피어슨 상관계수로 유명한 영국 통계학자 칼 피어슨Karl Pearson이 1903년에 실험을 위해 수집한 1,078개의 아버지와 아들의 키(신장)로 구성된 데이터셋을 활용하여 넘파이 어레이를 활용한 다양한 연산을 살펴본다.
기본 설정
import numpy as np데이터 저장소
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'15.1실전 예제: 피어슨 아버지-아들 키 데이터셋¶
피어슨 아버지-아들 키 데이터는 원래 인치 단위로 작성되었지만 편의를 위해 센티미터 단위로 변환되었으며,
pearson_dataset.csv 파일에 아래 형식으로 저장되어 있다.
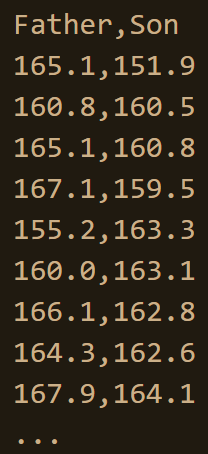
첫행의 Father,Son은 각각의 열에 포함된 데이터가 아버지들의 키와 아들의 키임을 알려주는
헤더header다.
15.1.11차원 어레이로 불러오기¶
피어슨 아버지-아들 키 데이터셋에서 아버지와 아들의 키 데이터를 구분하여 각각 1차원 어레이로 불러오려 한다.
피어슨 데이터셋은 숫자만으로 구성되었기에 np.loadtxt() 함수로 편하게 어레이로 불러올 수 있다.
아래 코드에서는 pearson_dataset.csv 파일을 읽어올 때 첫행인 헤더를 건너뛰고,
첫 번째 열(0번 인덱스 열)은 fathers 변수가 가리키는 1차원 어레이로,
두 번째 열(1번 인덱스 열)은 sons 변수가 가리키는 1차원 어레이로 각각 불러온다.
fathers = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1, usecols=0)
sons = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1, usecols=1)15.1.22차원 어레이로 불러오기¶
아래 코드는 피어슨 아버지-아들 키 데이터셋에서 아버지와 아들의 키 데이터를 함께 2차원 어레이로 불러온다.
fathers와 sons를 정의할 때와는 다르게 useccols 키워드 인자를 지정하지 않는다.
여기서도 또한 헤더는 생략한다.
pearson = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1)피어슨 아버지-아들 키 데이터셋은 2개의 열만 포함하기에 usecols=(0, 1)로 지정해도 동일한 어레이가 반환된다.
pearson = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1, usecols=(0, 1))불러온 값을 확인하면 shape이 (1078, 2), 즉
1,078개의 행과 2개의 열로 구성된 2차원 어레이라고 알려준다.
pearsonarray([[165.1, 151.9],
[160.8, 160.5],
[165.1, 160.8],
...,
[182.4, 176. ],
[179.6, 176. ],
[178.6, 170.2]], shape=(1078, 2))ndim과 dtype 속성을 확인하면 다음과 같다.
print('아버지-아들 키 데이터의 차원:', pearson.ndim)
print('아버지-아들 키 데이터의 항목 자료형:', pearson.dtype)아버지-아들 키 데이터의 차원: 2
아버지-아들 키 데이터의 항목 자료형: float64
15.1.3연습 문제¶
문제 1
np.loadtxt() 함수를 사용하여 피어슨 데이터셋(pearson_dataset.csv)에서 아들의 키(Son) 데이터만 포함된 1차원 어레이를 생성하라.
단, 헤더는 건너뛰고, 데이터 타입은 float32로 지정한다.
생성된 어레이의 모양(shape)과 항목 자료형(dtype)을 출력하라.
답:
import numpy as np
# data_url은 본문에서 정의된 변수를 사용한다고 가정
# 아들의 키는 1번 열(인덱스 1)에 위치함
sons_f32 = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, dtype='float32', usecols=1)
print("어레이 모양:", sons_f32.shape)
print("항목 자료형:", sons_f32.dtype)어레이 모양: (1078,)
항목 자료형: float32
설명:
아들의 키 데이터는 CSV 파일의 두 번째 열에 있으므로 usecols=1을 지정한다.
첫 행은 헤더이므로 skiprows=1로 건너뛰고, dtype='float32'를 통해 32비트 부동소수점 자료형으로 데이터를 불러온다.
문제 2
np.loadtxt() 함수를 사용하여 피어슨 데이터셋(pearson_dataset.csv)에서
처음 10 가족의 아버지와 아들 키 데이터만 포함하는 2차원 어레이를 생성하라.
단, 헤더는 건너뛰고 두 열 모두 불러오지만 아들 키를 왼편에 위치하도록 하라.
또한 생성된 어레이의 모양(shape)을 확인한다.
답:
pearson_10 = np.loadtxt(
data_url + "pearson_dataset.csv",
delimiter=",",
skiprows=1,
usecols=(1, 0), # 아들 키(1번 열)와 아버지 키(0번 열)를 선택
max_rows=10 # 처음 10행만 읽어오기
)[아들키, 아버지키] 형식으로 불러옴을 확인한다.
pearson_10array([[151.9, 165.1],
[160.5, 160.8],
[160.8, 165.1],
[159.5, 167.1],
[163.3, 155.2],
[163.1, 160. ],
[162.8, 166.1],
[162.6, 164.3],
[164.1, 167.9],
[162.6, 170.2]])print("어레이 모양:", pearson_10.shape)어레이 모양: (10, 2)
설명:
usecols=(1, 0)을 지정하면 아들과 아버지의 키 순서대로 두 열을 함께 불러온다.
또한 max_rows=10을 사용하면 헤더를 제외한 데이터 중 처음 10개 행만 읽어온다.
따라서 생성된 어레이는 (10, 2) 모양의 2차원 어레이가 된다.
문제 3
피어슨 데이터셋의 아버지 키(fathers) 데이터를 기본 자료형(float64)으로 불러온 1차원 어레이와,
16비트 부동소수점(float16)으로 불러온 1차원 어레이를 각각 생성하라.
두 어레이가 차지하는 전체 메모리 크기(바이트)를 비교하여 출력하라.
답:
import numpy as np
# data_url은 본문에서 정의된 변수를 사용한다고 가정
# 기본 자료형(float64)으로 불러오기
fathers_f64 = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=0)
# float16 자료형으로 불러오기
fathers_f16 = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, dtype='float16', usecols=0)
print("기본 어레이(float64) 전체 크기(바이트):", fathers_f64.nbytes)
print("float16 어레이 전체 크기(바이트):", fathers_f16.nbytes)기본 어레이(float64) 전체 크기(바이트): 8624
float16 어레이 전체 크기(바이트): 2156
설명:
기본적으로 부동소수점 어레이는 float64(항목당 8바이트)로 생성되므로, 1,078개의 항목을 가진 어레이는 총 8,624바이트를 차지한다.
반면 dtype='float16'(항목당 2바이트)을 지정하여 불러오면 전체 크기가 2,156바이트로 줄어들어 메모리 사용량을 크게 절약할 수 있다.
문제 4
피어슨 데이터셋의 아들 키(sons) 데이터를 기본 자료형(float64)으로 불러온 후, 이 어레이를 정수형(int32)으로 변환(astype)한 새로운 어레이를 생성하라.
변환 전과 후의 항목 자료형(dtype)과 각 항목이 차지하는 메모리 크기(itemsize)를 출력하고, 자료형 변환으로 인해 데이터에 어떤 변화가 생길 수 있는지 설명하라.
답:
import numpy as np
# 아들 키 데이터 불러오기 (기본 float64)
sons_float = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=1)
# int32 자료형으로 변환
sons_int = sons_float.astype('int32')
print("변환 전(float64) 항목 자료형:", sons_float.dtype)
print("변환 전(float64) 항목 크기(바이트):", sons_float.itemsize)
print("변환 후(int32) 항목 자료형:", sons_int.dtype)
print("변환 후(int32) 항목 크기(바이트):", sons_int.itemsize)변환 전(float64) 항목 자료형: float64
변환 전(float64) 항목 크기(바이트): 8
변환 후(int32) 항목 자료형: int32
변환 후(int32) 항목 크기(바이트): 4
설명:
부동소수점(float64) 어레이를 정수형(int32)으로 변환하면,
각 항목이 차지하는 메모리 크기가 8바이트에서 4바이트로 줄어든다.
하지만 소수점 이하의 값이 모두 버려지고 정수 부분만 남게 되므로(예: 165.1 -> 165),
데이터의 정밀도 손실이 발생할 수 있음을 주의해야 한다.
15.2어레이 연산¶
넘파이 어레이 연산은 기본적으로 동일한 모양을 갖는 두 어레이에 대해 항목별로 이루어진다. 즉, 지정된 연산을 동일한 위치의 항목끼리 실행하여 새로운, 동일한 모양의 어레이를 생성한다.
15.2.1사칙연산¶
동일한 모양의 1차원 어레이 두 개를 이용한다.
arr1 = np.arange(1, 6)
arr1array([1, 2, 3, 4, 5])arr2 = np.arange(5, 6, 0.2)
arr2array([5. , 5.2, 5.4, 5.6, 5.8])동일한 모양의 두 1차원 어레이에 대한 사칙연산은 항목별로 이뤄지며 최종적으로 동일한 모양의 1차원 어레이가 계산된다.
arr1 + arr2array([ 6. , 7.2, 8.4, 9.6, 10.8])arr1 - arr2array([-4. , -3.2, -2.4, -1.6, -0.8])arr1 * arr2array([ 5. , 10.4, 16.2, 22.4, 29. ])arr1 / arr2array([0.2 , 0.38461538, 0.55555556, 0.71428571, 0.86206897])2차원 어레이 연산도 동일한 방식으로 진행된다. 먼저 예제를 위해 (2, 3) 모양의 2차원 어레이를 두 개를 정의한다.
arr3= np.arange(1, 7).reshape((2, 3)).astype('float16')
arr3array([[1., 2., 3.],
[4., 5., 6.]], dtype=float16)arr4= np.arange(13, 2, -2).reshape((2, 3)).astype('float16')
arr4array([[13., 11., 9.],
[ 7., 5., 3.]], dtype=float16)동일한 모양의 두 2차원 어레이에 대한 사칙연산은 항목별로 이뤄지며 최종적으로 동일한 모양의 2차원 어레이가 계산된다.
arr3 + arr4array([[14., 13., 12.],
[11., 10., 9.]], dtype=float16)arr3 - arr4array([[-12., -9., -6.],
[ -3., 0., 3.]], dtype=float16)arr3 * arr4array([[13., 22., 27.],
[28., 25., 18.]], dtype=float16)arr3 / arr4array([[0.0769, 0.1818, 0.3333],
[0.5713, 1. , 2. ]], dtype=float16)15.2.2브로드캐스팅과 연산¶
브로드캐스팅
브로드캐스팅broadcasting은 모양이 서로 다른 두 어레이가 주어졌을 때 두 모양을 통일시킬 수 있다면 두 어레이의 연산이 가능하도록 도와주는 기능이다. 설명을 위해 하나의 어레이와 하나의 정수의 곱셈, 즉 어레이와 스칼라의 연산이 작동하는 과정을 살펴본다.
arr1 = np.arange(6).reshape((2,3))
arr1array([[0, 1, 2],
[3, 4, 5]])위 어레이에 4를 곱한 결과는 다음과 같다.
arr1 * 4array([[ 0, 4, 8],
[12, 16, 20]])결과가 항목별로 곱해지는 이유는 arr1 * 4 가 아래 어레이의 곱셈과 동일하게 작동하기 때문이다.
즉, 정수 4로 채워진 동일한 모양의 어레이를 먼저 생성한 후에 항목별 곱셈을 진행한다.
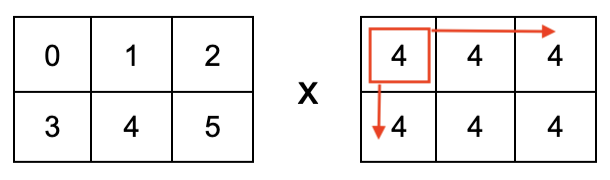
곱셈 이외에 다른 연산도 동일한 방식으로 작동한다.
arr1 + 4array([[4, 5, 6],
[7, 8, 9]])arr1 - 4array([[-4, -3, -2],
[-1, 0, 1]])arr1 / 4array([[0. , 0.25, 0.5 ],
[0.75, 1. , 1.25]])사칙연산은 아니지만 몫과 나머지 연산도 동일하게 항목별로 계산된다.
arr1 // 2array([[0, 0, 1],
[1, 2, 2]])arr1 % 2array([[0, 1, 0],
[1, 0, 1]])이와 같이 어레이의 모양을 확장하여 항목별 연산이 가능해지도록 하는 기능은 두 어레이의 모양을 통일시킬 수 있는 경우 항상 작동한다.
어레이 연산에서 두 어레이의 모양을 맞추기 위해 브로드캐스팅이 가능하면 먼저 적용되 후에 연산이 실행된다.
1차원 어레이와 2차원 어레이 연산
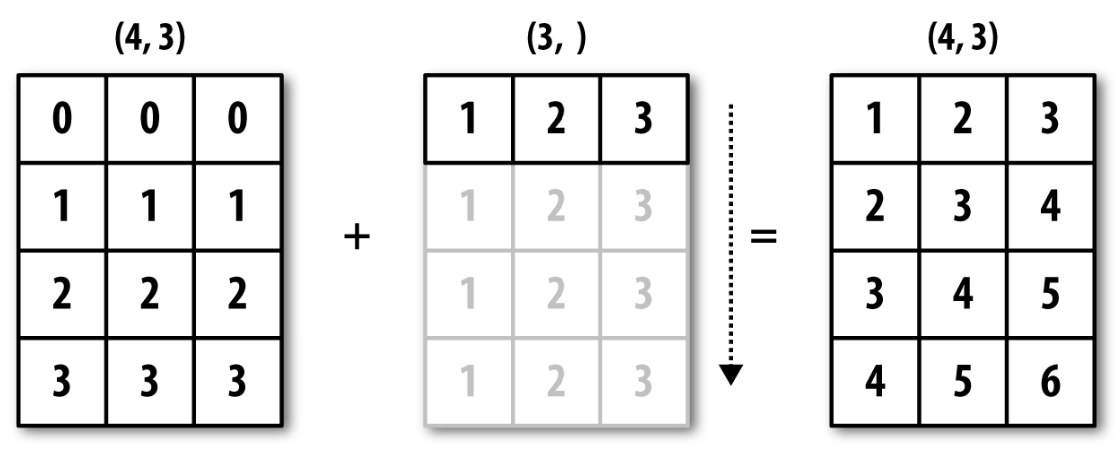
아래 코드는 1차원 어레이를 2차원 어레이로 확장하여 다른 어레이와 모양을 맞춘 후 연산을 실행한 결과를 보여준다.
arr2 = np.array([[0, 0, 0],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])arr3 = np.arange(1, 4)
arr3array([1, 2, 3])arr2 + arr3array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])아래 그림이 위 연산이 작동하는 이유를 설명한다.
동일한 이유로 다음 연산도 가능하다.
arr3_a = np.arange(1, 4).reshape((1, 3))
arr3_aarray([[1, 2, 3]])arr2 + arr3_aarray([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])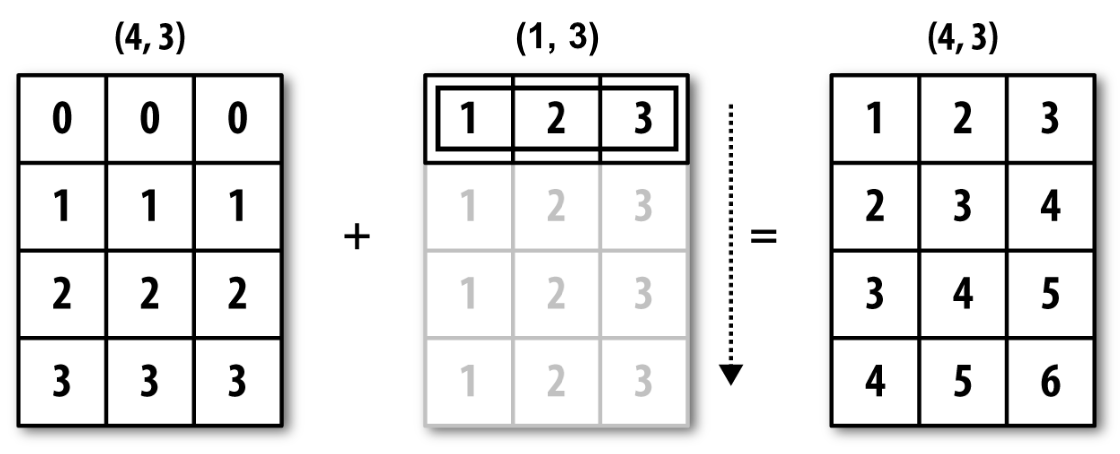
두 2차원 어레이 모양 맞추기
아래 예제는 2차원 어레이의 칸을 복제하여 모양을 맞춘 후 연산을 실행한다.
arr4 = np.arange(1, 5).reshape((4,1))
arr4array([[1],
[2],
[3],
[4]])arr2 + arr4array([[1, 1, 1],
[3, 3, 3],
[5, 5, 5],
[7, 7, 7]])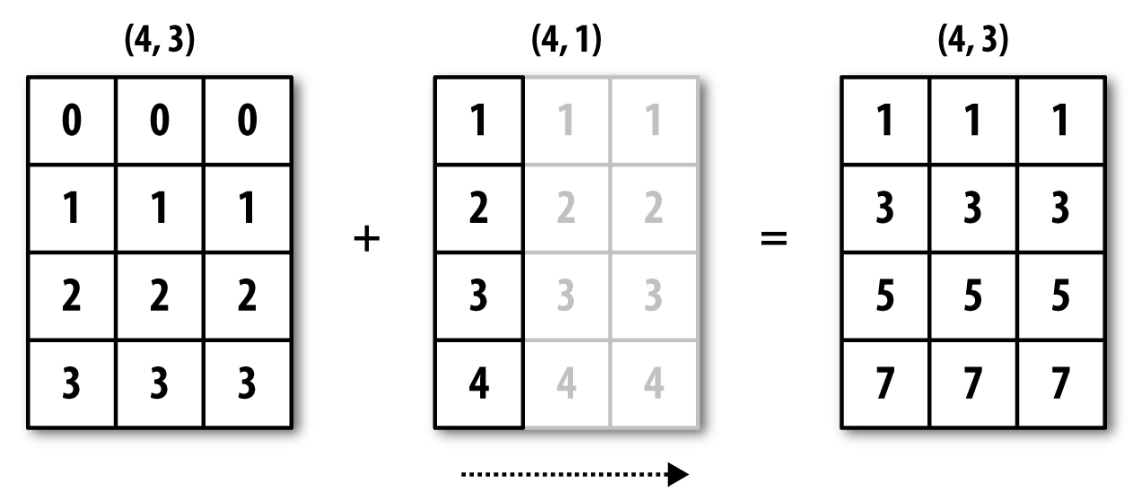
그런데 브로드캐스팅은 두 어레이의 모양을 통일시킬 수 있을 때만 가능하다. 예를 아래 두 어레이의 덧셈은 불가능하다.
arr5 = np.array([[ 0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])arr6 = np.arange(1, 5)
arr6array([1, 2, 3, 4])arr5 + arr6---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[48], line 1
----> 1 arr5 + arr6
ValueError: operands could not be broadcast together with shapes (4,3) (4,) 아래 그림이 브로드캐스팅이 작동할 수 없는 이유를 설명한다.
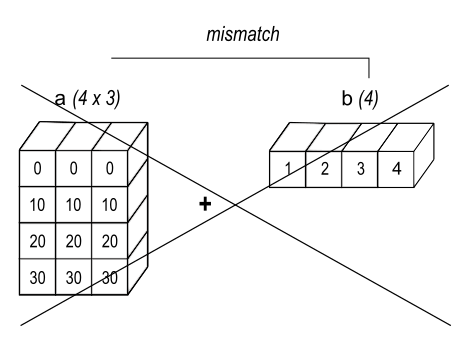
15.2.3비교 연산¶
모양이 동일한 두 어레이의 값 비교도 항목별로 수행되며,
결과물로 생성되는 어레이는 모든 항목이 bool 자료형, 즉 True 또는 False이다.
설명을 위해 앞서 다음 네 개의 어레이를 활용한다.
arr1 = np.arange(1, 6)
arr1array([1, 2, 3, 4, 5])arr2 = np.arange(5, 6, 0.2)
arr2array([5. , 5.2, 5.4, 5.6, 5.8])arr3= np.arange(1, 7).reshape((2, 3)).astype('float16')
arr3array([[1., 2., 3.],
[4., 5., 6.]], dtype=float16)arr4= np.arange(13, 2, -2).reshape((2, 3)).astype('float16')
arr4array([[13., 11., 9.],
[ 7., 5., 3.]], dtype=float16)arr2의 항목 중에서 동일한 위치의arr1항목보다 큰 경우에만True
arr1 < arr2array([ True, True, True, True, True])arr2의 항목 중에서 동일한 위치의arr1항목과 동치일 경우에만True
arr1 == arr2array([False, False, False, False, False])arr3의 항목 중에서 동일한 위치의arr4항목보다 갖거나 큰 경우에만True
arr3 >= arr4array([[False, False, False],
[False, True, True]])arr3의 항목 중에서 동일한 위치의arr4항목과 동치가 아닐 경우에만True
arr3 != arr4array([[ True, True, True],
[ True, False, True]])어레이와 스칼라의 비교 연산 또한 어레이와 스칼라의 사칙연산의 경우처럼 브로드캐스팅이 적용되어 항목별 비교 연산으로 계산된다.
arr2의 항목 중에서 5.5보다 클 경우에만True
5.5 < arr2array([False, False, False, True, True])arr2의 항목 중에서 5.5와 동치일 경우에만True
5.4 == arr2array([False, False, True, False, False])arr4의 항목 중에서 2의 배수, 즉 짝수일 경우에만True
arr4 % 2 == 0array([[False, False, False],
[False, False, False]])arr4의 항목 중에서 3의 배수가 아닐 경우에만True
arr4 % 3 != 0array([[ True, True, False],
[ True, True, False]])15.2.4논리 연산¶
부울 어레이
어레이 비교 연산의 결과는 dtype이 bool, 즉 모든 항목이 부울값인 부울 어레이다.
부울 어레이 논리 연산
부울 어레이를 대상으로 사용 가능한 논리 연산은 세 가지이다.
첫째, ~는 부정(not) 연산자로, True를 False로, False는 True로 값을 반전시킨다.
둘째, &는 논리곱(and) 연산자로, 두 조건이 모두 참일 때만 참을 반환한다.
셋째, |는 논리합(or) 연산자로, 두 조건 중 하나 이상이 참이면 참을 반환한다.
언급된 세 논리 연산자는 어레이의 모든 요소에 대해 항목별로 실행되어 동일한 모양의 부울 어레이를 생성한다.
| 기호 | 기능 |
|---|---|
~ | 부정(not) 연산자 |
& | 논리곱(and) 연산자 |
| | 논리합(or) 연산자 |
예제: 부정 연산자
arr1 * 3 >= arr2array([False, True, True, True, True])~(arr1 * 3 >= arr2)array([ True, False, False, False, False])부울 어레이 논리 연산 표현식을 작성할 때 괄호를 적절하게 사용해야 한다. 그렇지 않으면 오류가 발생하거나 다른 결과가 계산될 가능성이 높아진다. 예를 들어, 아래 코드는 부정 연산자를 비트 연산자로 처리하여 엉뚱한 어레이를 계산한다.
~arr1 * 3 >= arr2array([False, False, False, False, False])예제: 논리곱 연산자
(arr1 + 3 < arr2) & ~(arr1 * 2 >= arr2)array([ True, True, False, False, False])(arr3 > arr4) & (arr3 <= arr4 * 2)array([[False, False, False],
[False, False, True]])괄호를 사용하지 않으면 오류가 발생한다. 이유는 비트 연산과 논리 연산이 혼용되어 사용되기 때문이다.
arr1 + 3 < arr2 & ~arr1 * 2 >= arr2---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[108], line 1
----> 1 arr1 + 3 < arr2 & ~arr1 * 2 >= arr2
TypeError: ufunc 'bitwise_and' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''예제: 논리합 연산자
(arr1 < arr2-3) | (arr1 >= arr2)array([ True, True, False, False, False])~(arr3 == 5) | (arr4 == 9)array([[ True, True, True],
[ True, False, True]])역시나 괄호를 적절하게 사용하지 않으면 오류가 발생한다. 괄호를 적절하게 사용하지 않는 경우 발생하는 오류에 대해서는 여기서는 자세하게 설명하지 않는다.
~arr3 == 5 | arr4 == 9---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[111], line 1
----> 1 ~arr3 == 5 | arr4 == 9
TypeError: ufunc 'invert' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''15.2.5연습문제¶
문제 1
다음 두 개의 2차원 어레이 arr_A와 arr_B를 중첩 리스트를 이용하여 생성하라.
arr_A: 1부터 6까지의 정수로 구성된 (2, 3) 모양의 어레이arr_B: 10부터 60까지 10 단위로 증가하는 정수로 구성된 (2, 3) 모양의 어레이
두 어레이를 더한 후, 그 결과 어레이의 모든 항목을 2로 나눈 새로운 어레이를 생성하고 출력하라.
답:
import numpy as np
# 중첩 리스트를 이용한 2차원 어레이 생성
list_A = [[1, 2, 3],
[4, 5, 6]]
arr_A = np.array(list_A)
list_B = [[10, 20, 30],
[40, 50, 60]]
arr_B = np.array(list_B)
# 어레이 간 덧셈 후 스칼라 나눗셈
result_arr = (arr_A + arr_B) / 2
print("arr_A:\n", arr_A)
print("arr_B:\n", arr_B)
print("계산 결과:\n", result_arr)arr_A:
[[1 2 3]
[4 5 6]]
arr_B:
[[10 20 30]
[40 50 60]]
계산 결과:
[[ 5.5 11. 16.5]
[22. 27.5 33. ]]
설명:
동일한 모양의 두 2차원 어레이 arr_A와 arr_B의 덧셈은 같은 위치의 항목끼리 더해져 새로운 (2, 3) 모양의 어레이를 생성한다. 이후 스칼라 값 2로 나누면, 생성된 어레이의 모든 항목이 각각 2로 나뉘어 최종 결과가 도출된다.
문제 2
먼저 아래 조건에 맞는 1차원 어레이 arr_C를 생성하라.
arr_C: 1부터 10까지의 정수로 구성된 어레이
이 어레이에서 값이 3 이하이거나 8 이상인 항목을 판별하는 부울 어레이를 생성하라.
단, 논리합(|) 연산자와 부정(~) 연산자를 각각 한 번 이상 사용하여 조건식을 작성하고, 생성된 부울 어레이를 출력하라.
답:
import numpy as np
# 어레이 생성
arr_C = np.arange(1, 11)
# 논리합(|)과 부정(~) 연산자를 활용한 조건식
# "3 이하이거나 8 이상"은 "~(3 초과 이고 8 미만)"과 동일하지만,
# 문제 조건에 맞춰 직관적으로 작성: (arr_C <= 3) | ~(arr_C < 8)
condition_C = (arr_C <= 3) | ~(arr_C < 8)
print("arr_C:", arr_C)
print("조건 만족 여부:", condition_C)arr_C: [ 1 2 3 4 5 6 7 8 9 10]
조건 만족 여부: [ True True True False False False False True True True]
설명:
넘파이 어레이에서 두 개 이상의 조건을 결합할 때는 파이썬의 기본 or, not 대신 비트 논리 연산자인 |, ~를 사용해야 한다.
~(arr_C < 8)은 “8 미만이 아니다”, 즉 "8 이상이다"를 의미한다.
연산자 우선순위 문제로 인해 오류가 발생하지 않도록 각각의 비교 연산식을 반드시 괄호 ()로 묶어주어야 한다.
문제 3
피어슨 데이터셋의 ‘아들 키(Son)’ 데이터를 1차원 어레이로 불러온 후, 모든 아들의 키를 센티미터(cm)에서 미터(m) 단위로 변환하는 코드를 작성하라.
단, 1m = 100cm이며, 변환된 어레이의 항목 자료형(dtype)과 전체 항목 개수(size)를 출력하라.
답:
import numpy as np
# data_url은 본문에서 정의된 변수를 사용한다고 가정
# 아들 키는 1번 열(인덱스 1)에 위치함
sons_cm = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=1)
# 스칼라 나눗셈을 이용한 단위 변환 (cm -> m)
sons_m = sons_cm / 100
print("변환된 어레이 자료형:", sons_m.dtype)
print("전체 항목 개수:", sons_m.size)변환된 어레이 자료형: float64
전체 항목 개수: 1078
설명:
어레이와 스칼라(숫자 100)의 나눗셈 연산은 어레이의 모든 항목에 대해 개별적으로 적용된다. 따라서 sons_cm / 100을 실행하면 모든 아들의 키 데이터가 100으로 나뉘어 미터 단위로 변환된 새로운 어레이가 생성된다.
문제 4
피어슨 데이터셋에서 '아버지 키(Father)'와 '아들 키(Son)'를 각각 1차원 어레이로 불러오라. 아버지의 키가 170cm 미만이면서
아들의 키는 180cm 이상인 샘플을 판별하는 부울 어레이를 생성하라.
생성된 부울 어레이의 차원(ndim)과 모양(shape)을 출력하라.
답:
import numpy as np
# 아버지 키(0번 열)와 아들 키(1번 열) 불러오기
fathers = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=0)
sons = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=1)
# 논리곱(&) 연산자를 사용한 복합 조건 판별
# 주의: 각 비교 연산식은 반드시 괄호로 묶어야 함
condition = (fathers < 170.0) & (sons >= 180.0)
print("부울 어레이 차원:", condition.ndim)
print("부울 어레이 모양:", condition.shape)부울 어레이 차원: 1
부울 어레이 모양: (1078,)
설명:
넘파이 어레이에서 두 개 이상의 조건을 결합할 때는 파이썬의 기본 and 대신 비트 논리곱 연산자인 &를 사용해야 한다.
또한, 연산자 우선순위 문제로 인해 오류가 발생하지 않도록 각각의 비교 연산식(fathers < 170.0 등)을 반드시 괄호 ()로 묶어주어야 한다.
문제 5
아래 모양의 2차원 어레이를 생성하라.
단, np.arange(36)과 np.arange(0, 21, 4)에서 출발하여 reshape() 메서드와 덧셈 연산을 활용해야 한다.
array([[ 0, 1, 2, 3, 4, 5],
[10, 11, 12, 13, 14, 15],
[20, 21, 22, 23, 24, 25],
[30, 31, 32, 33, 34, 35],
[40, 41, 42, 43, 44, 45],
[50, 51, 52, 53, 54, 55]])답:
어레이의 모양이 (6, 6)이기에 우선 np.arange(36)과 reshape() 메서드를 이용하여 아래 어레이를 생성한다.
arange_36_6x6 = np.arange(36).reshape(6, 6)
arange_36_6x6array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])이제 0행부터 차례대로 0, 4, 8, 12, 16, 20을 더해야 하기에 언급된 값들을 항목으로 갖는 (6, 1) 모양의 어레이를 다음과 같이 생성한다.
arange_214_6x1 = np.arange(0, 21, 4).reshape(6, 1)
arange_214_6x1array([[ 0],
[ 4],
[ 8],
[12],
[16],
[20]])이제 두 어레이를 더하면 원하는 2차원 어레이가 생성된다.
arange_36_6x6 + arange_214_6x1array([[ 0, 1, 2, 3, 4, 5],
[10, 11, 12, 13, 14, 15],
[20, 21, 22, 23, 24, 25],
[30, 31, 32, 33, 34, 35],
[40, 41, 42, 43, 44, 45],
[50, 51, 52, 53, 54, 55]])문제 6
다음 코드를 작성하라.
np.arange(1, 13).reshape((4, 3))으로arr_base를 생성하라.1차원 어레이
add_col = np.array([0, 10, 20])를 이용해arr_base의 각 행에 열별로 더한arr_step1을 생성하라.2차원 어레이
add_row = np.array([[0], [100], [200], [300]])를 이용해arr_step1의 각 행에 행별로 더한arr_step2를 생성하라.arr_base,arr_step1,arr_step2를 출력하고,arr_step2의shape를 출력하라.
답:
import numpy as np
# 1) 기본 어레이
arr_base = np.arange(1, 13).reshape((4, 3))
# 2) 열 방향(각 행에 동일하게) 브로드캐스팅
add_col = np.arange(3) * 10 # shape: (3,)
arr_step1 = arr_base + add_col # (4, 3) + (3,)
# 3) 행 방향 브로드캐스팅
add_row = np.arange(4).reshape(-1, 1) * 100 # shape: (4, 1)
arr_step2 = arr_step1 + add_row # (4, 3) + (4, 1)
print("arr_base:\n", arr_base)
print("\narr_step1:\n", arr_step1)
print("\narr_step2:\n", arr_step2)
print("\narr_step2 shape:", arr_step2.shape)arr_base:
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
arr_step1:
[[ 1 12 23]
[ 4 15 26]
[ 7 18 29]
[10 21 32]]
arr_step2:
[[ 1 12 23]
[104 115 126]
[207 218 229]
[310 321 332]]
arr_step2 shape: (4, 3)
설명:
arr_base는 (4, 3) 모양이다.
add_col의 모양은(3,)이므로, 각 행에 동일한 열 기준 값이 더해진다.add_row의 모양은(4, 1)이므로, 각 행에 서로 다른 값이 열 전체에 반복되어 더해진다.
즉 브로드캐스팅을 이용해 별도 반복문 없이 열 기준/행 기준 보정을 순차적으로 적용할 수 있다.
문제 7
데이터의 평균을 0으로 맞추는 평균 중심화Mean-Centering 작업을 진행 하려 한다. 설명을 위해 피어슨 아버지-아들 데이터셋을 활용한다.
pearson = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1)(1) 어레이의 mean() 메서드를 이용하여 아버지 키와와 아들 키의 평균값을 계산하라.
힌트: 어레이의 열별 평균값은 axis=0 키워드 인자를 지정하면 계산된다.
답:
pearson.mean(axis=0)를 호출하면 (2,) 모양의 1차원 어레이가 생성된다.
means = pearson.mean(axis=0) # axis=0은 열 방향으로 평균 계산 (각 열의 평균)
meansarray([171.92263451, 174.45797774])아버지와 아들 키의 평균값은 다음과 같다.
print("아버지 키 평균:", means[0])
print("아들 키 평균:", means[1])아버지 키 평균: 171.92263450834864
아들 키 평균: 174.45797773654868
(2) 브로드캐스팅을 활용하여 단 한 줄의 코드로 원래의 pearson 어레이에서 각 열의 평균키를 빼는 연산을 수행한 다음에 각 열의 평균값을 계산하라.
답:
(1078 x 2) 모양의 2차원 어레이에서 (2,) 모양의 1차원 (2)를 빼면된다.
이때 1차원 어레이가 2차원 어레이의 모양에 맞게 행 단위로 브로드캐스팅되어 연산이 가능해진다.
pearson_centered = pearson - means이론적으로 각 열에서 각 열의 평균값을 빼면 평균값이 0이 되어야 한다. 하지만 부동소수점 연산은 어느 정도의 오차가 발생하기에 0으로 계산되지는 않는다. 다만 0에 매우 가까운 값이 계산된다.
pearson_centered.mean(axis=0)array([1.59588689e-13, 4.83116330e-13])15.3인덱싱과 슬라이싱¶
15.3.11차원 어레이 인덱싱과 슬라이싱¶
1차원 어레이의 인덱싱과 슬라이싱은 리스트의 경우와 동일하다. 설명을 위해 아래 1차원 어레이를 활용한다.
arr_1D = np.arange(10)
arr_1Darray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])5번 인덱스 항목 인덱싱. 결과는 스칼라.
arr_1D[5]np.int64(5)5번부터 8번 인덱스 이전까지의 항목 슬라이싱. 결과는 1차원 어레이.
arr_slice = arr_1D[5:8]
arr_slicearray([5, 6, 7])15.3.22차원 어레이 인덱싱¶
2차원 이상의 다차원 어레이는 리스트의 경우보다 훨씬 효율적인 인덱싱, 슬라이싱 기능을 제공한다. 설명을 위해 아래 2차원 어레이를 활용한다.
arr_2D = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr_2Darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])행과 열 인덱스
2차원 어레이는 행과 열 각 축에 대해 각각의 인덱스를 갖는다. 아래 그림에서 보여지듯이 (3, 3) 모양의 2차원 어레이의 상단부터 아래로 내려오는 순서대로 0, 1, 2를 행 인덱스를, 행렬 왼쪽부터 오른쪽으로 이동하면서 순서대로 0, 1, 2를 열 인덱스로 갖는다. 반면에 각 항목 우측 아래에 표시된 튜플은 각 항목의 좌표에 해당하며, 각 항목이 위치한 행과 열의 인덱스의 조합으로 구성된다.
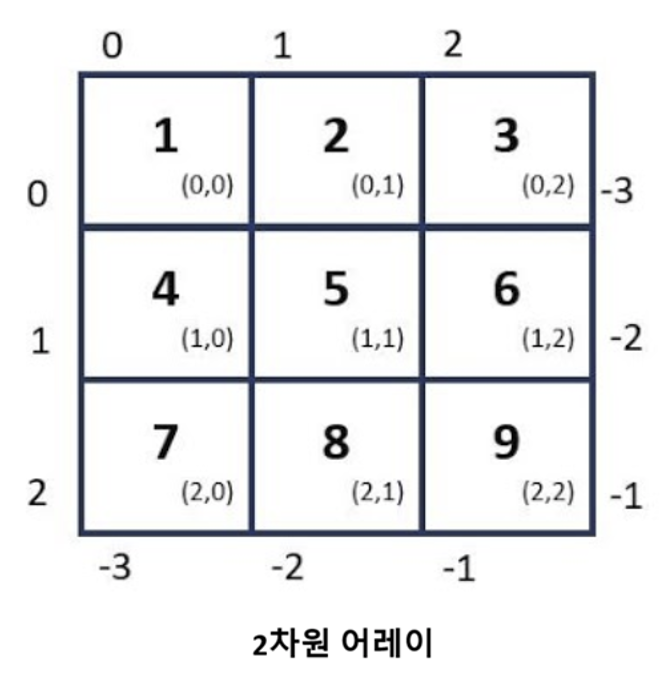
행 인덱싱
2차원 어레이의 특정 행을 대상으로 하는 인덱싱은 리스트의 인덱싱을 방식과 동일하며, 결과는 지정된 행의 항목들로 구성된 1차원 어레이다.
0번 행 인덱싱. 결과는 1차원 어레이.
arr_2D[0]array([1, 2, 3])2번 행 인덱싱. 결과는 1차원 어레이.
arr_2D[2]array([7, 8, 9])
열 인덱싱
열을 대상으로 하는 인덱싱은 지정된 열에 위치한 항목들로 구성된 1차원 어레이가 생성된다.
행 인덱싱과는 달리, 행과 열의 인덱스를 동시에 지정해야 하며,
모든 행을 대상한다는 의미에서 전체 행을 슬라이싱하는 의미의 : 로 지정한다.
0번 열 인덱싱. 결과는 1차원 어레이.
arr_2D[:, 0]array([1, 4, 7])2번 열 인덱싱. 결과는 1차원 어레이.
arr_2D[:, 2]array([3, 6, 9])행과 열 동시 인덱싱
몇 번 행의 몇 번 열에 위치한 값을 확인하는 방법을 소개한다. 먼저 아래 코드는 중첩 리스트의 경우처럼 인덱싱을 두 번 연속 적용하는 방식이 동일하게 작동함을 보여준다.
0번 행의 2번 열에 위치한 값 인덱싱. 결과는 스칼라.
arr_2D[0][2]np.int64(3)하지만 2차원 어레이의 0번 행의 2번 열의 값을 인덱싱 하기 위헤
다음과 같이 축별 인덱스를 활용한 좌표 형식의 인덱스 (0, 2)를 활용한
인덱싱이 가능하며, 보다 직관적이면서 효율적이다.
0번 행, 2번 열 인덱싱. 결과는 스칼라.
arr_2D[0, 2]np.int64(3)참고로 아래 방식은 어레이 고유의 방식이며 리스트에 대해서는 동작하지 않는다. 예를 들어 아래 코드는 중첩 리스트에 대해 동일한 방식을 시도하면 오류가 발생함을 보여준다.
list_2D = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
list_2D[0, 2]---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[135], line 5
1 list_2D = [[1, 2, 3],
2 [4, 5, 6],
3 [7, 8, 9]]
----> 5 list_2D[0, 2]
TypeError: list indices must be integers or slices, not tuple15.3.32차원 어레이 슬라이싱¶
행 슬라이싱
2차원 어레이에 대한 행 슬라이싱은 리스트 슬라이싱 방식과 동일하게 작동한다.
1번 행 이전까지, 즉 0번 행만 대상으로 슬라이싱. 결과는 2차원 어레이.
arr_2D[:1]array([[1, 2, 3]])1번 행부터 3번 행 이전까지, 즉 1번 행과 2번 행을 대상으로 슬라이싱. 결과는 2차원 어레이.
arr_2D[1:3]array([[4, 5, 6],
[7, 8, 9]])전체 행 슬라이싱. 결과는 2차원 어레이.
arr_2D[:3]array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])다음 방식도 가능
arr_2D[:]array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])열 슬라이싱
열에 대해서만 슬라이싱을 적용하려면 전체 행을 대상으로 열 슬라이싱을 적용하면 된다.
2번 열 이전까지, 즉 0번 열과 1번 열 대상 슬라이싱. 결과는 2차원 어레이.
arr_2D[:, :2]array([[1, 2],
[4, 5],
[7, 8]])
행과 열 동시 슬라이싱
행과 열을 함께 슬라이싱하려면 행과 열에 대한 슬라이싱을 동시에 지정한다.
행 기준 2번 행 이전까지, 열 기준 1번 열부터 끝까지 슬라이싱. 결과는 2차원 어레이.
arr_2D[:2, 1:]array([[2, 3],
[5, 6]])
인덱싱과 슬라이싱 동시 적용
인덱싱과 슬라이싱이 행과 열 각각에 대해 독립적으로 사용될 수 있다.
행 기준 1번 행 인덱싱, 열 기준 2번 열 이전까지 슬라이싱. 결과는 1차원 어레이.
arr_2D[1, :2]array([4, 5])
행 기준 1번 행부터 2번행까지 슬라이싱, 열 기준 0번 열 인덱싱. 결과는 1차원 어레이.
arr_2D[1:3, 0]array([4, 7])주의사항:
인덱싱을 적용하는 축은 결과에서 사라지며, 따라서 인덱싱 결과는 기존 어레이보다 차원이 1 줄어든다. 따라서 1차원 어레이에 인덱싱을 적용한 결과는 스칼라이고, 2차원 어레이에 행 인덱싱 또는 열 인덱싱을 적용한 결과는 1차원 어레이다. 만약에 2차원 어레이에 행과 열 인덱싱을 동시에 적용하면 결과는 스칼라가 된다.
따라서 동일한 항목을 얻는 슬라이싱일지라도, 인덱싱을 사용할 때와 아닐 때의 결과물은 다른 모양이 된다. 예를 들어, 아래 두 코드는 동일한 항목을 포함한다. 하지만 인덱싱을 적용한 결과는 1차원 어레이인 반면에, 행과 열 모두 슬라이싱을 적용한 결과는 2차원 어레이다.
행 인덱스 적용
arr_2D[1, :2]array([4, 5])행과 열 슬라이싱 적용
arr_2D[1:2, :2]array([[4, 5]])행 인덱싱 적용 결과의 모양과 차원
print('모양:', arr_2D[1, :2].shape)
print('차원:', arr_2D[1, :2].ndim)모양: (2,)
차원: 1
행과 열 슬라이싱 적용 결과의 모양과 차원
print('모양:', arr_2D[1:2, :2].shape)
print('차원:', arr_2D[1:2, :2].ndim)모양: (1, 2)
차원: 2
15.3.4슬라이싱과 브로드캐스팅¶
브로드캐스팅으로 어레이의 항목을 대체할 수 있다. 단, 지정된 슬라이싱 영역의 모양과 지정된 값에 대해 브로드캐스팅 조건이 만족되어야 한다. 설명을 위해 아래 어레이를 사용한다.
arr7 = np.arange(0, 12).reshape((4, 3))
arr7array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])스칼라 지정
모든 항목을 5로 대체한다.
arr7[:] = 5
arr7array([[5, 5, 5],
[5, 5, 5],
[5, 5, 5],
[5, 5, 5]])열 지정
모든 열을 지정된 열로 대체한다.
new_column = np.arange(4).reshape((4, 1))
new_columnarray([[0],
[1],
[2],
[3]])arr7[:] = new_column
arr7array([[0, 0, 0],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])15.3.5연습문제¶
문제 1
아래 그림은 arr_5x5이 가리키는 2차원 어레이를 보여준다.
그림에 색깔별로 표시된 어레이를 슬라이싱을 이용하여 구해보자.

(1) 위 그림의 어레이를 가리키는 arr_5x5 변수를 선언하라. 단, 중첩 리스트를 활용한다.
답:
중첩 리스트를 이용하여 2차원 어레이를 정의한다.
arr_5x5 = np.array([[ 1, 2, 3, 4, 5],
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45]])(2) 어레이 0번 행에 보라색 상자로 표시된 1차원 어레이를 계산하는 슬라이싱
답:
0번 행의 2번 열부터 모든 항목을 대상으로 하는 1차원 어레이를 생성한다.
arr_5x5[0, 2:]array([3, 4, 5])(3) 1번 열 파랑색 상자로 표시된 2차원 어레이를 계산하는 슬라이싱
답:
1번 열에 위치한 항목들로 구성된 2차원 어레이를 생성하려면 모든 행에 대해 1번 열만 추출하되, 인덱싱이 아닌 슬라이싱을 이용해야 한다.
arr_5x5[:, 1:2]array([[ 2],
[12],
[22],
[32],
[42]])2번 열에 대해 인덱싱을 적용하면 다음과 같은 1차원 어레이가 된다.
arr_5x5[:, 1]array([ 2, 12, 22, 32, 42])(4) 2번 행과 4번행에서 주황색 상자 네 개로 감싸진 항목들로 구성된 2차원 어레이를 계산하는 슬라이싱
답:
2번 행부터 끝까지 스텝 2를 사용하고, 0번 열부터 3번 열 이전까지 역시 스텝 2를 사용하는 슬라이싱을 적용한다.
arr_5x5[2::2, 0:3:2]array([[21, 23],
[41, 43]])(5) 3번 행부터, 그리고 2번 열부터 회색 상자로 표시된 2차원 어레이를 계산하는 슬라이싱
답:
3번 행부터, 2번 열부터 끝까지의 행과 열을 대상으로 하는 슬라이싱을 적용한다.
arr_5x5[3:, 2:]array([[33, 34, 35],
[43, 44, 45]])문제 2
먼저 피어슨 아버지-아들 키 데이터셋을 2차원 어레이로 불러온다.
import numpy as np
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'
pearson = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1)(1) 이 데이터셋의 첫 번째 가족(0번 인덱스 행)의 아버지와 아들 키 데이터를 인덱싱하여 1차원 어레이로 출력하라.
답:
# 0번 행 인덱싱 (결과는 1차원 어레이)
first_family = pearson[0]
print("첫 번째 가족 데이터:", first_family)
print("차원:", first_family.ndim)첫 번째 가족 데이터: [165.1 151.9]
차원: 1
설명:
2차원 어레이에서 단일 행 인덱스([0])를 지정하면 해당 행의 데이터만 추출되어 차원이 1 줄어든 1차원 어레이가 반환된다.
(2) 처음 5개 가족(0번~4번 인덱스 행)의 데이터를 슬라이싱하여 2차원 어레이로 출력하라.
답:
# 0번부터 4번 행까지 슬라이싱 (결과는 2차원 어레이)
first_five_families = pearson[:5]
print("\n처음 5개 가족 데이터:\n", first_five_families)
print("차원:", first_five_families.ndim)
처음 5개 가족 데이터:
[[165.1 151.9]
[160.8 160.5]
[165.1 160.8]
[167.1 159.5]
[155.2 163.3]]
차원: 2
설명:
콜론(:)을 사용한 슬라이싱([:5])을 적용하면 지정된 범위의 행들이 추출되며 원래의 2차원 구조가 그대로 유지된다.
(3) 모든 아버지의 키 데이터(0번 열)만 인덱싱하여 1차원 어레이로 추출하고, 첫 5개 항목을 출력하라.
답:
# 0번 열 인덱싱 (결과는 1차원 어레이)
fathers_1d = pearson[:, 0]
print("아버지 키 (1차원 어레이) 첫 5개:", fathers_1d[:5])
print("차원:", fathers_1d.ndim)아버지 키 (1차원 어레이) 첫 5개: [165.1 160.8 165.1 167.1 155.2]
차원: 1
설명:
열을 추출할 때 쉼표(,) 앞에는 전체 행을 의미하는 :을 지정한다.
(4) 모든 아버지의 키 데이터(0번 열)를 슬라이싱을 이용하여 2차원 어레이 형태(열 벡터 모양)로 추출하고, 첫 5개 행을 출력하라.
답:
# 0번 열 슬라이싱 (결과는 2차원 어레이)
fathers_2d = pearson[:, 0:1]
print("\n아버지 키 (2차원 어레이) 첫 5개:\n", fathers_2d[:5])
print("차원:", fathers_2d.ndim)
아버지 키 (2차원 어레이) 첫 5개:
[[165.1]
[160.8]
[165.1]
[167.1]
[155.2]]
차원: 2
설명:
쉼표 뒤에 단일 인덱스 0을 지정하면 차원이 축소되어 1차원 어레이가 되지만, 슬라이싱 0:1을 지정하면 차원이 유지되어 (1078, 1) 모양의 2차원 어레이가 반환된다.
(5) 100번째 가족(인덱스 99)의 아들 키(인덱스 1 열) 값을 인덱싱하여 스칼라 값으로 출력하라.
답:
# 행과 열 동시 인덱싱 (결과는 스칼라)
son_100th = pearson[99, 1]
print("100번째 가족의 아들 키:", son_100th)
print("자료형:", type(son_100th))100번째 가족의 아들 키: 173.0
자료형: <class 'numpy.float64'>
설명:
2차원 어레이에서 행과 열 모두에 단일 인덱스([99, 1])를 지정하면 해당 좌표의 단일 값(스칼라)이 추출된다.
(6) 10번째부터 14번째 가족(인덱스 9~13)의 아들 키 데이터만 추출하되, 2차원 어레이 형태가 유지되도록 슬라이싱하여 출력하라.
답:
# 행과 열 동시 슬라이싱 (결과는 2차원 어레이)
sons_subset_2d = pearson[9:14, 1:2]
print("\n10~14번째 가족의 아들 키 (2차원):\n", sons_subset_2d)
print("차원:", sons_subset_2d.ndim)
10~14번째 가족의 아들 키 (2차원):
[[162.6]
[165.6]
[166.1]
[166.9]
[166.1]]
차원: 2
설명:
행과 열 모두에 슬라이싱([9:14, 1:2])을 적용하면 지정된 부분 행렬이 추출되며 원래의 2차원 구조가 그대로 유지된다.
문제 3
피어슨 데이터셋(pearson)의 단위는 센티미터(cm)로 되어 있다. 단위를 인치(inch)로 변환하기 위해 전체 데이터에 를 곱한 후, 소수점 첫째 자리까지만 남기려고 한다. 또한, 데이터 수집 과정의 오류로 인해 처음 5개 가족(인덱스 0~4)의 기록에 문제가 있어 모두 0으로 초기화해야 하는 상황이라고 가정한다.
(1) 모든 키 데이터를 인치 단위로 변환하여 새로운 어레이 pearson_inch에 저장하고, 이 어레이의 모든 값을 np.round() 함수를 이용해 소수점 첫째 자리까지 반올림하라.
답:
# 센티미터를 인치로 변환 (브로드캐스팅 적용)
pearson_inch = pearson / 2.54
# 소수점 첫째 자리까지 반올림
pearson_inch = np.round(pearson_inch, 1)
# 처음 5행의 결과 확인
print("단위 변환 및 반올림 결과 (처음 5행):\n", pearson_inch[:5])단위 변환 및 반올림 결과 (처음 5행):
[[65. 59.8]
[63.3 63.2]
[65. 63.3]
[65.8 62.8]
[61.1 64.3]]
설명:
어레이를 2.54로 나누면 브로드캐스팅이 작동하여 모든 항목이 동시에 계산된다.
이후 np.round(어레이, 1)을 통해 모든 요소를 소수점 1자리까지 쉽게
계산할 수 있다.
np.round() 함수는 다른 어레이 연산자처럼 항목별로 작동한다.
즉, 어레이에 포함된 각각의 항목에 대해 round() 함수가 적용된다.
(2) pearson_inch 어레이에서 처음 5개 가족(행 인덱스 0부터 4까지)의 데이터를 모두 0으로 대체(수정)하는 코드를 작성하라. 그 후, 수정된 pearson_inch의 처음 7개 행을 출력하여 값이 제대로 대체되었는지 확인하라.
답:
# 처음 5개 행의 모든 열에 대해 0 할당 (항목 대체 및 브로드캐스팅)
pearson_inch[:5, :] = 0
# 수정 결과 확인
print("수정된 데이터 (처음 7행):\n", pearson_inch[:7])수정된 데이터 (처음 7행):
[[ 0. 0. ]
[ 0. 0. ]
[ 0. 0. ]
[ 0. 0. ]
[ 0. 0. ]
[63. 64.2]
[65.4 64.1]]
설명:
슬라이싱을 통해 대체할 영역([:5, :])을 지정한 뒤 단일 숫자 0을 할당하면 브로드캐스팅에 의해 지정된 5개 행과 2개 열의 총 10개 항목이 모두 일괄적으로 0으로 바뀐다.
15.4부울 인덱싱¶
부울 인덱싱boolean indexing은
True/False로 구성된 부울 어레이를 인덱스로 사용하여 조건에 맞는 항목만 선택하거나 수정하는 기법으로, 일반 인덱싱/슬라이싱으로는 처리하기 어려운 조건부 추출이 가능하다.
15.4.1부울 마스크¶
부울 마스크Boolearn mask는 부울 어레이를 인덱싱에
활용할 때 부르는 이름이다.
부울 마스크의 활용법을 보여주기 위해 아래 (7, 5) 모양의 2차원 어레이를 사용한다.
data = np.arange(-50, 53, 3).reshape((7, 5))
dataarray([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[-20, -17, -14, -11, -8],
[ -5, -2, 1, 4, 7],
[ 10, 13, 16, 19, 22],
[ 25, 28, 31, 34, 37],
[ 40, 43, 46, 49, 52]])행 마스크 적용
7개의 행 중에서 첫째 항목이 4의 배수인 행만 추출하고자 할 때 다음과 같이 먼저 부울 마스크를 정의한다.
mask4 = data[:, 0] % 4 == 0mask4는 0번 열을 대상으로 4로 나눈 나머지를 계산한 다음에 나머지가 0인 경우에만 참으로 계산된다.
즉, 4의 배수로 시작하는 행을 추려낼 수 있는 정보를 갖고 있다.
따라서 mask4를 data 2차원 어레이에 인덱싱 형식으로 적용하면
True가 위치한 인덱스에 해당하는 행인 2번과 6번 행만 추출해서
새로운 2차원 어레이를 생성한다.
data[mask4]array([[-20, -17, -14, -11, -8],
[ 40, 43, 46, 49, 52]])열 마스크 적용
열에 대해 마스크를 적용하려면 열 길이에 맞는 부울 마스크를 먼저 지정해야 한다. 아래 코드는 3번 인덱스 행을 기준으로 항목이 양수인 열인 경우만 참으로 처리한다.
mask_column = data[3, :] > 0
mask_columnarray([False, False, True, True, True])mask_column 마스크를 이용하여 참인 열만 추출하려면
다음과 같이 모든 행에 대해 해당 열만 추출하라고 지정하면 된다.
data[:, mask_column]array([[-44, -41, -38],
[-29, -26, -23],
[-14, -11, -8],
[ 1, 4, 7],
[ 16, 19, 22],
[ 31, 34, 37],
[ 46, 49, 52]])부울 인덱싱과 일반 인덱싱/슬라이싱 혼합
부울 인덱싱과 정수를 이용한 일반 인덱싱을 임의로 조합해서 활용할 수 있다.
예를 들어 아래 코드는 mask4에 의해 선택된 행에서 3번 인덱스 열만 추출해서
1차원 어레이로 반환한다.
즉, 4의 배수로 시작하는 모든 행에서 3번 인덱스 열에 위치한 값들로 구성된
1차원 어레이가 생성된다.
data[mask4, 3]array([-11, 49])반면에 아래 코드는 0번과 1번 행에 대해 mask_column을 적용시킨 결과를 생성한다.
data[:2, mask_column]array([[-44, -41, -38],
[-29, -26, -23]])15.4.2부울 마스크 논리 연산¶
부울 마스크는 부울 어레이이기에 논리 연산자(~, &, |)를 적용하여
새로운 보다 다양한 기능의 부울 마스크를 생성할 수 있다.
예를 들어 아래 코드는 4의 배수로 시작하지 않는 행만 추출한다.
mask_not4 = ~mask4
data[mask_not4]array([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[ -5, -2, 1, 4, 7],
[ 10, 13, 16, 19, 22],
[ 25, 28, 31, 34, 37]])아래 코드는 4의 배수로 시작하면서 마지막 항목이 50보다 큰 정수인 행을 추출한다.
mask4and50 = mask4 & (data[:, -1] > 50)
data[mask4and50]array([[40, 43, 46, 49, 52]])다음은 4의 배수로 시작하지 않거나 마지막 항목이 50보다 큰 정수인 행을 추출한다.
mask4or50 = ~mask4 | (data[:, -1] > 50)
data[mask4or50]array([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[ -5, -2, 1, 4, 7],
[ 10, 13, 16, 19, 22],
[ 25, 28, 31, 34, 37],
[ 40, 43, 46, 49, 52]])15.4.3항목 업데이트¶
마스크를 이용하여 일부 행 또는 열을 특정 값으로 채울 수 있다. 아래 코드는 짝수로 시작하는 행을 0으로 채운다.
data = np.arange(-50, 53, 3).reshape((7, 5))
mask_even = data[:, 0] % 2 == 0
data[mask_even] = 0
dataarray([[ 0, 0, 0, 0, 0],
[-35, -32, -29, -26, -23],
[ 0, 0, 0, 0, 0],
[ -5, -2, 1, 4, 7],
[ 0, 0, 0, 0, 0],
[ 25, 28, 31, 34, 37],
[ 0, 0, 0, 0, 0]])아래 코드는 홀수로 시작하는 행을 [1, 2, 3, 4, 5]로 대체한다.
data = np.arange(-50, 53, 3).reshape((7, 5))
mask_odd = data[:, 0] % 2 == 1
data[mask_odd] = [1, 2, 3, 4, 5]
dataarray([[-50, -47, -44, -41, -38],
[ 1, 2, 3, 4, 5],
[-20, -17, -14, -11, -8],
[ 1, 2, 3, 4, 5],
[ 10, 13, 16, 19, 22],
[ 1, 2, 3, 4, 5],
[ 40, 43, 46, 49, 52]])15.4.42차원 마스크¶
data가 가리키는 2차원 어레이에서 홀수 항목만 추출해서 1차원 어레이를 생성해보자.
이를 위해 먼저 어레이의 각 항목이 홀수인지 여부를 확인하는 부울 마스크를 다음과 같이 생성한다.
data = np.arange(-50, 53, 3).reshape((7, 5))
mask_odd_all = data % 2 == 1
mask_odd_allarray([[False, True, False, True, False],
[ True, False, True, False, True],
[False, True, False, True, False],
[ True, False, True, False, True],
[False, True, False, True, False],
[ True, False, True, False, True],
[False, True, False, True, False]])위 마스크를 data에 인덱싱으로 적용하면 홀수 항목만 끄집어 낸 1차원 어레이가 생성된다.
data[mask_odd_all]array([-47, -41, -35, -29, -23, -17, -11, -5, 1, 7, 13, 19, 25,
31, 37, 43, 49])또한 마스크를 이용하여 모든 홀수 항목을 0으로 변경할 수도 있다.
data = np.arange(2, 105, 3).reshape((7, 5))
data[mask_odd_all] = 0
dataarray([[ 2, 0, 8, 0, 14],
[ 0, 20, 0, 26, 0],
[ 32, 0, 38, 0, 44],
[ 0, 50, 0, 56, 0],
[ 62, 0, 68, 0, 74],
[ 0, 80, 0, 86, 0],
[ 92, 0, 98, 0, 104]])15.4.5연습문제¶
문제 1
10부터 49까지의 연속된 정수로 구성된 (8, 5) 모양의 2차원 어레이를 생성하라.
이후 부울 마스크 논리 연산을 활용하여 해당 어레이에서 값이 35 이상이면서 동시에 짝수인 항목만을 추출해 1차원 어레이를 생성하는 코드를 작성하라.
답:
import numpy as np
arr1 = np.arange(10, 50).reshape((8, 5))
mask1 = (arr1 >= 35) & (arr1 % 2 == 0)
arr1[mask1]array([36, 38, 40, 42, 44, 46, 48])설명:
아래 순서대로 진행한다.
35 이상인 값 대상 마스크 지정:
arr1 >= 35짝수 대상 마스크 지정:
arr1 % 2 == 0논리곱 연산자
&활용후 행에 대해 부울 인덱식 적용하면 조건이True인 항목만 모인 1차원 어레이 반환됨
문제 2
1부터 24까지의 연속된 정수로 구성된 (4, 6) 모양의 2차원 어레이를 생성하라.
0번 행의 값이 3의 배수이거나 마지막 행의 값이 22를 초과하는 열들만 추출하여 반환하는 코드를 작성하라.
답:
arr2 = np.arange(1, 25).reshape((4, 6))
mask2 = (arr2[0, :] % 3 == 0) | (arr2[-1, :] > 22)
arr2[:, mask2]array([[ 3, 5, 6],
[ 9, 11, 12],
[15, 17, 18],
[21, 23, 24]])설명:
아래 순서대로 진행한다.
0번 행 대상 마스크 지정:
arr2[0, :] % 3 == 0)마지막 행 대상 마스크 지정:
arr2[-1, :] > 22논리합 연산자
|활용 후 열에 대해 부울 인덱싱 적용하면 2차원 어레이 생성됨
문제 3
0부터 29까지의 정수를 담은 (6, 5) 모양의 2차원 어레이를 생성하라.
각 행의 첫 번째 항목(0번 열)이 짝수인지 확인하는 부울 마스크를 생성하고, 이를 이용해 짝수로 시작하는 행의 모든 값을 [-1, -2, -3, -4, -5]로 한 번에 변경한 뒤 어레이를 출력하는 코드를 작성하라.
답:
arr3 = np.arange(30).reshape((6, 5))
mask3 = arr3[:, 0] % 2 == 0
arr3[mask3] = [-1, -2, -3, -4, -5]
arr3array([[-1, -2, -3, -4, -5],
[ 5, 6, 7, 8, 9],
[-1, -2, -3, -4, -5],
[15, 16, 17, 18, 19],
[-1, -2, -3, -4, -5],
[25, 26, 27, 28, 29]])설명:
arr3[:, 0] % 2 == 0으로 첫 번째 열이 짝수인 행들을 찾아내는 1차원 마스크를 만든다. 이를 어레이의 인덱스에 넣고 값을 할당하면(arr3[mask3] = [...]), 리스트의 값이 해당 행들의 모양에 맞춰 브로드캐스팅되어 지정된 행이 전부 새로운 값으로 덮어쓰여진다.
문제 4
-20부터 19까지의 정수로 구성된 (5, 8) 모양의 2차원 어레이를 생성하라.
어레이의 값이 음수인 경우 그 값을 0으로 일괄 변경하고 수정된 어레이를 출력하는 코드를 작성하라.
답:
arr4 = np.arange(-20, 20).reshape((5, 8))
mask4 = arr4 < 0
arr4[mask4] = 0
arr4array([[ 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 1, 2, 3],
[ 4, 5, 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17, 18, 19]])설명:
arr4 < 0을 실행하면 다차원 어레이의 각각의 값에 대해 음수 여부를 판별하여, 기존 어레이와 모양이 완벽히 동일한 2차원 부울 마스크를 생성한다.
그리고 이 마스크를 활용해 arr4[mask4] = 0을 실행하면 2차원 구조를 유지한 채로 마스크가 True인 위치의 값들만 0으로 일괄 업데이트됩니다.
문제 5
pearson_dataset.csv 파일로부터 아버지의 키(0번 열)와 아들의 키(1번 열) 데이터를 불러와 2차원 어레이 pearson_data에 저장하라.
이후 부울 마스크를 활용하여 아버지의 키가 185 센티미터 이상이면서, 아들의 키가 190 센티미터 이상인 데이터(행)만 추출하여 새로운 어레이로 반환하고, 이 조건에 해당하는 데이터가 몇 개(행 기준)인지 출력하는 코드를 작성하라.
답:
# 데이터 불러오기 (헤더 제외)
pearson_data = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1, usecols=(0, 1))
# 아버지 키 >= 185 & 아들 키 >= 190 인 마스크 생성
mask5 = (pearson_data[:, 0] >= 185) & (pearson_data[:, 1] >= 190)
# 마스크를 적용해 조건에 맞는 행만 추출
filtered_data = pearson_data[mask5]
print("조건(아버지 185 이상 & 아들 190 이상)을 만족하는 데이터:\n")
print(filtered_data)
print("\n해당 데이터 개수:", filtered_data.shape[0])조건(아버지 185 이상 & 아들 190 이상)을 만족하는 데이터:
[[186.4 191.3]
[186.7 193.3]
[185.7 192. ]]
해당 데이터 개수: 3
설명:
loadtxt() 함수를 이용해 필요한 데이터를 2차원 어레이로 불러온다.
그 후 [:, 0] 인덱싱으로 아버지 키 열을, [:, 1] 인덱싱으로 아들 키 열을 선택하여 각각의 조건을 논리곱 연산자 (&)로 연결한다.
이렇게 생성된 1차원 부울 마스크를 행 단위로 인덱싱하면 조건에 부합하는 모든 열을 포함한 2차원 어레이 형태의 뷰가 반환됩니다.
배열의 크기는 .shape 속성을 활용해 확인할 수 있습니다.
문제 6
pearson_data 어레이에서 아들의 키 데이터(전체 행, 1번 열) 중, 아들 키의 평균값보다 작은 항목을 찾아 모두 일괄적으로 평균값으로 덮어쓰는(변경하는) 코드를 작성하라.
데이터를 수정한 후, 변경된 데이터가 반영된 pearson_data의 처음 10개 행을 출력하라.
답:
# 아들 키의 평균값 계산
son_height_mean = pearson_data[:, 1].mean()
# 아들의 키가 아들 키의 평균보다 작은지 판별하는 부울 마스크 생성
mask6 = pearson_data[:, 1] < son_height_mean
# 마스크가 True인 아들의 키 항목을 평균값으로 대체 (0번 열인 아버지 키는 건드리지 않음)
pearson_data[mask6, 1] = son_height_mean
# 변경 결과 확인 (처음 10개 행)
pearson_data[:10]array([[165.1 , 174.45797774],
[160.8 , 174.45797774],
[165.1 , 174.45797774],
[167.1 , 174.45797774],
[155.2 , 174.45797774],
[160. , 174.45797774],
[166.1 , 174.45797774],
[164.3 , 174.45797774],
[167.9 , 174.45797774],
[170.2 , 174.45797774]])설명:
어레이의 1번 인덱스 열([:, 1])에 대해 평균값을 구한 다음 비교 연산을 수행해 그 열의 길이와 일치하는 1차원 부울 마스크를 만든다.
값을 업데이트할 때에는 행의 위치 속성엔 부울 마스크를 위치시키고, 열의 속성엔 대상 열이었던 1 인덱스를 지정하여 대입하면 특정 열의 조건에 부합하는 항목만 선택적으로 변경할 수 있다.
15.5뷰와 copy() 메서드¶
기존 어레이의 데이터를 복사하지 않고 동일한 메모리를 공유하여 새로운 어레이인 것처럼 보여주는 객체를 뷰View라 부른다.
넘파이와 다음 장에서 다룰 판다스의 많은 도구가 뷰를 활용한다.
뷰는 메모리를 효율적으로 활용하도록 고안되었지만, 뷰를 수정하면 원본 어레이도 함께 수정되어 혼란을 야기할 수 있다.
따라서 독립적인 데이터가 필요한 경우에는 어레이의 copy() 메서드를 적절하게 활용해야 한다.
여기서는 어레이 인덱싱과 슬라이싱이 새로운 어레이를 생성하는 게 아니라 기존 어레이에 대한 뷰를 생성한다는 점과, copy() 메서드의 활용법을 간단한 사례를 통해 살펴본다.
15.5.1인덱싱의 뷰 기능¶
넘파이 어레이의 인덱싱은 리스트 인덱싱과 조금 다르게 작동하기도 한다. 예를 들어 2차원 어레이에 대해 행 또는 열 하나의 축에 대해서만 정수 인덱싱을 실행하면 지정된 인덱스 위치에 해당하는 1차원 어레이를 복사하여 독립된 새로운 어레이 객체를 생성하는 대신 원본 데이터의 메모리를 그대로 공유하면서 항목의 정보만 활용한다.
예를 들어, 아래 코드에서 arr_5x5_indexing의 항목을 변경하면 변경된 항목에 대응하는 기존 arr_5x5의 항목도 함께 달라진다.
즉, 인덱싱 결과가 새로운 어레이를 생성하는 것이 아니라 기존 어레이의 행과 열 인덱스 정보만 활용해서
마치 새로운 어레이를 생성하는 것처럼 보이게 할 뿐이다.
arr_5x5 = np.array([[ 1, 2, 3, 4, 5],
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45]])arr_5x52차원 어레이의 1번 행 인덱싱. 결과는 (5,) 모양의 1차원 어레이
arr_5x5_indexing = arr_5x5[1]
arr_5x5_indexingarray([11, 12, 13, 14, 15])arr_5x5_indexing1차원 어레이의 0번 인덱스의 항목을 11에서 999로 대체.
arr_5x5_indexing[0] = 999
arr_5x5_indexingarray([999, 12, 13, 14, 15])기존
arr_5x52차원 어레이의 1번 행, 0번 열의 값이 999로 대체되었음을 확인.
arr_5x5array([[ 1, 2, 3, 4, 5],
[999, 12, 13, 14, 15],
[ 21, 22, 23, 24, 25],
[ 31, 32, 33, 34, 35],
[ 41, 42, 43, 44, 45]])15.5.2슬라이싱의 뷰 기능¶
아래 코드에서 arr_5x5_slicing의 항목을 변경하면 변경된 항목에 대응하는 기존 arr_5x5의 항목도 함께 달라진다.
즉, 슬라이싱 또한 새로운 어레이를 생성하는 것이 아니라 기존 어레이의 행과 열 인덱스 정보만 활용해서
마치 새로운 어레이를 생성하는 것처럼 보이게 할 뿐이다.
arr_5x52차원 어레이에 대한 행과 열 모두 1번부터 3번까지만 슬라이싱 적용. 결과는 (3, 3) 모양의 2차원 어레이
arr_5x5_slicing = arr_5x5[1:4, 1:4]
arr_5x5_slicingarray([[12, 13, 14],
[22, 23, 24],
[32, 33, 34]])슬라이싱으로 생성된 2차원 어레이의 0번 행, 1번 열의 항목을 13에서 3450으로 대체.
arr_5x5_slicing[0, 1] = 3450
arr_5x5_slicingarray([[ 12, 3450, 14],
[ 22, 23, 24],
[ 32, 33, 34]])기존
arr_5x5어레이의 1번 행, 2번 열의 항목이 13에서 3450으로 대체되었음 확인.
arr_5x5array([[ 1, 2, 3, 4, 5],
[ 999, 12, 3450, 14, 15],
[ 21, 22, 23, 24, 25],
[ 31, 32, 33, 34, 35],
[ 41, 42, 43, 44, 45]])15.5.3copy() 메서드¶
인덱싱과 슬라이싱 결과가 기존 어레이와 독립된 새롭게 생성된 어레이가 되도록 하려면 copy() 메서드로 사본을 만들어 활용해야 한다.
예를 들어, 아래 코드는 인덱싱 결과의 사본을 생성하면 기존 어레이와 독립된 별도의 어레이로 지정됨을 보여준다.
copy() 메서드의 활용법을 설명하기 위해 먼저 arr_5x5 어레이를 초기화한다.
arr_5x5 = np.array([[ 1, 2, 3, 4, 5],
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45]])인덱싱 결과에 copy() 메서드를 적용해서 독립된 객체를 생성한다.
arr_5x5_indexing_copy = arr_5x5[2].copy()
arr_5x5_indexing_copyarray([21, 22, 23, 24, 25])arr_5x5_indexing_copy를 변경해도 arr_5x5은 영향받지 않는다.
arr_5x5_indexing_copy[1] = 999
arr_5x5_indexing_copyarray([ 21, 999, 23, 24, 25])arr_5x5array([[ 1, 2, 3, 4, 5],
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45]])아래 코드는 슬라이싱의 사본도 기존 어레이와 독립된 어레이 객체로 생성됨을 확인해준다.
arr_5x5_slicing_copy = arr_5x5[1:4, 1:4].copy()
arr_5x5_slicing_copy[0, 1] = 3450
arr_5x5array([[ 1, 2, 3, 4, 5],
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45]])15.5.4부울 인덱싱과 뷰¶
부울 인덱싱은 뷰를 이용하지 않고 항상 새로운 어레이를 생성한다.
data = np.arange(-50, 53, 3).reshape((7, 5))
dataarray([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[-20, -17, -14, -11, -8],
[ -5, -2, 1, 4, 7],
[ 10, 13, 16, 19, 22],
[ 25, 28, 31, 34, 37],
[ 40, 43, 46, 49, 52]])mask = data[:, 0] < 0
data2 = data[mask]
data2array([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[-20, -17, -14, -11, -8],
[ -5, -2, 1, 4, 7]])data2의 0번 행을 모두 -1로 변경해도 data는 변하지 않는다.
data2[0] = -1
data2array([[ -1, -1, -1, -1, -1],
[-35, -32, -29, -26, -23],
[-20, -17, -14, -11, -8],
[ -5, -2, 1, 4, 7]])하지만 data는 변경되지 않았다.
dataarray([[-50, -47, -44, -41, -38],
[-35, -32, -29, -26, -23],
[-20, -17, -14, -11, -8],
[ -5, -2, 1, 4, 7],
[ 10, 13, 16, 19, 22],
[ 25, 28, 31, 34, 37],
[ 40, 43, 46, 49, 52]])15.5.5연습 문제¶
피어슨 아버지-아들 키 데이터셋을 2차원 어레이로 불러온다.
import numpy as np
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'
pearson = np.loadtxt(data_url+"pearson_dataset.csv", delimiter=',', skiprows=1)문제 1
data_url 어레이에서 처음 5개 가족(0번~4번 행)의 데이터를 슬라이싱하여 first_five라는 변수에 할당하라.
그 후 first_five 어레이의 0번 행, 1번 열(첫 번째 가족의 아들 키) 값을 999.0으로 변경하라.
마지막으로 원본 어레이 pearson_data의 첫 번째 가족 데이터를 출력하여 원본 데이터가 어떻게 변했는지 확인하고 그 이유를 설명하라.
답:
import numpy as np
# data_url은 본문에서 정의된 변수를 사용한다고 가정
# 2차원 어레이로 데이터셋 불러오기
pearson = np.loadtxt(data_url + "pearson_dataset.csv", delimiter=',', skiprows=1)
# 처음 5개 행 슬라이싱 (뷰 생성)
first_five = pearson[:5]
# 슬라이싱된 어레이의 값 변경
first_five[0, 1] = 999.0
# 원본 어레이 확인
print("원본 어레이의 첫 번째 가족 데이터:", pearson[0])원본 어레이의 첫 번째 가족 데이터: [165.1 999. ]
설명:
넘파이 어레이의 슬라이싱은 새로운 어레이를 메모리에 생성하는 것이 아니라,
원본 어레이의 특정 부분을 가리키는 뷰(View)를 반환한다.
따라서 뷰(first_five)의 값을 변경하면, 메모리를 공유하고 있는 원본 어레이(pearson)의 해당 위치 값도 함께 999.0으로 변경된다.
문제 2
처음 5개 가족의 데이터를 슬라이싱한 후, copy() 메서드를 사용하여 독립적인 사본을 만들고 first_five_copy 변수에 할당하라.
first_five_copy의 0번 행, 1번 열 값을 888.0으로 변경한 후, 원본 어레이 pearson의 첫 번째 가족 데이터를 출력하여 원본이 유지되는지 확인하라.
답:
import numpy as np
# copy() 메서드를 사용하여 독립적인 사본 생성
first_five_copy = pearson[:5].copy()
# 사본 어레이의 값 변경
first_five_copy[0, 1] = 888.0
# 원본 어레이 확인
print("사본 어레이의 첫 번째 가족 데이터:", first_five_copy[0])
print("원본 어레이의 첫 번째 가족 데이터:", pearson[0])사본 어레이의 첫 번째 가족 데이터: [165.1 888. ]
원본 어레이의 첫 번째 가족 데이터: [165.1 999. ]
설명:
슬라이싱 결과에 copy() 메서드를 적용하면 원본 어레이와 메모리를 공유하지 않는 완전히 독립적인 새로운 어레이 객체가 생성된다.
따라서 사본(first_five_copy)의 값을 변경하더라도 원본 어레이(pearson)의 데이터는 전혀 영향을 받지 않고 원래 값을 유지한다.
문제 3
피어슨 데이터셋에서 아버지의 키(fathers) 데이터만 1차원 어레이로 불러오라.
이 어레이에서 10번부터 19번 인덱스까지의 데이터를 슬라이싱하여 fathers_subset에 할당하라.
fathers_subset의 모든 항목을 0.0으로 일괄 변경한 후, 원본 fathers 어레이의 10번부터 19번 인덱스 항목들을 출력하여 결과를 확인하라.
답:
import numpy as np
# 10~19번 인덱스 슬라이싱 (뷰 생성)
fathers_subset = fathers[10:20]
# 뷰의 모든 항목을 0.0으로 변경 (스칼라 대입)
fathers_subset[:] = 0.0
# 원본 어레이 확인
print("원본 어레이의 10~19번 인덱스 데이터:\n", fathers[10:20])원본 어레이의 10~19번 인덱스 데이터:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
설명:
1차원 어레이의 슬라이싱 역시 뷰(View)를 반환한다.
fathers_subset[:] = 0.0과 같이 뷰의 전체 항목에 스칼라 값을 대입하면, 원본 어레이(fathers)에서 해당 슬라이싱 범위에 속하는 모든 항목의 값이 0.0으로 일괄 변경된다.
문제 4
아들의 키 데이터(1번 열)만 추출하여 별도의 분석을 진행하려 한다.
원본 데이터를 훼손하지 않기 위해, 1번 열 전체를 슬라이싱한 후 copy()를 사용하여 sons_safe라는 독립적인 1차원 어레이를 생성하라.
sons_safe의 첫 번째 항목을 100.0으로 변경하고, 원본 pearson의 첫 번째 행 데이터를 출력하여 원본이 보호되었는지 확인하라.
답:
import numpy as np
# 1번 열(아들 키) 슬라이싱 후 사본 생성
sons_safe = pearson[:, 1].copy()
# 사본의 첫 번째 항목 변경
sons_safe[0] = 100.0
# 원본 어레이 확인
print("사본 어레이의 첫 번째 항목:", sons_safe[0])
print("원본 어레이의 첫 번째 행 데이터:", pearson[0])사본 어레이의 첫 번째 항목: 100.0
원본 어레이의 첫 번째 행 데이터: [165.1 999. ]
설명:
2차원 어레이에서 특정 열을 슬라이싱([:, 1])할 때도 뷰가 반환되므로, 추출한 열 데이터를 수정하면 원본 2차원 어레이의 해당 열 데이터도 변경된다.
이를 방지하기 위해 .copy()를 호출하여 독립적인 1차원 어레이 사본을 만들면, 사본을 자유롭게 수정해도 원본 데이터(pearson_data)는 안전하게 보호된다.