넘파이numpy는 NUMerical PYthon의 줄임말이며, 파이썬 데이터 사이언스에서 가장 유용하게 활용되는 도구를 제공하는 라이브러리다. 넘파이가 제공하는 핵심 요소는 효율적으로 데이터를 저장하고 관리하는 1차원, 2차원, 3차원 등 다차원 어레이(배열)와 메모리 효율적이며 빠른 어레이 연산이다.
numpy 라이브러리는 관습적으로 별칭 np로 불러온다.
import numpy as np14.1다차원 어레이¶
넘파이 어레이는 리스트 자료형처럼 많은 데이터를 하나의 객체로 묶어 다루는 모음 자료형이며, 데이터 분석, 머신러닝, 딥러닝 등 다량의 데이터로 구성된 데이터셋을 처리할 때 일반적으로 활용된다. 아래 표에 리스트와 넘파이 어레이의 차이점을 정리하였다.
| 요소 | 리스트 | 넘파이 어레이 |
|---|---|---|
| 데이터 저장 | 데이터 모음 | 데이터 모음 |
| 객체 속성 | 항목 저장 이외에 기타 속성 없음. | 값과 함께 데이터 저장 형식의 모양, 차원, 항목 자료형 등 객체의 메타 데이터를 속성으로 저장 |
| 메서드 | 기본 메서드 제공 | 데이터 과학에 유용한 많은 메서드 제공 |
| 자료형 제약 | 서로 다른 자료형 혼용 가능 | 모든 항목이 동일한 자료형으로 통일되어야 함 |
| 차원 | 차원 개념 없지만 중첩 리스트 지원 | 1차원, 2차원, 3차원, 4차원 등 다차원 구조 지원 |
여기서는 가장 많이 활용되는 1차원과 2차원 어레이의 사용법을 소개한다.
14.1.11차원 어레이¶
1차원 어레이는 중첩이 없는 리스트와 동일한 모양을 가지며, 리스트에 np.array() 함수를 적용하여 생성할 수 있다.
1차원 어레이는 벡터vector로도 불린다.
list_1D = [1, 17, -7.5, 3.14, 2.71828]
arr_1D = np.array(list_1D)arr_1D는 list_1D 변수가 가리키는 리스트와 동일한 항목을 갖는 1차원 어레이를 가리킨다.
arr_1D항목 자료형
리스트의 경우 임의의 자료형이 섞인 항목들을 가질 수 있지만
어레이는 항목들의 통일된 자료형을 요구한다.
따라서 위 출력 결과를 보면 1과 17이 각각 1.과 17. 변환되어 모든 항목이 부동소수점으로 구성되었다.
1.과 17.은 각각 1.0과 17.0을 가리킨다.
어레이 항목들의 통일된 자료형은 어레이 객체의 dtype 속성으로 확인된다.
arr_1D.dtype축
1차원 어레이의 항목은 리스트처럼 왼쪽에서부터 오른쪽으로 하나의 방향으로만 이동하면서 확인할 수 있다. 이런 의미에서 1차원 어레이는 한 개의 축axis을 갖는다고 말한다.
인덱스
각 항목은 왼쪽에서부터 차례대로 0, 1, 2, ... 로 시작하는 인덱스를 갖는다.
예를 들어, arr_1D이 가리키는 1차원 어레이에 포함된 -7.5의 인덱스는 2다.
차원
어레이 자신의 차원은 ndim 속성에 할당되어 있다.
arr_1D.ndim모양
어레이는 자신의 모양을 shape 속성에 튜플 자료형으로 저장한다.
1차원 어레이의 모양은 길이가 1인 튜플이며, 튜플의 유일한 항목은 1차원 어레이에 포함된 항목의 개수다.
arr_1D가 가리키는 1차원 어레이는 5개의 항목을 포함하기에
모양은 (5,)이다.
arr_1D.shape어레이 객체 자료형
넘파이 어레이 객체의 자료형은 항목 자료형, 차원, 모양과 상관없이 항상 numpy.ndarray다.
자료형은 type() 함수를 이용하여 확인한다.
type(arr_1D)14.1.2np.arange() 함수¶
np.arange() 함수는 range() 함수와 매우 유사한 기능을 갖지만, 리스트가 아닌 넘파이 어레이를 반환한다.
예를 들어, 아래 코드는 0부터 9 사이의 정수로 구성된 1차원 어레이를 생성한다.
np.arange(10)range() 함수와는 다르게 부동소수점을 스텝으로 사용할 수도 있으며,
그러면 부동소수점으로 구성된 1차원 어레이가 생성된다.
예를 들어, 아래 코드는 0부터 시작해서 스텝 0.1씩 증가시키면서 생성되는 값들로 구성된 1차원 어레이를 생성한다.
단, 오른쪽 끝값인 1 이전까지 스텝을 반복 적용한다.
np.arange(0, 1, 0.1)14.1.32차원 어레이¶
2차원 어레이의 모든 항목은 동일한 모양의 1차원 어레이어야 한다.
따라서 동일한 길이의 리스트를 항목으로 갖는 중첩 리스트를 2차원 어레이로 변환할 수 있다.
아래 코드는 길이가 4인 세 개의 리스트를 항목으로 갖는 중첩 리스트 list_2D를 2차원 어레이 arr_2D로 변환한다.
list_2D = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]
arr_2D = np.array(list_2D)
arr_2D축과 행렬
2차원 어레이는 행row과 열column
두 개의 축을 가지며, 행은 0번 축, 열은 1번 축이라 부르기도 한다.
행과 열을 갖는다는 의미에서 행렬matrix로 불린다.
예를 들어, arr_2D는 3개의 행과 4개의 열을 갖는 아래 모양의 행렬에 대응한다.
행과 열 인덱스
인덱스는 축별로 지정된다. 위 2차원 어레이의 경우 3개의 행에 대해 맨 위 행부터 차례대로 0, 1, 2 행 인덱스가, 4개의 열에 대해 맨 왼쪽 열부터 차례대로 0, 1, 2, 3 열 인덱스가 지정된다. 2차원 어레이에 포함된 모든 항목의 위치는 행과 열 인덱스를 조합해서 지정된다. 예를 들어, 정수 7의 위치는 1번 행 인덱스와 2번 열 인덱스로 특정된다.
차원
차원은 축의 개수로 지정되며, 따라서 arr_2D는 행과 열 두 개의 축을 갖는 2차원 어레이다.
arr_2D.ndim모양
2차원 어레이의 모양은 행과 열의 개수를 항목으로 갖는, 길이가 2인 튜플이다.
arr_2D는 3개의 행과 4개의 열을 갖기에 (3, 4) 모양의 어레이다.
arr_2D.shape어레이 객체 자료형
2차원 어레이의 자료형도 항목 자료형, 모양과 무관하게 numpy.ndarray다.
type(arr_2D)14.1.4어레이 변형¶
주어진 어레이의 항목을 그대로 유지하면서 모양만 변형시키는 가장 기초적인 방식과 활용법을 소개한다.
reshape() 메서드
reshape() 메서드를 활용하여 주어진 어레이의 모양을 원하는 대로 변형한다.
단, 항목의 수가 변하지 않도록 모양을 지정해야 한다.
예를 들어, 길이가 8인 1차원 어레이가 다음과 같다.
arr_1D_8 = np.arange(8)
arr_1D_8array([0, 1, 2, 3, 4, 5, 6, 7])이제 (4, 2) 모양의 2차원 어레이로 모양을 변형할 수 있다.
arr_1D_8.reshape((4, 2))array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])항목의 개수만 어떤 모양으로의 변형도 가능하다.
arr_1D_8.reshape((2, 4))array([[0, 1, 2, 3],
[4, 5, 6, 7]])arr_1D_8.reshape((1, 8))array([[0, 1, 2, 3, 4, 5, 6, 7]])arr_1D_8.reshape((8, 1))array([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7]])-1의 역할
어레이의 모양을 지정할 때 튜플의 특정 위치에 -1을 사용할 수 있다. 그러면 그 위치의 값은 튜플의 다른 항목의 정보를 이용하여 자동 결정된다. 예를 들어, 아래 코드에서 -1은 4를 의미한다. 이유는 20개의 항목을 5개의 행으로 이루어진 2차원 어레이로 지정하려면 열은 4개 있어야 하기 때문이다.
arr_1D_20 = np.arange(20)
arr_1D_20.reshape((5, -1))array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])동일한 이유로 아래에서 -1은 5를 의미한다.
arr_1D_20.reshape((-1, 4))array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])14.1.5연습문제¶
문제 1
다음 조건을 만족하는 1차원 어레이를 생성하고, 해당 어레이의 항목 자료형(dtype), 차원(ndim), 모양(shape)을 출력하는 코드를 작성하라.
2.5부터 시작하여 0.5씩 증가하는 값으로 구성된 어레이 (단, 5.0 이전까지)
답:
import numpy as np
# 어레이 생성
arr_ex1 = np.arange(2.5, 5.0, 0.5)
# 속성 출력
print("어레이:", arr_ex1)
print("항목 자료형(dtype):", arr_ex1.dtype)
print("차원(ndim):", arr_ex1.ndim)
print("모양(shape):", arr_ex1.shape)문제 2
아래의 학생별 과목 점수 데이터를 2차원 어레이로 생성하고, 어레이의 모양(shape)과 차원(ndim)을 출력하는 코드를 작성하라.
학생 A: [85, 92, 78]
학생 B: [90, 88, 95]
학생 C: [76, 85, 80]
학생 D: [88, 90, 92]
답:
import numpy as np
# 중첩 리스트를 이용한 2차원 어레이 생성
scores = [[85, 92, 78],
[90, 88, 95],
[76, 85, 80],
[88, 90, 92]]
arr_scores = np.array(scores)
# 속성 출력
print("어레이:\n", arr_scores)
print()
print("모양(shape):", arr_scores.shape)
print("차원(ndim):", arr_scores.ndim)문제 3
다음 리스트 mixed_list를 넘파이 어레이로 변환하는 코드를 작성하라.
또한 변환된 어레이를 출력하고, 어레이의 항목 자료형(dtype)이 어떻게 결정되었는지 그 이유를 설명하라.
mixed_list = [10, 20, 3.14, 40]답:
import numpy as np
mixed_list = [10, 20, 3.14, 40]
arr_mixed = np.array(mixed_list)
print("변환된 어레이:", arr_mixed)
print("항목 자료형(dtype):", arr_mixed.dtype)설명:
리스트는 서로 다른 자료형(정수와 부동소수점)을 함께 가질 수 있지만, 넘파이 어레이는 모든 항목이 동일한 자료형으로 통일되어야 한다.
mixed_list에는 부동소수점(3.14)이 포함되어 있으므로, 데이터의 손실을 막기 위해 정수 항목들(10, 20, 40)이 모두 부동소수점(10., 20., 40.)으로 자동 변환된다.
따라서 어레이의 dtype은 float64로 결정된다.
문제 4
다음 조건을 만족하는 코드를 작성하라.
np.arange(1, 13)을 이용해 1차원 어레이arr_1D_12를 생성하라.arr_1D_12를(3, 4)모양의 2차원 어레이로 변형하여arr_2D_a에 저장하라.같은 어레이를
(-1, 2)모양으로 변형하여arr_2D_b에 저장하라.arr_2D_a와arr_2D_b의shape,ndim,size를 각각 출력하라.변형 전후
size가 동일한지 확인하는 코드를 작성하라.
답:
import numpy as np
# 1차원 어레이 생성
arr_1D_12 = np.arange(1, 13)
# reshape 적용
arr_2D_a = arr_1D_12.reshape((3, 4))
arr_2D_b = arr_1D_12.reshape((-1, 2))
print("arr_1D_12:", arr_1D_12)
print("arr_2D_a:\n", arr_2D_a)
print("arr_2D_b:\n", arr_2D_b)
print("\narr_2D_a -> shape:", arr_2D_a.shape, ", ndim:", arr_2D_a.ndim, ", size:", arr_2D_a.size)
print("arr_2D_b -> shape:", arr_2D_b.shape, ", ndim:", arr_2D_b.ndim, ", size:", arr_2D_b.size)
print("\nsize 동일 여부:")
print("arr_1D_12.size == arr_2D_a.size ?", arr_1D_12.size == arr_2D_a.size)
print("arr_1D_12.size == arr_2D_b.size ?", arr_1D_12.size == arr_2D_b.size)arr_1D_12: [ 1 2 3 4 5 6 7 8 9 10 11 12]
arr_2D_a:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
arr_2D_b:
[[ 1 2]
[ 3 4]
[ 5 6]
[ 7 8]
[ 9 10]
[11 12]]
arr_2D_a -> shape: (3, 4) , ndim: 2 , size: 12
arr_2D_b -> shape: (6, 2) , ndim: 2 , size: 12
size 동일 여부:
arr_1D_12.size == arr_2D_a.size ? True
arr_1D_12.size == arr_2D_b.size ? True
설명:
reshape()는 어레이의 항목 순서와 개수는 유지한 채 모양(shape)만 바꾼다.
따라서 변형 전후 size는 항상 동일해야 한다.
(-1, 2)에서 -1은 자동 계산을 의미한다.
전체 항목 수가 12개이고 열 수를 2로 지정했으므로 행 수는 자동으로 6이 되어
arr_2D_b의 모양은 (6, 2)가 된다.
14.2주요 항목 자료형¶
데이터 분석, 머신러닝, 딥러닝 등에서 사용되는 넘파이 어레이는 거의 대부분 부동소수점, 정수, 그리고 문자열로 구성된다.
14.2.1부동소수점 자료형¶
부동소수점으로 구성된 arr_1D의 dtype은 부동소수점 자료형인 float64다.
print('arr_1D:', arr_1D)
print("arr_1D dtype:", arr_1D.dtype)float64에서 64는 넘파이 어레이가 각각의 부동소수점을 저장하기 위해 64비트 크기의 메모리 공간을 할당한다는 의미다.
아래 코드는 arr_1D가 가리키는 어레이가 메모리상에서 총 40바이트를 사용함을 확인해준다.
print("항목 자료형:", arr_1D.dtype)
print("어레이 크기 (바이트):", arr_1D.nbytes)참고로 1바이트는 8비트에 해당한다.
arr_1D가 가리키는 어레이는 총 5개의 부동소수점이 포함되고 하나의 부동소수점이 8바이트 공간을 사용하기에,
총 5 * 8 = 40 바이트를 어레이가 차지한다.
어레이의 항목 하나가 차지하는 메모리 크기는 itemsize 속성에,
어레이에 포함된 항목의 개수는 size 속성에 저장되어 nbytes를 다음처럼 계산할 수도 있다.
print("항목 크기 (바이트):", arr_1D.itemsize)
print("항목 수:", arr_1D.size)
print("전체 크기 (바이트):", arr_1D.itemsize * arr_1D.size)머신러닝, 특히 딥러닝에서 다루는 빅데이터는 항목의 개수가 경우에 따라 수억개 이상인 경우도 있어서
그런 경우엔 메모리 사용량을 줄이기 위해 64비트 형식의 부동소수점 대신에 32비트, 16비트 형식을 사용하기도 한다.
아래 코드는 arr_1D를 생성할 때 dtype을 지정하는 방식으로 16비트 형식의 부동소수점을 사용하도록 강제한다.
arr_1D_16 = np.array(list_1D, dtype='float16')
arr_1D_16.dtype기존에 생성된 어레이의 dtype을 astype() 메서드를 이용하여 변경할 수도 있다.
예를 들어, 아래 코드는 64비트가 아닌 16비트 형식의 부동소수점을 사용하도록 강제한다.
arr_1D_16 = arr_1D.astype('float16')항목에 포함된 부동소수점이 2바이트만으로는 제대로 다뤄지지 않은 경우에는
소수점 이하 특정 자리에서 잘릴 수도 있다.
예를 들어, 5번째 항목이 2.71828에서 2.719로 소수점 이하 넷째 자리에서 반올림된 형식으로 지정된다.
arr_1D_16항목 자료형인 dtype은 지정한대로 float16으로 확인된다.
arr_1D_16.dtype각 항목이 차지하는 메모리 공간이 4분의 1로 줄었기에 어레이가 차지하는 메모리 공간 또한 4분의 1로 줄어든 10바이트다.
print("항목 크기 (바이트):", arr_1D_16.itemsize)
print("항목 수:", arr_1D_16.size)
print("전체 크기 (바이트):", arr_1D_16.itemsize * arr_1D_16.size)14.2.2정수 자료형¶
정수로 구성된 arr_2D의 dtype은 정수 자료형인 int64다.
arr_2Dprint('arr_2D dtype:', arr_2D.dtype)int64에서 64는 넘파이 어레이가 각각의 정수를 64비트 크기의 공간을 기본 크기로 사용한다는 의미다.
아래 코드는 arr_2D가 가리키는 어레이가 메모리상에서 총 96바이트를 사용함을 확인해준다.
arr_2D = np.array(list_2D)
print("항목 자료형:", arr_2D.dtype)
print("어레이 크기 (바이트):", arr_2D.nbytes)arr_2D가 가리키는 어레이는 총 12개의 정수가 포함되고 하나의 정수가 8바이트 공간을 차지하게
총 12 * 8 = 96 바이트를 어레이가 차지한다.
arr_2D.itemsize * arr_2D.size빅데이터를 다룰 때 메모리 사용량을 줄이기 위해 64비트 형식의 정수 대신 32비트, 16비트, 심지어 8비트 형식의 정수를 사용하기도 한다. 아래 코드는 64비트가 아닌 8비트 형식의 정수를 사용하도록 강제한다.
arr_2D_8 = np.array(list_2D, dtype='int8')또는 기존에 생성된 어레이를 astype() 메서드를 이용하여 dtype을 변경할 수도 있다.
arr_2D_8 = arr_2D.astype('int8')항목에 포함된 정수가 최대 12이기에 1바이트만 사용해도 필요한 정수를 다루는 데에 충분하다. 실제로 어레이를 확인해도 겉모습은 동일하다.
arr_2D_8다만, dtype이 달라졌을 뿐이다.
arr_2D_8.dtype각 항목이 차지하는 메모리 공간이 8분의 1로 줄었기에 어레이가 차지하는 메모리 공간 또한 8분의 1로 줄어든 12바이트다.
print("항목 크기 (바이트):", arr_2D_8.itemsize)
print("항목 수:", arr_2D_8.size)
print("전체 크기 (바이트):", arr_2D_8.itemsize * arr_2D_8.size)14.2.3문자열 자료형¶
문자열은 기본적으로 유니코드로 처리되며, 크기는 최장 길이의 문자열 항목에 맞춰 결정된다.
예를 들어 아래 코드는 어레이에 포함된 가장 긴 문자열 'python' 의 길이가 6이기에
<U6가 자료형으로 지정됨을 보여준다.
즉, 어레이에 포함된 모든 문자열의 최대 길이가 6이라는 의미다.
arr_string = np.array(['python', 'data', 'numpy'])
arr_string.dtype어레이를 생성할 때 dtype='str'을 지정하면 모든 항목을 문자열로 변환한다.
예를 들어, 아래 코드는 정수와 부동소수점으로 구성된 리스트의 항목을 모두 문자열로 변환하여
어레이를 생성한다.
numeric_1D_strings = np.array(list_1D, dtype='str')
numeric_1D_strings아래 어레이의 자료형은 <U7인데, 문자열 '2.71828' 길이가 7로 가장 크기 때문이다.
반면에 아래 코드는 list_2D에 포함된 모든 정수를 문자열로 변환하여 2차원 어레이를 생성하며,
dtype은 최대 2개의 기호를 사용하는 문자열로 구성되었기에 '<U2'로 지정된다.
numeric_2D_strings = np.array(list_2D, dtype='str')
numeric_2D_strings14.2.4부울 자료형¶
참(True)과 거짓(False) 두 가지 값만 갖는 부울boolean 자료형으로 구성된 어레이의 dtype은 bool이다.
이처럼 항목 자료형이 bool인 어레이를 부울 어레이Boolean array라 부른다.
예를 들어, 아래 코드는 부울 값으로 구성된 리스트를 부울 어레이로 변환한다.
arr_bool = np.array([True, False, True, True])
arr_bool부울 어레이의 항목 자료형은 bool로 확인된다.
arr_bool.dtype부울 값은 내부적으로 1바이트(8비트)의 메모리 공간을 사용한다. 아래 코드는 4개의 부울 항목을 갖는 어레이가 총 4바이트를 차지함을 보여준다.
print("항목 크기 (바이트):", arr_bool.itemsize)
print("항목 수:", arr_bool.size)
print("전체 크기 (바이트):", arr_bool.nbytes)기존의 숫자형 어레이를 astype('bool')을 이용하여 부울값으로만 구성된 어레이로 변환할 수도 있다.
이때 0과 0.0은 False로, 그 외의 모든 0이 아닌 숫자는 True로 변환된다.
arr_num = np.array([0, 1, -2.5, 0.0, 3])
arr_num_bool = arr_num.astype('bool')
arr_num_bool14.2.5object 자료형¶
파이썬의 모든 자료형은 object 클래스를 상속한다.
즉, 임의의 값의 자료형은 항상 object 자료형이 된다.
따라서 넘파이 어레이를 정의할 때 dtype=object를 사용하면
각 항목의 자료형을 그대로 보존하면서 어레이를 생성할 수 있다.
array_of_object = np.array([1, 'two', 3.0], dtype=object)
array_of_objectobject를 항목 자료형으로 지정하면 여러 자료형을 그대로 유지하면서 하나의 어레이로 다룰 수 있다는 점에서 매우 유용하다.
하지만 int64, float64, str 등 특정 자료형으로 지정한
경우에 비해 메모리 효율이 낮고 처리 속도가 느려진다는 점은 기억해 두어야 한다.
14.2.6연습문제¶
문제 1
다음 1차원 정수 어레이 arr_int의 기본 항목 자료형(dtype)과 전체 메모리 크기(바이트)를 확인하라.
그 후, 이 어레이의 자료형을 16비트 정수형(int16)으로 변경한 새로운 어레이를 생성하고, 변경된 어레이의 전체 메모리 크기가 어떻게 달라졌는지 출력하라.
import numpy as np
arr_int = np.array([10, 20, 30, 40, 50])답:
import numpy as np
arr_int = np.array([10, 20, 30, 40, 50])
print("기본 자료형:", arr_int.dtype)
print("기본 어레이 전체 크기(바이트):", arr_int.nbytes)
print("\n-- 자료형 변경 --\n")
print("int16으로 자료형 변경")
arr_int16 = arr_int.astype('int16')
print("변경된 자료형:", arr_int16.dtype)
print("변경된 어레이 전체 크기(바이트):", arr_int16.nbytes)설명:
기본적으로 정수 어레이는 int64(항목당 8바이트)로 생성되므로 전체 크기는 40바이트다.
이를 int16(항목당 2바이트)으로 변경하면 전체 크기가 10바이트로 줄어들어 메모리 사용량을 크게 절약할 수 있다.
문제 2
다음 리스트를 이용하여 넘파이 어레이를 생성하라.
생성된 어레이의 항목 자료형(dtype)을 확인하고, 해당 dtype이 의미하는 바를 설명하라.
words = ['apple', 'banana', 'strawberry', 'kiwi']답:
import numpy as np
words = ['apple', 'banana', 'strawberry', 'kiwi']
arr_words = np.array(words)
print("어레이:", arr_words)
print("항목 자료형(dtype):", arr_words.dtype)설명:
출력되는 dtype은 <U10이다.
이는 어레이 항목들이 유니코드 문자열로 처리되며,
포함된 문자열 중 가장 긴 단어인 'strawberry'의 길이(10글자)에 맞춰 최대 길이가 10인 문자열 자료형으로 자동 지정되었음을 의미한다.
문제 3
다음 정수 어레이 arr_scores를 부울(bool) 자료형으로 변환한 새로운 어레이를 생성하라.
변환된 어레이를 출력하고, 변환 전과 후의 어레이 전체 메모리 크기(바이트)가 어떻게 달라졌는지 비교하여 설명하라.
import numpy as np
arr_scores = np.array([0, 85, 0, 92, -5])답:
import numpy as np
arr_scores = np.array([0, 85, 0, 92, -5])
print("기본 어레이 전체 크기(바이트):", arr_scores.nbytes)
# bool 자료형으로 변환
arr_bool = arr_scores.astype('bool')
print("변환된 부울 어레이:", arr_bool)
print("변경된 어레이 전체 크기(바이트):", arr_bool.nbytes)설명:
정수 어레이를 부울(bool) 자료형으로 변환하면 0은 False로, 0이 아닌 모든 숫자(85, 92, -5)는 True로 변환된다.
메모리 측면에서 기본 정수 어레이(int64)는 항목당 8바이트를 차지하여 총 40바이트(5개 항목)를 사용하지만,
부울 어레이는 항목당 1바이트만 차지하므로 전체 크기가 5바이트로 크게 줄어든다.
문제 4
정수, 부동소수점, 문자열이 섞여 있는 아래 리스트를 넘파이 어레이로 변환하려 한다.
각 항목의 원래 자료형을 그대로 유지하면서 어레이를 생성하는 코드를 작성하고, 생성된 어레이의 항목 자료형(dtype)을 확인하라.
mixed_data = [100, 3.14, 'Python']답:
import numpy as np
mixed_data = [100, 3.14, 'Python']
print("원래 자료형을 유지하기 위해 dtype=object 지정")
arr_obj = np.array(mixed_data, dtype=object)
print("어레이:", arr_obj)
print("항목 자료형(dtype):", arr_obj.dtype)
print("\n각 항목의 실제 파이썬 자료형 확인")
for item in arr_obj:
print(f"값: {item}, 자료형: {type(item)}")설명:
일반적으로 서로 다른 자료형이 섞인 리스트를 어레이로 변환하면 문자열 등 하나의 자료형으로 강제 통일된다.
하지만 dtype=object를 지정하면 파이썬의 기본 객체 형태를 유지하므로, 정수(int), 부동소수점(float), 문자열(str) 고유의 자료형을 잃지 않고 하나의 어레이에 담을 수 있다.
단, 메모리 효율과 연산 속도는 일반적인 넘파이 어레이보다 떨어진다.
14.3기초 통계 메서드¶
넘파이 어레이는 매우 다양한 메서드를 제공하지만, 여기서는 그중에서도 데이터 과학에 유용하게 활용되는 기초 통계 관련 메서드 몇 개만 다룬다.
14.3.1합, 평균, 표준편차¶
넘파이 어레이에 사용된 항목들의 합, 평균값, 표준편차 등 기본 통계를 계산하는 어레이 메서드가 지원된다.
활용법을 보여주기 위해 아래 (2, 3) 모양의 어레이를 활용한다.
arr = np.arange(1, 7).reshape(2, 3)
arrarray([[1, 2, 3],
[4, 5, 6]])sum() 메서드
어레이에 포함된 모든 값들의 합을 계산한다.
arr.sum()np.int64(21)mean() 메서드
어레이에 포함된 모든 값들의 평균값을 계산한다.
arr.mean()np.float64(3.5)std() 메서드
어레이에 포함된 모든 값들의 표준편차 계산한다.
arr.std()np.float64(1.707825127659933)14.3.2축 활용¶
앞서 언급된 모든 메서드는 축axis을 이용하는 옵션도 지원한다.
축 지정은 axis 매개변수의 키워드 인자를 활용한다.
axis=0: 열별로 메서드 적용. 1차원 어레이 반환.axis=1: 행별로 메서드 적용. 1차원 어레이 반환.
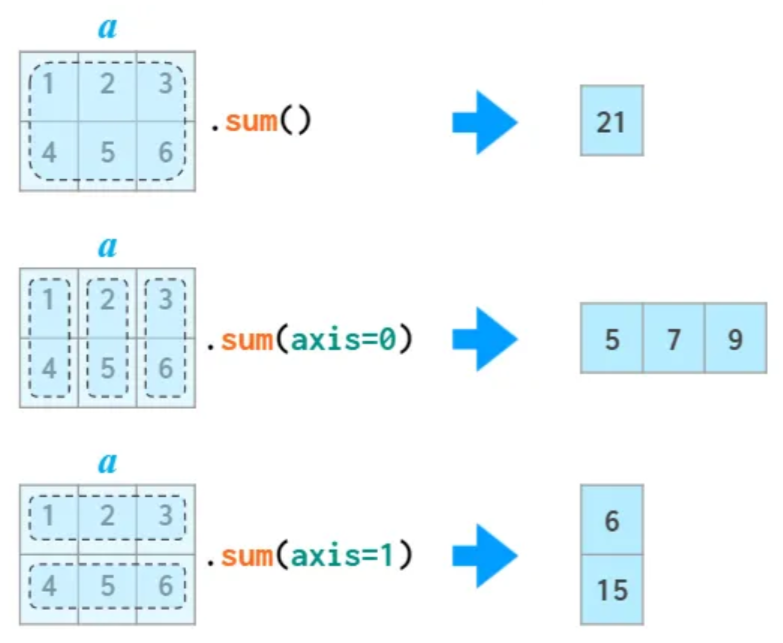
열별 합
arr.sum(axis=0)array([5, 7, 9])행별 합
arr.sum(axis=1)array([ 6, 15])열별 평균값
arr.mean(axis=0)array([2.5, 3.5, 4.5])행별 평균값
arr.mean(axis=1)array([2., 5.])열별 표준편차
arr.std(axis=0)array([1.5, 1.5, 1.5])행별 표준편차
arr.std(axis=1)array([0.81649658, 0.81649658])14.3.3min() vs. argmin()¶
설명을 위해 아래 어레이를 이용한다.
arr= np.array([[4, 8, 5], [9, 3, 1]])
arrarray([[4, 8, 5],
[9, 3, 1]])min() 메서드
어레이에 포함된 항목 중에서 최솟값을 반환한다. 축을 활용하면 열별, 행별 최솟값을 포함한 1차원 어레이가 반환된다.
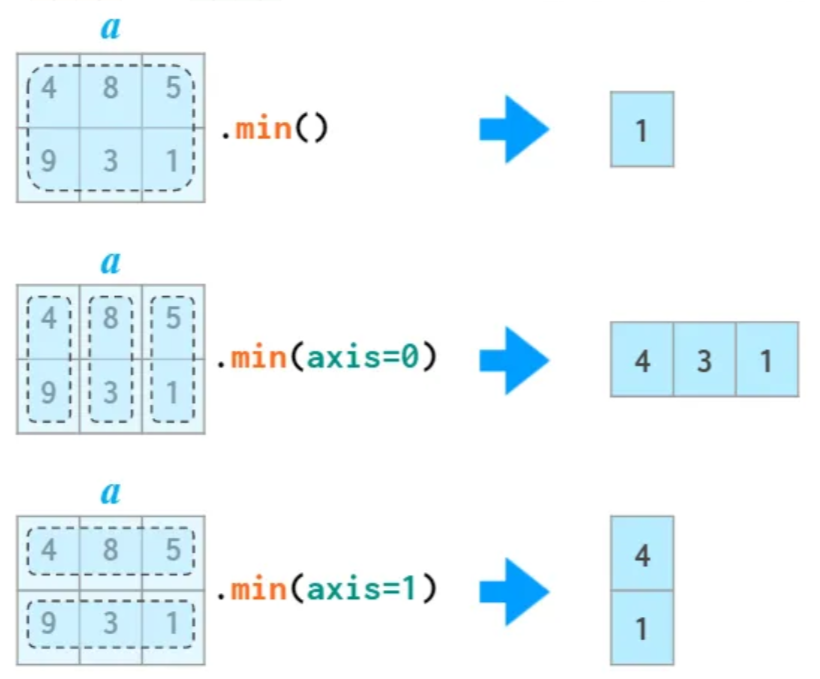
arr.min()np.int64(1)arr.min(axis=0)array([4, 3, 1])arr.min(axis=1)array([4, 1])max() 메서드
어레이에 포함된 항목 중에서 최댓값을 반환한다. 축을 활용하면 열별, 행별 최댓값을 포함한 1차원 어레이가 반환된다.
arr.max()np.int64(9)arr.max(axis=0)array([9, 8, 5])arr.max(axis=1)array([8, 9])argmin() 메서드
어레이에 포함된 항목 중에서 최솟값이 위치한 곳의 인덱스를 반환한다. 반환값은 정수 인덱스이며, 상단 왼편부터 0, 1, 2, 등으로 인덱스를 정한다. 축을 활용하면 열별, 행별 최솟값이 위치한 곳의 인덱스로 구성된 1차원 어레이가 반환된다.
arr.argmin()np.int64(5)arr.argmin(axis=0)array([0, 1, 1])arr.argmin(axis=1)array([0, 2])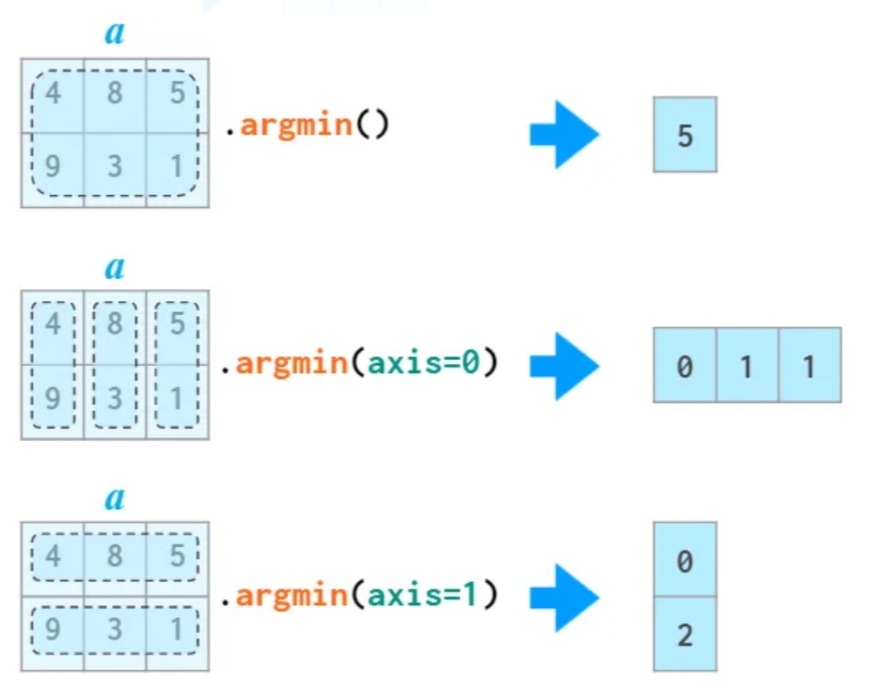
argmax() 메서드
어레이에 포함된 항목 중에서 최댓값이 위치한 곳의 인덱스를 반환한다. 반환값은 정수 인덱스이며, 상단 왼편부터 0, 1, 2, 등으로 인덱스를 정한다. 축을 활용하면 열별, 행별 최댓값이 위치한 곳의 인덱스로 구성된 1차원 어레이가 반환된다.
arr.argmax()np.int64(3)arr.argmax(axis=0)array([1, 0, 0])arr.argmax(axis=1)array([1, 0])14.3.4연습문제¶
문제 1
eng_scores 변수는 앞선 10명 학생의 영어 점수를 포함한 1차원 어레이를 가리킨다.
eng_scores = np.array([69, 71, 56, 76, 74, 69, 80, 68, 67, 66])이 10명의 영어 점수 중에서 최고점(최댓값)과 최저점(최솟값)을 각각 구하는 코드를 작성하라.
답:
어레이에 포함된 값 전체를 대상으로 가장 큰 값과 가장 작은 값은
각각 max()와 min() 메서드가 계산한다.
max_eng = eng_scores.max()
min_eng = eng_scores.min()
print("영어 점수 최대값:", max_eng)
print("영어 점수 최소값:", min_eng)영어 점수 최대값: 80
영어 점수 최소값: 56
문제 2
math_scores 변수는 어느 학교 학생 10명의 수학 점수를 담은 1차원 어레이를 가리킨다.
math_scores = np.array([58, 67, 46, 60, 67, 59, 72, 57, 58, 45])이 10명 학생의 전체 수학 점수 총합과 평균 점수를 구하는 코드를 작성하라.
답:
1차원 어레이 객체에 대해 sum()과 mean() 메서드를 적용하면 저장된 모든 값들의 합계와 평균을 간단하게 계산할 수 있다.
math_sum = math_scores.sum()
math_mean = math_scores.mean()
print("수학 점수 총합:", math_sum)
print("수학 점수 평균:", math_mean)수학 점수 총합: 589
수학 점수 평균: 58.9
문제 3
앞서 사용한 영어 점수와 수학 점수 데이터를 합쳐서 아래와 같이 2차원 어레이 scores를 만들었다.
0번 인덱스 열과 1번 인덱스 열은 각각 영어 점수와 수학 점수를 담고 있다.
scores = np.array([[69, 58],
[71, 67],
[56, 46],
[76, 60],
[74, 67],
[69, 59],
[80, 72],
[68, 57],
[67, 58],
[66, 45]])scores 어레이를 활용하여 이 10명 학생의 영어와 수학의 최고와 최저 점수를 구하는 코드를 작성하라.
답:
min() 또는 max() 메서드에 axis=0을 지정하면
열별 최솟값 또는 최댓값으로 구성된 1차원 어레이를 반환한다.
subject_max = scores.max(axis=0)
subject_min = scores.min(axis=0)
print('과목별 최고 점수 (영어, 수학):', subject_max)
print('과목별 최저 점수 (영어, 수학):', subject_min)과목별 최고 점수 (영어, 수학): [80 72]
과목별 최저 점수 (영어, 수학): [56 45]
문제 4
영어와 수학 점수가 가장 낮은 학생은 각각 몇 번째 위치(인덱스)에 있는지 확인하는 코드를 작성하라. 단, 동일한 최저 점수가 여러 명일 경우 첫 번째 위치를 반환한다.
답:
argmin(axis=0) 메서드를 사용하면 열별 최솟값이
위치한 곳의 인덱스로 구성된 1차원 어레이가 반환된다.
가장 작은 값이 여러 개 존재할 때는 맨 먼저 찾은 인덱스가
사용된다.
min_idx = scores.argmin(axis=0)
print('과목별 최저 점수를 가진 학생의 인덱스 (영어, 수학):', min_idx)과목별 최저 점수를 가진 학생의 인덱스 (영어, 수학): [2 9]
영어는 2번 인덱스 학생이, 수학은 9번 인덱스 학생이 최저점을 받았다.
14.4실전 예제: 붓꽃 데이터셋¶
붓꽃Iris 데이터셋은 1936년 통계학자 로날드 피셔Ronald Fisher에 의해 발표된 고전 데이터셋이다. 자동분류 문제를 연구하기 위해 수집되었으며, 세토사Setosa, 버시컬러Versicolor, 버지니카Verginica 등 붓꽃의 세 가지 품종에 대해 꽃잎 길이와 너비, 꽃받침 길이와 너비 정보를 포함한 150개의 샘플로 구성되어 있다.
이 데이터셋은 데이터 분석과 기계학습 분야에서 가장 널리 사용되는 예제 데이터셋이다.
14.4.1데이터 저장소¶
데이터 저장소는 데이터 분석과 머신러닝 학습을 위해 수집하고 정리한 데이터셋들을 보관하는 공간이다. 본 강의노트는 아래 저장소에서 실전 데이터셋을 다운로드하여 데이터 과학의 기초 개념을 소개하는 예제 위주로 구성된다.
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'14.4.2CSV 파일¶
CSV 파일은 Comma-Separated Values의 약자로, 데이터를 쉼표로 구분하여 저장하는 단순한 텍스트 형식의 파일이며 확장자는 .csv이다. 각 행은 줄바꿈으로 구분되고, 행 안의 데이터는 쉼표로 나뉘어 엑셀과 같은 표 형태로 표현된다. 따라서 모든 행은 동일한 개수의 쉼표를 가지며, 행별 데이터 수가 일정하고, 행별로 동일한 열에 위치한 값들은 동일한 특성을 공유한다.
CSV는 주로 간단한 표 데이터를 저장하고 공유하는 데 적합한 파일 형식이다. 구조가 단순하고 호환성이 뛰어나기 때문에 엑셀과 파이썬을 비롯한 다양한 편집기와 프로그래밍 언어에서 CSV 파일을 다루는 기능을 너비넓게 제공한다.
iris.csv 파일
iris.csv 파일에 붓꽃 데이터 150개가 아래 형식으로 저장되어 있다.
각 샘플은 꽃받침 길이와 너비, 꽃잎 길이와 너비 등 4개의 수치형 특성과 해당 샘플의 품종을 나타내는 문자열을 포함하고 있다.
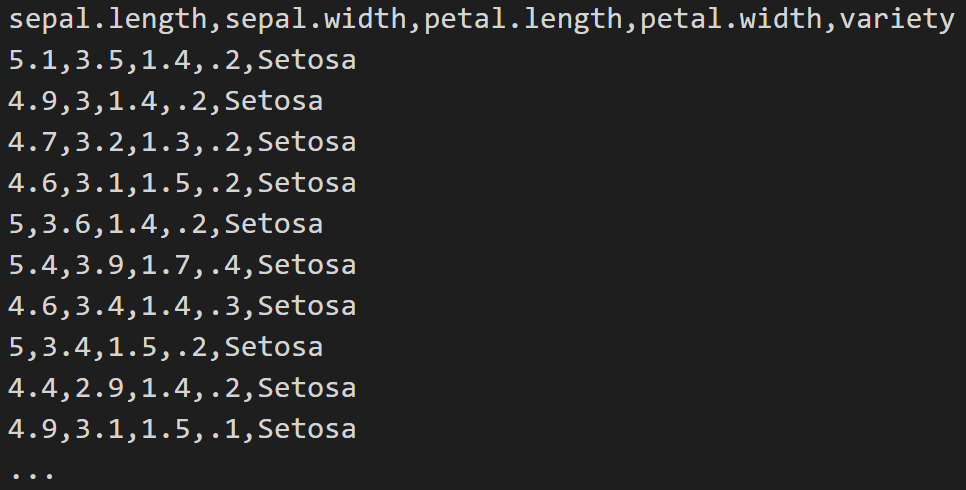
헤더
파일 첫행의 sepal.length,sepal.width,petal.length,petal.width,variety은 각각의 열에 포함된 데이터의 종류를 알려주는 헤더header다.
헤더는 열별 데이터를 대변하는 이름들의 목록을 보여준다.
열별 이름을 통계학 분야에서는 변수 또는 변인을,
데이터 분석과 머신러닝 분야에서는 특성feature이라 부른다.
붓꽃 데이터셋에 포함된 5개 특성은 다음과 같다.
| 영어 특성명 | 한글 특성명 |
|---|---|
| sepal.length | 꽃받침 길이 |
| sepal.width | 꽃받침 너비 |
| petal.length | 꽃잎 길이 |
| petal.width | 꽃잎 너비 |
| variety | 품종 |

14.4.31차원 어레이로 불러오기¶
np.loadtxt() 함수는 지정된 데이터 저장소나 폴더의 CSV 파일 등 텍스트 파일에 포함된 데이터를 불러와 넘파이 어레이 객체로 반환한다.
이때 구분자(delimiter), 건너뛸 행(skiprows), 불러올 열(usecols), 항목 자료형(dtype) 등의 키워드 인자를
지정하여 원하는 데이터만 원하는 형식으로 선택적으로 불러올 수 있다.
아래 코드에서는 iris.csv 파일을 읽어올 때 첫행인 헤더를 건너뛰고,
usecols=0키워드 인자를 지정하여 0번 열, 즉 꽃받침 길이 데이터가 포함된 열만 1차원 어레이로 가져온다.
iris_sepal_length = np.loadtxt(data_url+"iris.csv", delimiter=',', skiprows=1, dtype='float16', usecols=0)
iris_sepal_length반면에 아래 코드는 4번 열, 즉 꽃잎 너비 데이터를 담은 열만 1차원 어레이로 불러온다.
iris_variety = np.loadtxt(data_url+"iris.csv", delimiter=',', skiprows=1, dtype=str, usecols=4)
iris_variety각 변수가 가리키는 값을 확인하면 shape이 (150,), 즉 150개의 항목을 갖는 1차원 어레이라고 알려준다.
차원은 모양을 가리키는 튜플의 길이가 1인 것으로 확인된다.
iris_sepal_length.shapeiris_variety.shape실제로 두 어레이의 ndim 속성을 확인하면 차원이 1로 확인된다.
iris_sepal_length.ndimiris_variety.ndim반면에 두 1차원 어레이의 항목 자료형은 서로 다르다.
iris_sepal_length.dtypeiris_variety.dtype14.4.42차원 어레이로 불러오기¶
수치형 특성들만 2차원 어레이로 불러오기
붓꽃 샘플별로 품종을 제외한 나머지 네 개의 특성으로 구성된 데이터만 불러오기 위해
usecols=(0, 1, 2, 3)을 지정한다.
즉, 0번 열부터 3번 열까지만 대상으로 np.loadtxt() 함수를 적용한다.
네 열에 포함된 데이터가 모두 부동소수점이기에 생성된 어레이의 항목 자료형은
float64로 자동 지정된다.
iris_features = np.loadtxt(data_url+"iris.csv", delimiter=',', skiprows=1, usecols=(0, 1, 2, 3))
iris_features아래 코드는 iris_features가 가리키는 어레이의 모양, 항목 자료형, 차원을 확인해준다.
print('모양:', iris_features.shape)
print('항목 자료형:', iris_features.dtype)
print('차원:', iris_features.ndim)품종 데이터까지 2차원 어레이로 불러오기
품종 특성은 문자열로 구성되어 다른 열의 특성값들과 자료형이 다르다.
따라서 모든 데이터를 함께 넘파이 어레이로 불러오려면 dtype='object' 또는 dtype='str'로 지정해야 한다.
그러면 모든 값이 문자열로 변환되어 어레이에 포함된다.
모든 열(특성)을 2차원 어레이로 불러오려면 usecols 키워드 인자는 굳이 지정하지 않아도 된다.
물론 usecols=(0, 1, 2, 3, 4)로 모든 열을 지정해도 된다.
iris_full_object = np.loadtxt(data_url+"iris.csv", delimiter=',', skiprows=1, dtype=object)
iris_full_objectnp.loadtxt() 함수의 dtype=object 키워드 인자를 지정해도 모든 열의 자료형이 문자열로 지정되는
np.loadtxt() 함수가 여러 자료형이 포함된 경우 문자열로 모든 값을 변환하여 불러오기 때문이다.
따라서 아래 코드에서처럼 차라리 dtype='str 지정하는 것이 자료형을 명확히 한다는 측면에서 보다 좋다.
iris_full_str = np.loadtxt(data_url+"iris.csv", delimiter=',', skiprows=1, dtype='str')
iris_full_strdtype='str'로 지정해서 생성된 어레이의 항목 자료형이 <U10인 이유는
항목에 포함된 문자열 중에서 'Versicolor'의 길이가 10으로 가장 길기 때문이다.
아래 코드는 iris_full_str이 가리키는 어레이의 모양, 항목 자료형, 차원을 확인해준다.
print('모양:', iris_full_str.shape)
print('항목 자료형:', iris_full_str.dtype)
print('차원:', iris_full_str.ndim)14.4.5연습 문제¶
문제 1
np.loadtxt() 함수를 사용하여 붓꽃 데이터셋(iris.csv)에서 ‘꽃받침 너비(sepal.width)’ 데이터만 포함된 1차원 어레이를 생성하라.
단, 헤더는 건너뛰고, 데이터 타입은 float32로 지정한다.
또한 생성된 어레이의 모양(shape)과 항목 자료형(dtype)을 출력하라.
답:
import numpy as np
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'
# 꽃받침 너비는 1번 열(인덱스 1)에 위치함
iris_sepal_width = np.loadtxt(data_url + "iris.csv", delimiter=',', skiprows=1, dtype='float32', usecols=1)
print("어레이 모양:", iris_sepal_width.shape)
print("항목 자료형:", iris_sepal_width.dtype)어레이 모양: (150,)
항목 자료형: float32
설명:
꽃받침 너비 데이터는 CSV 파일의 두 번째 열에 있으므로 usecols=1을 지정한다.
첫 행은 헤더이므로 skiprows=1로 건너뛰고, dtype='float32'를 통해 32비트 부동소수점 자료형으로 데이터를 불러온다.
문제 2
붓꽃 데이터셋에서 '꽃잎 길이(petal.length)'와 ‘꽃잎 너비(petal.width)’ 두 가지 특성만 추출하여 2차원 어레이를 생성하라.
생성된 어레이의 차원(ndim)과 모양(shape)을 확인하라.
답:
import numpy as np
# 꽃잎 길이(2번 열)와 꽃잎 너비(3번 열) 추출
iris_petal_features = np.loadtxt(data_url + "iris.csv", delimiter=',', skiprows=1, usecols=(2, 3))
print("어레이 차원:", iris_petal_features.ndim)
print("어레이 모양:", iris_petal_features.shape)어레이 차원: 2
어레이 모양: (150, 2)
설명:
꽃잎 관련 데이터는 각각 2번, 3번 인덱스 열에 위치하므로 usecols=(2, 3) 튜플을 전달하여 두 열만 선택적으로 불러온다. 반환된 객체는 행과 열을 갖는 2차원 어레이(ndim=2)가 되며, 150개의 샘플과 2개의 특성을 가지므로 모양은 (150, 2)가 된다.
문제 3
붓꽃 데이터셋의 ‘꽃받침 길이(sepal.length)’(0번 열)와 ‘품종(variety)’(4번 열) 데이터를 함께 2차원 어레이로 불러오려 한다.
두 열을 함께 불러오는 코드를 작성하고, 생성된 어레이의 항목 자료형(dtype)이 어떻게 결정되는지 확인한 후 그 이유를 설명하라.
답:
import numpy as np
# 0번 열(숫자)과 4번 열(문자열)을 함께 불러오기
iris_mixed = np.loadtxt(data_url + "iris.csv", delimiter=',', skiprows=1, dtype='str', usecols=(0, 4))
print("항목 자료형:", iris_mixed.dtype)항목 자료형: <U10
설명:
숫자형 데이터(꽃받침 길이)와 문자열 데이터(품종)를 하나의 넘파이 어레이로 불러오려면
모든 항목이 동일한 자료형을 가져야 한다는 규칙 때문에 dtype='str'(또는 object)을 지정해야 한다.
이 경우 숫자 데이터도 모두 문자열로 강제 변환되어 저장되며, dtype은 포함된 문자열 중 가장 긴 길이에 맞춰(예: <U10) 자동 지정된다.
문제 4
데이터셋 크기는 데이터셋에 포함된 데이터 샘플의 수를 가리킨다.
np.loadtxt()를 이용해 붓꽃 데이터셋의 모든 수치형 특성(0번~3번 열)을 2차원 어레이로 불러온 후,
어레이의 속성을 이용하여 이 데이터셋에 총 몇 개의 붓꽃 샘플(행)이 포함되어 있는지 출력하는 코드를 작성하라.
답:
import numpy as np
# 수치형 특성 4개 불러오기
iris_numeric = np.loadtxt(data_url + "iris.csv", delimiter=',', skiprows=1, usecols=(0, 1, 2, 3))
# 샘플 수(행의 개수) 확인
num_samples = iris_numeric.shape[0]
print("어레이 모양:", iris_numeric.shape)
print("총 붓꽃 샘플 수:", num_samples)어레이 모양: (150, 4)
총 붓꽃 샘플 수: 150
설명:
2차원 어레이의 shape 속성은 (행의 개수, 열의 개수) 형태의 튜플을 반환한다.
여기서 행의 개수(shape[0])가 바로 데이터셋에 포함된 전체 샘플의 수를 의미한다.
튜플의 인덱싱은 리스트와 동일하게 작동하므로 [0]을 사용하여 첫 번째 항목을 가져올 수 있다.
붓꽃 데이터셋의 경우 150개의 샘플이 있으므로 150이 출력된다.
문제 5
붓꽃의 4개 특성 각각의 평균값을 구하는 코드를 작성하라.
답:
feature_means = iris_numeric.mean(axis=0)
print("특성별 평균:", feature_means)특성별 평균: [5.84333333 3.05733333 3.758 1.19933333]
설명:
어레이의 데이터들이 열(column) 방향으로 각각 다른 특성(꽃받침 길이 등)을 나타내고 있으므로, 각 특성별로 통계량을 구하려면 세로 방향으로 연산해야 한다.
이때 mean() 메서드에 축 인자인 axis=0을 지정하면 열별 계산 결과가 1차원 어레이로 반환된다.
문제 6
붓꽃의 4가지 특성별로 측정한 최댓값들을 비교하여,
가장 큰 수치를 기록한 특성은 몇 번째 열(인덱스)에 있는지를 찾는 코드를 작성하라.
예를 들어, "꽃받침 길이"의 최댓값이 모든 특성의 최댓값 중 가장 크다면 0이 반환되어야 한다.
답:
# 1단계: 각 특성별(열별) 최댓값 구하기
feature_maxes = iris_numeric.max(axis=0)
# 2단계: 최댓값들 중 가장 큰 값이 있는 위치(인덱스) 찾기
max_feature_index = feature_maxes.argmax()
print("가장 큰 수치를 기록한 특성의 인덱스:", max_feature_index)가장 큰 수치를 기록한 특성의 인덱스: 0
설명:
먼저 max(axis=0)을 사용해 특성별로 가장 큰 값 4개를 뽑아 1차원 어레이(feature_maxes)를 생성한다.
그리고 이 4개의 값 중에서 진짜 최고값이 위치한 인덱스를 찾을 때는 위치(인덱스)를 반환하는 argmax() 메서드를 활용한다.