10. 컴퓨터 비전#
감사의 글
아래 내용은 프랑소와 숄레의 Deep Learning with Python(2판)의 소스코드 내용을 참고해서 작성되었습니다. 자료를 공개한 저자에게 진심어린 감사를 전합니다.
소스코드
여기서 언급되는 코드를 (구글 코랩) 컴퓨터 비전에서 직접 실행할 수 있다.
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
합성곱 신경망의 주요 활용 분야(컴퓨터 비전)
이미지 분류
이미지 분할
객체 탐지
합성곱 신경망 기본 아키텍처
잔차 연결
배치 정규화
채널 분리 합성곱
10.1. 컴퓨터 비전 주요 과제#
컴퓨터 비전 분야에서 가장 주요한 연구 주제는 다음과 같다.
이미지 분류(image classification): 이미지에 포함된 사물(들)의 클래스 분류
단일 라벨 분류(single-label classification)
예제: 한 장의 사진에서 고양이, 강아지, 사람, 자전거, 자동차 등 중에하 하나의 클래스 선택
다중 라벨 분류(multi-label classification)
예제: 한 장의 사진에 포함된 여러 종류의 객체를 모두 분류. 예를 들어 두 사람이 자전거를 타는 사진에서 두 사람과 자전거 등 사진에 포함된 모든 객체의 클래서 확인.
이미지 분할(image segmentation): 이미지를 특정 클래스를 포함하는 영역으로 분할
예제: 줌(Zoom), 구글 미트(Google Meet) 등에서 사용되는 배경 블러처리 기능
객체 탐지(object detection): 이미지에 포함된 객체 주의에 경계상자(bounding box) 그리기
예제: 자율주행 자동차의 주변에 위치한 다른 자동차, 행인, 신호등 등 탐지 기능

언급된 세 분야 이외에 아래 컴퓨터 비전 분야에서도 딥러닝이 중요하게 활용된다.
이미지 유사도 측정(image similarity scoring)
키포인트 탐지(keypoint detection)
자세 추정(pose estimation)
3D 메쉬 추정(3D mesh estimation)

여기서는 이미지 분할을 보다 자세히 살펴본다. 반면에 객체 탐지 등 다른 분야는 다루지 않는다. 다만 객체 탐지 관련해서 다음 논문을 참고할 것을 권유한다.
작동원리 설명: 핸즈온 머신러닝 14장
기초 활용법: RetinaNet 활용 객체 탐지
주요 활용 예제: YOLOv5
10.2. 이미지 분할#
이미지 분할은 크게 두 종류로 나뉜다.
시맨틱 분할(semantic segmentation)
객체가 속하는 클래스(범주)에 따라 분류
아래 사진 왼편: 배경과 구분된 고양이들을 cat 클래스로 하나로 묶어 배경과 구분
인스턴스 분할(instance segmentation)
클래스뿐만 아니라 객체 각각도 구분
아래 사진 오른편: 배경과 구분된 각각의 고양이를 cat1, cat2 등으로 구분

Oxford-IIIT 애완동물 데이터셋
시맨틱 분할을 보다 상세히 살펴보기 위해 Oxford-IIIT 애완동물 데이터셋을 이용하여 훈련을 진행한다. 데이터셋은 강아지와 고양이를 비롯해서 총 37 종의 애완동물이 찍힌 7,390장의 사진으로 구성된다. 사진의 크기는 제 각각이다.
데이터셋 크기: 7,390
클래스(범주) 개수: 37
클래스별 사진 수: 약 200 장
사진별 라벨: 종과 품종, 머리 표시 경계상자, 트라이맵 분할trimap segmentation 마스크 등 4 종류로 구성
트라이맵 분할 마스크는 원본 사진과 동일한 크기의 흑백 사진이며 각각의 픽셀은 1, 2, 3 셋 중에 하나의 값을 갖는다.
1: 동물의 몸에 해당하는 픽셀
2: 배경에 해당하는 픽셀
3: 동물과 배경을 구분하는 경계에 해당하는 픽셀
아래에서 맨 왼쪽은 동물 사진을, 가운데 사진은 동물의 머리 영역을 표시하는 경계 상자를 맨 오른쪽 사진은 트라이맵 분할 마스크를 시각화하여 보여준다.

이미지 분할 모델 구성
이미지 분할 모델의 구성은 기본적으로 Conv2D 층으로 구성된
다운샘플링 블록downsampling block과
Conv2DTranspose 층으로 구성된
업샘플링 블록upsampling block으로 이루어진다.
먼저 Conv2D 층을 활용하는 다운샘플링 블록으로 시작한다.
이미지 분류를 위해 맥스풀링을 사용하는 대신 Conv2D 층에서 보폭을 2로
설정하는 이유는 픽셀에 담긴 값(정보) 뿐만 아니라 각 픽셀의 위치도 중요하기 때문이다.
맥스풀링은 픽셀의 위치 정보를 무시하면서 동시에 위치와 독립적인 패턴을 알아내는 것이 중요할 때 사용된다.
실제로 맥스풀링은 여러 개의 픽셀 중에 가장 큰 값을 선택하는데 선택된 픽셀의 정보는 무시한다.
이미지 분류 모델과 동일한 기능.
보폭(
strides=2)을 사용하는 경우와 그렇지 않은 경우를 연속으로 적용하기에 별도의MaxPooling2D은 사용하지 않음.패딩(
padding="same")을 사용하지만 보폭을 2로 두면 이미지 크기는 가로, 세로 모두 1/2로 줄어듦.채널 수는 동일한 방식으로 두 배씩 증가시킴.
다운샘플링 블록에 이어 Conv2DTranspose 층을 활용하는 업샘플링 블록을 추가한다.
이미지 분할 모델의 최종 출력값은 입력 이미지의 동일한 크기의 트라이맵 분할 이미지임.
Conv2D층을 통과하면서 크기가 작아진 텐서를 입력 이미지 크기로 되돌리는 기능 수행.Conv2D층이 적용된 역순으로 크기를 되돌려야 함.모델 훈련과정에서 어떤 값들을 사용하여 모양을 되돌릴지 스스로 학습함.
아래 그림이 업샘플링이 작동하는 과정을 보여준다.
검정 테두리로 표시된
2x2모양의 텐서에 포함된 하나의 항목에 초록색 바탕의3x3모양의 필터를 적용하면 왼편에 위치한 파랑색 바탕의3x3모양의 텐서가 생성된다.이 과정을
2x2텐서의 모든 항목에 대해 실행한다. 단, 생성되는3x3모양의 텐서는 지정된 보폭 크기만큼 오른쪽 또는 아래로 이동시키며 겹친다.중첩되는 영역에 포함된 항목은 해당 항목에 대해 계산된 모든 값들의 합으로 지정한다.
여기서 사용하는 다운/업 샘플링 블록은 다음과 같다.
def get_model(img_size, num_classes):
inputs = keras.Input(shape=img_size + (3,))
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(256, 3, strides=2, padding="same", activation="relu")(x)
x = layers.Conv2D(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same", strides=2)(x)
outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x)
model = keras.Model(inputs, outputs)
return model
출력층으로 사용된 Conv2D 층의 활성화 함수로 지정된 소프트맥스 함수는
출력 텐서의 마지막 축을 대상으로 작동한다.
즉, num_classes 개의 출력맵으로 구성된 3차원 텐서의 픽셀별로 소프트맥스 함수가 적용된다.
여기서는 num_classes가 3으로 지정된다.
이유는 최종적으로 픽셀별로 0, 1, 2 중에 하나의 값을 예측해야 하기 때문이다.
위 모델을 훈련시킬 때 손실함수로 sparse_categorical_crossentropy를 지정한다.
그러면 샘플의 타깃으로 사용되는 정수 0, 1, 2가
각각 (1, 0, 0), (0, 1, 0), (0, 0, 1) 에 상응하도록 작동하여
타깃 샘플의 모양이 (200, 200, 3)인 것인양 작동하여
위 모델의 출력값의 모양과 동일해진다.
get_model(img_size=(200,200), num_classes=3)을 호출해서 생성된 모델을 요약하면 다음과 같다.
img_size=(200,200): 크기가 제 각각인 사진을 모두 지정된 크기로 변환시켜서 훈련셋으로 활용num_classes=3: 최종적으로 3개의 채널을 갖는 텐서 생성. 소프트맥스 활성화 함수는 픽셀별로 적용됨.
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 200, 200, 3)] 0
_________________________________________________________________
rescaling (Rescaling) (None, 200, 200, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 100, 100, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 100, 100, 64) 36928
_________________________________________________________________
conv2d_2 (Conv2D) (None, 50, 50, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 50, 50, 128) 147584
_________________________________________________________________
conv2d_4 (Conv2D) (None, 25, 25, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 25, 25, 256) 590080
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 25, 25, 256) 590080
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 50, 50, 256) 590080
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 50, 50, 128) 295040
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 100, 100, 128) 147584
_________________________________________________________________
conv2d_transpose_4 (Conv2DTr (None, 100, 100, 64) 73792
_________________________________________________________________
conv2d_transpose_5 (Conv2DTr (None, 200, 200, 64) 36928
_________________________________________________________________
conv2d_6 (Conv2D) (None, 200, 200, 3) 1731
=================================================================
Total params: 2,880,643
Trainable params: 2,880,643
Non-trainable params: 0
_________________________________________________________________
모델 컴파일과 훈련은 특별한 게 없다.
단, 앞서 설명한 대로 sparse_categorical_crossentropy를 손실함수로 지정한다.
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy")
GPU의 성능에 따라 아래 코드를 실행할 때
ResourceExhaustedError: Graph execution error 가 발생하거나
파이썬 서버가 다운될 수 있다.
이유는 입력 데이터 사진의 용량이 커서 GPU의 메모리가 부족해지는 현상이 발생할 수 있기 때문이다.
그런 경우 배치 크기를 16 정도로 줄여야 한다.
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
# batch_size=64, # 고성능 GPU 활용
batch_size=16, # 저성능 GPU 활용
validation_data=(val_input_imgs, val_targets))
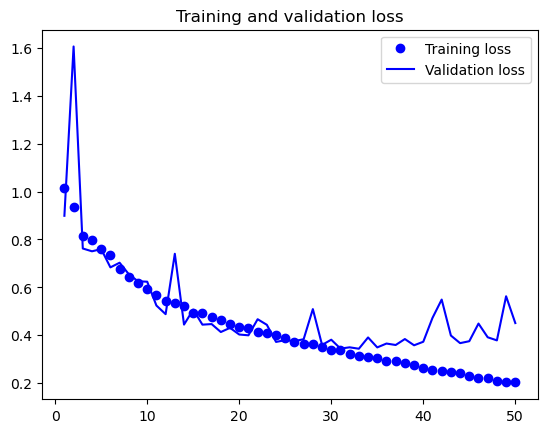
훈련 결과를 그래프로 시각화해서 보면 과대적합이 20 에포크 정도 지나면서 발생함을 확인할 수 있다.
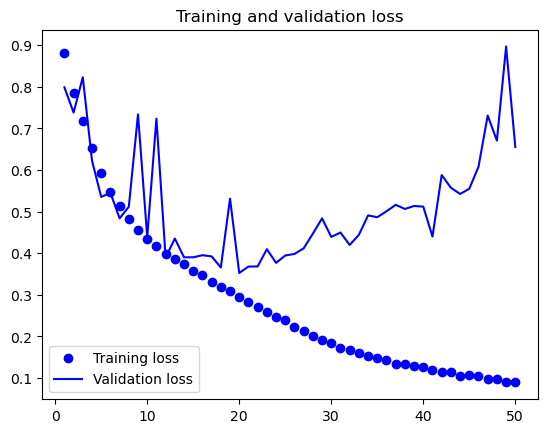
참고로 배치 크기를 64로 할 경우 25 에포크 정도 지나면서 과대적합이 발생한다.
훈련중 저장된 최고 성능의 모델을 불러와서 이미지 분할을 어떻게 진행했는지 하나의 이미지에 대해 테스트해보면 원본 이미지에 포함된 다른 사물이나 배경 때문에 약간의 잡음이 있지만 대략적으로 이미지 분할을 잘 적용함을 알 수 있다.

10.3. CNN 아키텍처 주요 유형#
모델 아키텍처model architecture는 모델 설계방식을 의미하며 심층 신경망 모델을 구성할 때 매우 중요하다. 신경망 모델은 주어진 문제와 데이터셋에 따라 적절한 층을 적절하게 구성해야 한다. 적절한 모델 아키텍처를 사용할 수록 적은 양의 데이터로 보다 빠르게 좋은 성능의 모델을 얻을 가능성이 높아진다. 하지만 아쉽게도 좋은 모델 아키텍처와 관련되어 정해진 이론은 없다. 대신 많은 경험을 통한 직관이 모델 구성에 보다 중요하다.
10.3.1. 모듈(블록), 계층, 재활용#
합성곱 신경망 모델을 포함하여 주요 신경망 모델의 아키텍처는 다음 두 가지 특징을 갖는다.
첫째, 깊게 쌓아 올린 합성곱 신경망 모델은 기본적으로 모듈module을 계층hierarchy으로 쌓아 올린 구조를 갖는다. 여기서 모듈은 여러 개의 층layer으로 구성되며 블록block이라 불리기도 한다. 하나의 모듈(블록)이 여러 번 재활용reuse 된다. 예를 들어, 9장에서 다룬 VGG16 모델은 “Conv2D, Conv2D, MaxPooling2D” 로 구성된 모듈(블록)을 재활용하여 계층으로 쌓아 올렸다.
둘째, 대부분의 합성곱 신경망 모델은 특성 피라미드 형식의 계층적 구조를 사용하는 점이다. VGG16의 경우에 필터 수를 32, 64, 128 등으로 수를 늘리는 반면에 특성맵feature maps의 크기는 그에 상응하여 줄여 나간다(아래 그림 참고).
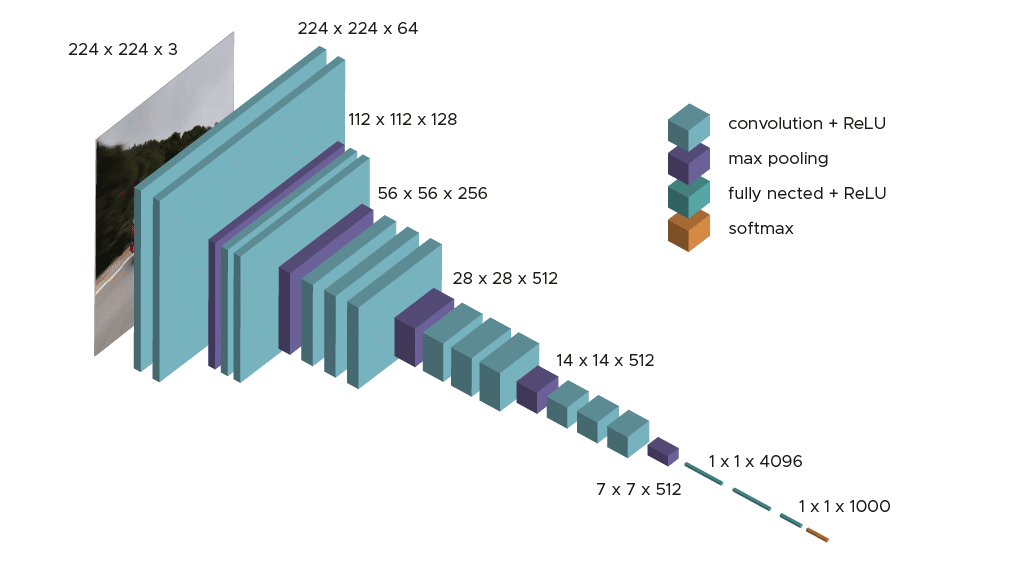
그런데 블록을 연결하는 계층을 높게 쌓으면 그레이디언트 소실 문제 등으로 인해 모델의 훈련이 잘 이뤄지지 않는다. 이를 해결하는 다양한 해결책이 개발되었으며 여기서는 합성곱 신경망 구성에 사용되는 세 개의 주요 아키텍처 유형을 살펴본다.
잔차 연결residual connections
배치 정규화batch normalization
채널 분리 합성곱depthwise separable convolutions
10.3.2. 잔차 연결#
일반적으로 많은 유닛이 포함된 층을 몇 개 쌓는 것보다 적은 유닛이 포함된 층을 높이 쌓을 때 모델의 성능이 좋아진다. 하지만 층을 높이 쌓을 수록 전달되어야 하는 손실값(오차)의 그레이디언트 소실 문제vanishing gradient problem가 발생하여 역전파가 제대로 작동하지 못한다. 이 문제를 극복하기 위해 제시된 대표적인 아키텍처(설계방식)가 잔차 연결residual connections이다.
아래 그림은 블록(모듈)의 입력값을 모델을 통과하여 생성된 출력값과 합쳐서 다음 모델으로 전달하는 아키텍처를 보여준다. 이 방식을 통해 모델의 입력값에 대한 정보가 보다 정확하게 상위 모델에 전달되어, 그레이디언트 소실 문제를 해결하는 데에 많은 도움을 준다. 실제로 잔차 연결을 이용하면 모델을 매우 높게 쌓아도 모델 훈련이 가능해질 수 있다.

ResNet 모델
잔차 연결 아키텍처는 2015년에 소개된 ResNet 계열의 모델에서 처음 사용되었으며, 2015년 ILSVRC 이미지 분류 경진대회에서 1등을 차지했다.
잔차 연결 핵심: 모양 맞추기
잔차 연결을 사용할 때 주의해야할 기본사항은 모듈의 입력텐서와 출력테서의 모양을 맞추는 일이다.
이때 맥스풀링 사용여부에 따라 보폭(strides)의 크기가 달라진다.
맥스풀링을 사용하지 않는 경우:
Conv2D에서 사용된 필터 수를 맞추는 데에만 주의하면 된다.Conv2D층:padding="same"옵션을 사용하여 모양을 유지필터 수가 변하는 경우: 잔차에
Conv2D층을 이용하여 필터 수를 맞춤. 필터 크기는1x1사용. 활성화 함수는 없음.
inputs = keras.Input(shape=(32, 32, 3)) x = layers.Conv2D(32, 3, activation="relu")(inputs) residual = x x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) # padding 사용 residual = layers.Conv2D(64, 1)(residual) # 필터 수 맞추기 x = layers.add([x, residual])
맥스풀링을 사용하는 경우: 보폭을 활용해야 한다.
잔차에
Conv2D층을 적용할 때 보폭 사용
inputs = keras.Input(shape=(32, 32, 3)) x = layers.Conv2D(32, 3, activation="relu")(inputs) residual = x x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) x = layers.MaxPooling2D(2, padding="same")(x) # 맥스풀링 residual = layers.Conv2D(64, 1, strides=2)(residual) # 보폭 사용 x = layers.add([x, residual])
예제
아래 코드는 잔차 연결을 사용하는 활용법을 보여준다. 맥스풀링과 필터 수에 따른 구분을 사용함에 주의하라.
# 입력층
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Rescaling(1./255)(inputs)
# 은닉층
def residual_block(x, filters, pooling=False):
residual = x
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
if pooling: # 맥스풀링 사용하는 경우
x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(filters, 1, strides=2)(residual)
elif filters != residual.shape[-1]: # 필터 수가 변하는 경우
residual = layers.Conv2D(filters, 1)(residual)
x = layers.add([x, residual])
return x
x = residual_block(x, filters=32, pooling=True)
x = residual_block(x, filters=64, pooling=True)
x = residual_block(x, filters=128, pooling=False)
x = layers.GlobalAveragePooling2D()(x) # 채널 별로 하나의 값(채널 평균값) 선택
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델 설정
model = keras.Model(inputs=inputs, outputs=outputs)
10.3.3. 배치 정규화#
정규화normalization는 다양한 모양의 샘플을 정규화를 통해 보다 정규 분포를 따르도록 만든다. 이를 통해 모델의 학습을 도와주고 결국 훈련된 모델의 일반화 성능을 올려준다. 지금까지 살펴 본 정규화는 모델의 입력 데이터를 전처리 과정에서 평균을 0으로, 표준편차를 1로 만드는 방식이었다. 이는 데이터셋이 정규 분포를 따른다는 가정 하에 진행된 정규화였다. 아래 그림은 주택가격 예측 데이터의 특성 중에 주택가격과 건축년수를 정규화한 경우(오른편)와 그렇지 않는 경우(왼편)의 데이터 분포의 변화를 보여준다.

정규 분포와 머신러닝
정규 분포를 따르지 않는 데이터에 대한 분석은 기본적으로 머신러닝(딥러닝) 기법을 적용할 수 없다.
하지만 입력 데이터셋에 대한 정규화가 층을 통과한 출력값의 정규화를 보장하는 것은 아니다. 따라서 다음 층으로 넘겨주기 전에 정규화를 먼저 진행하면 보다 훈련이 잘 될 수 있다. 더 나아가 출력값을 먼저 정규화한 후에 활성화 함수를 적용할 때 보다 좋은 성능의 모델이 구현될 수 있음이 밝혀지기도 했다.
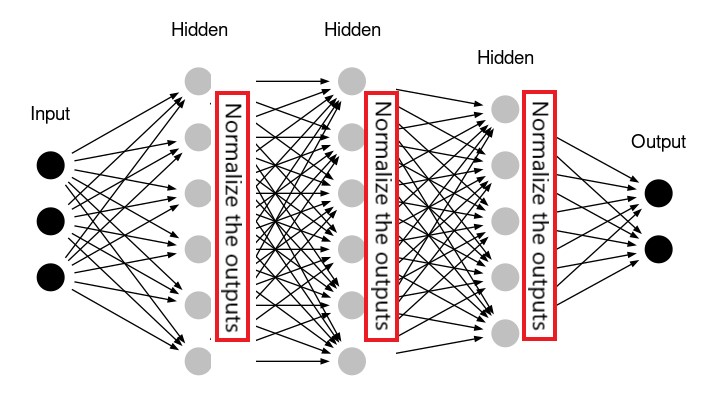
배치 정규화batch normalization가 바로 앞서 설명한 기능을 대신 처리하며,
2015년에 발표된 한 논문에서 소개되었다.
케라스의 경우 layers.BatchNormalization 층이 배치 정규하를 지원한다.
배치 정규화를 실행하는 함수를 넘파이 어레이로 다음과 같이 구현할 수 있다.
def batch_normalization(batch_of_images):
mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2))
variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2))
return (batch_of_images - mean) / variance
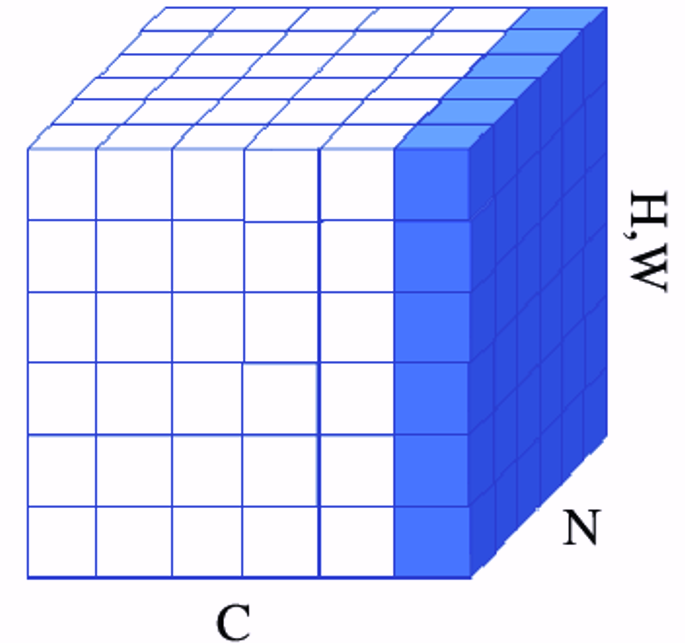
아래 그림은 배치 정규화 층에서 입력 배치를 대상으로 정규화를 진행하는 과정을 시각화한다. 입력 텐서의 모양은 (N, H, W, C) 라고 가정한다.
N: 배치 크기
H와 W: 높이와 너비
C: 채널 수
즉, 배치 정규화는 배치에 포함된 모든 샘플을 대상으로 채널 단위로 계산된 평균값과 표준편차를 이용하여 각각의 샘플에 대해 정규화를 진행한다. 즉, 배치에 포함된 모든 샘플에 대해 동일한 평균값과 표준편차를 이용한다.
배치 정규화로 인한 모델 성능 향상에 대한 구체적인 이론은 아직 존재하지 않는다. 다만 경험적으로 합성곱 신경망 모델의 성능에 많은 도움을 준다는 사실만 알려져 있다. 잔차 연결과 함께 배치 정규화 또한 모델 훈련과정에 그레이디언트 역전파에 도움을 주어 매우 깊은 심층 신경망 모델의 훈련에 도움을 준다. 예를 들어, ResNet50, EfficientNet, Xception 모델 등은 배치 정규화 없이는 제대로 훈련되지 않는다.
배치 정규화 사용법
BatchNormalization 층을 Conv2D, Dense 등 임의의 층 다음에 사용할 수 있다.
주로 사용되는 형식은 다음과 같다.
x = ...
x = layers.Conv2D(32, 3, use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = ...
use_bias=False옵션: 배치 정규화에 의해 어차피 데이터의 평균값을 0으로 만들기에 굳이 편향bias 파라미터를 훈련 과정 중에 따로 학습시킬 이유가 없다. 따라서 학습되어야 할 파라미터 수가 아주 조금 줄어들어 학습 속도가 그만큼 빨라진다.활성화 함수 사용 위치: 배치 정규화 이후에 활성화 함수를 실행한다. 이를 통해
relu()활성화 함수의 기능을 극대화할 수 있다(고 주장된다).
모델 미세조정과 배치 정규화
배치 정규화 층이 포함된 모델을 미세조정할 때 배치 정규화 층도 함께 동결(freeze)할 것을 추천한다. 배치 정규화 층을 동결하면 재활용되는 모델이 기존 훈련과정에서 사용한 훈련 데이터셋 전체를 대상으로 계산된 평균값과 분산이 대신 활용된다.
이렇게 하는 이유는 미세조정의 경우 훈련셋의 데이터가 모델이 기존에 훈련했을 때의 훈련셋과 비슷하다고 전제하기 때문이다. 만약에 많이 다른 훈련셋으로 미세조정을 진행하면 동결해제된 모델의 파라미터가 급격하게 달라지게 되여 모델의 성능이 오히려 떨어질 수 있다(라고 추정된다).
예제
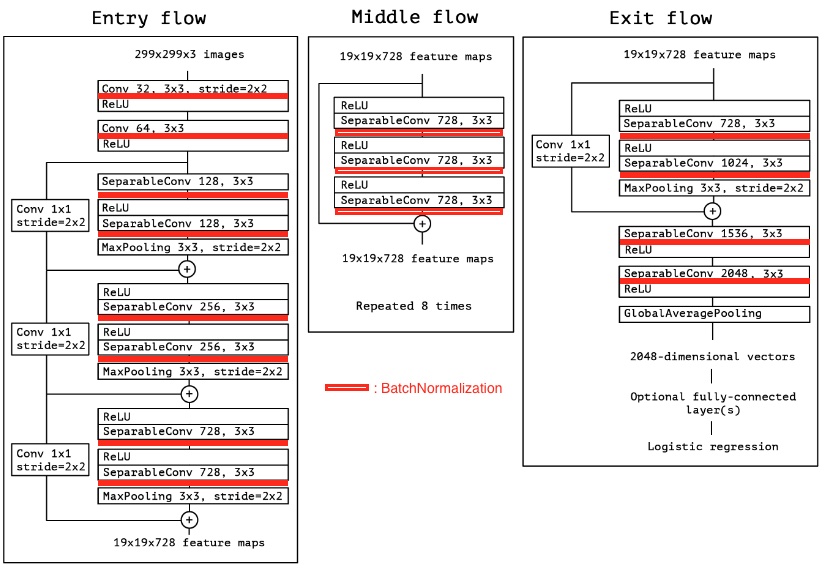
아래 그림은 2017년에 소개된 Xception 모델의 구조를 보여준다.
빨강색 사각형으로 표시된 부분에 BatchNormalization 층이 사용되었다.
10.3.4. 채널 분리 합성곱#
케라스의 SeparableConv2D 층은 Conv2D 층보다
적은 수의 가중치 파라미터를 사용하여 보다 적은 양의 계산으로 성능이 좀 더 좋은 모델을 생성한다.
2017년 Xception 모델 논문에서 소개되었으며 당시 최고의 이미지 분류 성능을 보였다.
Top 1 / Top 5 정확도
최신 이미지 분류 모델의 성능은 Image Classification on ImageNet에서 확인할 수 있다. 2023년 기준으로 최고 성능 모델의 Top 1 정확도는 91.1%, Top 5 정확도는 99.02% 정도이다.
Top 1 정확도: 분류 모델이 모든 클래스에 대해 예측한 확률값 중에 가장 높은 확률값을 갖는 클래스가 실제 타깃과 일치할 확률
Top 5 정확도: 분류 모델이 모든 클래스에 대해 예측한 확률값 중에 가장 높은 5 개의 확률값을 갖는 5개의 클래스 중에 실제 타깃이 포함된 확률
SeparableConv2D 작동법
SeparableConv2D는 필터를 채널 별로 적용한 후
나중에 채널 별 결과를 합친다.
이렇게 작동하는 층이 채널 분리 합성곱(depthwise separable convolution) 층이며
아래 그림처럼 채널 별로 생성된 결과를 합친 후 1x1 합성곱 신경망을 통과시킨다.

SeparableConv2D 작동 원리
이미지에 저장된 정보가 채널 별로 서로 독립적이라는 가정을 사용한다.
따라서 채널 별로 서로 다른 필터를 사용한 후 결과들을 1x1 모양의 필터를 사용하여 합친다.
이때 원하는 종류의 채널 수 만큼의 1x1 모양의 필터를 사용하여
다양한 정보를 추출한다.
Conv2D와 SeparableConv2D의 서로 다른 작동과정은 다음과 같이 설명된다.
Conv2D작동 원리padding="same"옵션 사용한 경우필터 1개 사용

SeparableConv2D작동 원리padding="same"옵션 사용한 경우필터 1개 사용

층의 파라미터 개수 비교
채널 분리 합성곱 신경망이 Conv2D 층을 사용하는 경우보다 몇 배 이상 적은 수의
파라미터를 사용한다.
경우 1(위 그림): 3x3 모양의 필터 64개를 3개의 채널을 갖는 입력 데이터에 사용할 경우
Conv2D의 경우:3*3*3*64 = 1,728SeparableConv2D의 경우:3*3*3 + 3*64 = 219
경우 2: 3x3 모양의 필터 64개를 10개의 채널을 갖는 입력 데이터에 사용할 경우
Conv2D의 경우:3*3*10*64 = 5,760SeparableConv2D의 경우:3*3*10 + 10*64 = 730
채널 분리 합성곱의 약점
채널 분리 합성곱의 연산이 CUDA에서 제대로 지원되지 않는다.
따라서 GPU를 사용하더라도 기존 Conv2D 층만을 사용한 모델에 비해
학습 속도에 별 차이가 없다.
즉 채널 분리 합성곱이 비록 훨씬 적은 수의 파라미터를 학습에 사용하지만
이로 인해 시간상의 이득은 주지 않는다.
하지만 적은 수의 파라미터를 사용하기에 일반화 성능이 보다 좋은 모델을
구현한다는 점이 매우 중요하다.
참고: CUDA와 cuDNN
CUDA(Compute Unified Device Architecture)
CPU와 GPU를 동시에 활용하는 병렬 컴퓨팅을 지원하는 플랫폼
C, C++, Fortran 등의 저수준 언어 활용
cuDNN(CUDA Deep Neural Network): CUDA를 활용하여 딥러닝 알고리즘의 실행을 지원하는 라이브러리
Conv2D 등 특정 딥러닝 알고리즘에 대해서만 최적화됨.
미니 Xception 모델
미니 Xception 모델을 직접 구현하여 강아지-고양이 이항분류 작업을 실행해본다. 모델 구현에 사용되는 기법을 정리하면 다음과 같다.
모듈을 쌓을 수록 필터 수는 증가시키고, 텐서 크기는 감소시킨다.
층의 파라미터 수는 가능한 적게 유지하고 모듈은 높게 쌓는다.
잔차 연결을 활용한다.
모든 합성곱 층 이후에는 배치 정규화를 적용한다.
채널 분리 합성곱 신경망을 활용한다.
여기서는 비록 이미지 분류 모델을 예제로 활용하지만 앞서 언급된 기법은 컴퓨터 비전 프로젝트 일반에 적용될 수 있다. 예를 들어 DeepLabV3 모델은 Xception 모델을 이용하는 2021년 기준 최고의 이미지 분할 모델이다.
사용하는 데이터셋은 9장에서 사용한 캐글(kaggle)의 강아지-고양이 데이터셋이며, 데이터 증식층, 합성곱 층, 채널 분리 합성곱 층을 이용하여 아래와 같이 이진 분류 모델을 구성한다.
# 데이터 증식 층
data_augmentation = keras.Sequential(
[layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2)]
)
# 입력층
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
# 하나의 Conv2D 은닉층
x = layers.Conv2D(filters=32, kernel_size=5, use_bias=False)(x)
# SeparableConv2D, BatchNormalization, MaxPooling2D 층으로 구성된 모듈 쌓기
# 잔차 연결 활용
for size in [32, 64, 128, 256, 512]: # 필터 수
residual = x
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# 잔차 연결
residual = layers.Conv2D(size, 1, strides=2, padding="same", use_bias=False)(residual)
x = layers.add([x, residual])
# 마지막 은닉층은 GlobalAveragePooling2D과 Dropout
x = layers.GlobalAveragePooling2D()(x) # flatten 역할 수행(채널 별 평균값으로 구성)
x = layers.Dropout(0.5)(x)
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델 지정
model = keras.Model(inputs=inputs, outputs=outputs)
이진 분류 모델의 훈련을 시작한 후 50번 정도의 에포크 실행 후에 과대적합이 발생한다.

직접 구현한 모델이지만 테스트셋에 대한 정확도가 90% 정도 나오며, 9장에서 직접 구현해서 훈련시킨 모델의 성능인 83% 정도보다 훨씬 높게 나온다. 보다 성능을 높이려면 하이퍼파라미터를 조정하거나 앙상블 학습을 적용한다 (14장 참고).
10.4. KerasCV 라이브러리#
KerasCV는 컴퓨터 비전에서 활용될 수 있는 케라스 라이브러리 모음집이다. 유튜브: Applied ML with KerasCV and KerasNLP에서 KerasCV에 대한 간략한 소개를 시청할 수 있다.
10.5. 연습 문제#
ink detection with Keras 내용 학습 후 깃허브 페이지에 블로그 작성하기