1. 한눈에 보는 머신러닝#
감사의 글
자료를 공개한 저자 오렐리앙 제롱과 강의자료를 지원한 한빛아카데미에게 진심어린 감사를 전합니다.
소스코드
본문 내용의 일부를 파이썬으로 구현한 내용은 (구글코랩) 한눈에 보는 머신러닝에서 확인할 수 있다.
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
1.1. 머신러닝이란?#
아서 새뮤얼Artuhr Samuel (1959)
컴퓨터 프로그램을 명시적으로 구현하는 대신 컴퓨터 스스로 학습하는 능력를 갖도록 하는 연구 분야
1.2. 머신러닝 활용#
1.2.1. 전통적 프로그래밍#
전통적 프로그래밍 다음 과정으로 진행된다.
문제 연구: 문제 해결 알고리즘 연구
규칙 작성: 알고리즘 규현
평가: 구현된 프로그램 테스트
테스트 통과: 프로그램 론칭
테스트 실패: 오차 분석 후 1 단계로 이동

예를 들어 전통적 프로그래밍 방식으로 구현된 스팸 메일 분류기는 특정 단어가 들어가면 스팸으로 처리한다. 그런데 프로그램이 론칭된 후 새로운 스팸단어가 사용되면 스팸 메일 분류가 실패한다. 따라서 개발자가 새로운 규칙을 매번 업데이트 시켜줘야 하기에 유지 보수가 매우 어렵다.
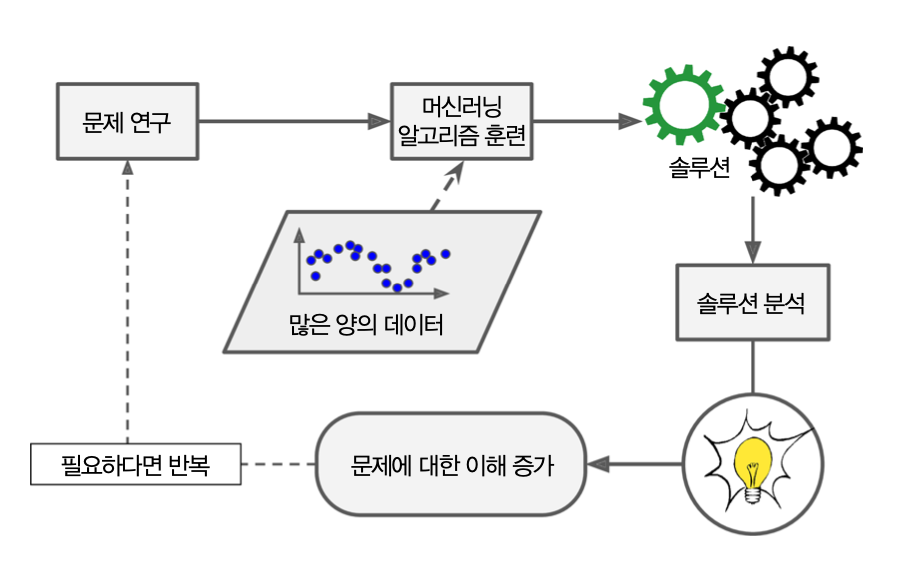
1.2.2. 머신러닝 프로그래밍#
스팸으로 지정된 메일에 “광고”, “투^^자”, “무❤료” 등의 표현이 자주 등장하는 경우 새로운 메일에 그런 표현이 사용되면 자동으로 스팸으로 분류하도록 스스로 학습하는 프로그램을 작성한다.

스팸 메일과 아닌 메일의 구분법을 머신러닝 모델로 학습시킬 수 있다. 이때 사용되는 머신러닝 모델은 훈련셋, 즉 훈련용 데이터셋에 포함된 데이터 샘플을 학습하여 새로운 메일의 스팸 여부를 잘 판단하도록 학습된다.
머신러닝 프로그램 학습 과정의 자동화
머신러닝 프로그램을 학습시키는 과정을 관장하는 머신러닝 파이프라인 또는 MLOps(Machine Learning Operations, 머신러닝 운영) 의 자동화가 가능하다.

머신러닝 프로그래밍의 장점
스팸 메일 분류기 처럼 알고리즘에 대한 너무 많은 세부 튜닝과 매우 긴 규칙을 요구하는 문제를 해결할 수 있다.
음성 인식 등 전통적인 방식으로 해결하기에 너무 복잡한 문제를 해결할 수 있다.
새로운 데이터에 바로 적용이 가능한 시스템을 쉽게 재훈련할 수 있다.
머신러닝 프로그램으로 생성된 솔루션 분석을 통해 데이터에 대한 통찰을 얻을 수 있다.
1.3. 머신러닝 시스템 유형#
머신러닝 시스템의 유형을 다양한 기준으로 분류할 수 있다.
훈련 지도 여부
지도 학습
비지도 학습
준지도 학습
자기주도 학습
강화 학습
실시간 훈련 여부
배치 학습
온라인 학습
예측 모델 사용 여부
사례 기반 학습
모델 기반 학습
언급된 분류 기준이 상호 배타적이지 않다. 예를 들어, 신경망을 활용하는 스팸 필터 프로그램은 아래 언급된 방식을 모두 사용할 수 있다.
지도 학습: 스팸 메일과 스팸이 아닌 메일로 이루어진 훈련셋으로 모델 학습 진행
온라인 학습: 실시간 학습 가능
모델 기반 학습: 훈련 결과로 생성된 모델을 이용하여 스팸 여부 판단
1.4. 머신러닝 모델 훈련의 어려움#
머신러닝 모델을 훈련할 때 경험할 수 있는 어려운 점들을 살펴본다. 기본적으로 훈련에 사용되는 훈련 데이터 또는 훈련 알고리즘 둘 중에 하나에 기인한다.
데이터 문제
충분치 않은 양의 훈련 데이터: 머신러닝 알고리즘을 제대로 학습시키려면 많은 양의 데이터가 필요하다. 이미지 분류, 자연어 처리 등의 문제는 수백, 수천만, 수억, 수십억 개가 필요할 수도 있다.
대표성 없는 훈련 데이터: 편향되거나 잘못 측정된 노이즈noise 등 머신러닝 알고리즘에 나쁜 영향을 미치는 데이터가 포함될 수 있다.
특성 공학: 해결하는 문제에 관련이 높은 데이터의 특성을 파악해야 한다.
알고리즘 문제
과대 적합: 모델이 훈련 과정에서 훈련셋에 특화되어 실전에서의 성능이 떨어지는 현상
과소 적합: 훈련되는 모델이 과제를 해결하기에 적절하지 못해서 훈련 성능이 않좋은 현상
1.5. 예제: 삶의 만족도 예측 선형 모델#
데이터셋
OECD(경제협력개발기구) 국가의 1인당 GDP(국내 총생산)와 삶의 만족도 사이의 관계를 확인한다. 여기서는 2015년 기준으로 OECD에 속한 36개 국가의 데이터를 이용한다. 아래 표는 그중 5개 국가의 1인당 GDP와 삶의 만족도를 보여준다.
Country |
GDP percapita |
Life satisfaction |
|---|---|---|
Hungary |
12239.894 |
4.9 |
Korea |
27195.197 |
5.8 |
France |
37675.006 |
6.5 |
Austrailia |
50961.865 |
7.3 |
United States |
55805.204 |
7.2 |
머신러닝 모델을 훈련시킬 때 발생할 수 있는 과대적합 문제를 설명하기 위해 고의로 7개 국가의 데이터를 데이터 셋에서 제외시키고 훈련 시킬 때와 그렇지 않을 때를 비교한다.
제외 대상 국가는 브라질, 멕시코, 칠레, 체코, 노르웨이, 스위스, 룩셈부르크 이다. 아래 그래프는 36개 국가 중에서 언급된 7개을 제외한 29개 국가를 대상으로 1인당 GDP와 삶의 만족도를 이용한 산점도scatter plot이다. 1인당 GDP가 증가할 수록 삶의 만족도가 선형적linear으로 증가하는 것처럼 보인다.

선형 모델 훈련
위 가정을 바탕으로 1인당 GDP가 알려진 국가의 삶의 만족도를 예측하는 머신러닝 모델을 구현한다. 여기서는 1인당 GDP와 삶의 만족도 사이의 관계를 설명하는 예제 모델로 선형 회귀 모델linear regression model을 선택한다.
선형 회귀 모델은 아래 모양의 일차 방정식을 이용하여 1인당 GDP가 주어졌을 때 해당 국가의 삶의 만족도를 예측하게 된다.
아래 이미지는 세 개의 적절하지 않은 선형 회귀 모델을 보여준다.

선형 회귀 모델은 1인당 GDP가 주어졌을 때 해당 국가의 삶의 만족도를 아래 그림에서처럼 최대한 정확하게 계산하는 최선의 \(\theta_0\)와 \(\theta_1\)를 주어진 훈련셋을 대상으로 반복된 훈련을 통해 찾아낸다. 아래 그림은 제대로 훈련된 선형 회귀 모델이 찾아낸 직선을 보여준다.

데이터 문제
머신러닝 알고리즘을 훈련시키다보면 다양한 어려움에 부딪힌다. 여기서는 선형 회귀 모델이 훈련셋에 민감하게 반응하는 것을 보인다. 앞서 제외시킨 7개 국가의 데이터를 포함해서 선형 회귀 모델을 훈련시켜 보자. 제외된 7개 국가의 데이터는 다음과 같다.
Country |
GDP percapita |
Life satisfaction |
|---|---|---|
Brazil |
8669.998 |
7.0 |
Mexico |
9009.280 |
6.7 |
Chile |
13340.905 |
6.7 |
Czech Republic |
17256.918 |
6.5 |
Norway |
74822.106 |
7.4 |
Switzerland |
80675.308 |
7.5 |
Luxembourg |
101994.093 |
6.9 |
위 7개 국가를 포함해서 모두 36개 국가를 대상으로 선형 회귀 모델을 훈련시키면 아래 그림에서 검은 직선에 해당하는 기울기와 절편을 7개 국가를 제외한 경우와는 많이 다르게 찾아낸다.

결론적으로 7개 국가를 포함하는 경우와 그렇지 않은 경우 상당히 다른 선형 회귀 모델이 훈련된다. 즉, 모델 훈련이 훈련 데이터 셋에 민감하게 반응하는 과대 적합 현상이 발생한다. 이런 의미에서 선형 회귀 모델은 1인당 GDP와 삶의 만족도 사이의 관계를 모델링 하기에 부적절하다고 말할 수 있다.
1.6. 연습문제#
참고: (실습) 한눈에 보는 머신러닝