16. 힙(Heap)#
우선순위 큐(priority queue)는 큐의 탑(top) 위치에 최대 힙(max heap)의 경우 우선순위가 가장 높은 항목이, 최소 힙(min heap)의 경우 우선순위가 가장 낮은 항목이 위치하도록 한다. 즉, (지정된 기준에 따른) 우선순위(key)에 따라 큐에 포함된 항목의 위치가 정해진다. 핵심은 항목을 큐에 추가거나 제거할 때 우선순위가 반영되도록 하는 것이다. 우선순위 큐는 특정 그래프 알고리즘에서 유용하게 활용된다.
여기서는 바이너리 힙(binary heap)을 이용하여 우선순위 큐를 구현한다. 바이너리 힙은 이진트리 형식을 따르지만 내부적으로는 리스트를 이용한다는 측면에서 매우 흥미로운 자료구조이다.
리스트에 항목을 추가한 후에 정렬하는 방식으로 우선순위 큐를 구현할 수 있다. 하지만 정렬 시간복잡도가 \(O(n \log n)\) 이기에 항목 추가에 비용이 많이 든다. 여기서는 바이너리 힙을 이용하여 항목 추가와 제거 모두 \(O(\log n)\) 시간복잡도를 갖도록 할 수 있다는 것을 보여준다.
16.1. 바이너리 힙 추상 자료형#
바이너리 힙 추상 자료형은 기본적으로 아래 기능을 제공해야 한다.
insert(k): 항목 추가get_min(): 최저 우선순위 항목 반환. 제거하지는 않음.delete(): 최저 우선순위 항목을 반환하면서 동시에 힙에서 삭제is_empty(): 힙이 비어있는지 여부 판단size(): 힙에 포함된 항목 개수 반환heapify(list): 리스트로부터 힙 생성하기
16.2. 바이너리 힙 구현#
완전 이진트리
항목의 추가와 탑 항목의 삭제를 모두 \(O(\log n)\)으로 처리하기 위해 균형 이진트리(balanece binary tree)를 활용한다. 균형 이진트리는 좌우 자식 마디의 개수가 거의 같은 이진트리이다.
여기서는 완전 이진트리(complete binary tree)를 균형 이진트리로 사용한다. 완전 이진트리는 아래 그림처럼 잎 마디를 제외는 모든 레벨의 마디가 좌우 자식 마디 모두를 갖는 이진트리이다.
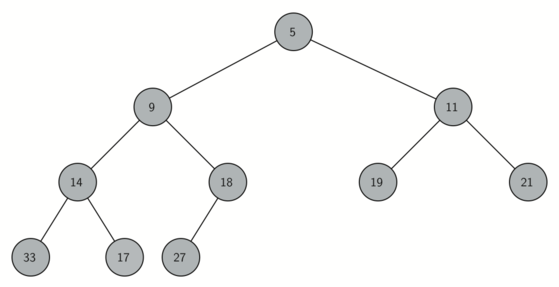
완전 이진트리의 장점은 1차원 리스트로 간단하게 구현할 수 있다는 점이다.
부모 마디의 인덱스가 p일 때, 좌우 자식 마디의 인덱스는 각각
2p + 1과 2p + 2로 사용한다.
따라서 n 번 인덱스에 위치한 마디의 부모 마디는 (n-1)//2 번 인덱스에 위치한다.
이 성질을 이용하면 바이너리 힙을 간단하게 구현할 수 있다.
바이너리 힙 특성
바이너리 힙은 부모 마디의 키(key)가 항상 자식 마디의 키보다 작은 이진트리이다. 앞서 본 완전 이진트리가 하나의 바이너리 힙이며, 1차원 리스트로 구현된 바이너리 힙의 내부 구조는 아래 그림에서와 같은 리스트와 같다.
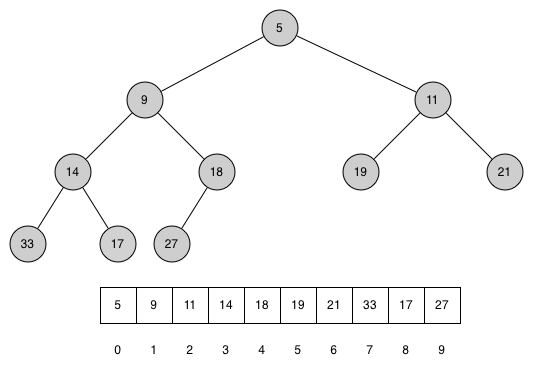
바이너리 힙 구현의 핵심은 추가되는 새로운 항목을 적절한 위치에 저장하는 것과 탑 항목을 삭제할 때 바이너리 힙 특성을 유지하는 것이다.
항목 추가: 상승 침투
아래 그림은 새로운 항목을 먼저 리스트의 맨 끝에 추가한 다음에 적절한 위치로 이동시키는 과정을 보여준다.
새로운 항목을 리스트 마지막 항목에 추가한다.
부모 마디의 키와 비교하여 보다 작으면 자리를 교환하는 상승 침투(percolation up) 과정을 가능할 때까지 반복한다.
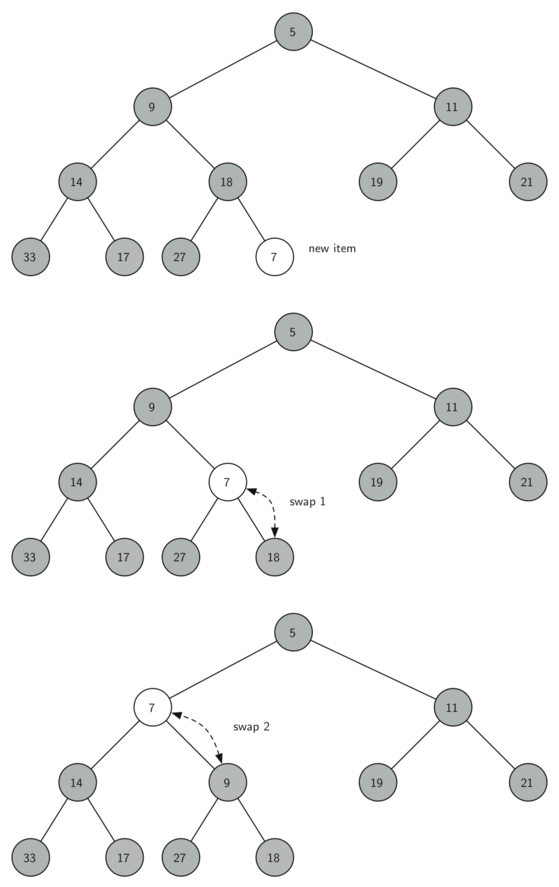
탑 항목 삭제: 하강 침투
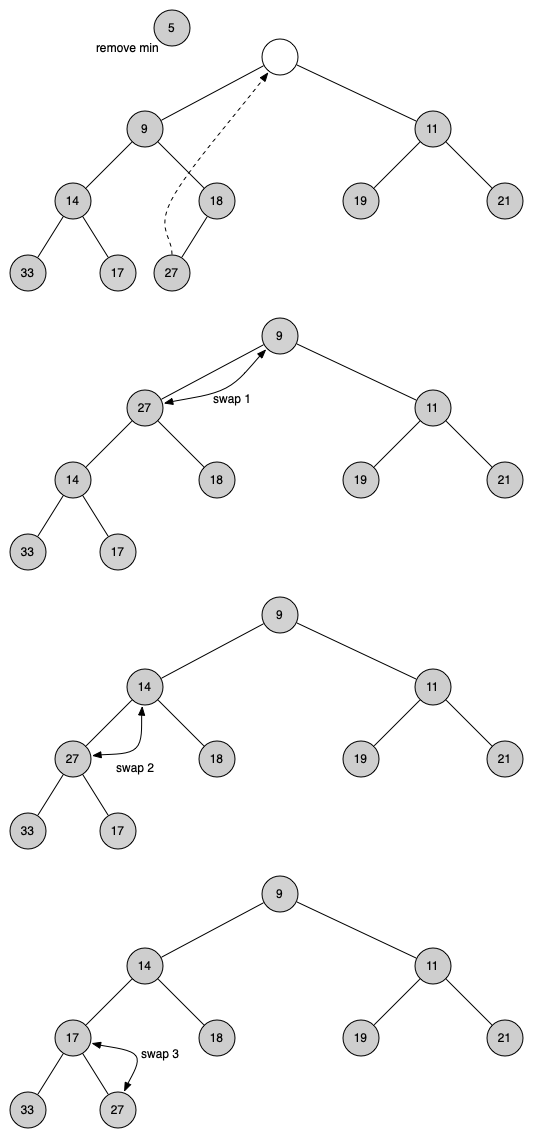
아래 그림은 탑 항목을 삭제한 후에 바이너리 힙 특성을 맞추는 과정을 보여준다.
탑 항목 삭제: 맨 마지막 항목과 탑 항목을 교환하면서 동시에 마지막 항목을 삭제한다.
탑 항목을 두 자식 마디의 키와 비교하여 보자 작은 값을 가진 자식 마디와 자리를 교환하는 하강 침투(percolation up) 과정을 가능할 때까지 반복한다.
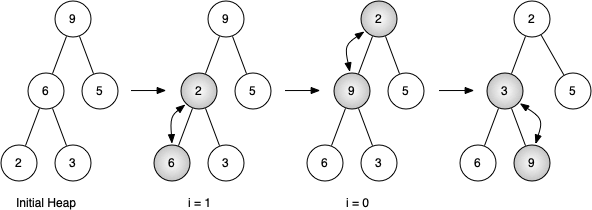
힙 생성 예제
아래 그림은 리스트로부터 힙을 생성하는 과정을 보여준다.
리스트의 마지막 항목의 부모 마디에서 시작한다.
해당 마디에 대해 하강 침투를 수행한 후 원래 마디의 왼편에 위치한 마디에 대해 동일과정을 반복한다.
지금까지 설명한 바이너리 힙의 특성을
BinaryHeap 클래스의 메서드로 구현한 결과는 다음과 같다.
class BinaryHeap:
# 생성자: 빈 리스트 활용.
def __init__(self):
self._heap = []
# 상승 침투
def _perc_up(self, cur_idx):
while (cur_idx - 1) // 2 >= 0:
parent_idx = (cur_idx - 1) // 2
if self._heap[cur_idx] < self._heap[parent_idx]:
self._heap[cur_idx], self._heap[parent_idx] = (
self._heap[parent_idx],
self._heap[cur_idx],
)
cur_idx = parent_idx
# 하강 침투
def _perc_down(self, cur_idx):
while 2 * cur_idx + 1 < len(self._heap):
min_child_idx = self._get_min_child(cur_idx)
if self._heap[cur_idx] > self._heap[min_child_idx]:
self._heap[cur_idx], self._heap[min_child_idx] = (
self._heap[min_child_idx],
self._heap[cur_idx],
)
else:
return
cur_idx = min_child_idx
# 자식 마디 중 최소 마디의 인덱스
def _get_min_child(self, parent_idx):
if 2 * parent_idx + 2 > len(self._heap) - 1:
return 2 * parent_idx + 1
if self._heap[2 * parent_idx + 1] < self._heap[2 * parent_idx + 2]:
return 2 * parent_idx + 1
return 2 * parent_idx + 2
# 리스트로부터 힙 생성
def heapify(self, not_a_heap):
self._heap = not_a_heap[:]
cur_idx = len(self._heap) // 2 - 1 # 리스트 마지막 항목의 부모 마디
while cur_idx >= 0:
self._perc_down(cur_idx)
cur_idx = cur_idx - 1
# 탑 항목 확인(최솟값)
def get_min(self):
return self._heap[0]
# 항목 추가: 상승 침투 활용
def insert(self, item):
self._heap.append(item)
self._perc_up(len(self._heap) - 1)
# 탑 항목 삭제: 하강 침투 활용
def delete(self):
self._heap[0], self._heap[-1] = self._heap[-1], self._heap[0]
result = self._heap.pop()
self._perc_down(0)
return result
# 바이너리 힙이 비어있는지 여부 판단
def is_empty(self):
return not bool(self._heap)
# 항목 개수
def __len__(self):
return len(self._heap)
# 힙 표시
def __str__(self):
return str(self._heap)
예제
리스트로부터 바이너리 힙을 생성한 후에 탑 항목을 차례대로 제거해본다.
a_heap = BinaryHeap()
a_heap.heapify([9, 6, 5, 2, 3])
while not a_heap.is_empty():
print(a_heap.delete())
2
3
5
6
9
heapify() 함수의 시간복잡도
길이가 \(n\)인 리스트로부터 바이너리 힙을 생성하는 데 걸리는 시간은 \(O(n)\)이다. 하지만 이에 대한 증명은 간단하지 않아 여기서는 다루지 않는다. 다만, 바이너리 힙의 높이가 \(\log n\)이기에 매 마디에 대해 하강 침투는 최대 \(\log n\)번 이루어진다는 사실은 기억해 두어야 한다.
16.3. 우선순위 큐 구현#
BinaryHeap 클래스를 상속하여 PriorityQueue 클래스를 간단하게 구현한다.
class PriotiryQueue(BinaryHeap):
# 생성자: 빈 리스트 활용.
def __init__(self):
super().__init__()
def __repr__(self):
"""큐 표기법: <<[1, 2, 3]>> 등등"""
return self.__str__()
def is_empty(self):
"""비었는지 여부 확인"""
return not bool(self._heap)
def enqueue(self, item):
"""꼬리에 항목 추가"""
self.insert(item)
def dequeue(self):
"""머리 항목 삭제"""
return self.delete()
def size(self):
"""항목 개수 확인"""
return len(self._heap)
a_pQue = PriotiryQueue()
a_pQue.heapify([9, 6, 5, 2, 3])
print(a_pQue)
[2, 3, 5, 6, 9]
a_pQue.enqueue(7)
a_pQue
[2, 3, 5, 6, 9, 7]
a_pQue.enqueue(4)
a_pQue
[2, 3, 4, 6, 9, 7, 5]
a_pQue.dequeue()
2
a_pQue
[3, 5, 4, 6, 9, 7]
a_pQue.dequeue()
3
a_pQue
[4, 5, 7, 6, 9]
연습문제
정수들의 리스트를 임의로 생성한 후에 리스트의 원소들을 순서대로 하나씩 바이너리 힙에 추가한 결과를 트리 모양으로 그려라.
이전 문제에서 생성된 바이너리 힙과 사용된 리스트를
heapify()함수의 인자로 활용하여 생성된 바이너리 힙을 비교하는 그림을 그려라.[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]에 포함된 항목을 차례대로 하나씩 바이너리 힙에 추가한 결과를 그려라.[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]에 포함된 항목을 차례대로 하나씩 바이너리 힙에 추가한 결과를 그려라.
16.4. 프로그래밍 실습 과제#
heapify()메서드를 활용하여 \(O(n\log{n})\)의 시간복잡도를 갖는 정렬 알고리즘을 구현하라.n개의 중요한 항목만 저장하는 바이너리 힙을 구현하라. 즉, 바이너리 힙의 크기가n보다 커지면 새로운 항목이 추가될 때 중요도가 가장 떨어지는 항목을 먼저 삭제한다.최대 힙(max heap)으로 바이너리 힙을 구현하라.