5. 판다스 데이터프레임#
기본 설정
numpy와 pandas 라이브러리를 각각 np와 pd로 불러온다.
import numpy as np
import pandas as pd
데이터프레임DataFrame은 인덱스를 공유하는 여러 개의 시리즈를 다루는 객체다.
5.1. 데이터프레임 생성#
아래 그림은 세 개의 시리즈를 하나의 데이터프레임으로 만든 결과를 보여준다.
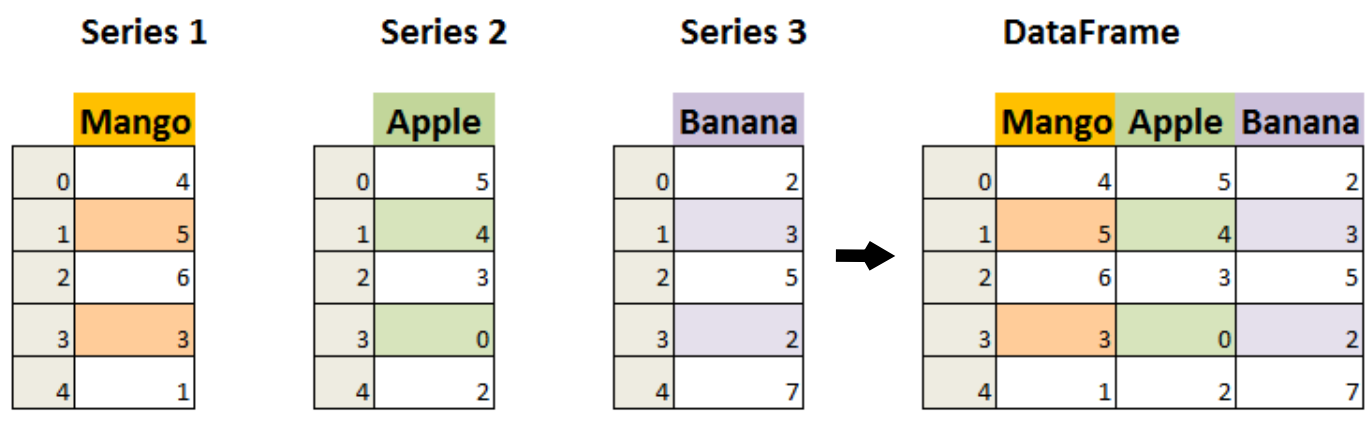
pd.concat() 함수 활용
위 이미지에 있는 세 개의 시리즈는 다음과 같으며,
name 속성에 각 시리즈의 이름도 함께 지정한다.
series1 = pd.Series([4, 5, 6, 3, 1], name="Mango")
series1
0 4
1 5
2 6
3 3
4 1
Name: Mango, dtype: int64
series2 = pd.Series([5, 4, 3, 0, 2], name="Apple")
series2
0 5
1 4
2 3
3 0
4 2
Name: Apple, dtype: int64
series3 = pd.Series([2, 3, 5, 2, 7], name="Banana")
series3
0 2
1 3
2 5
3 2
4 7
Name: Banana, dtype: int64
pd.concat() 함수는 여러 개의 시리즈 또는 데이터프레임을 묶어 하나의 데이터프레임을 생성한다.
묶는 방식은 축을 지정함으로써 결정되는데, 위 그림처럼 옆으로 묶으려면 열 단위로 추가한다는 뜻으로 axis=1을, 아래로 묶으려면 행 단위로 추가한다는 뜻으로 axis=0로 설정하면 된다.
위 그림에서 추가되는 각 열의 이름은 해당 시리즈의 name으로 지정된다.
fruits = pd.concat([series1, series2, series3], axis=1)
fruits
| Mango | Apple | Banana | |
|---|---|---|---|
| 0 | 4 | 5 | 2 |
| 1 | 5 | 4 | 3 |
| 2 | 6 | 3 | 5 |
| 3 | 3 | 0 | 2 |
| 4 | 1 | 2 | 7 |
엑셀 파일로 보면 다음과 같다. 단, 엑셀에서는 2번 행부터 데이터가 위치한다.
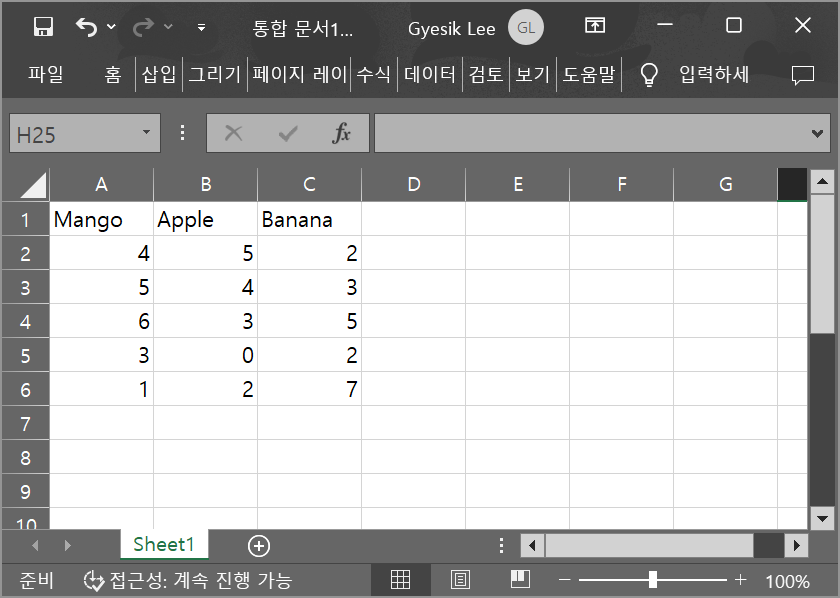
데이터프레임은 행과 열에 각각에 대해 Index 객체를 사용한다.
행에 대한 인덱스는 index 속성이, 열에 대한 인덱스는 columns 속성이 저장하고 있다. 이 두 가지 속성의 활용은 아래의 부분절에서 상세히 살펴본다.
행 인덱스
fruits.index
RangeIndex(start=0, stop=5, step=1)
열 인덱스
fruits.columns
Index(['Mango', 'Apple', 'Banana'], dtype='object')
2차원 넘파이 어레이 활용
아래 코드와 같이, 2차원 어레이의 행과 열에 대한 인덱스는 각각 index와 column 속성에서 지정하면 된다.
frame1= pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'], # 행 인덱스
columns=['year', 'state', 'p', 'four']) # 열 인덱스
frame1
| year | state | p | four | |
|---|---|---|---|---|
| Ohio | 0 | 1 | 2 | 3 |
| Colorado | 4 | 5 | 6 | 7 |
| Utah | 8 | 9 | 10 | 11 |
| New York | 12 | 13 | 14 | 15 |
행 인덱스
frame1.index
Index(['Ohio', 'Colorado', 'Utah', 'New York'], dtype='object')
열 인덱스
frame1.columns
Index(['year', 'state', 'p', 'four'], dtype='object')
사전 활용
데이터의 이름을 키key로, 리스트를 값value으로 갖는 사전을 이용해 데이터프레임을 생성할 수 있다.
아래 코드에서 dict2는 state, year, pop을 키key로 사용하며,
각각의 키에 할당된 리스트는 모두 길이가 동일하다.
dict2 = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada', 'NY', 'NY', 'NY'],
'year': [2000, 2001, 2002, 2001, 2002, 2003, 2002, 2003, 2004],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2, 8.3, 8.4, 8.5]}
위 사전 객체를 데이터프레임으로 변환하면 다음과 같다. 행 인덱스를 지정하지 않으므로 기본 인덱스인 정수 인덱스가 사용된다.
frame2 = pd.DataFrame(dict2)
frame2
| state | year | pop | |
|---|---|---|---|
| 0 | Ohio | 2000 | 1.5 |
| 1 | Ohio | 2001 | 1.7 |
| 2 | Ohio | 2002 | 3.6 |
| 3 | Nevada | 2001 | 2.4 |
| 4 | Nevada | 2002 | 2.9 |
| 5 | Nevada | 2003 | 3.2 |
| 6 | NY | 2002 | 8.3 |
| 7 | NY | 2003 | 8.4 |
| 8 | NY | 2004 | 8.5 |
5.1.1. columns 속성과 index 속성#
앞서 언급한 대로 데이터프레임은 행과 열 각각에 대해 Index 객체를 사용한다.
columns 속성
dict2.keys()
dict_keys(['state', 'year', 'pop'])
columns 속성을 이용하여 열의 순서를 변경할 수 있다.
frame2 = pd.DataFrame(dict2, columns=['year', 'state', 'pop'])
frame2
| year | state | pop | |
|---|---|---|---|
| 0 | 2000 | Ohio | 1.5 |
| 1 | 2001 | Ohio | 1.7 |
| 2 | 2002 | Ohio | 3.6 |
| 3 | 2001 | Nevada | 2.4 |
| 4 | 2002 | Nevada | 2.9 |
| 5 | 2003 | Nevada | 3.2 |
| 6 | 2002 | NY | 8.3 |
| 7 | 2003 | NY | 8.4 |
| 8 | 2004 | NY | 8.5 |
5.2. index 속성#
데이터프레임 frame2의 행 인덱스는 자동 지정되었으므로 RangeIndex 객체가 사용되었다.
frame2.index
RangeIndex(start=0, stop=9, step=1)
데이터프레임을 생성할 때 특정 인덱스를 사용하려면 index 속성에서 정의하면 된다.
frame3 = pd.DataFrame(dict2, index=['one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine'])
frame3
| state | year | pop | |
|---|---|---|---|
| one | Ohio | 2000 | 1.5 |
| two | Ohio | 2001 | 1.7 |
| three | Ohio | 2002 | 3.6 |
| four | Nevada | 2001 | 2.4 |
| five | Nevada | 2002 | 2.9 |
| six | Nevada | 2003 | 3.2 |
| seven | NY | 2002 | 8.3 |
| eight | NY | 2003 | 8.4 |
| nine | NY | 2004 | 8.5 |
물론 columns, index 등 여러 속성을 동시에 지정할 수도 있다.
frame3 = pd.DataFrame(dict2, columns=['year', 'state', 'pop'],
index=['one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine'])
frame3
| year | state | pop | |
|---|---|---|---|
| one | 2000 | Ohio | 1.5 |
| two | 2001 | Ohio | 1.7 |
| three | 2002 | Ohio | 3.6 |
| four | 2001 | Nevada | 2.4 |
| five | 2002 | Nevada | 2.9 |
| six | 2003 | Nevada | 3.2 |
| seven | 2002 | NY | 8.3 |
| eight | 2003 | NY | 8.4 |
| nine | 2004 | NY | 8.5 |
5.3. name 속성과 values 속성#
name 속성
데이터프레임 객체 또한 name 속성을 이용해 행과 열의 이름을 지정할 수 있다.
frame3.index.name = 'id' # 행 이름 지정
frame3.columns.name = 'features' # 열 이름 지정
frame3
| features | year | state | pop |
|---|---|---|---|
| id | |||
| one | 2000 | Ohio | 1.5 |
| two | 2001 | Ohio | 1.7 |
| three | 2002 | Ohio | 3.6 |
| four | 2001 | Nevada | 2.4 |
| five | 2002 | Nevada | 2.9 |
| six | 2003 | Nevada | 3.2 |
| seven | 2002 | NY | 8.3 |
| eight | 2003 | NY | 8.4 |
| nine | 2004 | NY | 8.5 |
values 속성
데이터프레임의 values 속성은 항목들만으로 이루어진 2차원 어레이를 가리킨다.
frame3.values
array([[2000, 'Ohio', 1.5],
[2001, 'Ohio', 1.7],
[2002, 'Ohio', 3.6],
[2001, 'Nevada', 2.4],
[2002, 'Nevada', 2.9],
[2003, 'Nevada', 3.2],
[2002, 'NY', 8.3],
[2003, 'NY', 8.4],
[2004, 'NY', 8.5]], dtype=object)
5.4. 데이터프레임 인덱싱#
2차원 넘파이 어레이와 거의 유사하게 작동한다. 데이터프레임 frame3의 예를 들어 설명한다.
frame3
| features | year | state | pop |
|---|---|---|---|
| id | |||
| one | 2000 | Ohio | 1.5 |
| two | 2001 | Ohio | 1.7 |
| three | 2002 | Ohio | 3.6 |
| four | 2001 | Nevada | 2.4 |
| five | 2002 | Nevada | 2.9 |
| six | 2003 | Nevada | 3.2 |
| seven | 2002 | NY | 8.3 |
| eight | 2003 | NY | 8.4 |
| nine | 2004 | NY | 8.5 |
데이터프레임 열 라벨 인덱싱
열 라벨 인덱싱은 시리즈, 사전 등과 동일한 방식을 사용한다.
예를 들어, state 열을 인덱싱하면 새로운 시리즈를 생성한다.
frame3['state']
id
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
six Nevada
seven NY
eight NY
nine NY
Name: state, dtype: object
대괄호 대신 속성 형식을 사용할 수도 있다.
아래 코드는 year 열을 시리즈로 보여준다.
frame3.year
id
one 2000
two 2001
three 2002
four 2001
five 2002
six 2003
seven 2002
eight 2003
nine 2004
Name: year, dtype: int64
데이터프레임 열 팬시 인덱싱
여러 개의 열을 동시에 인덱싱 하려면 아래와 같이 열 라벨의 리스트 또는 정수 인덱스의 리스트를 이용하면 된다. 지정된 순서의 열로 구성된 별도의 데이터프레임이 생성된다.
frame3[['state','year']]
| features | state | year |
|---|---|---|
| id | ||
| one | Ohio | 2000 |
| two | Ohio | 2001 |
| three | Ohio | 2002 |
| four | Nevada | 2001 |
| five | Nevada | 2002 |
| six | Nevada | 2003 |
| seven | NY | 2002 |
| eight | NY | 2003 |
| nine | NY | 2004 |
길이가 1인 리스트일 때도 데이터프레임을 생성한다.
frame3[['state']]
| features | state |
|---|---|
| id | |
| one | Ohio |
| two | Ohio |
| three | Ohio |
| four | Nevada |
| five | Nevada |
| six | Nevada |
| seven | NY |
| eight | NY |
| nine | NY |
데이터프레임 열 추가/업데이트
열 라벨 인덱싱을 이용하여 새로운 특성을 추가할 수 있다.
아래 코드는 'debt' 열의 값을 16.5로 지정해 브로드캐스팅을 적용한다.
frame3['debt'] = 16.5
frame3
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| one | 2000 | Ohio | 1.5 | 16.5 |
| two | 2001 | Ohio | 1.7 | 16.5 |
| three | 2002 | Ohio | 3.6 | 16.5 |
| four | 2001 | Nevada | 2.4 | 16.5 |
| five | 2002 | Nevada | 2.9 | 16.5 |
| six | 2003 | Nevada | 3.2 | 16.5 |
| seven | 2002 | NY | 8.3 | 16.5 |
| eight | 2003 | NY | 8.4 | 16.5 |
| nine | 2004 | NY | 8.5 | 16.5 |
행의 길이와 동일한 리스트, 어레이 등을 이용하여 지정된 열의 항목을 업데이트할 수 있다. 이때 리스트, 어레이의 길이가 행의 개수와 동일해야만 오류를 발생시키지 않는다.
frame3['debt'] = np.arange(9.)
frame3
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| one | 2000 | Ohio | 1.5 | 0.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
| seven | 2002 | NY | 8.3 | 6.0 |
| eight | 2003 | NY | 8.4 | 7.0 |
| nine | 2004 | NY | 8.5 | 8.0 |
데이터프레임 행 인덱싱
행 인덱싱은 loc() 또는 iloc() 함수를 이용한다.
loc()함수: 인덱스 라벨을 이용할 경우iloc()함수: 정수 인덱스를 이용할 경우
설명을 위해 계속해서 frame3가 가리키는 데이터프레임을 이용한다.
frame3
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| one | 2000 | Ohio | 1.5 | 0.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
| seven | 2002 | NY | 8.3 | 6.0 |
| eight | 2003 | NY | 8.4 | 7.0 |
| nine | 2004 | NY | 8.5 | 8.0 |
아래 코드는 'three' 라벨을 인덱스로 갖는 행을 별도의 시리즈로 추출한다.
frame3.loc['three']
features
year 2002
state Ohio
pop 3.6
debt 2.0
Name: three, dtype: object
'three' 행이 2번 인덱스의 행이므로 다음과 같이 정수 인덱싱을 진행해도 된다.
frame3.iloc[2]
features
year 2002
state Ohio
pop 3.6
debt 2.0
Name: three, dtype: object
데이터프레임 행 팬시 인덱싱
열 팬시 인덱싱과 마찬가지로, 여러 행을 동시에 인덱싱 하려면 아래 코드와 같이, 행 라벨의 리스트 또는 정수 인덱스의 리스트를 이용한다. 지정된 순서의 행으로 구성된 새로운 데이터프레임이 생성된다.
행 라벨 리스트 활용
frame3.loc[['four', 'two', 'three']]
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| four | 2001 | Nevada | 2.4 | 3.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
정수 인덱스 리스트 활용
frame3.iloc[[3, 1, 2]]
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| four | 2001 | Nevada | 2.4 | 3.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
5.5. 데이터프레임 슬라이싱#
loc() 과 iloc() 함수를 행과 열에 동시에 적용할 수 있으며,
2차원 넘파이 어레이에 대한 인덱싱/슬라이싱이 작동하는 방식과 거의 동일하다.
설명을 위해 계속해서 frame3가 가리키는 데이터프레임을 이용한다.
frame3
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| one | 2000 | Ohio | 1.5 | 0.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
| seven | 2002 | NY | 8.3 | 6.0 |
| eight | 2003 | NY | 8.4 | 7.0 |
| nine | 2004 | NY | 8.5 | 8.0 |
데이터프레임 열 슬라이싱
열에 대해서만 슬라이싱을 적용하려면 행을 전체로 지정한다. 아래 코드는 전체 행을 대상으로 2번 인덱스열 이전까지 추출한다.
frame3.iloc[:, :2]
| features | year | state |
|---|---|---|
| id | ||
| one | 2000 | Ohio |
| two | 2001 | Ohio |
| three | 2002 | Ohio |
| four | 2001 | Nevada |
| five | 2002 | Nevada |
| six | 2003 | Nevada |
| seven | 2002 | NY |
| eight | 2003 | NY |
| nine | 2004 | NY |
정수 인덱스가 아닌 열 라벨을 이용한 슬라이싱은 loc()함수를 써야하고, 지정한 구간의 끝도 포함됨에 유의한다.
frame3.loc[:, :'pop']
| features | year | state | pop |
|---|---|---|---|
| id | |||
| one | 2000 | Ohio | 1.5 |
| two | 2001 | Ohio | 1.7 |
| three | 2002 | Ohio | 3.6 |
| four | 2001 | Nevada | 2.4 |
| five | 2002 | Nevada | 2.9 |
| six | 2003 | Nevada | 3.2 |
| seven | 2002 | NY | 8.3 |
| eight | 2003 | NY | 8.4 |
| nine | 2004 | NY | 8.5 |
데이터프레임 행 슬라이싱
행에 대해서만 슬라이싱을 적용하려면 열을 전체로 지정한다. 아래 코드는 2번 인덱스 행부터 모두 가져온다.
frame3.iloc[2:, :]
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
| seven | 2002 | NY | 8.3 | 6.0 |
| eight | 2003 | NY | 8.4 | 7.0 |
| nine | 2004 | NY | 8.5 | 8.0 |
열 슬라이싱은 지정하지 않아도 된다.
frame3.iloc[2:]
| features | year | state | pop | debt |
|---|---|---|---|---|
| id | ||||
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
| seven | 2002 | NY | 8.3 | 6.0 |
| eight | 2003 | NY | 8.4 | 7.0 |
| nine | 2004 | NY | 8.5 | 8.0 |
행과 열 슬라이싱을 동시에 진행할 수도 있다. 아래 코드는 2번 인덱스 행부터의 모든 행을 대상으로 3번 인덱스 열 이전까지의 항목만 추출한다.
frame3.iloc[2:, :3]
| features | year | state | pop |
|---|---|---|---|
| id | |||
| three | 2002 | Ohio | 3.6 |
| four | 2001 | Nevada | 2.4 |
| five | 2002 | Nevada | 2.9 |
| six | 2003 | Nevada | 3.2 |
| seven | 2002 | NY | 8.3 |
| eight | 2003 | NY | 8.4 |
| nine | 2004 | NY | 8.5 |
스텝 활용
스텝step도 사용할 수 있다. 아래 코드는 짝수 인덱스 행에 속한 항목 중에서 홀수 인덱스 열의 항목만 추출한다.
frame3.iloc[::2, 1::2]
| features | state | debt |
|---|---|---|
| id | ||
| one | Ohio | 0.0 |
| three | Ohio | 2.0 |
| five | Nevada | 4.0 |
| seven | NY | 6.0 |
| nine | NY | 8.0 |
인덱싱과 슬라이싱 조합
인덱싱과 슬라이싱의 어떤 조합도 행과 열에 대해 적용할 수 있다.
아래 코드는 'three'라벨 행의 'state'와 'pop' 열의 항목을 별도의 시리즈로 추출한다.
frame3.loc['three', ['state', 'pop']]
features
state Ohio
pop 3.6
Name: three, dtype: object
아래 코드는 'three' 라벨 행까지의 모든 행에서 'pop' 열의 항목을 시리즈로 추출한다.
frame3.loc[:'three', 'pop']
id
one 1.5
two 1.7
three 3.6
Name: pop, dtype: float64
아래 코드는 2번 인덱스 행의 1번, 2번 인덱스 열의 항목을 시리즈로 추출한다.
frame3.iloc[2, [1, 2]]
features
state Ohio
pop 3.6
Name: three, dtype: object
아래 코드는 1번, 2번 인덱스 행의 3번, 0번, 1번 인덱스 열의 항목을 별도의 데이터프레임으로 추출한다.
frame3.iloc[[1, 2], [3, 0, 1]]
| features | debt | year | state |
|---|---|---|---|
| id | |||
| two | 1.0 | 2001 | Ohio |
| three | 2.0 | 2002 | Ohio |
아래 코드는 'three' 라벨 행까지의 모든 행에서 'pop' 열 이후의 모든 열의 항목을 데이터프레임으로 추출한다.
frame3.loc[:'three', 'pop':]
| features | pop | debt |
|---|---|---|
| id | ||
| one | 1.5 | 0.0 |
| two | 1.7 | 1.0 |
| three | 3.6 | 2.0 |
5.6. 예제#
예제 1
(1) 아래 사전으로 데이터프레임 df1을 생성하시오.
abcd_dict = {"A": 1.0,
"B": pd.Series(1, index=list(range(4)), dtype="float32"),
"C": np.array([3] * 4, dtype="int32"),
"D": ["test", "train", "test", "train"]}
답:
동일한 길이의 리스트를 값으로 갖는 사전이므로, 데이터프레임 생성에서 키가 열 인덱스로 사용된다.
df1 = pd.DataFrame(abcd_dict)
df1
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 3 | test |
| 1 | 1.0 | 1.0 | 3 | train |
| 2 | 1.0 | 1.0 | 3 | test |
| 3 | 1.0 | 1.0 | 3 | train |
(2) 데이터프레임 df1의 열별 자료형을 확인하시오.
답:
열별 자료형은 dtypes 속성으로 확인할 수 있다.
df1.dtypes
A float64
B float32
C int32
D object
dtype: object
예제 2
pd.date_range() 함수는 시간으로 구성된 인덱스 자료형을 생성한다.
아래 코드에서 함수 호출에 사용된 키워드 인자의 의미는 다음과 같다.
start="20250101: 2025년 1월 1일부터 시작periods=6: 첫째 인자로 지정된 시간부터 6 개의 시간 데이터 샘플 생성freq="D": 시간 데이터 샘플을 일(Day) 단위로 생성
dates = pd.date_range(start="20250101", periods=6, freq="D")
dates
DatetimeIndex(['2025-01-01', '2025-01-02', '2025-01-03', '2025-01-04',
'2025-01-05', '2025-01-06'],
dtype='datetime64[ns]', freq='D')
아래 코드는 (6, 4) 모양의 데이터프레임을 생성한다.
행 인덱스: 앞서 선언한
dates변수가 가리키는DatetimeIndex객체를 이용항목:
np.random.randn()함수를 이용하여 무작위 부동소수점으로 생성된 2차원 어레이 이용열 인덱스:
['A', 'B', 'C', 'D']지정
np.random.seed(0) # 무작위 생성 함수의 시드 지정.
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
df
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-01 | 1.764052 | 0.400157 | 0.978738 | 2.240893 |
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-03 | -0.103219 | 0.410599 | 0.144044 | 1.454274 |
| 2025-01-04 | 0.761038 | 0.121675 | 0.443863 | 0.333674 |
| 2025-01-05 | 1.494079 | -0.205158 | 0.313068 | -0.854096 |
| 2025-01-06 | -2.552990 | 0.653619 | 0.864436 | -0.742165 |
(1) 'A' 열만을 추출하여 시리즈를 생성하시오.
답:
열 라벨을 이용한 인덱싱을 적용한다.
df["A"]
2025-01-01 1.764052
2025-01-02 1.867558
2025-01-03 -0.103219
2025-01-04 0.761038
2025-01-05 1.494079
2025-01-06 -2.552990
Freq: D, Name: A, dtype: float64
또는 열 라벨을 객체의 속성처럼 이용하는 방식도 가능하다. 단, 열 라벨의 이름이 공백을 포함하지 않아야 한다.
df.A
2025-01-01 1.764052
2025-01-02 1.867558
2025-01-03 -0.103219
2025-01-04 0.761038
2025-01-05 1.494079
2025-01-06 -2.552990
Freq: D, Name: A, dtype: float64
(2) 0번 행부터 2번 행까지만 포함하는 데이터프레임을 생성하시오.
답:
정수 인덱스를 활용한 슬라이싱을 적용한다.
df.iloc[0:3]
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-01 | 1.764052 | 0.400157 | 0.978738 | 2.240893 |
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-03 | -0.103219 | 0.410599 | 0.144044 | 1.454274 |
또는 인덱스 라벨을 활용하여 슬라이싱을 진행할 수도 있다. 위치 인덱스 방식과는 달리 구간의 마지막 라벨로 포함된다.
df["2025-01-01":"2025-01-03"]
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-01 | 1.764052 | 0.400157 | 0.978738 | 2.240893 |
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-03 | -0.103219 | 0.410599 | 0.144044 | 1.454274 |
날짜표기에 사용된 대쉬 기호는 생략해도 된다.
df["20250101":"20250103"]
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-01 | 1.764052 | 0.400157 | 0.978738 | 2.240893 |
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-03 | -0.103219 | 0.410599 | 0.144044 | 1.454274 |
(3) 첫번째 날짜, 즉 2025년 1월 1일의 데이터를 확인하는 한 줄 표현식을 작성하시오.
단, loc[] 객체와 dates 변수를 이용해야 한다.
답:
df.loc[dates[0]]
A 1.764052
B 0.400157
C 0.978738
D 2.240893
Name: 2025-01-01 00:00:00, dtype: float64
(4) loc[] 객체를 이용해 'A'와 'B' 두 열만 추출하는 한 줄 표현식을 작성하시오.
답:
df.loc[:, ["A", "B"]]
| A | B | |
|---|---|---|
| 2025-01-01 | 1.764052 | 0.400157 |
| 2025-01-02 | 1.867558 | -0.977278 |
| 2025-01-03 | -0.103219 | 0.410599 |
| 2025-01-04 | 0.761038 | 0.121675 |
| 2025-01-05 | 1.494079 | -0.205158 |
| 2025-01-06 | -2.552990 | 0.653619 |
(5) loc[] 객체를 이용하여 2025년 1월 2일부터 1월 4일까지를 대상으로 A, B 두 열만 추출하는 한 줄 표현식을 작성하시오.
답:
df.loc["20250102":"20250104", ["A", "B"]]
| A | B | |
|---|---|---|
| 2025-01-02 | 1.867558 | -0.977278 |
| 2025-01-03 | -0.103219 | 0.410599 |
| 2025-01-04 | 0.761038 | 0.121675 |
(6) loc[] 객체를 이용하여 2025년 1월 2일의 A, B 두 열만 추출하는 한 줄 표현식을 작성하시오.
답:
df.loc["20250102", ["A", "B"]]
A 1.867558
B -0.977278
Name: 2025-01-02 00:00:00, dtype: float64
(7) loc[] 객체와 dates 변수를 이용해 2025년 1월 1일의 A 열만 추출하는 한 줄 표현식을 작성하시오.
답:
df.loc[dates[0], "A"]
1.764052345967664
(8) iloc[] 객체를 이용해 3번 행만 추출하는 한 줄 표현식을 작성하시오.
답:
df.iloc[3]
A 0.761038
B 0.121675
C 0.443863
D 0.333674
Name: 2025-01-04 00:00:00, dtype: float64
(9) iloc[] 객체를 이용해 3번부터 4번 인덱스 행을 대상으로 0번, 1번 인덱스의 열만 추출하는 한 줄 표현식을 작성하시오.
답:
df.iloc[3:5, 0:2]
| A | B | |
|---|---|---|
| 2025-01-04 | 0.761038 | 0.121675 |
| 2025-01-05 | 1.494079 | -0.205158 |
(10) 아래 두 리스트에 포함된 행과 열만 순서대로 추출하는 한 줄 표현식을 작성하시오.
단, iloc[] 객체와 팬시 인덱싱을 활용한다.
행:
[1, 2, 4]열:
[0, 2, 3, 1]
답:
df.iloc[[1, 2, 4], [0, 2, 3, 1]]
| A | C | D | B | |
|---|---|---|---|---|
| 2025-01-02 | 1.867558 | 0.950088 | -0.151357 | -0.977278 |
| 2025-01-03 | -0.103219 | 0.144044 | 1.454274 | 0.410599 |
| 2025-01-05 | 1.494079 | 0.313068 | -0.854096 | -0.205158 |
(11) iloc[] 객체를 이용해 홀수 행만 추출하는 한 줄 표현식을 작성하시오.
답:
df.iloc[1::2, :]
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-04 | 0.761038 | 0.121675 | 0.443863 | 0.333674 |
| 2025-01-06 | -2.552990 | 0.653619 | 0.864436 | -0.742165 |
1번 축(행) 정보는 무시해도 된다.
df.iloc[1::2]
| A | B | C | D | |
|---|---|---|---|---|
| 2025-01-02 | 1.867558 | -0.977278 | 0.950088 | -0.151357 |
| 2025-01-04 | 0.761038 | 0.121675 | 0.443863 | 0.333674 |
| 2025-01-06 | -2.552990 | 0.653619 | 0.864436 | -0.742165 |
(12) iloc[] 객체를 이용해 1번, 2번 열만 추출하는 한 줄 표현식을 작성하시오.
답:
0번 축에 대해서는 모든 행을 가져오라는 슬라이싱을 명시해야 한다.
df.iloc[:, 1:3]
| B | C | |
|---|---|---|
| 2025-01-01 | 0.400157 | 0.978738 |
| 2025-01-02 | -0.977278 | 0.950088 |
| 2025-01-03 | 0.410599 | 0.144044 |
| 2025-01-04 | 0.121675 | 0.443863 |
| 2025-01-05 | -0.205158 | 0.313068 |
| 2025-01-06 | 0.653619 | 0.864436 |