9. 합성곱 신경망#
감사의 글
아래 내용은 프랑소와 숄레의 Deep Learning with Python(2판)의 소스코드 내용을 참고해서 작성되었습니다. 자료를 공개한 저자에게 진심어린 감사를 전합니다.
소스코드
여기서 언급되는 코드를 (구글 코랩) 합성곱 신경망에서 직접 실행할 수 있다.
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
합성곱 신경망
데이터 증식
모델 재활용: 전이 학습
9.1. 합성곱 신경망#
2011년부터 2015년 사이에 컴퓨터 비전 분야에서 딥러닝 기법이 획기적으로 발전하였다. 그 결과 지금은 사진 검색, 자율주행, 로봇공학, 의학 진단 프로그램, 얼굴 인식 등 일상의 많은 영역에서 딥러닝 모델이 사용되고 있다.
컴퓨터 비전 분야에서 일반적으로 가장 많이 사용되는 딥러닝 모델은 CNN으로 불리는 합성곱 신경망convolutional neural networks이다. 여기서는 이미지 분류 문제에 CNN을 적용하는 방법을 소개한다.
9.1.1. MNIST 데이터셋 분류 CNN 모델#
아래 층들을 이용하여 모델을 함수형 API 방식으로 선언한다.
Input(): 입력층shape=(28, 28, 1). 훈련 샘플의 모양 지정.훈련 샘플은 원래
(28, 28)모양의 흑백 손글씨 사진이었음.2차원 어레이를 3차원 어레이로 변환함.
Conv2D: 합성곱 층filters: 필터 수 지정. 층 출력값의 채널 수로 사용됨. 하나의 필터를 이용해 하나의 채널 생성.kernel_size: 합성곱 연산에 사용되는 커널의 크기. 일반적으로 3 사용.출력값: 3D 텐서 (높이, 너비, 채널수).
MaxPooling2D: 맥스풀링 층입력 사진의 높이와 너비를 지정된 비율만큼 축소. 즉 사진 크기 축소 변형 실행.
출력값: 3D 텐서 (축소된높이, 축소된너비, 채널수).
Flatten: 평탄화 층입력 샘플을 모두 1차원 텐서로 변환
(None, 높이, 너비, 채널수)모양의 입력 배치를(None, 높이*너비*채널수)모양의 배치 텐서로 변환
Dense: 밀집 층CNN 모델의 출력층은 일반적으로 밀집층 사용
입력값:
Flatten()층을 통과한(None, N)모양의 2차원 텐서
# 입력층
inputs = keras.Input(shape=(28, 28, 1))
# 은닉층
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
# 출력층으로 넘기기 전에 1차원 텐서로 변환
x = layers.Flatten()(x)
# 출력층
outputs = layers.Dense(10, activation="softmax")(x)
# 모델
model = keras.Model(inputs=inputs, outputs=outputs)
모델 구성 요약
MaxPooling2D 층과 Flatten 층엔 파라미터가 전혀 사용되지 않는다.
왜 그런지를 포함해서 각 층별로 출력값의 모양과 사용되는 파라미터의 수에 대해
나중에 자세히 다룬다.
>>> model.summary()

MNIST 이미지 분류 훈련
모델 훈련은 이전과 동일하다.
다만 훈련 샘플은 (28, 28, 1) 모양의 3차원 텐서이어야 한다.
이유는 합성곱 층(Conv2D)이 3차원 텐서를 입력값으로 받기 때문이며,
따라서 Input() 함수의 인자로 (28, 28, 1) 모양이 지정되었다.
지금까지 입력층으로 사용한 Dense 층은 입력 샘플의 모양이 1차원 텐서, 즉 벡터이어야 했고,
따라서 2차원 텐서인 MNIST 데이터셋의 샘플들을 모두
1차원 텐서로 변형한 다음에 훈련셋으로 활용하였다.
반면에 여기서는 3차원 텐서 이미지로 오히려 차원을 키우는 전처리를 실행한다.
또한 항목의 값을 0과 1사이의 값을 갖는 부동소수점으로 변환한다.
훈련셋 준비
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
모델 컴파일과 훈련
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy", # 레이블이 정수인 경우
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
테스트셋에 대한 정확도가 99% 정도로 이전에 사용한 Sequential 모델보다 훨씬 좋다.
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> print(f"테스트 정확도: {test_acc:.3f}")
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9894 - loss: 0.0410
테스트 정확도: 0.991
9.1.2. 합성곱 연산#
합성곱 층(Conv2D)에서 입력값을 변환하는 과정은 Dense 층에서의 변환과 다르다.
차이점의 핵심은 아핀 변환을 적용하는 방식에 있다.
Dense층: 입력값의 전체 특성을 대상으로 한 번의 아핀 변환 적용Conv2D층:kernel_size로 지정된 크기의 공간에 대해 여러 개의 아핀 변환 적용. 예를 들어,kernel_size=3인 경우3x3크기의 영역에 대해 아핀 변환 적용.
직관적으로 풀어서 설명하면 다음과 같다.
Dense층: 입력 샘플의 모든 특성을 대상으로 가중치와 편향을 적용하여 지정된 개수의 특성으로 구성된 텐서로 데이터를 변환함. 예를 들어,Dense(64, activation="relu")에 MNIST 데이터셋을 입력하면 흑백 손글씨 이미지에 포함된 784개 특성에 아핀 변환을 적용하여 64개의 특성으로 구성된 텐서 생성.Conv2D층: 예를 들어kernel_size=3으로 설정된 경우3x3크기의 영역에 대해 아핀 변환 적용. 이 과정을 입력 이미지 전체 영역에 반복적으로 적용. 주어진 커널 사이지의 영역에 존재하는 패턴을 파악하는 기능 수행.
합성곱 층의 특징
합성곱 층의 특징은 크게 다음 두 가지로 요약된다.
첫째, 위치와 무관한 패턴을 찾아낸다. 즉, 서로 다른 위치에 있는 동일한 패턴은 동일한 값으로 계산된다.

둘째, Con2D 층 여러 개를 연속적으로 통과시키면 보다 복잡한 패턴을 파악할 수 있다.
아래 층에서는 단순한 패턴을 인식하고, 위 층으로 진행할 수록 이미지에 포함된 보다 복잡한 패턴을 파악한다.

특성맵(채널), 필터, 출력맵
합성곱 연산의 작동법을 이해하려면 아래 세 개념을 이해해야 한다.
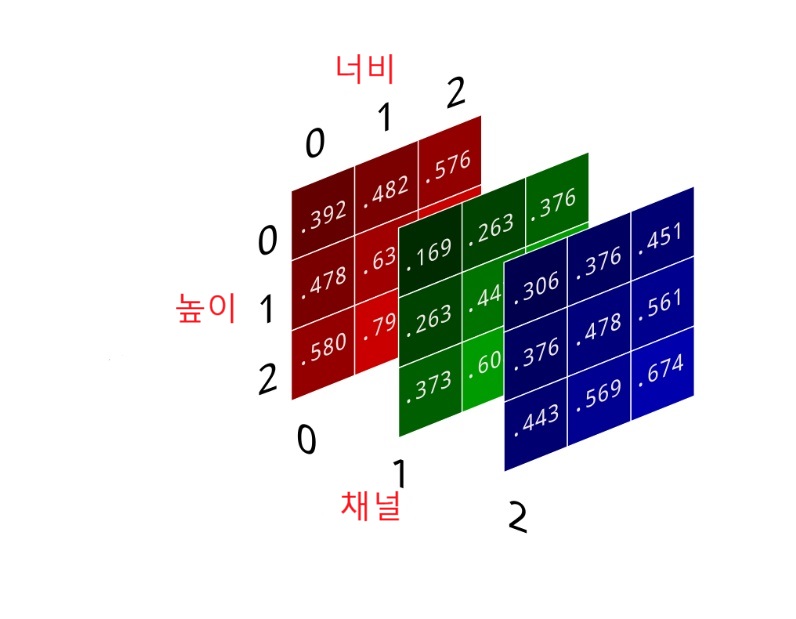
채널channel:
특성맵feature map이라고도 불림.
(높이, 너비)모양의 2D 텐서.예제: MNIST 데이터셋에 포함된
(28, 28)모양의 흑백 이미지 샘플이(28, 28, 1)모양의 채널(특성맵) 한 개로 구성된 3차원 텐서로 변형되어 입력 데이터로 사용됨.예제: 컬러사진의 경우 세 개의 채널(특성맵)로 구성됨.
이미지에 포함된 채널(특성맵)의 수를 깊이라 부름.
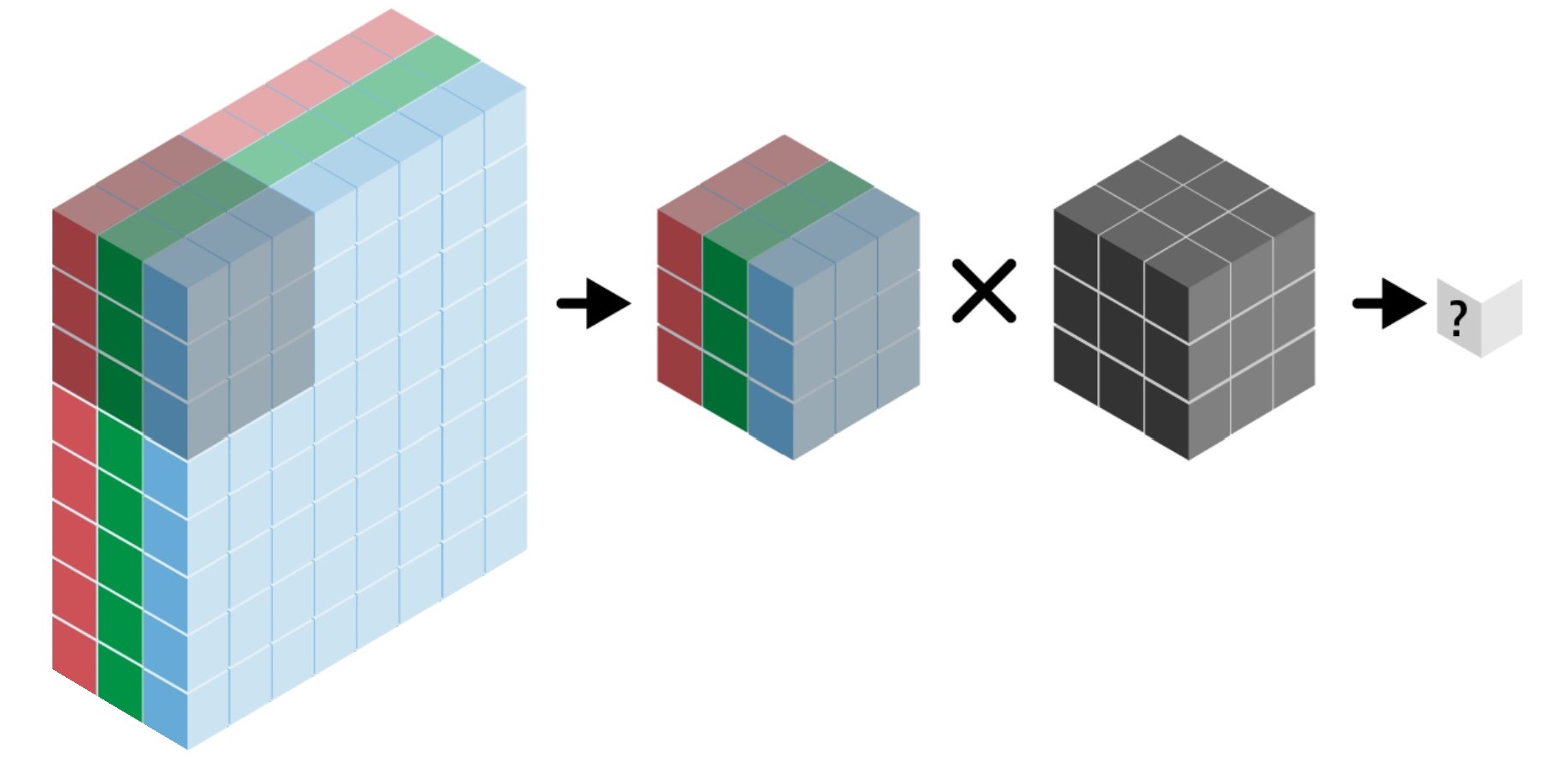
필터filter:
kernel_size를 이용한 3D 텐서.예제:
kernel_size=3인 경우 필터는(3, 3, 입력샘플의깊이)모양의 3D 텐서.필터 수:
filters인자에 의해 결정됨.
출력맵response map: 입력 샘플을 대상으로 하나의 필터를 적용해서 생성된 하나의 특성맵(채널). 필터 수만큼의 출력맵 생성.
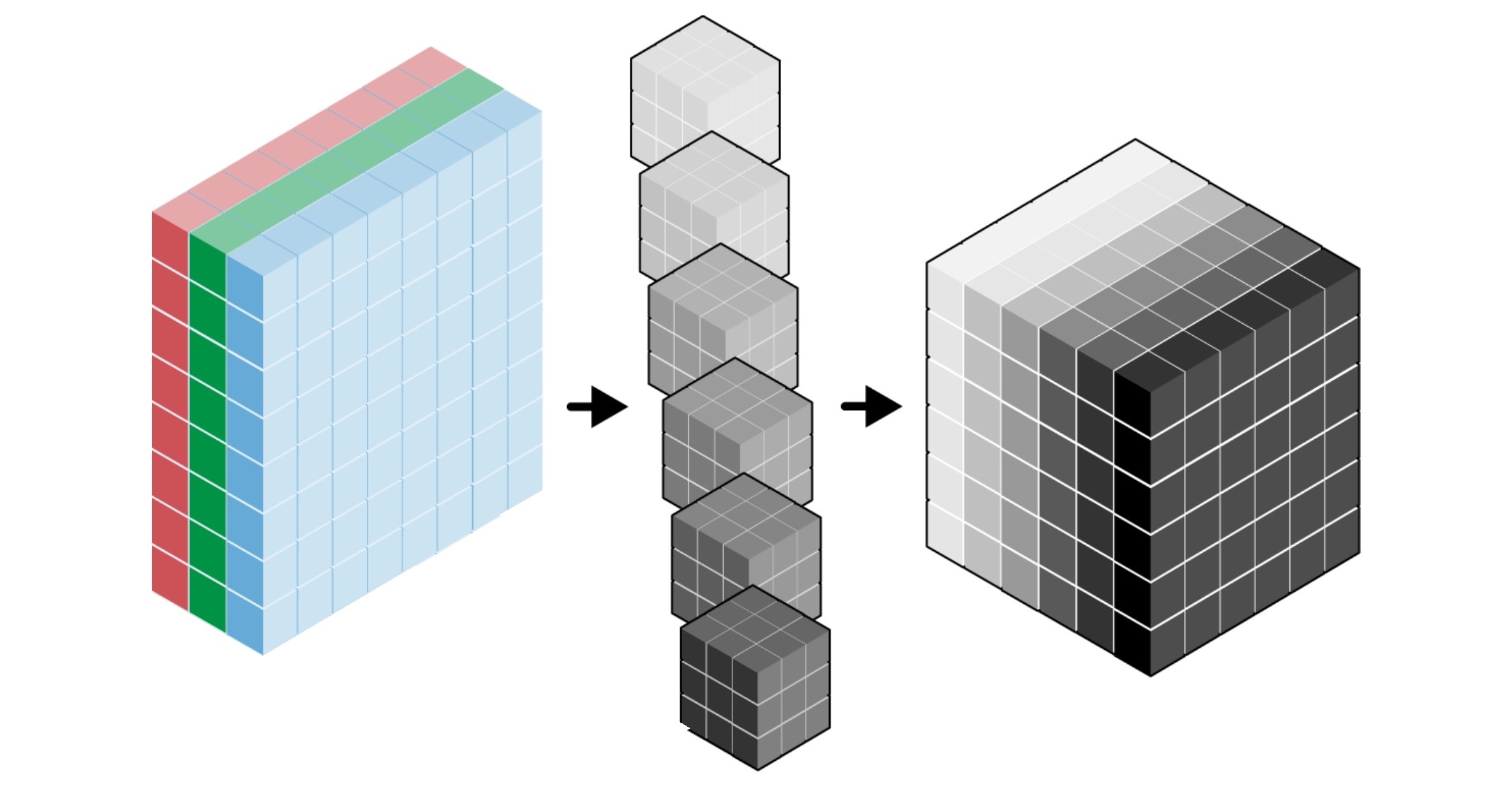
컬러 이미지와 채널
컬러 이미지는 R(red), G(green), B(blue) 세 개의 채털로 구성된다. 각각의 채널은 2차원 어레이로 다뤄지기에 하나의 컬러 이미지는 세 개의 채널을 모은 3차원 어레이로 표현된다.

필터 적용
아래 그림은 필터의 모양과 동일한 크기의 국소 텐서 하나를 대상으로 하나의 필터를 적용하여 하나의 값을 생성하는 과정을 보여준다.
출력맵
하나의 필터를 슬라이딩 시키면서 입력 텐서 전체를 대상으로 위 과정을 적용하여 한 개의 출력맵을 생성한다. 아래 그림은 (5, 5, 1) 모양의 입력 텐서를 대상으로 (3, 3, 1) 모양의 필터 하나를 적용하여 (3, 3, 1) 모양의 출력맵을 생성하는 과정을 보여준다. 단, 편향은 0이라고 가정한다.
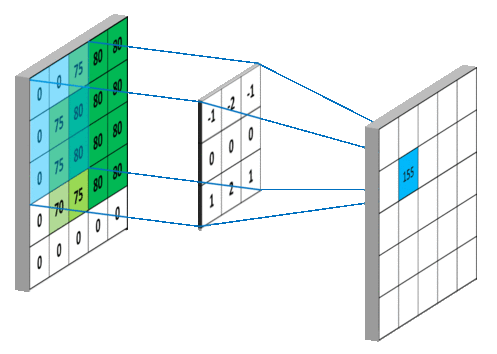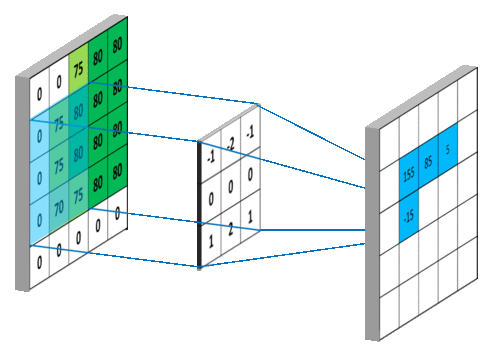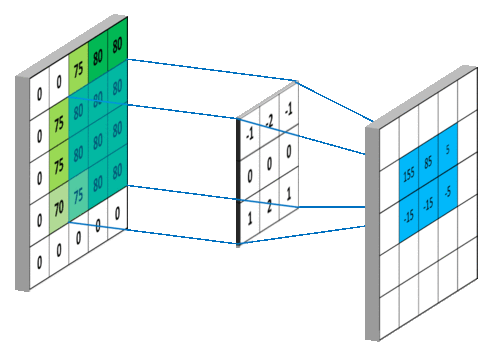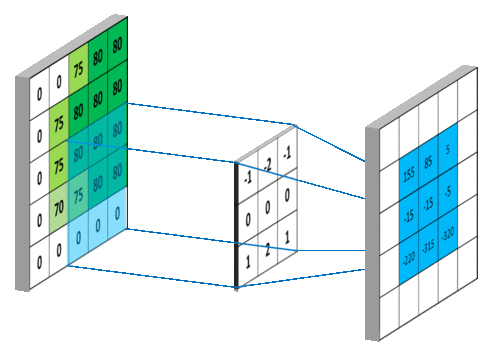
예를 들어 출력맵의 맨 상단 왼쪽에 위치한 155가 계산되는 과정은 다음과 같으며 이와 같은 방식으로 파랑색으로 표시된 높이와 너비 각각 3인 2차원 텐서 항목의 값들이 정해진다.
0 * -1 + 0 * -2 + 75 * -1 +
0 * 0 + 75 * 0 + 80 * 0 +
0 * 1 + 75 * 2 + 80 * 1 +
0
= 155
필터와 출력맵
출력 텐서의 채널 수, 즉 출력맵의 개수는 사용되는 필터의 개수와 동일하다. 예를 들어 아래 그림은 6개의 필터를 적용하면 최종적으로 6개의 출력맵(채널)으로 구성된 출력 텐서가 생성된다.
입력 텐서: (8, 8, 3) 모양의 텐서
필터: (3, 3, 3) 모양의 텐서
커널 크기(
kernel_size): 3, 즉 세로, 가로 크기가 (3, 3)으로 지정.입력 텐서의 깊이: 3. 필터의 세 번째 항목은 입력 텐서의 깊이로 지정됨. 즉, 커널 크기와 무관함.
출력 텐서: (6, 6, 6) 모양의 텐서
필터 수가 6이기에 출력 텐서의 깊이가 6이 됨.
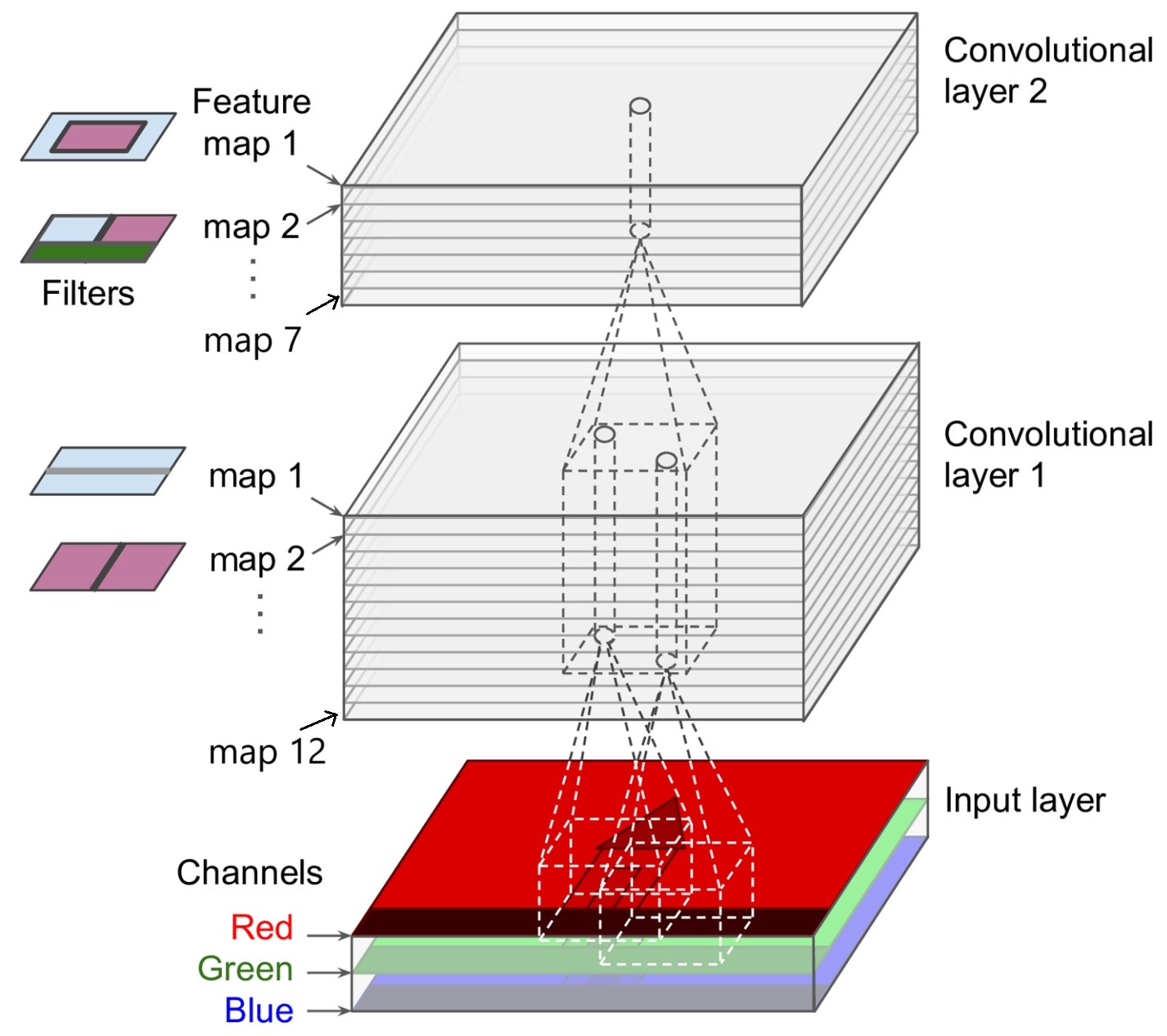
합성곱 층 연속 적용
Conv2D 층을 통과할 때 마다 동일한 작업이 반복된다.
앞서 패턴 공간의 계층에서 설명했듯이
위쪽의 Conv2D 층을 통과할 수록 보다 복잡한 구조의 패턴을 알아낸다.
입력 샘플: 3개의 채털로 구성된 칼라 사진
첫째
Conv2D층: 필터 12개둘째
Conv2D층: 필터 7개
합성곱 층 학습 파라미터
Dense 층은 아핀 변환에 필요한 가중치와 편향을 학습시킨다.
반면에 합성곱 신경망 모델은 Conv2D 층에서 필터로 사용되는 텐서들을 학습시킨다.
따라서 모델 훈련 과정에서 Conv2D 층에서 학습되어야 하는 파라미터의 수는
커널 크기 kernel_size와 필터 수 filters에 의해 결정된다.
패딩과 보폭
필터를 적용하여 생성된 출력 특성맵의 모양이 입력 특성맵(채널)의 모양과 다를 수 있다. 실제로 출력 특성맵의 높이와 너비는 패딩padding의 사용 여부와 보폭stride의 크기에 의해 결정된다.
keras.layers.Conv2D(
filters,
kernel_size,
strides=(1, 1), # 보폭
padding="valid", # 패딩
...,
)
아래 세 개의 그림은 입력 특성맵의 높이와 너비가 5x5일 때
패딩의 사용 여부와 보폭의 크기에 따라
출력 특성맵의 높이와 너비가 어떻게 달라지는가를 보여준다.
경우 1: 패딩 없음, 보폭은 1.
strides와padding키워드 인자의 기본값 사용필터가 1칸씩 슬라이딩
출력 특성맵의 깊이와 너비:
3x3출력 특성맥의 깊이와 너비가 줄어듦.
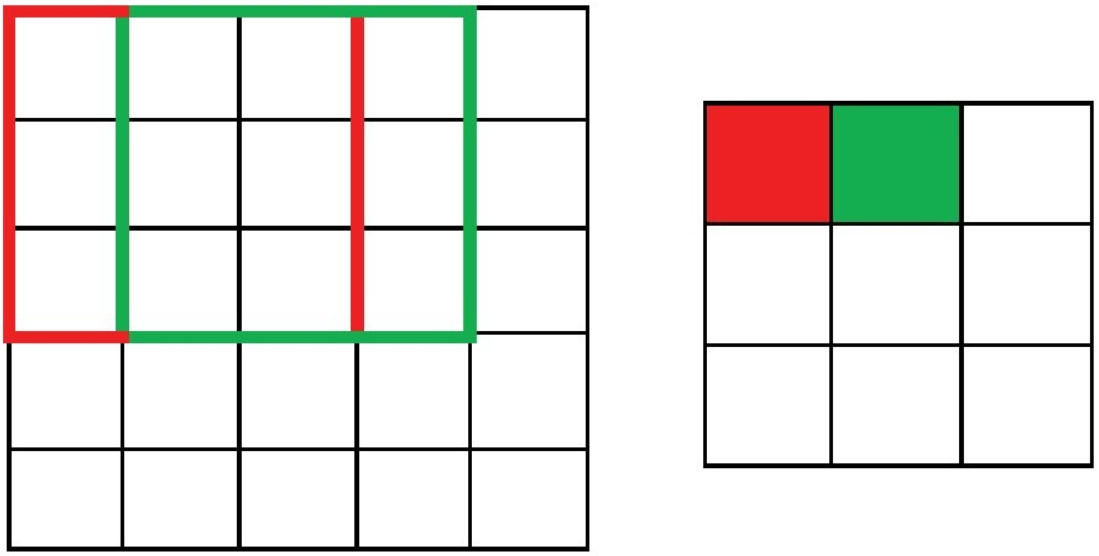
경우 2: 패딩 없음, 보폭은 2.
strides=2또는strides=(2, 2)필터가 2칸씩 건너 뛰며 슬라이딩
출력 특성맵의 깊이와 너비:
2x2출력 특성맵의 깊이와 너비가 보폭의 반비례해서 줄어듦.
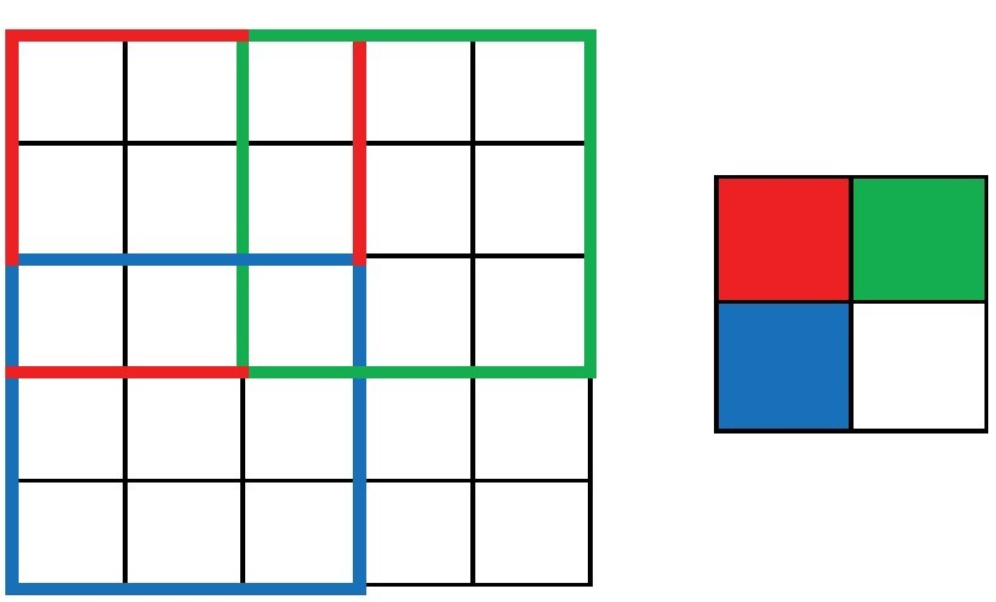
경우 3: 패딩 있음, 보폭은 1.
padding="same"입력 텐서의 테두리에 0으로 채워진 패딩 추가.
출력 특성맵의 깊이와 너비가 동일하게 유지됨.
경우 4: 패딩을 사용하고 보폭이 1보다 큰 경우는 굳이 사용할 필요 없음. 이유는 보폭이 1보다 크기에 출력 특성맵의 깊이와 너비가 어차피 보폭에 반비례해서 줄어들기 때문임.
9.1.3. 맥스 풀링#
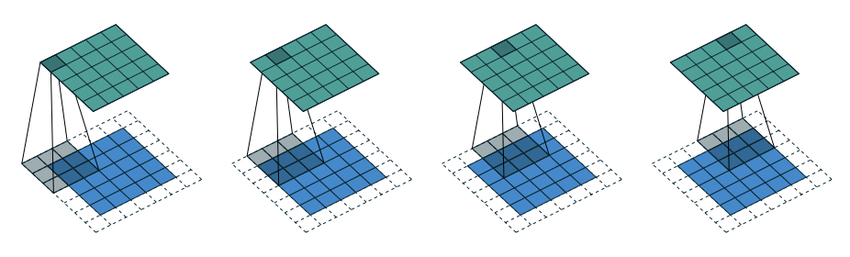
합성곱 신경망의 전형적인 구조는 아래 그림에서처럼 합성곱 층과 풀링 층을 번갈아 가며 사용한다.
맥스 풀링 기능
풀링 층은 일정 크기의 영역에서 하나의 값만 선택하여 특성맵의 높이와 너비를 일정 비율로 줄인다.
keras.layers.MaxPooling2D(
pool_size=(2, 2), # 풀링 크기
strides=None,
padding="valid",
...
)
일정 영역에서 최댓값을 선택하는 맥스 풀링(max-pooling) 층이 가장 많이 사용된다.
예를 들어 아래 그림은 2x2영역에서 최댓값만 선택하는 과정을
보폭 2만큼씩 이동하며 반복한 결과를 보여준다.
결과적으로 입력 사진의 높이와 너비를 각각 1/2씩 줄인 사진이 생성된다.
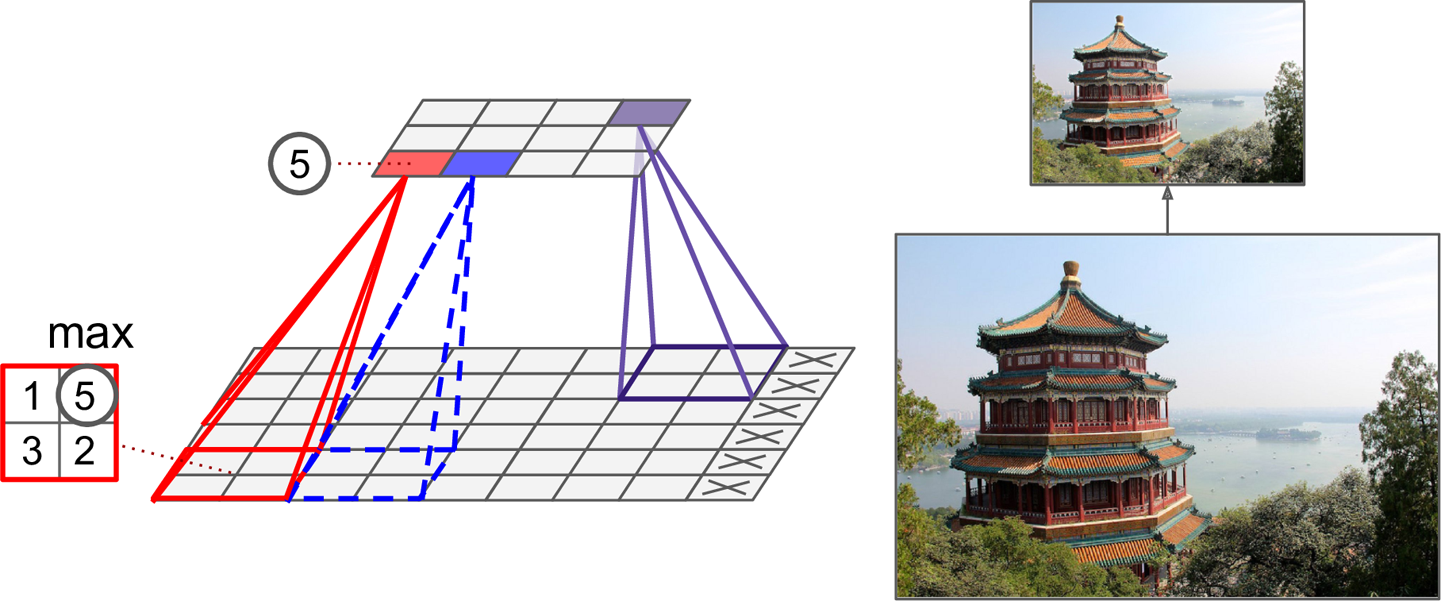
맥스 풀링은 입력 샘플의 채널 단위로 적용된다.
따라서 사진의 가로, 세로 사이즈는 줄어들지만 채널 수는 그대로 유지한다.
예를 들어, 만약 x가 (26, 26, 32) 모양의 3D 텐서이면
다음 맥스 풀링 층의 출력값은 (13, 13, 32) 모양의 3D 텐서가 된다.
layers.MaxPooling2D(pool_size=2)(x)
맥스 풀링 사용 이유
맥스 풀링 층을 합성곱 층(Conv2D)과 함께 사용하는 이유는 두 가지이다.
모델이 훈련 중에 학습해야할 파라미터의 수를 줄인다. 단, 다음에 주의한다.
합성곱 층 자체에서 사용되는 파라미터의 수는 맥스 풀링 층에 줄어들지 않는다.
반면에 합성곱 층에 이어서
Flatten층을 거쳐Dense층에 전달되는 입력 샘플의 특성 수가 적어지며, 결국Dense층에서 필요한 가중치와 편향 파라미터의 수가 획기적으로 줄어든다.
상위 합성곱 층으로 이동할 수록 입력 데이터의 보다 넓은 영역에 대한 함축된 정보를 얻을 수 있다. 또한 이 과정을 통해 이미지에서의 위치와 무관한 특정 패턴을 모델이 보다 용이하게 학습할 수 있게 된다.
아래 코드는 맥스 풀링 층을 사용하지 않는 경우 가중치 파라미터의 수가 엄청나게 증가함을 잘 보여준다.
맥스 풀링 사용하는 경우: 104,202개
그렇지 않은 경우: 712,202개
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model_no_max_pool = keras.Model(inputs=inputs, outputs=outputs)
>>> model.summary()

9.2. 합성곱 신경망 실전 활용 예제#
9.2.1. 작은 데이터셋과 딥러닝 모델#
이미지 분류 모델을 훈련시킬 때 데이터셋의 크기가 그다지 크지 않은 경우가 일반적이다. 즉, 데이터셋의 크기가 적게는 몇 백 개에서 많게는 몇 만 개 정도이다. 여기서 훈련시켜야 하는 모델은 개와 고양이 사진을 대상으로 하는 이진 분류 합성곱 신경망 모델이다. 실전 상황을 재현하기 위해 5천 개의 이미지로 이루어진 작은 데이터셋을 사용한다.
합성곱 신경망 모델은 작은 크기의 데이터셋으로도 어느 정도의 성능을 얻을 수 있다. 또한 데이터 증식 기법을 이용하여 훈련셋의 크기를 늘리거나 기존에 잘 훈련된 모델을 재활용하면 보다 좋은 성능의 모델을 구현할 수 있다.
9.2.2. 데이터 다운로드#
다양한 종류의 데이터 모델을 활용할 수 있는 캐글Kaggle에서 훈련에 필요한 데이터셋을 다운로드하려면 다음 사항을 먼저 확인해야 한다.
캐글 계정을 갖고 있어야 하며, 로그인된 상태에서 아래 두 과정을 먼저 해결해야 한다.
캐글에 로그인한 후 “Account” 페이지의 계정 설정 창에 있는 “API” 항목에서 “Create New Token”을 생성하여 다운로드한다.
캐글: Dogs vs. Cats를 방문해서 “I Understand and Accept” 버튼을 클릭해야 한다.
다운로드된 데이터셋은 총 25,000장의 강아지와 고양이 사진으로 구성되었으며 570MB 정도로 꽤 크다. 강아지 사진 고양이 사진이 각각 12,500 장씩 포함되어 있으며, 사진들의 크기가 다음과 같이 일정하지 않다.

훈련셋, 검증셋, 테스트셋 준비
25,000 장의 사진 중에서 총 5,000 장의 사진만 사용해서 합성곱 신경망 모델을 훈련시키려 한다.
훈련셋: 강아지와 고양이 각각 1,000 장
검증셋: 강아지와 고양이 각각 500 장
테스트셋: 강아지와 고양이 각각 1,000 장
여기서는 무작위로 선택된 5,000 장의 사진이 현재 디렉토리를 기준으로 다음과 같이 구성된 하위 디렉토리에 저장되어 있다고 가정한다. 5천장 선택과 저장 과정은 (구글 코랩) 합성곱 신경망을 참고한다.
cats_vs_dogs_small/
...train/
......cat/
......dog/
...validation/
......cat/
......dog/
...test/
......cat/
......dog/
9.2.3. 모델 구성#
CNN 모델은 앞서 설명한대로 Conv2D와 MaxPooling2D 레이어를
연속에서 쌓는 방식을 사용한다.
앞서 소개한 모델 보다 Conv2D 층과 MaxPooling2D 층을 두 번 더 쌓는다.
이유는 보다 큰 이미지를 훈련 데이터로 사용하면서
동시에 보다 복잡한 문제를 해결해야 하기 때문이다.
합성곱 층과 맥스 풀링 층을 더 많이 쌓으면
모델이 활용할 수 있는 정보를 보다 많이 저장할 수 있으면서
동시에 최종 맥스 풀링 층의 출력맵의 크기를 더 작게 만든다.
모델 지정
아래 모델의 층 구성을 요약하면 다음과 같다.
입력층: 입력 샘플의 모양을
(180, 180, 3)으로 지정. 사진의 크기가 제 각각이기에 먼저 지정된 크기의 텐서로 변환을 해주는 전처리 과정이 필요함.Rescaling(1./255)층: 0에서 255 사이의 값을 0에서 1 사이의 값으로 변환하는 용도로 사용Conv2D층에서 지정되는 필터의 수는 32에서 256으로 점차 키워짐. 맥스풀링 층에 의해 사진의 크기가 줄어드는 대신 필터 수를 늘려 출력맵의 개수를 키워주면서 모델의 정보 저장 능력을 유지시키기 위함임.MaxPooling2D층을Conv2D층과 함께 사용.Flatten층에 최종적으로(7, 7, 256)크기의 텐서가 입력값으로 전달됨.출력층: 이항 분류 모델이기에 한 개의 유닛과 시그모이드 활성화 함수 사용하는
Dense층으로 지정.
# 입력층
inputs = keras.Input(shape=(180, 180, 3))
# 은닉층
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
모델 컴파일
이진 분류 모델이기에 손실 함수는 binary_crossentropy로 정한다.
분류 모델의 평가지표는 일반적으로 정확도, 정밀도, 재현율 중에 하나 이상을 선택한다.
훈련 데이터셋에 포함된 강아지와 고양이의 비율이 동일하게 지정되기에
여기서는 정확도를 평가지표로 사용한다.
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
9.2.4. 데이터 전처리와 모델 훈련#
데이터 불러오기와 전처리
강아지-고양이 데이터셋에 포함된 사진들의 크기가 제 각각이기에
모든 입력 사진을 (180, 180, 3) 모양의 텐서로 변환하는
케라스의 image_dataset_from_directory() 함수를 이용하면 데이터 변환뿐만 아니라
지정된 크기의 배치로 구성된 훈련셋, 검증셋, 테스트셋을 쉽게 생성할 수 있다.
아래 코드는 cats_vs_dogs_small의 하위 디렉토리인 train, validation, test 디렉토리에 포함된
사진들을 무작위로 섞어 크기가 32인 배치들로 구성된
훈련셋, 검증셋, 테스트셋을 지정한다.
from tensorflow.keras.utils import image_dataset_from_directory
new_base_dir = pathlib.Path("cats_vs_dogs_small")
train_dataset = image_dataset_from_directory(
new_base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / "test",
image_size=(180, 180),
batch_size=32)
예를 들어 train_dataset에 포함된 각각의 배치는 (32, 180, 180, 3) 모양의 4차원 입력 텐서와
(32,) 모양의 1차원 타깃으로 구성된다.
>>> for data_batch, labels_batch in train_dataset:
... print("data batch shape:", data_batch.shape)
... print("labels batch shape:", labels_batch.shape)
... break
data batch shape: (32, 180, 180, 3)
labels batch shape: (32,)
모델 훈련
ModelCheckpoint 콜백을 이용하여 검증셋에 대한 손실값("val_loss")을
기준으로 최고 성능의 모델을 저장한다.
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch",
save_best_only=True,
monitor="val_loss")
]
크기가 32인 배치 단위로 이미 묶여 있기에 fit() 메서드를 호출할 때 배치 크기(batch_size)는 지정할 필요가 없다.
또한 train_dataset과 validation_dataset이 모두 입력 데이터셋과 타깃 데이터셋의 튜플로 구성되어 있음에 주의한다.
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)
과대 적합이 10번 정도의 에포크 이후에 빠르게 발생한다.

훈련된 최고 성능의 모델에 대한 테스트셋에 대한 정확도가 70% 정도의 정확도로 그렇게 높지 않다. 과대적합이 매우 빠르게 발생했기 때문인데 이는 훈련셋의 크기가 2,000 정도로 매우 작기 때문이다.
9.3. 데이터 증식#
데이터 증식 기법을 사용하여 훈련셋의 크기를 키우는 효과를 추가하면, 과대적합이 보다 늦게 발생하여 모델의 일반화 성능이 올라간다. 참고로 데이터 증식은 새로운 훈련셋을 추가하는 것이 아니다. 대신 그런 효과를 낼 뿐이다.
예를 들어 아래 코드의 data_augmentation는 Sequential 모델을 이용하여 간단하게
데이터 증식을 지원하는 층을 지정한다.
RandomFlip(): 사진을 50%의 확률로 지정된 방향으로 반전.RandomRotation(): 사진을 지정된 범위 안에서 임의로 좌우로 회전RandomZoom(): 사진을 지정된 범위 안에서 임의로 확대 및 축소
하나의 사진이 입력되면 앞서 설명한 세 개의 층을 통과하면서 사진이 무작위적으로 반전/회전/확대/축소 된다. 그리고 에포크가 바뀔 때마다 동일한 사진이 변하는 방식은 매번 달라진다. 즉 하나의 사진이 매 에포크마다 다른 방식으로 무작위적으로 변환되어 훈련에 사용되어 훈련 샘플의 다양성이 커진다.
data_augmentation = keras.Sequential(
[layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2)]
)
훈련셋의 이미지 샘플 하나를 대상으로 데이터 증식 층을 아홉 번 적용한 결과를 다음고 같다.

데이터 증식 층을 이용하여 모델 구성을 다시 한다. 과대적합을 최대한 방지하기 위해 출력층 바로 이전에 드롭아웃(Dropout) 층도 추가한다.
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
과대 적합이 보다 늦게 발생한다.

테스트셋에 대한 정확도가 83% 정도로 올라간다.
Conv2D와 MaxPooling2D 층을 더 쌓거나 층에 사용된 필터수를 늘리는 방식으로
모델의 성능을 90% 정도까지 끌어올릴 수는 있지만 그 이상은 어려울 것이다.
9.4. 모델 재활용#
적은 양의 데이터셋을 대상으로 훈련하는 것보다 대용량의 데이터셋을 이용하여 훈련하면 보다 좋은 성능의 모델을 구현할 수 있다. 하지만 대용량의 데이터를 구하기는 매우 어렵거나 아예 불가능할 수 있다. 하지만 유사한 목적으로 대용량의 훈련 데이터셋을 이용하여 사전에 훈련된 모델을 재활용하면 높은 성능의 모델을 얻을 수 있다.
여기서는 좋은 성능으로 잘 알려진 모델인 VGG16을 재활용하여 높은 성능의 강아지와 고양이 분류 모델을 구현하는 두 가지 방식을 소개한다.
전이 학습transfer learning
모델 미세조정model fine tuning
VGG16 모델
VGG16 모델은 ILSVRC 2014 경진대회에 참여해서 2등을 차지한 모델이다. 당시 훈련에 사용된 데이터셋은 120만 장의 이미지와 1,000개의 클래스로 구성되었으며 훈련은 여러 주(weeks)에 걸쳐서 진행되었다.
VGG16은 당시 1등을 차지한 모델인 GoogleNet 보다 인기가 높다.
이유는 VGG16가 최상위에 위치한 몇 개의 밀집층(Dense 층)을 제외한 나머지 층을
합성곱 신경망의 기본인 Conv2D와 MaxPooling2D 두 종류의 층만으로
구성해서 모델의 구조가 매우 단순하기 때문이다.
보다 자세한 소개는 1등보다 빛나는 2등, VGG16을
참고할 수 있다.
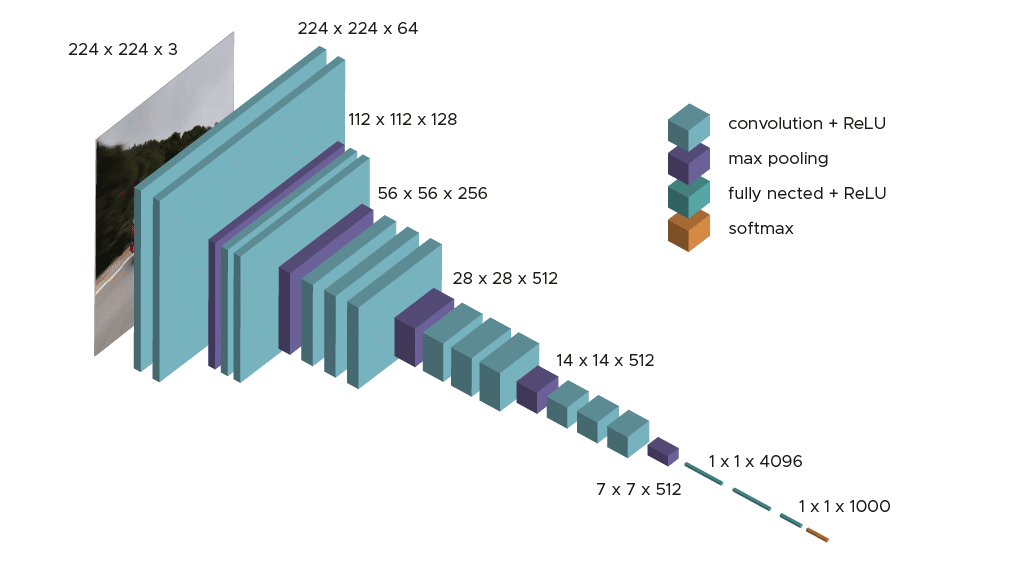
유명 합성곱 신경망 모델
ketas.applications 에 포함된 유명 합성곱 신경모델은 다음과 같다.
VGG16
Xception
ResNet
MobileNet
EfficientNet
DenseNet
등등
이미지넷(ImagNet) 소개
이미지넷(Imagenet)은 대용량의 이미지 데이터셋이며, ILSVRC 이미지 분류 경진대회에 사용된다. 이미지넷의 전체 데이터셋은 총 2만2천 개 정도의 클래스로 구분되는 동물, 사물 등의 객체를 담은 고화질 사진 1500만장 정도로 구성된다. 2017년까지 진행된 ILSVRC 경진대회는 보통 1000 개의 클래스로 구분되는 사물을 담은 1백만장 정도의 이미지를 이용한다.

9.4.1. 전이 학습#
전이 학습 기본 아이디어
사전에 잘 훈련된 모델은 새롭게 구현하고자 하는 모델과 일반적으로 다른 목적으로 구현되었다. 하지만 예를 들어 강아지와 고양이를 포함한 동물 및 기타 여러 사물을 분류할 목적으로 훈련된 모델은 기본적으로 강아지와 고양이를 분류하는 능력을 갖고 있어야 한다.
반면에 이항 분류 모델과 다중클래스 분류 모델은 기본적으로 출력층에서 서로 다른 종류의 값을 출력한다. 고양이와 강아지를 포함해서 총 1000개의 사물 클래스로 이미지를 분류하는 모델의 출력층은 1000개의 유닛과 softmax 등과 같은 활성화 함수를 사용할 것이지만 고양이-강아지 분류 모델은 1개의 유닛과 sigmoid 등과 같은 활성화 함수를 사용해야 한다.
따라서 기존 모델의 출력층을 포함하여 분류값을 직접적으로 예측하는 마지막 몇 개의 층 (일반적으로 밀집층)을 제외시킨 나머지 합성곱 층으로 이루어진 기저(베이스, base)만을 가져와서 그 위에 원하는 목적에 맞는 층을 새롭게 구성한다(아래 그림 참조).
학습 관점에 보았을 때 Conv2D 합성곱층과 MaxPooling2D 맥스풀링층으로 구성된 기저는
이미지의 일반적인 특성을 파악한 정보(가중치)를 포함하고 있기에
강아지/고양이 분류 모델의 기저로 사용될 수 있는 것이다.

VGG16 모델을 이용한 전이 학습
VGG16 합성곱 모델에서 밀집층(dense 층)을 제외한 나머지 합성곱 층으로만 이루어진 모델을 가져온다.
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
모델을 가져올 때 사용된 옵션의 의미는 다음과 같다.
weights="imagenet": Imagenet 데이터셋으로 훈련된 모델의 가중치 가져옴.include_top=False: 출력값을 결정하는 밀집층은 제외함.input_shape=(180, 180, 3): 앞서 준비해 놓은 데이터셋을 활용할 수 있도록 지정함. 사용자가 직접 지정해야 함. 지정하지 않으면 임의의 크기의 이미지를 처리할 수 있음. 층 별 출력 텐서의 모양의 변화 과정을 확인하기 위해 특정 모양으로 지정함.
가져온 모델을 요약하면 다음과 같다.
마지막 맥스풀링 층을 통과한 특성맵의 모양은 (5, 5, 512)이다.
>>> conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_19 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 180, 180, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 180, 180, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 90, 90, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 90, 90, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 90, 90, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 45, 45, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 45, 45, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 22, 22, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 22, 22, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 11, 11, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 5, 5, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
특성 추출
특성 추출feature extraction은 전이 학습에 사용되는 모델을 이용한
데이터 변환 과정을 의미한다.
여기서는 conv_base 기저를 특성 추출에 활용하는 두 가지 방식을 소개한다.
1) 단순 특성 추출
아래 get_features_and_labels() 함수는
conv_base 모델의 predict() 메서드를 이용하여
준비된 훈련 데이터셋을 변환한다.
즉 모델 예측에 유용한 특성들로 구성된 데이터로 변환한다.
단, 레이블(타깃)은 그대로 둔다.
keras.applications.vgg16.preprocess_input()함수:tf.float32자료형으로의 형변환 담당. 일종의 리스케일링 함수.
def get_features_and_labels(dataset):
all_features = []
all_labels = []
# 배치 단위로 VGG16 모델 적용
for images, labels in dataset:
preprocessed_images = keras.applications.vgg16.preprocess_input(images)
features = conv_base.predict(preprocessed_images)
all_features.append(features)
all_labels.append(labels)
# 생성된 배치를 하나의 텐서로 묶어서 반환
return np.concatenate(all_features), np.concatenate(all_labels)
훈련셋, 검증셋, 테스트셋을 변환하면 다음과 같다.
train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset)
test_features, test_labels = get_features_and_labels(test_dataset)
예를 들어, 변환된 강아지/고양이 이미지 샘플 2,000개는 이제 각각 (5, 5, 512) 모양을 갖는다.
>>> train_features.shape
(2000, 5, 5, 512)
변환된 데이터셋을 훈련 데이터셋으로 사용하는
간단한 분류 모델을 구성하여 훈련만 하면 된다.
Dropout 층은 과대적합을 예방하기 위해 사용한다.
# 입력층
inputs = keras.Input(shape=(5, 5, 512))
# 은닉층
x = layers.Flatten()(inputs)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_features, train_labels,
epochs=20,
validation_data=(val_features, val_labels),
callbacks=callbacks)
검증셋에 대한 정확도가 97% 정도까지 향상되지만 과대적합이 매우 빠르게 발생한다. 아무래도 훈련셋이 너무 작기 때문이다.

2) 데이터 증식과 특성 추출
데이터 증식 기법을 활용하려면 VGG16 합성곱 기저(베이스)를 구성요소로 사용하는 모델을 직접 정의해야 한다. 다만 앞서 설명한 방식과는 달리 가져온 VGG16 기저에 포함된 파라미터가 새로운 모델의 훈련 과정동안 함께 훈련되지 않도록 동결(freezing)해야 한다.
기저 동결하기:
trainable=False로 지정.입력 데이터의 모양도 미리 지정하지 않음에 주의할 것.
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False)
# 기저 동결
conv_base.trainable = False
동결 해제(trainable=True)로 설정하는 경우와 그렇지 않은 경우 학습되어야 하는
파라미터의 수가 달라짐을 다음처럼 확인할 수 있다.
참고로 합성곱 층마다 하나의 가중치 행렬과 하나의 편향 행렬이 존재하여 총 2개의 파라미터 행렬이
학습에 활용되며, VGG16은 13개의 Conv2D 층을 포함한다.
>>> conv_base.trainable = True
>>> print("합성곱 기저의 학습을 허용하는 경우 학습 가능한 파라미터 행렬 개수: ",
len(conv_base.trainable_weights))
합성곱 기저의 학습을 허용하는 경우 학습 가능한 파라미터 행렬 개수: 26
동결 설정(trainable=False)인 경우에 학습되는 파라미터 수가 0이 된다.
>>> conv_base.trainable = False
>>> print("합성곱 기저의 학습을 금지하는 경우 학습 가능한 파라미터 행렬 개수: ",
len(conv_base.trainable_weights))
합성곱 기저의 학습을 금지하는 경우 학습 가능한 파라미터 행렬 개수: 0
아래 모델은 데이터 증식을 위한 층과 VGG16 기저를 함께 이용한다.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
# 모델 구성
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs) # 데이터 증식
x = keras.applications.vgg16.preprocess_input(x) # VGG16용 전처리
x = conv_base(x) # VGG16 베이스
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x) # 출력층
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction_with_data_augmentation",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=50,
validation_data=validation_dataset,
callbacks=callbacks)
이렇게 훈련하면 재활용된 합성곱 기저에 속한 층은 학습하지 않으며 두 개의 밀집층에서만 파라미터 학습이 이뤄진다. 과대적합이 보다 늦게 이루어지며 성능도 향상되었다. 테스트셋에 대한 정확도가 97.7%까지 향상된다.

9.4.2. 모델 미세 조정#
모델 미세 조정(파인 튜닝, fine-tuning)은 특성 추출 방식과는 달리 기존 합성곱 모델의 최상위 합성곱 층 몇 개를 동결 해제해서 새로운 모델에 맞추어 학습되도록 하는 모델 훈련기법이다.
여기서는 아래 그림에처럼 노락색 배경을 가진 상자 안에 포함된 합성곱 층을 동결 해제해서 함께 학습되도록 한다.

아래 코드는 모든 층에 대해 동결해제를 진행한 후에 마지막 4개 층을 제외한 나머지 층에 대해 다시 동결을 설정한다.
conv_base.trainable = True
for layer in conv_base.layers[:-4]:
layer.trainable = False
상위 4개 층만 동결 해제하는 이유는 합성곱 신경망의 하위층은 보다 일반적인 형태의 패턴을 학습하는 반면에 최상위층은 주어진 문제 해결에 특화된 패턴을 학습하기 때문이다. 따라서 이미지넷으로 훈련된 모델 전체를 대상으로 훈련하기 보다는 최상위층 몇 개만 훈련시키는 것이 보다 유용하다.
모델 컴파일과 훈련 과정은 이전과 동일하며, 정확도가 98%(\(\pm\!\) 1%)에 육박하는 모델을 얻게 된다.
model.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.RMSprop(learning_rate=1e-5),
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="fine_tuning",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)