아래 표에 여섯 명의 이름, 전화번호, 나이, 키, 출생지 정보가 담겨 있다.
| 이름 | 전화번호 | 나이 | 키 | 출생지 |
|---|---|---|---|---|
| 김강현 | 010-1234-5678 | 20 | 172.3 | 제주 |
| 황현 | 02-9871-1234 | 19 | 163.5 | 서울 |
| 남세원 | 010-3456-7891 | 21 | 156.7 | 경기 |
| 최흥선 | 070-4321-1111 | 21 | 187.2 | 부산 |
| 김현선 | 010-3333-8888 | 22 | 164.6 | 광주 |
| 함중아 | 010-7654-2345 | 18 | 178.3 | 강원 |
예를 들어 김강현, 최흥선 등의 전화번호를 알고 싶으면 이름 칸에서 김강현과 최흥선이 위치한 행을 찾아 전화번호를 확인하면 된다. 하지만 만약에 여섯 명이 아니라 수천, 수만명의 정보를 담겨 있다면 특정인의 전화번호, 나이, 키, 출생지 등을 확인하는 일이 매우 어려워진다. 반면에 컴퓨터는 이런 일을 매우 빠르고 정확하게 처리한다.
그런데 컴퓨터가 정보를 처리하도록 하려면 먼저 위 표의 내용을 하나의 값으로 저장해야 한다. 예를 들어, 아래 김강현의 데이터를 저장하는 것처럼 이름, 전화번호, 나이, 키, 출생지 각각을 하나의 변수에 저장할 수 있다.
kgh_name = '김강현'
kgh_phone = '010-1234-5678'
kgh_age = 20
kgh_height = 172.3
kgh_birthplace = '제주'그런데 이렇게 하면 저장해야 하는 사람의 수가 조금만 늘어나도 데이터를 제대로 관리할 수 없게 된다. 이런 경우에는 여러 개의 값을 하나로 묶어 처리하는 모음 자료형이 활용된다. 모음 자료형은 예를 들어 아래 질문에 대해 적절한 답변을 제공한다.
표에 언급된 여섯 명의 이름으로 구성된 목록을 하나의 값으로 다룰 수 있을까?
이름과 전화번호를 하나의 쌍으로 묶어서 전화번호부를 만든 다음에 이름을 입력하면 전화번호를 확인하는 프로그램을 작성할 수 있을까?
11.1파이썬 내장 자료 구조¶
아래 그림은 여러 개의 값을 하나의 값으로 묶어 처리할 수 있도록 도와주는 네 개의 내장 자료 구조built-in data structure를 표현한다. 여기서 내장built-in이라 함은 파이썬이 기본으로 제공한다는 의미이다. 반면에 자료 구조data structure는 여러 개의 값을 효율적으로 다룰 수 있도록 저장한 값을 가리킨다.
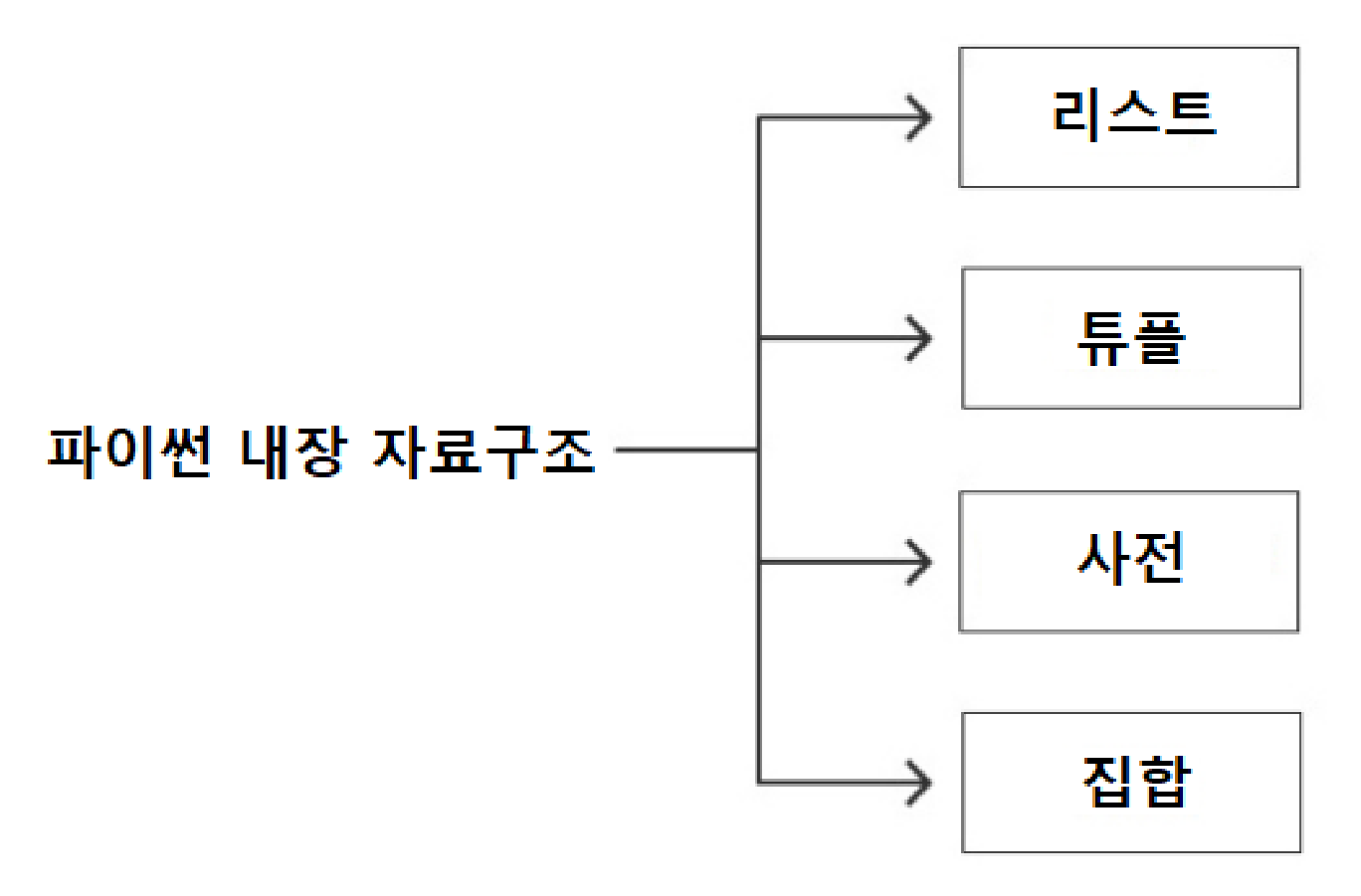
11.1.1모음 자료형 대 스칼라 자료형¶
리스트, 튜플, 사전, 집합은 각자 고유의 방식으로 여러 개의 값을 모아서 하나의 값으로 다룬다. 여러 개의 값을 모아 항목으로 포함한다는 의미에서 이들을 모음 자료형이라 부르며 경우에 따라 컬렉션collection, 컨테이너container 등으로도 불린다. 반면에 정수, 부동소수점, 불리언 등은 하나의 값으로만 구성되었다는 의미에서 스칼라scalar 자료형이라 부른다.
11.1.2모음 자료형 구분¶
모음 자료형을 일반적으로 다음 두 가지 기준으로 구분한다.
첫째, 항목의 순서와 중복 허용 여부
순차 자료형sequence type: 항목의 순서와 항목의 중복 사용 허용. 시퀀스sequences라고도 불림.
비순차 자료형non-sequence type: 항목의 순서와 중복된 항목 무시
둘째, 항목 변경의 허용 여부
가변 자료형mutable type: 항목의 추가, 삭제, 변경 등 허용됨
불변 자료형immutable type: 생성된 객체의 어떠한 변경도 불가능
리스트와 튜플은 모두 순서를 고려하는 순차 자료형이다. 문자열 1부에서 살펴 본 문자열 또한 순차 모음 자료형으로 간주된다. 반면에 리스트는 수정이 가능한 가변 자료형이지만 튜플은 불변 자료형이다. 그리고 사전과 집합은 비순차 자료형이면서 동시에 가변 자료형이다.
이번 장에서 리스트와 튜플, 즉 두 개의 순차(시퀀스) 자료형을 생성하고 활용하는 다양한 방식을 살펴본다.
11.2리스트¶
리스트의 항목이 반드시 동일한 자료형을 가질 필요는 없으며, 서로 다른 자료형의 항목이 사용될 수도 있다. 예를 들어 아래 리스트는 김강현과 황현의 이름, 전화번호, 나이, 키, 출생지로 구성된 리스트를 정의한다. 전화번호가 문자열로 지정되었음에 주의한다.
kgh = ['김강현', '010-1234-5678', 20, 172.3, '제주']whang = ['황현', '02-9871-1234', 19, 163.5, '서울']즉, 리스트의 자료형은 포함된 항목과 아무 상관없이 그냥 list 다.
type(kgh)list빈 리스트
빈 리스트는 아무것도 포함하지 않는 리스트를 의미한다. 다음 두 가지 방식으로 빈 리스트를 선언할 수 있다.
방법 1: 대괄호 활용
empty_list = []방법 2:
list()함수 활용
empty_list = list()중첩 리스트
임의의 값이 리스트의 항목으로 사용될 수 있다. 따라서 리스트가 다른 리스트의 항목으로 허용된다. 아래 코드는 김강현과 황현 두 사람의 정보로 구성된 길이가 2인 리스트를 정의한다.
kgh_whang = [kgh, whang] # 김강현, 황현 두 사람 정보확인하면 리스트의 리스트, 즉 중첩 리스트가 된다.
kgh_whang[['김강현', '010-1234-5678', 20, 172.3, '제주'],
['황현', '02-9871-1234', 19, 163.5, '서울']]kgh_whang이 가리키는 리스트에 포함된 항목의 개수, 리스트의 길이는 2다.
len(kgh_whang)2자료형은 여전히 list 다.
type(kgh_whang)list반면에 kgh와 whang 두 변수가 가리키는 리스트의 길이는 5다.
즉, 중첩 리스트의 길이는 항목으로 사용된 리스트의 길이와 무관하다.
len(kgh)5len(whang)5아래 코드에서 info_list는 나머지 4명의 정보도 항목으로 포함하는 (중첩) 리스트를 가리킨다.
sewon = ['남세원', '010-3456-7891', 21, 156.7, '경기']
choihs = ['최흥선', '070-4321-1111', 21, 187.2, '부산']
sjkim = ['김현선', '010-3333-8888', 22, 164.6, '광주']
ja = ['함중아', '010-7654-2345', 18, 178.3, '강원']
info_list = [kgh, whang, sewon, choihs, sjkim, ja]
info_list[['김강현', '010-1234-5678', 20, 172.3, '제주'],
['황현', '02-9871-1234', 19, 163.5, '서울'],
['남세원', '010-3456-7891', 21, 156.7, '경기'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['김현선', '010-3333-8888', 22, 164.6, '광주'],
['함중아', '010-7654-2345', 18, 178.3, '강원']]info_list 변수가 가리키는 리스트의 길이는 6이다.
len(info_list)611.2.1인덱싱과 슬라이싱¶
문자열, 리스트, 튜플 등 모든 시퀀스 자료형은 대괄호와 정수를 사용하는 인덱싱과 슬라이싱을 지원하며, 사용 방식도 거의 동일하다.
인덱싱
리스트 인덱싱은 정수 인덱스가 가리키는 위치의 항목을 확인하거나 수정할 때 사용한다.
예를 들어 김강현의 정보를 담은 리스트 kgh 에서 이름은 0번 인덱스에 위치한다.
print(kgh)['김강현', '010-1234-5678', 20, 172.3, '제주']
kgh[0]'김강현'김강현의 전화번호는 1번 인덱스에 위치한다.
kgh[1]'010-1234-5678'-1, -2, -3 등 음수 인덱스는 리스트 오른쪽에서부터 위치를 찾는다. 따라서 김강현의 출생지는 -1번 인덱스로 확인한다.
kgh[-1]'제주'-1번 인덱스는 리스트의 길이에서 1을 뺀 인덱스와 동일한 위치를 가리킨다. 즉, 다음이 성립한다.
kgh_last_index = len(kgh) - 1
kgh[kgh_last_index] == kgh[-1]True김강현의 키는 리스트의 오른쪽 끝에서 두 번째 항목이기에 -2번 인덱스로 확인된다.
kgh[-2]172.3리스트 수정
리스트는 항목을 수정할 수 있는 가변 자료형이며 인덱싱을 이용하여 특정 위치의 항목을 수정할 수 있다. 예를 들어 아래 코드는 김강현의 출생지를 제주가 아닌 제주시로 수정한다.
kgh[kgh_last_index] = '제주시' # kgh의 마지막 인덱스에 '제주시'를 수정물론 -1번 인덱스도 사용할 수 있다.
kgh[-1] = '제주시'김강현의 출생지 정보가 제주시로 변경되었다.
kgh['김강현', '010-1234-5678', 20, 172.3, '제주시']인덱스 허용 범위
리스트 인덱싱에 사용되는 인덱스는 리스트의 길이에 의해 결정된다.
예를 들어 김강현의 정보를 담은 리스트의 길이가 5이기 때문에
-5부터 4까지의 정수만 인덱싱에 허용된다.
지정된 범위를 벗어난 인덱스를 사용하면
지정된 인덱스의 범위를 벗어났다(list index out of range)는
설명과 함께 IndexError오류가 발생한다.
kgh[5]---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[23], line 1
----> 1 kgh[5]
IndexError: list index out of range슬라이싱
슬라이싱은 두 개의 인덱스로 지정된 구간에 포함된 항목들을 확인하거나 수정할 때 사용한다. 경우에 따라 몇 걸음씩 건너뛸지 지정하기도 한다.
시작 인덱스: 슬라이싱 구간 시작 인덱스. 생략되면 0을 기본값으로 사용.
끝 인덱스: 슬라이싱 구간 끝 인덱스. 이 인덱스 이전 인덱스까지 항목 확인. 생략되면 오른쪽 끝까지를 의미함.
보폭: 구간 시작부터 몇 개씩 건너뛰며 항목을 확인할 것인지 결정. 보폭이 1이면 생략 가능.
예를 들어 김강현의 이름, 전화번호, 나이, 키는 0번부터 3번 인덱스에 위치하기에
대괄호 안에 0:4를 입력하여 0번 인덱스부터 4번 인덱스 이전인 3번 인덱스의 항목으로
구성된 리스트가 확인된다.
kgh[0:4]['김강현', '010-1234-5678', 20, 172.3]보폭이 1인 경우와 동일하다.
kgh[0:4:1]['김강현', '010-1234-5678', 20, 172.3]시작 인덱스가 0이면 생략해도 된다. 단 콜론은 그대로 둬야 한다.
kgh[:4]['김강현', '010-1234-5678', 20, 172.3]슬라이싱의 결과는 항상 리스트이다. 구간의 크기가 1이라 해도 그렇다. 예를 들어 아래 코드는 김강현의 전화번호로만 구성되어 길이가 1인 리스트가 확인된다.
kgh[1:2]['010-1234-5678']보폭을 1보다 크게 지정하면 지정된 보폭만큼 건너 뛰며 항목을 확인한 결과를 리스트로 보여준다. 예를 들어 김강현의 전화번호와 키를 함께 확인하려면 1번과 3번 인덱스를 확인해야 하기에 다음과 같이 보폭을 2로 지정한다.
kgh[1:4:2]['010-1234-5678', 172.3]이름과 키를 확인하려면 0번부터 끝까지를 구간으로 하면서 보폭을 3으로 지정한다.
kgh[0::3]['김강현', 172.3]시작 인덱스를 생략해도 된다.
kgh[::3]['김강현', 172.3]리스트 전체를 대상으로 슬라이싱하려면 아래와 같이 한다.
kgh[:]['김강현', '010-1234-5678', 20, 172.3, '제주시']또는
kgh[::] # kgh 전체 대상 슬라이싱. 스텝은 1이 기본값.['김강현', '010-1234-5678', 20, 172.3, '제주시']슬라이싱에 리스트의 크기를 벗어나는 인덱스를 사용하더라도 오류가 발생하지 않는다. 대신 허용되는 인덱스의 구간에 대해서만 슬라이싱이 적용된다. 아래 코드는 5번 인덱스부터 9번 인덱스까지 확인하려 하지만 해당 인덱스의 위치를 찾을 수 없기에 빈 리스트를 생성한다.
kgh[5:10][]아래 코드는 0번 인덱스부터 7번 인덱스까지 확인하려 하지만 결국엔 4번 인덱스까지만 확인하게 된다.
kgh[0:8]['김강현', '010-1234-5678', 20, 172.3, '제주시']보폭을 2 이상으로 지정해도 허용된 인덱스의 범위를 벗어난 인덱스는 무시된다.
kgh[0:8:2]['김강현', 20, '제주시']역순 슬라이싱
슬라이싱은 기본적으로 작은 인덱스에서 큰 인덱스 방향으로 확인한다. 음수 보폭을 지정하면 큰 인덱스에서 작은 인덱스 방향으로 움직이는 역순 슬라이싱이 실행된다.
예를 들어, 아래 코드는 보폭이 -1이고, 시작 인덱스와 끝 인덱스를 생략하면 문자열 전체를 역순으로 확인한다. 이 기법은 리스트 항목들의 순서를 뒤집는 데에 자주 활용된다.
kgh[:: -1]['제주시', 172.3, 20, '010-1234-5678', '김강현']보폭이 음수이면서 시작 인덱스가 끝 인덱스보다 작으면 빈 리스트가 생성된다.
kgh[2:5:-1][]시작 인덱스가 끝 인덱스보다 크면 구간의 오른쪽부터 항목을 확인한다 점만 다를 뿐이다. 아래 코드는 -2번 인덱스부터 왼쪽으로 두 걸음씩 건너 뛰며 슬라이싱을 진행한다. 역순 인덱싱에서 끝 인덱스가 생략되면 왼쪽 끝까지를 의미힌다.
kgh[-2::-2][172.3, '010-1234-5678']리스트 구간 수정
슬라이싱을 이용하여 리스트의 지정된 구간을 다른 리스트로 대체할 수 있다. 아래 코드는 김강현의 키와 출생지를 동시에 수정한다.
kgh[3:] = [172.5, '제주']
kgh['김강현', '010-1234-5678', 20, 172.5, '제주']11.2.2중첩 리스트의 인덱싱/슬라이싱/반복문¶
중첩 리스트는 리스트의 항목 또한 리스트이기 때문에
항목의 항목을 확인/추출/변경 하려면 인덱싱, 슬라이싱, for 반복문을
연속적으로 또는중첩해서 적용해야 한다.
인덱싱 연속 적용
예를 들어 김강현의 이름은 info_list의 첫째 항목 리스트의 첫째 항목이다.
info_list[['김강현', '010-1234-5678', 20, 172.5, '제주'],
['황현', '02-9871-1234', 19, 163.5, '서울'],
['남세원', '010-3456-7891', 21, 156.7, '경기'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['김현선', '010-3333-8888', 22, 164.6, '광주'],
['함중아', '010-7654-2345', 18, 178.3, '강원']]김강현의 이름은 info_list의 0번 인덱스에 포함되어 있다.
따라서 먼저 김강현의 정보를 담은 리스트를 인덱싱으로 추출한다.
kgh_name = info_list[0]
kgh_name['김강현', '010-1234-5678', 20, 172.5, '제주']다시 0번 인덱스를 적용하면 김강현의 이름이 확인된다.
kgh_name[0]'김강현'인덱싱을 연속 적용하는 과정을 다음과 같이 줄여서 하나의 표현식으로 나타낼 수 있다.
info_list[0][0]'김강현'아래 코드는 유사한 방식으로 황현의 이름과 나이를 확인한다.
hwang_name = info_list[1][0]
hwang_age = info_list[1][2]
print(f"{hwang_name}의 나이: {hwang_age}세")황현의 나이: 19세
슬라이싱과 인덱싱 연속 적용
황현, 최흥선, 함중아만 대상으로 나이를 확인하려 한다.
그런데 세 사람의 정보는 info_list가 가리키는 리스트의 1번, 3번, 5번 인덱스에 위치한다.
info_list[1::2][['황현', '02-9871-1234', 19, 163.5, '서울'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['함중아', '010-7654-2345', 18, 178.3, '강원']]아래 코드는 세 사람의 정보를 대상으로 for 반복문과 인덱싱을 인덱싱을 적용하면
세 사람의 나이 정보를 추출한다.
for person in info_list[1::2]:
print(f"{person[0]}:\t{person[2]}세")황현: 19세
최흥선: 21세
함중아: 18세
인덱싱과 슬라이싱 연속 적용
아래 코드는 4번 인덱스에 위치한 김현선의 이름, 전화번호, 나이를 확인한다.
info_list[4][:3]['김현선', '010-3333-8888', 22]중첩 반복문 활용
예제 1
중첩 for 반복문을 사용하여 6명 각자의 정보를 일일이 나열할 수 있다.
for person in info_list: # 6명 모두를 대상으로 반복
for item in person:
print(item) # 한 사람의 모든 정보 출력. 항목들 사이는 탭으로 구분
print() # 사람들 사이의 구분을 위해 줄 바꿈김강현
010-1234-5678
20
172.5
제주
황현
02-9871-1234
19
163.5
서울
남세원
010-3456-7891
21
156.7
경기
최흥선
070-4321-1111
21
187.2
부산
김현선
010-3333-8888
22
164.6
광주
함중아
010-7654-2345
18
178.3
강원
print() 함수의 end='\n' 키워드 옵션을 변경하여 한 사람의 정보를 한 줄에 출력할 수 있다.
for person in info_list:
for item in person:
print(item, end='\t') # 한 사람의 정보는 탭으로 구분
print() 김강현 010-1234-5678 20 172.5 제주
황현 02-9871-1234 19 163.5 서울
남세원 010-3456-7891 21 156.7 경기
최흥선 070-4321-1111 21 187.2 부산
김현선 010-3333-8888 22 164.6 광주
함중아 010-7654-2345 18 178.3 강원
예제 2
아래 코드는 나이가 21살인 사람의 정보만 출력한다.
for person in info_list:
if 21 == person[2]: # 나이가 21살인 사람만 선택
for item in person:
print(item, end='\t')
print()남세원 010-3456-7891 21 156.7 경기
최흥선 070-4321-1111 21 187.2 부산
예제 3
이름에 “현” 자가 포함된 사람의 정보만 출력하러면 다음과 같이 한다.
for person in info_list:
if '현' in person[0]: # 이름에 "현" 자가 포함된 사람만 선택
for item in person:
print(item, end='\t')
print()김강현 010-1234-5678 20 172.5 제주
황현 02-9871-1234 19 163.5 서울
김현선 010-3333-8888 22 164.6 광주
"현"으로 끝나는 경우만 다루려면 endswith() 문자열 메서드를 이용한다.
for person in info_list:
if person[0].endswith('현'): # 이름이 "현" 자로 끝나는 사람만 선택
for item in person:
print(item, end='\t')
print()김강현 010-1234-5678 20 172.5 제주
황현 02-9871-1234 19 163.5 서울
startswith() 문자열 메서드를 이용하여 김씨 성만 추출할 수도 있다.
for person in info_list:
if person[0].startswith('김'): # 김씨 성 정보만 선택
for item in person:
print(item, end='\t')
print()김강현 010-1234-5678 20 172.5 제주
김현선 010-3333-8888 22 164.6 광주
11.2.3리스트 메서드¶
모음 자료형의 기본 용도는 여러 개의 값을 모아 하나의 값으로 다루면서 필요에 따라 유용한 항목을 탐색하고 추출하는 기능이다. 문자열 2부에서 살펴 본 문자열 메서드처럼 리스트 자료형에 대해서만 사용할 수 있는 함수들인 리스트 메서드가 다양하게 제공된다.
문자열 자료형과는 달리 리스트는 변경을 허용하는 가변 자료형이기에 항목의 탐색뿐만 아니라 리스트 자체를 수정하는 항목의 추가와 삭제, 항목들의 정렬을 수행하는 메서드 또한 제공된다. 간단한 예제를 이용하여 리스트의 아래 표에 언급된 주요 리스트 메서드의 기능을 살펴 본다.
Table 1:리스트 주요 메서드
기능 | 메서드 | 설명 |
|---|---|---|
복사 |
| 리스트의 사본 반환 |
탐색 |
| 리스트에서 지정된 항목이 등장한 횟수 반환 |
| 지정된 항목이 처음 사용된 인덱스 반환 | |
추가/삽입/확장 |
| 리스트 끝에 항목 추가. 반환값은 |
| 지정된 인덱스에 항목 삽입. 반환값은 | |
| 다른 리스트를 연결하여 확장. 반환값은 | |
삭제 |
| 지정된 인덱스의 항목 삭제 후 반환. |
| 가장 왼쪽에 위치한 지정된 항목 삭제. 반환값은 | |
정렬 |
| 리스트의 항목을 크기 순으로 정렬. 반환값은 |
| 리스트의 항목들 순서 뒤집기. 반환값은 |
copy() 메서드
리스트는 가변 자료형이기에 인덱싱, 슬라이싱을 포함하여 이어서 소개하는 많은 메서드에 의해
수정될 수 있다.
따라서 경우에 따라 주어진 원본 리스트는 전혀 건드리지 않으면서 리스트를 이용할 필요가 있다.
그럴 때 copy() 메서드로 사본을 만들어 이용한다.
예를 들어, 아래 코드는 변수 x가 가리키는 리스트의 사본을 만들어 변수 y에 할당한다.
그 다음에 y가 가리키는 리스트의 0번 인덱스 항목을 수정하지만 변수 x가
가리키는 리스트는 전혀 변하지 않는다.
x = [1, 2, 3]
y = x.copy()
y[0] = 10 # 0번 인덱스 항목 수정
print("y:", y) # 수정됨
print("x:", x) # 불변y: [10, 2, 3]
x: [1, 2, 3]
아래 그림은 두 변수 x와 y가 선언된 순간의 메모리 상태를 보여준다.
x와 y가 동일하게 생겼지만 각각 서로 다른 리스트 객체를 가리킨다.

아래 그림은 y가 가리키는 리스트의 첫째 항목이 10으로 업데이트된 이후의 메모리 상태를 보여주며,
변수 x가 가리키는 리스트는 전혀 수정되지 않는다.

반면에 아래 코드에서처럼 사본을 만들지 않으면 리스트 원본이 함께 수정된다.
이유는 x와 y가 동일한 리스트 객체를 가리키기 때문이다.
x = [1, 2, 3]
y = x
y[0] = 10 # 0번 인덱스 항목 수정
print("x:", x) # 수정됨
print("y:", y) # 함께 수정됨x: [10, 2, 3]
y: [10, 2, 3]
아래 그림은 두 변수 x와 y가 선언된 순간의 메모리 상태를 보여준다.
x와 y가 동일한 리스트 객체를 가리킨다.

아래 그림은 y가 가리키는 리스트의 첫째 항목이 10으로 업데이트되면
x가 동일한 리스트를 가리키기에 0번 인덱스 항목이 똑같이 10이 된다.

중첩 리스트의 사본
copy() 메서드는 중첩 리스트에 대해서는 모든 것을 사본으로 만들지는 않는다.
설명을 위해 먼저 아래 코드를 이용한다.
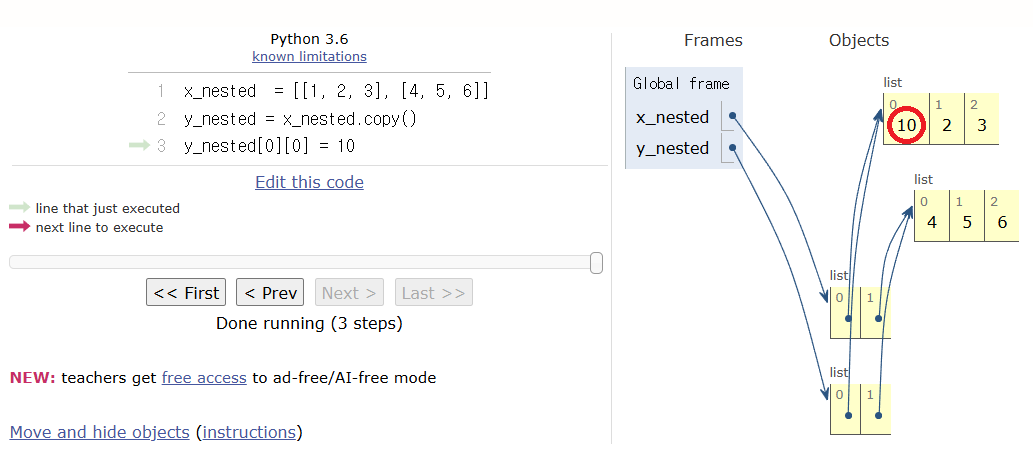
x_nested = [[1, 2, 3], [4, 5, 6]]
y_nested = x_nested.copy() # 얕은 복사로 x_nested의 항목 리스트는 복사하지만, 항목 리스트의 항목들은 복사하지 않음
y_nested[0][0] = 10 # 0번 인덱스 항목 수정
print("y_nested:", y_nested) # 수정됨
print("x_nested:", x_nested) # 함께 수정됨.y_nested: [[10, 2, 3], [4, 5, 6]]
x_nested: [[10, 2, 3], [4, 5, 6]]
위 코드에서 y_nested는 x_nested의 사본을 가리키지만 y_nested[0][0] 항목을 수정하니 x_nested[0][0] 역시 수정되었다.
이유는 리스트의 항목이 리스트인 경우는 사본이 생성되지 않기 때문이며,
아래 이미지가 위 코드의 실행 결과를 보여준다.
copy.deepcopy() 함수
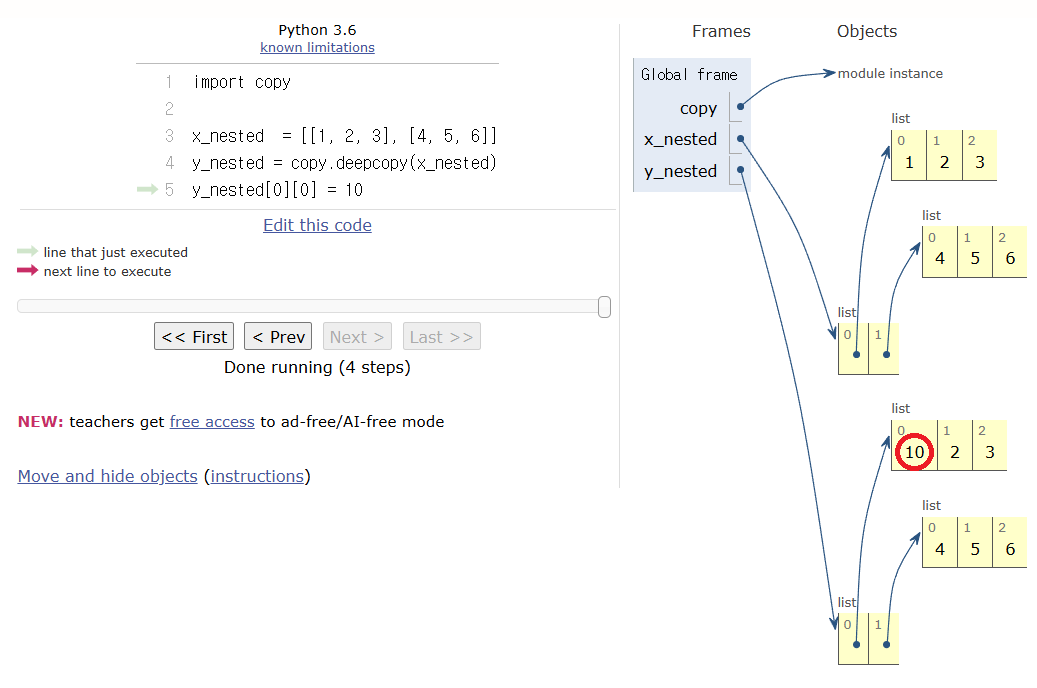
중첩 리스트의 항목까지 복제해서 사본을 만드려면 copy 모듈의 deepcopy() 함수를 활용한다.
아래 코드에서 확인할 수 있듯이 copy.deepcopy() 함수를 활용하면 완전히 독립된 사본이 생성된다.
import copy
x_nested = [[1, 2, 3], [4, 5, 6]]
y_nested = copy.deepcopy(x_nested) # 깊은 복사로 x_nested의 모든 항목 리스트도 복사
y_nested[0][0] = 10 # 0번 리스트의 0번 인덱스 항목 수정
print("y_nested:", y_nested) # 수정됨
print("x_nested:", x_nested) # 수정되지 않음. 항목 리스트도 불변y_nested: [[10, 2, 3], [4, 5, 6]]
x_nested: [[1, 2, 3], [4, 5, 6]]
아래 이미지가 위 코드의 실행 결과를 보여준다.
count() 메서드
인자로 지정된 항목이 리스트에 몇 번 사용되었는지를 반환한다.
예를 들어, [1, 2, 3, 1, 2]에 1과 2는 두 번, 3은 한 번 사용된다.
oneTwoThree = [1, 2, 3, 1, 2]oneTwoThree.count(1)2oneTwoThree.count(2)2oneTwoThree.count(3)1항목이 아니면 0을 반환한다.
oneTwoThree.count(4)0index() 메서드
인자로 지정된 항목이 위치한 인덱스를 반환한다.
항목이 여러 번 사용된 경우 가장 왼쪽에 위치한 곳의 인덱스를 선택한다.
예를 [1, 2, 3, 1, 2, 3]에서 2가 두 번 사용되었지만
1번 인덱스에서 가장 먼저 사용된다.
oneTwoThree.index(2)1반면에 3은 2번 인덱스에서 처음 사용된다.
oneTwoThree.index(3)2리스트의 항목으로 존재하지 않으면 ValueError 오류가 발생한다.
oneTwoThree.index(5)---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[65], line 1
----> 1 oneTwoThree.index(5)
ValueError: 5 is not in list참고로 문자열의 경우와는 다르게 리스트는 find() 메서드를 제공하지 않는다.
append() 메서드
리스트의 오른쪽 끝에 항목을 추가한다.
반환값은 None이다.
아래 코드는 oneTwoThree가 가리키는 리스트에 3을 추가한다.
oneTwoThree.append(3)반면에 oneTwoThree가 가리키는 리스트 자체가 수정되었다.
oneTwoThree[1, 2, 3, 1, 2, 3]아래 for 반복문은 1, 2, 3을 한 번씩 더 추가한다.
for i in range(1, 4):
oneTwoThree.append(i)oneTwoThree[1, 2, 3, 1, 2, 3, 1, 2, 3]insert() 메서드
insert() 메서드는 인덱스를 이용하여 특정 위치에 항목을 삽입한다.
반환값은 None이다.
항목이 삽입되면 원래 그 위치를 포함해서 오른쪽에 위치했던 항목들은
모두 한 칸씩 오른쪽으로 이동된다.
아래 코드는 1번 인덱스 자리에 2를 삽입하여 1부터 4까지의 정수로 구성된 리스트를 완성한다.
one2four = [1, 3, 4]
one2four.insert(1, 2) # 1번 인덱스에 2 삽입one2four[1, 2, 3, 4]아래 for 반복문은 4, 3, 2, 1을 차례대로 0번 인덱스에 추가한다.
for i in range(4, 0, -1):
one2four.insert(0, i)one2four[1, 2, 3, 4, 1, 2, 3, 4]extend() 메서드
append() 메서드는 기존의 리스트 오른쪽 끝에 하나의 항목을 추가한다.
반면에 extend() 메서드는 기존 리스트의 오른쪽 끝에 인자로 지정된 리스트를 연결한다.
반환값은 None이다.
아래 코드는 one2four가 가리키는 리스트에
[1, 2, 3, 4]를 연결한다.
one2four.extend([1, 2, 3, 4])one2four[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]참고로 + 연산자는 리스트 두 개를 이어붙여 완전히 새로운 리스트를 생성한다.
예를 들어 아래 코드는 one2four가 가리키는 리스트와 [1, 2, 3, 4]를 연결한 새로운 리스트를 생성한다.
one2four + [1, 2, 3, 4][1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]one2four가 가리키는 리스트는 수정되지 않았다.
one2four[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]pop() 메서드
pop() 메서드는 지정된 인덱스의 항목을 반환하는 동시에 리스트에서 삭제한다.
설명을 위해 one2four 변수를 계속 활용한다.
아래 코드는 3번 인덱스에 위치한 정수 4를 리스트에서 삭제하면서 동시에 반환한다.
four_index3 = one2four.pop(3)pop() 함수는 삭제된 항목을 반환한다.
four_index343번 인덱스의 항목인 4가 one2four에서 삭제되었다.
삭제된 항목의 오른쪽에 위치한 항목은 한 칸씩 왼쪽으로 이동한다.
one2four[1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4]one2four를 원래대로 되돌려 놓기 위해 insert() 메서드를 이용한다.
one2four.insert(3, four_index3)one2four[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]pop() 메서드의 인자를 지정하지 않으면 리스트의 마지막 항목이 삭제된 후 반환된다.
one2four.pop()4마지막 항목이기에 이번엔 append() 메서드로 원래대로 되돌린다.
one2four.append(4)one2four[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]remove() 메서드
remove() 메서드는 리스트에서 지정된 항목을 삭제할 뿐 해당 항목을 반환하진 않는다.
즉 None을 반환한다.
지정된 항목이 리스트에 여러 번 포함되었을 경우 가장 왼편에 위치한 항목을 삭제한다.
아래 코드는 1을 삭제한다.
one2four.remove(1)0번 인덱스에 있었던 1만 삭제되었다.
one2four[2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]삭제할 항목이 없으면 ValueError 오류가 발생한다.
one2four.remove(0)---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[88], line 1
----> 1 one2four.remove(0)
ValueError: list.remove(x): x not in listfor 반복문을 이용하여 2, 3, 4를 차례로 삭제하자.
for num in [2, 3, 4]:
one2four.remove(num)one2four[1, 2, 3, 4, 1, 2, 3, 4]sort() 메서드
리스트의 항목을 크기 순으로 정렬하는 방식으로 리스트를 수정한다.
즉, 리스트 자체가 수정되며, 반환값은 None이다.
예를 들어 아래 코드는 one2four의 항목을 크기 순으로 정렬한다.
one2four.sort()one2four[1, 1, 2, 2, 3, 3, 4, 4]reverse=True 키워드 인자를 지정하면 내림차순으로 정렬한다.
one2four.sort(reverse=True)one2four[4, 4, 3, 3, 2, 2, 1, 1]reverse() 메서드
단순히 리스트에 포함된 항목들의 순서를 뒤집는다.
반환값은 None이다.
설명을 위해 아래 리스트를 이용한다.
acbgf = ['a', 'c', 'b', 'g', 'f']아래 코드는 acbgf에 포함된 순서를 뒤집는다.
acbgf.reverse()acbgf['f', 'g', 'b', 'c', 'a']reverse() 메서드를 한 번 더 적용하면 원래 순서대로 돌아온다.
acbgf.reverse()acbgf['a', 'c', 'b', 'g', 'f']11.2.4예제¶
예제 1
num_list 변수 3중으로 중첩된 리스트를 가리킨다.
num_list = [[1, 2, 3, [4, 5]], [6, 7, 8], 9](1) num_list의 길이가 3임을 확인하라.
답:
len(num_list)3(2) 위 리스트에서 9를 확인하는 인덱싱 표현식을 정의하라.
답:
9는 num_list의 마지막 항목이다.
num_list[-1]9(3) 위 리스트에서 7을 확인하는 인덱싱 표현식을 정의하라.
답:
7은 1번 인덱스 항목인 리스트의 1번 항목으로 포함되어 있다.
num_list[1][6, 7, 8]따라서 다음과 같이 확인한다.
num_list[1][1]7(4) 위 리스트에서 [3, [4, 5]]를 확인하는 인덱싱/슬라이싱 표현식을 정의하라.
답:
[3, [4, 5]]는 1번 항목의 부분 리스트이다.
num_list[0][1, 2, 3, [4, 5]]2번부터 시작하는 슬라이싱을 사용하면 된다.
num_list[0][2:4][3, [4, 5]]또는
num_list[0][2:][3, [4, 5]]예제 2
리스트에 중복된 항목이 있는지 여부를 판단하는 has_duplicates() 함수를 구현하라.
힌트: 리스트의 in 연산자와 append() 메서드를 이용한다.
답:
다음 has_duplicates() 함수는 for 반복문을 이용하여 항목의 중복 여부를 확인한다.
지역변수인 items는 for 반복문이 진행되는 동안 확인된 항목들로 모아둔다.
def has_duplicates(aList):
items = []
for i in aList:
if i in items:
return True
else:
items.append(i)
return Falseprint(has_duplicates([1, 2, 1, 3]))
print(has_duplicates(['hello', 'hi', 'hey']))
print(has_duplicates(['a', [1, 2], 1, 2]))
print(has_duplicates([True, False, [True, True]]))
print(has_duplicates([[True, False], True, [True, False]]))True
False
False
False
True
예제 3
아래 리스트가 주어졌다.
['dog', 'cat']위 리스트에 아래 리스트를 마지막 항목으로 추가한 새로운 리스트를 생성하라.
['tiger', 'eagle']생성된 리스트는 아래 모양이어야 한다.
['dog', 'cat', ['tiger', 'eagle']]단, 리스트의 메서드만 활용해야 한다.
답:
append() 메서드를 이용한다.
animal = ['dog', 'cat']
animal.append(['tiger', 'eagle'])
print(animal)['dog', 'cat', ['tiger', 'eagle']]
또는 extend() 메서드를 이용할 수도 있다.
단, append() 메서드와 다른 인자를 사용함에 주의함다.
animal = ['dog', 'cat']
animal.extend([['tiger', 'eagle']])
print(animal)['dog', 'cat', ['tiger', 'eagle']]
예제 4
sorted() 함수는 리스트를 파이썬이 정한 값들의 크기를 기준으로 오름차순으로 정렬한 리스트를 반환한다.
num_list = [3, -2, 1, -4, 5]
sorted_list = sorted(num_list)
sorted_list[-4, -2, 1, 3, 5](1) rev_sorted_list 변수가 num_list를 크기 기준 내림차순으로 정렬한 리스트를 가리키도록 하라.
힌트: sorted() 함수와 sort() 리스트 메서드는 모두 key와 reverse 두 개의 키워드 인자를 사용한다.
key: 항목 정렬을 위한 기준. 기본값은 파이썬이 정한 값들의 크기.reverse: 내림차순으로 정렬할지 여부. 기본은False, 즉 오름차순으로 정렬하기.
답:
rev_sorted_list = sorted(num_list, reverse=True)
rev_sorted_list[5, 3, 1, -2, -4](2) abs_sorted_list가 num_list를 절댓값 기준으로 오름차순으로 정렬한 리스트를 가리키도록 하라.
힌트: 절댓값을 계산하는 abs() 함수 활용
답:
key=abs 키워드 인자를 활용한다.
key 키워드 인자로 사용되는 함수는 리스트의 항목을 인자로 받았을 때 반환되는 값을 기준으로 정렬되도록 하는 기능을 수행한다.
abs_sorted_list = sorted(num_list, key=abs)
abs_sorted_list[1, -2, 3, -4, 5](3) abs_rev_sorted_list가 num_list를 절댓값 기준으로 내림차순으로 정렬한 리스트를 가리키도록 하라.
답:
key=abs와 reverse=False 키워드 인자를 활용한다.
abs_rev_sorted_list = sorted(num_list, key=abs, reverse=True)
abs_rev_sorted_list[5, -4, 3, -2, 1]11.2.5연습문제¶
문제 1
4중으로 중첩된 리스트를 아래와 같이 선언한다.
a_nested_list = [0, [1, [2, [3, 4], 5]], 6, [7, 8, 9], 10](1) 위 리스트의 길이가 5임을 확인하라.
(2) 위 리스트에서 7을 확인하는 인덱싱 표현식을 정의하라.
(3) 위 리스트에서 [2, [3, 4], 5]를 확인하는 인덱싱 표현식을 정의하라.
(4) 위 리스트에서 4를 확인하는 인덱싱 표현식을 정의하라.
문제 2
0부터 10까지의 수 중에서 3의 배수를 제외한 항목으로 이루어진 리스트를 가리키는
list10_3 변수를 정의하는 코드를 작성하라.
list10_3 = [1, 2, 4, 5, 7, 8, 10]힌트: for 반복문, continue 명령문, 리스트 append 메서드 활용
문제 3
영어 단어 인자와 함께 호출되면 알파벳순으로 정렬된 문자열을 반환하는 abc() 함수를 구현하라.
예를 들어 다음과 같이 작동해야 한다.
>>> abc('dog')
'dgo'힌트: sorted() 함수와 문자열 join() 메서드 활용
문제 4
6명의 정보가 다음과 같다.
kgh = ['김강현', '010-1234-5678', 20, 172.3, '제주']
whang = ['황현', '02-9871-1234', 19, 163.5, '서울']
sewon = ['남세원', '010-3456-7891', 21, 156.7, '경기']
choihs = ['최흥선', '070-4321-1111', 21, 187.2, '부산']
sjkim = ['김현선', '010-3333-8888', 22, 164.6, '광주']
ja = ['함중아', '010-7654-2345', 18, 178.3, '강원']6명의 정보를 하나의 리스트로 묶는다.
info_list = [kgh, whang, sewon, choihs, sjkim, ja]
info_list[['김강현', '010-1234-5678', 20, 172.3, '제주'],
['황현', '02-9871-1234', 19, 163.5, '서울'],
['남세원', '010-3456-7891', 21, 156.7, '경기'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['김현선', '010-3333-8888', 22, 164.6, '광주'],
['함중아', '010-7654-2345', 18, 178.3, '강원']](1) info_list를 활용하여 중첩 리스트를 다루는 코드를 작성하기 전에 사본을 만들어 두기 위해
copy 모듈의 deepcopy() 함수를 활용하라.
복제된 중첩 리스트는 info_list_copy 변수에 할당해야 한다.
(2) info_list_copy를 키 순서대로 정렬하라.
단, sort() 메서드의 key 키워드 인자를 활용해야 한다.
(3) 추가로 6명의 몸무게로 구성된 리스트를 가리키는 weights 변수를 선언한다.
weights = [65.3, 51.5, 48.0, 81.4, 53.8, 90.1]6명의 키와 몸무게 정보를 이용하여 계산된 6명의 비만도로 구성된 리스트를 생성하라. 체질량지수(bmi)는 몸무게(kg)를 키(m)의 제곱으로 나눈 값이다.
bmi = 몸무게 / 키**2(4) info_list_copy에 6명 각각의 체질량 지수를 추가하라.
(5) info_list는 수정되지 않았음을 확인하라.
(6) 리스트 copy() 메서드는 중첩 리스트의 항목까지는 복제 하지 않음을 확인하라.
11.3튜플¶
튜플은 리스트와 아주 비슷하다.
다만 한 번 생성되면 항목의 추가, 삭제, 변경 등 일체의 수정이 불가능한
불변immutable 자료형이라는 점이 다르다.
하지만 튜플의 항목을 활용하는 방법은 리스트의 그것과 동일하다.
예를 들어, 연산, 인덱싱, 슬라이싱, for 반복문 활용 등은 리스트의 경우와 완전히 동일하다.
튜플은 항목들을 소괄호 ()로 감싸고, 각각 항목은 쉼표(,)로 구분된다.
예를 들어, 1부터 5까지의 정수로 구성된 튜플을 가리키는 변수를 다음과 같이 선언한다.
one2five_tuple = (1, 2, 3, 4, 5)다음 튜플은 영어 알파벳 a부터 c까지로 구성된다.
a2c_tuple = ('a','b', 'c')소괄호를 생략해도 튜플로 자동 처리된다.
a2c_tuple = 'a','b', 'c'
a2c_tuple('a', 'b', 'c')길이가 1인 튜플인 경우 항목 뒤에 반드시 쉼표를 붙여야 한다.
tup_3 = (3, )
type(tup_3)tuple쉼표를 사용하지 않으면 튜플로 간주되지 않을 수 있다.
아래 코드에서 non_tup_3은 3을 포함한 튜플이 아닌 정수 3을 가리킨다.
즉, 모음 자료형 값이 아니라 스칼라이다.
non_tup_3 = (3)
type(non_tup_3)int튜플의 항목으로 여러 종류의 값이 사용될 수 있다.
다음 mixed_tuple은 항목으로 정수, 부동소수점, 문자열, 부울값, 리스트, 튜플을 포함한다.
mixed_tuple = (1, 2.3, 'abc', False, ['ab', 'c'], (2, 4))빈 튜플
빈 튜플empty tuple은 아무것도 포함하지 않는 튜플을 의미한다. 다음 두 가지 방식으로 빈 튜플을 선언할 수 있다.
방법 1: 소괄호 활용
empty_tuple = ()방법 2:
tuple()함수 활용
empty_tuple = tuple()11.3.1튜플 활용법¶
튜플은 여러 값을 하나로 묶어 다룰 때 사용한다는 점에서 리스트와 비슷하지만, 한 번 생성된 뒤에는 항목을 수정할 수 없다는 점이 다르다. 따라서 값들의 묶음이 하나의 고정된 정보로 다루어져야 하는 경우에 특히 유용하다.
첫째, 함수가 여러 개의 값을 한 번에 반환할 때 튜플이 자주 사용된다.
예를 들어 아래 get_user() 함수는 info_list에 포함된 사람의 정보를 받아
이름과 나이를 함께 반환하며,
반환값은 두 값으로 구성된 튜플이다.
def get_user(x):
name = x[0] # 이름은 0번 인덱스 항목
age = x[2] # 나이는 2번 인덱스 항목
return name, age
kgh = ['김강현', '010-1234-5678', 20, 172.3, '제주']
get_user(kgh)('김강현', 20)get_user() 함수의 반환값은 튜플 자료형이다.
print(type(get_user(kgh)))<class 'tuple'>
둘째, 좌표, 색상값, 사람의 기본 정보처럼 서로 관련된 값들을 하나의 묶음으로 표현할 때 튜플을 활용한다. 이런 값들은 항목의 개수와 의미가 정해져 있는 경우가 많기에 리스트 대신 수정이 불가능한 튜플 사용이 권장된다.
point = (10, 20)
rgb = (255, 128, 0)
person = ("김강현", "010-1234-5678", 20)셋째, 값이 중간에 바뀌면 안 되는 데이터를 표현할 때 튜플이 적절하다. 예를 들어 요일 이름처럼 프로그램 실행 중 수정할 필요가 없는 값들은 튜플로 저장하면 실수로 항목을 변경하는 일을 막을 수 있다.
weekdays = ("월", "화", "수", "목", "금", "토", "일")11.3.2튜플 연산¶
튜플 연산은 리스트의 경우와 유사하게 작동한다. 설명을 위해 김강현의 정보를 튜플로 변환하여 활용한다.
kgh = ['김강현', '010-1234-5678', 20, 172.3, '제주']
kgh_tuple = tuple(kgh)
kgh_tuple('김강현', '010-1234-5678', 20, 172.3, '제주')in 연산자
튜플의 항목으로 등장하는지 여부를 알려주는 논리 연산자이다.
'김강현' in kgh_tupleTrue'서울' in kgh_tupleFalse20 in kgh_tupleTrue이어붙이기/복제
리스트의 경우처럼 튜플도 이어붙이기와 복제 연산을 이용하여 새로운 튜플을 생성할 수 있다. 아래 코드는 김강현과 황현의 정보를 함께 담은 튜플을 생성한다.
whang_tuple = tuple(whang)
whang_tuple('황현', '02-9871-1234', 19, 163.5, '서울')kgh_tuple + whang_tuple('김강현',
'010-1234-5678',
20,
172.3,
'제주',
'황현',
'02-9871-1234',
19,
163.5,
'서울')아래 코드는 김강현의 정보를 두 번 담은 튜플을 생성한다.
2 * kgh_tuple('김강현',
'010-1234-5678',
20,
172.3,
'제주',
'김강현',
'010-1234-5678',
20,
172.3,
'제주')len()함수
튜플의 길이, 즉 튜플에 포함된 항목의 개수를 반환한다.
len(kgh_tuple)5len(2 * kgh_tuple)1011.3.3튜플 인덱싱/슬라이싱/반복문¶
튜플도 문자열과 리스트처럼 인덱싱과 슬라이싱이 가능하다.
kgh_tuple[0]'김강현'kgh_tuple[-1]'제주'kgh_tuple[::2]('김강현', 20, '제주')튜플은 불변 자료형이라 값을 수정할 수 없다. 예를 들어, 김강현의 나이를 21세로 수정하려 시도하면 오류가 발생한다.
kgh_tuple[2]20kgh_tuple[2] = 21---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[169], line 1
----> 1 kgh_tuple[2] = 21
TypeError: 'tuple' object does not support item assignment튜플에 대한 반복문은 리스트에 대한 반복문과 동일하게 작동한다.
for item in kgh_tuple:
print(item)김강현
010-1234-5678
20
172.3
제주
11.3.4튜플 메서드¶
튜플 자료형의 메서드는 많지 않으며, 다음 두 개의 메서드가 자주 활용된다.
| 메서드 | 설명 |
|---|---|
count() | 지정된 항목이 등장한 횟수 반환 |
index() | 지정된 항목이 처음 위치한 인덱스 반환 |
count() 메서드
아래 코드는 김강현의 정보를 두 번 연속으로 갖고 있는 튜플에서 김강현의 이름이 두 번 사용되었음을 확인해준다.
double_kgh = 2 * kgh_tuple
double_kgh('김강현',
'010-1234-5678',
20,
172.3,
'제주',
'김강현',
'010-1234-5678',
20,
172.3,
'제주')double_kgh.count("김강현")2index() 메서드
아래 코드는 김강현의 출생지는 김강현의 정보에서 4번 인덱스에 위치함을 확인해준다.
kgh_tuple.index('제주')411.3.5예제¶
예제 1
두 변수 a, b가 가리키는 값을 서로 바꾸는 코드를 작성하라.
단, 임시 변수를 사용하지 않아야 한다.
a = 10
b = 20답:
두 변수가 가리키는 값을 서로 바꾸기 이전은 다음과 같다.
a = 10
b = 20
print("a:", a)
print("b:", b)a: 10
b: 20
아래 코드는 오른쪽의 b, a가 먼저 튜플처럼 묶이고, 그 값을 왼쪽의 a, b에 각각 해체 대입하는 방식을
활용하며, 바꾸기 이후의 결과를 보여준다.
a, b = b, a
print("a:", a)
print("b:", b)a: 20
b: 10
예제 2
정수 나눗셈을 실행하여 몫과 나머지를 튜플로 반환하는 함수 divide_qr() 함수를 구현하라.
힌트: 몫 연산자 //와 나머지 연산자 %를 활용하며 함수의 반환값은 튜플로 지정.
답:
def divide_qr(numerator, denominator):
quotient = numerator // denominator # 몫
remainder = numerator % denominator # 나머지
return (quotient, remainder)assert divide_qr(17, 3) == (5, 2)
assert divide_qr(28, 7) == (4, 0)
assert divide_qr(-18, 4) == (-5, 2)예제 3
sorted() 함수는 리스트를 파이썬이 정한 값들의 크기를 기준으로 오름차순으로 정렬한 리스트를 반환한다.
예를 들어 아래 코드는 튜플로 구성된 리스트를 정렬할 때 튜플의 첫째 항목인 문자열들을 대상으로 알파벳 순서를 기준으로 정렬한다. 이유는 튜플들의 크기 비교는 먼저 첫째 항목을 기준으로 정하고, 첫째 항목의 크기가 동일하면 둘째 항목의 크기를 비교하는 방식으로 결정되기 때문이다.
my_tuples = [('one', 1), ('three', 3), ('two', 2), ('four', 4)]
sorted(my_tuples)[('four', 4), ('one', 1), ('three', 3), ('two', 2)]리스트의 항목을 튜플의 둘째 항목인 정수를 기준으로 정렬하여 아래와 같은 리스트를 생성하는 코드를 구현하라.
[('one', 1), ('two', 2), ('three', 3), ('four', 4)]힌트: sorted() 함수와 sort() 리스트 메서드는 모두 key와 reverse 두 개의 키워드 인자를 사용한다.
key: 항목 정렬을 위한 기준. 기본값은 파이썬이 정한 값들의 크기.reverse: 내림차순으로 정렬할지 여부. 기본은False, 즉 오름차순으로 정렬하기.
답:
sorted() 함수는 key와 reverse 두 개의 키워드 인자를 사용한다.
key: 항목 정렬을 위한 기준. 기본값은 파이썬이 정한 값들의 크기.reverse: 내림차순으로 정렬할지 여부. 기본은False, 즉 오름차순으로 정렬하기.
아래 코드에서 num_sorted_list 변수가 my_tuples를
튜플의 둘째 항목인 크기 기준 오름차순으로 정렬한 리스트를 가리키도록 한다.
튜플의 둘째 항목을 크기 비교에 활용하도록 key 매개변수의 인자로 튜플에서 둘째 인자를 선택하는
함수가 사용되었음에 주목한다.
num_sorted_tuples = sorted(my_tuples, key=lambda x: x[1])
num_sorted_tuples[('one', 1), ('two', 2), ('three', 3), ('four', 4)]11.3.6연습문제¶
문제 1
아래처럼 학생 이름과 점수로 구성된 튜플들의 리스트가 주어졌다.
scores = [('김강현', 85), ('황현', 91), ('남세원', 78), ('최흥선', 91)]점수가 높은 순서대로 정렬한 리스트를 생성하라. 단, 점수가 같으면 이름순으로 정렬한다.
문제 2
사용자의 이름과 전화번호를 입력 받으면 다음과 같이 반환하는
phone_book() 함수를 구현하라.
단, 사용자의 이름은 두 글자에서 네 글자 사이며,
핸드폰 번호는 9개에서 11개의 숫자가 다양한 방식으로 주어진다.
phone_book('김강현', '010-1234-5678') = ('김*현', 5678)
phone_book('강현', '01012345678') = ('강*', 5678)
phone_book('김강현이', '031-123-5678') = ('김*현이', 5678)
phone_book('강현이', '02-123-5678') = ('강*이', 5678)
phone_book('김강현', '010.1234.5678') = ('김*현', 5678)힌트: 리스트 변환, 문자열 join() 메서드 활용
문제 3
직사각형 모양의 바닥에 정사각형 모양의 타일을 깔아야 한다. 타일은 온장을 그대로 사용할 수도 있고, 잘라서 일부분만 사용할 수도 있다. 잘라서 사용한 타일의 나머지는 버린다.
공간의 가로와 세로 크기, 그리고 타일의 크기가 cm 단위로 주어졌을 때
타일을 깔 때 필요한 온장 타일과 잘라서 사용한 타일의 개수를 반환하는 함수 tiling_tuple()을 구현하라.
단 공간 크기의 가로, 세로, 타일의 크기는 정수라고 가정하며,
타일의 크기의 기본값은 한 변의 길이가 30cm인 정사각형이다.
예를 들어, 가로와 세로 각각 4미터, 3미터인 공간을 한 변의 길이가 30cm인 타일과 35cm 타일로 채우는 경우 각각에 대해 필요한 타일의 개수를 계산하라.
11.4순차 자료형 활용¶
문자열, 리스트, 튜플 등 순차형 자료형에 포함된 값들을 효율적으로 활용하는 기능 몇 가지 소개한다.
11.4.1순차 자료형 해체¶
순자 자료형의 항목 각각에 대해 변수 할당을 진행할 수 있으며, 이를 해체unpacking이라 한다. 순차 자료형의 해체에 사용되는 변수는 항목만큼 지정되어야 한다.
문자열 해체
a, b, c = "123"print(a)
print(b)
print(c)1
2
3
a, b, c 각각의 자료형은 문자열이다.
type(a)str리스트 해체
아래 코드는 김강현의 정보 각각에 대해 변수를 선언한다.
kgh['김강현', '010-1234-5678', 20, 172.3, '제주']name, phone, age, height, birth_place = kghprint(name)
print(phone)
print(age)
print(height)
print(birth_place)김강현
010-1234-5678
20
172.3
제주
튜플 해체
아래 코드는 황현의 정보 각각에 대해 변수를 선언한다.
name, phone, age, height, birth_place = whang_tupleprint(name)
print(phone)
print(age)
print(height)
print(birth_place)황현
02-9871-1234
19
163.5
서울
밑줄 기호 _ 활용
변수의 이름이 굳이 필요 없다면 관용적으로 밑줄underscore(_) 기호 하나로 구성된 변수를
사용한다.
예를 들어, 전화번호와 키 정보가 필요없다면 phone과 height 변수 대신에 밑줄 _ 기호를 사용하는 게 일반적이다.
name, _, age, _, birth_place = kghprint(name)
print(age)
print(birth_place)김강현
20
제주
주의사항
항목의 개수와 변수의 개수가 일치하지 않으면 오류가 발생한다. 오류를 피하려면 위해 밑줄 등을 반드시 활용해야 한다.
name, age, _, birth_place = kgh---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[196], line 1
----> 1 name, age, _, birth_place = kgh
ValueError: too many values to unpack (expected 4)별표 기호 * 활용
앞에 몇 개의 값에만 변수 할당에 사용하고 나머지는 하나의 리스트로 묶어서 퉁쳐버릴 수도 있다.
이를 위해 별표 기호 * 를 하나의 변수명과 함께 사용한다.
name, phone, *etc = whang_tupleprint(name)
print(phone)
print(etc)황현
02-9871-1234
[19, 163.5, '서울']
나머지 항목들을 무시하고 싶다면, 별표와 밑줄을 함께 사용한다.
name, phone, *_ = whang_tupleprint(name)
print(phone)황현
02-9871-1234
11.4.2순차 자료형에 유용한 함수¶
문자열, 튜플, 리스트처럼 항목들의 순서가 중요한 순차 자료형과 함께 유용하게 사용되는 두 개의 함수를 소개한다.
enumerate()함수zip()함수
11.4.2.1enumerate() 함수¶
튜플과 리스트는 항목들의 인덱스를 바로 제공하지 않는다.
하지만 항목과 해당 항목의 인덱스 정보를 함께 활용해야 할 때가 있는데
이때 enumerate() 함수가 매우 유용하다.
이를 위해 아래 리스트를 이용한다.
some_list = ['foo', 'bar', 'baz', 'pyt', 'thon']enumerate() 함수는 리스트를 받아서
리스트의 항목과 인덱스를 쌍으로 갖는 enumerate 객체를 준비시킨다.
이렇게 준비된 객체는 range 객체처럼 바로 확인할 수는 없다.
enumerate(some_list)<enumerate at 0x2aad5b78bd0>하지만 리스트로 변환하면 인덱스와 항목의 튜플로 이루어져 있음을 확인 할 수 있다.
list(enumerate(some_list))[(0, 'foo'), (1, 'bar'), (2, 'baz'), (3, 'pyt'), (4, 'thon')]인덱스 활용 for 반복문
아래 코드는 짝수 인덱스의 값들만 출력하도록 한다. 이유는 다음과 같다.
enumerate(some_list):(인덱스, 항목)형식의 튜플로 구성된 리스트 같은 값idx, item:(인덱스, 항목)형식의 항목 해체에 사용되는 두 변수
for idx, item in enumerate(some_list):
if idx % 2 == 0:
print(item)foo
baz
thon
enumerate() 함수를 사용하지 않으면서 동일한 기능을 구현하려면
다음과 같이 range() 함수를 이용하여 인덱스에 대해 for 반복문을 이용해야 한다.
for i in range(len(some_list)):
if i % 2 == 0:
print(some_list[i])foo
baz
thon
11.4.2.2zip() 함수¶
문자열, 리스트, 튜플 등 순차 자료형 여러 개를 묶어 하나의 순차 자료형으로 사용되는 zip 객체를 만들며,
i 번째 항목은 i 번째 항목들의 튜플로 구성된다.
zip() 함수의 반환값 또한 항목을 바로 확인시켜주지는 않는다.
zip("abc", [1, 2, 3])<zip at 0x2aad5c0ae40>리스트로 변환하여 zip() 함수가 튜플로 구성된 리스트 형식의 값을 반환함을 확인할 수 있다.
list(zip("abc", [1, 2, 3]))[('a', 1), ('b', 2), ('c', 3)]zip() 함수의 인자는 3개 이상도 가능하다.
단. 길이가 다르면 가장 짧은 길이에 맞춰서 짝을 짓고, 나머지 항목은 모두 무시한다.
아래 코드는 가장 짧은 [5, 10, 15]에 맞춰서 2번 인덱스까지만 튜플로 묶고 나머지 항목들은 버린다.
list(zip("abcdefgh",(1, 2, 3, 4, 5), [5, 10, 15]))[('a', 1, 5), ('b', 2, 10), ('c', 3, 15)]동시 반복
zip() 함수를 이용하면 여러 개의 리스트, 튜플을 대상으로 동시에 반복문을 실행할 수 있다.
아래 코드는 튜플 해체를 활용하여 두 개의 변수에 대해 동시에 for 반복문을 실행한다.
letters = ['a', 'b', 'c']
numbers = [0, 1, 2]
for l, n in zip(letters, numbers):
print(f'문자: {l}', end=', ')
print(f'숫자: {n}')문자: a, 숫자: 0
문자: b, 숫자: 1
문자: c, 숫자: 2
zip() 함수를 사용하지 않으면 2중으로 중첩된 for 반복문과
인덱싱을 함께 이용해야 한다.
for idx1 in range(len(letters)):
for idx2 in range(len(numbers)):
if idx1 == idx2:
print(f'문자: {letters[idx1]}, 숫자: {numbers[idx2]}')문자: a, 숫자: 0
문자: b, 숫자: 1
문자: c, 숫자: 2
위 코드에서 안쪽 for 반복문의 본문에 있는 if idx1 == idx2 조건문이 없다면
총 3 곱하기 3, 즉 9개의 모든 조합의 출력됨에 주의한다.
for idx1 in range(len(letters)):
for idx2 in range(len(numbers)):
print(f'문자: {letters[idx1]}, 숫자: {numbers[idx2]}')문자: a, 숫자: 0
문자: a, 숫자: 1
문자: a, 숫자: 2
문자: b, 숫자: 0
문자: b, 숫자: 1
문자: b, 숫자: 2
문자: c, 숫자: 0
문자: c, 숫자: 1
문자: c, 숫자: 2
즉, 동시 반복은 중첩 반복과 다르게 작동한다.
11.4.3예제¶
예제 1
num_sorted_tuples 변수가 다음과 같이 정의되었다.
num_sorted_tuples = [('one', 1), ('two', 2), ('three', 3), ('four', 4)]num_sorted_tuples 를 이용하여 1부터 4까지의 정수를 입력하면 해당 숫자의 영어 단어를 반환하는 함수
num2word() 함수를 정의하라.
단, 1부터 4까지의 정수가 아닌 경우엔 'unknown'을 반환해야 한다.
답:
num_sorted_tuples를 이용하여 for 반복문을 실행한다.
단, 항목이 튜플이기에 튜플 해체를 바로 적용하여 영단어와 숫자 각각에 변수를 할당한다.
for word, number in num_sorted_tuples:
...for 반복문의 본문은 number 변수가 지정된 숫자인지 여부에 따라 반환값을 지정하는 if 조건문을 활용한다.
def num2word(num):
for word, number in num_sorted_tuples:
if num == number:
return word
return "unknown"num2word(1)'one'num2word(4)'four'num2word(10)'unknown'예제 2
6명의 정보가 다음과 같다.
kgh = ['김강현', '010-1234-5678', 20, 172.3, '제주']
whang = ['황현', '02-9871-1234', 19, 163.5, '서울']
sewon = ['남세원', '010-3456-7891', 21, 156.7, '경기']
choihs = ['최흥선', '070-4321-1111', 21, 187.2, '부산']
sjkim = ['김현선', '010-3333-8888', 22, 164.6, '광주']
ja = ['함중아', '010-7654-2345', 18, 178.3, '강원']info_list_copy = [kgh, whang, sewon, choihs, sjkim, ja]
info_list_copy[['김강현', '010-1234-5678', 20, 172.3, '제주'],
['황현', '02-9871-1234', 19, 163.5, '서울'],
['남세원', '010-3456-7891', 21, 156.7, '경기'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['김현선', '010-3333-8888', 22, 164.6, '광주'],
['함중아', '010-7654-2345', 18, 178.3, '강원']](1) info_list_copy을 이름순으로 정렬하라.
힌트: sort() 메서드의 key 키워드 인자 활용
답:
sort() 메서드의 key 키워드 인자로 리스트의 2번 인덱스 값을 반환하는 함수를 지정한다.
key 키워드 인자로 사용되는 함수는 리스트의 항목을 인자로 받았을 때 반환되는 값을 기준으로 정렬되도록 하는 기능을 수행한다.
따라서 이름순으로 정렬되도록 하려면 각 항목 리스트의 0번 인덱스 항목을 추출하는 다음 람다 함수를 이용할 수 있다.
def 키워드로 이름을 갖는 함수로 정의할 수도 있지만 단순하며 한 번만 사용될 함수이기에 람다 함수를 활용한다.
lambda x: x[0]info_list_copy.sort(key=lambda x:x[0])
info_list_copy[['김강현', '010-1234-5678', 20, 172.3, '제주'],
['김현선', '010-3333-8888', 22, 164.6, '광주'],
['남세원', '010-3456-7891', 21, 156.7, '경기'],
['최흥선', '070-4321-1111', 21, 187.2, '부산'],
['함중아', '010-7654-2345', 18, 178.3, '강원'],
['황현', '02-9871-1234', 19, 163.5, '서울']](2) info_list_copy에 포함된 6명의 이름과 전화번호만으로 구성된 중첩 리스트를 가리키는 phone_list 변수를 선언하라.
단, for 반복문, 슬라이싱, append() 메서드를 반드시 활용한다.
답:
phone_list를 빈 리스트로 초기화한 다음에 for 반복문과 인덱싱을 이용하여
6명 각각의 정보를 담은 리스트에서 전화번호 정보가 위치한 1번 인덱스 항목을 phone_list에
append() 메서드로 추가한다.
phone_list = [] # 전화번호를 저장할 리스트 초기화
for person in info_list_copy:
phone_list.append(person[:2]) # 전화번호만 추출해서 phone_list에 추가
phone_list[['김강현', '010-1234-5678'],
['김현선', '010-3333-8888'],
['남세원', '010-3456-7891'],
['최흥선', '070-4321-1111'],
['함중아', '010-7654-2345'],
['황현', '02-9871-1234']](3) 이름순으로 정렬된 6명의 전화번호 정보 각각에 대해 0번 인덱스의 값으로 해당 정보의 순서를 추가하라. 예를 들어 김강현의 정보는 다음과 같이 0번 인덱스에 0이 추가되어야 한다.
[0, '김강현', '010-1234-5678']힌트: 리스트 insert() 메서드와 enumerate() 함수 활용
답:
for idx, item in enumerate(phone_list):
item.insert(0, idx)
phone_list[[0, '김강현', '010-1234-5678'],
[1, '김현선', '010-3333-8888'],
[2, '남세원', '010-3456-7891'],
[3, '최흥선', '070-4321-1111'],
[4, '함중아', '010-7654-2345'],
[5, '황현', '02-9871-1234']]예제 3
세 개의 리스트가 다음과 같이 주어졌다.
letters = ['a', 'b', 'c']
numbers = [0, 1, 2]
operators = ['*', '/', '+'](1) zip() 함수를 이용하여 아래 형식으로 출력되는 코드를 작성하라.
a * 0
b / 1
c + 2답:
세 개의 리스트를 zip() 함수로 묶은 후 길이가 3인 튜플의 각 원소에 대한 동시 반복을 실행한다.
for l, n, o in zip(letters, numbers, operators):
print(f'{l} {o} {n}')a * 0
b / 1
c + 2
(2) zip() 함수를 사용하지 않으면 아래 형식으로 출력되는 3중 중첩 for 반복문을 작성하라.
a * 0
b / 1
c + 2답:
3중으로 중첩된 for 반복문과
인덱싱을 함께 이용해야 한다.
또한 동시 반복 효과를 내기 위해 if 조건문을 가장 안쪽의 반복문에 적용한다.
for idx1 in range(len(letters)):
for idx2 in range(len(numbers)):
for idx3 in range(len(operators)):
if idx1 == idx2 and idx2 == idx3:
print(f'{letters[idx1]} {operators[idx3]} {numbers[idx2]}')a * 0
b / 1
c + 2
예제 4
두 개의 리스트가 다음과 같이 주어졌다.
names = ["김강현", "황현", "남세원", "최흥선"]
scores = [85, 91, 78, 91]위 두 리스트를 이용하여 다음과 같이 출력하는 코드를 작성하라. 즉, 점수대로 등수를 매기고, 동점인 경우 등수는 동일하게, 하지만 이름순으로 출력되도록 한다.
1등: 최흥선, 91점
1등: 황현, 91점
3등: 김강현, 85점
4등: 남세원, 78점답:
먼저 zip() 함수로 이름과 점수를 묶어, 튜플로 구성된 리스트를 생성한다.
name_scores = list(zip(names, scores))
name_scores[('김강현', 85), ('황현', 91), ('남세원', 78), ('최흥선', 91)]sorted() 함수를 이용하여 점수와 이름순으로 정렬한다.
name_scores_sorted = sorted(name_scores, key=lambda x: (-x[1], x[0]))
name_scores_sorted[('최흥선', 91), ('황현', 91), ('김강현', 85), ('남세원', 78)]앞서 생성된 name_scores_sorted는 (이름, 점수) 형식의 튜플로 구성된 리스트다.
따라서 enumerate(name_scores_sorted, start=1)를 적용하면
반복 과정에서 (인덱스, (이름, 점수)) 형식의 튜플이 생성된다.
따라서 아래와 같이 중첩 튜플 해체를 사용해야 한다.
idx, (name, score)아래처럼 세 개의 변수로 바로 해체할 수는 없음에 주의한다.
idx, name, scoreprev_score = None # 이전 점수를 저장할 변수
rank = 0 # 현재 등수를 저장할 변수
for idx, (name, score) in enumerate(name_scores_sorted, start=1):
if score != prev_score: # 현재 점수가 이전 점수와 다르면 등수 갱신
rank = idx
print(f"{rank}등: {name}, {score}점")
prev_score = score1등: 최흥선, 91점
1등: 황현, 91점
3등: 김강현, 85점
4등: 남세원, 78점
11.4.4연습문제¶
문제 1
단어들의 리스트가 다음과 같다.
words = ["python", "java", "c", "javascript", "go", "rust"]인덱스가 짝수인 항목만 모아 다음 리스트를 생성하라.
["python", "c", "go"]힌트: enumerate() 함수와 append() 메서드 활용
문제 2
두 개의 리스트가 다음과 같다.
xs = [1, 3, 5, 7]
ys = [2, 4, 6, 8]두 리스트의 같은 위치에 있는 항목끼리 더해 다음 리스트를 생성하라.
[3, 7, 11, 15]힌트: zip() 함수와 append() 메서드 활용
문제 3
아래 코드는 인덱스와 리스트의 항목의 순서를 바꾼 튜플의 리스트를 생성한다.
some_list = ['foo', 'bar', 'baz', 'pyt', 'thon']
mapping = []
for idx, item in enumerate(some_list):
mapping.append((item, idx))
mapping[('foo', 0), ('bar', 1), ('baz', 2), ('pyt', 3), ('thon', 4)]enumerate() 함수를 사용하지 않으면서 동일한 기능을 구현하는 for 반복문을 작성하라.
문제 4
메뉴와 가격이 공백으로 구분된 두 개의 문자열로 주어졌다.
menu = "ham bread chicken egg"
prices = "1200 5000 17000 500"(1) 두 문자열을 공백 기준으로 쪼개서 생성되는 두 리스트를 각각 menu_list 변수와 price_list 변수에 할당하라.
(2) 가장 저렴한 메뉴와 가장 비싼 메뉴를 추천하는 문자열을 다음과 같이 출력하는 프로그램을 구현하라.
가장 저렴한 메뉴: egg
가장 비싼 메뉴: chicken 힌트: zip() 함수, 리스트 sort() 메서드 활용