8. 차수#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
차수의 직관적 이해
\(O\), \(\Omega\), \(\Theta\) 정의
8.1. 궁극적으로 빠르다? 느리다?#
일반적으로 고차 다항식의 시간 복잡도를 갖는 알고리즘이 실행 시간 측면에서 비효율적이다. 하지만 최고차 항의 계수가 상대적으로 작으면 입력값의 크기에 따라 충분히 좋은 알고리즘으로 사용될 수 있다.
반면에 최고차 항의 계수가 아무리 작더라도 입력값의 크기가 어느 정도 이상 크면 실행시간이 많이 또는 매우 오래 걸릴 수 있다.
“입력값의 크기가 어느 정도 이상 크면 실행시간이 …. 보다 오래 걸린다” 라는 의미를 가리키는 궁극적으로 느리다/빠르다의 개념을 소개한다.
동일한 문제를 해결하는 아래 두 알고리즘 중에서 어떤 알고리즘을 선택해야 할까?
알고리즘 |
일정 시간 복잡도 |
|---|---|
A |
\(100n\) |
B |
\(0.01 n^2\) |
위 두 알고리즘의 경우 입력 크기 10,000을 기준으로 다르게 선택할 수 있다.
입력 크기 |
선택 알고리즘 |
|---|---|
|
A |
|
B |
이유는 다음과 같이, \(n\)이 1만보다 큰 경우에만 \(100 n\)이 \(0.01 n^2\) 보다 작기 때문이다.
이처럼 어떤 값 \(N\)을 기준으로 입력 크기에 따른 두 알고리즘의 실행시간이 크기가 달라질 때 “궁극적으로 느리다” 또는 “궁극적으로 빠르다” 라고 말한다. 예를 들어 알고리즘 A와 B의 경우에는 \(N=10,000\)을 사용할 수 있으며 다음 두 가지 방식으로 두 알고리즘 빠르기를 설명할 수 있다.
알고리즘 A가 알고리즘 B 보다 궁극적으로 빠르다
알고리즘 B가 알고리즘 A 보다 궁극적으로 느리다
동일한 문제를 해결하는 두 개의 알고리즘 A와 B에 대해 “누가 누구보다 궁극적으로 느리다/빠르다”를 판단하기 위해 일반적으로 차수order를 이용한다.
차수 개념 활용
알고리즘 A에 대해 다음이 성립할 때, “알고리즘 A의 시간 복잡도 함수의 차수가 \(\Theta(f(n))\) 이다” 라고 말한다:
알고리즘 A는 임의의 입력 크기 \(n\)에 대해 항상 \(f(n)\) 시간 정도 보다 빠르지도 느리지도 않게 실행한다.
차수 예제
알고리즘 분석에서 가장 많이 언급되는 차수는 다음과 같다.
기호 |
시간 복잡도 |
예제 |
|---|---|---|
\(\Theta(1)\) |
상수 복잡도 |
\(1\), \(17\), \(1000\), \(1000000\), … |
\(\Theta(n)\) |
1차 시간 복잡도 |
\(100 n\), \(0.001 n+100\), … |
\(\Theta(n^2)\) |
2차 시간 복잡도 |
\(5 n^2\), \(0.1 n^2 + n + 100\), … |
\(\Theta(n^3)\) |
3차 시간 복잡도 |
\(7 n^3\), \(n^3 + 5 n^2 + 100 n + 2\), … |
\(\Theta(\log n)\) |
로그 복잡도 |
\(\log n\), \(2 \log n\), \(\frac{1}{2} \cdot \log n+ 3\), … |
\(\Theta(n \log n)\) |
엔-로그-엔(\(n \log n\)) 복잡도 |
\(n \log n\), \(2 n \log n\), \(\frac 1 2 n \log n+ \log n + 3\), … |
앞서 언급된 시간 복잡도를 사용 효율성 측면에서 구분하면 다음과 같다.
효율성 |
알고리즘 복잡도 |
|---|---|
매우 효율적인 알고리즘 |
\(\Theta(1)\), \(\Theta(\log n)\) |
효율적인 알고리즘 |
\(\Theta(n)\), \(\Theta(n \log n)\) |
경우에 따라 괜찮은 알고리즘 |
\(\Theta(n^2)\), \(\Theta(n^3)\) |
사실상 사용 불가 알고리즘 |
\(\Theta(2^n)\), \(\Theta(n!)\) |
8.2. 차수의 정의#
차수(\(\Theta\))를 엄밀하게 정의하려면 Big-\(O\)와 \(\Omega\)(Omega, 오메가) 개념이 요구된다.
8.2.1. Big-\(O\) 표기법#
다음 성질을 갖는 양의 실수 \(c\) 와 양의 정수 \(N\) 이 존재할 때 \(g(n)\in O(f(n))\) 으로 표현한다.
알고리즘의 시간 복잡도 측면에서 볼 때 입력 크기 \(n\)에 대해 시간 복잡도 \(g(n)\)의 실행시간이 궁극적으로 \(f(n)\)보다 나쁘지는 않음을 의미한다. 즉, \(g(n)\)의 실행시간이 최악(worst)의 경우에도 \(f(n)\)의 실행시간보다는 느리지 않다.
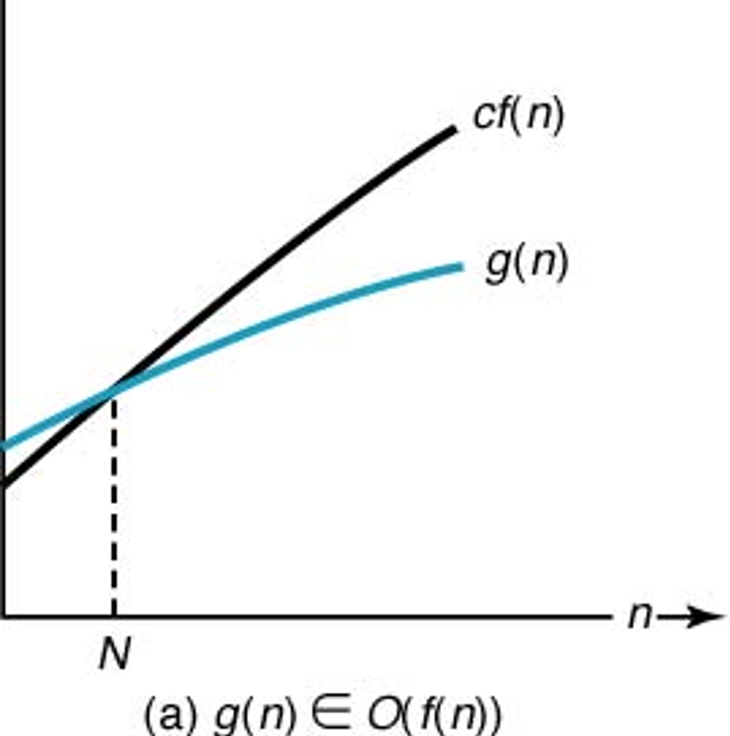
\(O(n^2)\)에 속하거나 속하지 않는 시간 복잡도 함수 몇 개를 살펴 본다.
예제 1
\(n \ge 10\)인 경우 다음 부등식이 참이다.
따라서 \(c=2\)와 \(N=10\)을 선택하면 Big-\(O\)의 정의에 의해 다음이 성립한다.
아래 그래프가 이를 잘 설명한다.
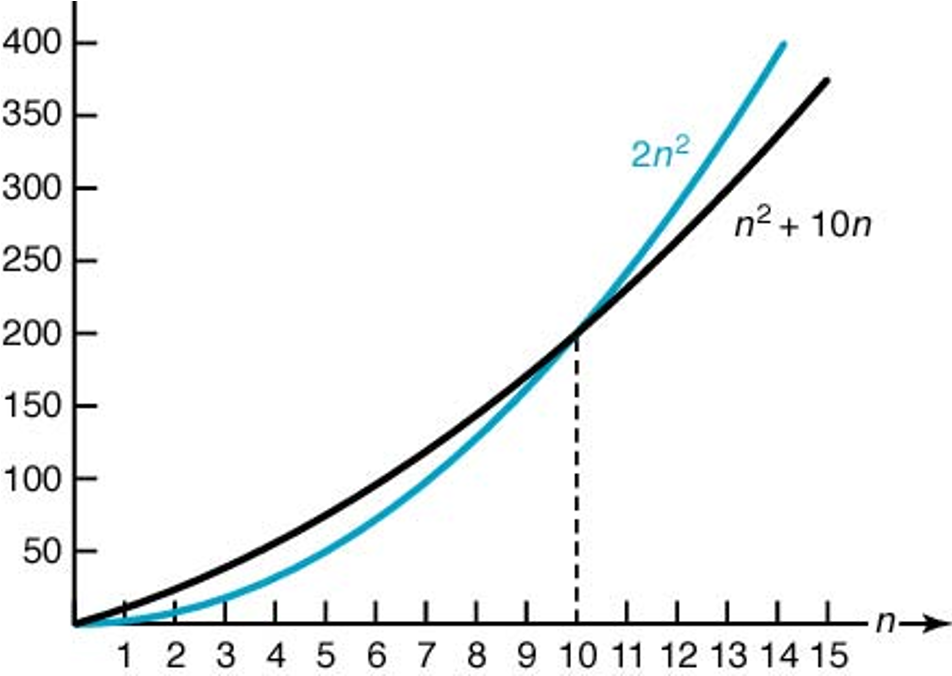
예제 2
모든 정수 \(n\)에 대해 다음 부등식이 참이다
따라서 \(c=5\)와 \(N=1\)을 선택하면 Big-\(O\)의 정의에 의해 다음이 성립한다.
예제 3
2보다 같거나 큰 임의의 양의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c = 1\)과 \(N=2\)을 선택하면 Big-\(O\)의 정의에 의해 다음이 성립한다.
예제 4
임의의 양의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c=1\)과 \(N=1\)을 선택하면 Big-\(O\)의 정의에 의해 다음이 성립한다.
예제 5
\(c\)와 \(N\)을 아무리 크게 잡더라도 \(n\)이 \(c\)보다 크면 다음 부등식이 참이다.
따라서 다음이 성립한다.
\(O(f(n))\) 에 속하는 시간 복잡도 함수는 기본적으로 \(f(n)\) 과 비슷하거나 보다 느리게 증가하는 그래프를 갖는다. 아래 그림은 \(O(n^2)\)에 속하는 시간 복잡도 함수들의 집합을 잘 묘사한다.
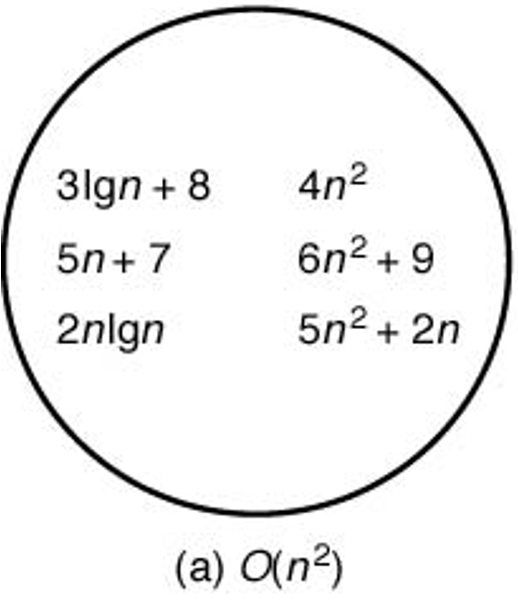
8.2.2. \(\Omega\) 표기법#
다음 성질을 갖는 양의 실수 \(c\) 와 양의 정수 \(N\) 이 존재할 때 \(g(n)\in \Omega(f(n))\) 으로 표현한다.
알고리즘의 시간 복잡도 측면에서 볼 때 입력 크기 \(n\)에 대해 시간 복잡도 \(g(n)\)의 실행시간은 궁극적으로 \(f(n)\)보다 효율적이지 못함을 의미한다. 즉, \(g(n)\)의 실행시간이 최선(best)의 경우에도 \(f(n)\)의 실행시간보다는 빠르지 않다.
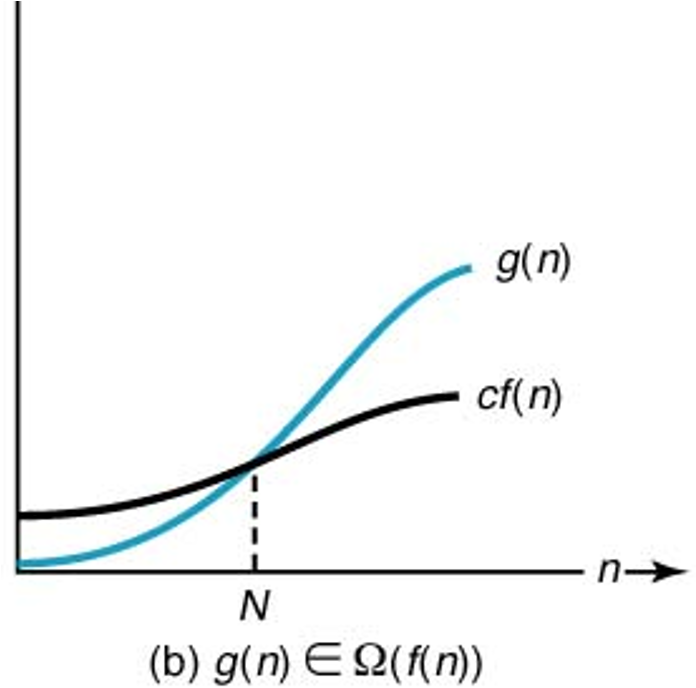
\(\Omega(n^2)\)에 속하거나 속하지 않는 시간 복잡도 함수 몇 개를 살펴 본다.
예제 6
2보다 같거나 큰 임의의 양의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c = \frac 1 4\)과 \(N=2\)을 선택하면 \(\Omega\)의 정의에 의해 다음이 성립한다.
예제 7
임의의 양의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c = 1\)과 \(N = 1\)을 선택하면 \(\Omega\)의 정의에 의해 다음이 성립한다.
예제 8
임의의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c = 1\)과 \(N = 1\)을 선택하면 \(\Omega\)의 정의에 의해 다음이 성립한다.
예제 9
임의의 양의 정수 \(n\)에 대해 다음 부등식이 참이다.
따라서 \(c = 1\)과 \(N = 1\)을 선택하면 \(\Omega\)의 정의에 의해 다음이 성립한다.
예제 10
양의 실수 \(c\)를 아무리 작게 잡더라도 \(n\) 이 \(\frac 1 c\) 보다 크면 다음 부등식이 참이다.
따라서 다음이 성립한다.
\(\Omega(f(n))\) 에 속하는 시간 복잡도 함수는 기본적으로 \(f(n)\) 과 비슷하거나 보다 빠르게 증가하는 그래프를 갖는다. 아래 그림은 \(\Omega(n^2)\)에 속하는 시간 복잡도 함수들의 집합을 잘 묘사한다.
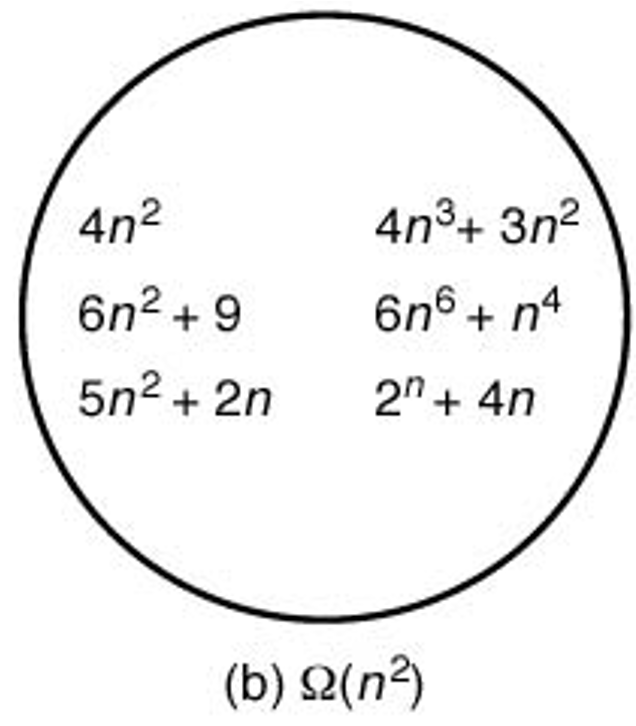
8.2.3. 차수(\(\Theta\)) 표기법#
차수(\(\Theta\))의 엄밀한 정의는 다음과 같다.
\(\Theta(f(n))\) 에 속하는 시간 복잡도 함수는 기본적으로 \(f(n)\) 과 비슷하게 증가하는 그래프를 갖는다. 아래 그림은 \(\Theta(n^2)\)에 속하는 시간 복잡도 함수들의 집합을 잘 묘사한다.
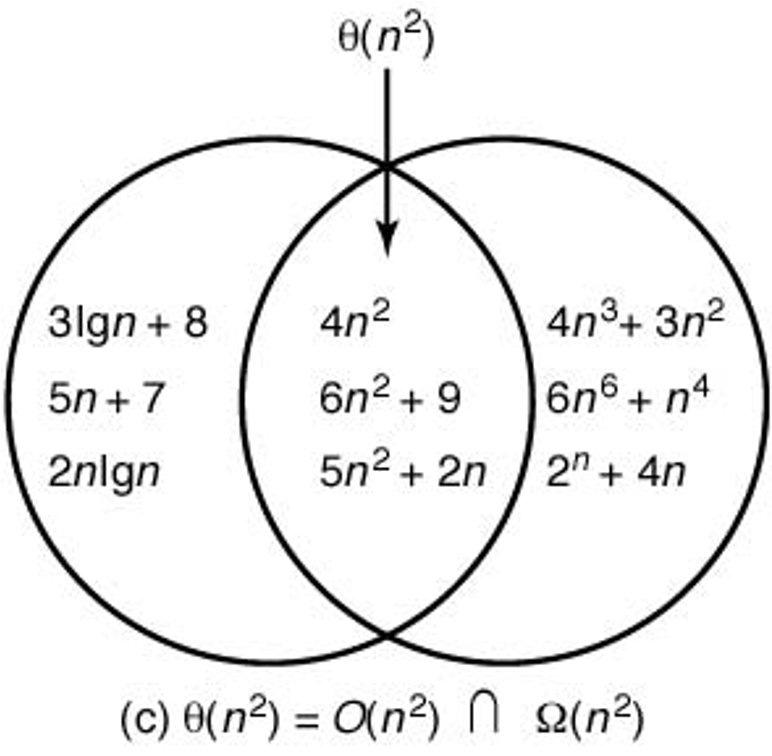
알고리즘의 시간 복잡도 측면에서 볼 때 \(\Theta(f(n))\)의 차수를 갖는 알고리즘은 입력 크기 \(n\)에 대해 최악의 경우와 최선의 경우 모두 시간 복잡도 \(f(n)\)의 실행시간보다 느리지도 않고 빠르지도 않다. 즉, 기본적으로 \(f(n)\)의 시간 내에 실행이 종료되며, 아래 그림이 이를 잘 반영한다.
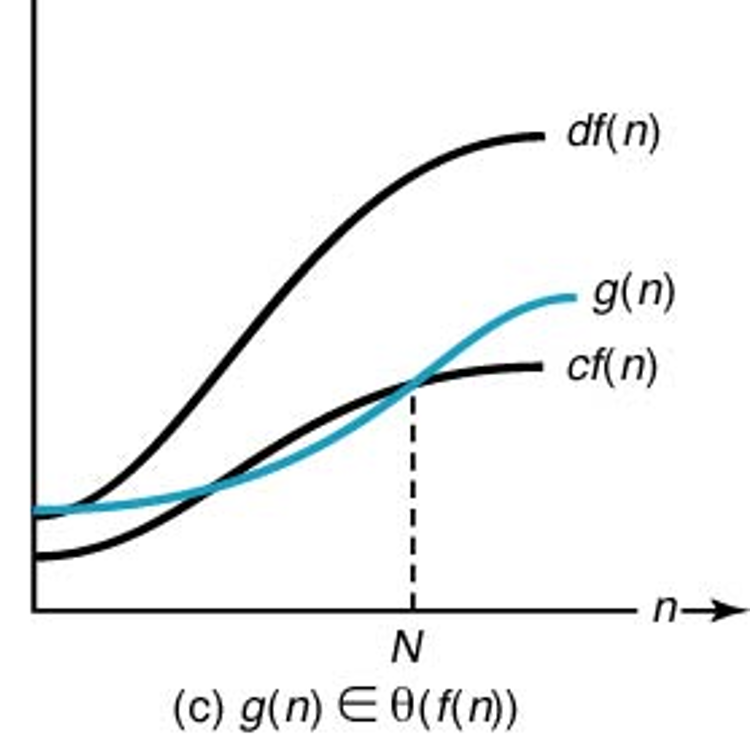
8.2.4. 차수 특성의 직관적 이해#
다음 세 가지 성질을 직관적으로 이해하고 기억해두어야 한다.
첫째, \(g(n) \in O(f(n))\) 이 성립하면 \(f(n) \in \Omega(g(n))\) 도 성립한다.
둘째, \(f(n) \in \Omega(g(n))\) 이 성립하면 \(g(n) \in O(f(n))\) 도 성립한다.
셋째, \(g(n) \in \Theta(f(n))\) 이 성립하면 \(f(n) \in \Theta(g(n))\) 도 성립한다.
로그 함수의 차수 비교
1보다 큰 임의의 양의 정수 \(a, b > 1\)에 대해 다음이 성립한다. 즉, 로그 함수는 모두 동일한 복잡도 카테고리에 속한다.
차수 카테고리 복잡도
알고리즘의 시간 복잡도와 관련해서 복잡도 순서대로 차수를 정렬하면 다음과 같다. 아래 식에서 \(2 < j < k\) 와 \(1 < a< b\)라고 가정한다.