1. 딥러닝 소개#
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
1.1. 인공지능, 머신러닝, 딥러닝#
관계 1: 연구 분야 관점
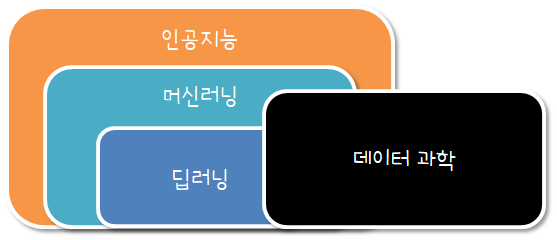
관계 2: 역사
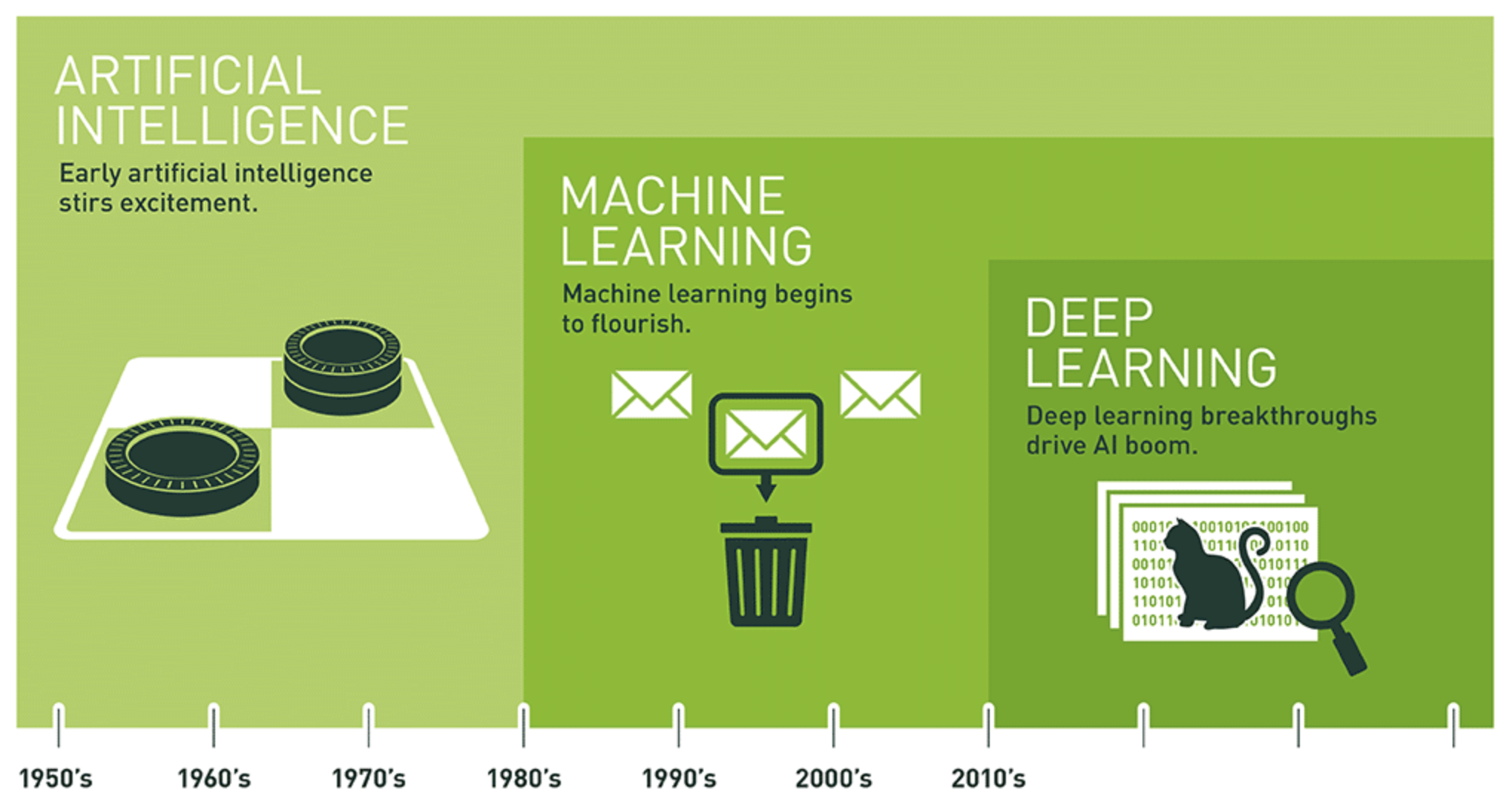
1.1.1. 인공지능의 기원#
인공지능: 인간의 지적 활동을 모방하여 컴퓨터로 자동화하려는 시도. 머신러닝과 딥러닝을 포괄함.
(1950년대) 컴퓨터가 생각할 수 있는가? 라는 질문에서 출발
(1956년) 존 맥카시(John McCarthy)
인간의 모든 지적 활동을 컴퓨터가 수행하도록 프로그램을 구현하는 것이 가능하다고 판단.
하나의 연구 분야로 제안
(1980년대까지) 학습(러닝)이 아닌 모든 가능성을 논리적으로 전개하는 기법 활용
서양장기(체스) 등에서 우수한 성능 발휘
반면에 이미지 분류, 음석 인식, 자연어 번역 등 보다 복잡한 문제는 제대로 다루지 못함.
(1990 년대부터) 입력 데이터로부터 규칙을 스스로 찾아내도록 유도하는 머신러닝 기법이 유행하기 시작함.
인공지능(AI) 분야의 주요 핵심 기법으로 자리잡음
보다 큰 데이터셋과 보다 좋은 성능의 하드웨어의 도움으로 성능과 중요도가 점차 올라감.
통계학과 수학의 이론 보다는 데이터를 이용한 학습 기법을 공학적으르 개발하고 개선하는 것이 보다 중요해짐. 특히 딥러닝 기법이 발전하면서 더더욱 그런 현상이 강해짐.
1.1.2. 머신러닝#
전통적 프로그램 대 머신러닝 프로그램
전통적 프로그램
컴퓨터가 수행해야 할 규칙을 순서대로 적어 놓은 프로그램 작성
입력값이 지정되면 지정된 규칙을 수행하여 답을 생성함.
머신러닝 프로그램
주어진 입력 데이터와 출력 데이터로부터 입력과 출력 사이에 존재하는 특정 통계적 구조를 스스로 알아내어 이를 이용하여 입력값으로부터 출력값을 생성하는 규칙을 생성함.
예제: 사진 태그 시스템. 태그가 이미 달린 사진 데이터셋을 이용하여 학습한 후 새로운 사진에 대해 태그 작성 가능.

머신러닝 모델 학습의 필수 요소
입력 데이터셋(훈련셋)
타깃 데이터셋
모델 평가지표
1.1.3. 딥러닝 모델#
딥deep의 의미
딥러닝의 딥deep은 데이터 변환을 실행하는 층layer을 세 개 이상 연속적으로 활용하는 머신러닝 모델을 활용한 학습법을 의미한다. 반면에 쉘로우 러닝shallow learning은 한 두 개의 층만 사용하는 학습을 의미한다.
심층 신경망 모델
딥러닝 모델은 세 개 이상의 층으로 구성된 심층 신경망deep neural network으로 구현된다. 신경망은 여러 개의 층을 쌓아 올린 구조를 가리키며, 신경망의 깊이는 쌓아 올려진 층의 높이다.
심층 신경망은 경우에 따라 수 십 층 이상으로 구성되기도 하며(아래 그림 참고), 각각의 층에서 데이터를 변환하여 최종적으로 원하는 결과를 쉽게 예측하는 값을 만들어내도록 유도한다.
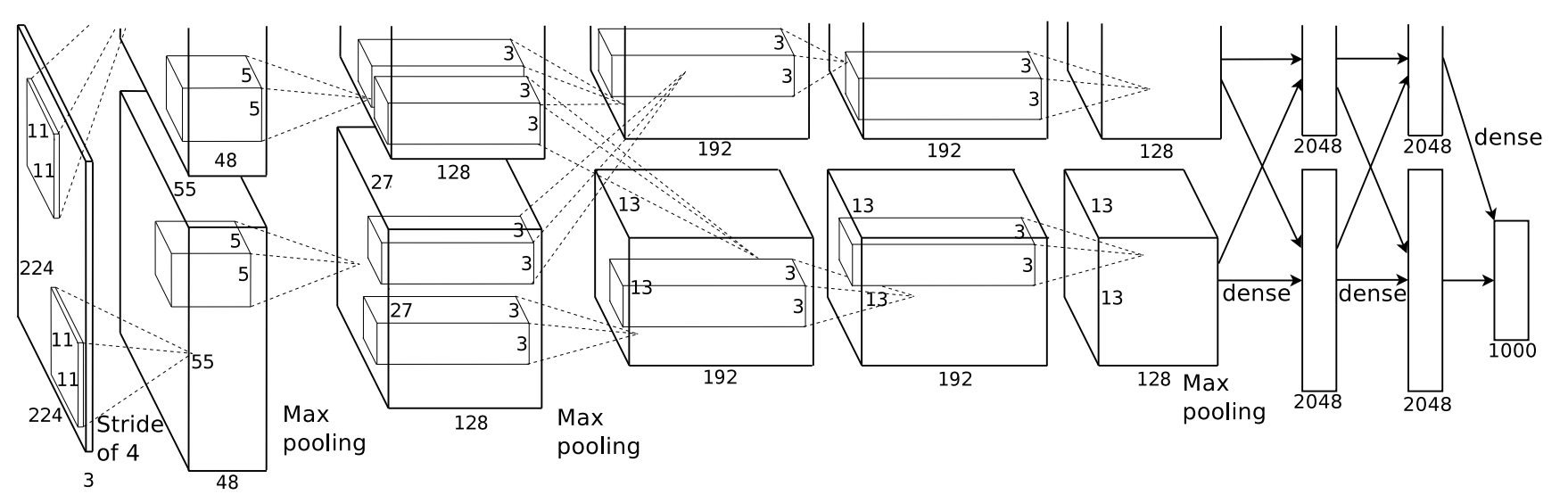
Example 1.1 (손글씨 숫자 인식)
아래 이미지는 네 개의 층을 사용하는 딥러닝 모델이 MNIST 손글씨 이미지를 변환해서 최종적으로 이미지가 가리키는 숫자를 예측하는 과정을 보여준다.
데이터가 하나의 층을 지날 때마다 원본 이미지와는 보다 많이 다른 방식으로 데이터로 변환되며, 최종적으로 (사람은 이해할 수 없지만) 모델은 어떻게든 적절한 예측값을 계산할 수 있게 된다.

1.2. 딥러닝의 성과와 전망#
2012년 이미지 분석 분야에서 딥러닝의 성과가 확인되고 2016년 알파고 바둑 프로그램의 등장으로 딥러닝으로 인한 혁신이 본격화되었다. 딥러닝이 가져올 가능성은 확실히 알 수 없지만 인간의 삶을 획기적으로 변화시킬 것으로 기대된다.
그럼에도 불구하여 딥러닝의 발전에 대한 너무 큰 기대를 가지면 위험할 수도 있다. 실제로 1960년대와 1990년을 전후에서 AI 붐이 있었지만 기대에 대한 실망이 너무 커서 1970년대에 1차, 1990년대의 2차 AI 겨울(AI winter)가 왔었다. 현재 진행중인 3차 AI 붐이 실제로 어떻게 전개될 것인가는 아무도 모른다.
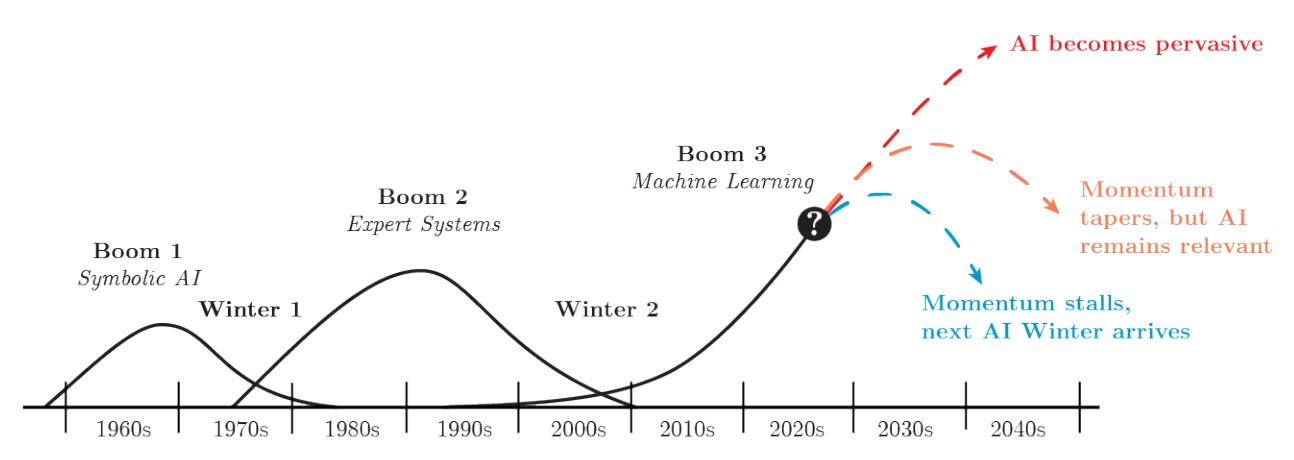
1.3. 머신러닝 역사#
딥러닝 발전 이전의 머신러닝의 역사를 간단하게 살펴본다.
초창기 신경망
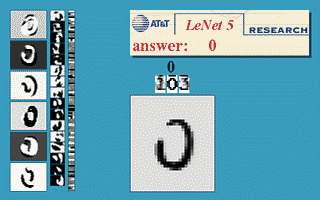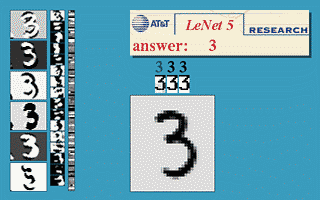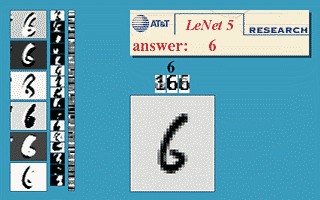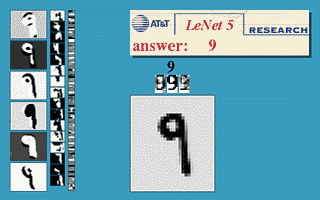
신경망의 기본 아이디어는 1950년대부터 연구되기 시작했다. 하지만 역전파를 어느 정도 제대로 실행할 수 있게 된 1990년 전후까지 제대로된 신경망 활용은 없었다. 최초의 성공적인 신경망 활용은 1989년 미국의 벨 연구소에서 이루어졌다. 얀 르쿤Yann LeCun이 손글씨 숫자 이미지를 자동으로 분류하는 시스템인 LeNet 합성곱 신경망을 소개했으며 1990년대에 미국 우체국에서 우편번호를 자동 분류하는 데에 이용되었다.
결정트리, 랜덤 포레스트, 그레이디언트 부스팅
2000년대에 들어서면서 결정트리decision tree가 인기를 얻기 시작했다. 많은 수의 결정트리에 앙상블ensemble 기법을 적용한 랜덤 포레스트random forest가 2010년 경에 소개되어 커널 기법보다 선호되기 시작했다.
기존에 주어진 모델의 성능을 좀 더 향상시키는 그레이디언트 부스팅gradient boosting 기법이 2014년 소개되었으며 랜덤 포레스트의 성능을 뛰어 넘는 모델에 활용되었다. 현재까지도 딥러닝과 더불어 가장 많이 활용되는 기법중의 하나다.
딥러닝의 본격적 발전 기점
2011년 GPU를 활용한 딥러닝 모델 훈련이 시작되었으며, 이미지 분류 경진대회인 이미지넷의 ILSVRC의 2012년 대회에서 이전 년도 우승 모델의 성능을 훨씬 뛰어 넘는 합성곱 신경망convolutional neural network(CNN) 모델이 소개되면서 딥러닝에 대한 관심이 폭발적으로 증가했다.
2011년 최고 모델의 성능: 74% 정도의 top-5 정확도
2012년 최고 모델의 성능: 84% 정도의 top-5 정확도
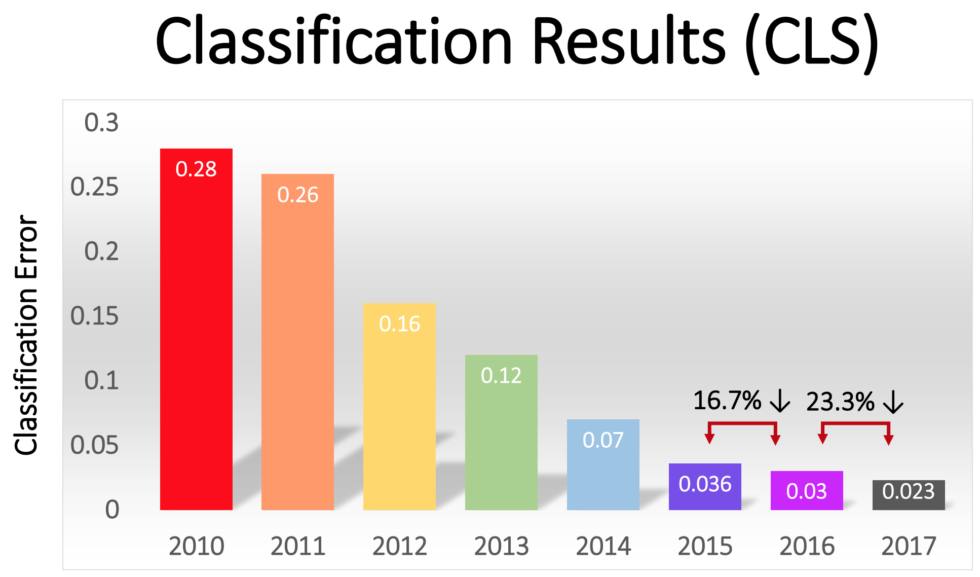
이미지넷 경진대회는 2017년 97.7% 정도의 top-5 정확도 성능을 보인 우승 모델이 소개된 이후로 더 이상 진행되지 않는다. 이는 이미지 분류 과제가 완성되었음을 의미한다.
ILSVRC와 top-5 정확도
분류 모델의 성능을 평가할 때 top-5 정확도, top-1 정확도, top-5 오류율, top-1 오류율 등을 사용한다. ILSVRC 이미지 분류 경진대회는 1,400만 개 이상의 이미지를 1,000 개의 범주로 분류하는 모델을 평가한다. 분류 모델은 각 이미지에 대해 이미지에 담긴 객체(사람, 사물, 품종 등)가 속하는 범주를 1,000개의 범주 전체에 대해 확률을 계산한다. 이때 가장 높은 확률을 가진 5개의 범주에 정답이 포함될 확률이 top-5 정확도이다. top-1 정확도는 가장 높은 확률을 갖는 범주가 정답일 확율을 의미한다. 정답이 아닐 확률을 계산하면 top-5 오류율 또는 top-1 오류율이 계산된다.
top-1이 아닌 top-5를 모델 성능의 평가 기준으로 사용하는 이유는 경우에 따라 매우 유사한 범주가 많아 인간조차도 정확히 분류하기 어려울 수 있다는 점을 고려했기 때문이다. 예를 들어, 고양이와 삵, 개와 늑대 등은 이미지로 쉽게 분류하기 어려운데 이런 경우 라벨 자체가 틀릴 수도 있다. 실제로 ILSVRC 경진대회에 사용된 데이터셋에 사용된 라벨의 5% 정도는 잘못 지정됐다.
딥러닝 발전 동력
이미지 분석과 시계열 데이터 분석이 2012년 이후 획기적으로 발전하였지만 이런 획기적 발전에 기여한 아래 기법은 이미 1990년대에 제시되었다.
1990년: 합성곱 신경망과 역전파
1997년: LSTM(Long Short-Term Memory)
1990년대와 2010년대의 차이를 만든 요소는 다음 세 가지다.
하드웨어
데이터
알고리즘