번의 비교가 요구된다. 따라서 다음이 성립한다.\[\begin{split} \begin{align*} W(n) &= 2 + 3 + \cdots + n + n\\ &= \frac {n(n+1)}{2} - 1 + n \\ & = \frac {1}{2}n^{2} + \frac {3}{2}n - 1\\ & \in O(n^{2}) \end{align*} \end{split}\]
두 문자열의 길이가 다를 때: 바로 어구전철이 아니다 라고 판단된다.
\[ B(n) = 1 \]
알고리즘 2: 정렬 후 비교
서로 어구전철인 두 문자열을 동일한 문자들을 포함해야 한다.
따라서 알파벳 순서대로 문자들을 정렬하면 완전히 동일한 두 문자열을 얻게 된다.
아래 알고리즘은 먼저 두 문자열을 리스트로 형변환한 후에
리스트의 sort() 메서드를 이용하여 두 문자열을 정렬한다.
그런 다음에 각 인덱스에 대해 정렬된 두 문자열이 동일한 문자를 갖는지
확인한다. 중간에 서로 다른 문자를 확인하면 바로 실행을 멈춘다.
def anagram_solution_2(s1, s2):
# 리스트로 형변환
a_list_1 = list(s1)
a_list_2 = list(s2)
# 리스트 정렬
a_list_1.sort()
a_list_2.sort()
# 동일 위치에 대해 일대일 비교. 다르면 바로 종료
pos = 0
matches = True
while pos < len(s1) and matches:
if a_list_1[pos] == a_list_2[pos]: # 계산 단위: 항목 비교
pos = pos + 1
else:
return False
return matches
print(anagram_solution_2("apple", "pleap")) # True
print(anagram_solution_2("abcd", "dcba")) # True
print(anagram_solution_2("abcd", "dcda")) # False
True
True
False
두 문자열이 서로 어구전철인 경우 비교 연산자가 \(n\) 번 발생하는 것으로 보인다.
하지만 sort() 함수를 이용한 정렬 과정 중에도 많은 비교가 발생한다.
실제로 대부분의 정렬 알고리즘은 \(O(n^2)\) 또는 \(O(n\log n)\)의
시간 복잡도를 갖는다.
따라서 위 알고리즘이 시간 복잡도는 사용되는 정렬 알고리즘의 시간 복잡도와 동일하다.
알고리즘 3: 빈도 활용
어구전철 관계인 두 문자열은 각 문자를 동일한 수만큼 포함한다. 따라서 모든 알파벳에 대해 각 문자열에 포함된 빈도를 측정한 후에 측정된 빈도가 모든 문자에 대해 일치하는지를 확인하면 된다.
아래 anagram_solution_3() 함수는 두 단어에 포함된 알파벳의 빈도수를 비교하여
어구전철 관계를 판정한다.
alphabets = "abcdefghijklmnopqrstuvwxys"
def anagram_solution_3(s1, s2):
alpha_dict1 = dict()
alpha_dict2 = dict()
for s in alphabets:
alpha_dict1[s] = 0
alpha_dict2[s] = 0
for s in s1.lower():
alpha_dict1[s] += 1 # 계산 단위: 카운트
for s in s2.lower():
alpha_dict2[s] += 1 # 계산 단위: 카운트
for alpha in alphabets:
if alpha_dict1[alpha] == alpha_dict2[alpha]: # 계산 단위: 값 비교
continue
else:
return False
return True
print(anagram_solution_3("apple", "pleap")) # True
print(anagram_solution_3("abcd", "dcba")) # True
print(anagram_solution_3("abcd", "dcda")) # False
True
True
False
길이가 \(n\)인 문자열에 포함된 문자들의 빈도를 확인하는 시간 복잡도는 카운트를 기준으로 했을 때 \(n\)이다. 그리고 두 개의 카운트 리스트를 비교하는 데에 최소 1번, 최대 26번의 항목 비교가 발생한다. 따라서 위 어구전철인 두 개의 문자열을 확인하는 알고리즘의 최선/최악 시간 복잡도는 다음과 같다.
알고리즘 2 vs. 알고리즘 3
입력 문자열의 길이를 2백60만, 2천600만, 2억6천만으로 늘릴 때 알고리즘 2와 알고리즘 3의 실행시간 차이를 직접 비교한다. 평가에 사용된 PC의 성능은 다음과 같다.
프로세서: 11th Gen Intel(R) Core(TM) i9-11950H @ 2.60GHz 2.61 GHz
RAM: 32GB
입력값은 영어 알파벳 26개로 구성된 문자열을 10만번, 100만번, 천만번 이어붙이는 방식으로 생성한다.
from time import time
s1 = alphabets
len(s1)
26
알고리즘 2: 입력 크기 2백60만
start = time()
k = 100_000
anagram_solution_2(s1*k, s1*k)
print(time()-start)
0.35188865661621094
알고리즘 2: 입력 크기 2천600만
start = time()
k = 1_000_000
anagram_solution_2(s1*k, s1*k)
print(time()-start)
3.6589527130126953
알고리즘 2: 입력 크기 2억6천만
start = time()
k = 10_000_000
anagram_solution_2(s1*k, s1*k)
print(time()-start)
39.13177156448364
알고리즘 3: 입력 크기 2백60만
start = time()
k = 100_000
anagram_solution_3(s1*k, s1*k)
print(time()-start)
0.19489121437072754
알고리즘 3: 입력 크기 2천600만
start = time()
k = 1_000_000
anagram_solution_3(s1*k, s1*k)
print(time()-start)
2.007293939590454
알고리즘 3: 입력 크기 2억6천만
start = time()
k = 10_000_000
anagram_solution_3(s1*k, s1*k)
print(time()-start)
19.824604749679565
실행 시간 자체는 별로 중요하지 않다. 이유는 실험에 사용된 컴퓨터 환경에 따라 실행 시간이 조금씩 다를 수 있다. 대신 아래 내용이 보다 중요하다.
알고리즘 2: 입력 크기가 10배 커질 때마다 실행시간이 10배보다 조금 더 오래 걸린다.
알고리즘 3: 입력 크기가 10배 커질 때마다 실행시간이 10배 정도 오래 걸린다.
알고리즘 2의 경우 정렬 알고리즘의 시간 복잡도가 \(O(n \ln n)\)일 것이기에 입력 크기 \(n\)이 10 배 커지면 실행시간은 10배보다 조금 더 걸린다.
7.4. 공간 복잡도 문제#
알고리즘 anagram_solution_3()의 시간 복잡도는 이전 세 알고리즘에 비해 훨씬 좋다.
하지만 그 대신에 빈도 리스트를 새로 생성하기 위해 보다 많은 메모리를 사용한다.
여기서는 겨우 길이가 26인 리스트 두 개를 생성하기에 별 문제가 아니지만
경우에 따라 길이가 수 백만, 수 천만, 수 억인 리스트를 생성해야 한다면 심각한 문제가 될 수도 있다.
하지만 이전 알고리즘들도 모두 추가 메모리를 사용한다.
anagram_solution_1(): 문자열s2를 리스트로 변환한 값anagram_solution_2(): 두 문자열을 리스트로 형변환한 후 정렬. 그리고 정렬 과정에서 추가 메모리 사용 가능.
따라서 어떤 알고리즘을 사용하는 게 좋을지 환경과 상황에 따라 결정해야 한다.