6. 앙상블 학습과 랜덤 포레스트#
감사의 글
자료를 공개한 저자 오렐리앙 제롱과 강의자료를 지원한 한빛아카데미에게 진심어린 감사를 전합니다.
소스코드
본문에 소개된 코드는 (구글코랩) 앙상블 학습과 랜덤 포레스트에서 직접 실행할 수 있다.
슬라이드
본문 내용을 요약한 슬라이드 1부, 슬라이드 2부를 다운로드할 수 있다.
소개
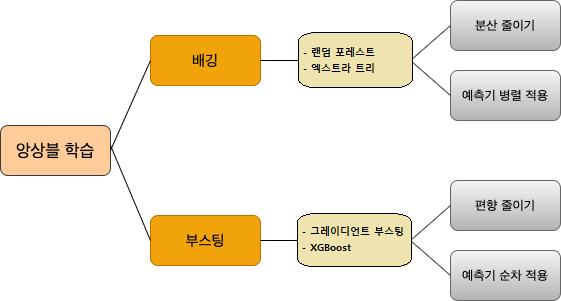
앙상블 학습ensemble learning은 여러 개의 모델을 훈련시킨 결과를 이용하여 기법이며, 대표적으로 배깅bagging 기법과 부스팅boosting 기법이 있다.
배깅 기법: 여러 개의 예측기를 (가능한한) 독립적으로 학습시킨 후 모든 예측기들의 예측값들의 평균값을 최종 모델의 예측값으로 사용한다. 분산이 보다 줄어든 모델을 구현한다.
부스팅 기법: 여러 개의 예측기를 순차적으로 훈련시킨 결과를 예측값으로 사용한다. 보다 적은 편향를 갖는 모델을 구현한다.
캐글Kaggle 경진대회에서 가장 좋은 성능을 내는 3 개의 모델은 다음과 같이 모두 앙상블 학습 모델이다.
XGBoost
랜덤 포레스트
그레이디언트 부스팅
앙상블 학습 모델은 특히 엑셀의 표table 형식으로 저장될 수 있는 정형 데이터structured data의 분석에 유용한다.
반면에 이미지, 오디오, 동영상, 자연어 등 비정형 데이터unstructured data에 대한 분석은 지금은 딥러닝 기법이 훨씬 좋은 성능을 보인다. 그럼에도 불구하고 앙상블 학습 기법을 딥러닝 모델에 적용하여 모델의 성능 최대한 끌어 올리기도 한다.
아래 그림은 165 개의 데이터셋에 14개의 앙상블 학습 모델을 훈련시켰을 때 각각의 모델이 다른 모델에 비해 보다 좋은 성능을 보인 횟수를 측정한 결과를 요약한다.
XGBoost, Gradient Boosting, Extra Trees, Random Forest, … 등의 순서로 성능 좋음.
예제: XGBoost와 Random Forest 모델 비교
XGBoost: 48 개의 데이터셋에서 우세
Random Forest: 16 개의 데이터셋에서 우세
나머지 101 개의 데이터셋에 대해서는 동등

앙상블 학습 모델의 성능 비교에 대한 보다 자세한 내용은 아래 논문을 참고한다.
R.S. Olson 외, Data-driven Advice for Applying Machine Learning to Bioinformatics Problems, 2018.
편향과 분산의 트레이드오프
앙상블 학습의 핵심은 편향bias과 분산variance을 최소화한 모델을 구현하는 것이다.
편향: 예측값과 정답이 떨어져 있는 정도를 나타낸다. 정답에 대한 잘못된 가정으로부터 유발되며 편향이 크면 과소적합이 발생한다.
분산: 입력 샘플의 작은 변동에 반응하는 정도를 나타낸다. 일반적으로 모델을 복잡하게 설정할 수록 분산이 커지며, 따라서 과대적합이 발생한다.
그런데 편향과 분산을 동시에 줄일 수 없다. 이유는 편향과 분산은 서로 트레이드오프 관계를 갖기 때문이다. 예를 들어 회귀 모델의 평균 제곱 오차(MSE)는 편향을 제곱한 값과 분산의 합으로 근사되는데, 회귀 모델의 복잡도에 따른 편향, 분산, 평균 제곱 오차 사이의 관계를 그래프로 나타내면 보통 다음과 같다.
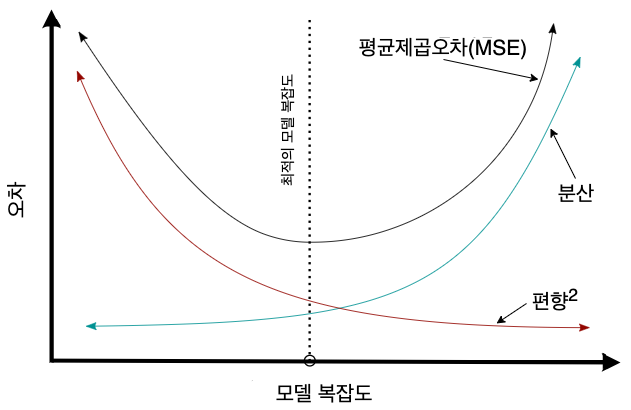
평균 제곱 오차, 편향, 분산의 관계
Bias, Variance, and MSE of Estimators 에서 평균 제곱 오차, 분산, 편향 사이의 다음 수학적 관계를 잘 설명한다.
6.1. 투표식 분류기#
동일한 훈련 세트에 대해 여러 종류의 분류 모델을 이용한 앙상블 학습을 진행한 후에 직접 또는 간접 투표를 통해 예측값을 결정한다.
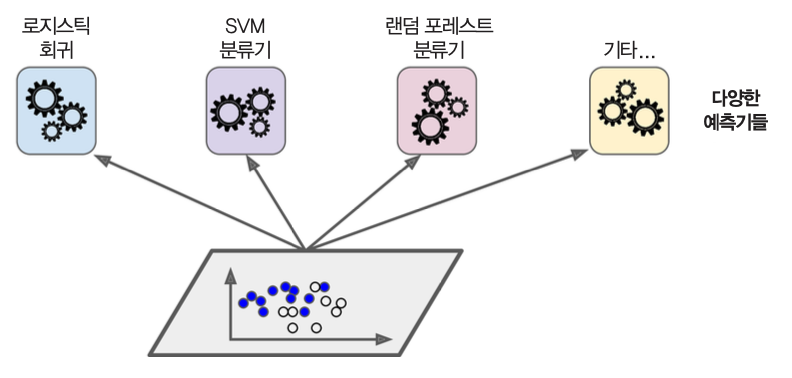
직접 투표
앙상블 학습에 사용된 예측기들의 예측값들 중에서 다수결 방식으로 예측하면 각각의 예측기보다 좋은 성능의 모델을 얻는다.
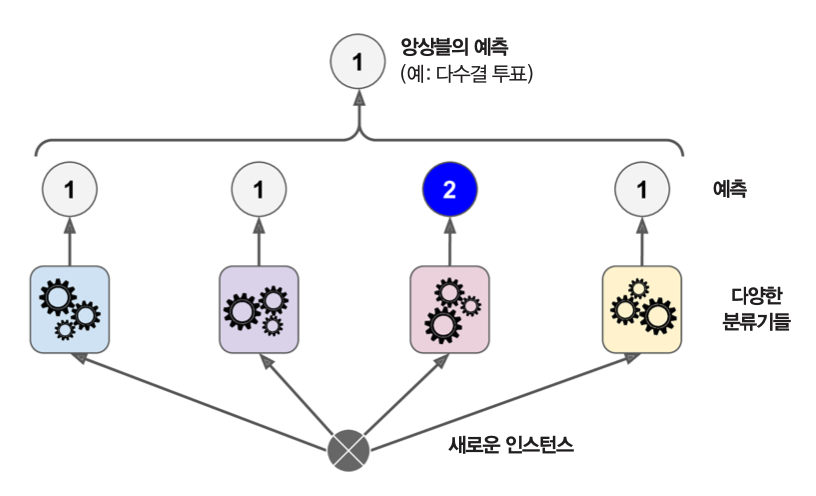
간접 투표
앙상블 학습에 사용된 예측기들의 예측한 확률값들의 평균값으로 예측값 결정한다.
이를 위해서는 사용되는 모든 분류기가 predict_proba() 메서드처럼 확률을 예측하는 기능을 지원해야 한다.
높은 확률의 비중을 크게 잡기 때문에 직접 투표 방식보다 일반적으로 성능이 좀 더 좋다.
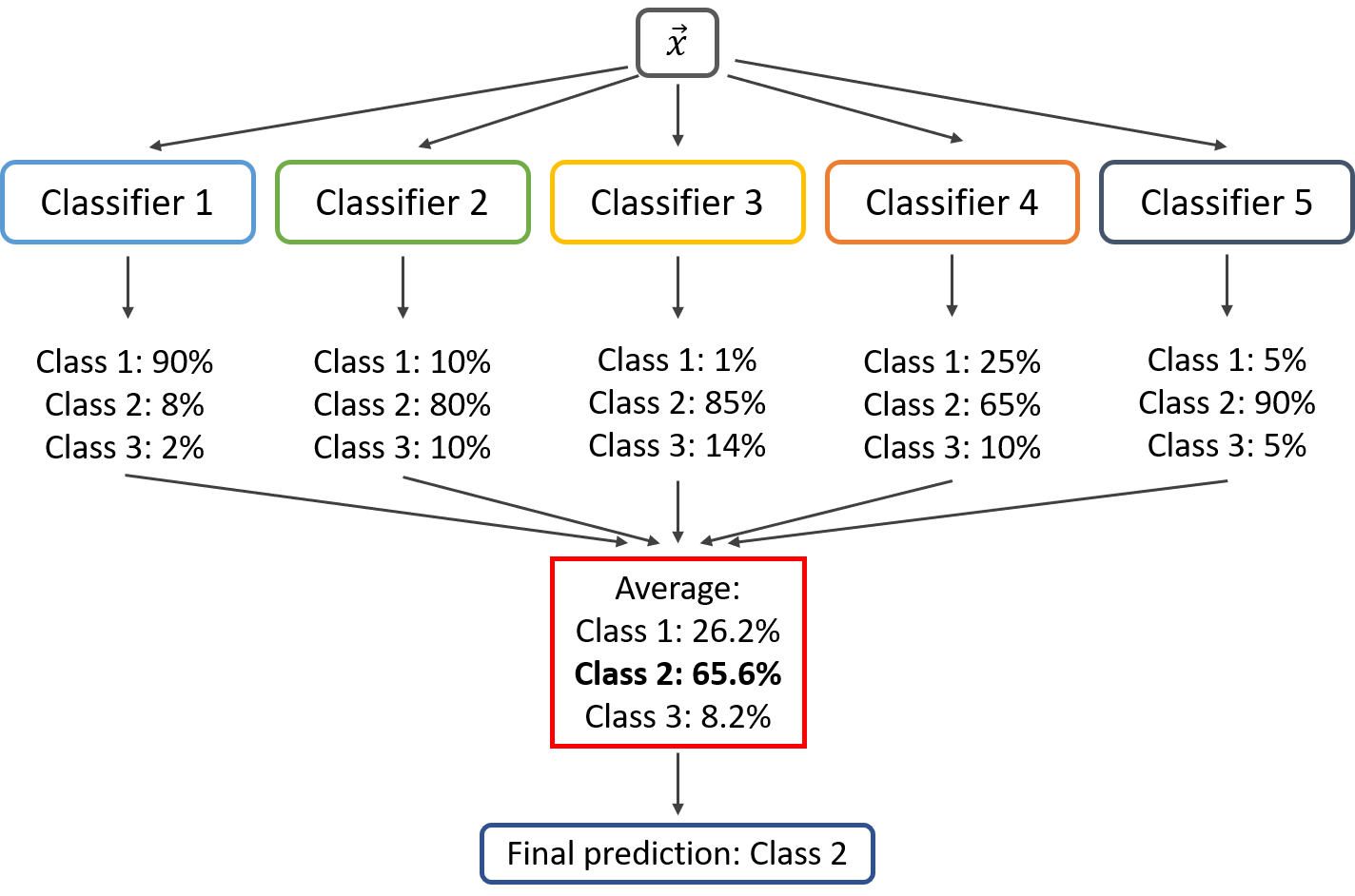
직접 투표 대 간접 투표
분류기 다섯개의 예측확률이 아래와 같은 경우 직접 투표 방시과 간접 투표 방식의 결과가 다르다.
분류기 |
클래스1 예측 확률 |
클래스2 예측 확률 |
클래스3 예측 확률 |
|---|---|---|---|
분류기1 |
90% |
8% |
2% |
분류기2 |
40% |
7% |
53% |
분류기3 |
45% |
9% |
46% |
분류기4 |
30% |
20% |
50% |
분류기5 |
44% |
16% |
40% |
합 |
249% |
60% |
191% |
직접 투표: 클래스 3으로 예측
간접 투표: 클래스 1로 예측
사이킷런의 투표식 분류기: VotingClassifier, VotingRegressor
voting='hard'또는voting='soft': 직접 또는 간접 투표 방식 지정 하이퍼파라미터. 기본값은'hard'.주의:
SVC모델 지정할 때probability=True사용해야predict_proba()메서드 지원됨.
voting_clf = VotingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(random_state=42))
]
)
투표식 분류 성능 향상의 확률적 근거
이항분포의 누적 분포 함수cumulative distribution function(cdf)를 이용하여 앙상블 학습의 성능이 향상되는 이유를 설명할 수 있다. 누적 분포 함수는 주어진 확률 변수가 특정 값보다 같거나 작은 값을 가질 확률을 계산한다.
아래 코드에서 binom.cdf(int(n*0.4999), n, p)는 p의 확률로
문제를 맞추는 예측기 n 개를 이용하여 다수결에 따라 예측을 했을 때
성공할 확률을 계산한다.
from scipy.stats import binom
def ensemble_win_proba(n, p):
"""
p: 예측기 성능. 즉, 예측값이 맞을 확률
n: 앙상블 크기, 즉 하나의 예측기를 독립적으로 사용한 횟수.
반환값: 다수결을 따를 때 성공할 확률. 이항 분포의 누적분포함수의 반환값.
"""
return 1 - binom.cdf(int(n*0.4999), n, p)
함수 설명
binom.cdf(int(n*0.4999), n, p)는 p의 확률로 정답을 맞추는 예측기를 n번
독립적으로 실행했을 때 n/2번 미만으로 정답을 맞출 확률을 계산한다.
따라서 ensemble_win_proba(n, p)는 과반 이상으로 정답을 맞출 확률이 된다.
즉, 동일한 예측기를 n번 실행했을 때 과반을 넘긴 정답을 선택했을 때
실제로 정답일 확률을 계산한다.
예제
적중률 51% 모델 1,000개의 다수결을 따르면 74.7% 정도의 적중률 나옴.
>>> ensemble_win_proba(1000, 0.51)
0.7467502275561786
적중률 51% 모델 10,000개의 다수결을 따르면 97.8% 정도의 적중률 나옴.
>>> ensemble_win_proba(10000, 0.51)
0.9777976478701533
적중률 80% 모델 10개의 다수결을 따르면 100%에 가까운 성능이 가능함.
>>> ensemble_win_proba(10, 0.8)
0.9936306176
위 결과는 앙상블 학습에 포함된 각각의 모델이 서로 독립인 것을 전제로한 결과이다. 만약에 훈련에 동일한 데이터를 사용하면 모델 사이의 독립성이 완전히 보장되지 않으며, 경우에 따라 오히려 성능이 하락할 수 있다. 모델들의 독립성을 높이기 위해 매우 다른 알고리즘을 사용하는 다른 종류의 모델을 사용할 수도 있다.
6.2. 배깅과 페이스팅#
배깅 기법은 하나의 훈련 세트의 다양한 부분집합을 이용하여 동일한 모델 여러 개를 학습시키는 방식이다. 부분집합을 임의로 선택할 때의 중복 허용 여부에 따라 앙상블 학습 방식이 달라진다.
배깅bagging: 중복을 허용하며 부분집합 샘플링(부분집합 선택)
페이스팅pasting: 중복을 허용하지 않으면서 부분집합 샘플링(부분집합 선택)
배깅과 부트스트랩
배깅은 bootstrap aggregation의 줄임말이며, 부트스트랩bootstrap은 전문 통계 용어로 중복 허용 리샘플링을 가리킨다.
아래 그림은 하나의 훈련셋으로 동일한 예측기 네 개를 훈련시키는 내용을 보여준다. 훈련셋으로 사용되는 각각의 부분집합이 중복을 허용하는 방식, 즉 배깅 방식으로 지정되는 것을 그림이 잘 보여준다.
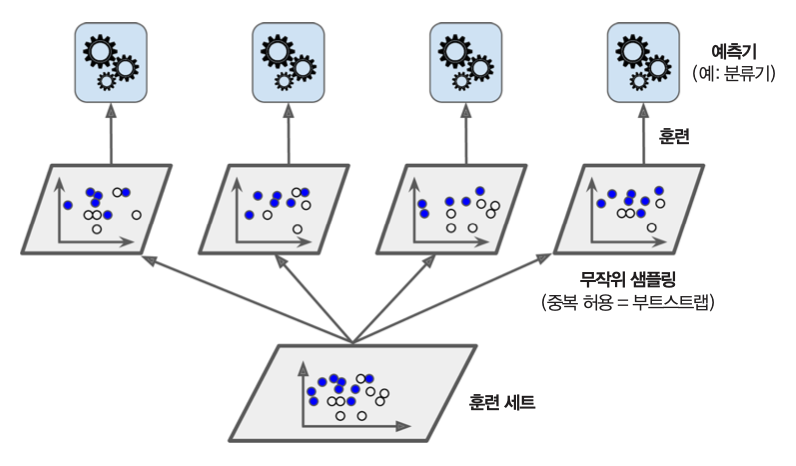
예측값
배깅 또는 페이스팅 방식으로 훈련된 모델의 예측값은, 분류기인 경우엔 최빈 예측값mode을, 회귀인 경우엔 예측값들의 평균값mean을 사용한다.
병렬 훈련 및 예측
배깅/페이스팅 기법은 각 모델의 훈련과 예측을 병렬로 다룰 수 있다. 즉, 다른 CPU 또는 심지어 다른 컴퓨터 서버를 이용하여 각 모델을 훈련 또는 예측을 하게 만든 후 그 결과를 병합하여 하나의 예측값을 생성할 수 있다.
편향과 분산
개별 예측기의 경우에 비해 배깅 방식으로 학습된 앙상블 모델의 편향은 비슷하거나 조금 커지는 반면에 분산은 줄어든다. 분산이 줄어드는 이유는 배깅 방식이 표본 샘플링의 다양성을 키우기 때문이다. 또한 배깅 방식이 페이스팅 방식보다 과대적합의 위험성을 잘 줄어주며, 따라서 보다 선호된다. 보다 자세한 설명은 Single estimator versus bagging: bias-variance decomposition 을 참고한다.
6.2.1. 사이킷런의 배깅과 페이스팅#
사이킷런은 분류 모델인 BaggingClassifier와 회귀 모델인 BaggingRegressor을 지원한다.
아래 코드에서 사용된 분류 모델의 하이퍼파라미터는 다음과 같다.
n_estimators=500: 500 개의DecisionTreeClassifier모델을 이용항 앙상블 학습.max_samples=100: 각각의 모델을 100 개의 훈련 샘플을 이용하여 훈련.
이외에 아래 옵션이 기본으로 사용된다.
n_jobs=None: 하이퍼파라미터를 이용하여 사용할 CPU 수 지정.None은 1을 의미함. -1로 지정하면 모든 CPU를 사용함.bootstrap=True: 배깅 방식. 페이스팅 방식을 사용하려면bootstrap=False로 지정.oob_score=False: oob 평가 진행 여부.bootstrap=True인 경우에만 설정 가능.
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=100, random_state=42)
모델의 예측값은 기본적으로 간전 투표 방식을 사용한다.
하지만 기본 예측기가 predict_proba() 메서드를 지원하지 않으면
직접 투표 방식을 사용한다.
위 코드에서는 결정트리가 predict_proba() 메서드를 지원하기에 간접 투표 방식을 사용하게 된다.
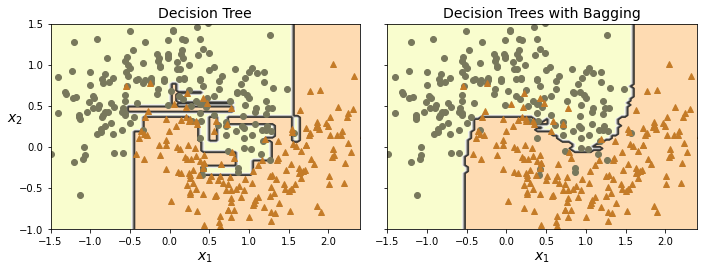
아래 두 그림은 한 개의 결정트리 모델의 훈련 결과와 500개의 결정트리 모델을 배깅 기법으로 훈련시킨 결과의 차이를 보여준다. 훈련셋으로 초승달 데이터셋moons dataset이 사용되었다.
왼쪽 그림은 규제를 전혀 사용하지 않아 훈련셋에 과대적합된 결정트리 모델을 보여준다.
반면에 오른쪽 그림은 규제 max_samples=100를 사용하는 결정트리 500개에
배깅 기법을 적용하여 훈련시킨 보다 높은 일반화 성능의 모델의 보여준다.
하나의 결정트리 모델과 비교해서 편향(오류 숫자)은 좀 더 커졌지만
분산(결정 경계의 불규칙성)은 훨씬 덜하다.
6.2.2. oob 평가#
배깅 기법을 적용하면 하나의 모델 훈련에 선택되지 않은 훈련 샘플이 평균적으로 전체 훈련셋의 37% 정도를 차지한다. 이런 샘플을 oob(out-of-bag) 샘플이라 부른다. oob 평가는 각각의 샘플에 대해 해당 샘플을 훈련에 사용하지 않은 모델들의 예측값을 이용하여 앙상블 학습 모델을 검증하는 기법이다.
oob 샘플의 비율: 약 37%
훈련셋의 크기가 \(m\)이라고 할 때, 훈련셋에 포함된 각 샘플에 대해 해당 샘플이 선택되지 않을 확률은 \((1- 1/m)\) 이다. 따라서 중복을 허용하면서 \(m\) 개의 샘플을 뽑을 때 각 샘플에 대해 해당 샘플이 뽑히지 않을 확률은 \((1 - 1/m)^m\) 이다. 그리고 \(m\) 이 충분히 크면 이값은 0.367879에 가까워진다. 따라서 약 37% 정도는 배깅 훈련에 사용되지 않는다.
참고: \(m\)이 충분히 크면 \((1 - 1/m)^m\) 는 \(\exp(-1) \simeq 0.367879\) 에 가까워진다. 이유는 \((1 + x/m)^m\)이 \(m\) 이 커질 수록 \(\exp(x)\) 값에 수렴하기 때문이다.
6 개의 훈련 샘플로 구성된 훈련셋 대해 5개의 결정트리 모델을 배깅 기법으로 적용할 때 예를 들어 아래 표와 같은 경우가 발생할 수 있다. 표에 사용된 정수는 중복으로 뽑힌 횟수를 가리키며, 각 샘플은 위치 인덱스로 구분한다.
훈련 샘플(총 6개) |
OOB 평가 샘플 |
|
|---|---|---|
결정트리1 |
1, 1, 0, 2, 1, 1 |
2번 |
결정트리2 |
3, 0, 1, 0, 2, 0 |
1번, 3번, 5번 |
결정트리3 |
0, 1, 3, 1, 0, 1 |
0번, 4번 |
결정트리4 |
0, 0, 2, 0, 2, 2 |
0번, 1번, 3번 |
결정트리5 |
2, 0, 0, 1, 3, 0 |
1번, 2번, 5번 |
그러면 각 샘플을 이용한 앙상블 학습에 사용된 모델은 다음과 같다.
0번 샘플: 결정트리3, 결정트리4
1번 샘플: 결정트리2, 결정트리4, 결정트리5
2번 샘플: 결정트리1, 결정트리5
3번 샘플: 결정트리2, 결정트리4
4번 샘플: 결정트리3
5번 샘플: 결정트리2, 결정트리5
예제: BaggingClassifier를 이용한 oob 평가
BaggingClassifier 의 경우 oob_score=True 하이퍼파라미터를 사용하면
oob 평가를 자동으로 실행한다.
평가 결과는 oob_score_ 속성에 저정되며, 테스트 성능과 비슷하게 나온다.
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
oob_score=True, random_state=42)
각 샘플에 대한 oob 예측값, 즉 해당 샘플을 훈련에 사용하지 않은 예측기들로 이루어진 앙상블 모델의 예측값은
oob_decision_function_ 속성에 저장된다.
예를 들어, 훈련셋의 맨 앞에 위치한 3 개의 훈련 샘플에 대한 oob 예측값은 다음과 같다.
결정트리 모델이 predict_proba() 메서드를 지원하기에 양성, 음성 여부를 확률로 계산한다.
>>> bag_clf.oob_decision_function_[:3]
array([[0.32352941, 0.67647059],
[0.3375 , 0.6625 ],
[1. , 0. ]])
예를 들어, 첫째 훈련 샘플에 대한 oob 평가는 양성일 확률을 67.6% 정도로 평가한다.
6.3. 랜덤 패치와 랜덤 서브스페이스#
이미지 데이터의 경우처럼 특성이 매우 많은 경우 특성에 대해 중복선택 옵션을 지정할 수 있다. 이를 통해 더 다양한 예측기를 만들게 되어 앙상블 학습 모델의 편향이 커지지만 분산은 보다 낮아진다.
max_features하이퍼파라미터: 학습에 사용할 특성 수 지정. 기본값은 1.0, 즉 전체 특성 모두 사용. 정수를 지정하면 지정된 수 만큼의 특성 사용. 0과 1 사이의 부동소수점이면 지정된 비율 만큼의 특성 사용.bootstrap_features하이퍼파라미터: 학습에 사용할 특성을 선택할 때 중복 허용 여부 지정. 기본값은 False. 즉, 중복 허용하지 않음.
랜덤 패치 기법
훈련 샘플과 훈련 특성 모두를 대상으로 중복을 허용하며 임의의 샘플 수와 임의의 특성 수만큼을 샘플링해서 학습하는 기법이다.
BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=0.75, bootstrap=True,
max_features=0.5, bootstrap_features=True,
random_state=42)
랜덤 서브스페이스 기법
전체 훈련 세트를 학습 대상으로 삼지만 훈련 특성은 임의의 특성 수만큼 샘플링해서 학습하는 기법이다.
샘플에 대해:
bootstrap=False이고max_samples=1.0특성에 대해:
bootstrap_features=True또는max_features는 1.0 보다 작게.
BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=1.0, bootstrap=False,
max_features=0.5, bootstrap_features=True,
random_state=42)
배깅 vs 랜덤 서브스페이스 vs 랜덤 패치
아래 세 개의 그림이 배깅, 랜덤 서브스페이스, 랜덤 패치 등 세 기법에 사용되는 훈련셋의 차이를 보여준다.

6.4. 랜덤 포레스트#
랜덤 포레스트random forest는
배깅 기법을 결정트리의 앙상블에 특화시킨 모델이다.
배깅 기법 대신에 페이스팅 기법을 옵션으로 사용할 수도 있으며,
RandomForestClassifier 는 분류 용도로, RandomForestRegressor 는 회귀 용도로 사용한다.
RandomForestClassifier 모델의 하아퍼파라미터는
BaggingClassifier와 DecisionTreeClassifier의 그것과 거의 동일하다.
예를 들어, 아래 두 모델은 기본적으로 동일하다.
RandomForestClassifier 모델
n_estimators=500: 500 개의 결정트리 사용max_leaf_nodes=16: 리프 노드 최대 16개n_jobs=-1: 모든 CPU 사용
RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
BaggingClassifier 모델
DecisionTreeClassifier의max_features="sqrt": 노드 분할에 사용되는 특성의 수를 전체 특성 수 \(n\)의 제곱근 값인 \(\sqrt{n}\)으로 제한하고 특성을 무작위로 선택.
BaggingClassifier(DecisionTreeClassifier(max_features="sqrt",
max_leaf_nodes=16),
n_estimators=500,
n_jobs=-1, random_state=42)
6.4.1. 엑스트라 트리#
랜덤 포레스트는 \(\sqrt{n}\) 개의 특성을 무작위로 선택하지만 선택된 특성의 임곗값은 모든 특성값에
대해 확인한다.
그런데 DecisionTreeClassifier 모델의 splitter="random" 하이퍼파라미터를 사용하면
임곗값도 무작위로 몇 개 선택해서 그중에 최선의 임곗값을 찾는다.
이렇게 작동하는 결정트리로 구성된 앙상블 학습 모델을
엑스트라 트리Extra-Tree라고 부른다.
참고로 엑스트라 트리는 Extremely Randomized Tree 의 줄임말이다.
엑스트라 트리는 일반적인 램덤포레스트보다 속도가 훨씬 빠르고,
보다 높은 편향을 갖지만 분산은 상대적으로 낮다.
아래 코드는 사이킷런의 엑스트라 모델을 선언한다.
하이퍼파라미터는 bootstrap=False 를 사용하는 것 이외에는 랜덤포레스트의 경우와 하나만 빼고 동일하다.
bootstrap=False 를 사용하는 이유는 특성과 임곗값을 무작위로 선택하기에 각
결정트리의 훈련에 사용될 훈련 샘플들까지 중복을 허용해서 모델의 다양성을 굳이
보다 더 키울 필요는 없다는 정도로 이해할 수 있다.
extra_clf = ExtraTreesClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
랜덤 포레스트와 엑스트르 트리 두 모델의 성능은 기본적으로 비슷한 것으로 알려졌다.
6.4.2. 특성 중요도#
어떤 특성의 중요도는 해당 특성을 사용한 마디가 평균적으로 불순도를 얼마나 감소시키는지를 측정한 값이다. 즉, 불순도를 많이 줄이면 그만큼 중요도가 커진다.
RandomForestClassifier 모델은 훈련할 때마다 자동으로 모든 특성에 대해
상대적 특성 중요도를 계산하여 feature_importances_ 속성에 저장한다.
상대적인 이유는 모든 특성 중요도의 합이 1이 되도록 계산되기 때문이다.
이렇듯 랜덤 포레스트 모델을 이용하여 특성의 상대적 중요도를 파악한 다음에 보다
중요한 특성을 선택해서 활용할 수 있다.
Example 6.1 (붓꽃 데이터셋)
붓꽃 데이터셋의 경우 특성별 상대적 중요도는 다음과 같이 꽃잎의 길이와 너비가 매우 중요하며, 꽃받침의 길이와 너비 정보는 상대적으로 훨씬 덜 중요하다. 지금까지 붓꽃 데이터셋을 사용할 때 꽃잎의 길이와 너비 두 개의 특성만을 사용한 이유가 여기에 있다.
특성 |
상대적 중요도 |
|---|---|
꽃받침 길이 |
0.11 |
곷받침 너비 |
0.02 |
꽃잎 길이 |
0.44 |
곷잎 너비 |
0.42 |
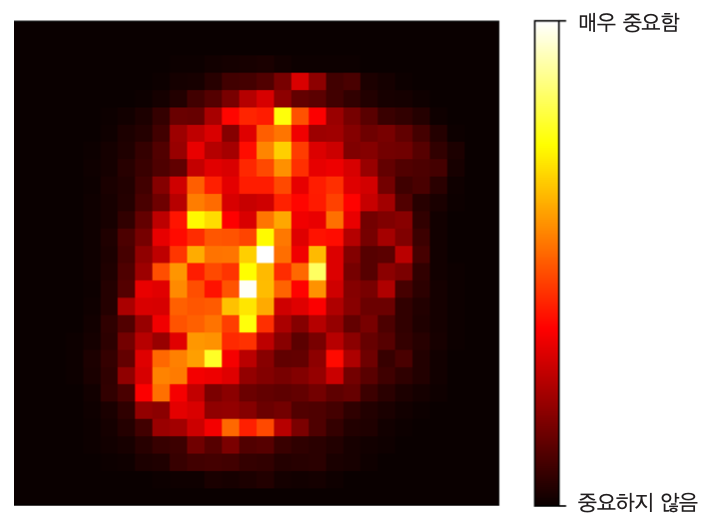
Example 6.2 (MNIST)
MNIST 데이터셋의 경우 특성으로 사용된 모든 픽셀의 중요도를 그래프로 그리면 다음과 같다. 숫자가 일반적으로 중앙에 위치하였기에 중앙에 위치한 픽셀의 중요도가 보다 높게 나온다.
6.5. 부스팅#
성능이 약한 하나의 예측기로부터 출발하여 선형적으로 차례대로 강력한 성능의 예측기를 만들어 가는 과정을 부스팅boosting이라 한다. 대표적으로 다음 세 기법이 사용된다.
에이다부스트AdaBoost
그레이디언트 부스팅Gradient Boosting
XGBoost
세 기법 모두 순차적으로 이전 예측기의 결과를 바탕으로 예측 성능을 조금씩 높혀 간다. 하지만 순차적으로 학습하기에 배깅/페이스팅 방식과는 달리 훈련을 동시에 진행할 수 없어서 훈련 시간이 훨씬 오래 걸릴 수 있는 단점을 갖는다.
여기서는 부스팅 기법을 사용하면서 가장 성능이 좋은 모델을 학습시키는 그레이디언트 부스팅 기법과 XGBoost 기법을 자세히 다룬다.
6.5.1. 그레이디언트 부스팅#
그레이디언트 부스팅Gradient Boosting 기법은 그레이디언트 부스팅 기법은 이전 예측기에 의해 생성된 잔차residual error에 대해 새로운 예측기를 학습시킨다. 잔차는 예측값과 타깃 사이의 오차를 가리킨다.
사이킷런 그레이디언트 부스팅 모델
사이키런에서 제공하는 그레이디언트 부스팅 모델은 두 개다.
분류 모델:
GradientBoostingClassifier회귀 모델:
GradientBoostingRegressor
두 모델 모두 결정트리 모델을 연속적으로 훈련시킨다.
예제: GBRT
아래 그래프는 2차 다항식 모양의 훈련 데이터셋에 결정트리 모델을 3번 연속 적용하면서 생성한 예측값의 변화과정을 보여준다.
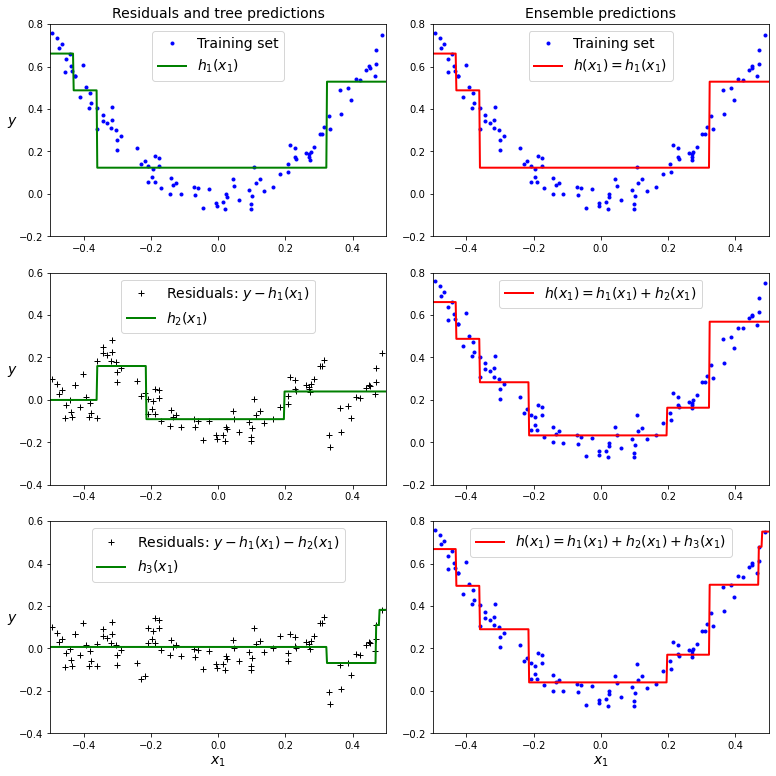
GradientBoostingRegressor 모델을 아래와 같이 설정하고 훈련하면 실제로 세 개의 결정트리가
위 그래프처럼 학습한다.
gbrt = GradientBoostingRegressor(max_depth=2,
n_estimators=3,
learning_rate=1.0, random_state=42)
GBRT
GBRT는 Gradient Boosted Regression Trees, 즉 ‘그레이디언트 부스팅 회귀 나무’의 줄임말이다.
학습률과 축소 규제
학습률(learnign_rate)은 그레이디언트 부스팅 기법으로 훈련할 때
훈련에 사용된 각 결정 트리 모델의 예측값이 최종 예측값을 계산할 때 기여하는 정도를 결정한다.
학습률이 0.1 등처럼 작게 잡으면 보다 많은 수의 모델을 훈련시켜야 하지만 그만큼 일반화 성능이 좋은 모델이 훈련된다. 이런 방식으로 훈련 과정을 규제하는 기법이 축소 규제shrinkage regularization다. 즉, 훈련에 사용되는 각 모델의 기여도를 어느 정도로 축소할지 결정하는 방식으로 모델의 훈련을 규제한다.
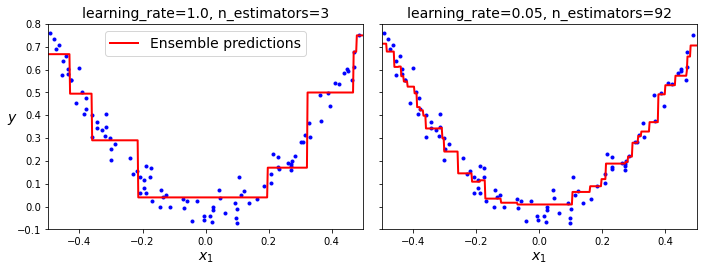
아래 두 그래프는 학습률이 1인 경우(왼쪽)와 0.05인 경우(오른쪽)의 차이를 보여준다.
학습률이 1인 경우(왼쪽): 모델 훈련 세 번 반복. 과소적합.
학습률이 0.05인 경우(오른쪽): 모델 훈련 92번 반복. 적절한 모델 생성.
조기 종료
훈련 모델의 수를 너무 크게 잡으면 과대적합의 위험성은 커지게 된다. 따라서 훈련되는 모델의 적절한 수를 알아내는 일이 중요하다. 이를 위해 그리드 탐색 기법, 랜덤 탐색 기법 등을 사용할 수 있다.
하지만 GradientBoostingRegressor 모델의 n_iter_no_change 하이퍼파라미터를 지정하면
간단하게 조기 종료 기법을 적용할 수 있다.
아래 코드는 n_iter_no_change=10 을 사용하여 원래 500번 연속 결정트리를 훈련시켜야 하지만
모델이 검증셋에 대해 연속적으로 10번 제대로 개선되지 못하는 경우
훈련을 종료시킨 다음에 그때까지의 최적의 모델을 저장한다.
GradientBoostingRegressor(max_depth=2,
learning_rate=0.05,
n_estimators=500,
n_iter_no_change=10, random_state=42)
n_iter_no_change=None이 기본값이지만 위 코드에서처럼 조기 종료를 위해 다른 정수값으로 지정되면validation_fraction=0.1이 기본값으로 사용되어 훈련셋의 10% 정도의 검증셋이 지정되어 에포크마다 훈련된 결정트리의 성능을 평가한다.tol=0.0001허용오차 이하로 성능이 변하지 않은 경우 좋아지지 않는다고 판단한다.
확률적 그레이디언트 부스팅
subsample 하이퍼파라리미터를 이용하여 각 결정트리가 훈련에 사용할 훈련 샘플의 비율을 지정한다.
예를 들어 subsample=0.25 로 설정하면 각 결정트리 모델은 전체 훈련셋의 25% 정도만
이용해서 훈련한다. 훈련 샘플은 매번 무작위로 선택된다.
이 방식을 사용하면 훈련 속도가 빨라지며, 편향은 높아지지만, 모델의 다양성이 많아지기에 분산은 낮아진다.
히스토그램 그레이디언트 부스팅
대용량 데이터셋을 이용하여 훈련해야 하는 경우
히스토그램 그레이디언트 부스팅Histogram-based Gradient Boosing(HGB)
기법이 추천된다.
이 기법은 훈련 샘플의 특성값을 max_bins 개의 구간으로 분류한다.
즉, 샘플의 특성이 최대 max_bins 개의 값 중에 하나라는 의미다.
max_bins=255가 기본값이며 255보다 큰 값의 정수를 지정할 수 없다.
이렇게 하면 결정트리의 CART 알고리즘이 적용될 때 최적의 임곗값을 결정할 때
확인해야 하는 경우의 수가 매우 작아지기에 수 백배 이상 빠르게 학습된다.
또한 특성값이 모두 정수이기에 메모리도 보다 효율적으로 사용한다.
실제로 하나의 결정트리 모델의 훈련 시간 복잡도는 원래 \(O(n\times m \times \log(m))\) 이지만
히스토그램 방식을 사용하면 \(O(b \times m)\) 로 줄어든다.
여기서 b는 실제로 사용된 구간의 수를 가리킨다.
물론 모델의 정확도는 떨어지며, 경우에 따라 과대적합을 방지하는 규제 역할도 수행한다.
하지만 과소적합을 유발할 수도 있다.
사이킷런의 히스토그램 그레이디언트 부스팅 모델
HistGradientBoostingRegressor: 회귀 모델HistGradientBoostingClassifier: 분류 모델
GradientBoostingRegressor, GradientBoostingClassifier 등과 유사하게 작동한다.
장점
언급된 두 모델은 범주 특성을 다룰 수 있으며, 결측치도 처리할 수 있다. 결측치는 255개의 구간 이외에 특별한 구간에 들어가는 것으로 간주된다.
예제
아래 코드는 캘리포니아 주택가격 데이터셋을 이용하여 히스토그램 그레이디언트 부스팅 모델을 적용하는 것을 보여준다.
(OrdinalEncoder(), ["ocean_proximity"]): 해안 근접도 특성값으로 사용된 5개를 0에서 4사이의 정수로 변환하는 변환기 지정.categorical_features=[0]: 범주형 특성의 위치 지정캘리포니아 주택가격 데이터셋에 결측치 존재하지만 전처리로 다루지 않음.
스케일링, 원-핫-인코딩 등도 필요하지 않음.
hgb_reg = make_pipeline(
make_column_transformer((OrdinalEncoder(), ["ocean_proximity"]),
remainder="passthrough"),
HistGradientBoostingRegressor(categorical_features=[0], random_state=42)
)
hgb_reg.fit(housing, housing_labels)
6.5.2. XGBoost#
XGBoost는 Extreme Gradient Boosting의 줄임말이며, 표현 그대로 그레이디언트 부스팅 기법을 속도와 성능 면에서 극단적으로 최적화한 모델이다. 그레이디언트 부스팅 모델과의 차이점은 다음과 같다.
결정트리 학습에 사용되는 노드 분할을 통해 낮춰야 하는 비용함수가 다르다.
불순도 대신 mse, logloss 등 모델 훈련의 목적에 맞는 손실 함수 사용한다. 무엇보다도 결정트리의 노드 분할에 필요한 시간이 획기적으로 줄어든다.
이와 더불어 생성되는 결정트리의 복잡도도 비용함수에 추가된다. 따라서 최종적으로 생성되는 모델에 사용되는 결정트리의 복잡도를 가능한한 낮추도록 유도된다.
보다 자세한 내용은 XGBoost의 공식 문서인 Introduction to Boosted Trees를 참고한다.
XGBoost 모델은 또한 훈련 속도가 빠르고 대용량 데이터셋을 이용한 훈련에도 용이하다. 이와 더불어 결측치를 포함한 데이터셋으로도 훈련이 가능하며, GPU를 활용할 수도 있다.
XGBoost 사용법
XGBoost 모델은 사이킷런 라이브러리에 포함되지 않아서 pip 파이썬 패키지 관리자를 추가로 설치해야 한다.
pip install xgboost
회귀 모델인 XGBRegressor와 분류 모델인 XGBClassifier 를 지원하며
사용법은 그레이디언트 부스팅과 유사하다.
아래 코드는 XGBRegressor 모델을 훈련시키는 코드이다.
import xgboost
xgb_reg = xgboost.XGBRegressor(random_state=42)
xgb_reg.fit(X_train, y_train,
eval_set=[(X_val, y_val)],
early_stopping_rounds=2)
참고
보다 자세한 설명은 XGBoost - An In-Depth Guide을 참고한다.