3. 분류#
감사의 글
자료를 공개한 저자 오렐리앙 제롱과 강의자료를 지원한 한빛아카데미에게 진심어린 감사를 전합니다.
소스코드
본문에 소개된 코드는 (구글코랩) 분류에서 직접 실행할 수 있다.
주요 내용
MNIST 데이터셋
이진 분류기 훈련
분류기 성능 측정
다중 클래스 분류
오류 분석
다중 라벨 분류
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
3.1. MNIST 데이터셋#
미국의 고등학생과 인구조사국 직원들이 손으로 쓴 70,000개의 숫자 이미지로 구성된 데이터셋이다.
sklearn.datasets 모듈은 데이터셋을 다운로드하거나 생성하는 세 종류를 함수를 제공하며
함수명에 사용된 접두사에 따라 용도가 다르다.
fetch_*: 다운로드 및 적재.sklearn.utils.Bunch객체 반환.load_*: 미니 데이터셋 적재. 다운로드 없음.make_*: 데이터셋 임의 생성. 입력 데이터셋과 타깃 데이터셋으로 구분된(X, y)모양의 넘파이 어레이 생성.
데이터 불러오기
MNIST 데이터셋을 다운로드해서 Bunch 객체로 적재온다.
Bunch 자료형은 사전 (Dict) 자료형의 일종이며
data, target 등 머신러닝 모델 훈련에 사용될 데이터셋을 저장할 때 활용된다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', as_frame=False)
입력 데이터셋과 타깃 데이터셋
입력 데이터는 0부터 9까지의 숫자는 모두 28x28 크기의 1차원 어레이로,
라벨은 정수가 아니라 '0', '1', …, '9'처럼 문자열로 지정되었다.
X, y = mnist.data, mnist.target
아래 이미지는 첫 손글씨 데이터를 28x28 모양으로 변환한 다음에 pyplot.imshow() 함수를 이용하여
그려진 것이며 숫자 5를 가리키는 것으로 보인다. 실제로도 타깃은 숫자 5이다.
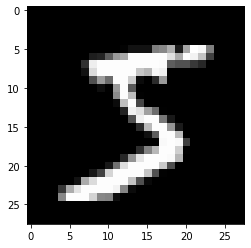
첫 100 개의 손글씨 이미지는 다음과 같다.

문제 정의
지도학습: 각 이미지가 담고 있는 숫자가 라벨로 지정됨.
모델: 이미지 데이터를 분석하여 0부터 9까지, 총 10개의 범주로 분류하는 다중 클래스 분류multiclass classification.
실시간 훈련 여부: 배치 또는 온라인 학습 둘 다 가능하지만 여기서는 확률적 경사하강법stochastic gradient descent(SGD)과 랜덤 포레스트 분류기를 이용하여 배치 학습 실행
배치 학습 대 온라인 학습
배치 학습은 빠르게 변하는 데이터에 적응할 필요가 없고 데이터셋의 크기도 충분히 작아 데이터셋 전체를 컴퓨터 메모리에 적재한 상태애서 모델 훈련을 진행하는 기법을 가리킨다. 반면에 온라인 학습은 데이터셋이 너무 크거나 실시간 학습이 필요한 경우 데이터셋을 보충하면서 모델 훈련을 점차적으로 진행시키는 기법이다.
훈련셋과 테스트셋
이미 6:1 의 비율로 훈련셋과 데이터셋으로 분류되어 있다. 모든 샘플은 무작위로 잘 섞여 있어서 교차 검증에 문제없이 사용될 수 있다.
훈련 세트(
X_train): 앞쪽 60,000개 이미지테스트 세트(
X_test): 나머지 10,000개의 이미지
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
3.2. 이진 분류기: 숫자-5 감별기#
10개의 클래스로 분류하는 다중 클래스 모델을 훈련하기 전에 먼저 이미지 샘플이 숫자 5를 표현하는지 여부를 판단하는 이진 분류기를 훈련시킨다. 이를 통해 분류기의 기본 훈련 과정과 성능 평가 방법을 알아본다.
이진 분류기인 숫자-5 감별기의 훈련을 위해 타깃 데이터셋(y_train_5)을 새로 설정한다.
1: 숫자 5를 가리키는 이미지 라벨
0: 숫자 5 이외의 수를 가리키는 이미지 라벨
y_train_5 = (y_train == '5')
y_test_5 = (y_test == '5')
먼저 SGDClassifier 클래스를 이용하여 숫자-5 감별기를 훈련시킨다.
SGDClassifier 분류기는
확률적 경사하강법stochastic gradient descent 분류기라고도 불린다.
한 번에 하나씩 훈련 샘플을 이용하여 훈련한 후 파라미터를 조정하기에
매우 큰 데이터셋 처리와 온라인 학습에 적합하다.
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
이미지 픽셀과 데이터 입력 특성
모델 훈련에 사용되는 입력 데이터셋의 모든 샘플은 길이가 784인 1차원 어레이로 주어졌다.
어레이의 각 항목은 28x28 모양의 손글씨 이미지에 포함된 하나의 픽셀값에 해당한다.
즉, 이미지에 포함된 모든 픽셀이 입력 데이터 샘플의 특성이 된다.
따라서 sgc_clf 모델은 784 개의 픽셀 정보를 이용하여 해당 이미지 샘플이 가리키는 숫자가
5인지 여부를 판정하도록 훈련된다.
3.3. 분류기 성능 측정#
분류기의 성능 측정 기준으로 보통 다음 세 가지를 사용한다.
정확도
정밀도와 재현율
ROC 곡선의 AUC
3.3.1. 오차 행렬#
오차 행렬confusion matrix은 클래스별 예측 결과를 정리한 행렬이다. 이진 분류기인 숫자-5 감별기에 대한 오차 행렬은 아래와 같은 (2, 2) 모양의 2차원 (넘파이) 어레이로 생성된다.
아래 코드는 교차 검증을 이용하여 예측을 수행한 다음 이를 이용하여 오차 행렬을 생성한다.
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
confusion_matrix(y_train_5, y_train_pred)
array([[53892, 687],
[ 1891, 3530]])
아래 그림은 숫자-5 감별기의 오차 행렬을 단순화하여 보여준다.
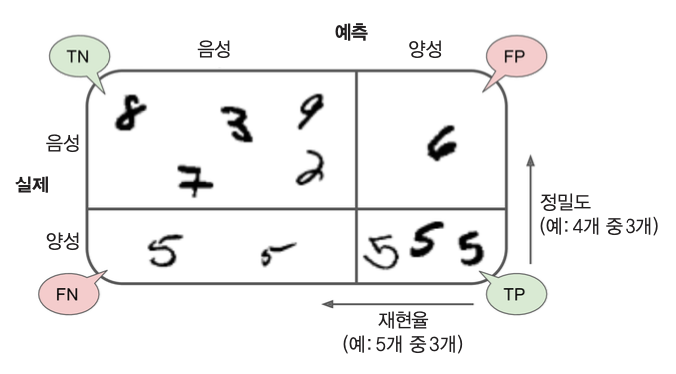
3.3.2. 정확도#
정확도accuracy는 라벨을 정확하기 맞힌 비율이다.
정확도의 한계
정확도가 96% 정도로 매우 좋은 결과로 보인다. 하지만 “무조건 5가 아니다” 라고 예측하는 모델도 90%의 정확도를 보인다. 특정 범주에 속하는 데이터가 상대적으로 너무 많을 경우 정확도는 신뢰하기 어려운 평가 기준임을 잘 보여주는 사례다. 이런 경우엔 정확도 보다는 정밀도와 재현율을 이용하여 평가하는데 성능이 상대적으로 낮게 나온다. 특히 재현율의 성능이 매우 낮다.
3.3.3. 정밀도와 재현율#
정밀도precision는 양성 예측의 정확도를 가리킨다. 여기서는 숫자 5라고 예측된 값들 중에서 진짜로 5인 숫자들의 비율이다.
5인지 여부를 맞추는 모델의 예에서 확인했듯이 정밀도 하나만으로 분류기의 성능을 평가할 수는 없다. 보다 구체적인 이유는 숫자 5를 가리키는 이미지 중에 숫자 5라고 판명된 비율인 재현율recall 함께 고려해야 하기 때문이다.
재현율recall은 양성 샘플에 대한 정확도, 즉, 분류기가 정확하게 감지한 양성 샘플의 비율이며, 참 양성 비율true positive rate로도 불린다.
정밀도와 재현율의 상대적 중요도
모델 사용의 목적에 따라 정밀도와 재현율의 중요도가 다를 수 있다.
재현율이 보다 중요한 경우: 암진단처럼 예측이 틀렸을 경우 큰 책임이 따르는 경우.
정밀도: 암이 있다고 진단된 경우 중에 실제로도 암이 있는 경우의 비율
재현율: 암으로 판정해야 하는 경우 중에서 양성 암진단으로 결론내린 경우의 비율
다른 예제: 금융 사기 여부, 태풍 예보
정밀도가 보다 중요한 경우: 아이에게 보여줄 안전한 동영상 선택처럼 일부 양성 모델을 놓치더라도 음성이 양성으로 판정되는 경우가 적어야 하는 경우.
정밀도: 안전하다고 판단된 동영상 중에서 실제로도 안전한 동영상의 비율
재현율: 실제로 좋은 동영상 중에서 좋은 동영상이라고 판정되는 동영상 비율
다른 예제: 스팸 필터링
3.3.4. 정밀도/재현율 트레이드오프#
분류기의 결정 함수decision function는 각 샘플에 대해 점수를 계산하며
이 점수가 결정 임계값decision threshold보다
같거나 크면 양성, 아니면 음성으로 판단한다.
예를 들어 SGDClassifier는 decision_function() 메서드를 결정 함수로 이용하며,
결정 함숫값이 0보다 작으면 음성, 0보다 같거나 크면 양성으로 판정한다.
정밀도와 재현율은 상호 반비례 관계이다. 즉, 한쪽이 증가하면 다른쪽이 감소하는 트레이드오프tradeoff 관계이다. 따라서 정밀도와 재현율 사이의 적절한 비율을 유지하는 분류기를 찾아야 한다. 정밀도와 재현율의 비율은 모델이 사용하는 결정 임곗값에 따라 달라진다.
아래 예제가 정밀도와 재현율의 트레이드오프 관계를 잘 보여준다.
결정 임곗값의 위치에 따라 정밀도와 재현율이 서로 다른 방향으로 움직인다.
결정 임곗값이 클 수록 분류기의 정밀도는 올라가지만 재현율은 떨어진다.
결정 임곗값이 작을 수록 분류기의 정밀도는 내려가지만 재현율은 올라간다.
Example 3.1 (정밀도와 재현율의 트레이드오프)
아래 그림에서 세 개의 화살표 (a), (b), (c)는 서로 다른 결정 임곗값을 가리키며, 화살표 윗쪽에 위치한 정밀도와 재현율은 해당 결정 임곗값을 기준으로 주어진 샘플의 양성, 음성 여부를 판단할 경우의 정밀도와 재현율이다.
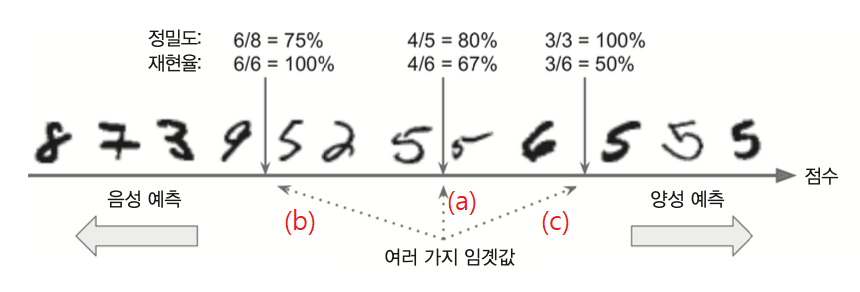
경우 (a)
정밀도 80%: 양성으로 예측된 5개의 샘플 중 정말로 5를 가리키는 샘플 4개, 아닌 샘플 1개
재현율 67%: 실제로 5인 샘플 총 6개 중에 5라고 판정된 샘플 4개
경우 (b)
정밀도 75%: 양성으로 예측된 8개의 샘플 중 정말로 5를 가리키는 샘플 6개, 아닌 샘플 2개
재현율 100%: 실제로 5인 샘플 총 6개 중에 5라고 판정된 샘플 6개
경우 (c)
정밀도 100%: 양성으로 예측된 3개의 샘플 중 정말로 5를 가리키는 샘플 3개, 아닌 샘플 0개
재현율 50%: 실제로 5인 샘플 총 6개 중에 5라고 판정된 샘플 3개
결정 함수와 결정 임곗값
결정 함수를 이용해서 교차 검증을 실행하면 각 샘플에 대한 결정 함수의 값으로 구성된 어레이가 생성된다.
이를 위해 앞서 오차 행렬 생성에 사용된 cross_val_predict() 함수를
method="decision_function" 키워드 인자와 함께 호출한다.
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
처음 10개 샘플에 대한 결정 함숫값은 다음과 같다. 첫째 샘플의 결정 함숫값만 양수이고 나머지 9개는 음수다. 따라서 첫째 샘플만 5로 판정되고 나머자 9개는 5가 아니다라고 판정된다.
y_scores[:10]
array([ 1200.93051237, -26883.79202424, -33072.03475406, -15919.5480689 ,
-20003.53970191, -16652.87731528, -14276.86944263, -23328.13728948,
-5172.79611432, -13873.5025381 ])
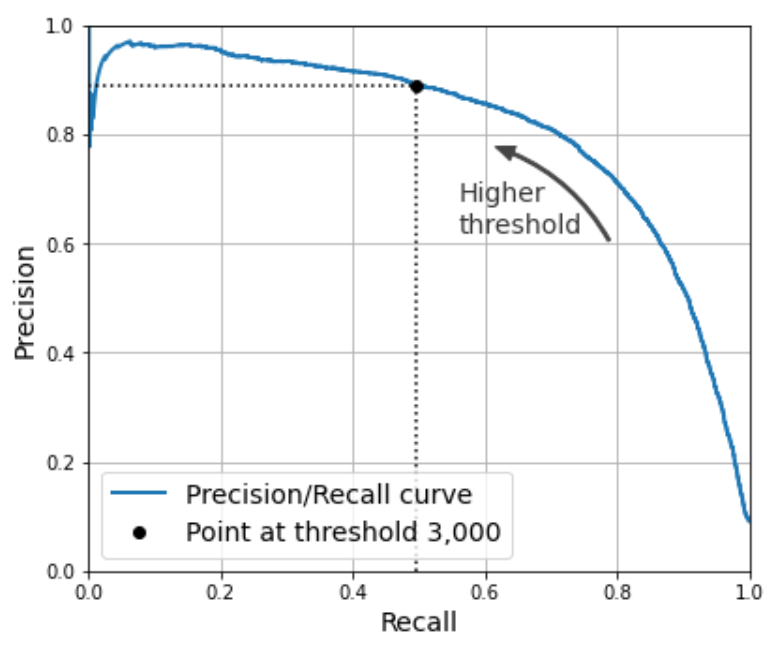
결정 임곗값/정밀도/재현율 그래프
아래 그래프는 SGDClassifier 모델을 숫자-5 감별기로 훈련시킨 결과를 이용한다.
그래프는 결정 임곗값을 독립 변수로 해서 정밀도와 재현율의 변화를 보여준다.
결정 임곗값이 커질 때 정밀도가 순간적으로 떨어질 수 있지만 결국엔 계속해서 상승한다.
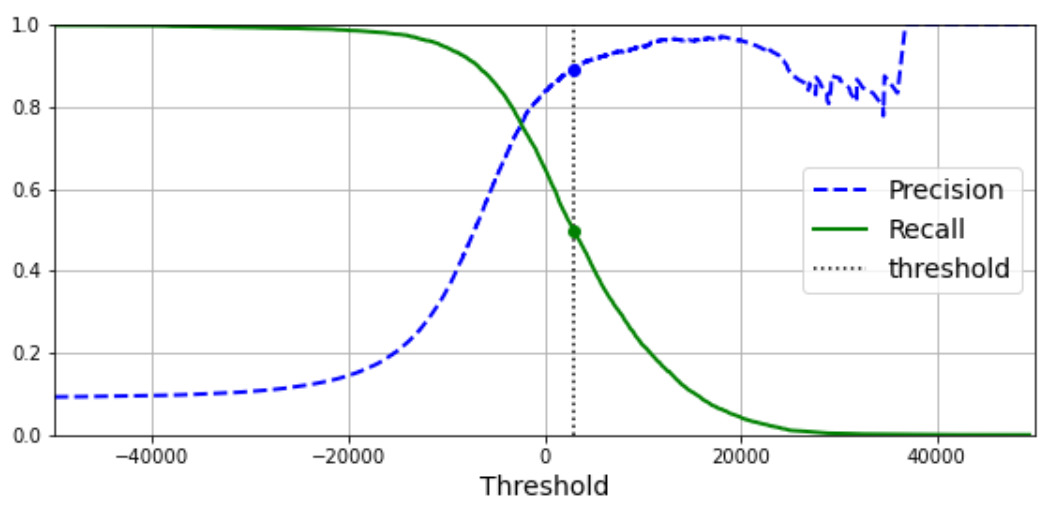
SGDClassifier 는 0을 결정 임곗값으로 사용하기에 정밀도는 84% 정도, 재현율은 65% 정도다.
반면에 검정 수직 점선은 정밀도는 90%, 재현율은 50% 정도가 되게 하는 결정 임곗값을 보여준다.
결정 임곗값을 변경하여 원하는 정밀도와 재현율을 갖는 숫자-5 감별기를 구현하려면
수동으로 분류기를 구현해야 한다 (90% 정밀도 분류기 구현 참고).
정밀도/재현율 그래프
위 그래프를 재현율 대 정밀도 그래프로 변환하면 다음과 같다.
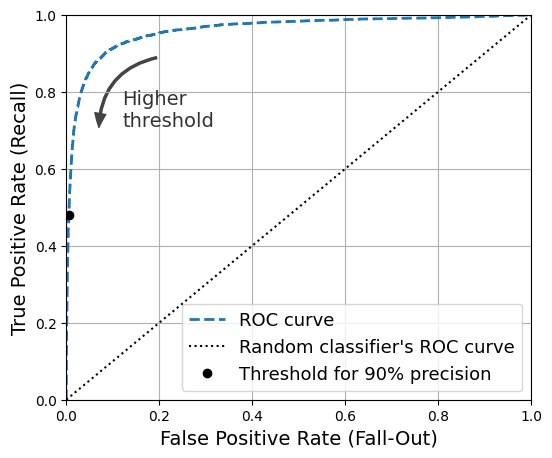
3.3.5. ROC 곡선의 AUC#
수신기 조작 특성receiver operating characteristic(ROC) 곡선을 활용하여 이진 분류기의 성능을 측정할 수 잇다. ROC 곡선은 거짓 양성 비율false positive rate(FPR)에 대한 참 양성 비율true positive rate(TPR)의 관계를 나타내는 곡선이다.
참 양성 비율(TPR): 재현율의 다른 이름.
거짓 양성 비율(FPR): 원래 음성인 샘플 중에서 양성이라고 잘못 분류된 샘플들의 비율. 예를 들어, 5가 아닌 숫자중에서 5로 잘못 예측된 숫자의 비율.
TPR 대 FPR
아래 그래프는 결정 임곗값에 따른 두 비율의 변화를 곡선으로 보여준다. 재현율(TPR)과 거짓 양성 비율(FPR) 사이에도 서로 상쇄하는 기능이 있다는 것을 확인할 수 있다. 이유는 재현율(TPR)을 높이고자 하면 거짓 양성 비율(FPR)도 함께 증가하기 때문이다.
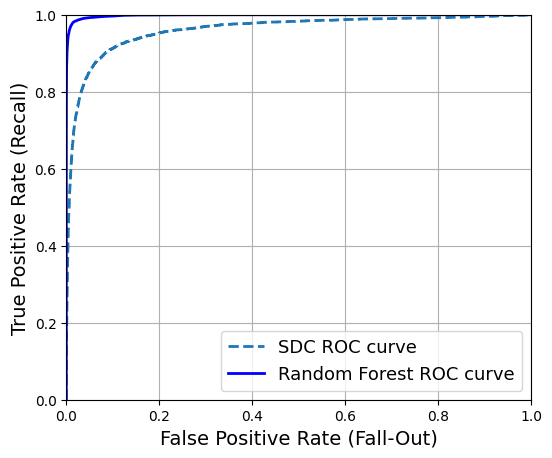
AUC와 분류기 성능
좋은 분류기는 재현율은 높으면서 거짓 양성 비율은 최대한 낮게 유지해야 한다. 즉, ROC 곡선이 y축에 최대한 근접하도록 해야 하며, 이는 ROC 곡선 아래의 면적, 즉 AUC(area under the curve)가 1에 가까울 수록 좋은 성능임을 의미한다.
MNIST 훈련 데이터셋으로 훈련된 SGDClassifier 와 RandomForestClassifier의
ROC 곡선을 함께 그리면 다음과 같이 랜덤 포레스트 모델의 AUC가 보다 1에 가깝다.
즉, 보다 성능이 좋다.
랜덤 포레스트 분류기는 predict_proba() 메서드를 결정 함수로 사용한다.
predict_proba() 메서드는 입력 샘플에 대해 각 클래스에 속할 확률을 계산한다.
여기서는 숫자-5가 아닌 경우(음성)와 숫자-5인 경우(양성)에 대한 확률값을 담은
길이가 2인 튜플을 계산한다.
양성으로 판정하는 기준값, 즉 결정 임계값은 0.5을 사용한다.
즉 계산된 양성일 확률이 0.5보다 같거나 큰 경우 양성으로 판정한다.
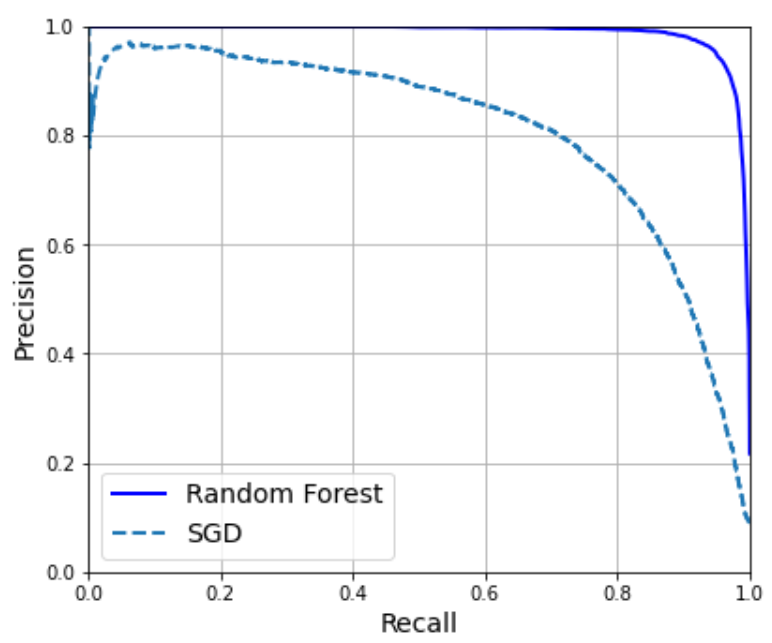
정밀도/재현율 그래프로 비교해 보더라도
RandomForestClassifier 가 훨씬 좋은 성능을 보임을 확인할 수 있다.
3.4. 다중 클래스 분류#
다중 클래스 분류multiclass classification는 세 개 이상의 범주(클래스)로 샘플을 분류한다. 예를 들어, MNIST 손글씨 숫자 문제는 입력값이 주어지면 0부터 9까지 10개의 범주로 분류하는 다중 클래스 모델을 훈련시키는 일이다.
다중 클래스 분류 지원 모델
아래 모델은 이진 분류와 다중 클래스 분류를 지원한다.
LogisticRegression모델RandomForestClassifier모델SGDClassifier모델SVC모델
이중에 LogisticRegression 모델은 딥러닝 모델에서도 많이 활용된다.
이진 분류: 로지스틱 회귀 활용
소프트맥스 회귀: 다중 클래스 분류
자세한 내용은 4장에서 다룬다.
다중 클래스 분류 모델 교차 검증
숫자-5 감별기의 경우와는 달리 0부터 9까지의 범주로 분류하는 다중 클래스 분류는 각 숫자에 해당하는 데이터가 고르게 분포되어 있어서 정확도를 기준으로 교차 검증을 진행해도 괜찮다.
아래 코드를 이용하여 SGDClassifier 모델에 대해
교차 검증으로 정확도를 계산하면 86.7% 정도로 확인된다.
참고로 정밀도와 재현율을 교차 검증으로 확인하려면
scoring 키워드의 인자로 "precision" 또는 "recall"을 지정한다.
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
스케일링의 중요성
하지만 표준화 스케일링만 해도 모델의 예측 정확도가 89.7% 까지 향상된다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype("float64"))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
그런데 MinMaxScaling 전처리를 적용하면 성능이 91.05까지 좋아진다.
손글씨 이미지가 아무래도 픽셀 정보를 담고 있는 반면에 표준화 스케일링을 진행하면
아무래도 음수로 변환되는 픽셀도 있다.
따라서 모델의 예측 성능에 영향을 미치는 것으로 추정되지만 정확한 이유는 불명확하다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train.astype("float64"))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
3.5. 오류 분석#
그리드 탐색, 랜덤 탐색 등을 이용한 모델 튜닝 과정을 실행하여 최선의 모델을 찾았다고 가정한다. 이제 오류 분석을 통해 모델의 성능을 평가하고 개선시키는 방안을 모색하는 과정을 살펴 본다. 먼저 훈련된 모델의 성능을 평가하기 위해 오차 행렬을 활용한다.
3.5.1. 다중 크래스 분류 모델의 오차 행렬#
먼저 cross_val_predict() 함수를 이용하여 교차 검증 방식으로 표준화 스케일링된 훈련셋에 대한 모델의 예측값을 계산한다.
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
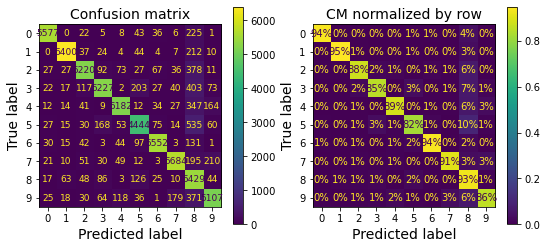
아래 왼쪽 이미지는 훈련된 분류 모델의 오차 행렬을 색상을 이용하여 표현한다. 대각선 상에 위치한 색상이 밝은 것은 분류가 대체로 잘 이루어졋음을 의미한다. 다만 5번 행이 상대적으로 어두운데 이는 숫자 5의 분류 정확도가 상대적으로 낮기 때문이다.
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
반면에 아래 오른쪽 이미지는 숫자별 비율로 변환하였다. 즉, 행별로 비율의 합이 100%가 되도록 정규화하였다.
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,,
normalize="true",
values_format=".0%")
오차율 활용
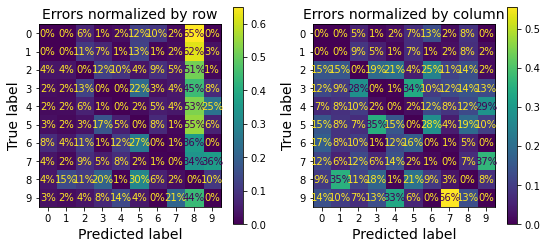
위 오른쪽 이미지에서 8로 오인된 이미지가 많았음을 알 수 있다. 실제로 올바르게 예측된 샘플을 제외한 다음에 행별로 오인된 숫자의 비율을 확인하면 아래 왼쪽 이미지와 같다. 8번 칸이 상대적으로 많이 밝으며, 이는 많은 숫자가 8로 오해되었다는 의미다.
sample_weight = (y_train_pred != y_train)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
sample_weight=sample_weight,
normalize="true",
values_format=".0%")
아래 오른쪽 이미지는 열 별로 정규화한 결과를 보여준다. 예를 들어, 7로 오인된 이미지 중에 숫자 9 이미지의 비율이 56%임을 알 수 있다.
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
sample_weight=sample_weight,
normalize="pred",
values_format=".0%")
개별 오류 확인
위 오른쪽 이미지에 의하면 5로 오인된 이미지 중에서 숫자 3 이미지의 비율이 34%로 가장 높다. 실제로 오차 행렬과 유사한 행렬을 3과 5에 대해 나타내면 다음과 같다.
음성: 3으로 판정
양성: 5로 판정

3.5.2. 데이터 증식#
사람 눈으로 보더라도 3과 5의 구분이 매우 어려울 수 있다. 여기서 사용한 SGD 분류 모델은 선형 회귀를 사용하기에 특히나 성능이 좋지 않다. 따라서 보다 좋은 성능의 모델을 사용할 수도 있지만 기본적으로 보다 많은 훈련 이미지가 필요하다. 새로운 이미지를 구할 수 있으면 좋겠지만 일반적으로 매우 어렵다. 반면에 기존의 이미지를 조금씩 회전하거나, 뒤집거나, 이동하는 방식 등으로 보다 많은 이미지를 훈련셋에 포함시킬 수 있다. 이런 방식을 데이터 증식data augmentation이라 부른다. 데이터 증식에 대한 보다 상세한 설명은 데이터 증식 연습문제를 참고한다.