판다스Pandas는 넘파이와 함께 데이터 분석에서 가장 많이 활용되는 라이브러리다.
판다스가 제공하는 두 개의 자료형 Series와 DataFrame은
데이터를 매우 효율적으로 다루는 다양한 기능을 제공한다.
넘파이 어레이는 다차원 수치형 데이터를 처리하는 데에 특화된 반면, 판다스의 시리즈와 데이터프레임은 표table 형식으로 제공되는 2차원 데이터에 특화되어 있다.
아래 이미지는 Mango, Apple, Banana 세 개의 과일 이름으로 구성된 열과 날짜별 과일 종류별 개수로 구성된 5개의 행으로 구성된 엑셀 표를 보여준다.
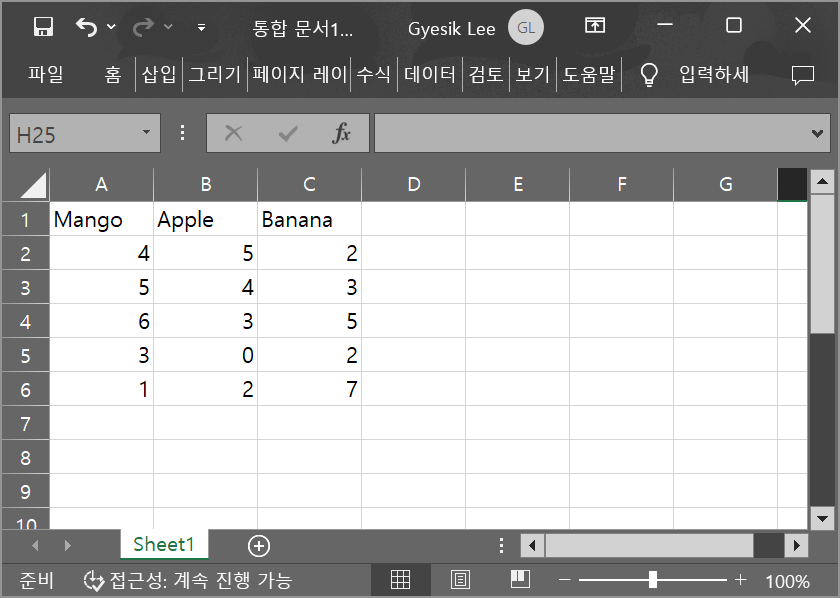
판다스 라이브러리의 Series 객체는 위 표의 각 열을,
DataFrame 객체는 위 표 전체를 효율적으로 다룰 수 있다.
여기서는 먼저 시리즈를, 다음 장에서 데이터프레임을 소개한다.
기본 설정
numpy와 pandas 라이브러리를 각각 np와 pd로 불러온다.
import numpy as np
import pandas as pd데이터 저장소
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'16.1시리즈 생성¶
시리즈는 1차원 어레이와 동일한 구조를 갖는다. 다만 인덱스를 0, 1, 2..가 아닌 원하는 값으로 지정할 수 있다. 시리즈를 생성하기 위해 리스트, 넘파이 1차원 어레이, 사전 등을 이용한다.
리스트 활용
리스트 또는 1차원 어레이를 이용하여 간단하게 시리즈를 생성할 수 있다.
어레이에서 dtype이 항목의 자료형을 나타내듯이, 시리즈에서도 동일한 의미로 사용된다
아래 코드는 리스트를 이용하여 위 그림의 표의 각 열에 대응하는 시리즈 객체를 생성한다.
시리즈를 정의할 때 사용되는 name 매개변수는 시리즈의 이름을 지정한다.
시리즈 이름의 기능은 나중에 데이터프레임을 생성할 때 유용하게 사용된다.
series1 = pd.Series([4, 5, 6, 3, 1], name="Mango")
series2 = pd.Series([5, 4, 3, 0, 2], name="Apple")
series3 = pd.Series([2, 3, 5, 2, 7], name="Banana")예를 들어 망고 데이터를 담은 series1을 확인해보자.
series10 4
1 5
2 6
3 3
4 1
Name: Mango, dtype: int64마치 하나의 열로 구성된 표를 담은 엑셀파일처럼 0부터 시작하는 행 인덱스와 함께 시리즈의 각 항목이 세로로 정렬된 형식으로 보여진다. 행 인덱스는 시리즈를 생성할 때 별도로 지정하지 않으면 0부터 시작하는 정수 인덱스가 사용된다. 행 인덱스는 또한 1차원 어레이와 유사한 방식으로 시리즈 인덱싱과 슬라이싱에 활용된다.
시리즈 객체의 자료형은 다음과 같다.
type(series1)pandas.Series시리즈는 1차원이다.
series1.ndim1어레이 활용
넘파이 1차원 어레이를 이용해 동일한 방식으로 시리즈를 생성할 수 있다.
series1 = pd.Series(np.array([4, 5, 6, 3, 1]), name="Mango")
series2 = pd.Series(np.array([5, 4, 3, 0, 2]), name="Apple")
series3 = pd.Series(np.array([2, 3, 5, 2, 7]), name="Banana")앞서 리스트를 이용한 경우와 동일한 시리즈 객체를 생성한다.
예를 들어 series2를 확인해보자.
series20 5
1 4
2 3
3 0
4 2
Name: Apple, dtype: int64사전 활용
사전을 이용하여 시리즈를 생성할 수 있다. 사전의 키가 인덱스로 지정되며, 따라서 아래 코드는 이전과 동일한 세 개의 시리즈 객체를 생성한다.
dic1 = {0: 4, 1: 5, 2: 6, 3: 3, 4: 1}
dic2 = {0: 5, 1: 4, 2: 3, 3: 0, 4: 2}
dic3 = {0: 2, 1: 3, 2: 5, 3: 2, 4: 7}
series1 = pd.Series(dic1, name="Mango")
series2 = pd.Series(dic2, name="Apple")
series3 = pd.Series(dic3, name="Banana")예를 들어 series3를 확인해보자.
series30 2
1 3
2 5
3 2
4 7
Name: Banana, dtype: int64라벨 인덱스 지정
사전의 키를 바꾸면 인덱스가 달라진다.
dic1 = {'첫째': 4, '둘째': 5, '셋째': 6, '넷째': 3, '다섯째': 1}
dic2 = {'첫째': 5, '둘째': 4, '셋째': 3, '넷째': 0, '다섯째': 2}
dic3 = {'첫째': 2, '둘째': 3, '셋째': 5, '넷째': 2, '다섯째': 7}
series1_count = pd.Series(dic1, name="Mango")
series2_count = pd.Series(dic2, name="Apple")
series3_count = pd.Series(dic3, name="Banana")예를 들어 series1_count를 확인하면 인덱스가 달라졌음이 확인된다.
series1_count첫째 4
둘째 5
셋째 6
넷째 3
다섯째 1
Name: Mango, dtype: int64이처럼 시리즈는 사용자가 라벨label을 이용하여 임의로 인덱스를 지정할 수 있다.
16.1.1연습문제¶
문제 1
아래 사전을 이용하여 시리즈를 생성하라. 단, 객체 이름을 '홀수’로 지정한다.
odds = {'일': 1, '삼': 3, '오': 5, '칠': 7, '구': 9}답:
pd.Series(odds, name="홀수")일 1
삼 3
오 5
칠 7
구 9
Name: 홀수, dtype: int64문제 2
아래 코드는 피어슨 아버지-아들 키 데이터셋에서 아버지 키만 넘파이 어레이로 불러온 다음에 시리즈로 변환한다.
넘파이 어레이로 불러올 때 skiprows=1 키워드 인자를 지정하여 생략한 'Father' 헤더 내용은
생성되는 시리즈의 name 속성으로 지정한다.
fathers_array = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1, usecols=0)
fathers = pd.Series(fathers_array, name="Father")
fathers0 165.1
1 160.8
2 165.1
3 167.1
4 155.2
...
1073 170.2
1074 181.1
1075 182.4
1076 179.6
1077 178.6
Name: Father, Length: 1078, dtype: float64반면에 판다스는 CSV, XLSX 파일을 직접 시리즈로 불러오는 API를 제공한다.
판다스의 read_csv() 함수를 이용하여 csv 파일의 특정 열을 한 번에 시리즈로 불러오는 코드를 작성하라.
답:
pd.read_csv() 함수를 이용하여 CSV 파일의 첫 번째 열만 불러온 후, .squeeze() 메서드를 사용하여 1차원 시리즈(Series) 형태로 변환하면 된다.
'Father' 헤더 내용이 자동으로 name 속성으로 지정됨에 유의한다.
fathers = pd.read_csv(data_url+"pearson_dataset.csv", usecols=[0]).squeeze()
fathers0 165.1
1 160.8
2 165.1
3 167.1
4 155.2
...
1073 170.2
1074 181.1
1075 182.4
1076 179.6
1077 178.6
Name: Father, Length: 1078, dtype: float64아래 코드에서처럼 불러오는 열 이름을 지정해도 된다.
fathers = pd.read_csv(data_url+"pearson_dataset.csv", usecols=["Father"]).squeeze()
fathers0 165.1
1 160.8
2 165.1
3 167.1
4 155.2
...
1073 170.2
1074 181.1
1075 182.4
1076 179.6
1077 178.6
Name: Father, Length: 1078, dtype: float6416.2시리즈 속성¶
시리즈는 넘파이 어레이보다 많은 속성을 객체 자체에 저장한다. 특히 인덱스와 항목 특성에 대한 정보가 유용하게 활용된다.
index 속성
index 속성은 행 인덱스로 사용된 값들로 구성된 Index 객체를 가리킨다.
자동으로 생성된 정수 인덱스는 range 객체와 유사하게 작동하는 RangeIndex 객체로 지정된다.
참고로 RangeIndex 클래스는 Index 클래스의 자식클래스다.
series1 = pd.Series(np.array([4, 5, 6, 3, 1]), name="Mango")
series1.indexRangeIndex(start=0, stop=5, step=1)정수 인덱스가 아닌 경우는 행 인덱스로 사용된 값들로 구성된 Index 객체로 지정되며,
어레이처럼 dtype을 이용하여 인덱스로 사용된 값들의 자료형을 명시한다.
dic1 = {'첫째': 4, '둘째': 5, '셋째': 6, '넷째': 3, '다섯째': 1}
series1_count = pd.Series(dic1, name="Mango")
series1_count.indexIndex(['첫째', '둘째', '셋째', '넷째', '다섯째'], dtype='str')index 속성을 임의의 값으로 지정할 수 있다.
단, 항목의 개수와 동일한 길이의 리스트를 이용해야 한다.
new_index = ['영', '일', '이', '삼', '사']
series1_count.index = new_index
series1_count영 4
일 5
이 6
삼 3
사 1
Name: Mango, dtype: int64시리즈를 정의할 때 index 매개변수의 키워드 인자를 이용하여
원하는 행 인덱스를 지정할 수도 있다.
단, 항목의 수와 동일한 길이를 갖는 리스트를 활용해야 한다.
another_index = ['one', 'two', 'three', 'four', 'five']
series1 = pd.Series([4, 5, 6, 3, 1], index=another_index, name="Mango")
series1one 4
two 5
three 6
four 3
five 1
Name: Mango, dtype: int64series1.indexIndex(['one', 'two', 'three', 'four', 'five'], dtype='str')name 속성
시리즈 객체는 두 종류의 name 속성을 활용한다.
앞서 사용한 시리즈 항목들의 특성을 가리키는 속성
시리즈 인덱스에 사용된 값들의 특성을 가리키는 속성
시리즈 객체의 name 속성
Series 객체를 생성할 때, 또는 생성 이후에
name 속성에 시리즈에 포함된 데이터를 대변하는 이름을 지정할 수 있다.
아래 코드는 series2의 name 속성을
'Apple'에서 '사과'로 변경한다.
series2.name = "사과"아래 코드는 시리즈의 이름이 변경되었음을 보여준다.
series20 5
1 4
2 3
3 0
4 2
Name: 사과, dtype: int64시리즈의 인덱스 객체의 name 속성
시리즈의 인덱스 객체도 name 속성을 가질 수 있다.
이 속성은 시리즈에 포함된 값들의 이름이 아니라,
행 인덱스로 사용된 값들의 용도를 설명한다.
예를 들어 날짜, 학생 이름, 지역명 등이 행 인덱스로 사용될 때
인덱스의 이름을 각각 날짜, 학생, 지역 등으로 지정할 수 있다.
series2.index.name = "순번"
series2순번
0 5
1 4
2 3
3 0
4 2
Name: 사과, dtype: int64values 속성
values 속성은 시리즈의 항목만으로 구성된 1차원 어레이를 가리킨다.
이처럼 판다스 시리즈는 넘파이 1차원 어레이를 기본 저장장치로 활용한다.
series1.valuesarray([4, 5, 6, 3, 1])series2.valuesarray([5, 4, 3, 0, 2])series3.valuesarray([2, 3, 5, 2, 7])16.2.1연습문제¶
문제 1
아래 사전을 이용하여 각 과일의 가격을 나타내는 시리즈 prices를 생성하고자 한다.
(1) 시리즈의 이름(name 속성)을 '과일가격'으로 지정하면서 시리즈를 생성하라.
fruit_prices = {'사과': 1500, '바나나': 2500, '망고': 4000}답:
name="과일가격" 키워드 인자를 사용하며 시리즈를 다음과 같이 생성한다.
prices = pd.Series(fruit_prices, name="과일가격")
prices사과 1500
바나나 2500
망고 4000
Name: 과일가격, dtype: int64(2) 생성된 prices 시리즈를 활용하여 다음 두 가지 작업을 순서대로 수행하는 코드를 작성하라.
행 인덱스가 무엇을 의미하는지 나타내기 위해 인덱스 객체의 이름(
index.name)을'과일종류'로 지정한다.시리즈에 저장된 가격 데이터(항목)만 넘파이 1차원 어레이로 추출하여 확인한다.
답:
인덱스 객체의 이름 지정
prices.index.name = "과일종류"
prices과일종류
사과 1500
바나나 2500
망고 4000
Name: 과일가격, dtype: int64항목(데이터)만 넘파이 1차원 어레이로 추출
prices.valuesarray([1500, 2500, 4000])문제 2
아래 코드는 4명 학생의 수학 점수를 담은 시리즈 scores를 기본 정수 인덱스를 사용하여 생성한다.
scores = pd.Series([85, 92, 78, 90])생성된 scores 시리즈를 활용하여 다음 세 가지 속성을 변경한 후 시리즈 전체를 확인하는 코드를 작성하라.
시리즈의 행 인덱스를
['철수', '영희', '민수', '지민']으로 변경한다.행 인덱스의 이름(
index.name)을'학생'으로 지정한다.시리즈의 이름(
name)을'수학점수'로 지정한다.
답:
시리즈의 index, index.name, name 속성에 새로운 값을 직접 할당하여 속성을 갱신할 수 있다.
scores.index = ['철수', '영희', '민수', '지민']
scores.index.name = '학생'
scores.name = '수학점수'
scores학생
철수 85
영희 92
민수 78
지민 90
Name: 수학점수, dtype: int6416.3시리즈 인덱싱과 슬라이싱¶
시리즈의 인덱싱과 슬라이싱은 정수 인덱스(.iloc[])를 사용하면 넘파이 어레이와 동일하게, 라벨 인덱스(.loc[])를 사용하면 다르게 작동한다
16.3.1시리즈 인덱싱¶
먼저, 시리즈 인덱싱을 설명한다. 설명을 위해 아래 시리즈를 이용한다.
series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4A 0.0
B 2.5
C 5.0
D 7.5
E 10.0
dtype: float64아래 코드는 지정된 인덱스 리스트에 포함된 라벨을 직접 이용하여 라벨 인덱스와 동일한 행에 위치한 항목을 확인하는 방식을 보여준다.
series4['B']np.float64(2.5)아래 방식도 동일하게 작동한다.
series4.loc['B']np.float64(2.5)사용자가 직접 지정한 라벨 인덱스와는 별도로
시리즈 객체는 내부에 0, 1, 2 등 행 순서에 맞는 정수 인덱스를 별도로 저장하며,
이 정수 인덱스를 리스트와 1차원 어레이의 인덱싱과 동일하게 작동하도록 할 수 있다.
대신 아래 코드에서처럼 시리즈.iloc[정수인덱스]형식으로 사용되어야 한다.
아래 코드는 B 인덱스 행이 둘째 행이기에 정수 인덱스 1을 이용하여
동일한 항목을 확인해준다.
series4.iloc[1]np.float64(2.5)반면에 인덱스 E에 해당하는 인덱싱은 다음 네 가지 방식으로 가능하다.
-1은 마지막 인덱스를 가리킴에 주의한다.
series4['E']np.float64(10.0)series4.loc['E']np.float64(10.0)series4.iloc[4]np.float64(10.0)series4.iloc[-1]np.float64(10.0)16.3.2시리즈 슬라이싱¶
행 위치를 나타내는 정수 인덱스로 슬라이싱할 때도 .iloc[]를 사용한다.
사용법은 1차원 어레이의 슬라이싱과 사실상 동일하다.
다만 슬라이싱 결과로 다시 시리즈가 생성되며,
인덱스는 슬라이싱 구간에 포함된 인덱스가 그대로 사용된다.
series4.iloc[1:3]B 2.5
C 5.0
dtype: float64반면에 정수가 아닌 주어진 라벨 인덱스를 이용하는 슬라이싱은 리스트의 슬라이싱과 비슷하지만, 지정된 구간의 양쪽 끝을 모두 포함한다는 점이 다르다.
예를 들어 아래 코드는 3번 인덱스의 행이 D 인덱스 행에 해당하지만 그 행까지 포함하여 슬라이싱이 적용된다.
series4['B':'D']B 2.5
C 5.0
D 7.5
dtype: float64.loc[]을 사용해도 동일한 결과를 얻는다.
series4.loc['B':'D']B 2.5
C 5.0
D 7.5
dtype: float6416.3.3항목 대체¶
인덱싱과 슬라이싱을 이용하여 지정된 구간의 항목을 한꺼번에 변경할 수 있다.
인덱싱 활용
지정된 인덱스 위치의 항목을 다른 값으로 대체한다.
series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4['B'] = -5.0
series4A 0.0
B -5.0
C 5.0
D 7.5
E 10.0
dtype: float64series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4.iloc[0] = -2.5
series4A -2.5
B 2.5
C 5.0
D 7.5
E 10.0
dtype: float64슬라이싱 활용
항목 변경에 사용되는 값은 스칼라, 즉 정수, 부동소수점, 불리언 등의 단일 값이거나, 슬라이싱 구간의 크기와 동일한 리스트, 튜플, 1차원 어레이 등으로 지정된다. 변경값으로 스칼라를 사용하면 지정된 구간의 모든 항목이 그 값으로 변경되며, 리스트 등을 사용하면 순서에 맞게 각 항목이 지정된다.
series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4.iloc[1:3] = 7.2
series4A 0.0
B 7.2
C 7.2
D 7.5
E 10.0
dtype: float64series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4.loc['B':'C'] = 5.0
series4A 0.0
B 5.0
C 5.0
D 7.5
E 10.0
dtype: float64series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4.iloc[1:3] = [1.5, 2.0]
series4A 0.0
B 1.5
C 2.0
D 7.5
E 10.0
dtype: float64series4 = pd.Series(np.arange(0, 11, 2.5), index=['A', 'B', 'C', 'D', 'E'])
series4['B':'C'] = np.array([7.2, 5.0])
series4A 0.0
B 7.2
C 5.0
D 7.5
E 10.0
dtype: float6416.3.4연습문제¶
문제 1
아래에는 5일 동안의 최고 기온을 기록한 시리즈 temps가 정의되어 있다.
temps = pd.Series([28.5, 30.2, 31.0, 29.5, 27.8],
index=['월', '화', '수', '목', '금'])(1) 정수 인덱스가 아닌 지정된 인덱스에 기반한 슬라이싱(예: ['화':'목'])과
정수 위치를 이용한 슬라이싱(.iloc) 두 가지 방식을 모두 사용하여,
화요일부터 목요일까지의 기온 데이터를 각각 추출하는 코드를 작성하라.
답:
라벨을 이용한 슬라이싱 (‘목’ 포함)
temps['화':'목']화 30.2
수 31.0
목 29.5
dtype: float64정수 위치 인덱스를 이용한 슬라이싱
temps.iloc[1:4]화 30.2
수 31.0
목 29.5
dtype: float64(2) 생성된 temps 시리즈 데이터 중에서 수요일과 목요일의 기온 값을 각각 32.0과 30.5로 한 번에 변경하려고 한다.
슬라이싱을 이용하여 이 두 항목의 값을 동시에 갱신하는 코드를 작성하라.
답:
슬라이싱 구간의 크기에 맞는 리스트를 지정하면 된다.
라벨을 이용한 슬라이싱
temps.loc['수':'목'] = [32.0, 30.5]
temps월 28.5
화 30.2
수 32.0
목 30.5
금 27.8
dtype: float64정수 위치 인덱스를 이용한 슬라이싱
temps.iloc[2:4] = [32.0, 30.5]
temps월 28.5
화 30.2
수 32.0
목 30.5
금 27.8
dtype: float64문제 2
A, B 두 구역의 제품별 재고량을 담은 시리즈 inventory가 다음과 같다.
inventory = pd.Series([50, 30, 20, 45, 10, 35],
index=['A01', 'A02', 'A03', 'B01', 'B02', 'B03'],
name='재고량')
inventoryA01 50
A02 30
A03 20
B01 45
B02 10
B03 35
Name: 재고량, dtype: int64(1) iloc[]과 음수 인덱스를 활용하여 뒤에서 3개 항목(B01~B03)을 슬라이싱으로 추출하라.
답:
끝에서 셋째 항목부터 슬라이싱을 적용하면 된다.
inventory.iloc[-3:]B01 45
B02 10
B03 35
Name: 재고량, dtype: int64(2) 라벨 인덱스를 활용하는 슬라이싱으로 동일한 결과를 얻는 코드를 작성하라.
답:
지정된 라벨의 구간을 지정하면 된다.
inventory['B01':'B03']B01 45
B02 10
B03 35
Name: 재고량, dtype: int64아래 방식도 가능하다.
inventory['B01':]B01 45
B02 10
B03 35
Name: 재고량, dtype: int64.loc[]을 활용해도 된다.
inventory.loc['B01':'B03']B01 45
B02 10
B03 35
Name: 재고량, dtype: int64inventory.loc['B01':]B01 45
B02 10
B03 35
Name: 재고량, dtype: int64(3) A 구역 제품(A01~A03)의 재고량을 모두 0으로, B 구역 제품(B01~B03)의 재고량을 [100, 200, 300]으로 한꺼번에 변경하는 코드를 작성하라.
답:
A구역 재고량을 스칼라 0으로 변경
inventory['A01':'A03'] = 0B 구역 재고량을 리스트로 변경
inventory['B01':'B03'] = [100, 200, 300]지정된 방식으로 값들이 수정되었음이 확인된다.
inventoryA01 0
A02 0
A03 0
B01 100
B02 200
B03 300
Name: 재고량, dtype: int64설명한 코드 전체를 정리하면 다음과 같다.
inventory = pd.Series([50, 30, 20, 45, 10, 35],
index=['A01', 'A02', 'A03', 'B01', 'B02', 'B03'],
name='재고량')
inventory['A01':'A03'] = 0
inventory['B01':'B03'] = [100, 200, 300]
inventoryA01 0
A02 0
A03 0
B01 100
B02 200
B03 300
Name: 재고량, dtype: int64문제 3
아래 코드는 피어슨 아버지-아들 키 데이터셋에서 아들 키 데이터를 시리즈로 불러온다.
sons = pd.read_csv(data_url+"pearson_dataset.csv", usecols=[1]).squeeze()
sons0 151.9
1 160.5
2 160.8
3 159.5
4 163.3
...
1073 179.8
1074 173.5
1075 176.0
1076 176.0
1077 170.2
Name: Son, Length: 1078, dtype: float64(1) .iloc[]을 활용하여 처음 5명과 마지막 5명의 아들 키 데이터를 각각 추출하는 코드를 작성하라.
답:
처음 5명
sons.iloc[:5]0 151.9
1 160.5
2 160.8
3 159.5
4 163.3
Name: Son, dtype: float64마지막 5명
sons.iloc[-5:]1073 179.8
1074 173.5
1075 176.0
1076 176.0
1077 170.2
Name: Son, dtype: float64(2) .iloc[] 슬라이싱을 활용하여 10번째부터 20번째 데이터(인덱스 9부터 19까지)를 추출한 후,
해당 구간의 모든 값을 0.0으로 변경하라.
변경 후 동일한 슬라이싱으로 값이 변경되었는지 확인하라.
답:
추출
sons.iloc[9:20]9 162.6
10 165.6
11 166.1
12 166.9
13 166.1
14 165.9
15 164.6
16 165.1
17 166.4
18 165.4
19 166.4
Name: Son, dtype: float64값 변경
sons.iloc[9:20] = 0.0변경 확인
sons.iloc[9:20]9 0.0
10 0.0
11 0.0
12 0.0
13 0.0
14 0.0
15 0.0
16 0.0
17 0.0
18 0.0
19 0.0
Name: Son, dtype: float64(3) 원본 데이터를 다시 불러온 뒤, .iloc[]을 활용하여
짝수 인덱스에 위치한 데이터만 추출하는 코드를 작성하라.
힌트: .iloc[]에 슬라이싱의 스텝(step)을 활용한다.
답:
짝수 인덱스만 추출하려면 0부터 스텝 2씩 증가하는 슬라이싱 [0::2]를 적용하면 된다.
# 데이터셋 다시 불러오기
sons = pd.read_csv(data_url+"pearson_dataset.csv", usecols=[1]).squeeze()
# 짝수 인덱스만 추출
sons.iloc[::2]0 151.9
2 160.8
4 163.3
6 162.8
8 164.1
...
1068 169.4
1070 172.5
1072 151.9
1074 173.5
1076 176.0
Name: Son, Length: 539, dtype: float64