12. 자연어 처리#
감사의 글
아래 내용은 프랑소와 숄레의 Deep Learning with Python(2판)의 소스코드 내용을 참고해서 작성되었습니다. 자료를 공개한 저자에게 진심어린 감사를 전합니다.
소스코드
여기서 언급되는 코드를 (구글 코랩) 자연어 처리에서 직접 실행할 수 있다.
슬라이드
본문 내용을 요약한 슬라이드를 다운로드할 수 있다.
주요 내용
텍스트 벡터화
단어 임베딩
트랜스포머 아키텍처
시퀀스-투-시퀀스 학습
영어-한국어 번역
12.1. 자연어 처리 소개#
파이썬, 자바, C, C++, C#, 자바스크립트 등 컴퓨터 프로그래밍언어와 구분하기 위해 일상에서 사용되는 한국어, 영어 등을 자연어natural language라 부른다. 자연어의 특성상 정확한 분석을 위한 알고리즘을 구현하는 일은 매우 어렵다. 딥러닝 기법이 활용되기 이전까지는 적절한 규칙을 구성하여 자연어를 이해하려는 수 많은 시도가 있어왔지만 별로 성공적이지 않았다.
1990년대부터 인터넷으로부터 구해진 엄청난 양의 텍스트 데이터에 머신러닝 기법을 적용하기 시작했다. 단, 언어의 이해를 주요 목표로 삼기에는 기술, 하드웨어 측면 모두에서 부족하였으며, 아래 예제들처럼 입력 텍스트를 분석하여 통계적으로 유용한 정보를 예측하는 정도의 수준에 머물렀다.
텍스트 분류: “이 텍스트의 주제는?”
내용 필터링: “욕설 사용?”
감성 분석: “그래서 내용이 긍정적이야 부정적이야?”
언어 모델링: “이 문장 다음에 어떤 단어가 와야 할까?”
번역: “이거를 한국어로 어떻게 말해?”
요약: “이 기사를 한 줄로 요약해 볼래?”
이와 같은 일을 자연어 처리Natural Language Processing라 하며 단어와 텍스트에서 찾을 수 있는 패턴을 인식하려 시도한다.
텍스트란?
텍스트text는 문자, 단어, 문장, 글 등 자연어로 표현된 데이터를 가리킨다.
머신러닝 활용
자연어 처리를 위해 1990년대부터 시작된 머신러닝 활용의 변화과정은 다음과 같다.
1990 - 2010년대 초반: 결정트리, 로지스틱 회귀 모델이 주로 활용됨.
2014-2015: LSTM 등 시퀀스 처리 알고리즘 활용 시작
2015-2017: (양방향) 순환신경망이 기본적으로 활용됨.
2017-2018: 트랜스포머transformer 아키텍처가 많은 난제들을 해결함.
2022 이후: 트랜스포머 아키텍처를 이용한 GPT의 혁명적 발전
12.2. 텍스트 벡터화#
딥러닝 모델은 텍스트 자체를 처리할 수 없다. 따라서 텍스트를 수치형 텐서로 변환하는 텍스트 벡터화text vectorization 과정이 요구된다. 아래 그림이 텍스트 벡터화의 기본적인 과정을 잘 보여준다.
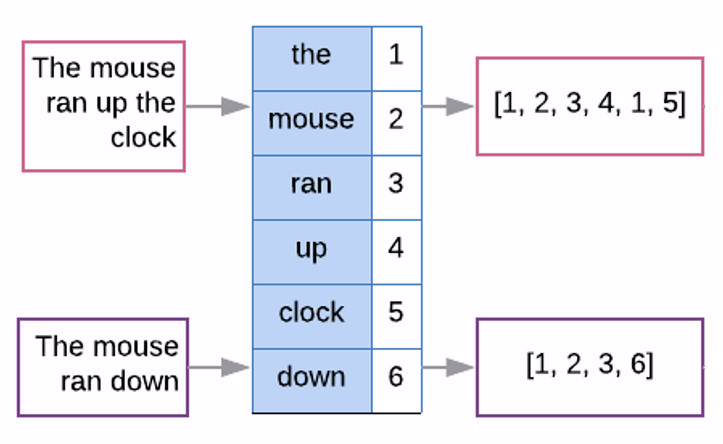
텍스트 벡터화는 보통 다음 세 단계를 따른다.
텍스트 표준화text standardization: 소문자화, 마침표 제거 등등
토큰화tokenization: 기본 단위의 유닛units으로 쪼개기. 문자, 단어, 단어 집합 등이 토큰으로 활용됨.
어휘 색인화vocabulary indexing: 토큰 각각을 하나의 정수 색인(인덱스)으로 변환.
12.2.1. 텍스트 표준화#
다음 두 텍스트를 표준화를 통해 동일한 텍스트로 변환해보자.
“sunset came. i was staring at the Mexico sky. Isnt nature splendid??”
“Sunset came; I stared at the México sky. Isn’t nature splendid?”
예를 들어 다음과 같은 표준화 기법을 사용할 수 있다.
모두 소문자화
.,;,?,'등 특수 기호 제거특수 알파벳 변환: “é”를 “e”로, “æ”를 “ae”로 등등
동사/명사의 기본형 활용: “cats”를 “[cat]”로, “was staring”과 “stared”를 “[stare]”로 등등.
그러면 위 두 텍스트 모두 아래 텍스트로 변환된다.
“sunset came i [stare] at the mexico sky isnt nature splendid”
표준화 과정을 통해 어느 정도의 정보를 상실하게 되지만
학습해야할 내용을 줄여 일반화 성능이 보다 좋은 모델을 훈련시키는 장점이 있다.
하지만 분석 목적에 따라 사용되는 표준화 기법이 달라질 수 있음에 주의해야 한다.
예를 들어 인터뷰 기사의 경우 물음표(?)는 제거하면 안된다.
12.2.2. 토큰화#
텍스트 표준화 이후 데이터 분석의 기본 단위인 토큰으로 쪼개야 한다. 보통 아래 세 가지 방식 중에 하나를 사용한다.
단어 토큰화
공백으로 구분된 단어들로 쪼개기.
경우에 따라 동사 어근과 어미를 구분하기도 함: “star+ing”, “call+ed” 등등
N-그램 토큰화
N-그램 토큰: 연속으로 위치한 N 개(이하)의 단어 묶음
예제: “the cat”, “he was” 등은 2-그램(바이그램) 토큰
문자 토큰화
하나의 문자를 하나의 토큰으로 지정.
텍스트 생성, 음성 인식 등에서 활용됨.
일반적으로 문자 토큰화는 잘 사용되지 않는다. 단어 토큰화와 N-그램 토큰화를 간략하게 소개하면 다음과 같다.
단어 토큰화: 단어들의 순서를 중요시하는 시퀀스 모델sequence models을 사용할 경우 주로 활용된다.
N-그램 토큰화: 단어들의 순서를 별로 상관하지 않는 단어 주머니bag-of-words 모델을 사용할 경우 주로 활용된다.
N-그램: 단어들 사이의 순서에 대한 지엽적 정보를 어느 정도 유지
일종의 특성 공학feature engineering 기법이며, 트랜스포머 등 최신 기법에는 활용되지 않음.
단어 주머니bag-of-words는 N-그램으로 구성된 집합을 의미하며 N-그램 주머니라고도 불린다. 예를 들어 “the cat sat on the mat.”에 대한 바이그램과 3-그램 주머니는 각각 다음과 같다.
2-그램(바이그램) 주머니
{"the", "the cat", "cat", "cat sat", "sat", "sat on", "on", "on the", "the mat", "mat"}
3-그램 주머니
{"the", "the cat", "cat", "cat sat", "the cat sat", "sat", "sat on", "on", "cat sat on", "on the", "sat on the", "the mat", "mat", "on the mat"}
여기서는 단어 토큰화를 이용한 자연어 처리 분석을 소개한다.
12.2.3. 어휘 색인화#
훈련셋에 포함된 모든 단어 토큰들의 색인(인덱스)을 생성한다.
6장에서 언급한 대로
사용 빈도가 높은 1만, 2만, 또는 3만 개의 단어만을 대상으로 어휘 색인화를 진행하는 게 일반적이다.
당시에 IMDB 영화 후기 데이터셋을 아래와 같이 불러오면서 불러올 때
num_words=10000을 사용하여 사용 빈도수가 상위 1만 등 안에 들지 않는 단어는
영화 후기에서 무시되도록 하였다.
from tensorflow.keras.datasets import imdb
imdb.load_data(num_words=10000)
어휘 색인화를 통해 생성된 어휘집vocabulary을 이용하여 텍스트를 아래와 같은 색인으로 구성된 리스트로 변환하는 과정이 텍스트 벡터화다.
[1, 14, 22, 16, 43, 530, 973, 1, 1385, 65, 0, 0, 0, 0, 0]
참고로 텍스트를 변환한 벡터에 사용되는 0과 1은 특별한 기능을 수행한다. 바로 위의 색인 리스트에는 1이 두 번, 0이 5번 사용되었다.
1의 기능: 미등록 어휘 인덱스. 즉, 어휘 색인에 미등록된(out-of-vocabulary, OOV) 단어는 모두 1로 처리된다. 그런 단어는 일반 텍스트로 재번역되는 경우 “[UNK]”, 즉 모르는(unknown) 단어로 표현된다.
0의 기능: 텍스트의 길이를 통일시키기 위해 패딩으로 사용하며, 마스크 토큰mask token이라 부르리도 한다.
영화 후기 분석을 위해 6장에서 사용한 케라스의 imdb 데이터셋은 앞서 설명한 방식으로 이미 텍스트 벡터화가 완료된 상태였다. 여기서는 영어 텍스트로 작성된 원본 영화 후기로 구성된 imdb 데이터셋을 다운로드하여 텍스트 벡터화 전처리를 직접 수행하는 단계부터 살펴보려 한다.
TextVectorization 층
케라스의 TextVectorization 층을 이용하여 텍스트 벡터화를 진행할 수 있다.
아래 코드는 TextVectorization 층의 구성에 사용되는 주요 기본 설정을 보여준다.
표준화, 토큰화, 출력 모드를 다양한 방식으로 지정할 수 있지만 기본값만 다룬다.
자세한 내용은 케라스 벡터화 층 공식문서를 참고한다.
표준화
standardize='lower_and_strip_punctuation': 소문자화와 마침표 등 제거
토큰화
split='whitespace': 단어 기준 쪼개기ngrams=None: n-그램 미사용
출력 모드
output_mode="int": 단어를 정수 색인으로 인코딩
텍스트 길이 제한
output_sequence_length=None: 단어 길이 제한 지정. 제한 없음이 기본값.
>>> from tensorflow.keras.layers import TextVectorization
>>> text_vectorization = TextVectorization(
... standardize='lower_and_strip_punctuation', # 기본값
... split='whitespace', # 기본값
... ngrams=None, # 기본값
... output_mode='int', # 기본값
... output_sequence_length=None, # 기본값
... )
예를 들어, 아래 데이터셋을 이용하여 텍스트 벡터화에 사용될 어휘집을 생성해보자.
>>> dataset = [
... "I write, erase, rewrite",
... "Erase again, and then",
... "A poppy blooms.",
... ]
어휘 색인화와 어휘집 생성은 adapt() 메서드가 담당한다.
>>> text_vectorization.adapt(dataset)
생성된 어휘집은 다음과 같다.
>>> vocabulary = text_vectorization.get_vocabulary()
>>> vocabulary
['',
'[UNK]',
'erase',
'write',
'then',
'rewrite',
'poppy',
'i',
'blooms',
'and',
'again',
'a']
텍스트 벡터화
생성된 어휘집을 활용하여 새로운 텍스트를 벡터화 해보자.
어휘집에 포함되지 않은 'still' 단어는 1로 변환되며
텍스트의 길이 설정은 없기에 0, 즉 마스크 토큰을 이용한 패딩은 사용되지 않는다.
>>> test_sentence = "I write, rewrite, and still rewrite again"
>>> encoded_sentence = text_vectorization(test_sentence)
>>> print(encoded_sentence)
tf.Tensor([ 7 3 5 9 1 5 10], shape=(7,), dtype=int64)
벡터화된 텐서로부터 텍스트를 복원하면 표준화된 텍스트가 생성된다.
1로 변환된 'still'은 [UNK]로 복원된다.
>>> inverse_vocab = dict(enumerate(vocabulary))
>>> decoded_sentence = " ".join(inverse_vocab[int(i)] for i in encoded_sentence)
>>> print(decoded_sentence)
i write rewrite and [UNK] rewrite again
TextVectorization 층과 GPU
TextVectorization 층은 GPU 또는 TPU에서 지원되지 않는다.
따라서 모델 구성에 직접 사용하는 방식은 모델의 훈련을
늦출 수 있기에 권장되지 않는다.
일반적으로 모델 훈련을 위한 데이터셋 전처리는
모델 구성과 독립적으로 처리한다.
하지만 훈련이 완성된 모델을 실전에 배치할 경우 TextVectorization 층을
완성된 모델에 추가해서 사용한다.
12.2.4. IMDB 영화 후기 데이터셋 벡터화#
IMDB 영화 후기 데이터셋을 이용하여 텍스트 벡타화 과정을 상세히 살펴 본다.
과정 1: 데이터셋 다운로드 후 압축 풀기
먼저 자연어로 구성된 IMDB 영화 후기 데이터셋을 다운로드한다. 5만 개의 IMDB 영화 후기를 압축한 aclImdb_v1.tar,gz 파일을 다운로드 한 후에 압축을 풀면 아래 구조의 디렉토리가 생성된다.
aclImdb/
...test/
......pos/
......neg/
...train/
......pos/
......neg/
train과 test 디렉토리 각각에 포함된 pos와 neg 서브디렉토리는
각각 12,500 개의 긍정과 부정 후기를 포함한다.
과정 2: 검증셋 준비
훈련셋의 20%를 검증셋으로 떼어낸다.
이를 위해 aclImdb/val 디렉토리를 생성한 후에
긍정과 부정 훈련셋 모두 무작위로 섞은 후 그중 20%를 검증셋 디렉토리로 옮긴다.
최종적으로 자연어로 구성된 IMDB 영화 후기 원본 데이터셋이 아래 디렉토리 구조로 나뉜다.
train:pos와neg서브디렉토리에 각각 10,000 개의 긍정과 부정 후기 포함test:pos와neg서브디렉토리에 각각 12,500 개의 긍정과 부정 후기 포함val:pos와neg서브디렉토리에 각각 2,500 개의 긍정과 부정 후기 포함
aclImdb/
...test/
......pos/
......neg/
...train/
......pos/
......neg/
...val/
......pos/
......neg/
과정 3: 텐서 데이터셋 준비
keras.utils.text_dataset_from_directory() 함수를 이용하여
훈련셋 텐서, 검증셋 텐서, 테스트셋 텐서를 생성한다.
생성된 값들의 자료형은 모두 Dataset이다.
Dataset 자료형은
데이터 샘플을 일정 크기로 묶은 배치 데이터셋으로 구성된다.
여기서는 데이터 샘플을 32 개씩 묶은 배치를 사용한다.
batch_size = 32
train_ds = keras.utils.text_dataset_from_directory(
"aclImdb/train", batch_size=batch_size)
val_ds = keras.utils.text_dataset_from_directory(
"aclImdb/val", batch_size=batch_size)
test_ds = keras.utils.text_dataset_from_directory(
"aclImdb/test", batch_size=batch_size)
Dataset의 항목이 입력값과 타깃으로 구성된 튜플 형식임에 주의한다.
사실 다운로드한 IMDB 데이터셋은 영화 후기만 포함한다.
그런데 text_dataset_from_directory() 함수가 컴퓨터 하드디스크의 디렉토리에 저장된
영화 후기를 Dataset 자료형의 텐서로 불러올 때
pos와 neg 서브디렉토리에 포함된 영화 후기의 타깃으로
각각 1과 0을 지정한다.
예를 들어, 훈련셋 텐서인 train_ds에 포함된 첫째 배치 항목에 포함된 첫째 훈련 샘플의 입력값과 타깃의 정보는 다음과 같다.
입력 샘플은 텐서플로우의 tf.string 이라는 문자열 텐서로,
타깃은 int32 정수 텐서로 지정된다.
tf.string은 파이썬의 기본 자료형인 str과 다름에 주의한다.
>>> for inputs, targets in train_ds:
... print("inputs.shape:", inputs.shape)
... print("inputs.dtype:", inputs.dtype)
... print("targets.shape:", targets.shape)
... print("targets.dtype:", targets.dtype)
... # 예제: 첫째 배치의 첫째 후기
... print("inputs[0]:", inputs[0])
... print("targets[0]:", targets[0])
... break
inputs.shape: (32,)
inputs.dtype: <dtype: 'string'>
targets.shape: (32,)
targets.dtype: <dtype: 'int32'>
inputs[0]: tf.Tensor(b'The film begins with a bunch of kids in reform school and
focuses on a kid named \'Gabe\', who has apparently worked hard to earn his parole.
Gabe and his sister move to a new neighborhood to make a fresh start and soon Gabe
meets up with the Dead End Kids. The Kids in this film are little punks, but they
are much less antisocial than they\'d been in other previous films and down deep,
they are well-meaning punks. However, in this neighborhood there are also some
criminals who are perpetrating insurance fraud through arson and see Gabe as a
convenient scapegoat--after all, he\'d been to reform school and no one would
believe he was innocent once he was framed. So, when Gabe is about ready to be sent
back to "The Big House", it\'s up to the rest of the gang to save him and expose
the real crooks.<br /><br />The "Dead End Kids" appeared in several Warner Brothers
films in the late 1930s and the films were generally very good (particularly ANGELS
WITH DIRTY FACES). However, after the boys\' contracts expired, they went on to
Monogram Studios and the films, to put it charitably, were very weak and formulaic
--with Huntz Hall and Leo Gorcey being pretty much the whole show and the group
being renamed "The Bowery Boys". Because ANGELS WASH THEIR FACES had the excellent
writing and production values AND Hall and Gorcey were not constantly mugging for
the camera, it\'s a pretty good film--and almost earns a score of 7 (it\'s REAL
close). In fact, while this isn\'t a great film aesthetically, it\'s sure a lot of
fun to watch, so I will give it a 7! Sure, it was a tad hokey-particularly towards
the end when the kids take the law into their own hands and Reagan ignores the Bill
of Rights--but it was also quite entertaining. The Dead End Kids are doing their
best performances and Ronald Reagan and Ann Sheridan provided excellent support.
Sure, this part of the film was illogical and impossible but somehow it was still
funny and rather charming--so if you can suspend disbelief, it works well.',
shape=(), dtype=string)
targets[0]: tf.Tensor(1, shape=(), dtype=int32)
과정 4: 텍스트 벡터화
데이터셋에 포함된 모든 영화 후기를 대상으로 텍스트 벡터화를 진행한다. 단, 영화 후기가 최대 600 개의 단어만 사용하도록 한다. 또한 사용되는 어휘는 사용빈도 기준으로 최대 2만 개로 제한한다.
영화 후기의 길이를 600 개의 단어로 제한한 이유는 후기가 평균적으로 233 개의 단어를 사용하고, 600 단어 이상을 사용하는 후기는 전체의 5% 정도에 불과하기 때문이다. 600 개 이상의 단어를 사용하는 영화 후기는 모두 600 단어로 끊는다. 600 개보다 적은 수의 단어를 사용한다면 마스크 토큰 0을 패딩으로 사용한다.
아래 코드는 텍스트 벡터화를 진행할 TextVectorization 층을 지정한다.
max_length = 600 # 후기 길이 제한
max_tokens = 20000 # 단어 사용빈도 제한
text_vectorization = layers.TextVectorization(
max_tokens=max_tokens, # 후기에 사용되는 단어의 종류는 총 2만 종류
output_mode="int",
output_sequence_length=max_length, # 하나의 후기에 포함된 최대 단어는 최대 600 개
)
어휘 색인화는 훈련셋만 대상으로 진행한다.
따라서 훈련셋에 포함되지 않은 단어는 모두 1로 처리되어 무시된다.
어휘 색인화를 위해 먼저 map() 메서드를 이용하여 훈련셋에서 타깃을 제외한 영화 후기만으로 구성된
데이터셋을 생성한다.
map()메서드:map()메서드의 반환값은 인자로 지정된 함수가 각각의 샘플에 대해 적용된 결과를 동일한 크기의 배치로 묶은Dataset객체이다.lambda x, y: x함수: 튜플 형식의 인자를 받아 첫째 항목을 반환하는 람다 함수이다. 여기서는train_ds텐서에 포함된 샘플이 영화 후기와 타깃을 하나로 묶은 튜플 형식의 값이기 때문에 영화 후기만을 추출하기 위해 사용된다.
# 어휘 색인 생성 대상 훈련셋 후기 텍스트 데이터셋
text_only_train_ds = train_ds.map(lambda x, y: x)
# 어휘 색인
text_vectorization.adapt(text_only_train_ds)
생성된 어휘집을 이용하여 훈련셋, 검증셋, 테스셋 모두 텍스트 벡터화를 진행한다.
영화 후기만을 대상으로 벡터화를 진행해야 하기에
map() 메서드를 이용하여 영화 후기와 타깃을 구분한다.
# 후기를 길이가 2만인 정수들의 리스트로 변환
int_train_ds = train_ds.map(lambda x, y: (text_vectorization(x), y))
int_val_ds = val_ds.map(lambda x, y: (text_vectorization(x), y))
int_test_ds = test_ds.map(lambda x, y: (text_vectorization(x), y))
예를 들어, 벡터화된 훈련셋의 첫째 영화 후기, 즉 첫째 배치의 첫째 샘플은 다음과 같다.
>>> for inputs, targets in int_train_ds:
... print("inputs[0]:", inputs[0])
... break
tf.Tensor(
[ 11 7 4 8614 18 38 9 139 138 197 640 12
30 22 167 6 3035 2 86 3146 664 19 12 291
11 14 2400 2996 13 55 322 429 11 19 172 4
337 35 116 230 172 4 1107 2 196 1562 14 12
10 399 9 100 9 14 478 46 1368 162 31 47
509 56 2 7585 645 66 733 5 239 1428 1 17
2 86 18 3 56 47 645 12 23 66 6 28
920 6 376 19 197 107 14487 39 8 8227 83 23
103 235 1 16 6307 13 4 309 869 21 2 7585
645 10 14 776 6 158 12 593 5 2 645 67
41 3488 5321 8 188 48 67 208 57 1 31 32
2 1990 67 154 239 1265 35 154 66 4 1 3
67 208 8 50 1244 450 39 55 322 6 103 12
217 53 6 493 72 167 6 2 3925 3 11 18
7 479 8 144 1 13 8499 49 330 2 223 14
5673 22 730 15 1428 15 8 2 86 42 327 18
19 943 5 250 16 2 322 57 2027 1932 383 62
14 4 13077 16 70 4 110 215 19 157 100 609
2 1013 5 1 500 55 322 3987 22 242 4 3852
690 14 2207 16 12 2227 13 32 8 32 450 129
11 7 4 84 18 16 322 5 98 588 29 172
1319 2224 6 381 99 104 10 328 22 6 28 2012
2677 19 193 66 6 1810 58 3 460 127 2 247
301 4 163 93 12 67 324 1 72 848 19 321
2224 6 544 2 698 301 11 29 450 129 1245 183
574 149 23 225 158 12 23 341 9 100 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0],
shape=(600,), dtype=int64)
12.3. 단어 임베딩#
단어 임베딩word embedding은 텍스트 벡터화를 통해 생성된 어휘집의 단어가 문맥에 따라 가질 수 있는 여러 의미와 다른 단어들과의 연관성 정보를 표현하는 부동소수점들로 구성된 벡터로 변환하는 과정이다.
Embedding 층
단어 임베딩은 모델 훈련을 통해 학습되도록 유도한다. 이유는 언어 종류, 텍스트 내용, 모델 훈련 목적에 따라 단어들 사이의 관계가 다르게 학습되어야 하기 때문이다. 예를 들어, 영화 후기에 포함된 텍스트와 재판 판결문 텍스트는 단어의 종류뿐만 아니라 동일한 단어의 의미와 용도까지 많이 다를 수 있기에 당연히 단어 임베딩 또한 달라져야 한다.
케라스의 Embedding 층이 훈련셋에 따라 다른 단어 임베딩이 학습되도록 하는 기능을 제공한다.
Embedding 층을 선언하는 방식은 아래 코드와 같다.
input_dim: 총 어휘 수. 여기서는 7 개.output_dim: 단어 임베딩에 사용되는 벡터의 크기. 여기서는 단어별로 4 개의 특성을 찾도록 유도함.
vocab_size = 7 # 총 어휘 수
embed_dim = 4 # 단어별로 4 개의 특성 파악.
embedding_layer = tf.keras.layers.Embedding(input_dim=vocab_size,
output_dim=embed_dim)
위와 같이 선언된 Embedding 층은 (7, 4) 모양의 2차원 텐서로 구성되며
모델 훈련이 시작될 때 균등 분포를 이용하여 초기화된다.
이후 훈련을 통해 7x4 개의 항목이 훈련 파라미터로써 학습된다.
아래 그림은 앞서 정의한 Embedding 층의 작동 과정을 보여준다.
예를 들어 6개의 단어로 구성된 “The mouse ran up the clock” 텍스트를 단어 임베딩하는 과정은 다음과 같다.
먼저 단어들의 정수 색인으로 구성된 길이가 6인 벡터인
[1, 2, 3, 4, 1, 5]로 변환한다.단어 임베딩을 통해 4 개의 부동소수점을 포함한 벡터 6 개로 구성된 (6, 4) 모양의 텐서로 변환된다.
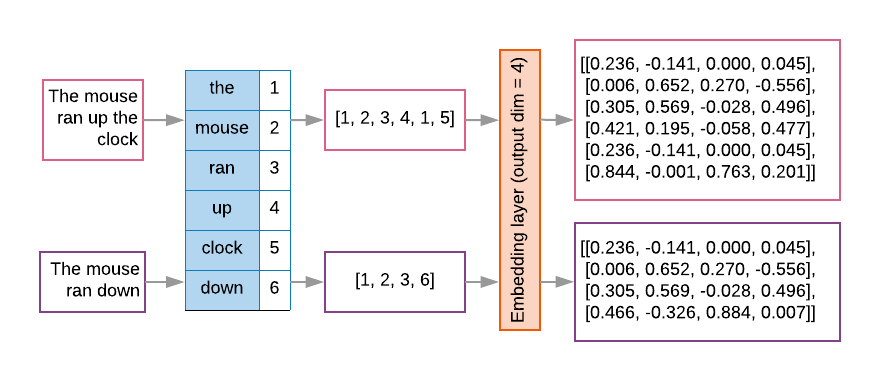
위 그림에서의 단어 임베딩에 사용된 (7, 4) 모양의 2차원 텐서는 다음과 같다.
embedding_matrix = [[-0.012, 0.005, 0.008, 0.001],
[0.236, -0.141, 0.000, 0.045],
[0.006, 0.652, 0.270, -0.556],
[0.305, 0.569, -0.028, 0.496],
[0.421, 0.195, -0.058, 0.477],
[0.844, -0.001, 0.763, 0.201],
[0.466, -0.326, 0.884, 0.007]]
그리고 “The mouse ran up the clock” 벡터화된
[1, 2, 3, 4, 1, 5] 가 Embedding 층에 입력되면
아래와 같이 위 embedding_matrix로부터
각각의 색인에 해당하는 벡터를 추출하여
(6, 4) 모양의 출력 텐서를 생성한다.
'the' => 1 => [0.236, -0.141, 0.000, 0.045]'mouse' => 2 => [0.006, 0.652, 0.270, -0.556]'ran' => 3 => [0.305, 0.569, -0.028, 0.496]'up' => 4 => [0.421, 0.195, -0.058, 0.477]'the' => 1 => [0.236, -0.141, 0.000, 0.045]'clock' => 5 => [0.844, -0.001, 0.763, 0.201]
반면에 “The mouse ran down”는 [1, 2, 3, 6]으로 벡터화 되기에 Embedding 층을
통과할 때 (4, 4) 모양으로 단어 임베딩된다.
'the' => 1 => [0.236, -0.141, 0.000, 0.045]'mouse' => 2 => [0.006, 0.652, 0.270, -0.556]'ran' => 3 => [0.305, 0.569, -0.028, 0.496]'down' => 6 => [0.466, -0.326, 0.884, 0.007]
단어 임베딩의 의미
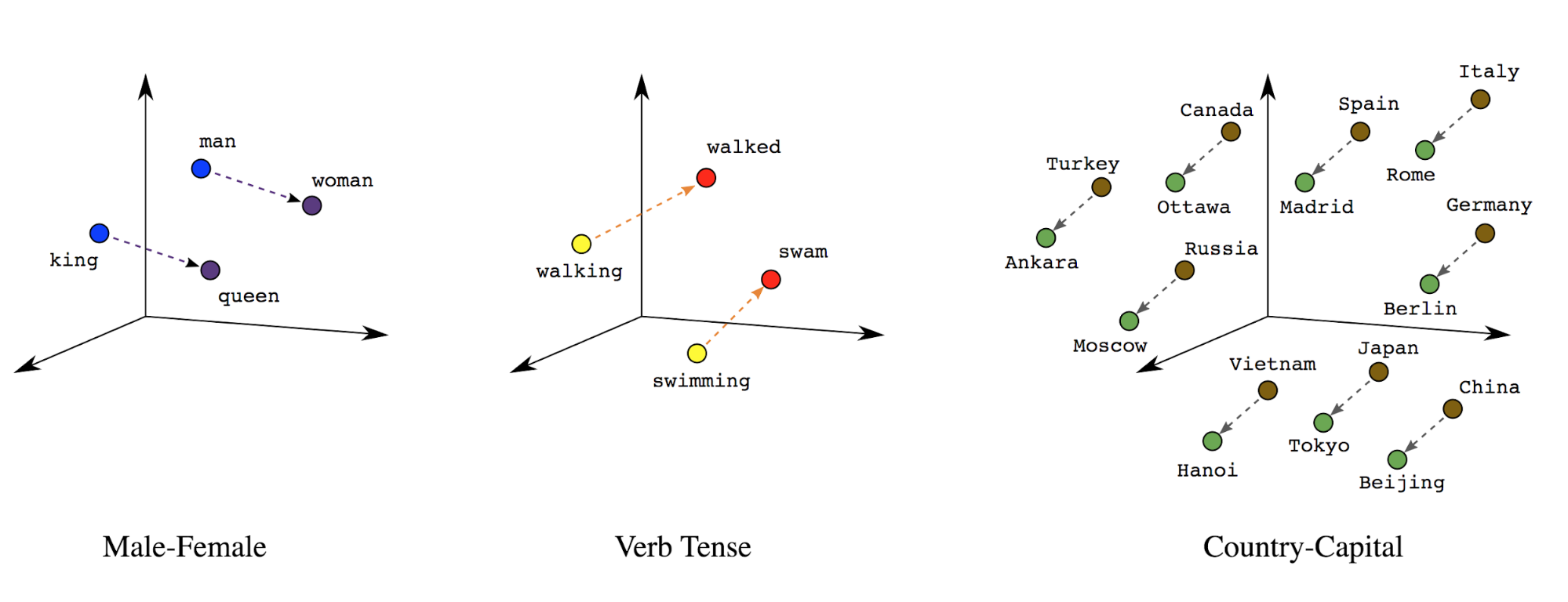
단어 임베딩의 결과로 생성된 벡터에 포함된 각각의 항목은 해당 단어가 가질 수 있는 다양한 의미를 가리킨다. 아래 그림은 3차원 벡터로 변환된 단어들의 예시를 담고 있다.
왼쪽: 남성을 가리키는 용어와 여성을 가리키는 용어의 관계
가운데: 동사의 시제 관계
오른쪽: 국가와 국가의 수도 관계
단어 임베딩 활용법
단어 임베딩은 입력층 다음에 위치시킨다. 그러면 어휘 인덱스로 구성된 훈련 배치 데이터셋에 대해 바로 단어 임베딩을 실행한다. 그 이후에 텍스트의 내용을 파악하는 훈련을 시작할 수 있다.
아래 코드에서 Embedding 층 바로 다음에 위치하는
TransformerEncoder 층이 텍스트의 내용을 파악한다.
그런 다음에 최종적으로 모델의 예측값을 Dense 층을 통해 결정한다.
vocab_size = 20000 # 총 어휘 수
embed_dim = 256 # 단어별로 256 개의 특성 파악.
# 입력층: 단어 벡터화된 배치 데이터셋
inputs = keras.Input(shape=(None,), dtype="int64")
# 단어 임베딩 실행
x = layers.Embedding(vocab_size, embed_dim)(inputs)
# 트랜스포머 인코더: 텍스트 내용 파악
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
# 출력층
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델 선언
model = keras.Model(inputs, outputs)
12.4. 트랜스포머 아키텍처#
앞서 언급한 트랜스포머 인코더는 2017년에 발표된 논문인 “Attention is all you need”에서 트랜스포머Transformer 아키텍처의 주요 구성 요소 중 하나로 소개되었다. 트랜스포머 아키텍처는 셀프 어텐션Self attention 이라는 뉴럴 어텐션neural attention 기법을 이용하며 자연어처리 분야에서 혁명을 불러왔다.
12.4.1. 셀프 어텐션#
입력값의 특성 중에 보다 중요한 특성에 집중attention하면 보다 효율적으로 훈련이 진행될 수 있다. 아래 그림에서 볼 수 있듯이 이미지의 주요 부분에 집중하여 보다 효율적인 이미지 분석을 진행할 수 있다. 그림 왼쪽 하단에 위치한 어텐션 점수attention score는 위쪽 고양이 사진에 포함된 각각의 픽셀에 대한 가중치로 구성된다. 오른쪽 사진은 원본 이미지와 어텐션 점수를 곱한 결과로 고양이의 머리에만 집중한다. 이와같이 모든 입력 사진에 어텐션 점수를 계산하여 활용한다면 사진 분석 모델을 보다 효율적으로 훈련시킬 수 있다.

자연어 처리에서의 셀프 어텐션
셀프 어텐션self-attention은 샘플의 어텐션 점수를 계산할 때 샘플 자신을 활용하는 기법이며 자연어 처리에서 텍스트에 포함된 단어들의 문맥상의 의미를 파악하기 위해 활용된다.
아래 그림은 “The train left the station on time.” 이라는 텍스트를 먼저 단어 임베딩한 다음에 셀프 어텐션을 적용하는 과정을 보여준다.
먼저 텍스트를
Embedding층을 이용하여 단어 임베딩시킨다.생성된 벡터 시퀀스에 셀프 어텐션을 적용하여 문맥이 적용된 동일 모양의 새로운 벡터 시퀀스를 생성한다.
1단계: 텍스트에 사용된 각 토큰들 사이의 연관성을 계산하여 어텐션 점수 계산
2단계: 계산된 어텐션 점수를 시퀀스의 각 단어 벡터와 결합시킨 후 더해서 단어별로 문맥이 반명된 새로운 단어 벡터 생성
그림 맨 오른쪽에 생성된 벡터는 “station”이 “train” 단어와 연결되어 “기차역”을 가리킨다는 문맥상의 의미를 반영하여 변환된 벡터를 가리킨다.
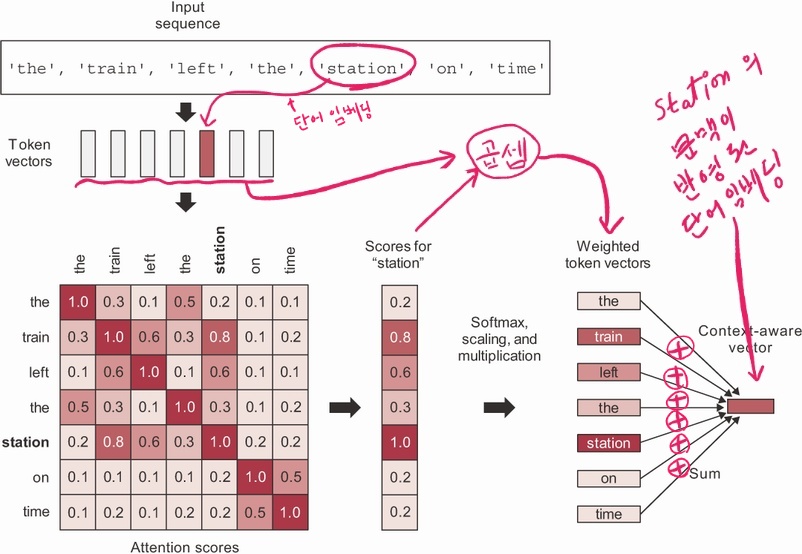
아래 self_attention() 함수는 셀프 어텐션이 작동하는 과정을 설명하는 유사코드다.
함수의 입력값은 단어 임베딩된 시퀀스이다.
def self_attention(input_sequence):
# 문맥이 반영된 시퀀스 저장
output = np.zeros(shape=input_sequence.shape)
# 단어 임베딩된 시퀀스의 단어 벡터 각각(pivor_vector)에 대해
# 셀프 어텐션 실행. 위 그림 참고.
for i, pivot_vector in enumerate(input_sequence):
# pivot_vector와 다른 단어 벡터들 사이의 문맥 점수 계산
scores = np.zeros(shape=(len(input_sequence),))
for j, vector in enumerate(input_sequence):
scores[j] = np.dot(pivot_vector, vector.T)
# 계산된 점수를 스케일링 후 소프트맥스 적용
scores /= np.sqrt(input_sequence.shape[1])
scores = softmax(scores)
# 문맥이 반영된 단어 벡터로 변환
# 각 단어 벡터와 점수를 곱한 결과를 더함.
new_pivot_representation = np.zeros(shape=pivot_vector.shape)
for j, vector in enumerate(input_sequence):
new_pivot_representation += vector * scores[j]
# pivot_vector를 변환한 벡터 저장
output[i] = new_pivot_representation
return output
케라스에서는 셀프 어텐션 기능을 MultiHeadAttention 층이 지원한다.
num_heads = 2 # 두 개의 셀프 어텐션 동시 진행. 각각 다른 문맥을 파악.
embed_dim = 256 # 단어 임베딩된 벡터의 길이
mha_layer = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
outputs = mha_layer(inputs, inputs, inputs)
질문-열쇠-값query-key-value
동일한 값을 인자로 세 번 사용하는 mha_layer(inputs, inputs, inputs), 즉 셀프 어텐션의 작동 과정을
식으로 표현하면 다음과 같다.
outputs = sum(inputs * pairwise_scores(inputs, inputs))
위 식은 원래 검색 엔진 또는 추천 시스템 등에서 질문-열쇠-값query-key-value 세 개의 입력값을 받는 보다 일반화된 어텐션의 작동과정을 표현한 식의 특별한 경우이다.
outputs = sum(values * pairwise_scores(query, keys))
예를 들어, 아래 그림은 “dogs on the beach.”라는 질문query에 가장 적절한 사진을 검색할 때 각 사진과의 핵심 연관성key 점수를 계산한 후 해당 사진value과 결합하여 가장 높은 점수를 갖는 사진을 추천하는 과정을 보여준다.

셀프 어텐션은 질문, 열쇠, 값 모두 동일한 값을 사용하여 주어진 대상이 자신을 비교 대상으로 활용하여 스스로 어느 부분에 집중할지를 판단하는 과정으로 이해할 수 있다.
12.4.2. 멀티헤드 어텐션#
멀티헤드 어텐션multi-head attention은 어텐션 변환을 수행하는 헤드head를 여러 개 사용해서 다양한 관점에서 단어들 사이의 연관성을 알아낸 후에 알아낸 결과를 합치는 기법이다. 아래 그림은 두 개의 헤드가 작동하는 과정을 보여준다. 각각의 헤드에 별도의 밀집층이 사용됨에 주목한다. 질문, 열쇠, 값을 어텐션 층에 넣어 주기 전에 먼저 밀집층을 이용하여 모델 스스로 질문, 열쇠, 값을 적절하게 변환하도록 유도한다.

두 개의 헤드를 사용하는 경우 입력 텐서를 아래처럼 각 단어의 특성을 이등분하여 각각의 헤드의 입력값으로 지정한다.
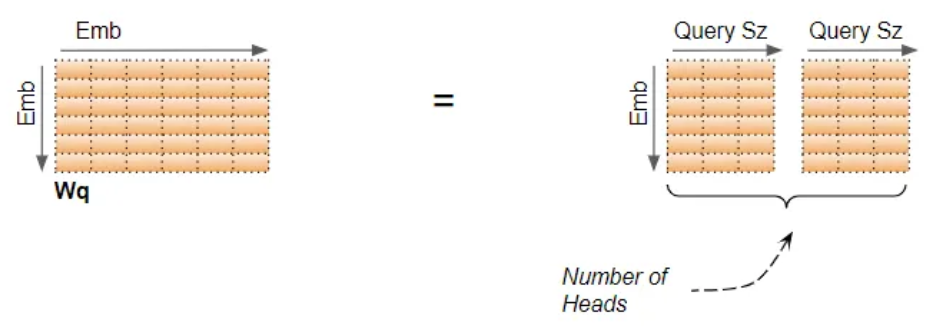
예를 들어 (600, 256) 으로 단어 임베딩된 텍스트가 두 개의 헤드를 사용하는 MultiHeadAtention에 입력되면
(600, 128) 모양의 두 개의 입력 텐서로 쪼개져서 각각의 헤드에서 셀프 어텐션이 적용되어
(600, 128) 모양의 출력 텐서로 변환된다.
이후에 두 출력 텐서를 다시 하나로 합쳐서 (600, 256) 모양의 텐서가 MultiHeadAtention의 최종 출력 텐서가 된다.
12.4.3. 트랜스포머 인코더#
헤드에 사용된 밀집층의 역할이 큰 것으로 밝혀지면서
멀티헤드 어텐션 층, 밀집dense 층, 정규화 층, 잔차 연결을
조합한 트랜스포머 인코더transformer encoder가 완성되었다.
정규화 층으로 사용되는 LayerNormalization은 배치 단위가 아닌 시퀀스 단위로 정규화를 실행하며
BatchNormalization과는 다르다.
트랜스포머 인코더에 포함된 LayerNormalization은
정규화를 배치 단위가 아닌 시퀀스 단위로 정규화를 실행하는 층이며
BatchNormalization과는 다르게 작동한다.

트랜스포머 인코더는 트랜스포머 아키텍처의 두 구성 요소중의 하나이다. 다른 요소는 아래 그림의 오른쪽에 위치한 트랜스포머 디코더transformer decoder이다. 트랜스포머 아키텍처는 언어 번역 등 텍스트를 텍스트로 변환하는 모델로 가장 많이 활용된다. 트랜스포머 디코더에 대해서는 아래에서 자세히 다룬다.
트랜스포머 인코더 구현
위 그림에서 설명된 트랜스포머 인코더를 층으로 구현하면 다음과 같다. 생성자의 인자는 다음과 같다.
embed_dim: 예를 들어embed_dim=256은 단어 임베딩(600, 256)모양의 샘플 생성dense_dim: 밀집 층에서 사용되는 유닛unit 개수num_heads: 헤드head 개수
call() 메서드의 attention_mask 옵션은 MultiHeadAttention 층을 호출할 때
사용되며 질문query에 들어온 입력값의 특정 위치를 무시할 필요가 있을 때 사용한다.
하지만 여기서는 굳이 사용하지 않는다.
어텐션 층은 원래 query-key-value에 해당하는 세 개의 인자를 요구하지만 query와 key 두 개의 인자만 지정하면 key 인자를 value 인자로 함께 사용한다. 아래 코드에서는 query와 key 모두 동일한 입력값을 사용하기에 셀프-어텐션 기능으로 작동한다.
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim # 예를 들어 256
self.dense_dim = dense_dim # 예를 들어 32
self.num_heads = num_heads # 예를 들어 2
# 어텐션 층 지정
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
# 밀집층 블록 지정
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
# 층 정규화 지정
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
# 트랜스포머 인코더의 순전파
def call(self, inputs, mask=None):
if mask is not None:
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
# 트랜스포머 인코더의 속성 지정
# 훈련된 모델을 저장할 때 활용됨
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
트랜스포머 인코더 활용
단어 벡터화된 훈련셋이 입력되면 먼저 단어 임베딩을 통과시켜 하나의 단어가 가질 수 있는 일반적인 특성을 찾는다. 이후 트랜스포머 인코더로 셀프 어텐션을 적용하여 단어가 사용되는 텍스트에서의 문맥상의 특성을 추가한다.
사용되는 변수들은 다음과 같다.
vocab_size = 20000: 어휘 색인 크기embed_dim = 256: 단어 임베딩 특성 수num_heads = 2: 트랜스포머 인코더에 사용되는 밀집층의 헤드(head) 수dense_dim = 32: 트랜스포머 인코더에 사용되는 밀집층의 유닛(unit) 수
inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
# (600, 256) 모양의 단어 임베딩된 텍스트 텐서를
# 길이가 256인 1차원 어레이로 변환.
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
GlobalMaxPooling1D
벡터(1차원 텐서)로 구성된 시퀀스가 GlobalMaxPooling1D 층을 통과하면 벡터의 특성별로 최댓값만 추출해서 사용한다.
따라서 벡터의 길이에 해당하는 하나의 벡터가 생성된다.
예를 들어, (4, 2, 3) 모양의 텐서, 즉, 길이가 3인 두 개의 벡터로 구성된 시퀀스 네 개를 묶은 배치가 GlobalMaxPooling1D 층을
통과해서 (4, 3) 모양의 텐서가 생성된다.
>>> x = tf.constant(
... [[[ 1., 5., 3.],
... [ 4., 2., 6.]],
... [[ 7., 8., 12.],
... [10., 11., 9.]],
... [[16., 14., 15.],
... [13., 17., 18.]],
... [[19., 20., 21.],
... [22., 23., 24.]]])
>>> max_pool_1d = tf.keras.layers.GlobalMaxPooling1D()
>>> max_pool_1d(x)
<tf.Tensor: shape=(4, 3), dtype=float32, numpy=
array([[ 4., 5., 6.],
[10., 11., 12.],
[16., 17., 18.],
[22., 23., 24.]], dtype=float32)>
앞서 살펴 본 모델에서 사용된 단어 임베딩은 단어순서를 제대로 활용하지는 못한다. 그런데 단어 인코딩 과정에서 단어의 순서 정보까지 추가하면 트랜스포머 인코더에게 단어들의 기능과 문맥을 보다 잘 추출하는 데에 도움이 된다.
다음 PositionalEmbedding 층 클래스는 두 개의 임베딩 클래스를 순전파에 사용한다.
단어 임베딩
self.token_embeddings = layers.Embedding(input_dim=input_dim, output_dim=output_dim)
위치 임베딩
self.position_embeddings = layers.Embedding(input_dim=sequence_length, output_dim=output_dim)
순전파를 담당하는 call() 메서드가 호출되면
self.token_embeddings는 단어 임베딩을,
self.position_embeddings는 단어의 위치 정보 임베딩을 수행한다.
최종적으로 각 임베딩의 출력값을 합친 값이 반환된다.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1] # 텍스트의 단어 수. 예를 들어 600.
positions=tf.range(start=0, limit=length, delta=1) # range(600)에 해당
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions # 단어 임베딩 + 위치 임베딩
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config
단어위치 인식 트랜스포머 인코더 활용
영화후기 분석등 이진분류 모델로 사용될 수 있는 모델을
PositionalEmbedding 층과 트랜스포머 인코더를 이용하여
구성하면 다음과 같다.
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
모델 컴파일과 훈련 진행은 별다른 점이 없다.
모델 컴파일
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
모델 훈련
callbacks = [
keras.callbacks.ModelCheckpoint("full_transformer_encoder",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
keras.models 모듈의 load_model() 함수를 이용하여
훈련과정 중에 저장된 최적의 모델을 불러올 때는
모델 구성에 사용된 층중에서 사용자가 직접 정의한 층의
클래스를 custom_objects 인자로 지정해야 함에 주의한다.
최고 성능 모델의 정확도
model = keras.models.load_model(
"full_transformer_encoder",
custom_objects={"TransformerEncoder": TransformerEncoder,
"PositionalEmbedding": PositionalEmbedding})
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
12.5. 시퀀스-투-시퀀스 학습#
기계 번역에 사용되는 시퀀스-투-시퀀스 모델은 하나의 텍스트가 들어오면 새로운 텍스트를 생성하는 모델이며, 자연어 처리의 다양한 분야에서 활용된다.
기계 번역
텍스트 내용 요약
질문 답변
챗봇 기능
텍스트 생성
12.5.1. 트랜스포머 모델#
기계 번역에 사용되는 트랜스포머 모델은 트랜스포머 인코더와 트랜스포머 디코더로 구성된 아래 구조의 아키첵처를 활용한다.
그림 왼쪽: 트랜스포머 인코더
그림 오른쪽: 트랜스포머 디코더

텍스트 데이터셋
예를 들어 영어 텍스트를 스페인어 텍스트로 기계 번역하는 트랜스포머 모델의 훈련에 사용되는 데이터셋은 영어 텍스트 데이터셋과 스페인어 텍스트 데이터셋으로 구성된 튜플을 사용한다. 아래 표는 각각 3 개의 영어 텍스트와 스페인어 텍스트로 구성된 데이터셋 예제이다.
영어 데이터셋 |
스페인어 데이터셋 |
|---|---|
How is the weather today? |
¿Qué tiempo hace hoy? |
You are welcome. |
De nada. |
It will be raining at this time tomorrow. |
Mañana a estas horas estará lloviendo. |
기계 번역 모델의 훈련에 사용되는 데이터셋은 Tab-delimited Bilingual Sentence Pairs에서 다운로드 받는다. 영어-스페인어 텍스트 데이터셋은 spa-eng.zip이다. 다른 언어 데이터셋도 제공된다. 예를 들어 kor-eng.zip은 영어-한국에 텍스트 데이터셋이다.
훈련셋
훈련은 하지만 텍스트의 길이를 일정 단어의 수로 제한한다.
아래 설명에서는 색인화된 텍스트의 길이를 5로 지정하였다.
또한 영어 텍스트와 스페인어 텍스트 모두
어휘 인덱스로 구성된 벡터로 텍스트 벡터화되었다고 가정한다.
단어수가 지정된 크기보다 적은 경우 0-패딩을 사용한다.
또한 스페인어 텍스트의 시작은 '[start]'로, 끝은 '[end]'로 지정하여
텍스트의 시작과 끝을 모델이 인지하도록 훈련시킨다.
단, 두 단어 포함 단어수가 지정된 크기보다 크면 '[end]'는 생략된다.
영어 훈련셋 |
스페인어 훈련셋 |
|---|---|
|
|
|
|
|
|
타깃셋
타깃셋은 스페인어 훈련셋으로부터 생성된다.
단어수는 동일하다.
하지만 [start]가 제거되고 대신 입력 텍스트를 계속 이어갈 단어 하나가 마지막 단어로 추가된다.
즉, 모델은 훈련을 통해 입력된 스페인어 텍스트를 어떤 단어로 이어갈 것인지를 학습한다.
스페인어 타깃셋 |
|---|
|
|
|
아래 그림은 영어와 스페인어 입력값이 사용되는 과정을 보여준다. 영어는 트랜스포머 인코더에 입력되고 그 출력값이 스페인어 입력값과 함께 트랜스포머 디코더에 입력된다. 모델의 최종 출력값은 트랜스포머 디코더가 생성한다.
트랜스포머 인코더
입력값: 영어 텍스트 배치 데이터셋
출력값: 셀프 어텐션을 이용하여 단어 임베딩된 배치 데이터셋
트랜스포머 디코더
입력값: 스페인어 텍스트 배치 데이터셋과 트랜스포머 인코더의 출력값
출력값: 두 입력값을 어텐션 층을 통과시켜 생성한 스페인어 텍스트 배치 데이터셋. query는 스페인어 입력값, key와 value는 트랜스포머 인코더의 영어 출력값.
트랜스포머 모델 활용
트랜스포머 모델은 실전에서는 입력된 영어 텍스트를 번역한 스페인어 텍스트를 생성하는 데에 활용된다. 앞서 설명한 훈련 과정에서와는 달리 입력값으로 영어 텍스트만 주어진 상황에서 스페인어 텍스트를 생성해야 한다. 즉, 모델의 둘째 입력값인 스페인어 텍스트가 없이 모델의 예측값을 생성해야 한다. 하지만 위 트랜스포머 모델은 두 종류의 입력값을 요구한다. 이에 대한 해결책은 다음과 같다.
아래 그림에서처럼
'[start]'단어 한 개로 구성된 스페인어 텍스트를 둘째 입력값으로 지정한다. 그러면 모델은 입력된 영어 텍스트를 참고하여 해당 텍스트를 스페인어로 번역한다. 이때 가장 마지막에 사용된 스페인어 단어가 입력 스페인어 텍스트를 연잘할 때 사용할 수 있는 단어다. 예를 들어, 아래 그림은"how is the weather today"텍스트를 번역할 때 스페인어 텍스트의 첫째 단어로'qué'를 추천한다.생성된 텍스트의 마지막 단어를 기존에 입력값으로 사용된 스페인어 텍스트 문장에 추가한 후에 새로운 스페인어 입력값으로 사용하여 트랜스포머 모델로 하여금 입력된 스페인어 문장을 이어갈 새로운 단어를 추천하도록 한다. 이 과정을
'[end]'단어가 추천될 때까지 반복한다.
정리하면 다음과 같다. 영어 텍스트가 입력되면 '[start]'로만 구성된 텍스트를
스페인어 입력 텍스르로 사용해서 '[end]'가 이전 스페인어 텍스트를 이어갈 단어로 추천될 때까지
트랜스포머 모델을 반복 활용하며, 이 과정을 통해 하나의 완성된 스펜인어 텍스트를 생성한다.
12.5.2. 트랜스포머 디코더#
트랜스포머 디코더를 하나의 층으로 구현하면 다음과 같다. 생성자의 인자는 다음과 같다.
embed_dim: 예를 들어embed_dim=256은 단어 임베딩(600, 256)모양의 샘플 생성dense_dim: 밀집층에서 사용되는 유닛unit 개수num_heads: 헤드head 개수
get_causal_attention_mask() 메서드는 스페인어 입력 텍스트에 대한 마스크를 지정할 때 활용되지만
여기서는 마스크를 사용하지 않는다.
순전파를 담당하는 call() 메서드는 두 개의 어텐션 층을 사용한다.
입력값으로는 스페인어 텍스트 배치 데이터셋과
트랜스포머 디코더의 출력값으로 셀프 어텐션이 적용되어 변환된 영어 텍스트 배치 데이터셋이 사용된다.
attention_1: 스페인어 텍스트 입력값에 대해 셀프 어텐션 적용attention_2:attention_1의 출력값을 query로, 트랜스포머 인코더의 출력값을 key와 value로 사용해서 어텐션 적용.
최종적으로 두 개의 밀집층을 통과시킨다. 또한 하나의 블록을 통과시킬 때마다 잔차연결과 층정규화를 진행한다.
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1),
tf.constant([1, 1], dtype=tf.int32)], axis=0)
return tf.tile(mask, mult)
def call(self, inputs, encoder_outputs, mask=None):
# 마스크 활용
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(
mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
# 셀프 어텐션 적용: 번역 언어(예를 들어 스페인어) 입력값 대상
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=causal_mask)
attention_output_1 = self.layernorm_1(inputs + attention_output_1)
# 셀프 어텐션이 적용된 (예를 들어 스페인어) 입력 텍스트를 query로
# 셀프 어텐션이 적용된 번역 대상 (예를 들어 영어) 입력 텍스트를 key와 value로
# 지정하여 어텐션 적용
attention_output_2 = self.attention_2(
query=attention_output_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
attention_output_2 = self.layernorm_2(
attention_output_1 + attention_output_2)
proj_output = self.dense_proj(attention_output_2)
return self.layernorm_3(attention_output_2 + proj_output)
12.5.3. 기계 번역 모델#
이미 설명한 대로 트랜스포머 인코더와 트랜스포머 디코더를 조합하여 기계 번역 트랜스포머 모델을 구성한다.
sequence_length = 20: 텍스트에 포함되는 단어수를 20으로 지정vocab_size = 15000: 어휘집 크기를 15,000으로 지정embed_dim = 256: 단어 임베딩 크기dense_dim = 2048: 밀집층에 사용되는 유닛 개수num_heads = 8: 어텐션 모델에 사용될 헤드 개수
모델의 입력값은 앞서 설명한 대로 예를 들어 일정 길이로 단어 벡터화된 영어 텍스트 데이터셋과
스페인어 텍스트 데이터셋의 튜플이다.
스페인어 텍스트는 모두 [start] 로 시작하도록 전처리되어 있다.
sequence_length = 20 # 텍스트의 단어수
vocab_size = 15000 # 어휘집 크기
embed_dim = 256 # 단어 임베딩 크기
dense_dim = 2048 # 밀집층 유닛수
num_heads = 8 # 어텐션 헤드수
# 트랜스포머 인코더 활용
# 첫째 입력값: 예를 들어 영어 텍스트셋
encoder_inputs = keras.Input(shape=(None,), dtype="int64", name="english")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(encoder_inputs)
encoder_outputs = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
# 트랜스포머 디코더 활용
# 둘째 입력값: 예를 들어 스페인어 텍스트셋
decoder_inputs = keras.Input(shape=(None,), dtype="int64", name="spanish")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(decoder_inputs)
x = TransformerDecoder(embed_dim, dense_dim, num_heads)(x, encoder_outputs)
x = layers.Dropout(0.5)(x)
decoder_outputs = layers.Dense(vocab_size, activation="softmax")(x)
transformer = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
모델의 출력값은 예를 들어 출력 스페인어 텍스트로 지정될 단어들에 대한 위치별 확률값을 계산한다. 아래 코드에서는 스페인어 텍스트에 포함될 20 개 단어들의 후보를 위치별로 확률값으로 계산한다. 예를 들어 출력 텍스트의 i-번 인덱스에 위치할 단어의 확률값을 계산하기 위해 어휘집에 포함된 15,000 개 단어를 대상으로 각각의 단어가 해당 위치에 자리할 확률을 소프트맥스 함수를 이용하여 계산한다.
예를 들어 크기가 64인 배치 입력에 대한 모델의 최종 출력값은 (64, 20, 15000) 모양의 텐서로 구성된다.
(20, 15000)은 아래와 같은 20개의 단어로 구성된 하나의 스페인어 텍스트에 해당하는 텐서이며,
텐서의 i-번째 행은 15,000개 단어 각각을 대상으로 출력 텍스트의 i-번째 단어로 사용될
(어휘)인덱스의 확률값으로 구성된 벡터이다.
tf.Tensor(
[[5.5714343e-05, 1.0322933e-04, ..., 6.9425951e-05], # 길이 15000, 열별 합: 1
[5.5894801e-05, 5.3953008e-05, ..., 6.7670873e-05],
[5.9929422e-05, 5.7787420e-05, ..., 5.9436632e-05],
...
[5.9041427e-05, 4.8372585e-05, ..., 6.5162356e-05]], # 총 20개 단어 대상
shape=(20, 15000), dtype=float32)
모델 훈련과 활용
모델 훈련은 특별할 게 없다.
다만 앞서 설명한대로 모델의 최종 출력값이 소프트맥스를 사용하여
(20, 15000) 모양을 갖는 반면에
타깃셋은 20 개의 어휘 인덱스로 구성된 벡터로 구성되기에
categorical_crossentropy 가 아닌 sparse_categorical_crossentropy를
손실함수로 지정한다.
그러면 20개 단어 각각에 대해 가장 높은 확률을 갖는 (어휘) 인덱스에 해당하는 단어가
15,000 개 중에 선택되어 타깃 단어와 비교된다.
transformer.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
아래 decode_sequence()는 함수는 영어 텍스트가 하나 입력되면
앞서 훈련된 트랜스포머 모델을 이용하여 지정된 길이인 20 개의 단어로
구성된 스페인어 텍스트를 생성한다.
함수 본문에 포함된 for 반복문은
트랜스포머 모델 활용 부분에서 설명한 방식 그대로
[start]로만 구성된 텍스트로 시작해서
계속해서 텍스트에 추가할 단어를 하나씩 선택해서 이어가는 과정을
[end] 키워드가 나올 때까지 반복한다.
단, 반복횟수는 20으로 제한한다.
import numpy as np
# 어휘집 확인
spa_vocab = target_vectorization.get_vocabulary()
# (단어 인덱스, 단어)로 구성된 사전 지정
spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab))
# 텍스트에 포함되는 단어수
max_decoded_sentence_length = 20
def decode_sequence(input_sentence):
tokenized_input_sentence = source_vectorization([input_sentence])
# 기계 번역 시작
decoded_sentence = "[start]"
for i in range(max_decoded_sentence_length):
# 트랜스포머 모델 적용
tokenized_target_sentence = target_vectorization(
[decoded_sentence])[:, :-1]
predictions = transformer(
[tokenized_input_sentence, tokenized_target_sentence])
# i-번째 단어로 사용될 어휘 인덱스 확인
sampled_token_index = np.argmax(predictions[0, i, :])
# i-번째 단어 확인
sampled_token = spa_index_lookup[sampled_token_index]
# 스페인어 입력 텍스트에 i-번째 단어로 추가
decoded_sentence += " " + sampled_token
# 기계 번역 종료 조건 확인
if sampled_token == "[end]":
break
return decoded_sentence
아래 코드는 decode_sequence() 함수를 이용하여
무작위로 5개의 영어 텍스트를 선택하여 기계 번역한 결과이다.
-
Tom isn't a good person.
[start] tom no es una persona [end]
-
Automobile sales suffered a setback at the end of the financial year.
[start] el examen de [UNK] a la luz al final de la año [end]
-
I don't need an explanation.
[start] no necesito una explicación [end]
-
Tom is going to college now.
[start] tom está a ir a la universidad ahora [end]
-
The dish is too sweet for Tom.
[start] la carta es demasiado bajo para tom [end]