주성분 분석(Principal Component Analysis, PCA)은 많은 특성을 갖는 고차원 데이터를 더 적은 수의 새로운 특성으로 압축하는 대표적인 차원 축소 기법이다. PCA의 목표는 정보 손실을 어느 정도 감수하더라도 데이터의 중요한 구조를 최대한 유지하여 모델의 훈련 속도와 성능을 향상시키는 것이다.
7.1차원의 저주¶
차원
하나의 샘플은 여러 특성값으로 표현된다.
예를 들어 온라인 쇼핑몰 고객 한 명을 최근 구매 금액, 방문 횟수 두 가지 특성으로만 표현하면 각 고객은 2차원 공간의 한 점으로 생각할 수 있다.
여기에 클릭한 상품 종류, 상품별 체류 시간, 검색어, 접속 시간대, 사용 기기, 쿠폰 사용 여부 같은 특성을 계속 추가하면 고객 한 명은 더 높은 차원의 공간에 놓인 점이 된다.
이처럼 데이터셋의 특성 수가 곧 데이터가 놓이는 공간의 차원dimension이다.
데이터의 차원이 높으면 그만큼 두 샘플 사이의 거리가 멀어진다. 실제로 2차원 공간보다 3차원 공간을 촘촘하게 채우기 위해 필요한 데이터 샘플은 3차원 공간이 훨씬 많다.
차원의 저주
특성이 많아지면 데이터를 더 자세히 설명할 수 있다는 장점이 있다.
하지만 특성 수가 너무 많아지면 일단 모델의 훈련시간에 비례해서 오래 걸리며, 모델의 훈련 성능도 올리기 어렵다.
이유는 두 샘플 사이의 거리가 너무 멀어서 두 샘플의 유사도를 평가하기가 매우 어려워지기 때문이다.
예를 들어, 최근 구매 금액, 방문 횟수 두 개의 특성으로 구성된 2차원 데이터에서는
서로 가까운 고객을 찾기 쉽지만, 수십 개나 수백 개의 기준을 동시에 고려하면 어떤 고객들이 서로 정말 비슷한지 판단하기가 어려워진다.
또한 새 고객 데이터를 접했을 때 그 고객이 어떤 유형의 고객인지 기존 데이터만으로 판단하기가 보다 어려워진다. 모델 훈련에 사용되었던 훈련셋 안에서 이 고객과 충분히 비슷한 기존 고객을 찾기 어려워져서 기존 고객의 구매 패턴을 바탕으로 새 고객의 행동을 제대로 추정하기가 어려워진다.
결국 과대적합 위험도 커진다.
모델이 전체 고객에게 공통으로 나타나는 일반적인 패턴을 배우기보다, 훈련셋에 우연히 포함된 세부적인 조합에 지나치게 맞춰질 수 있기 때문이다.
예를 들어 어떤 훈련 샘플 몇 개에서만 나타난 특정 시간대, 특정 기기, 특정 검색어, 특정 쿠폰 사용 여부의 조합을 모델이 중요한 규칙처럼 기억해버릴 수 있다.
훈련셋에서는 잘 맞는 것처럼 보이지만, 새로운 고객 데이터에는 잘 일반화되지 않을 가능성이 높다.
이처럼 특성 수가 너무 많아 학습이 느려지거나 어려워지고, 과대적합 위험까지 커지는 현상을 차원의 저주라 부른다.
7.2차원 축소¶
차원의 저주를 완화하는 가장 직접적인 방법은 훈련 샘플을 훨씬 많이 모아 훈련 샘플 사이의 거리를 줄이는 것이다. 하지만 차원이 늘어날수록 필요한 샘플 수는 기하급수적으로 증가한다. 일반적으로 과대적합을 피할 만큼 많은 샘플을 모으기가 어렵거나, 비용과 시간이 너무 많이 들 수 있다. 그래서 많은 경우에는 모든 특성을 그대로 사용하기보다, 데이터의 중요한 정보를 최대한 유지하면서 특성 수를 줄이는 방법을 고려한다. 이것이 차원 축소 기법이다.
차원 축소의 핵심은 정보를 무작정 버리는 것이 아니다. 서로 비슷한 정보를 담고 있는 특성들을 압축하거나, 데이터의 중요한 변화를 잘 보여주는 몇 개의 새로운 특성값으로 데이터를 변환하는 것이다.
예를 들어, 고객 데이터에서 여러 클릭 기록과 체류 시간 특성들이 모두 전자제품 관심도와 관련되어 있다면, 이 많은 특성을 하나의 핵심적인 행동 특성으로 요약할 수 있다.
또 여러 할인 쿠폰 관련 특성이 가격 민감도를 함께 설명한다면, 이 역시 더 적은 수의 특성으로 압축할 수 있다.
이렇게 특성 수를 줄이면 모델이 다루어야 할 공간이 작아지고, 훈련 속도가 빨라지며, 불필요한 세부 정보에 맞춰지는 위험도 줄어들 수 있다.
7.3주성분 분석(PCA)¶
차원 축소를 수행하는 가장 널리 사용되는 방법 중 하나가 주성분 분석(PCA) 기법이다. PCA는 기존 특성들 중 일부를 고르는 방법이 아니다. 대신 기존 특성들을 조합하여 데이터의 분산 정보가 가장 잘 유지되도록 하는 새로운 특성들을 계산해낸다. 이렇게 새롭게 계산된 새로운 특성들을 주성분이라 부른다.
PCA는 계산해낸 모든 주성분을 다 사용하지 않고, 중요한 주성분 몇 개만 선택하여 데이터를 더 낮은 차원의 데이터로 변환한다. 예를 들어 784개의 픽셀값으로 표현된 MNIST 손글씨 이미지를 154개의 주성분으로 줄여도 원래보다 훨씬 적은 차원으로도 숫자를 구분하는 데 필요한 정보를 상당 부분 유지할 수 있다. 즉 PCA는 고차원 데이터를 더 다루기 쉬운 저차원 데이터로 변환하면서 원래 데이터의 중요한 분산 정보를 최대한 보존하는 기법이다. 따라서 전체 흐름은 다음과 같이 정리할 수 있다.
단, PCA가 차원의 저주를 항상 완전히 해결하는 것은 아니다. PCA는 여러 특성 사이에 중복되거나 관련된 정보가 많고, 데이터의 중요한 변화가 비교적 적은 수의 특성에 잘 모여 있을 때 특히 효과적이다. PCA는 차원의 저주를 완화하기 위한 매우 유용한 출발점이지만, 데이터의 성격과 분석 목적에 맞게 사용해야 한다.
7.3.1기본 아이디어¶
PCA는 데이터를 가장 잘 설명하는 방향을 차례대로 찾는다. 데이터가 가장 넓게 퍼져 있는 방향을 첫째 주성분으로 잡고, 그 다음으로 많이 퍼져 있는 방향을 둘째 주성분으로 잡는 식이다. 이렇게 찾은 주성분들을 새로운 좌표축으로 사용하면 원래 데이터의 중요한 변화를 비교적 적은 차원으로 표현할 수 있다.
7.3.2사영과 초평면¶
PCA는 훈련 데이터셋을 특정 초평면hyperplane에 사영하는 방식으로 차원을 줄인다. 아래 그래프는 3차원 데이터를 3차원 공간의 (초)평면으로 사영projection하는 방식을 보여준다. 초평면 구성에 필요한 두 개의 축은 주성분 분석을 통해 결정되며 분산 보존 개념과 밀접하게 연관된다.
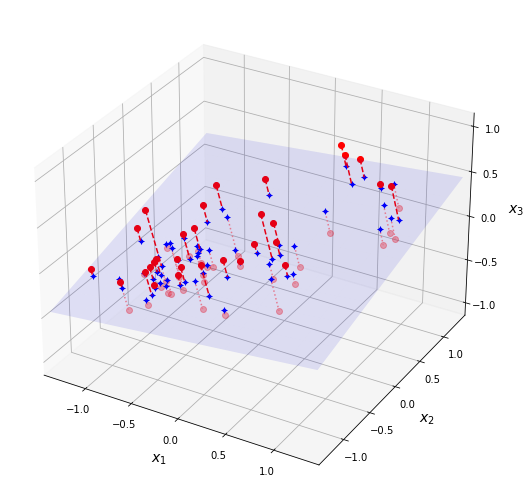
7.3.3분산 보존¶
고차원의 데이터를 저차원으로 사영할 때는 기존 고차원 데이터셋의 분산이 최대한 유지되도록 해야 한다. 분산이 많이 보존된다는 것은 데이터가 서로 얼마나 다르게 분포하는지에 대한 정보가 많이 남는다는 뜻이다.
아래 그림에서 c1 벡터(화살표)가 위치한 실선 축으로 사영하는 경우(우측 상단)가
파선 축으로 사영하는 경우(우측 중간) 또는 점선 축으로 사영하는 경우(우측 하단)보다 분산을 보다 많이 보존한다.
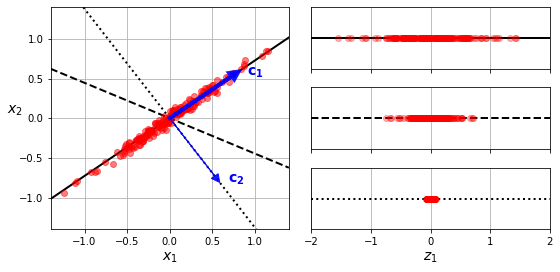
7.3.4주성분¶
주성분은 다음 과정으로 차례대로 찾는다.
첫째 주성분: 분산을 최대한 보존하는 축
둘째 주성분: 첫째 주성분과 수직을 이루면서, 첫째 주성분이 담당하지 않는 분산을 최대한 보존하는 축
셋째 주성분: 첫째와 둘째 주성분에 수직이면서, 앞의 두 주성분이 담당하지 않는 분산을 최대한 보존하는 축
이후 주성분도 같은 방식으로 찾는다.
사영에 사용되는 초평면은 주성분으로 구성된 축을 이용하는 공간으로 지정된다. 예를 들어 첫째와 둘째 주성분만 축으로 사용하면 2차원 초평면이 생성된다.
7.3.5특잇값 분해(SVD)¶
데이터셋의 주성분은 선형대수의 특잇값 분해(Singular Value Decomposition, SVD) 기법을 이용하여 효율적으로 찾을 수 있다. SVD를 사용하면 주성분을 계산하고, 찾아진 초평면으로 데이터를 사영하는 과정도 비교적 쉽게 처리된다. 단, 데이터셋이 크거나 특성이 많으면 계산 시간이 길어질 수 있다.
7.4사이킷런의 PCA 모델¶
사이킷런의 PCA 모델은 SVD 기법을 활용한다.
예를 들어 아래 코드는 데이터셋의 차원을 2로 줄인다.
PCA 모델은 변환기이기에 fit_transform() 메서드를 지원한다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X2D = pca.fit_transform(X)7.4.1설명 분산 비율¶
훈련된 PCA 모델의 explained_variance_ratio_ 속성에는 각 주성분이 원 데이터셋의 분산을 얼마나 설명하는지가 저장된다.
예를 들어 아래 사영 그림에서 3차원 데이터를 새로운 축 z1과 z2를 사용하는 2차원 평면 위의 데이터로 표현하면, 두 축에 대한 설명 분산 비율은 각각 82.3%와 10.8%이다.
따라서 이 두 주성분만 사용해도 원 데이터셋의 분산 중 약 93%를 유지하면서 데이터를 2차원으로 축소할 수 있다.
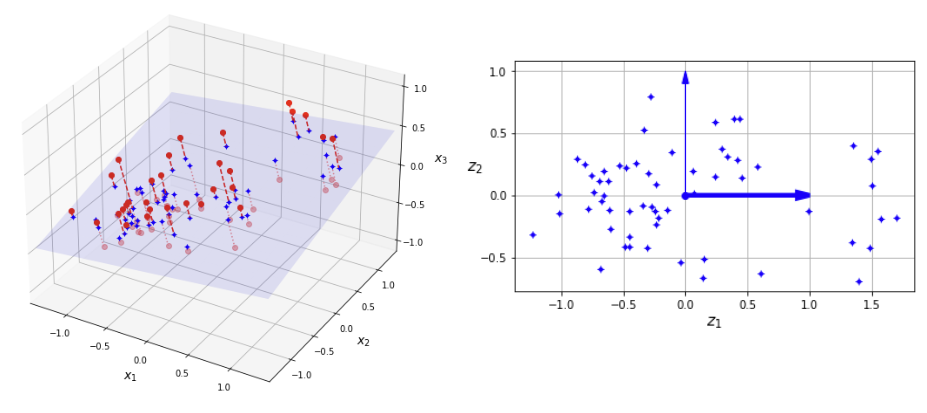
7.4.2적절한 차원 선택¶
일반적으로는 누적 설명 분산 비율이 95% 이상이 되도록 주성분의 개수를 정하는 방법이 자주 사용된다. 반면 데이터 시각화가 목적이라면 사람이 눈으로 확인할 수 있도록 2개 또는 3개의 주성분만 선택한다.
적절한 차원을 결정하기 위해 설명 분산 비율의 누적합과 차원 사이의 그래프를 활용할 수 있다. 예를 들어 설명 분산 비율의 누적합 증가가 완만하게 변하는 지점, 즉 팔꿈치elbow 지점을 살펴보면 좋다.
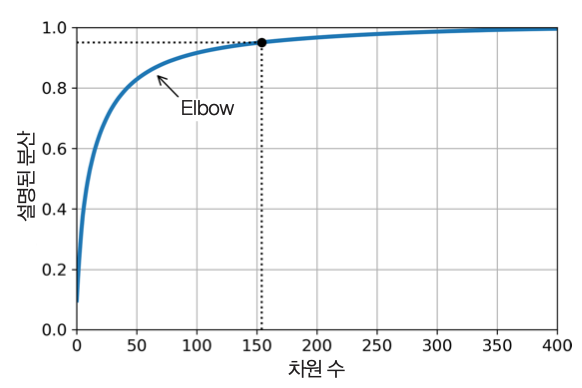
위 그래프는 MNIST 데이터셋에 대해 누적 설명 분산 비율이 95% 이상 되려면 150개보다 조금 많은 주성분이 필요함을 보여준다.
보다 정확히 확인하기 위해 n_components=0.95로 지정하여 PCA 모델을 훈련시키면, 실제로 필요한 주성분 개수가 154개임을 확인할 수 있다.
아래 코드에서 X_train은 6만개의 손글씨 사진으로로 구성된 MINIST 훈련셋을 가리킨다.
pca = PCA(n_components=0.95)
pca.fit(X_train)n_components 하이퍼파라미터에 0과 1 사이의 부동소수점 대신 정수를 사용하면, 축소할 차원의 수를 직접 지정한다.
따라서 위 코드는 아래 코드와 동일한 차원 수의 데이터로 변환한다.
pca = PCA(n_components=154)
pca.fit(X_train)7.5PCA 활용¶
PCA 활용법은 크게 두 가지로 나뉜다.
첫째, 고차원 데이터를 2차원 또는 3차원으로 압축하여 데이터의 구조나 군집을 눈으로 확인하는 시각화 도구로 사용할 수 있다. 둘째, 데이터의 차원을 축소하여 모델 훈련 속도를 높이고 저장 공간을 줄이는 데이터 전처리로 활용될 수 있다.
두 목적은 주성분 개수를 정하는 방식에서 차이가 있다.
시각화 목적: 사람이 직접 확인할 수 있어야 하므로 2개 또는 3개의 주성분만 사용한다.
데이터 압축 목적: 보통 누적 설명 분산 비율이 충분히 크게 유지되도록, 예를 들어 95% 이상이 되도록 주성분 개수를 정한다.
7.5.1데이터 시각화¶
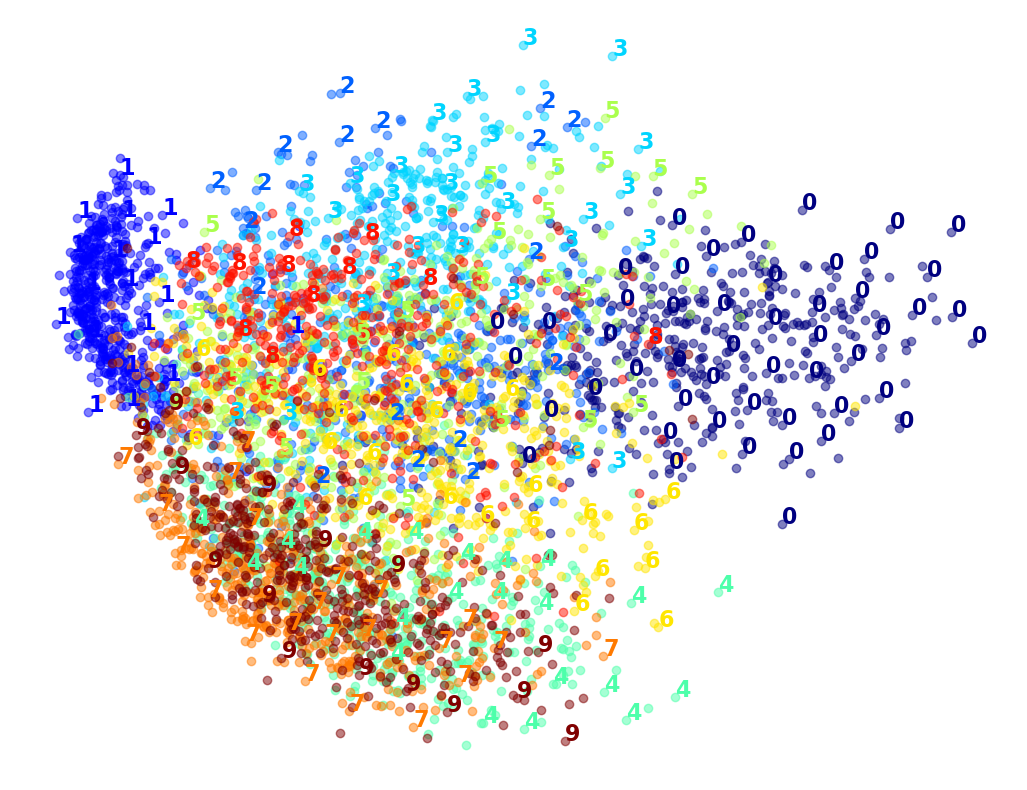
PCA를 이용해 MNIST 데이터셋을 두 개의 주성분으로 축소한 후, 산점도로 시각화해 보자. 아래 코드에서는 설명의 편의를 위해 MNIST 훈련셋에서 5,000개의 샘플만 추출하여 PCA를 적용하고, 두 개의 주성분만 남긴다.
X_sample, y_sample = X_train[:5000], y_train[:5000]
pca = PCA(n_components=2, random_state=42)
X_pca_reduced = pca.fit_transform(X_sample)두 개의 특성으로 축소된 5,000개의 데이터를 산점도로 나타내면 다음과 같다. 각 점이 나타내는 손글씨 숫자는 색상과 숫자 레이블로 구분하여 표시된다.
손글씨 숫자 군집 간에 겹치는 영역이 많고 일부 군집은 분포가 뚜렷하지 않지만, PCA를 통해 고차원 데이터의 구조를 저차원 공간에서 어느 정도 확인할 수 있음을 보여준다.
7.5.2차원 축소 데이터 전처리¶
아래 코드는 차원 축소를 담당하는 PCA와 랜덤 포레스트 분류기를 하나의 파이프라인으로 묶은 후, 랜덤 탐색을 이용하여 적절한 주성분 개수와 랜덤 포레스트의 트리 개수를 함께 찾는다.
clf = make_pipeline(PCA(random_state=42),
RandomForestClassifier(random_state=42))
param_distrib = {
"pca__n_components": np.arange(100, 200, 10),
"randomforestclassifier__n_estimators": np.arange(100, 1000, 100)
}
rnd_search = RandomizedSearchCV(clf,
param_distrib,
n_iter=10,
cv=3,
random_state=42)
rnd_search.fit(X_train, y_train)머신러닝 모델은 보통
클래스 간 차이
데이터 구조
상관관계
거리
패턴
을 이용해 예측하는데, 이런 구조들이 종종 큰 분산 방향에 집중되어 있다. PCA가 바로 그 방향을 보존하며, 따라서 PCA를 전처리로 활용하면 모델의 성능을 크게 저하시키지 않으면서 모델 훈련 비용을 줄일 수 있게 된다.
7.5.3PCA 차원 축소 효과¶
차원 축소가 항상 훈련 속도와 모델 성능을 향상시키는 것은 아니다. 예를 들어, MNIST 데이터셋에 대해 랜덤 포레스트 모델의 경우엔 속도와 성능 두 측면 모두에서 나빠지지만, 확률적 경사하강법 모델의 경우엔 두 측면 모두에서 좋아진다.
랜덤 포레스트 모델의 경우
MNIST 데이터셋에서 PCA를 적용하기 전후에 랜덤 포레스트 모델의 훈련이 달라지는 이유는 다음과 같다.
PCA 적용 전의 원본 데이터
데이터 형태: 각 픽셀의 밝기를 나타내는 0부터 255 사이의 정수값
분할 후보 수: 하나의 특성, 즉 픽셀이 가질 수 있는 고유값은 최대 256개이다. 따라서 결정 트리 기반 알고리즘이 분할 기준을 탐색할 때 고려해야 하는 후보의 수가 상대적으로 제한적이다.
또한 이미지 가장자리의 픽셀은 대부분 값이 0이므로, 유효한 분할 후보가 적어 계산량이 더욱 줄어들 수 있다.
PCA 적용 후에 차원이 축소된 데이터
데이터 형태: 연속적인 실수값으로 표현된 주성분
분할 후보 수: PCA로 생성된 특성은 대부분의 샘플에서 서로 다른 값을 갖는다. 예를 들어 훈련 데이터가 60,000개라면, 하나의 주성분이 최대 60,000개의 고유값을 가질 수 있다.
결정 트리 기반 알고리즘은 최적의 분할 지점을 찾기 위해 이러한 값들을 정렬하고, 인접한 값 사이의 여러 후보 지점에서 불순도 감소량을 평가해야 한다. 그 결과, 특성 하나당 필요한 계산량이 크게 증가한다.
즉, PCA를 적용하면 특성의 수는 784개에서 154개로 줄어들지만, 각 특성이 정수형 픽셀값에서 고유값이 많은 연속형 변수로 바뀐다. 이로 인해 각 특성에서 분할 지점을 탐색하는 비용이 크게 증가하여, 전체 훈련 시간이 오히려 더 길어질 수밖에 없다.
확률적 경사하강법 모델의 경우
반면에 확률적 경사하강법은 데이터셋의 차원, 측 특성 수만큼의 가중치 파라미터가 학습되어야 한다. 따라서 적어지는 특성 수만큼 모델 훈련시간이 줄어들게 된다. 실제로 154는 784의 약 1/5 정도이며, 훈련 시간은 약 1/4 정도 줄어든다.
7.6대용량 데이터셋을 위한 PCA¶
7.6.1랜덤 PCA¶
랜덤 PCA는 주성분을 계산할 때 사용하는 SVD를 확률적 알고리즘으로 근사하는 기법이다. 전체 SVD를 정확히 계산하지 않고, 지정된 개수의 주성분에 대한 근삿값을 더 빠르게 찾는다.
rnd_pca = PCA(n_components=154,
svd_solver="randomized",
random_state=42)
X_reduced = rnd_pca.fit_transform(X_train)시간 복잡도
전체 SVD를 사용하는 기본 PCA의 시간 복잡도는 보통 일 때 대략 다음과 같다.
여기서 은 샘플 수, 은 원본 특성 수이다.
반면 랜덤 PCA는 필요한 주성분 개수 가 보다 훨씬 작을 때 더 빠르게 작동한다. 단순화하면 다음과 같다.
랜덤 PCA는 전체 SVD를 정확히 계산하는 대신 지정된 개수의 주성분만 근사적으로 계산하므로, 특히 필요한 주성분 개수가 원본 특성 수보다 훨씬 작을 때 계산 시간을 크게 줄일 수 있다.
7.6.2점진적 PCA (IPCA)¶
점진적 PCA, 즉 IPCA(Incremental PCA)는 훈련 세트를 미니배치로 나눈 후 하나씩 주입하여 학습하는 PCA 기법이다.
전체 훈련 세트를 한 번에 메모리에 올리기 어려운 경우나 온라인 학습에 활용할 수 있다.
IPCA는 훈련에 partial_fit() 메서드를 사용한다.
n_batches = 100
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)넘파이 memmap 클래스 활용
넘파이의 memmap 클래스는 바이너리 파일로 저장된 매우 큰 데이터셋을 메모리에 모두 올리지 않고도, 일반 배열과 비슷한 방식으로 다룰 수 있게 해준다.
이를 이용하면 큰 데이터셋에 대해서도 미니배치 방식의 점진적 PCA를 적용할 수 있다.
# memmap 파일 생성
filename = "my_mnist.mmap"
X_mmap = np.memmap(filename, dtype="float32", mode="w+", shape=X_train.shape)
X_mmap[:] = X_train
X_mmap.flush()
# IPCA 적용
X_mmap = np.memmap(filename, dtype="float32", mode="r", shape=X_train.shape)
n_batches = 100
batch_size = X_mmap.shape[0] // n_batches
inc_pca = IncrementalPCA(n_components=154, batch_size=batch_size)
inc_pca.fit(X_mmap)
# MNIST 데이터 압축
X_reduced = inc_pca.transform(X_train)위 코드에서 IncrementalPCA.fit()은 batch_size에 맞춰 데이터를 나누어 내부적으로 여러 번 partial_fit()을 호출한다.
7.7연습문제¶
문제 1
(코드 워크아웃) 주성분 분석(PCA) 내용을 학습하라.
문제 3
Kaggle: Principal Component Analysis의 Your Turn에서 제시된 문제(Improve your feature set)를 해결하라.