13. 버블/선택/합병/퀵 정렬#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
버블 정렬
선택 정렬
합병 정렬
퀵 정렬
정렬sorting은 모음 객체에 포함된 항목들을 특정 크기 기준에 따라 오름차순 또는 내림차순으로 순서대로 위치시키는 과정이다. 예를 들어, 문자열들로 이루어진 리스트의 항목을 알파벳 순서대로 정렬하거나, 도시들의 리스트를 인구, 면적, 또는 우편번호 등으로 정렬할 수 있다.
정렬의 중요성은 어구전철anagram 관계 확인, 이진탐색 등에서 정렬된 리스트가 얼마나 유용하게 활용되는지를 통해 확인했었다.
다양한 종류의 정렬 알고리즘이 알려져 있으며 각자 고유의 장점을 갖는다. 이는 모든 경우에 항상 효율적으로 작동하는 정렬 알고리즘이 알려지지 않았음을 의미한다. 여기서는 다양한 알고리즘을 소개하고 장단점을 비교한다.
정렬 알고리즘의 시간복잡도 분석에 사용되는 기본 단위연산은 다음 두 가지가 일반적으로 사용된다.
두 값의 크기 비교: 두 항목의 크기를 서로 비교할 수 있어야 함.
두 항목의 자리 교환: 예를 들어, 보다 작은 값을 보다 큰 값보다 왼편에 위치하도록 해야 함.
13.1. 버블 정렬#
버블 정렬bubble sort 알고리즘은 패스pass로 구성된다. 하나의 패스 과정 동안 연속된 위치의 두 수를 비교하여 작은 항목은 왼쪽으로, 큰 항목은 오른쪽으로 자리를 바꾸는 일을 리스트의 맨 왼쪽에서 시작하여 오를쪽 끝까지 진행한다. 하나의 패스가 완료되면 패스 과정에서 확인된 가장 큰 항목이 리스트의 맨 오른쪽에 위치하게 된다.
그런 다음엔 맨 오른쪽에 위치한 가장 큰 항목을 제외한 왼쪽 구간을 대상으로 두번째 패스를 진행하고, 최종적으로 두번째로 큰 항목을 리스트의 맨 오른쪽 끝에서 둘째 자리에 위치시킨다. 이런 패스 과정을 반복하면 결국에 가장 작은 항목이 리스트의 맨 왼편에, 가장 큰 항목은 리스트의 맨 오른편에 위치하고 모든 항목이 크기 순서대로 정렬된 리스트가 생성된다.
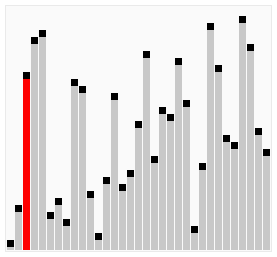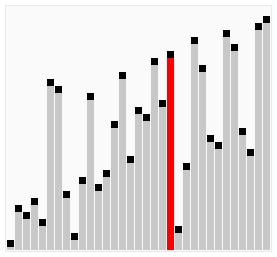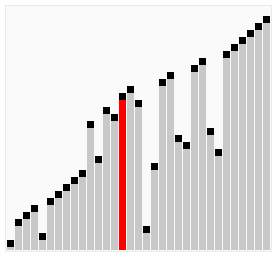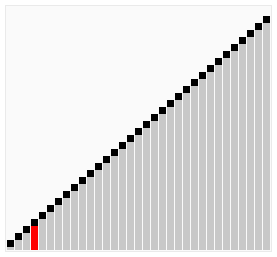
아래 그림은 첫번째 패스 과정을 묘사하며 최종적으로 가장 큰 항목이 맨 오른쪽으로 이동한다.
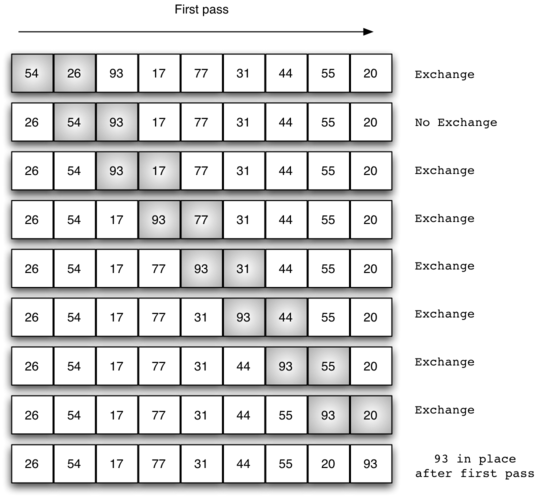
아래 이미지는 버블 정렬의 전체 패스가 작동하는 과정을 보여준다. 거품이 뽀글뽀글 위로 올라가(bubble up)는 거에 비유해서 버블 정렬이라 부른다.
다음 bubble_sort() 함수가 리스트를 버블 정렬한다.
이주 for 반복문을 사용하며 각 반복문에서 사용되는 변수들의 역할은 다음과 같다.
a_pass: 하나의 패스를 가리킴. 동시에 자리교환 대상의 끝자리 인덱스도 지정.j: 패스 별 크기비교 및 자리교환 수행
def bubble_sort(a_list):
for a_pass in range(len(a_list) - 1, 0, -1): # 패스. 자리교환 인덱스 끝자리 지정
for j in range(a_pass): # 크기비교 및 자리교환
if a_list[j] > a_list[j + 1]:
a_list[j], a_list[j+1] = a_list[j + 1], a_list[j]
a_list = [11, 54, 26, 93, 17, 77, 4, 31, 44, 55, 20, 100]
bubble_sort(a_list)
print(a_list)
[4, 11, 17, 20, 26, 31, 44, 54, 55, 77, 93, 100]
버블 정렬 시간복잡도 분석
항목들의 비교 횟수는 1부터 (n-1)까지의 합임을 쉽게 알 수 있다.
패 스 |
비교 횟수 |
|---|---|
\(1\) |
\(n-1\) |
\(2\) |
\(n-2\) |
\(3\) |
\(n-3\) |
\(\vdots\) |
\(\vdots\) |
\(n-1\) |
\(1\) |
따라서 총 비교 횟수는 다음과 같이 \(O(n^2)\)의 시간복잡도를 갖는다.
반면에 자리교환은 최소 0, 최대 비교횟수와 동일하게 발생하며, 평균적으로 비교횟수의 절반정도 발생한다. 따라서 최선, 최악, 평균 시간복잡도 모두 \(O(n^2)\)의 시간복잡도를 갖는다.
버블 정렬 조기종료
버블 정렬이 실행되는 동안 특정 패스에서 자리교환이 한 번도 발생하지 않는다면
해당 리스트는 이미 크기순으로 정렬이 되어 있음을 의미한다.
따라서 그때 바로 실행을 종료해도 된다.
다음 bubble_sort_early_stop() 함수는 조기종료를 지원하는 버블 정렬 알고리즘을 구현한다.
참고로 정렬 알고리즘 중에서 이러한 조기종료 기능을 갖는 알고리즘은 버블 정렬이 유일하다.
def bubble_sort_early_stop(a_list):
for a_pass in range(len(a_list) - 1, 0, -1): # 패스. 자리교환 인덱스 끝자리 지정
exchanges = False # 패스 기간 내 자리교환 발생 여부 저장
for j in range(a_pass): # 크기비교 및 자리교환
if a_list[j] > a_list[j + 1]:
a_list[j], a_list[j+1] = a_list[j + 1], a_list[j]
exchanges = True
if not exchanges: # 자리교환이 발생하지 않은 경우 조기종료
print("조기종료!")
break
a_list = [20, 30, 40, 90, 50, 60, 70, 80, 100, 110]
bubble_sort_early_stop(a_list)
print(a_list)
조기종료!
[20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
퀴즈
리스트 [19, 1, 9, 7, 3, 10, 13, 15, 8, 12]에 대해 버블 정렬을 진행할 때
세 번의 패스가 완성된 후의 리스트는 어떤 모습인가?
정답: [1, 3, 7, 9, 10, 8, 12, 13, 15, 19]
13.2. 선택 정렬#
선택 정렬selection sort은 버블 정렬의 단점인 많은 자리교환 횟수를 패스당 최대 한 번만 수행하도록 개선한 기법이다. 따라서 작동과정은 기본적으로 버블 정렬과 동일하며, 다만 자리교환을 바로 실행하는 게 아니라 패스 별로 최댓값을 확인한 다음에 최종적으로 필요에 따라 딱 한 번 자리교환을 실행한다.
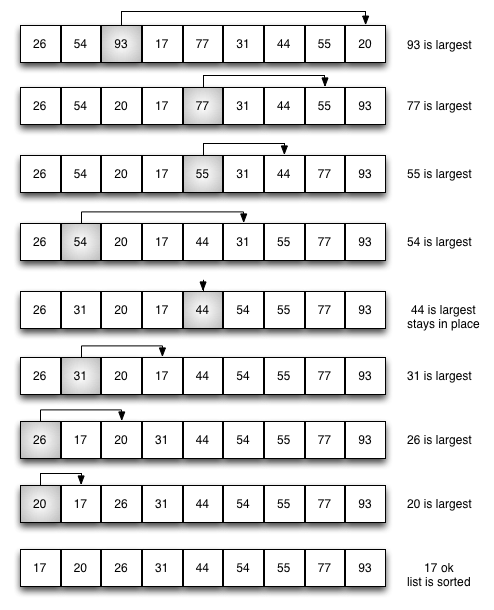
아래 그림은 길이가 9인 리스트에 대해 8번의 패스를 실행하는 동안 각 팩스에서 최대 한 번의 자리교환이 발생함을 보여준다. 심지어 다섯번째 패스에서는 자리교환이 전혀 없다. 이유는 44가 해당 패스에서의 최댓값인데 있어야할 위치에 있기 때문이다.
다음 selection_sort() 함수가 리스트를 선택 정렬한다.
이주 for 반복문을 사용하며 각 반복문에서 사용되는 변수들의 역할은 다음과 같다.
a_pass: 하나의 패스를 가리킴. 동시에 자리교환 대상의 끝자리 인덱스도 지정.max_idx: 패스 별로 탐색된 최댓값의 위치 인덱스j: 패스 별 크기비교 수행
def selection_sort(a_list):
for a_pass in range(len(a_list)-1, 0, -1):
max_idx = 0
for j in range(a_pass):
if a_list[j] > a_list[max_idx]:
max_idx = j
# a_pass 인덱스 이전까지 찾은 최댓값과 a_pass 위치의 값 자리교환 여부 판단
if a_list[max_idx] > a_list[a_pass]:
a_list[max_idx], a_list[a_pass] = a_list[a_pass], a_list[max_idx]
a_list = [26, 54, 93, 17, 77, 31, 44, 55, 20]
selection_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
선택 정렬 시간복잡도 분석
크기비교는 버블 정렬의 경우와 동일하게 발생하여 시간복잡도는 \(O(n^2)\)이다. 다만 자리교환 횟수가 최대 \((n-1)\) 번 발생해서 버블 정렬보다 좀 더 빠르다.
퀴즈
리스트 [11, 7, 12, 14, 19, 1, 6, 18, 8, 20]에 대해
선택 정렬을 진행할 때
세 번의 패스가 완성된 후의 리스트는 어떤 모습인가?
정답: [11, 7, 12, 14, 8, 1, 6, 18, 19, 20]
13.3. 합병 정렬#
분할 정복 기법을 이용하는 정렬 알고리즘인 합병 정렬과 퀵 정렬을 소개한다.
합병 정렬merge sort에 사용되는 분할과 정복은 다음과 같다.
분할: 리스트의 길이가 1이 될 때까지 반복적으로 이등분한다.
정복: 길이가 작은 두 개의 리스트를 합병해서 보다 큰 길이의 리스트를 생성한다. 합병 과정에서 항목들을 크기 순으로 정렬한다.
분할 과정
분할 과정은 쉽다. 재귀적으로 리스트의 길이가 1이 될 때까지 이등분을 반복한다.
코드 끝에서 사용된 merge() 함수는 합병을 담당하는 함수이며 바로 이어서 설명하고 정의한다.
def merge_sort(a_list):
# 분할 과정: 이등분 반복
if len(a_list)>1:
print("분할:", a_list)
mid = len(a_list) // 2
left_half = a_list[:mid]
right_half = a_list[mid:]
# 재귀 호출
merge_sort(left_half)
merge_sort(right_half)
# 합병 과정: 작은 리스트 두 개 합병하면서 정렬
merge(a_list, left_half, right_half)
print("합병:", a_list)
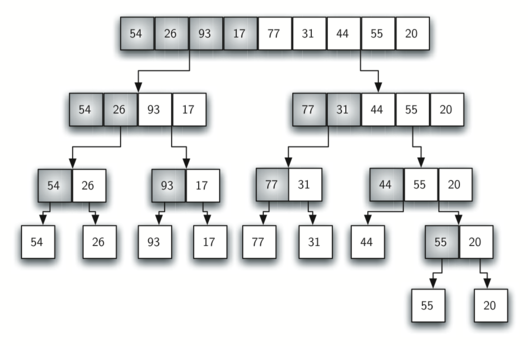
합병 과정
합병 과정은 보다 어렵다. 이미 정렬된 두 개의 리스트를 합쳐서 정렬된 새 리스트를 만들어야 한다. 이를 위해 사용되는 알고리즘은 다음과 같다.
두 리스트의 항목을 하나씩 비교해서 작은 수를 먼저 새로운 리스트에 추가한다.
한 쪽 리스트의 항목을 모두 새로운 리스트에 추가했다면 다른 리스트의 나머지 항목들은 그대로 새로운 리스트에 추가한다.
def merge(a_list, left_half, right_half):
i, j, k = 0, 0, 0
while i < len(left_half) and j < len(right_half):
if left_half[i] <= right_half[j]:
a_list[k] = left_half[i]
i = i + 1
else:
a_list[k] = right_half[j]
j = j + 1
k = k + 1
while i < len(left_half):
a_list[k] = left_half[i]
i = i + 1
k = k + 1
while j < len(right_half):
a_list[k] = right_half[j]
j = j + 1
k = k + 1
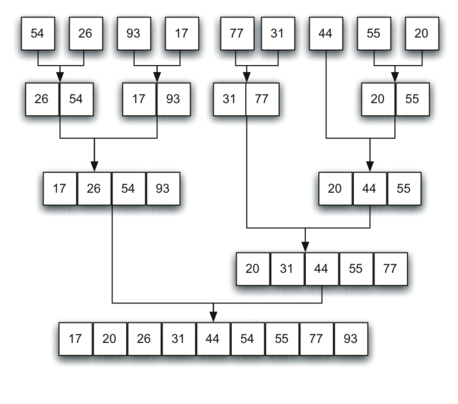
분할과 합병이 재귀적으로 발생하는 순서
merge_sort() 함수는
print() 함수를 이용하여 분할이 발생하는 순간과 합병이 진행될 때의 결과물을
화면에 출력한다.
이 기능을 통해 분할과 정복이 재귀적으로 어떤 순서대로 진행되는지를 시각적으로 파악할 수 있다.
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
merge_sort(a_list)
분할: [54, 26, 93, 17, 77, 31, 44, 55, 20]
분할: [54, 26, 93, 17]
분할: [54, 26]
합병: [26, 54]
분할: [93, 17]
합병: [17, 93]
합병: [17, 26, 54, 93]
분할: [77, 31, 44, 55, 20]
분할: [77, 31]
합병: [31, 77]
분할: [44, 55, 20]
분할: [55, 20]
합병: [20, 55]
합병: [20, 44, 55]
합병: [20, 31, 44, 55, 77]
합병: [17, 20, 26, 31, 44, 54, 55, 77, 93]
아래 그래프는 분할과 합병이 이뤄지는 순서를 보여준다.
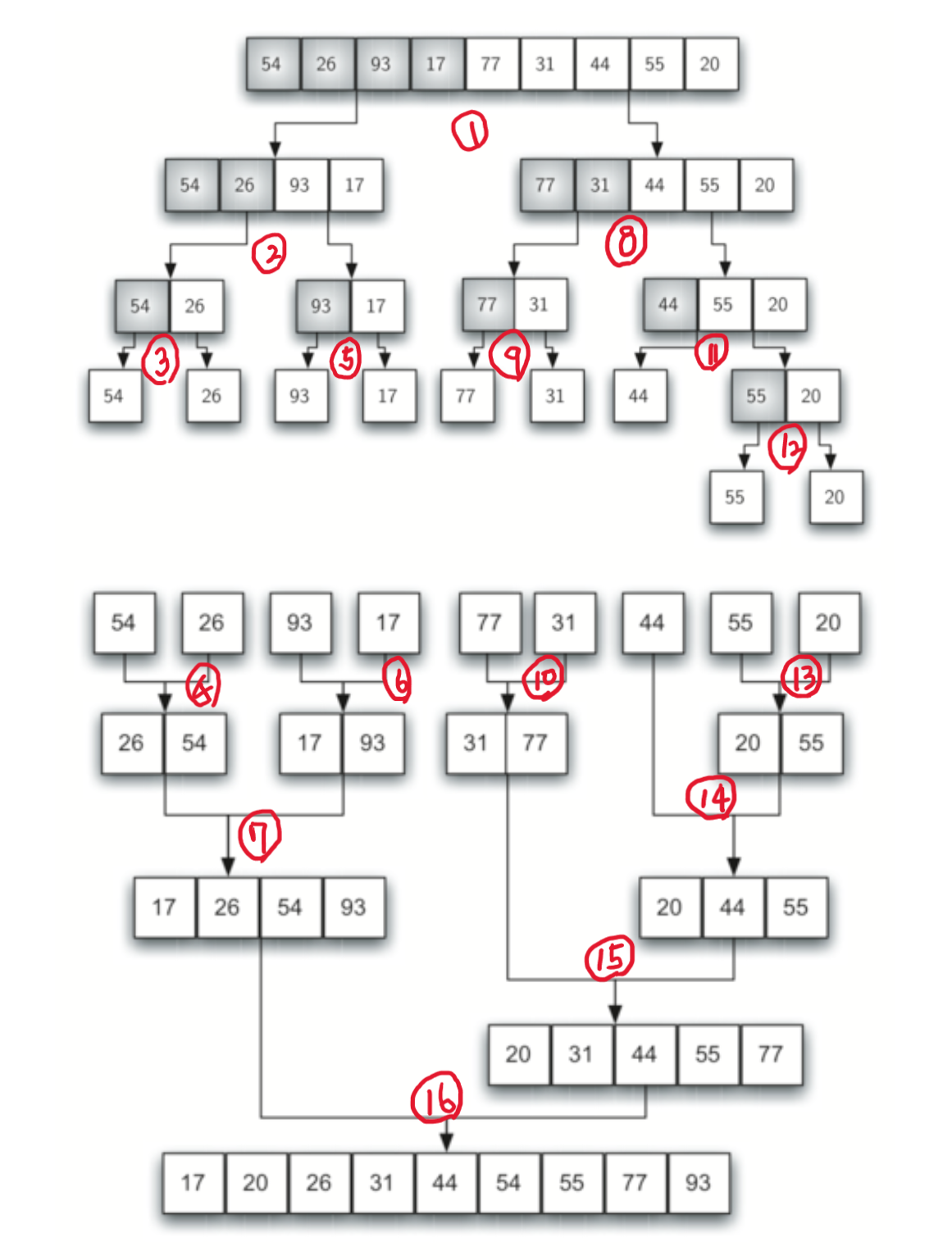
합병 정렬 시간복잡도 분석
분할과 합병에 필요한 시간을 분리해서 계산한다. 입력 리스트의 길이 \(n\)을 입력 크기로 사용한다.
분할 과정
비교연산이나 위치 이동이 전혀 없음.
합병 과정
합병과정을 그래프로 간주하면 높이가
int(log(n)) + 1인 가지가 두 개로 갈라지는 이진 트리임.하나의 레벨(나무의 동일한 높이)에서 합병이 여러 번 발생하는 데 각각의 합병 과정에서 발생하는 항목 비교와 위치 이동을 다 합치면 최대
2*n번임.따라서 합병 과정에서 발생하는 항목 비교와 위치 이동은 최악의 경우 \(O(n \log n)\)의 시간 복잡도를 가짐.
슬라이싱과 추가 메모리 사용
위 코드의 분할 과정에 사용된 재귀는 슬라이싱을 이용하기 때문에 실제 시간복잡도는 \(O(n^2 \log n)\)이다. 이유는 길이가 \(k\)인 구간을 슬라이싱 하는 알고리즘의 시간복잡도가 \(O(k)\)이기 때문이다.
참고
슬라이싱을 직접 사용하는 대신 구간을 지정하는 기술을 적용하면 분할 알고리즘의 시간복잡도를 \(O(n \log n)\)으로 만들 수 있다(연습 문제 참고). 그런데 슬라이싱 대신 구간을 사용하여 분할 과정을 추가 메모리 없이 진행하면 합병 과정에서 기존 리스트와의 충돌 방지를 위해 추가 메모리를 사용할 수 밖에 없다. 따라서 어떤 방식이든 \(O(n)\)의 공간복잡도에 해당하는 메모리를 추가로 사용해야 한다.
반면에 앞서 소개한 버블 정렬과 선택 정렬은 추가 메모리를 전혀 사용하지 않는다.
퀴즈
아래 리스트를 합병 정렬 알고리즘을 이용하여 정렬하는 단계를 그래프로 표현하라.

13.4. 퀵 정렬#
퀵 정렬merge sort 또한 분할과 정복 기법을 활용한다. 하지만 합병 정렬과는 달리 분할 과정이 경우에 따라 이등분이 아닌 한쪽으로 치우치는 방식으로 진행될 수 있으며, 그렇게 되면 알고리즘이 최악의 경우 \(O(n^2)\) 시간 복잡도로 실행될 수 있다. 하지만 평균적으로 \(O(n \log n)\)의 시간복잡도를 보이며, 무엇보다도 추가 메모리를 전혀 사용하지 않기에 합병 정렬에 비해 공간 복잡도 측면에서 큰 장점을 갖는다.
퀵 정렬은 분할과 정복을 동시에 진행한다. 피벗(기준값)으로 지정된 값보다 작은 값은 피벗 왼쪽으로, 같거나 큰 값은 피벗 오른쪽으로 이동시킨다. 피벗으로 사용된 값의 위치를 기준으로 좌우 두 개의 부분 리스트로 분할한 후 동일 과정을 반복한다.
피벗 지정
피벗은 리스트의 임의의 값을 사용해도 되지만 여기서는 맨 왼편에 위치한 값을 사용한다. 경우에 따라 양끝과 중앙에 위치한 세 값의 중앙값을 사용하거나 오른쪽 맨 끝, 또는 중앙에 위치한 값 등도 사용된다. 하지만 성능 차이는 기본적으로 없으며, 입력 사례에 따라 달라진다.

분할과 정복
분할과 정복을 동시에 진행한다. 분할 과정을 통해 두 개의 보다 작은 리스트로 분할할 때 정복 과정을 동시에 진행한다. 분할 된 두 개의 리스트에 대해 동일한 과정을 반복 적용한다.
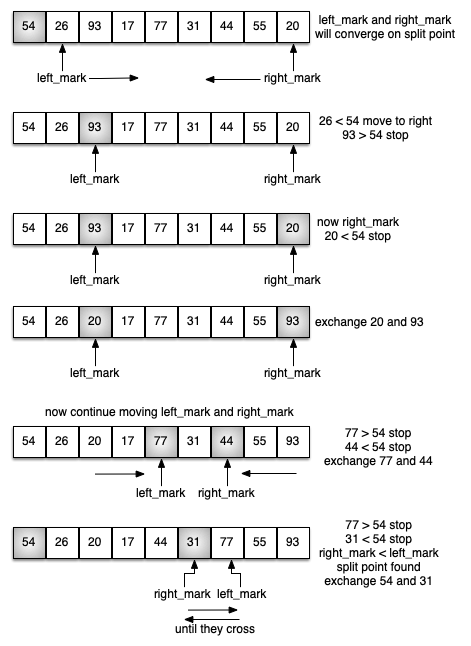
아래 partition() 함수는 주어진 리스트에 대해 분할과 정복을 수행한다.
# 분할과 정복. 피벗은 맨 왼편 항목. 반환값은 피벗의 최종 자리 위치
def partition(a_list, first, last):
pivot_val = a_list[first] # 피벗
left_mark = first + 1 # 탐색 구간 시작
right_mark = last # 탐색 구간 끝
done = False # 탐색 종료여부 확인
while not done:
while left_mark <= right_mark and a_list[left_mark] < pivot_val:
left_mark = left_mark + 1
while left_mark <= right_mark and a_list[right_mark] >= pivot_val:
right_mark = right_mark - 1
# 자리 교환
if right_mark < left_mark:
done = True
else:
a_list[left_mark], a_list[right_mark] = a_list[right_mark], a_list[left_mark]
# 피벗 자리 교환
a_list[first], a_list[right_mark] = a_list[right_mark], a_list[first]
# 피벗 위치 반환
return right_mark
재귀 적용
재귀는 partition() 함수를 재귀적으로 활용하는 방법만을 지정한다.
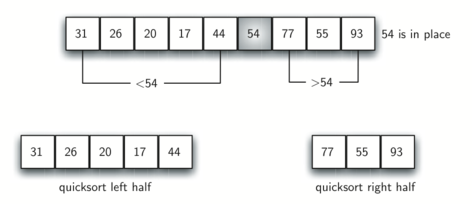
# 재귀 보조함수: 리스트의 지정된 구간에 대해 partion() 함수 재귀적으로 활용
def quick_sort_helper(a_list, first, last):
if first < last:
split = partition(a_list, first, last)
quick_sort_helper(a_list, first, split - 1)
quick_sort_helper(a_list, split + 1, last)
아래 quick_sort() 함수는 quick_sort_helper() 함수를
구간 지정과 함께 호출한다.
# 재귀 함수
def quick_sort(a_list):
quick_sort_helper(a_list, 0, len(a_list) - 1)
예제
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
퀵 정렬 시간복잡도 분석
피벗을 기준으로 분할할 때 이상적인 경우 기존의 리스트를 거의 정확하게 이등분한다. 이 경우 분할 횟수는 \(\log n\) 이다. 여기서 \(n\)은 입력 리스트의 길이를 나타낸다. 그리고 한 번 분할할 때마다 피벗과 나머지 값들이 비교되고 필요에 따라 자리교환이 발생하는데 이에 대한 시간복잡도는 \(n\) 이다. 따라서 퀵 정렬 알고리즘의 최선 시간복잡도는 \(O(n \log n)\)이다.
하지만 최악의 경우 분할이 한쪽으로 쏠리도록 이뤄질 수 있다. 예를 들어, 거의 정렬이 되어있는 리스트일 경우 피벗을 기준으로 1대 (n-1) 개의 부분 리스트로 분할될 수 있다. 이런 경우가 많이 발생하면, 즉 \(n\) 번에 가까운 분할이 필요하면 시간복잡도는 최악의 경우 \(O(n^2)\)이 나온다.
합병 정렬 대 퀵 정렬
합병 정렬이 퀵 정렬에 비해 시간복잡도 측면에서 이론적으로 좋기는 하지만 공간복잡도와 자리교환(swapping) 횟수 측면에서는 비효율적이다. 또한 퀵 정렬이 대부분의 운영체제와 프로그래밍언어에서 최적화되는 데에 용이하기에 기본 정렬 알고리즘으로 활용된다.
퀴즈
아래 리스트를 퀵 정렬 알고리즘을 이용하여 정렬하는 단계를 그래프로 표현하라.
13.5. 정렬 알고리즘 시간복잡도 비교#
1부터 100까지의 정수 중에서 무작위로 선택된 천 개의 정수들로 구성된 리스트를 대상으로 5 개의
알고리즘 실행시간을 모의실험 하려 한다.
이를 위해 먼저 조기 종료를 사용하는 버블 정렬 알고리즘과 합병 정렬 알고리즘의 이해를 위해 사용된
print() 함수를 제외한다.
그렇지 않으면 불필요한 문장이 반복해서 출력된다.
def bubble_sort_early_stop(a_list):
for a_pass in range(len(a_list) - 1, 0, -1): # 패스. 자리교환 인덱스 끝자리 지정
exchanges = False # 패스 기간 내 자리교환 발생 여부 저장
for j in range(a_pass): # 크기비교 및 자리교환
if a_list[j] > a_list[j + 1]:
a_list[j], a_list[j+1] = a_list[j + 1], a_list[j]
exchanges = True
if not exchanges: # 자리교환이 발생하지 않은 경우 조기종료
# print("조기종료!")
break
def merge_sort(a_list):
# 분할 과정: 이등분 반복
if len(a_list)>1:
# print("분할:", a_list)
mid = len(a_list) // 2
left_half = a_list[:mid]
right_half = a_list[mid:]
# 재귀 호출
merge_sort(left_half)
merge_sort(right_half)
# 합병 과정: 작은 리스트 두 개 합병하면서 정렬
merge(a_list, left_half, right_half)
# print("합병:", a_list)
from time import time
import random
random.seed(42)
size = 1000
count = 100
algorithms = [bubble_sort, bubble_sort_early_stop, selection_sort, merge_sort, quick_sort]
for algo in algorithms:
running_time = 0
for count in range(count):
random_list = [random.randrange(1, 101, 1) for _ in range(size)]
start_time = time()
algo(random_list)
end_time = time()
running_time += end_time - start_time
print(algo.__name__, running_time / count)
bubble_sort 0.022219448378591827
bubble_sort_early_stop 0.022225705944761937
selection_sort 0.01125301036638083
merge_sort 0.0008539805809656779
quick_sort 0.0005603890669973273
정리하면 다음과 같다.
조기 종료를 사용하는 버블 정렬은 조기 종료가 없는 경우보다 미세하게 느리다. 이유는
if명령문을 실행하기 때문에 조기 종료의 장점이 상쇄되는 것으로 추정된다.선택 정렬이 버블 정렬 보다 두 배 정도 빠르다.
퀵 정렬 대 합병 정렬: 퀵 정렬이 합병 정렬보다 1.5배 정도 빠르다. 일반적으로 퀵 정렬이 합병 정렬보다 평균적으로 2배 정도 빠르다고 알려져 있다.
그런데 모의실험에 사용되는 리스트의 길이를 몇 만 단위로 늘리면 퀵 정렬이 오히려 합병 정렬보다 느려진다. 이유는 파이썬에서 매우 긴 리스트를 다루는 방식의 한계때문으로 추정된다. 다른 언어에서는 다른 결과가 나올 것으로 기대한다. 예를 들어 리스트의 길이를 2만으로 할 경우의 모의실험 결과는 다음과 같다.
알고리즘 |
최선 |
평균 |
최악 |
모의실험 |
|---|---|---|---|---|
버블 정렬 |
n^2 |
n^2 |
n^2 |
9.129473 |
버블 정렬(조기 종료) |
n^2 |
n^2 |
n^2 |
9.414862 |
선택 정렬 |
n^2 |
n^2 |
n^2 |
4.365451 |
합병 정렬 |
n log n |
n log n |
n log n |
0.023475 |
퀵 정렬 |
n log n |
n log n |
n^2 |
0.056168 |