10. 재귀 함수#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
재귀 개념
재귀 함수
10.1. 재귀 함수#
재귀recursion는 주어진 문제를 해결하기 위해 보다 간단한 문제들로 쪼개어 해결하는 과정을 반복하는 기법이다. 많은 문제가 재귀를 이용하여 간단하게 해결될 수 있다. 대표적으로 분할 정복 기법으로 풀릴 수 있는 문제가 재귀를 활용하여 쉽게 해결될 수 있다. 재귀 함수는 재귀를 이용하여 정의된 함수를 의미한다.
예제: 리스트 항목들의 합
리스트에 포함된 항목들의 합을 구하는 함수를
for 반복문을 이용하여 구현하면 다음과 같다.
항목들의 누적합을 0으로 지정하고 시작
각 항목을 확인할 때마다 누적합 계산
def sum(num_list):
# 누적 합 저장
the_sum = 0
# 모든 항목을 누적합에 더하기
for item in num_list:
the_sum = the_sum + item
return the_sum
print(sum([1, 3, 5, 7, 9]))
25
위 코드의 for 반복문에서 항목을 확인할 때마다 업데이트되는
the_sum 변수는 아래 괄호가 묶인 순서대로 계산되는 값을 차례대로 가리킨다.
반면에 재귀 기법을 적용하면 the_sum의 값이 다음과 같이 업데이트 된다.
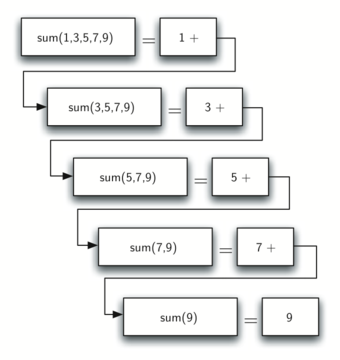
즉, 항목들의 합이 다음과 같이 계산된다.
이유는 예를 들어 sum([1, 3, 5, 7, 9)를 계산하기 위해 먼저
sum([3, 5, 7, 9)를 계산한 다음 그 값을 1과 더하기 때문이다.
리스트의 머리와 꼬리 활용
리스트의 항목들의 합이 아래 과정을 반복 적용하는 방식으로 계산된다.
sum(num_list) = num_list[0] + sum(num_list[1:])
위 식을 리스트의 머리와 꼬리 개념으로 이해하면 재귀 알고리즘의 작동과정을 보다 쉽게 이해할 수 있다.
머리(head): 리스트의 0번 인덱스 값, 즉
num_list[0]꼬리(tail): 0번 인덱스를 제외한 나머지, 즉
num_list[1:]
머리와 꼬리 개념을 이용하여 재귀를 설명하면 다음과 같다.
먼저 꼬리에 재귀를 적용한다.
꼬리에 대한 재귀가 특정 값을 반환할 때까지 기다린 다음 머리와 합한다.
앞서 설명한 재귀를 함수로 구현하면 다음과 같다.
def sum(num_list):
if len(num_list) == 1: # 항목이 1개 일때
return num_list[0]
else: # 항목이 2개 이상일 때: 머리와 꼬리 재귀 결과의 합
return num_list[0] + sum(num_list[1:])
print(sum([1, 3, 5, 7, 9]))
25
재귀 호출
함수가 실행될 때 함수 자신을 호출하는 것을 재귀 호출recursive call이라 한다. 재귀 호출을 이용하여 구현된 알고리즘은 재귀 알고리즘recursive algorithm, 재귀 알고리즘을 사용한 함수가 재귀 함수recursive function이다.
10.2. 재귀 알고리즘의 특징#
재귀 알고리즘은 아래 세 가지 특징을 가져야 한다.
재귀 호출이 반드시 발생해야 한다.
종료 조건base case이 존재해야 한다.
sum()함수의 경우len(num_list) == 1이 종료 조건을 다룬다.종료 조건이 없는 재귀 알고리즘은 실행이 종료되지 않을 수 있다.
재귀 호출에 사용되는 입력값의 크기가 줄어들어야 한다.
sum()함수의 경우sum(num_list[1:])에 사용된 리스트num_list[1:]의 크기는num_list보다 1 작다.재귀 호출이 반복되어 결국에는 종료 조건을 만족하는 상태, 즉
len(num_list) == 1이 되는num_list가 인자로 사용되어야 한다.
예제 1: 종료 조건이 없는 경우
종료 조건이 없는 재귀 호출은 실행이 종료되지 않을 수 있다.
def f(x):
return f(x-1) + 1
예제 2: 종료 조건에 다달하는지 여부를 알 수 없는 경우
아래 collatz(n) 함수는 임의의 양의 정수 n에 대해 짝수면 2로 나누고,
홀수면 세 배 더하기 1을 반복적으로 실행하여 언젠가 1이 나오면 멈춘다.
def collatz(n):
if n == 1:
print(n)
elif n % 2 == 0:
print(n, end=', ')
collatz(n//2)
else:
print(n, end=', ')
collatz(3*n + 1)
collatz(7)
7, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1
collatz(27)
27, 82, 41, 124, 62, 31, 94, 47, 142, 71, 214, 107, 322, 161, 484, 242, 121, 364, 182, 91, 274, 137, 412, 206, 103, 310, 155, 466, 233, 700, 350, 175, 526, 263, 790, 395, 1186, 593, 1780, 890, 445, 1336, 668, 334, 167, 502, 251, 754, 377, 1132, 566, 283, 850, 425, 1276, 638, 319, 958, 479, 1438, 719, 2158, 1079, 3238, 1619, 4858, 2429, 7288, 3644, 1822, 911, 2734, 1367, 4102, 2051, 6154, 3077, 9232, 4616, 2308, 1154, 577, 1732, 866, 433, 1300, 650, 325, 976, 488, 244, 122, 61, 184, 92, 46, 23, 70, 35, 106, 53, 160, 80, 40, 20, 10, 5, 16, 8, 4, 2, 1
collatz(1024)
1024, 512, 256, 128, 64, 32, 16, 8, 4, 2, 1
앞서 보았듯이 입력값이 커질 수록 재귀 호출 횟수가 반드시 많아지는 것은 아니다. 실제로 지금까지 재귀 호출 횟수와 관련해서 어떤 규칙도 발견되지 않았다. 즉, 입력값이 주어지면 언제 종료되는지 아직 아무도 모른다. 이런 이유로 이 문제를 콜라츠 추측(Collatz Conjecture)이라 부른다.
아래 그림은 collatz(27) 이 실행되는 동안 재귀 호출에 사용되는 인자의 변화를 보여준다.
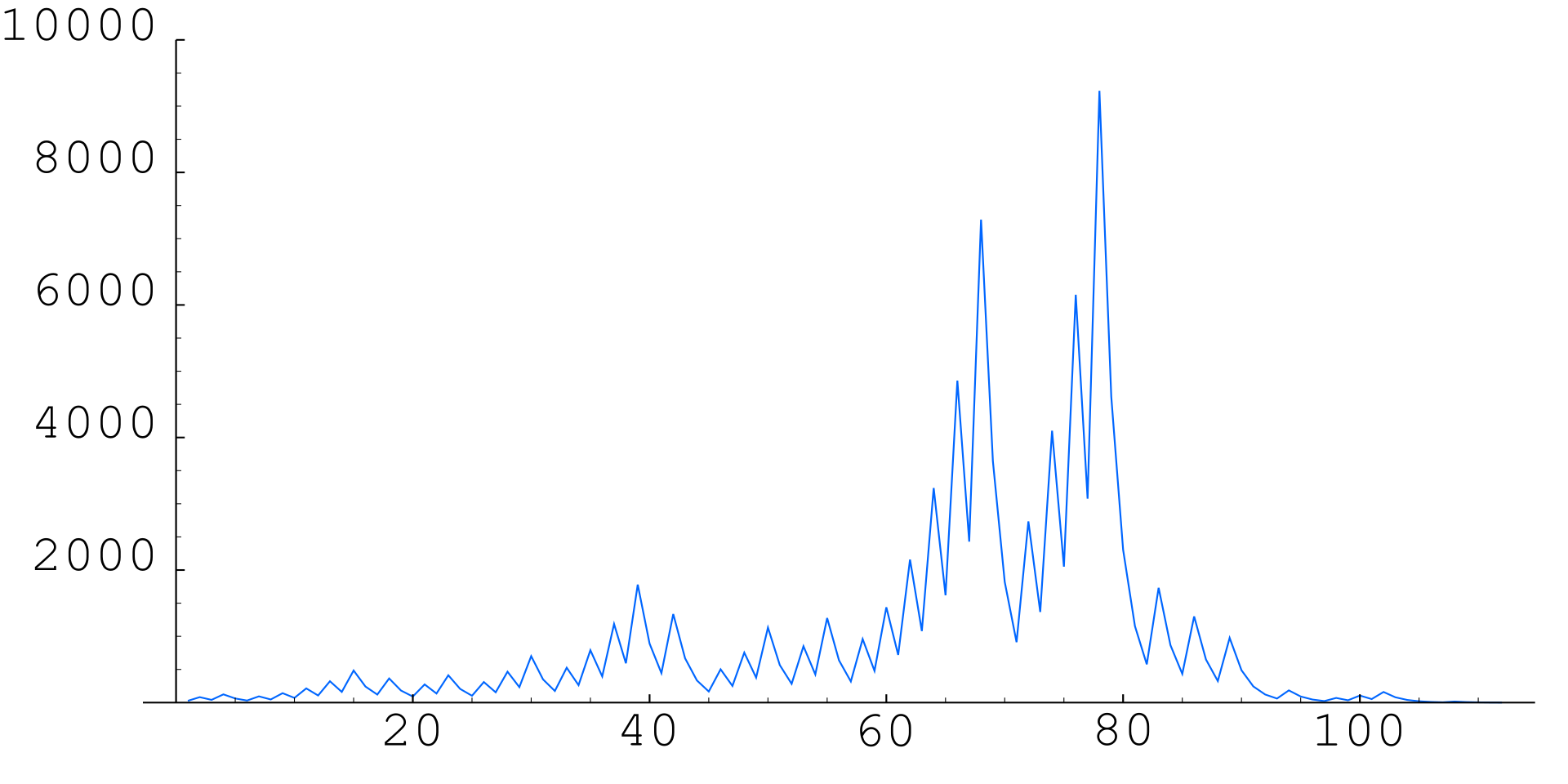
<그림 출처: 위키백과: 콜라츠 추측>
10.3. 진법 변환#
정수를 특정 진법으로 변환하는 함수를 재귀를 이용하여 구현한다. 반환값은 문자열로 처리한다.
이진법 변환
아래 그림은 정수 10을 이진법으로 변환하는 과정을 보여준다.
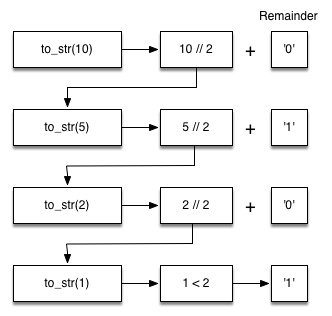
결론적으로 아래 세 가지 사항을 재귀 알고리즘 정의에 활용할 수 있다.
종료 조건: 사용되는 진법보다 작은 수는 그대로 문자열로 사용한다. 예를 들어
8진법인 경우엔 0부터 7까지의 수는 각각
'0','1', …,'7'등으로 변환한다.16진법인 경우엔 0부터 15까지의 수를 각각
'0','1', …,'9','A','B', …,'F'로 변환한다.
재귀: 사용되는 진법보다 큰 수는 진법의 수로 나눈 다음에 몫에 대해 재귀를 적용한 결과를 최종 반환값에 더한다.
아래 to_str() 함수는 정수와 진법이 정해졌을 때 해당 진법으로 변환된 문자열을 반환하며,
앞서 설명한 재귀 알고리즘을 그대로 구현한다.
단, 이진법에서 16진법까지만 지원한다.
def to_str(n, base):
numeric_string = "0123456789ABCDEF"
if n < base: # 종료 조건
return numeric_string[n]
else: # 재귀
return to_str(n // base, base) + numeric_string[n % base]
print(to_str(46685, 2))
1011011001011101
print(to_str(46685, 8))
133135
print(to_str(46685, 16))
B65D
10.4. 콜 스택#
파이썬의 경우 재귀 함수가 실행되면 재귀 호출이 발생할 때마다 함수 호출의 실행을 관리하는 프레임frame이 생성된다. 생성되는 프레임은 스택으로 관리되며 이를 콜 스택call stack이라 부른다.
아래 진법 변환 함수를 PythonTutor: 콜 스택 에서 실행하면서 프레임 스택의 변화를 한 눈에 살펴볼 수 있다.
참고: 메모리 상에서의 변화를 보다 명료하게 보여주기 위해 이전 보다 변수가 몇 개 더 추가되었다.
numeric_string = "0123456789ABCDEF" # 진법 표현에 사용될 기호
remainder_list = [] # 나머지 기호 저장용 스택
def to_str(n, base):
if n < base: # 종료 조건
return numeric_string[n]
else:
quotient = n // base # 몫
remainder = n % base # 나머지
remainder_string = numeric_string[remainder]
remainder_list.append(remainder_string) # 나머지 기호 저장
return to_str(quotient, base) + remainder_list.pop() # 몫에 대한 재귀 호출
print(to_str(46685, 16))
B65D
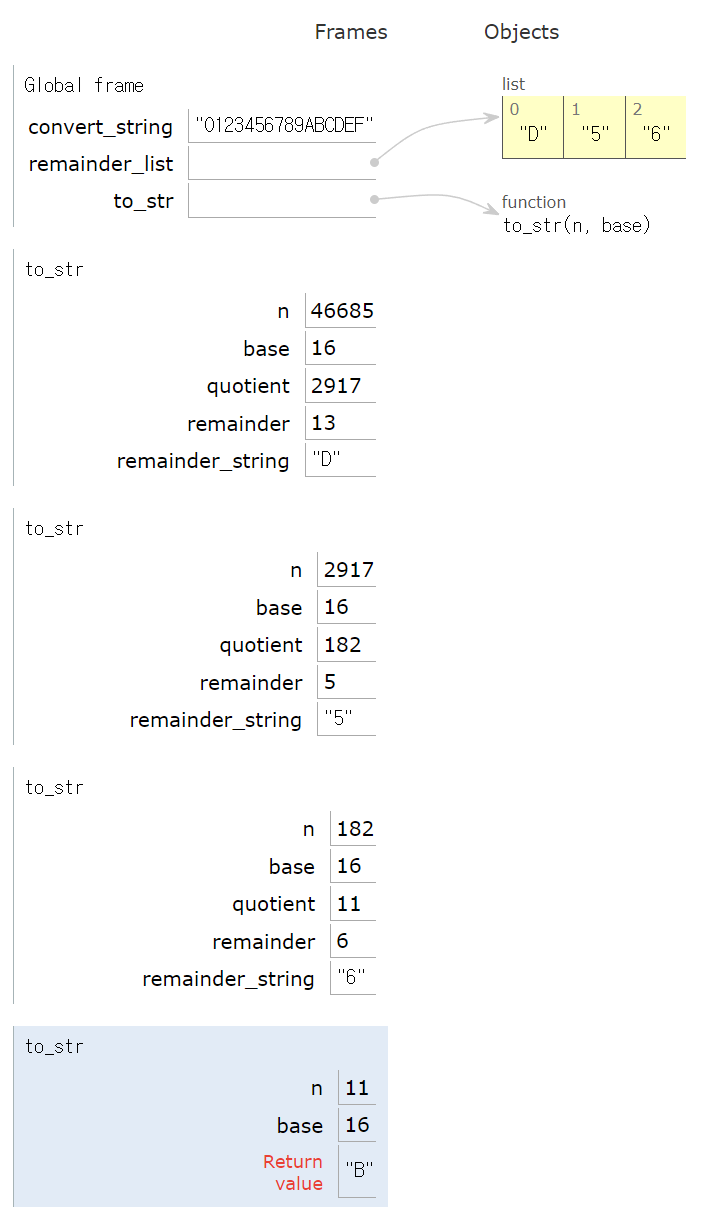
아래 그림은 to_str(46685, 16)이 호출되어 콜 스택이 가장 높게 쌓였을 때를 보여준다.
스택 오버플로우
재귀 호출이 너무 많은 경우 스택 오버플로우로 인한 RecursionError 오류가 발생한다.
예를 들어 아래 f() 함수는 재귀를 무한정 호출한다.
파이썬은 재귀 호출에 활용되는 스택 메모리 영역을 보호하기 위해 최대 1만번 까지의 재귀 호출을 허용한다.
def f(x):
return f(x-1) + 1
f(10)
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
Cell In[16], line 4
1 def f(x):
2 return f(x-1) + 1
----> 4 f(10)
Cell In[16], line 2, in f(x)
1 def f(x):
----> 2 return f(x-1) + 1
Cell In[16], line 2, in f(x)
1 def f(x):
----> 2 return f(x-1) + 1
[... skipping similar frames: f at line 2 (2975 times)]
Cell In[16], line 2, in f(x)
1 def f(x):
----> 2 return f(x-1) + 1
RecursionError: maximum recursion depth exceeded
재귀 호출 허용 횟수를 지정할 수는 있지만 권장되지 않는다.