파이썬은 객체 지향 프로그래밍(OOP)을 지원하는 언어다. 객체 지향 프로그래밍 언어의 가장 큰 장점 중 하나는 필요한 값을 생성하는 클래스를 직접 정의하여 활용할 수 있다는 점이다.
데이터 과학에서 활용되는 넘파이의 1차원 어레이에 대응하는 벡터를 값으로
생성하기 위한 Vector 클래스를 직접 정의하면서
클래스, 인스턴스, 객체, 생성자, 메서드 개념을 상세히 소개한다.
OOP란?
객체 지향 프로그래밍Object-Oriented Programming은 프로그램을 객체들의 상호작용으로 구성하는 프로그래밍 기법이며, 줄여서 보통 OOP라고 부른다. OOP를 지원하는 객체 지향 언어로는 파이썬, 자바, C++, C#, 루비, 자바스크립트 등이 있다.
OOP와 대비되는 개념으로 절차 지향 프로그래밍이 주로 언급된다. 절차 지향 프로그래밍은 수행해야 할 일을 순차적인 명령과 함수 호출의 흐름으로 처리하는 과정을 중요하게 여기는 프로그래밍 기법이다. C, Pascal, Fortran 등이 절차 지향 프로그래밍 언어의 대표적인 예이다.
"해야 할 일을 순차적으로 처리한다"는 표현은 가장 기초적인 프로그래밍 기법이며, 모든 프로그램은 원하는 결과를 얻기 위한 과정을 논리적이며 순차적으로 처리하도록 구현되어야 한다. OOP 역시 예외가 아니다. 하지만 OOP는 프로그램을 구성하는 객체들이 어떤 속성과 기능을 가지며 서로 어떻게 협력하는지를 논리적으로 묘사하는 데에 많은 방점을 둔다.
14.1OOP와 객체¶
OOP에 대한 이해는 아래 두 가지 질문과 관련되어 있다.
객체object란?
"객체를 중심으로 프로그래밍한다"의 의미는?
14.1.1객체란?¶
파이썬에서 객체는 특정 클래스의 인스턴스instance로 생성된 값이다. 객체의 자료형은 그 객체를 생성한 클래스에 의해 결정된다.
모든 게 객체!
파이썬의 모든 값은 객체, 즉 어떤 클래스의 인스턴스이다.
예를 들어 정수, 부동소수점, 부울값, 문자열, 리스트, 튜플, 사전, 집합 등은
각각 int, float, bool, str, list, tuple, dict, set 클래스의 인스턴스다.
심지어 함수, 모듈, 클래스 자체도 객체이며, 각각 function, module, type 클래스의 인스턴스다.
| 값의 종류 | 예 | 클래스 |
|---|---|---|
| 정수 | -2, 0, 17 | int |
| 부동소수점 | 1.0, 3.14 | float |
| 부울값 | True, False | bool |
| 문자열 | "Hello World!" | str |
| 리스트 | [1, 2, 3] | list |
| 튜플 | (1, 2, 3) | tuple |
| 사전 | {"a":1, "b":2} | dict |
| 집합 | {1, 2, 3} | set |
| 함수 | def f(x): return x | function |
| 모듈 | random, statistics | module |
| 클래스 | int, float, list | type |
14.1.2객체 중심 프로그래밍¶
객체는 자신이 정의할 때 사용된 클래스에서 정의된 기능을 활용할 때 객체 자신을 중심에 둔다. 이런 의미에서 객체 지향 프로그래밍의 핵심을 객체 중심 프로그래밍이라 할 수 있다.
예를 들어 아래 코드는 리스트에 새로운 항목을 추가하거나 삭제할 때 항상 리스트 객체 자신을 중심으로 이루어지도록 한다는 점을 잘 보여준다.
evens = [0, 2, 4]
odds = [1, 3, 5]
# 새로운 짝수 추가
evens.append(6)
print('새로이 짝수가 추가된 후:', evens)
# 마지막 홀수 삭제
print('삭제되는 마지막 홀수:', odds.pop())새로이 짝수가 추가된 후: [0, 2, 4, 6]
삭제되는 마지막 홀수: 5
심지어 두 리스트의 이어붙이기 연산도 실제로는 덧셈 기호 + 왼쪽에 위치한 리스트를
중심으로 이루어진다.
예를 들어 아래 코드를 실행하면
evens + odds[0, 2, 4, 6, 1, 3]파이썬은 실제로는 아래 코드를 실행한다.
evens.__add__(odds)[0, 2, 4, 6, 1, 3]즉, evens 가 자신이 사용할 수 있는 __add__() 메서드를 이용하여
odds 리스트를 이어붙여 새로운 리스트를 생성한다.
__add__() 메서드에 대해서는 아래에서 자세히 설명한다.
OOP의 핵심
OOP의 핵심은 프로그램을 객체들의 속성과 기능, 그리고 객체들 사이의 상호작용을 구성하여 원하는 결과를 얻는 과정을 논리적으로 표현하는 데에 있다.
이제부터 객체 생성의 필수 요소인 클래스, 인스턴스, 메서드 등을 차례대로 소개한다.
14.2클래스와 인스턴스¶
데이터 과학에서 많이 활용되는 넘파이NumPy 라이브러리는
1차원 어레이array를 이용하여 벡터와 비슷한 값을 표현한다.
이번 장에서는 이와 비슷하게 작동하는 Vector 클래스를 직접 정의하면서
클래스 정의과 인스턴스 생성 과정을 살펴본다.
벡터
벡터는 여러 개의 숫자를 순서대로 담은 값으로, 숫자만 담은 리스트와 비슷하게 생각할 수 있다. 리스트처럼 항목의 개수를 확인하거나 인덱스를 이용해 특정 항목을 꺼낼 수 있지만, 일반적인 리스트와 달리 벡터 덧셈, 스칼라 곱셈, 내적, 크기 계산처럼 숫자들의 묶음에 어울리는 수학적 연산을 지원하도록 만들 수 있다. 이런 차이를 하나씩 구현하면서 사용자 정의 자료형이 어떻게 만들어지는지 확인한다.
14.2.1클래스 정의¶
클래스 정의의 기본 형식은 다음과 같다.
class 클래스명:
# 속성과 메서드 정의Vector 클래스
아래 코드에는 Vector 클래스가 정의되어 있다.
Vector 클래스는 여러 개의 수를 항목으로 갖는 벡터 객체를 자신의 인스턴스로 생성하는 데에 사용된다.
class Vector:
def __init__(self, components):
self.components = tuple(float(x) for x in components)
self.shape = (len(self.components), )
def __repr__(self):
return f"V({list(self.components)})"
def __len__(self):
return len(self.components)
def __getitem__(self, index):
return self.components[index]
def __add__(self, other):
if len(self.components) != len(other.components):
raise ValueError("벡터의 길이가 다름.")
return Vector(a + b for a, b in zip(self.components, other.components))
def __mul__(self, scalar):
return Vector(x * scalar for x in self.components)
def __rmul__(self, scalar):
return self * scalar
def __eq__(self, other):
return self.components == other.components
def to_list(self):
return list(self.components)
def concat(self, other):
return Vector(list(self.components) + list(other.components)) Vector 클래스 본문에서 정의된 인스턴스 변수와 메서드는 다음과 같다.
인스턴스 변수와 속성
Vector 클래스에서 정의된 인스턴스 변수instance variable는 다음과 같다.
인스턴스 변수는 객체가 생성될 때 객체 내부에 저장되는 값을 가리키는 변수이다.
인스턴스 변수에 할당되는 값은 클래스의 인스턴스가 생성될 때 지정되며,
생성된 객체의 속성attribute으로 불린다.
이런 의미에서 인스턴스 변수를 속성 변수라고 부르기도 한다.
| 인스턴스 변수 | 속성 |
|---|---|
self.components | 벡터 객체의 항목을 저장하는 튜플 |
self.shape | 벡터 객체에 포함된 항목의 개수로 구성된 길이가 1인 튜플 |
메서드
Vector 클래스에서 정의된 메서드는 다음과 같다.
메서드method는 클래스 내부에서 정의된 함수를 가리키며,
생성된 객체가 사용할 수 있는 기능을 제공한다.
메서드의 첫 번째 매개변수 self는 해당 메서드를 호출한 객체 자신을 가리킨다.
self에 대한 자세한 설명은 아래에서 다룬다.
| 메서드 | 기능 |
|---|---|
__init__() | 생성자. 인스턴스 초기화 |
__repr__() | 객체의 공식 문자열 표현 |
__len__() | 벡터의 항목 개수 반환 |
__getitem__() | 인덱싱과 슬라이싱 지원 |
__add__() | 두 벡터의 덧셈 |
__mul__(), __rmul__() | 벡터와 스칼라의 곱셈 |
__eq__() | 두 벡터의 동등성 판단 |
__abs__() | 벡터의 크기 반환 |
to_list() | 벡터를 리스트로 변환 |
concat() | 두 벡터 이어 붙이기 |
기타 변수와 함수
Vector 클래스에서 사용되지만 인스턴스 변수도 메서드도 아닌 이름들은 다음과 같다.
이 이름들은 객체의 속성이나 기능으로 저장되는 것이 아니라,
메서드가 실행되는 동안 값을 전달하거나 계산을 돕는 역할을 한다.
| 기능 | 변수 또는 함수 |
|---|---|
| 매개변수 | components, index, other, scalar |
| 지역변수 | a, b, x |
| 내장 함수 | tuple(), float(), list(), len(), sum() |
14.2.2클래스의 인스턴스 정의¶
클래스가 필요한 이유는 공통 속성과 공통 기능을 갖는 다양한 값을 쉽게 생성하기 위해서다.
클래스를 이용하여 생성된 값이 해당 클래스의 인스턴스instance이며, 특정 클래스의 인스턴스를 일반적으로 객체object라 부른다. 지금까지 값이라고 불린 대상은 실제로는 특정 클래스의 인스턴스, 즉 객체이다.
예를 들어 모든 리스트는 list 클래스의 인스턴스이다.
그리고 모든 리스트는 여러 개의 항목을 저장한다는 속성과,
항목의 추가와 삭제 등을 수행하는 기능, 즉 메서드를 공유한다.
따라서 어떤 리스트를 만들더라도 append(), pop() 같은 리스트 메서드를 같은 방식으로 사용할 수 있다.
Vector 클래스의 인스턴스
아래 코드에서 변수 v에 Vector 클래스의 인스턴스인 Vector([1, 2, 3])이 할당된다.
Vector([1, 2, 3])는 리스트 [1, 2, 3]과 유사하지만 다르게 작동하는 벡터 객체를 가리킨다.
v = Vector([1, 2, 3])Vector([1, 2, 3])의 자료형은 Vector라고 확인된다.
type(v)__main__.Vector위 코드의 실행 결과에서 __main__.Vector의 __main__ 현재 파일을 모듈로 가리키는 표현이다.
따라서 __main__.Vector는 현재 파일에서 사용자가 직접 정의한 Vector 클래스를 가리킨다.
isinstanc() 함수
아래 코드는 변수 v가 가리키는 값(객체)이 Vector 클래스의 인스턴스임을,
즉 Vector 자료형임을 확인해준다.
isinstance(v, Vector)True14.2.3생성자: __init__() 메서드¶
Vector([1, 2, 3]) 객체 생성에 사용된 리스트 [1, 2, 3]은
Vector 클래스의 본문에서 가장 먼저 정의된 __init__() 메서드의
components 매개 변수의 인자로 전달된다.
def __init__(self, components):
self.components = tuple(float(x) for x in components)
self.shape = (len(self.components),)__init__() 메서드
클래스의 인스턴스를 생성할 때 __init__() 메서드가 가장 먼저 호출되어
객체 생성에 필요한 준비작업을 진행한다.
이런 의미에서 __init__() 메서드를 생성자라고 부른다.
앞서 설명한 대로 __init__()는 주로 생성되는 인스턴스의
인스턴스 변수 정의를, 즉 생성되는 객체의 속성을 지정하는 일을 수행한다.
예를 들어, Vector 클래스의 인스턴스를 정의하는 아래 코드를 실행한다고 가정하자.
v = Vector([1, 2, 3])그러면 파이썬 실행기는 내부에서 Vector 클래스의 __init__() 메서드를 아래 형식으로 호출한다.
__init__(v, [1, 2, 3])호출 과정에 사용되는 매개변수별 인자는 다음과 같다.
self=v: 생성되는 객체를 가리키는 변수self.components=[1, 2, 3]: 벡터의 항목으로 저장될 값들로 구성된 리스트
호출된 생성자는 self.components 인스턴스 변수에
벡터에 포함될 항목들의 튜플인 (1.0, 2.0, 3.0)을 할당하여 저장하고,
self.shape에는 생성되는 벡터의 모양을 기억하도록 한다.
아래 코드는 인스턴스 변수에 할당된 값을 확인하는 방법을 보여준다.
self. 대신 v.이 사용됨에 주의한다.
v = Vector([1, 2, 3])
print(f"{"Components:":11} {v.components}")
print(f"{"Shape:":11} {v.shape}")Components: (1.0, 2.0, 3.0)
Shape: (3,)
14.2.4인스턴스 변수¶
__init__() 메서드는 components 매개변수로 전달된 값을
self.components라는 변수가 가리키도록 한다.
반면 self.shape 변수는 self.components가 가리키는 벡터의 모양을 저장한다.
벡터의 모양은 항목의 개수를 이용해 (3,)처럼 길이가 1인 튜플로 표현된다.
이처럼 클래스 내부에서 정의되며 self.으로 시작하는 변수를
인스턴스 변수instance variable라 부른다.
인스턴스 변수에 저장된 값은 일반적으로 Vector([1, 2, 3])처럼 객체를 생성할 때 지정되며,
앞서 설명한 대로 생성된 객체의 속성으로 객체 자체에 저장된다.
즉 Vector([1, 2, 3])으로 객체를 만들면
그 객체는 자기 안에서 components에는 (1, 2, 3)을
shape에는 튜플 (3,)을 저장한다고 말할 수 있다.
self의 기능
self는 아래 설명처럼 “지금 만들어지는 객체” 또는 "지금 메서드를 실행하는 객체"를 가리킨다.
self.components: 생성되는 객체 안에 저장되는 값을 가리킨다.self.shape: 생성되는 객체 안에 저장되는 값을 가리킨다.__init__(self, components): 인스턴스 변수 지정 등 새로 객체 생성에 필요한 기초 작업을 진행한다.
주의사항
__init__() 메서드의 components 매개변수는 메서드 외부에서 들어오는 인자를 가리키는 변수인 반면에,
메서드 본문에서 정의되는 self.components의 components는 매개변수로 함수 본문에 전달되는 값을
생성되는 객체 내부에 저장하는 기능을 수행하는 다른 변수이다.
다만, __init__() 메서드 본문에서 정의되는 인스턴스 변수는 관례적으로
매개변수와 동일한 이름으로 정의되곤 한다.
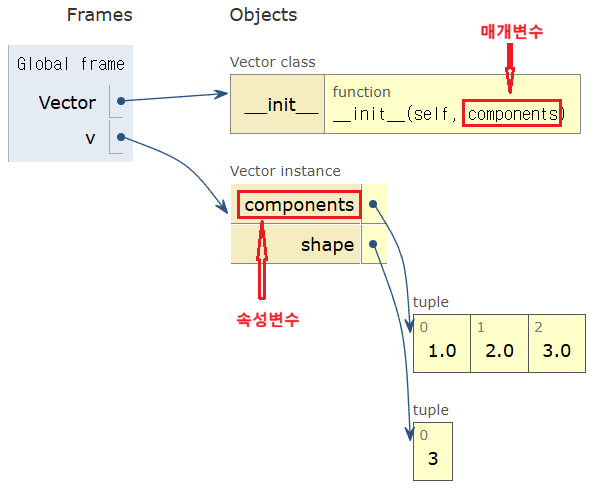
아래 v = Vector([1, 2, 3]) 변수 할당을 실행한 후의 메모리 상태를 보여주는 아래 이미지에서 볼 수 있듯이
인스턴스 변수로서의 components와 생성자 메서드의 매개변수로서의 components는 서로 다른 기능을 수행하는 독립된 두 개의 변수다.
14.2.5예제¶
예제 1
아래 코드 실행 후 v.components의 값이 (1.0, 2.0, 3.0)이 되는 이유를 설명하라.
v = Vector([1, 2, 3])답:
Vector([1, 2, 3])을 실행하면 Vector 클래스의 __init__() 메서드가 호출된다.
이때 리스트 [1, 2, 3]이 components 매개변수의 인자로 전달된다.
def __init__(self, components):
self.components = tuple(float(x) for x in components)
self.shape = (len(self.components), )float(x) for x in components는 1, 2, 3을 각각 1.0, 2.0, 3.0으로 변환한다.
그리고 tuple() 함수가 이 값들을 튜플로 묶는다.
따라서 v.components는 (1.0, 2.0, 3.0)을 가리킨다.
예제 2
다음 두 벡터 객체를 생성한 다음, 두 객체의 속성이 서로 독립적으로 저장되는 이유를 __init__() 메서드와 연결하여 설명하라.
v = Vector([1, 2, 3])
w = Vector([10, 20])답:
v와 w는 같은 Vector 클래스를 이용하여 생성되지만, 서로 다른 인스턴스이다.
각 객체가 생성될 때마다 __init__() 메서드가 새로 호출되고,
self는 그때 생성되는 객체를 가리킨다.
v를 만들 때의self는v가 가리키는 객체이고,w를 만들 때의self는w가 가리키는 객체이다.
따라서 v.components와 w.components는 서로 다른 객체 안에 독립적으로 저장된다.
v = Vector([1, 2, 3])
w = Vector([10, 20])
print(v.components)
print(v.shape)
print(w.components)
print(w.shape)(1.0, 2.0, 3.0)
(3,)
(10.0, 20.0)
(2,)
예제 3
리스트 객체와 Vector 객체를 비교하라.
numbers = [1, 2, 3]
v = Vector([1, 2, 3])답:
numbers는 파이썬이 기본으로 제공하는 list 클래스의 인스턴스이고,
v는 사용자가 직접 정의한 Vector 클래스의 인스턴스이다.
numbers = [1, 2, 3]
v = Vector([1, 2, 3])
print(type(numbers))
print(type(v))
print(isinstance(numbers, list))
print(isinstance(v, Vector))<class 'list'>
<class '__main__.Vector'>
True
True
두 객체 모두 동일한 값을 항목으로 담고 있지만 자료형은 서로 다르다.
따라서 사용할 수 있는 속성과 메서드도 각 객체를 생성한 클래스에 따라 달라진다.
예를 들어 리스트는 append() 메서드로 항목을 추가할 수 있는 반면에
벡터는 그럴 수 없다.
리스트
append()메서드 사용 가능
numbers.append(4)
print('numbers:', numbers)numbers: [1, 2, 3, 4]
벡터는
append()메서드 사용 불가능
v.append(4)---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[14], line 1
----> 1 v.append(4)
AttributeError: 'Vector' object has no attribute 'append'예제 4
self.components와 components의 차이를 설명하라.
힌트: 하나는 인스턴스 변수이고, 다른 하나는 __init__() 메서드의 매개변수이다.
답:
components는 __init__() 메서드가 호출될 때 외부에서 전달된 인자를 받는 매개변수이다.
반면 self.components는 생성되는 객체 안에 저장되는 인스턴스 변수이다.
예를 들어 v = Vector([1, 2, 3])을 실행하면 [1, 2, 3]은 먼저 components에 전달된다.
그런 다음 self.components에 (1.0, 2.0, 3.0)이 저장된다.
메서드 실행이 끝나면 매개변수 components는 더 이상 직접 사용할 수 없지만,
self.components에 저장된 값은 v.components처럼 객체의 속성으로 계속 사용할 수 있다.
14.2.6연습문제¶
문제 1
학생 정보를 표현하는 Student 클래스를 정의하라.
Student 클래스는 다음 두 개의 인스턴스 변수를 가져야 하며,
학생 점수는 부동소수점으로 저장되어야 한다.
| 인스턴스 변수 | 설명 |
|---|---|
self.name | 학생 이름 |
self.score | 학생 점수 |
단, 클래스 본문에 __init__() 메서드만 정의하여 아래 코드가 작동하도록 해야 한다.
kgh = Student("김강현", 85)
print(kgh.name)
print(kgh.score)힌트: Student("김강현", 85) 처럼 Student 클래스의 인스턴스를 생성할 때
"김강현"과 85 두 개의 인자를 지정하려면
생성자 메서드가 def __init__(self, name, score): ... 헤더를 가져야 한다.
또한 함수 본문에서 name과 score 두 매개변수의 인자로 들어오는 값을 각각 서로 다른
인스턴스 변수로 저장해야 한다.
문제 2
아래 두 학생 객체를 생성한 후에 두 객체의 name, score 속성을 각각 출력하고, 두 객체가 서로 다른 학생 정보를 독립적으로 저장한다는 점을 설명하라.
kgh = Student("김강현", 85)
whang = Student("황현", 91)문제 3
Student 클래스를 수정하여 점수를 항상 정수로 저장하도록 하라.
예를 들어 아래 코드 실행 후 kgh.score는 정수 85가 되어야 한다.
kgh = Student("김강현", "85")힌트: int() 함수를 활용한다.
문제 4
Student 클래스를 수정하여 학생의 이름, 점수, 학년을 저장하도록 하라.
| 인스턴스 변수 | 설명 |
|---|---|
self.name | 학생 이름 |
self.score | 학생 점수 |
self.grade | 학생 학년 |
아래 코드가 작동해야 한다.
sewon = Student("남세원", 78, 2)
print(sewon.name)
print(sewon.score)
print(sewon.grade)힌트: Student("남세원", 78, 2) 처럼 Student 클래스의 인스턴스를 생성할 때 세 개의 인자를 지정하려면
생성자 메서드 __init__() 메서드는 self 이외에 세 개의 매개변수를 사용해야 한다.
14.3매직 메서드¶
매직 메서드magic methods는 클래스의 인스턴스가
특별한 문법과 함께 사용할 수 있도록 미리 정해 둔 이름의 메서드이다.
__init__() 생성자 메서드처럼 매직 메서드의 이름은 두 개의 밑줄로 감싸인다.
정의된 클래스에 기본으로 포함된 매직 메서드와 사용자가 직접 정의한 메서드의 목록은 dir() 함수를 이용하여 확인할 수 있다.
Vector 클래스의 경우 총 37개의 메서드를 지원하고 그 중에 concat()와 to_list()를 제외한 35개가 매직 메서드이다.
dir(Vector)['__add__',
'__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__firstlineno__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__len__',
'__lt__',
'__module__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rmul__',
'__setattr__',
'__sizeof__',
'__static_attributes__',
'__str__',
'__subclasshook__',
'__weakref__',
'concat',
'to_list']매직 메서드는 사용자가 정의한 클래스가 파이썬의 기본 문법과 자연스럽게 어울리도록 해 준다. 예를 들어 객체를 출력하거나, 길이를 구하거나, 인덱싱하거나, 연산자를 사용하는 동작은 각각 정해진 매직 메서드와 연결된다. 모든 매직 메서드는 각자 고유한 기능을 갖는다.
여기서는 Vector 클래스가 사용자가 기대하는 벡터다운 속성과 기능을 갖추도록 하는 데
필요한 매직 메서드 몇 개를 살펴보면서 매직 메서드의 개념을 소개한다.
14.3.1객체 출력¶
아래 코드에서 정의된 변수 v는 항목이 1.0, 2.0, 3.0인 벡터를 가리킨다.
v = Vector([1, 2, 3])v 변수가 가리키는 벡터를 출력하면 V([1.0, 2.0, 3.0])로 표현된다.
print(v)V([1.0, 2.0, 3.0])
위와 같이 출력되는 이유는 Vector 클래스의
__repr__() 메서드가 아래와 같이
V([...]) 형식의 문자열을 반환하도록 정의되었기 때문이다.
def __repr__(self):
return f"V({list(self.components)})"print(v) 명령문이 실행되면 파이썬 실행기는 먼저 v의 문자열 표현을 구한다.
이를 위해 Vector 클래스에는 __str__() 메서드가 정의되어 있지 않으므로,
파이썬은 대신 __repr__() 메서드를 활용한다.
이때 __repr__() 메서드는 아래 코드와 같이 호출할 수 있다.
self에 대한 인자를 따로 지정하지 않음에 주의한다.
이유는 메서드를 호출한 객체 v가 자동으로 self에 전달되기 때문이다.
v.__repr__()'V([1.0, 2.0, 3.0])'14.3.2벡터 길이¶
벡터는 여러 항목을 순서대로 저장하고, 항목의 개수를 확인하는 기능도 지원한다.
len(v)3len(v)가 호출되면 실제로는 Vector 클래스 본문에 정의된 __len__() 매직 메서드가
아래 코드처럼 호출된다.
def __len__(self):
return len(self.components)v.__len__()3__repr__()와 __len__() 두 매직 메서드의 경우처럼 self 매개변수에 대한
인자는 자동 지정되기에 self 자체는 무시되는 것처럼 보인다.
14.3.3벡터 인덱싱과 슬라이싱¶
순서 자료형으로 구상된 벡터의 항목을 추출하는 인덱싱과 슬라이싱은
__getitem__() 메서드가 지원한다.
def __getitem__(self, index):
return self.components[index]v의 1번 인덱스 항목은 2.0으로 잘 확인된다.
v[1]2.0파이썬 내부에서는 아래 코드가 대신 실행된다.
v.__getitem__(1)2.0__getitem__() 매직 메서드는 슬라이싱도 함께 지원한다.
이유는 index에 매개변수에 정수가 아니라 슬라이스 객체도 인자로 전달할 수 있기 때문이다.
아래 코드는 전체 항목을 슬라이싱한다.
v[:](1.0, 2.0, 3.0)슬라이싱 결과가 튜플 자료형인 이유는 components 속성이 튜플 자료형으로 저장되었기 때문이다.
14.3.4for 반복문¶
__getitem__() 메서드가 정의되어 있으면 아래 코드에서처럼 Vector 객체에 대해서도
for 반복문이 작동한다.
이유는 파이썬이 for 반복문을 실행할 때 객체의 항목을 0번 인덱스부터 차례대로 꺼내려고 시도하기 때문이다. Vector 클래스에 __getitem__() 메서드가 정의되어 있으므로 v[0], v[1], v[2]처럼 인덱싱을 이용해 항목을 하나씩 가져올 수 있고, 더 이상 가져올 항목이 없으면 반복을 멈춘다.
for component in v:
print(component)1.0
2.0
3.0
14.3.5벡터 연산¶
in 연산자
__getitem__() 메서드가 정의되어 있으면 아래 코드에서처럼 Vector 객체에 대해서도
in 연산자가 작동한다.
이유는 파이썬이 in 연산자를 실행할 때 객체의 항목을 차례대로 확인하기 때문이다.
Vector 클래스에 __getitem__() 메서드가 정의되어 있으면 파이썬은 v[0], v[1], v[2]처럼 인덱싱을 이용해 항목을 하나씩 꺼낼 수 있고, 그중 찾는 값과 같은 항목이 있으면 True를 반환한다. 더 이상 확인할 항목이 없을 때까지 찾지 못하면 False를 반환한다.
2.0 in vTrue__add__() 매직 메서드
두 개의 벡터 객체를 더하면 항목별로 더해진 값들로 구성된 벡터가 생성된다.
v = Vector([1, 2, 3])
w = Vector([10, 20, 30])
print(v + w)V([11.0, 22.0, 33.0])
항목별 덧셈 연산을 가능케 하는 매직 메서드는 __add__()이다.
def __add__(self, other):
if len(self.components) != len(other.components):
raise ValueError("벡터의 길이가 다름.")
return Vector(a + b for a, b in zip(self.components, other.components))v + w가 실행되는 파이썬 내부에서는 아래 코드가 실행된다.
v.__add__(w)V([11.0, 22.0, 33.0])즉, v 벡터의 __add__() 메서드를 이용하여 w 벡터와 항목별로 더해진 값들로 구성된
새로운 벡터가 생성된다.
여기서도 self에는 v가 자동 할당되기에 other에 w만 할당하면 되어
v.__add__(w) 표현식이 사용되었다.
객체의 메서드를 호출할 때 self에 대한 인자는 별도로 지정하지 않음에 주의한다.
서로 길이가 다른 두 벡터의 덧셈 연산은 허용되지 않으며,
ValueError를 벡터의 길이가 다르기 때문이라는 정보도 함께 출력한다.
이 또한 __add__() 메서드의 정의에 따른 결과이다.
u = Vector([1, 2])
v + u---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[28], line 2
1 u = Vector([1, 2])
----> 2 v + u
Cell In[5], line 17, in Vector.__add__(self, other)
15 def __add__(self, other):
16 if len(self.components) != len(other.components):
---> 17 raise ValueError("벡터의 길이가 다름.")
18 return Vector(a + b for a, b in zip(self.components, other.components))
ValueError: 벡터의 길이가 다름.__mul__()과 __rmul__() 매직 메서드
벡터와 정수의 곱셈은 모든 항목에 같은 정수를 곱하는 방식으로 작동하는데 이는 다음 두 함수가 담당한다.
def __mul__(self, scalar):
return Vector(x * scalar for x in self.components)
def __rmul__(self, scalar):
return self * scalar__mul__()메서드 담당: 벡터가 정수 왼쪽에 올 때.
v * 3V([3.0, 6.0, 9.0])v.__mul__(3)V([3.0, 6.0, 9.0])__rmul__()메서드 담당: 벡터가 정수 오른쪽에 올 때.__rmul__()의 반환값이self * scalar로 정의되어 있어서 스칼라의 위치를 바꾼 후mul()처럼 작동함.
2 * vV([2.0, 4.0, 6.0])v.__rmul__(2)V([2.0, 4.0, 6.0])14.3.6동일성 대 동등성¶
두 객체의 동일성identity은 두 객체가 동일한 메모리 주소에 저장되었는가에 따라 결정된다. 반면 두 객체의 동등성equality은 두 객체가 같은 값을 표현하는가에 따라 결정된다.
동일성 판단: is 연산자
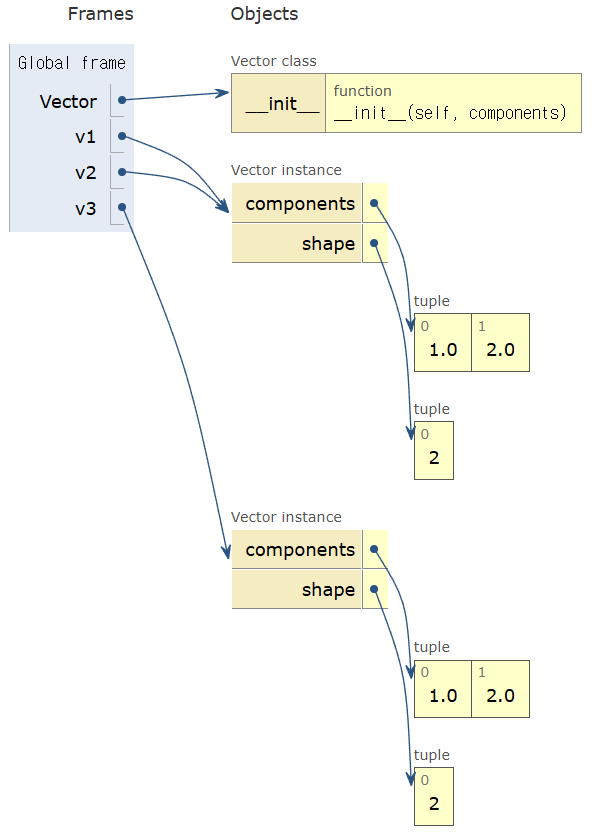
아래 코드에서 v2는 v1과 동일한 벡터를 가리킨다.
반면에 v3는 v1과 동일한 모양의 벡터를 가리킬 뿐이며 v1과 동일하지 않다.
v1 = Vector([1, 2])
v2 = v1
v3 = Vector([1, 2])
print(v1 is v2)
print(v1 is v3)True
False
동등성 판단: == 연산자
서로 다른 객체라도 내용이 같은지 판단하려면 __eq__() 메서드를 정의해야 한다.
== 연산자는 두 객체의 동등성을 판단할 때 사용되며,
사용자 정의 클래스에서는 __eq__() 메서드가 그 판단 기준을 정한다.
이처럼 두 객체가 같은 내용을 나타낼 때 두 객체가 동등하다라고 말한다.
두 벡터의 동등성 아래 __eq__() 메서드에 의해
두 튜플로서 동등하다고 정의된다.
이때 사용된 == 연산자는 튜플 클래스의 __eq__() 메서드에 기반하여 작동한다.
def __eq__(self, other):
return self.components == other.components아래 코드는 v1, v2, v3가 모두 동등함을 확인해준다.
print(v1 == v2)
print(v1 == v3)
print(v2 == v3)True
True
True
14.3.7예제¶
예제 1
아래 코드가 실행될 때 실제로 호출되는 Vector 클래스의 매직 메서드는 무엇인가?
v = Vector([2, 4, 6])
print(v)답:
print(v)가 실행될 때 v의 문자열 표현을 구하기 위해 __repr__() 메서드가 활용된다.
Vector 클래스에는 __str__() 메서드가 따로 정의되어 있지 않으므로 __repr__()이 대신 사용된다.
v = Vector([2, 4, 6])__init__() 메서드가 항목을 모두 부동소수점으로 바꾸어 저장하므로 출력 결과는
V([2.0, 4.0, 6.0])이다.
print(v)
print(v.__repr__())V([2.0, 4.0, 6.0])
V([2.0, 4.0, 6.0])
예제 2
벡터 객체가 다음과 같이 정의되었다.
v = Vector([5, 10, 15, 20])아래 두 코드가 동일한 값을 반환하는 이유를 설명하라.
len(v)
v.__len__()답:
len(v)는 파이썬 내부에서 v.__len__()을 호출한다.
Vector 클래스의 __len__() 메서드는 components 튜플의 길이를 반환하도록 정의되어 있고,
v.components는 (5.0, 10.0, 15.0, 20.0)이므로 두 코드 모두 4를 반환한다.
v = Vector([5, 10, 15, 20])
print(len(v))
print(v.__len__())4
4
예제 3
아래 코드가 실행될 때 실제로 호출되는 매직 메서드는 무엇인가?
temperatures = Vector([18, 21, 19, 23])
temperatures[2]답:
인덱싱 표현식 temperatures[2]가 실행되면 __getitem__() 메서드가 호출된다.
인덱스 2가 index 매개변수의 인자로 전달된다.
temperatures.components는 (18.0, 21.0, 19.0, 23.0)이고,
2번 인덱스 항목은 19.0이다.
temperatures = Vector([18, 21, 19, 23])
print(temperatures[2])
print(temperatures.__getitem__(2))19.0
19.0
예제 4
아래 코드의 실행 결과를 예측하고, 슬라이싱 결과가 리스트가 아니라 튜플인 이유를 설명하라.
scores = Vector([70, 85, 90, 100])
scores[1:3]답:
슬라이싱 표현식 scores[1:3]도 __getitem__() 메서드를 이용한다.
이때 index에는 정수가 아니라 슬라이스 객체가 전달된다.
def __getitem__(self, index):
return self.components[index]scores.components가 튜플로 저장되어 있으므로 self.components[index]의 결과도 튜플이다.
따라서 실행 결과는 (85.0, 90.0)이다.
scores = Vector([70, 85, 90, 100])
print(scores[1:3])
print(scores.__getitem__(slice(1, 3)))(85.0, 90.0)
(85.0, 90.0)
예제 5
아래 for 반복문이 작동하는 이유를 설명하라.
daily_steps = Vector([3200, 5400, 4100])
for steps in daily_steps:
print(steps)답:
Vector 클래스에는 __getitem__() 메서드가 정의되어 있어서 파이썬은 0번 인덱스부터 차례대로 항목을 꺼내며 반복할 수 있다.
따라서 아래 코드는 3200.0, 5400.0, 4100.0을 차례대로 출력한다.
daily_steps = Vector([3200, 5400, 4100])
for steps in daily_steps:
print(steps)3200.0
5400.0
4100.0
예제 6
아래 두 코드가 같은 결과를 반환하는 이유를 설명하라.
sales_monday = Vector([12, 8, 15])
sales_tuesday = Vector([10, 11, 9])
sales_monday + sales_tuesday
sales_monday.__add__(sales_tuesday)답:
+ 연산자는 왼쪽 객체의 __add__() 메서드를 호출한다.
따라서 sales_monday + sales_tuesday는 내부적으로 sales_monday.__add__(sales_tuesday)처럼 작동한다.
__add__() 메서드는 같은 위치의 항목끼리 더한 뒤 새 Vector 객체를 생성한다.
따라서 두 코드 모두 V([22.0, 19.0, 24.0])를 반환한다.
sales_monday = Vector([12, 8, 15])
sales_tuesday = Vector([10, 11, 9])
print(sales_monday + sales_tuesday)
print(sales_monday.__add__(sales_tuesday))V([22.0, 19.0, 24.0])
V([22.0, 19.0, 24.0])
예제 7
아래 코드를 실행하면 어떤 오류가 발생하는가? 왜 그런 오류가 필요한가?
morning = Vector([18, 20, 21])
afternoon = Vector([24, 26])
morning + afternoon답:
morning은 항목이 3개이고 afternoon은 항목이 2개이다.
__add__() 메서드는 두 벡터의 길이가 다르면 ValueError를 발생시키도록 정의되어 있다.
따라서 아래 코드를 실행하면 ValueError: 벡터의 길이가 다름. 오류가 발생한다.
벡터 덧셈은 같은 위치의 항목끼리 더하는 연산이므로 두 벡터의 길이가 같아야 한다.
길이가 다른 벡터의 덧셈을 막아야 잘못된 계산을 피할 수 있다.
try:
morning = Vector([18, 20, 21])
afternoon = Vector([24, 26])
morning + afternoon
except:
print("두 벡터의 길이가 다릅니다.")두 벡터의 길이가 다릅니다.
예제 8
아래 두 코드가 모두 작동하는 이유를 __mul__()과 __rmul__() 메서드와 연결하여 설명하라.
discounts = Vector([5, 10, 15])
discounts * 2
2 * discounts답:
discounts * 2처럼 벡터가 왼쪽에 있으면 __mul__() 메서드가 호출된다.
반대로 2 * discounts처럼 벡터가 오른쪽에 있으면 __rmul__() 메서드가 호출된다.
__mul__()은 모든 항목에 스칼라를 곱한 새 벡터를 반환한다.
__rmul__()은 return self * scalar로 정의되어 있으므로 다시 __mul__()을 이용한다.
따라서 두 곱셈 모두 V([10.0, 20.0, 30.0])를 반환한다.
discounts = Vector([5, 10, 15])
print(discounts * 2)
print(discounts.__mul__(2))
print(2 * discounts)
print(discounts.__rmul__(2))V([10.0, 20.0, 30.0])
V([10.0, 20.0, 30.0])
V([10.0, 20.0, 30.0])
V([10.0, 20.0, 30.0])
예제 9
아래 코드에서 first is third는 False이지만 first == third는 True이다. 그 이유를 동일성과 동등성의 차이로 설명하라.
first = Vector([7, 14])
second = first
third = Vector([7, 14])
print(first is second)
print(first is third)
print(first == third)답:
is 연산자는 두 변수가 같은 객체를 가리키는지, 즉 동일성을 판단한다.
== 연산자는 두 객체가 같은 값을 표현하는지, 즉 동등성을 판단한다.
second = first는 새 벡터를 만들지 않고 second가 first와 같은 객체를 가리키게 한다.
그래서 first is second는 True이다.
반면 third = Vector([7, 14])는 새 객체를 생성하므로 first is third는 False이다.
하지만 두 객체의 components 값이 같기 때문에 __eq__() 메서드에 의해 first == third는 True이다.
first = Vector([7, 14])
second = first
third = Vector([7, 14])
print(first is second)
print(first is third)
print(first == third)True
False
True
예제 10
아래 코드의 실행 결과를 예측하고, 왜 그렇게 되는지 설명하라.
Vector([3, 6]) == Vector([3.0, 6.0])답:
실행 결과는 True이다.
Vector([3, 6]) == Vector([3.0, 6.0])TrueVector 객체가 생성될 때 __init__() 메서드는 모든 항목을 float 자료형으로 변환하여 저장한다.
따라서 Vector([3, 6])의 components는 (3.0, 6.0)이고,
Vector([3.0, 6.0])의 components도 (3.0, 6.0)이다.
== 연산자는 __eq__() 메서드를 호출하고,
__eq__() 메서드는 두 벡터의 components 튜플을 비교한다.
두 튜플이 같으므로 전체 비교 결과는 True이다.
14.3.8연습문제¶
문제 1
아래 Student 클래스에 __repr__() 메서드를 추가하라.
class Student:
def __init__(self, name, score):
self.name = name
self.score = int(score)Student("김강현", 85) 객체를 출력하면 다음과 같이 보이도록 한다.
Student: '김강현'문제 2
Student 클래스에 __eq__() 메서드를 추가하라.
단, 두 학생의 점수가 같으면 동등하다고 판단해야 한다.
kgh1 = Student("김강현", 85)
kgh2 = Student("김강현", 95)
whang = Student("황현", 85)
print(kgh1 == kgh2) # False
print(kgh1 == whang) # True문제 3
Student 클래스에 __len__() 메서드를 추가하라.
단, len() 함수가 학생 이름의 글자 수를 반환하도록 한다.
kgh = Student("김강현", 85)
print(len(kgh)) # 3문제 4
Student 클래스에 __lt__() 메서드를 추가하라.
< 연산자가 두 학생의 점수를 기준으로 작동하도록 한다.
kgh = Student("김강현", 85)
whang = Student("황현", 91)
print(kgh < whang) # True
print(whang < kgh) # False힌트: __lt__()는 '작다’를 의미한다.
문제 5
Student 클래스에 __add__() 메서드를 추가하라.
두 학생 객체를 더하면 두 학생의 평균 점수를 반환하도록 한다.
kgh = Student("김강현", 85)
whang = Student("황현", 91)
print(kgh + whang) # 88.0문제 6
Student 클래스에 __bool__() 메서드를 추가하라.
학생의 점수가 60점 이상이면 True, 60점 미만이면 False로 판단되도록 한다.
kgh = Student("김강현", 85)
sewon = Student("남세원", 55)
print(bool(kgh)) # True
print(bool(sewon)) # False문제 7
Student 클래스에 __getitem__() 메서드를 추가하라.
인덱스 0은 학생 이름을, 인덱스 1은 학생 점수를 반환하도록 한다.
kgh = Student("김강현", 85)
print(kgh[0]) # 김강현
print(kgh[1]) # 85문제 8
문제 7의 __getitem__() 메서드를 이용하면 아래 for 반복문이 작동한다.
kgh = Student("김강현", 85)
for item in kgh:
print(item)위 코드가 이름과 점수를 차례대로 출력하는 이유를 설명하라.
14.4인스턴스 메서드¶
각각의 매직 메서드는 고유하면서도 정해진 기능을 수행한다. 반면 클래스 고유의 기능은 사용자가 정의한 속성과 메서드에 의해 결정된다. 이때 클래스 본문에서 정의되어, 해당 클래스의 인스턴스를 통해 호출되는 메서드를 인스턴스 메서드instance method라 부른다.
인스턴스 메서드 또한 첫 번째 매개변수로 self를 사용하며,
self는 해당 메서드를 호출한 인스턴스를 전달받는 용도로 쓰인다.
Vector 클래스에는 다음과 같이 to_list(), concat() 두 개의 인스턴스 메서드가 정의되어 있다.
def to_list(self):
return list(self.components)
def concat(self, other):
return Vector(list(self.components) + list(other.components))to_list() 인스턴스 메서드
튜플을 리스트로 변환한다.
인스턴스 메서드에 대해서도 self에 대한 인자는 생략한다.
v = Vector([1, 2, 3])
v_list = v.to_list()
print(v_list)
type(v_list)[1.0, 2.0, 3.0]
listv.to_list()를 호출하면 파이썬 내부에서는 아래 코드가 실행된다.
즉, self 매개변수에 v가 할당된다.
v.to_list()[1.0, 2.0, 3.0]concat() 인스턴스 메서드
두 개의 튜플을 이어붙인다. 리스트에 대한 + 연산과 유사하게 작동한다.
v = Vector([1, 2, 3])
w = Vector([10, 20, 30])
v.concat(w)V([1.0, 2.0, 3.0, 10.0, 20.0, 30.0])v.concat(w)를 호출하면 파이썬 내부에서 아래 코드가 실행된다.
self 매개변수에 대한 인자는 v가 자동으로 지정되기에
other 매개변수에 대한 인자인 w만 사용된다.
v.concat(w)V([1.0, 2.0, 3.0, 10.0, 20.0, 30.0])14.4.1예제¶
예제 1
Vector 클래스의 to_list() 인스턴스 메서드는 벡터의 항목을 리스트로 변환하여 반환한다.
아래 코드의 실행 결과를 예측하고, to_list() 메서드가 어떤 값을 반환하는지 설명하라.
scores = Vector([70, 85, 90])
scores.to_list()답:
to_list() 메서드는 components 속성에 저장된 튜플을 리스트로 변환하여 반환한다.
따라서 실행 결과는 모든 항목이 부동소수점으로 변환된 [70.0, 85.0, 90.0]이다.
scores = Vector([70, 85, 90])
print(scores.components)
print(scores.to_list())(70.0, 85.0, 90.0)
[70.0, 85.0, 90.0]
예제 2
to_list() 메서드가 반환한 리스트를 수정해도 원래 벡터 객체의 components 속성이 바뀌지 않는 이유를 설명하라.
scores = Vector([70, 85, 90])
score_list = scores.to_list()
score_list.append(100)
print(score_list)
print(scores.components)답:
to_list() 메서드는 components 튜플 자체를 반환하지 않고,
list(self.components)로 만든 새로운 리스트를 반환한다.
따라서 반환된 리스트를 수정해도 원래 벡터의 components 속성은 바뀌지 않는다.
scores = Vector([70, 85, 90])
score_list = scores.to_list()
score_list.append(100)
print(score_list)
print(scores.components)[70.0, 85.0, 90.0, 100]
(70.0, 85.0, 90.0)
예제 3
Vector 클래스의 concat() 인스턴스 메서드는 두 벡터를 이어붙인 새 벡터 객체를 반환한다.
아래 코드의 실행 결과를 예측하고, concat() 메서드가 + 연산자와 어떻게 다른지 설명하라.
morning = Vector([18, 20, 21])
afternoon = Vector([24, 26])
temperatures = morning.concat(afternoon)
print(temperatures)답:
+ 연산자는 같은 위치의 항목끼리 더하는 벡터 덧셈을 수행하지만,
concat() 메서드는 두 벡터의 항목을 순서대로 이어붙이며, 두 벡터의 길이가 달라도 작동한다.
따라서 morning.concat(afternoon)은 morning 벡터의 항목 뒤에 afternoon 벡터의 항목을 이어붙인
새 Vector 객체를 반환한다.
morning = Vector([18, 20, 21])
afternoon = Vector([24, 26])
temperatures = morning.concat(afternoon)
print(temperatures)V([18.0, 20.0, 21.0, 24.0, 26.0])
예제 4
아래 두 코드의 실행 결과가 서로 다른 이유를 설명하라.
v = Vector([1, 2])
w = Vector([10, 20])
print(v + w)
print(v.concat(w))힌트: + 연산자는 같은 위치의 항목끼리 더하고, concat() 메서드는 두 벡터의 항목을 이어붙인다.
답:
v + w는 __add__() 메서드를 호출하여 같은 위치의 항목끼리 더한다.
반면 v.concat(w)는 concat() 메서드를 호출하여 두 벡터의 항목을 이어붙인다.
v = Vector([1, 2])
w = Vector([10, 20])
print(v + w)
print(v.concat(w))V([11.0, 22.0])
V([1.0, 2.0, 10.0, 20.0])
예제 5
아래 코드에서 all_scores는 어떤 값을 가리키는가?
midterm = Vector([80, 75, 90])
final = Vector([85, 88, 92])
all_scores = midterm.concat(final).to_list()concat() 메서드와 to_list() 메서드가 어떤 순서로 호출되는지 설명하라.
답:
all_scores는 중간고사 점수 벡터와 기말고사 점수 벡터를 이어붙인 뒤,
그 결과를 리스트로 변환한 값을 가리킨다.
midterm = Vector([80, 75, 90])
final = Vector([85, 88, 92])
all_scores = midterm.concat(final).to_list()
print(all_scores)[80.0, 75.0, 90.0, 85.0, 88.0, 92.0]
실행 순서는 다음과 같다.
midterm.concat(final)이 먼저 실행되어V([80.0, 75.0, 90.0, 85.0, 88.0, 92.0])를 반환한다.이어서 반환된 벡터 객체의
to_list()메서드가 호출된다.최종적으로
all_scores는[80.0, 75.0, 90.0, 85.0, 88.0, 92.0]를 가리킨다.
이처럼 메서드 호출의 결과에 다시 메서드를 이어서 호출하는 방식을 메서드 체이닝이라 부른다.
14.4.2연습문제¶
Student 클래스가 다음과 같다.
class Student:
def __init__(self, name, score):
self.name = name
self.score = int(score)
def __repr__(self):
return f"Student: {self.name!r}"
def __eq__(self, other):
return self.score == other.score
def __len__(self):
return len(self.name)
def __lt__(self, other):
return self.score < other.score
def __add__(self, other):
return (self.score + other.score) / 2
def __bool__(self):
return self.score >= 60
def __getitem__(self, index):
if index == 0:
return self.name
elif index == 1:
return self.score
else:
raise IndexError("인덱스는 0 또는 1만 허용.")이어지는 문제들에서 요구하는 기능을 수행하는 인스턴스 메서드를 Student 클래스에 하나씩 추가하라.
문제 1
Student 클래스에 grade() 인스턴스 메서드를 추가하라.
grade() 메서드는 점수에 따라 다음 문자열을 반환해야 한다.
| 점수 | 반환값 |
|---|---|
| 90점 이상 | "A" |
| 80점 이상 90점 미만 | "B" |
| 70점 이상 80점 미만 | "C" |
| 60점 이상 70점 미만 | "D" |
| 60점 미만 | "F" |
whang = Student("황현", 91)
print(whang.grade()) # A문제 2
Student 클래스에 update_score(new_score) 인스턴스 메서드를 추가하라.
update_score() 메서드는 학생의 점수를 new_score로 변경해야 한다.
단, 새 점수는 정수로 저장되어야 한다.
kgh = Student("김강현", 85)
kgh.update_score("95")
print(kgh.score) # 95문제 3
Student 클래스에 is_better_than(other) 인스턴스 메서드를 추가하라.
is_better_than() 메서드는 현재 학생의 점수가 다른 학생의 점수보다 높으면 True,
그렇지 않으면 False를 반환해야 한다.
kgh = Student("김강현", 85)
whang = Student("황현", 91)
print(kgh.is_better_than(whang)) # False
print(whang.is_better_than(kgh)) # True문제 4
Student 클래스에 score_gap(other) 인스턴스 메서드를 추가하라.
score_gap() 메서드는 현재 학생과 다른 학생의 점수 차이를 반환해야 한다.
단, 점수 차이는 항상 0 이상의 정수로 반환되어야 한다.
kgh = Student("김강현", 85)
whang = Student("황현", 91)
print(kgh.score_gap(whang)) # 6
print(whang.score_gap(kgh)) # 6문제 5
Student 클래스에 summary() 인스턴스 메서드를 추가하라.
summary() 메서드는 학생의 이름, 점수, 통과 여부를 포함하는 문자열을 반환해야 한다.
통과 여부는 60점 이상이면 "통과", 아니면 "미통과"로 표시한다.
kgh = Student("김강현", 85)
sewon = Student("남세원", 55)
print(kgh.summary()) # 김강현: 85점, 통과
print(sewon.summary()) # 남세원: 55점, 미통과14.5종합 연습문제¶
기말시험 성적 분석
한 학생이 다섯 과목에서 받은 기말시험 점수를 하나의 Vector 객체로 관리하려 한다.
앞에서 정의한 Student 클래스는 score를 정수 하나로 저장했다.
이번 종합 연습문제에서는 score를 Vector 객체로 저장하도록 Student 클래스
를 새로 정의한다.
이어지는 문제를 순서대로 해결하면 마지막 문제에서 5명 학생의 전체 성적표가 완성된다. 전체 성적표는 학생별, 과목별 평균 및 등수가 포함된다.
과목의 순서는 다음과 같다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 과목 | 국어 | 영어 | 수학 | 과학 | 정보 |
문제 1: 여러 과목의 점수를 저장하는 Student 클래스
아래 Student 클래스의 __init__() 메서드를 완성하라.
name속성은 학생의 이름을 저장한다.score속성은 전달받은 다섯 과목의 점수로 만든Vector객체를 저장한다.__repr__()메서드는 학생 이름과 점수 벡터를 확인할 수 있는 문자열을 반환한다.
Student("김강현", [88, 76, 92, 85, 90])처럼 리스트를 인자로 사용해도
score 속성에는 Vector 객체가 저장되어야 한다.
class Student:
def __init__(self, name, scores):
self.name = _____
self.score = _____
def __repr__(self):
return f"Student({self.name!r})"
student = Student("김강현", [88, 76, 92, 85, 90])
print(student)
print(type(student.score)) # Vector문제 2: 다섯 명의 학생 객체 생성
다음 기말시험 점수를 이용하여 다섯 개의 Student 객체를 생성한 다음 students 리스트에 저장하라.
| 이름 | 국어 | 영어 | 수학 | 과학 | 정보 |
|---|---|---|---|---|---|
| 김강현 | 88 | 76 | 92 | 85 | 90 |
| 황현 | 95 | 89 | 84 | 91 | 87 |
| 남세원 | 72 | 81 | 78 | 74 | 80 |
| 이단아 | 90 | 93 | 96 | 88 | 94 |
| 박하늘 | 84 | 85 | 80 | 86 | 82 |
반복문으로 각 학생을 출력하여 이름과 다섯 점수가 올바르게 저장되었는지 확인하라.
subjects = ["국어", "영어", "수학", "과학", "정보"]
students = [
Student("김강현", [88, 76, 92, 85, 90]),
# 나머지 네 학생을 추가하라.
]
for student in students:
print(student)문제 3: 한 학생의 과목별 점수 확인
Vector 객체는 인덱싱을 지원한다. 첫 번째 학생의 이름과 과목별 점수를 다음 형식으로 출력하라.
김강현
국어: 88.0
영어: 76.0
수학: 92.0
과학: 85.0
정보: 90.0힌트: zip(subjects, students[0].score)를 이용하면 과목명과 점수를 함께 꺼낼 수 있다.
student = students[0]
print(_____)
for subject, score in zip(_____, _____):
print(f"{subject}: {score}")문제 4: 학생별 전체 평균 계산
Student 클래스에 다섯 과목의 평균을 반환하는 average() 인스턴스 메서드를 추가하라.
Vector 객체는 반복할 수 있으므로 sum() 함수의 인자로 사용할 수 있다.
def average(self):
# 다섯 과목 점수의 합을 과목 수로 나누어 반환한다.메서드를 추가한 다음 모든 학생의 이름과 평균을 소수점 둘째 자리까지 출력하라.
김강현의 평균은 86.20이어야 한다.
# 문제 1의 Student 클래스에 average() 메서드를 추가한 다음
# 문제 2의 students 리스트를 다시 생성하라.
for student in students:
print(f"{student.name}: {student.average():.2f}")문제 5: 전체 평균 기준 등수 계산
sorted() 함수와 average() 메서드를 이용하여 학생들을 전체 평균의 내림차순으로 정렬하라.
정렬된 학생들을 enumerate(..., start=1)로 순회하며 등수, 이름, 평균을 출력한다.
힌트:
sorted(students, key=lambda student: student.average(), reverse=True)평균이 가장 높은 학생은 이단아이고, 가장 낮은 학생은 남세원이어야 한다.
overall_ranking = sorted(_____)
for rank, student in enumerate(_____, start=1):
print(f"{rank}등 {student.name}: {student.average():.2f}")문제 6: 과목별 평균 계산
다섯 학생의 특정 과목 점수를 더한 뒤 학생 수로 나누어 과목 평균을 구하라. 먼저 국어 점수의 평균을 계산하고, 같은 방식을 반복문으로 확장하여 다섯 과목의 평균을 모두 출력하라.
힌트: student.score[subject_index]는 한 학생의 특정 과목 점수이다.
국어 평균은 85.80, 영어 평균은 84.80이어야 한다.
subject_averages = []
for subject_index, subject in enumerate(subjects):
total = sum(_____ for student in students)
average = _____
subject_averages.append(average)
print(f"{subject}: {average:.2f}")문제 7: 선택한 과목의 학생 등수 계산
과목을 인자로 받아 해당 과목의 학생 등수를 출력하는 print_subject_ranking() 함수를 완성하라.
함수를 이용하여 수학과 정보 과목의 등수를 각각 출력하라.
두 과목 모두 이단아가 1등이어야 한다.
힌트: sorted() 함수의 key 키워드 인자로 지정되는 함수가 각 학생의 해당 과목의 점수를 반환하도록 작성한다.
def print_subject_ranking(subject):
subject_index = subjects.index(subject)
ranking = sorted(
students,
key=lambda student: _____,
reverse=True,
)
print(f"[{subject} 등수]")
for rank, student in enumerate(ranking, start=1):
score = _____
print(f"{rank}등 {student.name}: {score:.0f}점")
print_subject_ranking('수학') # 수학 등수
print()
print_subject_ranking('정보') # 정보 등수문제 8: 전체 성적표 완성
지금까지 계산한 내용을 이용하여 다음 항목을 포함하는 최종 성적표를 출력하라.
각 학생의 이름과 다섯 과목 점수
각 학생의 전체 평균과 전체 등수
다섯 과목의 과목별 평균
사용자가 선택한 한 과목의 학생별 등수
먼저 전체 평균 등수를 이름과 연결하는 overall_rank 사전을 만든다.
overall_rank = {
student.name: rank
for rank, student in enumerate(overall_ranking, start=1)
}그런 다음 학생별 정보를 한 줄씩 출력하여 5명 학생의 기말시험 성적표를 완성하라.
이 문제를 해결하면 Vector는 여러 과목 점수의 저장과 계산을 담당하고,
Student는 이름과 한 학생의 성적을 하나의 객체로 관리한다는 역할 분담을 확인할 수 있다.
overall_rank = {
student.name: rank
for rank, student in enumerate(overall_ranking, start=1)
}
print("[기말시험 성적표]")
for student in students:
scores = ", ".join(f"{score:.0f}" for score in student.score)
print(
f"{student.name}: {scores} | "
f"평균 {student.average():.2f} | "
f"전체 {overall_rank[student.name]}등"
)
print("\n[과목별 평균]")
for subject, average in zip(subjects, subject_averages):
print(f"{subject}: {average:.2f}")
print()
print_subject_ranking('국어') # 국어 등수