11. 시계열 분석#
감사의 글
아래 내용은 프랑소와 숄레의 Deep Learning with Python(2판)의 소스코드 내용을 참고해서 작성되었습니다. 자료를 공개한 저자에게 진심어린 감사를 전합니다.
소스코드
여기서 언급되는 코드를 (구글 코랩) 시계열 분석에서 직접 실행할 수 있다.
주요 내용
시계열 분석 사례
온도 예측 순환 신경망(RNN) 모델 구현
순환 신경망 이해
순환 신경망 고급 활용법
11.1. 시계열 분석 사례#
시계열timeseries 데이터는 일정 간격으로 측정된 값들로 이루어진 데이터이다.
일일 단위 증시 가격
도시의 시간당 소비 전력
매장의 주별 판매량
시계열 데이터는 자연현상 및 사람들의 일상에서 쉽게 구할 수 있다.
지진 활동
물고기 개체수
지역 날씨
웹사이트 방문자수
국내총생산(GDP)
시계열 분석의 주요 목적은 예측forcasting이다. 예를 들어, 몇 시간 후의 소비 전력, 몇 달 후의 영업 이익, 며칠 뒤의 날씨 등을 예측할 때 사용한다. 이외에 시계열 분석과 관련된 과제는 다음과 같다.
분류classification: 웹사이트 방문자의 활동 이력을 보고 사람인지 기계인지 여부 판단
이벤트 탐지event detection: 오디오 스트림 감시 도중 “Ok Google”, “Hey Alexa”, “시리야” 등 핫워드hotword 탐지
이상치 탐지anomaly detection: 생산라인 중에 발생하는 특이현상, 회사 네트워크 상에 발생하는 특이 활동 등 탐지. 비지도 학습 활용.
11.2. 시계열 분석 사례: 온도 예측#
24시간 이후의 온도를 예측하는 순환 신경망recurrent neural network(RNN) 모델을 구현한다.
11.2.1. 데이터셋 준비#
독일 예나Jena시에 위치한 막스-플랑크 생지화확Max-Planck Biogeochemistry 연구소가 온도, 기압, 풍향 등 14 종류의 기상 데이터를 10분 단위로 측정해서 수집한 데이터셋이다. 원래 2003년부터 측정하였지만 여기서는 2009-2016년 데이터를 이용한다.
zip 파일 다운로드 및 압축풀기
jena_climate_2009_2016.csv.zip 파일을
다운로드해서 압축을 풀면 jena_climate_2009_2016.csv 파일이 생성된다.
예나 날씨 데이터셋 살펴보기
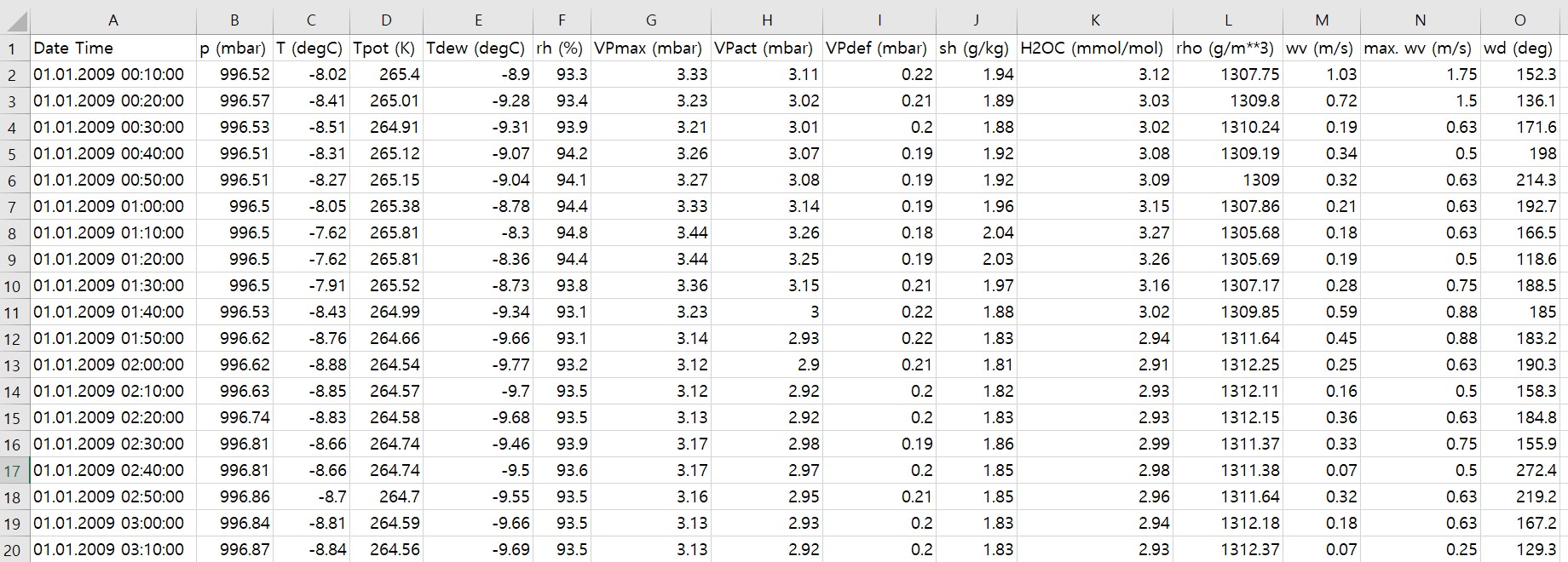
측정 시간을 제외한 14개의 날씨 관련 특성을 갖는 총 420,451 개의 데이터로 구성된다. 첫째 데이터는 2009년 1월 1일 0시 10분에 측정되었다. 아래 이미지는 예나 날씨 데이터셋을 엑셀로 열었을 때의 첫 20개의 데이터 샘플을 보여준다.
온도 변화 그래프
온도의 변화를 선그래프로 그리면 다음과 같다.

주기성은 시계열 데이터의 기본 특성 중 하나이다. 월별 주기성은 매우 일관성을 갖는다. 지난 몇 달동안의 데이터를 이용하여 다음 달의 평균 온도를 예측하는 일은 상대적으로 쉽다. 반면에 일 단위의 예측은 아래 그래프에서 보듯이 훨씬 혼잡하다.
아래 그래프는 2009년 1월 1일부터 1월 10일까지 열흘동안 측정된 온도의 선그래프이다.
10분에 한 번 측정되어서 열흘동안 총 6 * 24 * 10 = 1,440 개의 데이터 샘플이
x-축에 사용되었다.
그래프 상으로 마지막 4일 동안 일 단위 온도 변화가 어느 정도의 주기성을 보이기는 하지만
그런 주기성이 일반적이다 라고 말하기는 어렵다.

훈련셋, 검증셋, 테스트셋 지정하기
훈련셋, 검증셋, 테스셋의 비율을 각각 50%, 25%, 25%로 지정한다. 시계열 분석은 미래에 대한 예측을 실행하므로 훈련셋, 검증셋, 테스트셋 순으로 보다 오래된 데이터를 사용한다. 따라서 데이터셋을 섞지 않고 주어진 시간 순서대로 그대로 이용한다.
num_train_samples = int(0.5 * len(raw_data)) # 전체의 50%
num_val_samples = int(0.25 * len(raw_data)) # 전체의 25%
num_test_samples = len(raw_data) - num_train_samples - num_val_samples
입력 데이터셋과 타깃
여기서는 지난 5일치의 날씨 데이터를 이용하여 앞으로 24시간 후의 온도를 예측하는 모델을 구현하고자 한다. 따라서 이 목적을 위한 시계열 데이터의 입력 샘플은 지난 5일치의 날씨 데이터를 하나의 시퀀스로 묶은 데이터이고, 타깃은 해당 시퀀스보다 24시간 앞선 데이터의 온도이어야 한다.
데이터 정규화
5일 단위의 시퀀스와 타깃을 정하기 전에 먼저 기존 데이터셋을 정규화 한다. 즉, 특성별로 평균은 0, 표준편차는 1로 변환한다.
그런데 훈련셋의 평균값과 표준편차를 이용하여 모든 데이터셋을 정규화해야 한다. 앞서 언급한 것처럼 시계열 데이터의 훈련셋은 이른 시점에서의 데이터를 활용한다.
# 훈련셋의 평균
mean = raw_data[:num_train_samples].mean(axis=0)
raw_data -= mean
# 훈련셋의 표준편차
std = raw_data[:num_train_samples].std(axis=0)
raw_data /= std
5일 단위 시퀀스 데이터 준비
앞서 언급한 문제의 해결을 위한 모델을 구현하려면
5일 단위 시퀀스 데이터를 준비해야 하지만
timeseries_dataset_from_array() 함수를 활용하면 아주 쉽게 해결된다.
Example 11.1 (timeseries_dataset_from_array() 함수 활용법)
아래 코드는 넘파이 어레이를 이용하여
timeseries_dataset_from_array() 함수의 작동법을 설명한다.
>>> int_sequence = np.arange(10)
>>> dummy_dataset = keras.utils.timeseries_dataset_from_array(
... data=int_sequence[:-3],
... targets=int_sequence[3:],
... sequence_length=3,
... batch_size=2,
)
길이가 3인 시퀀스 샘플을 2개씩 묶은 배치 3개가 만들어진다.
>>> i = 0
>>> for inputs, targets in dummy_dataset:
... print(f"배치 {i}:")
... print(" samples shape:", inputs.shape)
... print(" targets shape:", targets.shape)
... print()
... i += 1
배치 0:
samples shape: (2, 3)
targets shape: (2,)
배치 1:
samples shape: (2, 3)
targets shape: (2,)
배치 2:
samples shape: (1, 3)
targets shape: (1,)
배치 별 샘플과 타깃을 확인하면 다음과 같다.
>>> i = 0
>>> for inputs, targets in dummy_dataset:
... print(f"배치 {i}:")
... for i in range(inputs.shape[0]):
... print(" 샘플:", [int(x) for x in inputs[i]], " 타깃:", int(targets[i]))
... print()
... i += 1
배치 0:
샘플: [0, 1, 2] 타깃: 3
샘플: [1, 2, 3] 타깃: 4
배치 2:
샘플: [2, 3, 4] 타깃: 5
샘플: [3, 4, 5] 타깃: 6
배치 2:
샘플: [4, 5, 6] 타깃: 7
아래 코드는 예나 데이터셋에 timeseries_dataset_from_array() 함수를 적용한다.
함수에 사용된 인자의 역할은 다음과 같다.
data: 선택 대상 데이터셋 전체targets: 선택 대상 데이터셋 전체sampling_rate: 표본 비율. 몇 개 중에 하나를 선택할 것인지 지정.sequence_length: 시퀀스 샘플 길이shuffle=True: 생성된 시퀀스들의 순서를 무작위하게 섞음.batch_size: 배치 크기. 생성된 시퀀스들을 배치로 묶음.start_index: 표본 추출 대상 시작 구간end_index: 표본 추출 대상 끝 구간
sampling_rate=6으로 지정한 이유는 10분 사이에는 온도의 변화가 거의 없기에 한 시간 단위로 표본을 추출하기 위함이다.
# 1시간에 하나의 데이터 선택
sampling_rate = 6
# 입력 데이터 시퀀스: 지난 5일치(120시간) 온도 데이터
sequence_length = 120
# 타깃 설정:24시간 이후의 온도. 지연(delay)을 6일치로 지정
delay = sampling_rate * (sequence_length + 24 - 1)
# 배치 크기
batch_size = 256
# 훈련셋
train_dataset = keras.utils.timeseries_dataset_from_array(
data=raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True, # 생성된 시퀀스들의 순서 무작위화
batch_size=batch_size,
start_index=0,
end_index=num_train_samples)
생성된 새로운 데이터셋은 훈련셋의 샘플과 타깃을 함께 배치 단위로 묶여있다. 예를 들어, 훈련셋의 첫째 배치의 모양은 다음과 같다.
배치 크기: 256
시퀀스 샘플 모양:
(120, 14). 14개의 특성을 갖는 날씨 데이터 5일치.
>>> for samples, targets in train_dataset:
... print("샘플 모양:", samples.shape)
... print("타깃 모양:", targets.shape)
... break
샘플 모양: (256, 120, 14)
타깃 모양: (256,)
11.2.2. 간단한 순환 모델 성능#
모델 성능의 최저 기준선으로 24시간 후의 온도를 현재 온도로 예측하는 것을 사용한다. 즉, 내일 이 시간 온도가 현재 온도와 별 차이가 없다는 가정을 이용한다. 그러면 검증셋과 테스트셋에 대한 평균절대오차는 각각 2.44와 2.62이다.
아래 코드는 가장 간단한 순환 신경망 모델이더라도 베이스라인보다 좋은 성능을 보여준다는 것을 확인할 수 있다.
모델에 사용된 LSTM 층은 장 기간의 정보를 잘 기억해서 활용하는 순환 신경망 층이다.
# 입력층
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
# LSTM 층
x = layers.LSTM(16)(inputs)
# 출력층
outputs = layers.Dense(1)(x)
# 모델 구성
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
학습과정을 그래프로 확인해보면 베이스라인과 유사하거나 좀 더 좋은 성능을 보인다.

11.3. 순환 신경망 이해#
순전파 신경망 대 순환 신경망
밀집층 Dense와 합성곱층 Conv2D는 샘플들 사이의 순서를 고려하지 않으며,
입력 샘플이 주어지면 그 샘플에 대한 출력값을 계산해서 다음 층으로 바로 전달한다.
이렇게 작동하는 층을 이용하는 신경망을 순전파 신경망feedforward network이라 부른다.
반면에 글을 읽으면서 이전 문장의 내용과 단어를 기억해야 하고,
날씨 예측을 위해 이전 며칠 동안의 날씨가 중요하듯이
데이터 사이의 순서를 함께 고려해야하는 경우에는
순환 신경망을 사용해야 한다.
순환 신경망recurrent neural network은 입력 시퀀스를 하나의 샘플로 한 번에 처리하는 대신 시퀀스에 포함된 항목들을 차례대로 하나씩 처리해서 얻은 정보를 시퀀스의 다음 항목을 처리할 때 함께 활용한다. 시퀀스의 항목을 하나 처리할 때마다 다음 항목에 활용되는 정보를 상태state라 부른다. 새로운 시퀀스를 다룰 때마다 상태는 초기화된다.
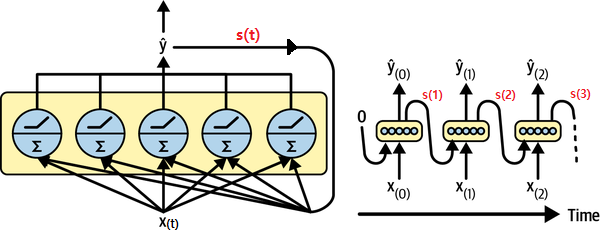
SimpleRNN 층 작동법
앞서 설명한 순환 신경망 아이디어를 가장 간단하게 구현한 모델이며 작동과정은 아래 그림과 같다.
t: 타임스텝time step. 하나의 시퀀스에서 항목의 순서를 가리킴.input_t: 시퀀스의t번째 항목.state_t: 시퀀스의t-1번째 항목에 대한 출력값.output_t:t번째 항목에 대한 출력값output_t = activation(dot(Wo, input_t) + dot(Uo, state_t) + bo)
Wo,Uo,bo는 학습되어야 하는 파라미터

LSTM 층 작동법
SimpleRNN 층은 실전에서 거의 사용되지 않는다.
이유는 이론과는 달리 시퀀스 내의 초기 상태가 제대로 전달되지 않기 때문인데,
이는 역전파 과정에서 그레이디언트 소실이 발생하기 때문이다.
이에 대한 해결책으로 잔차 연결과 유사한 아이디어가 적용된
LSTMLong Short Term Memory 층이 1997년에 제시되었다.
LSTM 층은 아래 그림에서 보듯이 장단기 메모리 모두 항목의 훈련에 활용된다.
c_t: 장기 메모리(carry)state_t: 단기 메모리output_t:t번째 항목에 대한 출력값output_t = activation(dot(Wo, input_t) + dot(Uo, state_t) + dot(Vo, c_t) + bo) c_{t+1} = i_t * k_t + c_t * f_t i_t = activation(dot(Ui, state_t) + dot(Wi, input_t) + bi) f_t = activation(dot(Uf, state_t) + dot(Wf, input_t) + bf) k_t = activation(dot(Uk, state_t) + dot(Wk, input_t) + bk)Wo,Uo,Vo,bo,Wi,Ui,bi,Wf,Uf,bf,Wk,Uk,bk는 학습되어야 하는 파라미터들이다.

RNN의 입력값과 출력값
RNN은 사용되는 층의 입력값과 출력값의 종류에 따라 아래 네 가지 유형으로 나뉜다.
sequence-to-sequence 신경망(아래 그림 상단 왼편)
입력 시퀀스를 이용하여 출력 시퀀스를 생성하여 다음 층으로 전달
예제: 시계열 데이터 예측. 지난 5일 동안의 온도를 이용하여 다음 날 온도 예측. 따라서 지난 4일과 하루 다음 날의 온도를 예측해야 함.
sequence-to-vector 신경망(아래 그림 상단 오른편)
예제: 영화 후기를 입력값으로 사용해서 영화에 대한 긍정/부정 결과를 예측하도록 함. (문장을 시퀀스 데이터로 다룸)
vector-to-sequence 신경망(아래 그림 하단 왼편)
예제: 사진을 입력하면 사진 설명을 출력값으로 생성하도록 함.
encoder-decoder: sequence-to-vector 신경망과 vector-to-sequence 신경망을 이어붙힌 신경망(아래 그림 하단 오른편)
예제: 문장 번역. 인코더는 한국어로 작성된 문장을 먼저 하나의 값으로 변환하고, 디코더는 생성된 값으로부터 영어로 된 문장을 생성함.
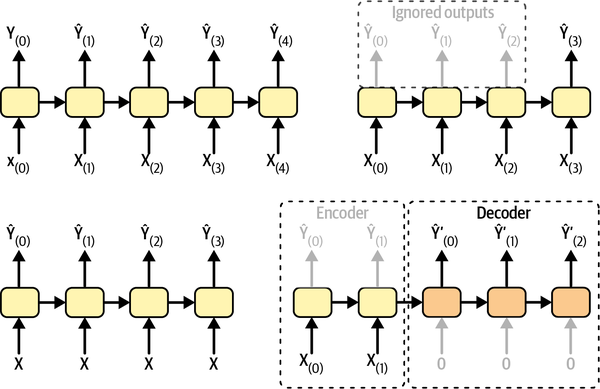
케라스 순환층 기본 사용법
첫째, 순환층은 임의의 길이의 시퀀스를 처리할 수 있다.
num_features = 14
inputs = keras.Input(shape=(None, num_features)) # 임의의 길이의 시퀀스 처리
outputs = layers.SimpleRNN(16)(inputs)
하지만 일정한 길이의 시퀀스만을 다룬다면 시퀀스의 길이steps를 지정하는 것이 좋다.
둘째, 순환층의 출력값은 층 생성자의 return_sequences 키워드 인자의 값에 따라
시퀀스의 마지막 항목에 대한 출력값만 출력할지를 지정한다.
만약 return_sequences=False, 즉 기본값으로 설정하면 시퀀스의 마지막 항목에 대한 출력값만 생성한다.
num_features = 14 # 특성 수
steps = 120 # 시퀀스 길이 지정
inputs = keras.Input(shape=(steps, num_features))
outputs = layers.SimpleRNN(16, return_sequences=False)(inputs) # 마지막 항목의 출력값만 사용
print(outputs.shape)
(None, 16)
return_sequences=True로 지정하면 시퀀스의 모든 항목에 대한 출력값을 갖는 시퀀스를 생성한다.
num_features = 14 # 특성 수
steps = 120 # 시퀀스 길이 지정
inputs = keras.Input(shape=(steps, num_features))
outputs = layers.SimpleRNN(16, return_sequences=True)(inputs) # 모든 항목의 출력값 사용
print(outputs.shape)
(None, 120, 16)
셋째, 순환층 또한 스택으로 쌓을 수 있다.
단, 마지막 순환층을 제외한 모든 순환층은 return_sequences=True로 설정해야 한다.
inputs = keras.Input(shape=(steps, num_features))
x = layers.SimpleRNN(16, return_sequences=True)(inputs)
x = layers.SimpleRNN(16, return_sequences=True)(x)
outputs = layers.SimpleRNN(16)(x)
11.4. 순환 신경망 고급 활용법#
순환 신경망의 성능을 끌어 올리는 세 가지 기법을 소개한다.
순환 드랍아웃recurrent dropout 적용
순환층 쌓기
양방향 순환층bidirectional recurrent layer 활용
순환 드랍아웃 적용
앞서 한 개의 LSTM 층을 사용한 모델 훈련은 매우 빠르게 과대적합이 발생했다. 과대적합 발생을 늦추기 위해 드랍아웃 기법을 순환층에 대해서도 효율적으로 적용할 수 있음이 2016년에 밝혀졌다.
매 타임스텝에 대해 동일한 드랍아웃 마스크 적용
두 종류의 드랍아웃 옵션 사용
dropout: 층의 입력값에 대한 드랍아웃 비율 지정recurrent_dropout: 순환 유닛에 대한 드랍아웃 비율 지정
아래 코드는 LSTM 층에 recurrent_dropout=0.25 옵션을 사용해서 모델을 훈련한다.
드랍아웃을 사용하기에 층의 유닛 수를 이전보다 두 배 늘림.
과대적합이 보다 늦게 발생할 것을 대비해 에포크 수를 50으로 늘림.
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(32, recurrent_dropout=0.25)(inputs)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
학습과정을 그래프로 나타내면 다음과 같으며, 과대적합이 20 에포크 이후에 발생함을 확인할 수 있다. 동시에 모델의 성능도 좋아졌다.

RNN 층 실행시간 가속화
드랍아웃을 적용한 순환층을 실행하면 이전보다 훈련시간이 훨씬 오래 걸린다. 단순히 에포크 수가 늘어나서가 아니라 하나의 에포크에 걸리는 시간이 몇 십배 느려지기 때문이다. 이유는 드랍아웃을 사용하는 LSTM, GRU 모델은 cuDNN에서 지원되지 않기 때문이다.
하지만 타임스텝이 100 이하로 지정된 경우에 unroll=True 옵션을 사용하면
cuDNN을 잘 활용할 수는 있지만 메모리가 훨씬 많이 더 요구된다는 단점이 발생한다.
inputs = keras.Input(shape=(sequence_length, num_features))
x = layers.LSTM(32, recurrent_dropout=0.2, unroll=True)(inputs)
순환층 쌓기
아래 모델은 LSTM의 변종이면서 좀 더 가벼운 GRUGated Recurrent Unit 층을 사용한다.
앞서 언급한 대로 마지막 순환층을 제외한 모든 순환층에서 return_sequences=True 옵션을
지정해야 함에 주의해야 한다.
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.GRU(32, recurrent_dropout=0.5, return_sequences=True)(inputs)
x = layers.GRU(32, recurrent_dropout=0.5)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
학습과정을 그래프로 나타내면 다음과 같으며 모델의 성능이 좀 더 좋아졌다. 하지만 층을 더 이상 쌓는다고 해서 성능이 반드시 더 좋아진다는 보장은 없으며 오히려 나빠질 수도 있다.

양방향 RNN 적용
자연어 처리Natural language processing(NLP) 등에서는 한쪽 방향으로 뿐만 아니라 반대 방향으로 시퀀스의 타임스텝을 처리하는 과정을 동시에 진행하는 양방향 RNNbidirectional RNN 층이 매우 효율적으로 적용된다. 하지만 날씨 예측 등과 같이 시간의 순서가 결정적인 경우에는 별 도움되지 않는다.

inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Bidirectional(layers.LSTM(16))(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
성능 최대한 끌어올리기
모델의 성능을 끌어 올리는 기본적인 접근법은 다음과 같다.
층의 유닛 개수 및 드랍아웃 비율 조정
RMSprop등의 옵티마이저의 학습률 조정 및 다른 옵티마이저 활용순환층 이후에 여러 개의 밀집층 적용
시퀀스 길이 조정, 샘플 선택 비율 조정 등 기타 특성 엔지니어링 시도.