16. 기댓값과 분산#
기본 설정
numpy와 pandas 라이브러리를 각각 np와 pd로 불러온다.
import numpy as np
import pandas as pd
데이터프레임의 chained indexing을 금지시키기 위한 설정을 지정한다. Pandas 3.0 버전부터는 기본 옵션으로 지정된다.
pd.options.mode.copy_on_write = True
주피터 노트북에서 부동소수점의 출력을 소수점 이하 6자리로 제한한다. 아래 코드는 주피터 노트북에서만 사용하며 일반적인 파이썬 코드가 아니다.
%precision 6
'%.6f'
아래 코드는 데이터프레임 내에서 부동소수점의 출력을 소수점 이하 6자리로 제한한다.
pd.set_option('display.precision', 6)
데이터 시각화를 위해 matplotlib.pyplot를 plt로,
seaborn을 sns로 불러온다.
seaborn 라이브러리는 통계 관련 데이터의 정보를 보다 세련되고 정확하게 전달하는 그래프를 그리는 도구를 제공한다.
matplotlib 라이브러리를 바탕으로 만들어져서 함께 사용해도 된다.
import matplotlib.pyplot as plt
import seaborn as sns
그래프 스타일을 seaborn에서 제공하는 white 스타일로 지정한다.
sns.set_style("white")
데이터 저장소 디렉토리
코드에 사용되는 데이터 저장소의 기본 디렉토리를 지정한다.
data_url = 'https://raw.githubusercontent.com/codingalzi/statsRev/refs/heads/master/data/'
주요 내용
확률변수가 취할 수 있는 값들의 평균값인 기댓값과 분산을 소개한다.
확률변수의 기댓값
확률변수의 분산
16.1. 이산확률변수의 기댓값과 분산#
16.1.1. 기댓값과 평균값#
데이터셋의 중심역할을 하는 대표하는 값으로 7장에서 소개된 평균값은 확률분포를 고려하지 않고 단순하게 주어진 값들만 이용하여 정의된다.
평균값
평균값은 데이터를 모두 더한 다음 데이터의 개수로 나눈다.
예를 들어 1부터 6까지의 정수로 구성된 데이터셋의 평균값은 1부터 6까지 더한 값인 21을 6으로 나눈 3.5다.
sum(range(1, 7)) / 6
3.500000
공정한 주사위 던지기의 기댓값
데이터셋을 확률변수가 취할 수 있는 값들의 집합으로 볼 때는 확률분포를, 즉 각각의 값이 발생할 확률을 함께 고려하면서 데이터들의 중심을 정의해야 한다.
예를 들어 주사위를 던졌을 때 나오는 값들의 평균값을 계산해보자. 주사위를 던지면 1부터 6 사이의 정수 하나가 나오기에 나온 값들의 평균값이 1부터 6까지의 정수의 평균값인 3.5가 값이 나올 것으로 기대한다. 아래 코드는 주사위 던지기를 반복해서 던지면 나온 값들의 평균값이 실제로 3.5에 수렴함을 보여준다.
코드는 아래 내용을 구현한다.
np.random.choice()함수를 이용한 주사위 총 10만 번 던지기 구현100번씩 끊어서 그때까지 나온 값들을 대상으로 누적 평균값 계산
np.random.seed(100)
fig = plt.figure(figsize=(6,4 ))
ax = fig.add_subplot(111)
# 총 10만번 주사위 던지기
size = 100_001
cubic100k = np.random.choice(range(1, 7), size)
# 100번 던질 때마다 누적 평균값 계산
cubic_means = [cubic100k[:step].mean() for step in range(100, size, 100)]
plt.plot(range(100, size, 100), cubic_means)
# 평균값들의 기댓값
mu_fair = 3.5
plt.hlines(mu_fair, 100, size, color='red')
plt.show()
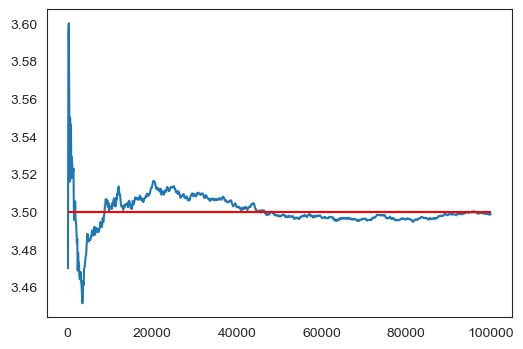
위 결과만 보면 확률분포를 고려할 때와 그렇지 않을 때의 결과가 동일해 보인다.
하지만 이는 정상적인 주사위를 사용한다는 전제가 있었기에 가능했다.
실제로 np.random.choice() 함수를 이용하여 1부터 6 사이의 정수를
다음과 같은 균등분포에 따라 임의로 선택하였다.
X |
1 |
2 |
3 |
4 |
5 |
6 |
|---|---|---|---|---|---|---|
확률 |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
불공정한 주사위 던지기의 기댓값
불공정한 주사위를 사용하는 경우에는 실행 결과의 평균값이 다르게 나올 수 있다. 예를 들어 다음과 같이 높은 숫자일 수록 나올 확률이 높아진다고 가정하자.
X |
1 |
2 |
3 |
4 |
5 |
6 |
|---|---|---|---|---|---|---|
확률 |
1/21 |
2/21 |
3/21 |
4/21 |
5/21 |
6/21 |
아래 코드는 불공정한 주사위를 던졌을 때 나오는 값을 가리키는 확률변수 \(X\)의 확률질량함수와 확률분포를 정의한다.
불공정한 주사위 던지기의 확률질량함수
def f_unfair(x):
return x/21
불공정한 주사위 던지기의 확률분포 지정
prob_X = [f_unfair(x) for x in range(1, 7)]
아래 코드는 위 확률분포를 이용하여 동일한 모의실험을 진행한다.
np.random.choice() 함수를 호출할 때 p=prob_X 키워드 인자를 지정하면
언급된 확률분포를 따르면서 1부터 6 사이의 정수를 10만 개 선택한다.
생성된 그래프에서 빨간 직선은 불공정한 주사위를 반복해서 던질 때 나온 값들의 평균값을 가리킨다.
np.random.seed(100)
fig = plt.figure(figsize=(6,4 ))
ax = fig.add_subplot(111)
# 총 10만번 불공정한 주사위 던지기
size = 100_001
cubic100k = np.random.choice(range(1, 7), size, p=prob_X)
# 100번 던질 때마다 누적 평균값 계산
cubic_means = [cubic100k[:step].mean() for step in range(100, size, 100)]
plt.plot(range(100, size, 100), cubic_means)
# 평균값들의 기댓값
mu_unfair = np.sum([x * f_unfair(x) for x in range(1, 7)])
plt.hlines(mu_unfair, 100, size, color='red')
plt.show()
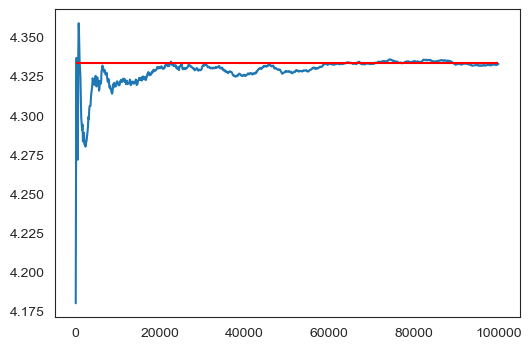
확률변수의 기댓값
이산확률변수 \(X\)가 취할 수 있는 값들의 평균값을 기댓값expectation value이라 부른다. 확률변수의 기댓값은 \(E[X]\)로 표기하며 다음과 같이 정의된다. 아래 식에서 함수 \(f\)는 확률질량함수를, \(n\)은 확률변수 \(X\)가 취할 수 있는 값들의 개수를 가리킨다.
위 식에 따르면 불공정한 주사위를 많이 던졌을 때 나올 수 있는 값들의 평균값은 4.33 정도다.
아래 코드가 이를 확인해준다.
mu_unfair = np.sum([x * f_unfair(x) for x in range(1, 7)])
mu_unfair
4.333333
반면에 정상적인 주사위를 사용한 경우에는 앞서 기댓값이 3.5로 계산된다.
mu_fair = np.sum([x * 1/6 for x in range(1, 7)])
mu_fair
3.500000
결론적으로 확률변수가 취할 수 있는 값들의 집합이 동일하더라도 기댓값은 확률변수가 따르는 확률분포에 따라 다르게 계산된다.
평균값과 균등분포
사실 평균값은 모든 데이터에 대한 선택 가능성이 동일하다는, 즉 균등분포를 따른다는 전제하에 계산된 기댓값이다. 데이터셋의 크기가 \(n\)일 때 확률변수가 임의의 값을 취할 확률은 항상 1/n이고, 따라서 기댓값과 평균값이 동일하게 계산된다.
예를 들어, 정상적인 주사위의 경우 모든 숫자가 나올 확률이 균등하게 1/6이다. 따라서 단순한 숫자로서의 평균값과 주사위 던지기의 확률변수에 대한 기댓값 모두 3.5로 계산된다.
16.1.2. 분산#
확률변수 \(X\)의 분산 \(V(X)\)는 확률변수가 가질 수 있는 값들과 기댓값 사이의 오차의 제곱에 대한 기댓값으로 다음과 같이 정의된다. 단, \(\mu_X\)는 \(E[X]\)를 가리킨다.
분산 \(V(X)\)를 \(\sigma_X^2\)로 표현하기도 한다. 그러면 \(\sigma_X\)는 확률변수 \(X\)의 표준편차를 나타낸다. 확률변수의 분산은 확률변수가 취하는 값들이 기댓값으로부터 얼마만큼 떨어져서 선택될 것인가에 대한 기댓값으로 이해될 수 있다.
앞서 언급된 불공정한 주사위의 확률변수 \(X\)의 분산은 2.222222로 계산된다.
V_unfair = np.sum([(x - mu_unfair)**2 * f_unfair(x) for x in range(1, 7)])
V_unfair
2.222222
표준편차는 1.49정도로 계산되며 이는 주사위를 던졌을 때 얻는 숫자가 기댓값 4.33에서 평균적으로 약 1.5정도 차이가 날 것으로 기대할 수 있음을 의미한다.
sigma_unfair = np.sqrt(V_unfair)
sigma_unfair
1.490712
예제: 캘리포니아 주택가격 데이터셋 중위소득 범주
13장에서 살펴 본대로 캘리포니아 주택가격 데이터셋에서 임의로 선택된 구역의 중위소득 범주를 가리키는 확률변수 \(X\)의 확률분포는 다음과 같다.
X |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|
확률 |
0.041372 |
0.333011 |
0.361017 |
0.177993 |
0.086607 |
따라서 임의로 선택된 구역의 중위소득 범주에 대한 기댓값과 분산은 다음과 같다.
중위소득 범주의 확률분포
prob_income = [0.041372 , 0.333011 , 0.361017 , 0.177993 , 0.086607]
중위소득 범주의 확률질량함수
def f_income(x):
assert 1 <= x <= 5
return prob_income[x-1]
중위소득 범주 확률변수의 기댓값
mu_income = np.sum([x * f_income(x) for x in range(1, 6)])
mu_income
2.935452
중위소득 범주 확률변수의 분산
V_income = np.sum([(x - mu_income)**2 * f_income(x) for x in range(1, 6)])
V_income
1.018754
중위소득 범주 확률변수의 표준편차
sigma_income = np.sqrt(V_income)
sigma_income
1.009333
16.1.3. 확률변수 선형 변환#
확률변수 \(X\)가 취할 수 있는 값에 상수 \(a\)를 곱한 다음에 상수 \(b\)를 더한 값을 가리키는 확률변수 \(Y\)는 다음과 같이 정의된다. 확률변수 \(Y\)는 확률변수 \(X\)를 선형 변환한 결과이며 서로 동일한 확률분포를 따른다.
확률변수 \(Y\)의 기댓값, 분산, 표준편차는 다음과 같으며 증명은 생략한다.
예제
캘리포니아 주택가격 데이터셋의 중위소득 범주는 1부터 5 사이의 정수이고, 각각의 범주가 가리키는 중위소득의 구간은 다음과 같다.
범주 |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|
구간 |
1.5 이하 |
1.5 - 3.0 |
3.0 - 4.5 |
4.5 - 6.0 |
6.0 이상 |
하지만 실제 중위소득은 몇 만 달러 단위로 움직인다. 따라서 범주에 1만5천을 곱한 다음에 7천5백 정도 빼주어 실제 중위소득을 계산한다고 가정하면 실제 중위소득을 가리키는 확률변수는 다음과 같게 된다.
앞선 공식을 적용하면 임의로 선택된 구역의 중위소득에 대한 기댓값은 36,532 달러 정도로 계산된다.
\(E[Y]\) 계산
mu_real_income = 15000 * mu_income - 7500
print(f"중위소득 기댓값: {mu_real_income:,.2f} 달러")
중위소득 기댓값: 36,531.78 달러
임의로 선택된 구역의 실제 중위소득은 위 기댓값으로부터 평균적으로 15,140 달러 정도의 오차를 가질 것으로 기대된다.
\(V(Y)\)와 \(\sigma_Y\) 계산
V_real_income = 15000**2 * V_income
sigma_real_income = 15000 * sigma_income
print(f"중위소득 분 산: {V_real_income:14,.2f} 달러")
print(f"중위소득 표준편차: {sigma_real_income:14,.2f} 달러")
중위소득 분 산: 229,219,550.03 달러
중위소득 표준편차: 15,140.00 달러
선형 변환 결과 확인
앞서 공식을 이용한 계산대로 결과가 나오는지 실제 확인해본다. 아래 표는 범주에 1만5천을 곱한 다음에 7천5백을 뺀 실제 중위소득을 담고 있다.
범주 |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|
실제 중위소득 |
7,500 |
22,500 |
37,500 |
52,500 |
67,500 |
확률분포는 f_income() 함수와 동일하기에
임의로 선택된 구역의 실제 중위소득에 대한 기댓값은 다음과 같이 계산된다.
mu_transformed = np.sum([(15000 * x - 7500) * f_income(x) for x in range(1, 6)])
print(f"중위소득 기댓값: {mu_transformed:,.2f} 달러")
중위소득 기댓값: 36,531.78 달러
아래 코드는 임의로 선택된 10만 개 구역의 중위소득에 대해 100개씩 누적된 평균값은
바로 앞서 계산된 mu_transformed에 수렴함을 보여준다.
np.random.seed(0)
fig = plt.figure(figsize=(6,4 ))
ax = fig.add_subplot(111)
# 총 10만번 실제 중위소득 선택
size = 100_001
income100k_transformed = np.random.choice(range(1, 6), size, p=prob_income) * 15000 - 7500
# 100번 던질 때마다 누적 평균값 계산
income_means_transformed = [income100k_transformed[:step].mean() for step in range(100, size, 100)]
plt.plot(range(100, size, 100), income_means_transformed)
# 평균값들의 기댓값
plt.hlines(mu_transformed, 100, size, color='red')
plt.show()
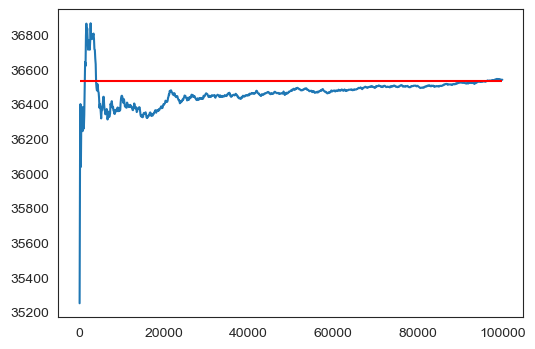
표준편차 또한 동일하게 계산된다.
V_transformed = np.sum([(15000 * x - 7500 - mu_transformed)**2 * f_income(x) for x in range(1, 6)])
sigma_transformed = np.sqrt(V_transformed)
print(f"중위소득 분 산: {V_transformed:14,.2f} 달러")
print(f"중위소득 표준편차: {sigma_transformed:14,.2f} 달러")
중위소득 분 산: 229,219,550.03 달러
중위소득 표준편차: 15,140.00 달러
16.2. 연속확률변수의 기댓값과 분산#
연속확률변수 \(X\)에 대한 기댓값, 분산, 선형 변환은 이산확률변수의 경우와 사실상 동일하다. 다만 유한 개수의 합 \(\sum\)이 적분 기호 \(\int\)로 대체되고 확률질량함수 대신에 확률밀도함수가 사용될 뿐이다.
16.2.1. 기댓값, 분산, 선형 변환#
기댓값
연속확률변수 \(X\)에 대한 기댓값 \(E[X]\)는 다음과 같이 정의된다. 단, \(f\)는 확률변수 \(X\)의 확률밀도함수다.
분산
연속확률변수 \(X\)에 대한 분산 \(V(X)\)는 다음과 같이 정의된다. 단, \(\mu_X\)는 확률변수 \(X\)의 기댓값이다.
확률변수 선형 변환
연속확률변수에 대해서도 동일한 선형 변환 공식이 성립한다. 다음 확률변수 \(Y\)는 확률변수 \(X\)를 선형 변환한 결과이며 서로 동일한 확률분포를 따른다.
확률변수 \(Y\)의 기댓값, 분산, 표준편차를 구하는 공식도 이산확률변수의 경우와 동일하다.
16.2.2. 예제: 캘리포니아 구역별 중위소득 확률분포#
15장에서 캘리포니아 주택가격 데이터셋의 중위소득 데이터를 활용하여 연속확률변수에 대한 기댓값, 분산, 선형 변환 결과를 계산한다.
아래 코드는 캘리포니아 주택가격 데이터셋을 불러온 후에 중위주택가격이 50만을 초과하는 경우는 삭제하고 인덱스를 초기화한다. 최종적으로 중위소득 특성만 남긴다.
housing = pd.read_csv(data_url+"california_housing_mini.csv")
# 중위주택가격이 50만1달러 이상인 구역 삭제
house_value_max = housing['median_house_value'].max() # 500,001
mask = housing['median_house_value'] >= house_value_max
housing = housing[~mask]
# 인덱스 초기화
housing = housing.reset_index(drop=True)
# 중위소득 특성만 선택
housing = housing.loc[:, 'median_income']
housing.index.name = 'district'
housing
district
0 8.3252
1 8.3014
2 7.2574
3 5.6431
4 3.8462
...
19670 1.5603
19671 2.5568
19672 1.7000
19673 1.8672
19674 2.3886
Name: median_income, Length: 19675, dtype: float64
아래 코드는 통계 함수를 제공하는 scipy.stats 모듈의 gaussian_kde() 함수를
이용하여 중위소득 데이터에 대한 확률밀도함수를 구한다.
import scipy.stats
f_income = scipy.stats.gaussian_kde(housing, bw_method=.19)
아래 코드는 확률밀도함수의 그래프를 그린다.
fig, ax = plt.subplots()
xs = np.arange(-0.2, 15.7, 0.01)
ax.plot(xs, f_income(xs), color='#ff7f0e')
ax.set_ylim([0.0, 0.299])
plt.show()
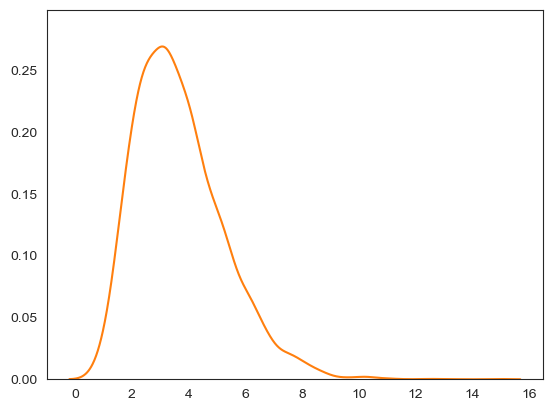
중위소득 기댓값
적분을 위해 scipy.integrate 모듈의 quad() 함수를 이용한다.
그런데 적분을 프로그래밍으로 실행하는 일은 완전하지 않아 종종 오류나 경고가 발생하곤 한다.
여기서는 엄밀한 계산이 중요하지 않기에
아래 코드를 이용하여 적분 과정에 발생하는 오류는 무시하도록 한다.
from scipy import integrate
import warnings
warnings.filterwarnings('ignore', category=integrate.IntegrationWarning)
중위소득을 가리키는 확률변수의 기댓값은 다음과 같다. 적분 대상인 \(x \, f(x)\) 는 아래 람다 함수로 구현된다.
lambda x: x * f_income(x)
from scipy.integrate import quad
E_X = quad(lambda x: x * f_income(x), -np.inf, np.inf)[0]
print(f"중위소득 기댓값: {E_X:.6f}")
중위소득 기댓값: 3.676717
적분 결과에 1만을 곱하면 실제 중위소득이 확인된다.
print(f"중위소득 기댓값: {E_X * 10000:,.2f} 달러")
중위소득 기댓값: 36,767.17 달러
앞서 중위소득 범주에 1만5천을 곱한 후 7천5백을 뺀 이산확률분포의 기댓값과 유사한 값이 계산되었다.
print(f"선형 변환된 중위소득: {mu_transformed:,.2f}")
선형 변환된 중위소득: 36,531.78
결론적으로 중위소득 범주에 대한 선형 변환이 적절했음이 확인된다.
중위소득 분산
분산도 적분을 이용하여 계산해본다.
V_X = quad(lambda x: (x - E_X)**2 * f_income(x), -np.inf, np.inf)[0]
print(f"중위소득 분산: {V_X:.6f}")
중위소득 분산: 2.554641
계산된 값에 1만의 제곱, 즉 10의 8승을 곱하면 앞서 이산확률변수에 선형 변환을 적용하여 계산된 분산과 유사한 값이 나온다.
이산확률변수 선형 변환 결과의 분산
print(f"선형 변환된 분산: {V_transformed:,.2f}")
선형 변환된 분산: 229,219,550.03
중위소득 분산에 10의 8승 곱하기. 분산은 제곱을 사용하기에 10의 4승의 제곱을 곱해야 단위가 동일해짐.
print(f"중위소득 분산 곱하기 10의8승: {V_X * 1.0e8:,.2f}")
중위소득 분산 곱하기 10의8승: 255,464,128.57
중위소득 표준편차
각각의 값에 루트 함수를 적용하여 각각의 표준편차를 계산해도 유사하게 계산된다.
sigma_X = np.sqrt(V_X)
print(f"중위소득 분산: {sigma_X:.6f}")
중위소득 분산: 1.598325
이산확률변수 선형 변환 결과의 표준편차
print(f"선형 변환된 표준편차: {sigma_transformed:,.2f}")
선형 변환된 표준편차: 15,140.00
중위소득 표준편차에 1만 곱하기.
print(f"중위소득 표준편차 곱하기 1만: {np.sqrt(V_X) * 1.0e4:,.2f}")
중위소득 표준편차 곱하기 1만: 15,983.25
선형 변환
실제 중위소득을 가리키는 확률변수 \(Y\)는 확률변수 \(X\)에 1만을 구해 얻어진다.
아래 코드는 확률변수 \(Y\)가 가리키는 실제 데이터셋 income_real을 선언한다.
income_real = housing * 10000
확률변수 \(Y\)에 대한 확률밀도함수
f_real = scipy.stats.gaussian_kde(income_real, bw_method=.19)
확률변수 \(Y\)에 대한 기댓값
E_real = quad(lambda x: x * f_real(x), -np.inf, np.inf)[0]
print(f"실제 중위소득 기댓값: {E_real:,.6f}")
실제 중위소득 기댓값: 37,545.065231
확률변수 \(Y\)에 대한 분산
V_real = quad(lambda x: (x - E_real)**2 * f_real(x), -np.inf, np.inf)[0]
print(f"실제 중위소득 분산: {V_real:,.6f}")
실제 중위소득 분산: 274,748,943.704969
확률변수 \(Y\)에 대한 표준편차
sigma_real = np.sqrt(V_real)
print(f"실제 중위소득 표준편차: {sigma_real:,.6f}")
실제 중위소득 표준편차: 16,575.552591
결론
E_real, V_real, sigma_real 결과가 1.0e4 * E_X, 1.0e8 * V_X, 1.0e4 * sigma_X와
차이가 많이 난다.
이유는 부동소수점에 대한 적분이 제대로 지원되지 않은 것으로 추정된다.
여기서는 엄밀한 계산이 아닌 연속확률변수에 대한 기댓값, 분산, 표준편차 계산 방식에 대한
이해가 중요하기에 더 이상 적분에 대해서는 언급하지 않는다.
16.3. 연습문제#
참고: (연습) 기댓값과 분산