이 장에서는 UCI Machine Learning Repository의 레드 와인 품질 데이터셋을 이용하여 품질이 좋은 와인을 찾는 이진 분류 문제를 다룬다. 분류 모델을 훈련하기 전에 데이터의 구조와 분포를 충분히 살펴보고, 정확도뿐만 아니라 혼동 행렬, 정밀도, 재현율을 함께 해석한다. 또한 랜덤 포레스트 모델을 활용하여 와인 품질 분류에 중요하게 사용된 주요 특성을 확인한다.
기본 설정
머신러닝 프로젝트에 필요한 기본 라이브러리를 불러온다.
numpy: 어레이 기반 데이터 처리pandas: 데이터프레임 기반 데이터 처리matplotlib.pyplot: 데이터 시각화seaborn: 통계 기반 데이터 시각화sklearn: 머신러닝 모델 훈련
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsseaborn 라이브러리의 기본 시각화 테마를 흰색 격자 배경을 사용하는 스타일로 지정한다.
sns.set_theme(style="whitegrid")데이터프레임 내 부동소수점을 소수점 이하 6자리까지만 출력하도록 지정한다.
pd.set_option('display.precision', 6)데이터 저장소
data_url = 'https://raw.githubusercontent.com/codingalzi/code-workout-datasci/refs/heads/master/data/'24.1프로젝트 흐름¶
분류 프로젝트의 진행 과정은 회귀 프로젝트와 기본적으로 동일하다. 보통 다음 순서로 진행된다.
문제 정의
모델 유형 확인
데이터 적재
데이터 구조 파악
훈련셋과 테스트셋
탐색적 데이터 분석
전처리
모델 선택과 훈련
모델 평가
모델 활용
24.21단계: 문제 정의¶
데이터셋
와인 품질 데이터셋은 포르투갈 비뉴 베르드 레드 와인의 물리화학적 측정값과 시음 평가로 매긴 품질 점수를 담고 있다.
| 특성 | 설명 |
|---|---|
fixed acidity | 고정 산도 |
volatile acidity | 휘발성 산도 |
citric acid | 구연산 함량 |
residual sugar | 잔당 |
chlorides | 염화물 함량 |
free sulfur dioxide | 유리 이산화황 |
total sulfur dioxide | 총 이산화황 |
density | 밀도 |
pH | 산성도 지표 |
sulphates | 황산염 |
alcohol | 알코올 도수 |
quality | 품질 점수, 원래 타깃 |
문제 정의
quality가 7 이상인 와인을 good, 나머지를 ordinary로 정의하고, 이 두 클래스를 예측하는 분류 문제를 머신러닝 모델로 해결한다.
24.32단계: 모델 유형 확인¶
quality 값을 기준으로 와인을 good 또는 ordinary 중 하나로 구분하는 머신러닝 모델을 훈련시켜야 한다.
예측값은 두 개의 범주 중 하나이므로 이진 분류 과제에 해당한다.
이 과제를 해결하기 위해 분류용 머신러닝 모델을 선택하고, 와인 품질 데이터셋을 이용하여 모델을 훈련시킨다. 모델 훈련은 지도 학습 방식으로 진행된다. 이는 와인 품질 데이터셋에 정답에 해당하는 품질 레이블이 포함되어 있으며, 모델이 주어진 입력 특성을 바탕으로 와인의 품질 등급을 최대한 정확하게 예측하도록 학습하기 때문이다.
24.43단계: 데이터 적재¶
UCI에서 제공하는 CSV 파일을 읽고, 품질 점수를 기준으로 이진 타깃을 만든다. head()는 열 이름과 값의 형태를 빠르게 확인하는 데 도움이 된다.
wine_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
wine_df = pd.read_csv(wine_url, sep=";")불러온 데이터는 다음과 같다.
wine_df.head()24.54단계: 데이터 구조 확인¶
데이터의 크기, 열의 자료형, 결측치, 기본 통계량, 타깃 클래스 구성을 확인한다.
와인 데이터셋은 총 1599개의 샘플과 12개의 특성으로 구성되었다.
wine_df.shape(1599, 12)각 열의 자료형과 결측치가 아닌 값의 수를 확인하면서 동시에 수치형 특성과 범주형 특성을 확인한다.
결측치는 전혀 없는 것으로 확인되며,
quality 특성 이외에는 모두 부동소수점을 값으로 갖는 수치형 특성이다.
wine_df.info()<class 'pandas.DataFrame'>
RangeIndex: 1599 entries, 0 to 1598
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 fixed acidity 1599 non-null float64
1 volatile acidity 1599 non-null float64
2 citric acid 1599 non-null float64
3 residual sugar 1599 non-null float64
4 chlorides 1599 non-null float64
5 free sulfur dioxide 1599 non-null float64
6 total sulfur dioxide 1599 non-null float64
7 density 1599 non-null float64
8 pH 1599 non-null float64
9 sulphates 1599 non-null float64
10 alcohol 1599 non-null float64
11 quality 1599 non-null int64
dtypes: float64(11), int64(1)
memory usage: 150.0 KB
quality 특성
quality 특성은 1점과 10점 사이의 정수 품질 점수이며, 높은 값일 수록 좋은 품질을 의미하기에
수치형 특성으로 간주하는 게 원칙이다.
하지만 여기서는 7 이상을 good, 아니면 ordinary 두 특성으로 구분하는 용도로 사용하기에 수치형 특성 여부는 전혀 중요하지 않다.
먼저 value_counts() 메서드를 이용하여 어떤 점수가 몇 번씩 사용되었는지 확인한다.
wine_df['quality'].value_counts().sort_index()quality
3 10
4 53
5 681
6 638
7 199
8 18
Name: count, dtype: int64수치형 특성
quality 특성을 제외한 수치형 특성의 기본 통계량을 확인한다.
특성마다 값의 범위가 크게 다르면 표준화 등 일부 특성의 전처리가 필요할 수 있다.
wine_df.select_dtypes(include="float").describe()수치형 특성별로 히스토그램을 통해 다음 정보를 얻을 수 있다.
각 특성마다 사용되는 단위와 스케일이 다르다. 1 미만 단위부터 백 단위까지 다양하다.
일부 특성은 한쪽으로 치우쳐저 있다. 특히
residual sugar,chlorides,free sulfur dioxide,total sulfur dioxide,sulphate,alcohol은 오른쪽 꼬리가 길다.
wine_df.hist(bins=35, figsize=(12, 10))
plt.show()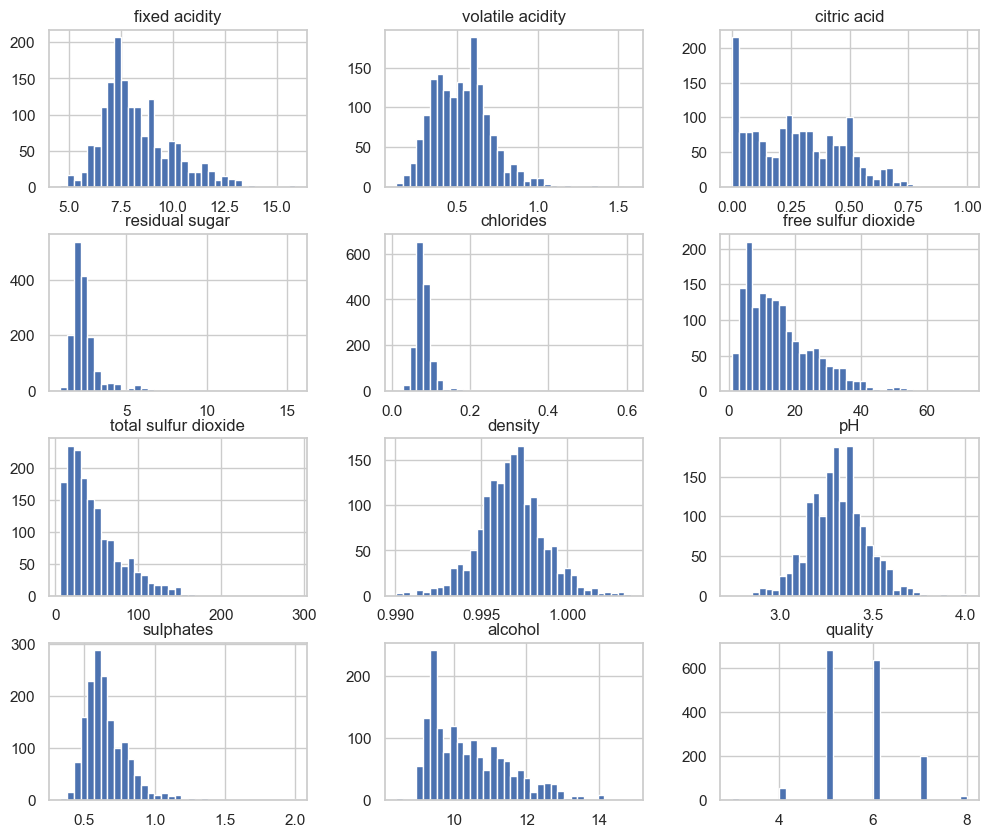
훈련에 사용되는 특성
quality가 7 이상인 와인을 구별해 내기 위해 quality_label 특성이 필요하다.
특성값은 quality > 7이면 good, 나머지를 ordinary로 지정된다.
wine_df["quality_label"] = (wine_df["quality"] >= 7).map({True: "good", False: "ordinary"})good 범주와 ordinaly 범주는 각각 13.6%, 86.4%로 ordinary 범주가 압도적으로 많다.
wine_df["quality_label"].value_counts(normalize=True)quality_label
ordinary 0.86429
good 0.13571
Name: proportion, dtype: float64quality, quality_label 두 특성 이외의 다른 특성은 모델 훈련에 필요한 입력 특성으로 사용된다.
24.65단계: 훈련셋과 테스트셋¶
모델 훈련을 시작하기 전에 전체 데이터셋을 훈련셋과 테스트셋으로 나눈다. 훈련셋은 모델을 학습시키는 데 사용하고, 테스트셋은 훈련이 끝난 뒤 모델의 성능을 평가하는 데 사용한다.
X는 모델 입력에 사용할 특성값으로 구성된 데이터프레임이고, y는 예측 대상인 타깃 레이블로 구성된 시리즈이다.
아래 코드는 train_test_split() 함수를 이용하여 전체 데이터셋의 20%를 테스트셋으로 분리한다.
stratify=y는 타깃인 quality_label의 클래스 비율이 훈련셋과 테스트셋에서 비슷하게 유지되도록 층화 샘플링을 적용한다.
good 클래스가 상대적으로 적기 때문에, 단순 무작위 분할보다 층화 샘플링을 사용하는 편이 평가 결과를 더 안정적으로 해석하는 데 도움이 된다.
from sklearn.model_selection import train_test_split
X = wine_df.drop(columns=["quality", "quality_label"]) # 입력 특성 데이터셋
y = wine_df["quality_label"] # 타깃 레이블 데이터셋
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
stratify=y,
random_state=42)층화 샘플링으로 얻은 표본이 전체 데이터의 분포를 잘 반영하는지도 그래프로 확인할 수 있다. 아래에서는 전체 데이터셋과 층화 샘플링 방식으로 나눈 두 데이터셋을 비교한다.
quality_label_ratio = pd.DataFrame({
"Full Dataset": wine_df["quality_label"].value_counts(normalize=True),
"Train Set": y_train.value_counts(normalize=True),
"Test Set": y_test.value_counts(normalize=True),
})
quality_label_ratioquality_label_ratio.plot.bar(rot=0, figsize=(9, 5))
plt.xlabel("")
plt.ylabel("Proportion")
plt.show()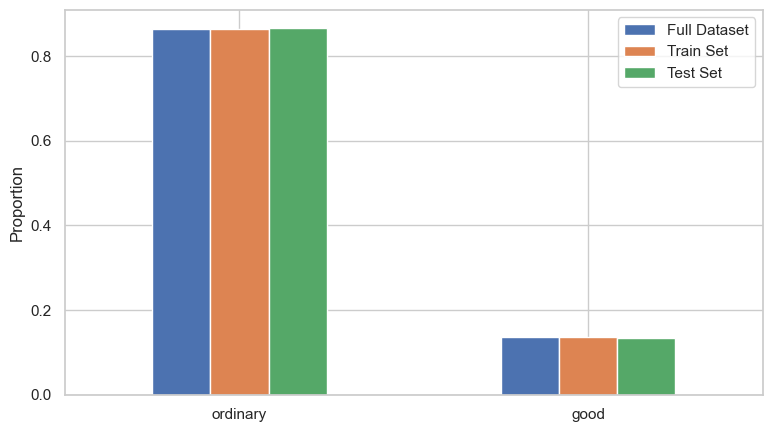
24.76단계: 탐색적 데이터 분석¶
머신러닝 모델 훈련을 본격적으로 시작하기에 앞서 탐색적 데이터 분석(EDA)을 진행한다. 여기서는 다음 질문에 답해 본다.
물리화학적 측정값이 와인의 품질 등급 예측에 도움이 될까?
지금까지와 달리, 여기서는 훈련셋만을 대상으로 EDA를 진행한다.
EDA에 사용할 훈련셋 데이터프레임을 준비한다.
X_train에는 모델 입력 특성만 포함되어 있으므로, 원래 품질 점수 quality와 이진 타깃 quality_label을 함께 붙여 분석용 데이터프레임을 만든다.
데이터 불균형
원래 품질 점수 분포와 이진 타깃 분포를 막대그래프로 확인하면, 점수 7 이상을 good으로 묶었을 때 두 클래스의 불균형이 어떻게 생기는지 시각적으로 확인할 수 있다.
wine_train = X_train.copy()
wine_train["quality"] = wine_df.loc[X_train.index, "quality"]
wine_train["quality_label"] = y_train
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
sns.countplot(data=wine_train, x="quality", ax=axes[0])
axes[0].set_title("Quality score counts")
axes[0].set_xlabel("quality")
axes[0].set_ylabel("count")
sns.countplot(data=wine_train, x="quality_label", order=["ordinary", "good"], ax=axes[1])
axes[1].set_title("Binary quality label counts")
axes[1].set_xlabel("quality label")
axes[1].set_ylabel("count")
plt.tight_layout()
plt.show()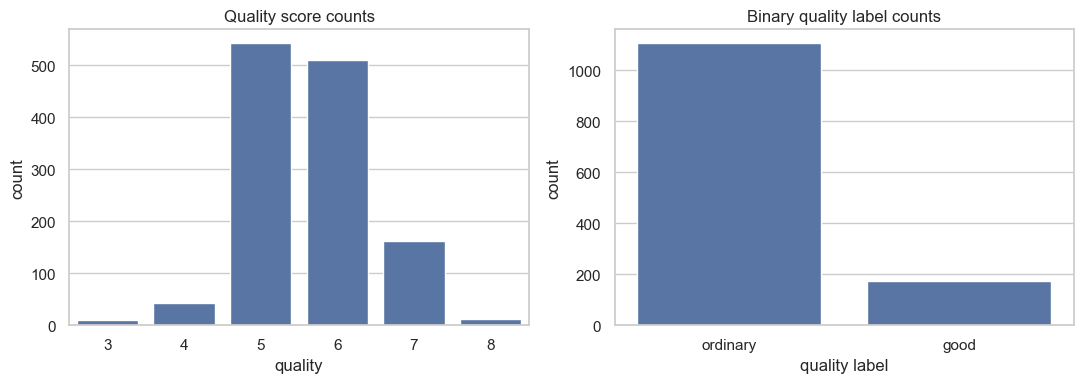
전체 특성을 한꺼번에 살펴보기보다, 선행 연구와 변수 중요도 분석에서 품질 예측에 중요한 것으로 나타난 알코올 도수, 휘발성 산도, 황산염, 밀도를 먼저 살펴본다. 이 변수들은 각각 알코올 함량, 초산 계열 산도, 황산염 농도, 와인의 전체적인 조성에 따른 밀도를 측정한다.
selected_features = [
"alcohol",
"volatile acidity",
"sulphates",
"density",
]
wine_train[selected_features + ["quality", "quality_label"]].head()상자 그림
선택한 특성의 클래스별 분포를 상자그림으로 비교한다. 상자그림은 두 클래스의 중앙값과 분포 범위가 어느 정도 다르고, 얼마나 겹치는지 보여준다.
그래프를 보면 good 와인은 ordinary 와인보다 알코올 도수와 황산염 값이 전반적으로 높은 편이다.
반대로 휘발성 산도와 밀도는 good 와인에서 상대적으로 낮은 경향을 보인다.
fig, axes = plt.subplots(2, 2, figsize=(10, 7))
for feature, ax in zip(selected_features, axes.ravel()):
sns.boxplot(data=wine_train, x="quality_label", y=feature, order=["ordinary", "good"], ax=ax)
ax.set_title(feature)
ax.set_xlabel("quality label")
plt.tight_layout()
plt.show()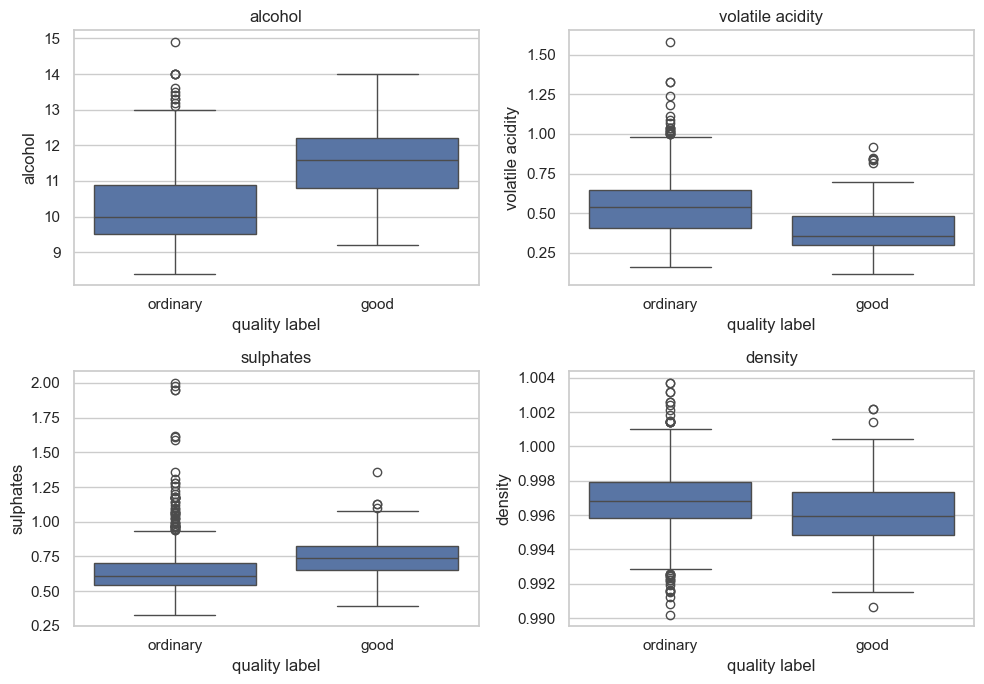
산점도
알코올 도수와 휘발성 산도의 조합을 산점도로 확인한다.
한 개 특성만 볼 때보다 두 특성을 함께 보았을 때 good 와인이 모이는 경향이 있는지 파악할 수 있다.
산점도를 보면 good 와인은 대체로 알코올 도수가 높고 휘발성 산도가 낮은 영역에 비교적 많이 분포한다.
특히 알코올 도수가 11 이상이면서 휘발성 산도가 0.5 이하인 구간에서 good 샘플이 눈에 띈다.
하지만 같은 영역에도 ordinary 와인이 함께 존재하므로, 두 특성만으로 두 클래스를 완전히 분리하기는 어렵다.
sns.scatterplot(
data=wine_train,
x="alcohol",
y="volatile acidity",
hue="quality_label",
hue_order=["ordinary", "good"],
alpha=0.7,
)
plt.title("Alcohol and volatile acidity by quality label")
plt.show()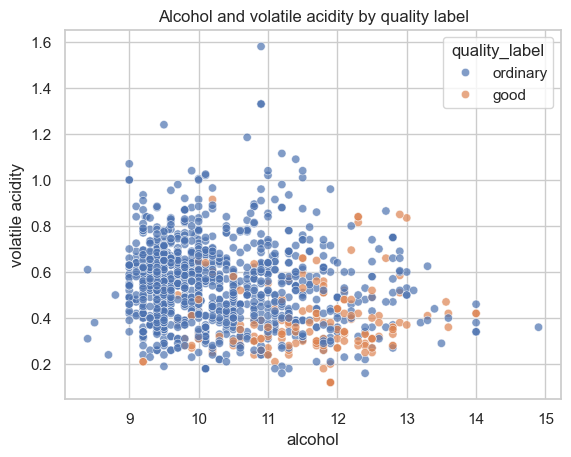
상관 계수
훈련셋의 수치형 특성들과 원래 품질 점수 사이의 상관계수를 히트맵으로 시각화한다. 상관계수는 선형적인 관계를 요약하므로, 품질과 관련이 큰 후보 특성을 찾는 출발점으로 사용할 수 있다.
히트맵에서는 품질 점수와 각 수치형 특성의 관계뿐만 아니라 입력 특성들 사이의 관계도 함께 확인할 수 있다.
예를 들어 fixed acidity와 citric acid, fixed acidity와 density처럼 서로 관련이 큰 특성 쌍이 있으며, 이런 관계는 모델 해석이나 특성 선택을 고민할 때 참고할 수 있다.
corr = wine_train.drop(columns="quality_label").corr()
plt.figure(figsize=(10, 8))
sns.heatmap(corr, annot=True, fmt=".2f", cmap="Blues", vmin=-1, vmax=1)
plt.title("Correlation between numerical features")
plt.show()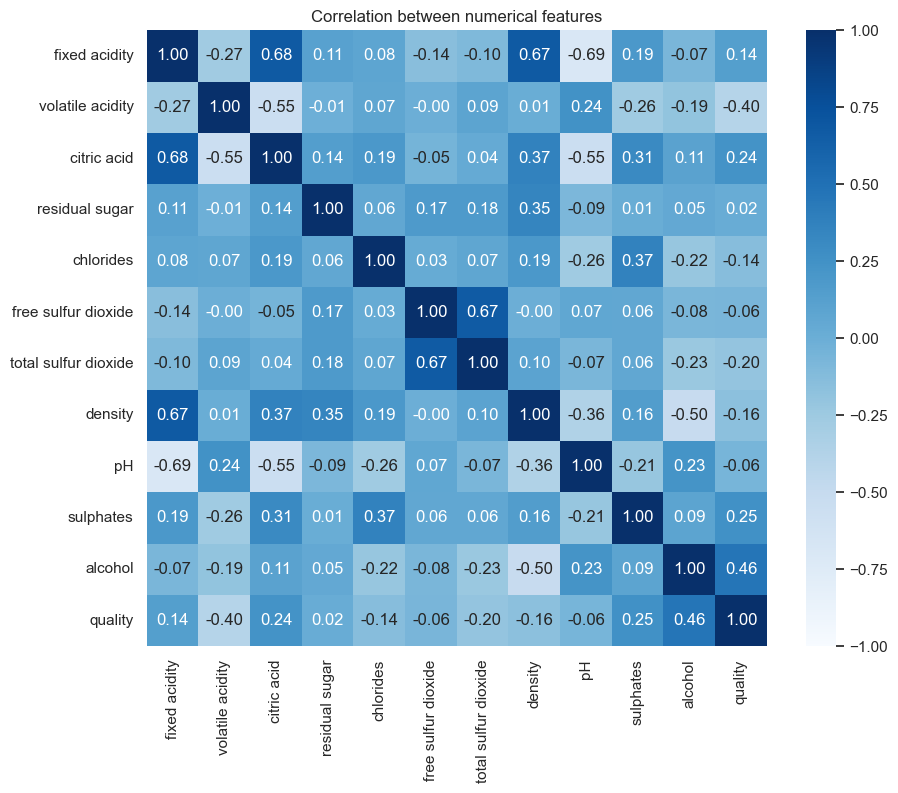
품질 점수와 각 특성의 상관계수만 따로 정렬하면 어떤 특성이 상대적으로 강한 양의 관계 또는 음의 관계를 갖는지 더 쉽게 비교할 수 있다. 단, 상관관계만으로 품질을 결정하는 원인이라고 결론 내릴 수는 없다.
훈련셋에서는 alcohol이 품질 점수와 가장 큰 양의 상관관계를 보이고, sulphates와 citric acid도 양의 상관관계를 보인다.
반대로 volatile acidity는 가장 큰 음의 상관관계를 보이며, total sulfur dioxide, density, chlorides도 품질 점수와 음의 관계를 보인다.
quality_correlation = (
corr["quality"]
.drop("quality")
.sort_values()
.rename("correlation_with_quality")
)
quality_correlation.to_frame()훈련셋을 대상으로 한 EDA 결과에서 다음을 확인할 수 있다.
품질 점수가 7 이상인
good와인은ordinary와인보다 적어 클래스 불균형이 존재한다.good와인은ordinary와인보다 알코올 도수와 황산염 값이 상대적으로 높은 경향을 보인다.volatile acidity는 품질 점수와 가장 뚜렷한 음의 상관관계를 보이며,good와인에서 상대적으로 낮은 경향을 보인다.density,chlorides,total sulfur dioxide도 품질 점수와 음의 관계를 보이지만, 관계의 크기는volatile acidity보다 작다.각 클래스의 분포가 완전히 분리되지는 않으므로 여러 특성을 함께 사용하는 분류 모델이 필요하다.
24.87단계: 전처리 파이프라인¶
일부 머신러닝 모델은 입력 특성의 스케일이 비슷할 때 더 안정적으로 학습된다. 이전 회귀 프로젝트에서는 펭귄의 신체 측정값을 표준화하여 확률적 경사 하강법 모델의 성능을 크게 향상시켰다.
분류 모델에서도 특성의 스케일을 통일하면 학습 안정성과 성능이 향상될 수 있다. 특히 로지스틱 회귀는 특성 스케일의 영향을 많이 받는다. 반면 랜덤 포레스트는 특성값의 상대적인 순서를 기준으로 데이터를 분할하므로 일반적으로 표준화의 영향을 거의 받지 않는다.
이전 장에서는 입력 데이터를 미리 표준화한 뒤 모델 훈련에 사용하였다. 여기서는 표준화와 함께 일부 특성에 로그 변환을 적용하고, 이러한 전처리 단계와 모델을 하나의 파이프라인으로 구성한다. 이를 통해 각 모델에 필요한 전처리를 선택적으로 적용할 수 있다.
로그 변환
아래 코드는 오른쪽 꼬리가 긴 여섯 특성에 log1p를 적용한 뒤 히스토그램을 다시 그린다.
log1p(x)는 log(1+x)를 계산하여 큰 값을 상대적으로 많이 압축하므로 치우친 분포를 완화할 수 있다.
1+x처럼 1을 더한 뒤 로그를 계산하므로 값이 0인 경우에도 사용할 수 있다.
로그 변환은 큰 값과 값 사이의 간격을 더 강하게 압축하여 소수의 매우 큰 값이 모델 학습에 미치는 영향을 줄인다. 그 결과 작은 값들의 차이가 큰 값들의 차이에 비해 상대적으로 더 잘 드러날 수 있다. 변환 전 히스토그램과 비교하면 각 특성의 오른쪽 꼬리가 얼마나 줄어드는지 확인할 수 있다.
log_features = [
"residual sugar",
"chlorides",
"free sulfur dioxide",
"total sulfur dioxide",
"sulphates",
"alcohol",
]
wine_log = np.log1p(wine_df[log_features])
wine_log.hist(bins=35, figsize=(12, 7), layout=(2, 3))
plt.tight_layout()
plt.show()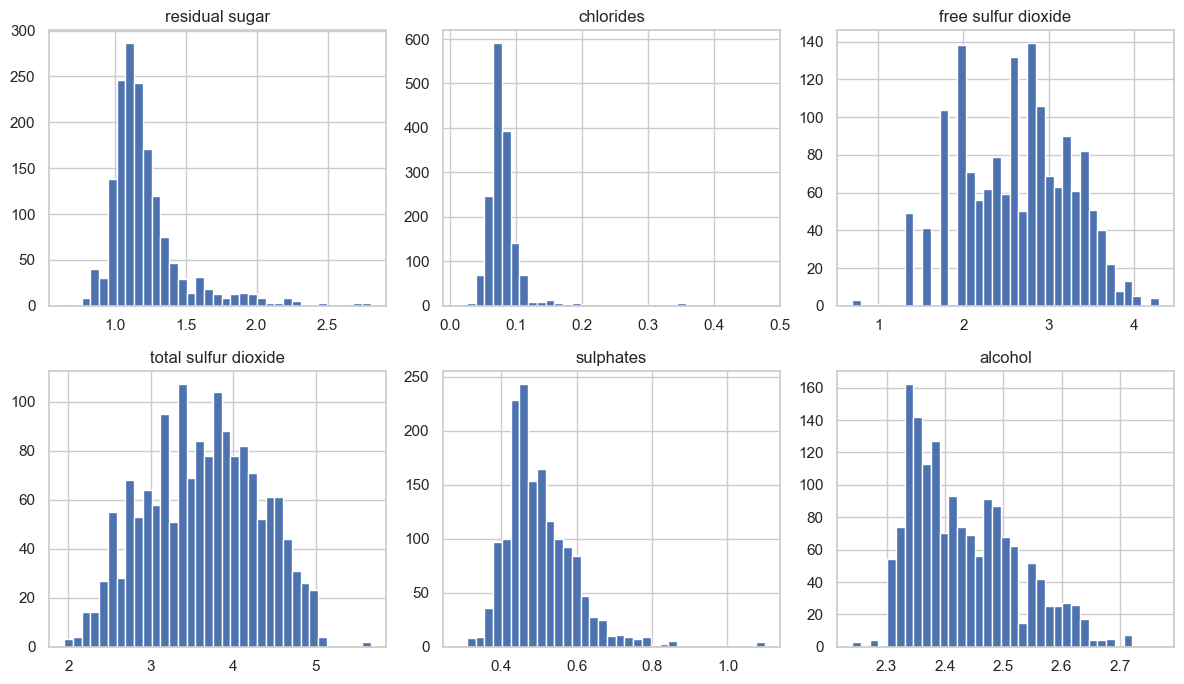
변환 파이프라인
이제 로그 변환과 표준화를 하나의 전처리기 preprocessor로 구성한다. 특성마다 필요한 변환이 다르므로 모든 특성에 동일한 변환을 적용하지 않고 아래 표에서처럼 두 그룹으로 나눈다.
| 대상 특성 | 적용 변환 | 파이프라인 구성 |
|---|---|---|
residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, sulphates, alcohol | log1p 로그 변환 → 표준화 | log_pipeline |
| 나머지 특성 | 표준화 | remainder=StandardScaler() |
아래 코드에서 preprocessor는 표에 언급된 변환을 동시에 처리하는 전처리 변환기를 가리킨다.
log_features: 로그 변환이 필요한 여섯 특성의 이름을 가리킨다.log_pipeline:FunctionTransformer(np.log1p)는 넘파이 함수인np.log1p를 사이킷런의 전처리 단계로 사용할 수 있게 감싼다.make_pipeline()은 로그 변환과StandardScaler를 연결한다.
preprocessor:ColumnTransformer는 열 그룹별로 서로 다른 전처리를 적용한다.transformers에 지정한 여섯 특성에는log_pipeline을 적용한다.여기에 포함되지 않은 나머지 특성에는
remainder=StandardScaler()를 통해 표준화만 적용한다.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer, StandardScaler
# 로그 변환이 필요한 특성 목록
log_features = [
"residual sugar",
"chlorides",
"free sulfur dioxide",
"total sulfur dioxide",
"sulphates",
"alcohol",
]
# 로그 변환과 표준화가 포함된 파이프라인
log_pipeline = make_pipeline(
FunctionTransformer(np.log1p), # 로그 변환
StandardScaler(), # 표준화
)
# 전체 특성에 대해 로그 변환과 표준화를 적용하는 ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[("log", log_pipeline, log_features)],
remainder=StandardScaler(),
)
preprocessorpreprocessor는 로그 변환과 표준화를 처리하는 전처리 변환기 객체이다. 위 코드는 변환 규칙을 구성하기만 하며 아직 실제 데이터를 변환하거나 표준화에 필요한 평균값과 표준편차를 계산하지 않는다.
preprocessor는 예측 모델과 하나의 파이프라인으로 연결된 후에 파이프라인의 fit(X_train, y_train)이 호출되면, 그제서야 먼저 훈련셋의 특성들 각각에 대해 지정된 전처리를 적용한다.
바로 이때 표준화에 필요한 특성별 평균값과 표준편차를 계산하여 데이터 변환에 활용되고,
변환된 데이터는 파이프라인에 포함된 예측 모델의 훈련셋으로 활용된다.
이렇게 전처리와 모델 훈련을 하나의 과정으로 묶을 수 있으며, 새로운 데이터에 대한 예측값을 계산할 때에도 훈련셋에서 학습한 것과 동일한 전처리가 자동으로 적용된다.
24.98단계: 모델 선택과 훈련¶
분류 모델로 로지스틱 회귀와 랜덤 포레스트를 사용한다. 두 모델은 데이터를 학습하는 방식과 전처리의 필요성이 서로 다르다.
| 모델 | 학습 방식 | 전처리 |
|---|---|---|
| 로지스틱 회귀 | 입력 특성의 선형 결합으로 범주에 속할 확률 추정 | 로그 변환과 표준화 적용 |
| 랜덤 포레스트 | 여러 결정 트리의 예측을 결합 | 별도의 전처리 없이 원본 특성 사용 |
두 모델 모두 동일한 훈련셋으로 훈련한 뒤 테스트셋에서 성능을 비교한다.
24.9.1로지스틱 회귀¶
로지스틱 회귀는 각 특성에 가중치를 곱한 선형 결합을 이용하여 샘플이 특정 클래스에 속할 확률을 추정한다. 특성의 스케일 차이에 영향을 받으므로 앞서 만든 preprocessor와
로지스틱 회귀 모델을 하나의 파이프라인으로 연결한다.
fit()을 호출하면 파이프라인이 훈련셋으로 전처리 기준을 학습하고, 변환된 데이터를 로지스틱 회귀 모델에 전달하여 연속해서 훈련한다.
from sklearn.linear_model import LogisticRegression
logistic_pipeline = make_pipeline(
preprocessor,
LogisticRegression(),
)
logistic_pipeline.fit(X_train, y_train)24.9.2랜덤 포레스트¶
랜덤 포레스트는 여러 개의 결정 트리를 만들고, 각 트리의 예측을 모아 최종 결과를 정하는 모델이다. 하나의 트리만 사용할 때보다 여러 트리의 의견을 함께 반영하므로 더 안정적으로 예측할 수 있다.
결정 트리는 값이 큰지 작은지를 기준으로 데이터를 나눈다. 따라서 숫자의 단위를 맞추는 표준화나 값의 크기를 줄이는 log1p 변환을 적용해도 값의 순서가 같다면 학습 결과가 기본적으로 달라지지 않는다. 그래서 랜덤 포레스트에는 앞에서 만든 전처리 파이프라인을 적용하지 않고 원본 데이터를 그대로 사용한다.
from sklearn.ensemble import RandomForestClassifier
forest_model = RandomForestClassifier(
n_estimators=300,
random_state=42,
)
forest_model.fit(X_train, y_train)24.109단계: 모델 평가¶
훈련한 분류 모델이 새로운 데이터도 잘 분류하는지 알아보기 위해 테스트셋으로 성능을 평가한다. 이때 전체 예측 중 몇 개를 맞혔는지 나타내는 정확도뿐만 아니라, 모델이 각 클래스를 어떻게 예측했는지 보여주는 혼동 행렬, 정밀도, 재현율도 함께 확인한다. 여러 지표를 함께 살펴보면 정확도만으로는 알기 어려운 모델의 장단점을 파악할 수 있다.
24.10.1정확도¶
먼저 로지스틱 회귀 파이프라인으로 테스트셋을 대상으로 모델 예측값의 정확도를 계산한다. 정확도는 전체 샘플 중 올바르게 분류한 샘플의 비율이다.
from sklearn.metrics import (
ConfusionMatrixDisplay,
accuracy_score,
confusion_matrix,
precision_score,
recall_score,
)
# 로지스틱 회귀 모델 예측 및 평가
logistic_pred = logistic_pipeline.predict(X_test)
logistic_accuracy = accuracy_score(y_test, logistic_pred)
# 정확도 출력
print("로지스틱 회귀 모델 정확도:", logistic_accuracy)로지스틱 회귀 모델 정확도: 0.8875
y_test.value_counts(normalize=True)quality_label
ordinary 0.865625
good 0.134375
Name: proportion, dtype: float64정확도는 약 89%로 높은 편이다. 하지만 모든 와인을 무조건 ordinary로 예측해도 약 86.6%의 정확도를 얻을 수 있다.
이처럼 클래스 비율이 크게 불균형한 데이터에서는 정확도가 높더라도 모델의 성능이 반드시 좋다고 판단할 수 없다. 이런 경우엔 혼동 행렬, 정밀도, 재현율 등 다른 평가 지표도 함께 확인해야 한다.
24.10.2혼동 행렬¶
혼동 행렬은 실제 클래스와 예측 클래스의 조합별 샘플 수를 보여준다. 행은 실제 클래스, 열은 예측 클래스를 나타낸다.
| 실제 클래스 | 예측 클래스 | 의미 |
|---|---|---|
ordinary | ordinary | 일반 와인을 올바르게 분류 |
ordinary | good | 일반 와인을 좋은 와인으로 잘못 분류 |
good | ordinary | 좋은 와인을 놓침 |
good | good | 좋은 와인을 올바르게 찾음 |
labels = ["ordinary", "good"]
logistic_cm = confusion_matrix(y_test, logistic_pred, labels=labels)
ConfusionMatrixDisplay(logistic_cm, display_labels=labels).plot(cmap="Blues")
plt.title("Logistic regression confusion matrix")
plt.show()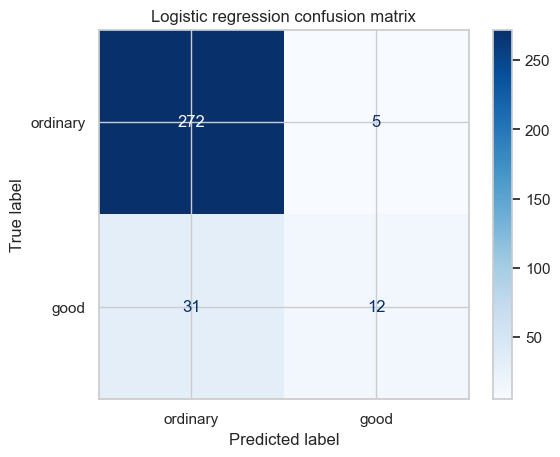
24.10.3정밀도와 재현율¶
정확도는 전체 예측을 하나의 숫자로 요약한다. 하지만 이 데이터처럼 ordinary가 많고 good이 적으면, 모델이 대부분을 ordinary로 예측해도 정확도가 높게 나올 수 있다. 따라서 우리가 관심 있는 good 클래스를 모델이 얼마나 잘 구분하는지 따로 확인해야 한다.
| 평가 지표 | 어디에서 출발하는가? | good 클래스에서의 질문 |
|---|---|---|
| 정밀도(precision) | 모델이 good이라고 예측한 와인 | 그중 실제로 good인 와인은 얼마나되는가? |
| 재현율(recall) | 실제로 good인 와인 | 그중 모델이 good이라고 찾아낸 와인은얼마나 되는가? |
이 모델은 와인 17개를 good이라고 예측했고 그중 12개가 실제로 good이므로 정밀도는 12/17인 약 0.71이다. 한편 테스트셋의 실제 good 와인은 43개이고 모델이 그중 12개를 찾아냈으므로 재현율은 12/43인 약 0.28이다. 즉, 같은 12개를 맞혔더라도 무엇을 기준으로 계산하는지에 따라 의미가 달라진다.
정밀도가 높다: 모델이
good이라고 고른 결과를 비교적 믿을 수 있다.재현율이 높다: 실제
good와인을 많이 놓치지 않고 찾아낸다.
어떤 지표가 더 중요한지는 목적에 따라 달라진다. 추천 목록에 확실히 좋은 와인만 넣고 싶다면 정밀도를 중요하게 볼 수 있다. 반대로 좋은 와인을 가능한 한 빠짐없이 후보에 포함하고 싶다면 재현율이 더 중요하다.
24.10.4모델 성능 비교¶
랜덤 포레스트도 같은 테스트셋을 예측하게 한 뒤 로지스틱 회귀와 정확도, good 정밀도, good 재현율을 비교한다. 같은 데이터 분할을 사용해야 두 모델의 차이를 공정하게 비교할 수 있다.
forest_pred = forest_model.predict(X_test)랜덤 포레스트의 혼동 행렬은 다음과 같다.
일단 good 이라고 예측된 샘플이 수가 26개로 늘어났다.
forest_cm = confusion_matrix(y_test, forest_pred, labels=labels)
ConfusionMatrixDisplay(forest_cm, display_labels=labels).plot(cmap="Greens")
plt.title("Random forest confusion matrix")
plt.show()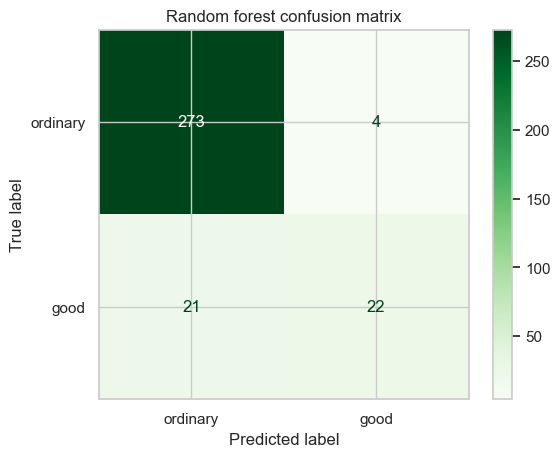
아래 코드는 로지스틱 회귀 모델과 랜덤 포레스트 모델을 정확도, 재현율, 정밀도 기준으로 비교하는 표를 담은 데이터프레임을 생성한다.
model_comparison = pd.DataFrame({
"accuracy": [
logistic_accuracy,
accuracy_score(y_test, forest_pred),
],
"good_precision": [
precision_score(y_test, logistic_pred, pos_label="good"),
precision_score(y_test, forest_pred, pos_label="good"),
],
"good_recall": [
recall_score(y_test, logistic_pred, pos_label="good"),
recall_score(y_test, forest_pred, pos_label="good"),
],
}, index=["logistic regression", "random forest"])
model_comparison랜덤 포레스트 모델이 정확도, 정밀도, 재현율 모든 면에서 성능이 더 좋다.
24.1110단계: 모델 활용¶
랜덤 포레스트는 각 특성이 트리의 분할 과정에서 불순도를 얼마나 감소시켰는지를 바탕으로
특성별 중요도를 계산하여 feature_importances_ 속성에 저장한다.
중요도가 높은 특성일 수록 모델이 예측 과정에서 해당 특성을 잘 활용하여 분류기의 성능을 높혔다는 뜻이다.
특성 중요도는 모델의 예측에 기여한 상대적인 정도이며 인과관계를 의미하지 않는다. 또한 서로 강하게 연관된 특성이 있으면 중요도가 여러 특성으로 나뉘어 나타날 수 있다.
feature_importance = pd.DataFrame(forest_model.feature_importances_,
index=X_train.columns,
columns=["importance"])
feature_importance특성 중요도를 기준으로 내림차순으로 막대그래프로 나타내면 랜덤 포레스트가 상대적으로 많이 활용한 특성을 쉽게 비교할 수 있다.
ax = feature_importance.sort_values(by="importance").plot.barh(figsize=(8, 5))
ax.bar_label(ax.containers[0], fmt="%.3f", padding=3) # 막대 위에 중요도 값 표시
ax.margins(x=0.15) # 막대와 축 사이의 여백 조정
plt.title("Random forest feature importance")
plt.xlabel("importance")
plt.ylabel("feature")
plt.tight_layout()
plt.show()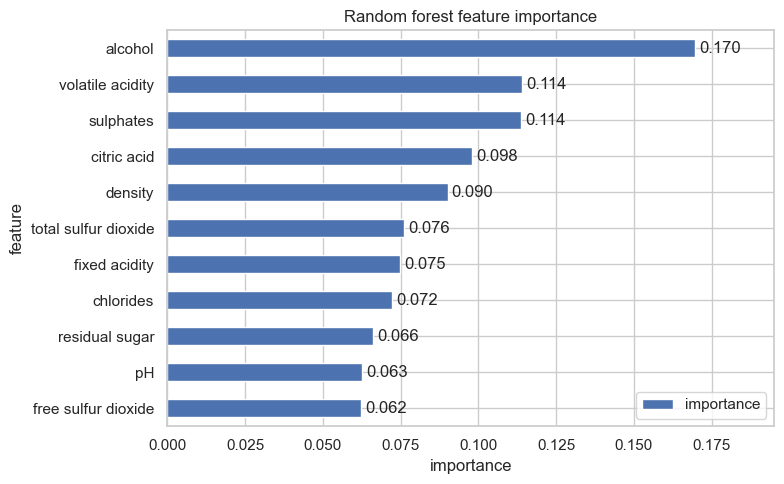
24.12연습문제¶
문제 1
테스트셋의 모든 와인을 ordinary로 예측할 때의 정확도를 구하고, 이 값을 로지스틱 회귀의 정확도와 비교해 보아라. 이 데이터에서 정확도만으로 모델을 평가하기 어려운 이유는 무엇인가?
답:
모든 와인을 ordinary로 예측하면 테스트셋의 ordinary 비율과 같은 약 0.866의 정확도를 얻는다. 이는 로지스틱 회귀의 정확도 약 0.888보다 약 0.022 낮을 뿐이다. 그러나 이 예측은 실제 good 와인을 하나도 찾지 못한다. 따라서 클래스가 불균형한 이 데이터에서는 정확도만으로 관심 클래스인 good을 얼마나 잘 찾는지 판단하기 어렵다.
ordinary_baseline_accuracy = (y_test == "ordinary").mean()
pd.Series({
"모두 ordinary로 예측": ordinary_baseline_accuracy,
"로지스틱 회귀": logistic_accuracy,
}, name="accuracy")모두 ordinary로 예측 0.865625
로지스틱 회귀 0.887500
Name: accuracy, dtype: float64문제 2
두 모델의 혼동 행렬에서 실제 good을 올바르게 찾은 개수와 놓친 개수, good으로 잘못 예측한 개수를 확인하라. 이 값으로 각 모델의 good 정밀도와 재현율을 직접 계산하고, 좋은 와인을 더 많이 찾아내는 모델이 무엇인지 설명해 보아라.
답:
로지스틱 회귀는 실제 good 43개 중 12개를 찾고 31개를 놓쳤으며, 실제 ordinary 5개를 good으로 잘못 예측했다. 따라서 정밀도는 , 재현율은 이다.
랜덤 포레스트는 실제 good 43개 중 22개를 찾고 21개를 놓쳤으며, 실제 ordinary 4개를 good으로 잘못 예측했다. 따라서 정밀도는 , 재현율은 이다. 랜덤 포레스트가 더 많은 good 와인을 찾았고 재현율도 더 높다.
confusion_counts = {}
for model_name, cm in {
"logistic regression": logistic_cm,
"random forest": forest_cm,
}.items():
tn, fp, fn, tp = cm.ravel()
confusion_counts[model_name] = {
"good을 올바르게 찾음": tp,
"good을 놓침": fn,
"ordinary를 good으로 잘못 예측": fp,
"good_precision": tp / (tp + fp),
"good_recall": tp / (tp + fn),
}
pd.DataFrame(confusion_counts).T문제 3
랜덤 포레스트의 특성 중요도에서 상위 세 특성을 확인하고, EDA에서 관찰한 품질과의 관계와 비교해 보아라. 특성 중요도가 높다는 사실만으로 해당 특성이 와인 품질의 원인이라고 결론 내릴 수 없는 이유도 설명하라.
답:
특성 중요도가 높은 상위 세 특성은 alcohol, volatile acidity, sulphates이다. EDA에서도 good 와인은 ordinary 와인보다 알코올 도수와 황산염이 높은 경향을 보였고, 휘발성 산도는 낮은 경향을 보였다. 따라서 랜덤 포레스트가 중요하게 사용한 특성은 EDA에서 품질과 비교적 뚜렷한 관계를 보인 특성과 대체로 일치한다.
다만 특성 중요도는 모델의 분할 과정에서 해당 특성이 예측에 기여한 상대적인 정도이다. 관찰 데이터에 나타난 연관성과 모델의 활용도를 보여줄 뿐이며, 다른 특성과의 상관관계나 측정되지 않은 요인의 영향이 있을 수 있으므로 인과관계를 뜻하지 않는다.
feature_importance.sort_values(
by="importance",
ascending=False,
).head(3)문제 4
good의 기준을 quality >= 6으로 변경한 뒤 타깃 생성, 층화 분할, 모델 훈련과 평가 과정을 다시 수행하라. 클래스 분포와 두 모델의 정확도, good 정밀도, good 재현율이 기존 결과와 어떻게 달라지는지 비교하고 그 이유를 설명해 보아라.
답:
good의 기준을 6점 이상으로 낮추면 전체 데이터에서 good은 855개로 약 53.5%, ordinary는 744개로 약 46.5%가 된다. 기존 기준에서는 good이 약 13.6%에 불과했지만 새 기준에서는 두 클래스의 크기가 비슷해진다.
새 기준에서 로지스틱 회귀의 정확도, good 정밀도, good 재현율은 각각 약 0.759, 0.780, 0.766이고, 랜덤 포레스트는 약 0.844, 0.846, 0.865이다. 기존 결과와 비교하면 두 모델의 정확도는 낮아지지만 good 재현율은 크게 높아진다. 6점 와인이 good에 포함되면서 두 클래스의 경계가 달라지고 good 샘플이 많아져 모델이 good을 더 많이 학습하고 예측할 수 있기 때문이다. 다만 타깃의 정의 자체가 달라졌으므로 두 기준의 지표를 동일한 분류 문제의 성능처럼 직접 비교해서는 안 된다.
from sklearn.base import clone
# quality가 6 이상이면 good으로 지정
y_6 = (wine_df["quality"] >= 6).map({True: "good", False: "ordinary"})
X_6 = wine_df.drop(columns=["quality", "quality_label"])
# 새로운 타깃의 클래스 비율을 유지하도록 다시 분할
X_train_6, X_test_6, y_train_6, y_test_6 = train_test_split(
X_6,
y_6,
test_size=0.2,
stratify=y_6,
random_state=42,
)
# 기존 모델을 복제하여 6점 기준 타깃으로 다시 훈련
logistic_pipeline_6 = clone(logistic_pipeline)
forest_model_6 = clone(forest_model)
logistic_pipeline_6.fit(X_train_6, y_train_6)
forest_model_6.fit(X_train_6, y_train_6)
# 새로운 타깃에 대한 예측 및 모델 비교
logistic_pred_6 = logistic_pipeline_6.predict(X_test_6)
forest_pred_6 = forest_model_6.predict(X_test_6)
# 클래스 분포와 모델 성능 비교
class_distribution_6 = y_6.value_counts().to_frame("count")
class_distribution_6["proportion"] = y_6.value_counts(normalize=True)
model_comparison_6 = pd.DataFrame({
"accuracy": [
accuracy_score(y_test_6, logistic_pred_6),
accuracy_score(y_test_6, forest_pred_6),
],
"good_precision": [
precision_score(y_test_6, logistic_pred_6, pos_label="good"),
precision_score(y_test_6, forest_pred_6, pos_label="good"),
],
"good_recall": [
recall_score(y_test_6, logistic_pred_6, pos_label="good"),
recall_score(y_test_6, forest_pred_6, pos_label="good"),
],
}, index=["logistic regression", "random forest"])
display(class_distribution_6)
display(model_comparison_6)