12. 탐색과 분할 정복#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
순차 탐색
이진 탐색
분할 정복
분할 정복과 재귀
12.1. 탐색#
파이썬 리스트의 경우 in 연산자가 항목 포함여부를 O(n)의
시간복잡도로 확인해준다.
>>> 15 in [3, 5, 2, 4, 1]
False
>>> 3 in [3, 5, 2, 4, 1]
True
이처럼 모음 객체에 특정 값이 포함되었는지 여부와 포함된 위치를 확인하는 과정이 탐색search이다. 여기서는 두 종류의 탐색 알고리즘을 살펴본다.
12.1.1. 순차 탐색#
리스트, 튜플, 넘파이 어레이 등은 위치에 따라 적절한 인덱스를 갖는다. 인덱스는 기본적으로 0, 1, 2, … 등의 자연수를 갖기 때문에 인덱스 순서대로 항목을 확인할 수 있다. 이런 탐색 기법이 순차 탐색sequential search이다.
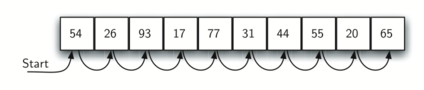
다음 sequential_search() 함수는 하나의 리스트와 하나의 값을 받았을 때
순차탐색을 통해 주어진 값의 포함여부를 판정한다.
for 반복문을 이용하여 순차탐색 진행. 일치되는 항목을 찾는 경우 바로 종료
for 반복문 다 돌았어도 반환값이 없는 경우 찾는 값이 없다고 판정.
def sequential_search(a_list, value):
# 순차 탐색
for item in a_list:
if item == value: # 찾은 경우 바로 True 반환
return True
# for 문을 다 돌아도 찾지 못한 경우 False 반환
return False
test_list = [54, 26, 93, 17, 77, 31, 44, 55, 20, 65]
print(sequential_search(test_list, 83))
print(sequential_search(test_list, 93))
False
True
순차 탐색 시간복잡도
탐색 알고리즘의 시간복잡도 분석은 일반적으로 항목과 값의 비교를 기본 계산단위로 사용한다. 그리고 순차탐색의 경우 모든 항목이 동일한 확률로 임의의 위치에 있을 수 있다고 가정한다. 즉, 특별한 값이 특정 위치에 있을 확률을 별도로 고려할 필요가 없다고 가정한다. 그렇지 않다면 확인하는 값에 따라 포함여부를 확인하는 데에 걸리는 시간이 다를 수 있다.
리스트의 길이 \(n\)을 입력크기로 사용 했을 때 두 가지 경우를 고려해야 한다.
항목이 리스트에 포함된 경우: 최선, 최악, 평균 시간복잡도가 달라짐.
항목이 리스트에 포함되지 않은 경우: 최선, 최악, 평균 시간복잡도가 \(n\)으로 동일함.
최선 |
최악 |
평균 |
|
|---|---|---|---|
항목인 경우 |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
항목 아닌 경우 |
\(n\) |
\(n\) |
\(n\) |
정렬된 리스트 순차 탐색
아래 그림의 리스트는 항목들이 오름차순으로 정렬되어 있다. 이런 경우 순차탐색을 일반적인 경우와는 조금 다르게 구현할 수 있다. 왜냐하면 항목을 확인하다가 찾아야 하는 값보다 큰 값이 항목으로 확인되면 더 이상 탐색을 진행할 필요가 없기 때문이다.
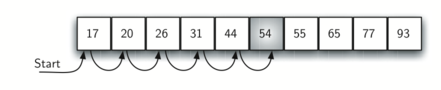
def ordered_sequential_search(a_list, value):
# 순차 탐색
for item in a_list:
if item == value:
return True
elif item > value: # 보다 큰 값이 확인되면 바로 탐색 중단
return False
return False
test_list = [17, 20, 26, 31, 44, 54, 55, 65, 77, 93]
print(ordered_sequential_search(test_list, 33))
print(ordered_sequential_search(test_list, 54))
False
True
찾는 값이 항목인 경우와 그렇지 않은 경우 모두 동일한 최선, 최악, 평균 시간 복잡도를 갖는다.
최선 |
최악 |
평균 |
|
|---|---|---|---|
항목인 경우 |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
항목 아닌 경우 |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
퀴즈
리스트 [15, 18, 2, 19, 18, 0, 8, 14, 19, 14]에 18이 포함되었는지
여부를 판단하는 데에 필요한 항목 비교 횟수는 얼마인가?
정답: 2회
퀴즈
리스트 [3, 5, 6, 8, 11, 12, 14, 15, 17, 18]에 13이 포함되었는지
여부를 판단하는 데에 필요한 항목 비교 횟수는 얼마인가?
정답: 7회
12.1.2. 이진 탐색#
정렬된 리스트를 대상으로 탐색할 때 순차탐색보다 훨씬 빠른 이진 탐색binary search 알고리즘을 사용할 수 있다. 이진 탐색은 리스트의 중앙에 위치한 항목부터 찾는 값과 비교한 다음에 참이면 탐색을 멈추고, 아니면 중앙 위치 왼편 또는 오른편 한 쪽만 대상으로 해서 동일한 동일한 탐색 과정을 반복 실행한다. 아래 그림은 54를 이진 탐색 방식으로 찾아가는 과정을 보여준다.
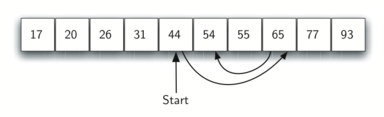
아래 binary_search() 함수는 이진 탐색 알고리즘을 구현한다.
항목의 탐색 구간을 전체 리스트를 대상으로 시작한 다음에
탐색을 반복할 때마다 구간의 크기를 절반으로 줄인다.
탐색 구간의 크기가 0이 될 때까지 탐색을 반복한다.
함수 정의에 사용된 변수는 다음과 같다.
first: 탐색을 반복할 때 마다 변하는 탐색 구간의 왼쪽 끝last: 탐색을 반복할 때 마다 변하는 탐색 구간의 오른쪽 끝midpoint: 탐색 구간의 중앙위치
def binary_search(a_list, value):
# 탐색 구간: 전체 리스트로 시작
first = 0
last = len(a_list) - 1
# 탐색 구간의 크기가 0이상인 경우 반복
while first <= last:
# 탐색 구간의 중앙위치
midpoint = (first + last) // 2
# 구간의 중앙값 확인
if a_list[midpoint] == value: # 항목을 찾은 경우
return True
# 구간의 중앙값이 찾는 값이 아닌 경우: 구간 절반 포기
elif value < a_list[midpoint]: # 중앙위치 왼편으로 탐색구간 조정
last = midpoint - 1
else: # 중앙위치 오른편으로 탐색구간 조정
first = midpoint + 1
return False
test_list = [17, 20, 26, 31, 44, 54, 55, 65, 77, 93]
print(binary_search(test_list, 33))
print(binary_search(test_list, 54))
False
True
이진 탐색 시간복잡도
이진 탐색 알고리즘에 사용된 반복문이 실행될 때마다 비교 횟수는 1이 늘고, 그 다음 탐색 구간의 크기는 절반으로 줄어든다.
비교 횟수 |
탐색구간 크기 |
|---|---|
\(1\) |
\(\frac{n}{2}\) |
\(2\) |
\(\frac{n}{4}\) |
\(3\) |
\(\frac{n}{8}\) |
\(\vdots\) |
\(\vdots\) |
\(k\) |
\(\frac{n}{2^k}\) |
따라서 최악의 경우 아래 조건이 만족될 때 까지 반복문이 실행된다.
즉, 최악의 경우 \(k = \log_2 n\) 번 반복문, 즉 비교가 발생하며, 따라서 이진 탐색 알고리즘의 시간복잡도는 \(O(\log_2 n)\)이다.
이진 탐색 알고리즘의 한계
이진 탐색을 사용하기 위해서는 리스트를 먼저 정렬해야 한다. 하지만 (나중에 살펴보겠지만) 지금까지 알려진 정렬 알고리즘의 최악 시간복잡도는 \(O(n^2)\)이기에 정렬을 하고 이진 탐색을 사용할지, 아니면 그냥 순차탐색을 사용할지 판단해야 한다.
한번 정렬해 둔 리스트를 대상으로 탐색을 많이 한다면 정렬 비용이 든다 하더라도 이후의 이진 탐색 시간이 훨씬 좋아지므로 그럴 가치가 있다. 하지만 리스트가 매우 긴 경우 정렬 자체가 매우 오래 걸리기에 그냥 순차탐색을 활용하는 것이 보다 나을 수도 있다.
12.2. 분할 정복#
분할 정복divide-and-conquer은 큰 입력사례의 해법을 보다 작은 크기의 입력사례에서 찾는 기법을 말한다. 앞서 살펴 본 이진 탐색이 대표적인 분할 정복 기법의 활용예제이다. 이유는 작은 크기의 구간에서 항목을 찾았을 때 바로 원래 리스트에서 항목을 찾은 것으로 간주하기 때문이다.
분할 정복과 재귀
분할 정복 기법으로 해결되는 문제는 기본적으로 재귀로 매우
효율적으로 해결된다.
다음 binary_search_rec() 함수는
이진 탐색을 재귀함수로 구현한다.
def binary_search_rec(a_list, value):
# 리스트의 길이가 0일 때
if len(a_list) == 0:
return False
# 리스트의 길이가 0보다 클 때
else:
midpoint = len(a_list) // 2
if a_list[midpoint] == value:
return True
# 재귀호출: 탐색구간 조정
elif value < a_list[midpoint]:
return binary_search_rec(a_list[:midpoint], value)
else:
return binary_search_rec(a_list[midpoint + 1 :], value)
test_list = [17, 20, 26, 31, 44, 54, 55, 65, 77, 93]
print(binary_search_rec(test_list, 33))
print(binary_search_rec(test_list, 54))
False
True
재귀 이진 탐색 알고리즘 시간 복잡도
binary_search_rec() 함수에 사용된 이진 탐색 알고리즘의 시간복잡도는
binary_search() 함수의 경우처럼 \(O(\log n)\)으로 보이지만 이는 정확하지 않다.
이유는 binary_search_rec() 함수가 재귀호출될 때마다
새로운 리스트를 슬라이싱으로 생성하여 사용하기 때문에
슬라이싱에 필요한 시간이 추가로 요구된다.
참고로 리스트의 슬라이싱 함수의 시간복잡도는
슬라이싱 구간의 크기 \(k\)에 선형적으로 비례하는 \(O(k)\)이다.
이런 단점을 보완하려면 슬라이싱을 실행하는 것 대신에
binary_search() 함수에서 처럼 탐색구간의 처음과 끝에 대한 인덱스를 활용할 수 있다.
구간 지정 재귀 이진 탐색 알고리즘
def interval_binary_search_rec(a_list, value, first, last):
# 탐색 구간의 크기가 0일 때
if len(a_list) == 0 or last < first:
return False
# 리스트의 길이가 0보다 클 때
else:
midpoint = (first + last) // 2
if a_list[midpoint] == value:
return True
# 재귀호출: 탐색구간 조정
elif value < a_list[midpoint]:
last = midpoint - 1
return interval_binary_search_rec(a_list, value, first, last)
else:
first = midpoint + 1
return interval_binary_search_rec(a_list, value, first, last)
test_list = [17, 20, 26, 31, 44, 54, 55, 65, 77, 93]
print(interval_binary_search_rec(test_list, 33, 0, len(test_list)-1))
print(interval_binary_search_rec(test_list, 20, 0, len(test_list)-1))
False
True
퀴즈
리스트 [3, 5, 6, 8, 11, 12, 14, 15, 17, 18]가 주어졌을 때
재귀 이진 탐색 알고리즘을 이용하여 8을 탐색할 때
비교되는 값들은 무엇인가?
정답: 12, 6, 11, 8
퀴즈
리스트 [3, 5, 6, 8, 11, 12, 14, 15, 17, 18]가 주어졌을 때
재귀 이진 탐색 알고리즘을 이용하여 16을 탐색할 때 비교되는 값들은 무엇인가?
정답: 12, 17, 15