참고: 오렐리앙 제롱의 <핸즈온 머신러닝(2판)> 1장의 소스코드를 사용합니다.
머신러닝에서 일어나는 일을 한 눈에 볼 수 있도록 실전예제를 사용하여 선형회귀 모델의 훈련과정을 자세하게 소개한다. 사용되는 예제는 한 나라의 1인당 GDP와 해당 국가의 삶의 만족도 사이의 선형회귀 관계를 예측하는 모델이다.
import numpy as np
import pandas as pd
# 노트북 실행 결과를 동일하게 유지하기 위해
np.random.seed(42)
# 깔끔한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
선형회귀 모델을 구현하는 다섯 단계를 밟아가면서 머신러닝 문제해결의 전형적인 과정을 살펴본다.
어느 국가의 1인당 GDP가 알려졌을 때 해당 국가의 삶의 만족도를 예측하는 모델(함수)을 구현한다.
1인당 GDP와 삶의 만족도 사이의 관계를 예측하는 모델을 구현하기위해 소위 모델 훈련 과정을 실행해야 한다. 모델 훈련을 위해 필요한 데이터셋(데이터 집합)을 훈련 세트라 부르며, 훈련 세트는 입력 데이터와 타깃(target) 데이터로 구분된다. 그러면 모델 훈련은 준비된 훈련 세트의 입력 데이터와 타깃 데이터 사이의 관계를 가장 적절하게 묘사하는 특정 모델(함수)을 학습해가는 과정이다.
1인당 GDP와 삶의 만족도 사이의 관계를 가장 적절하게 묘사하는 모델(함수)를 훈련시키기 위해 사용되는 훈련 세트는 여기서는 다음과 같다.
여기서는 2015년 기준 자료를 아래 링크에서 미리 준비된 두 개의 데이터 파일을 다운로드하는 것으로 대체한다. 다만 실제 자료를 아래와 같이 잘 정리된 데이터 파일로 만드는 과정이 일반적으로 간단하지 않다는 점만을 언급해둔다.
oecd_bli_2015.csv: 2015년도 기준 OECD 국가들의 '더 나은 삶의 지수'(BLI) 데이터gdp_per_capita.csv: IMF(국제통화기금)에 제공하는 1인당 국내총생산 데이터(GDP) 데이터다운로드 경로는 다음과 같다.
datapath = "https://raw.githubusercontent.com/codingalzi/handson-ml2/master/notebooks/datasets/lifesat/"
위 경로에 파일의 이름을 추가하면 해당 파일을 다운로드하여 컴퓨터에 저장할 수 있다. 하지만 컴퓨터에 저장하는 대신 이어서 설명하는 데이터 적재를 동시에 진행하는 것으로 데이터 구하기 단계를 해결한다.
컴퓨터에 저장된 또는 다운로드된 데이터는 일반적으로 바로 모델 훈련에 사용할 수 없으며, 데이터 적재, 데이터 정제, 데이터 전처리 등의 과정을 거쳐야 비로소 모델 훈련에 활용될 수 있다.
데이터 적재(data loading): 인터넷에 존재하거나 컴퓨터에 저장되어 있는 파일을 특정 자료형의 값으로 불러오는 과정
데이터 정제(data cleaning): 적재된 데이터셋에 포함된 오류, 부정확한 값, 누락된 값, 상관없는 값 등을 제거, 수정, 보완하는 과정
데이터 전처리(data preprocessing): 정제된 데이터셋에서 출발하여 적절한 내용의 데이터를 추가한 후 적절한 형식으로 변환하는 과정
아래 코드는 IMF 에서 다운로드한 csv 파일에서 2015년 기준 국가별 1인당 GDP 관련 데이터를 데이터프레임 객체로 불러온다.
thousands=',': 1000단위로 쉼표 찍기delimiter='\t': 탭(tab)으로 열 구분encoding='latin1': 인코딩 방식 지정. 파일에서 사용된 'Côte d'Ivoire'(코트디브와르)와 같은 특수 알파벳을 사용하는 국가명 처리용na_values="n/a": 결측치를 'NaN'으로 처리.gdp_per_capita = pd.read_csv(datapath+"gdp_per_capita.csv",
thousands=',',
delimiter='\t',
encoding='latin1',
na_values="n/a")
총 190개 국가의 1인당 GDP 정보를 담고 있다.
gdp_per_capita
| Country | Subject Descriptor | Units | Scale | Country/Series-specific Notes | 2015 | Estimates Start After | |
|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 599.994 | 2013.0 |
| 1 | Albania | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 3995.383 | 2010.0 |
| 2 | Algeria | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4318.135 | 2014.0 |
| 3 | Angola | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4100.315 | 2014.0 |
| 4 | Antigua and Barbuda | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 14414.302 | 2011.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 185 | Vietnam | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 2088.344 | 2012.0 |
| 186 | Yemen | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 1302.940 | 2008.0 |
| 187 | Zambia | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 1350.151 | 2010.0 |
| 188 | Zimbabwe | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 1064.350 | 2012.0 |
| 189 | International Monetary Fund, World Economic Ou... | NaN | NaN | NaN | NaN | NaN | NaN |
190 rows × 7 columns
국가명을 행 인덱스로 지정한다.
gdp_per_capita.set_index("Country", inplace=True)
gdp_per_capita.head()
| Subject Descriptor | Units | Scale | Country/Series-specific Notes | 2015 | Estimates Start After | |
|---|---|---|---|---|---|---|
| Country | ||||||
| Afghanistan | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 599.994 | 2013.0 |
| Albania | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 3995.383 | 2010.0 |
| Algeria | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4318.135 | 2014.0 |
| Angola | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4100.315 | 2014.0 |
| Antigua and Barbuda | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 14414.302 | 2011.0 |
이어서 1인당 GDP 데이터임을 명시하기 위해 열 이름 "2015"를 "GDP per capita"로 변경한다.
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.head()
| Subject Descriptor | Units | Scale | Country/Series-specific Notes | GDP per capita | Estimates Start After | |
|---|---|---|---|---|---|---|
| Country | ||||||
| Afghanistan | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 599.994 | 2013.0 |
| Albania | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 3995.383 | 2010.0 |
| Algeria | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4318.135 | 2014.0 |
| Angola | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 4100.315 | 2014.0 |
| Antigua and Barbuda | Gross domestic product per capita, current prices | U.S. dollars | Units | See notes for: Gross domestic product, curren... | 14414.302 | 2011.0 |
OECD 국가별 삶의 만족도 데이터는 '더 나은 삶의 지수' 데이터 파일에 포함되어 있다. 따라서 먼저 해당 csv 파일을 판다스의 데이터프레임 객체로 불러온 후에 삶의 만족도와 관련된 내용을 추출하는 과정을 밟는다.
pandas.read_csv() 함수는 지정한 경로에 저장되어 있는 csv 파일을 다운로드하여 바로 데이터프레임 객체를
생성한다.oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
생성된 데이터프레임의 모양은 다음과 같다.
oecd_bli.shape
(3292, 17)
처음 5행를 살펴보자.
oecd_bli.head()
| LOCATION | Country | INDICATOR | Indicator | MEASURE | Measure | INEQUALITY | Inequality | Unit Code | Unit | PowerCode Code | PowerCode | Reference Period Code | Reference Period | Value | Flag Codes | Flags | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AUS | Australia | HO_BASE | Dwellings without basic facilities | L | Value | TOT | Total | PC | Percentage | 0 | units | NaN | NaN | 1.1 | E | Estimated value |
| 1 | AUT | Austria | HO_BASE | Dwellings without basic facilities | L | Value | TOT | Total | PC | Percentage | 0 | units | NaN | NaN | 1.0 | NaN | NaN |
| 2 | BEL | Belgium | HO_BASE | Dwellings without basic facilities | L | Value | TOT | Total | PC | Percentage | 0 | units | NaN | NaN | 2.0 | NaN | NaN |
| 3 | CAN | Canada | HO_BASE | Dwellings without basic facilities | L | Value | TOT | Total | PC | Percentage | 0 | units | NaN | NaN | 0.2 | NaN | NaN |
| 4 | CZE | Czech Republic | HO_BASE | Dwellings without basic facilities | L | Value | TOT | Total | PC | Percentage | 0 | units | NaN | NaN | 0.9 | NaN | NaN |
국가별 삶의 만족도는 'Life satisfaction'이라는 측정지표('Indicator') 열(column)의
특성값 중에 하나이다.
총 24개 측정지표가 사용되며 그중에 하나임을 확인할 수 있다.
oecd_bli.Indicator.unique()
array(['Dwellings without basic facilities', 'Housing expenditure',
'Rooms per person', 'Household net adjusted disposable income',
'Household net financial wealth', 'Employment rate',
'Job security', 'Long-term unemployment rate', 'Personal earnings',
'Quality of support network', 'Educational attainment',
'Student skills', 'Years in education', 'Air pollution',
'Water quality', 'Consultation on rule-making', 'Voter turnout',
'Life expectancy', 'Self-reported health', 'Life satisfaction',
'Assault rate', 'Homicide rate',
'Employees working very long hours',
'Time devoted to leisure and personal care'], dtype=object)
oecd_bli.Indicator.unique().shape
(24,)
'Life satisfaction' in oecd_bli.Indicator.unique()
True
그런데 삶의 만족도와 관련된 행이 OECD 회원국의 수인 37보다 많다. 이는 삶의 만족도와 관련해서 데이터의 중복이 있다는 것을 의미한다.
mask = oecd_bli.Indicator == 'Life satisfaction'
oecd_bli[mask].shape
(179, 17)
무엇이 중복되었는지를 알아내기 위해
OECD 회원국가별로 'Indicator' 열에 포함된 24개 측정지표에 해당하는 값(value)만을 따로 추출해보자.
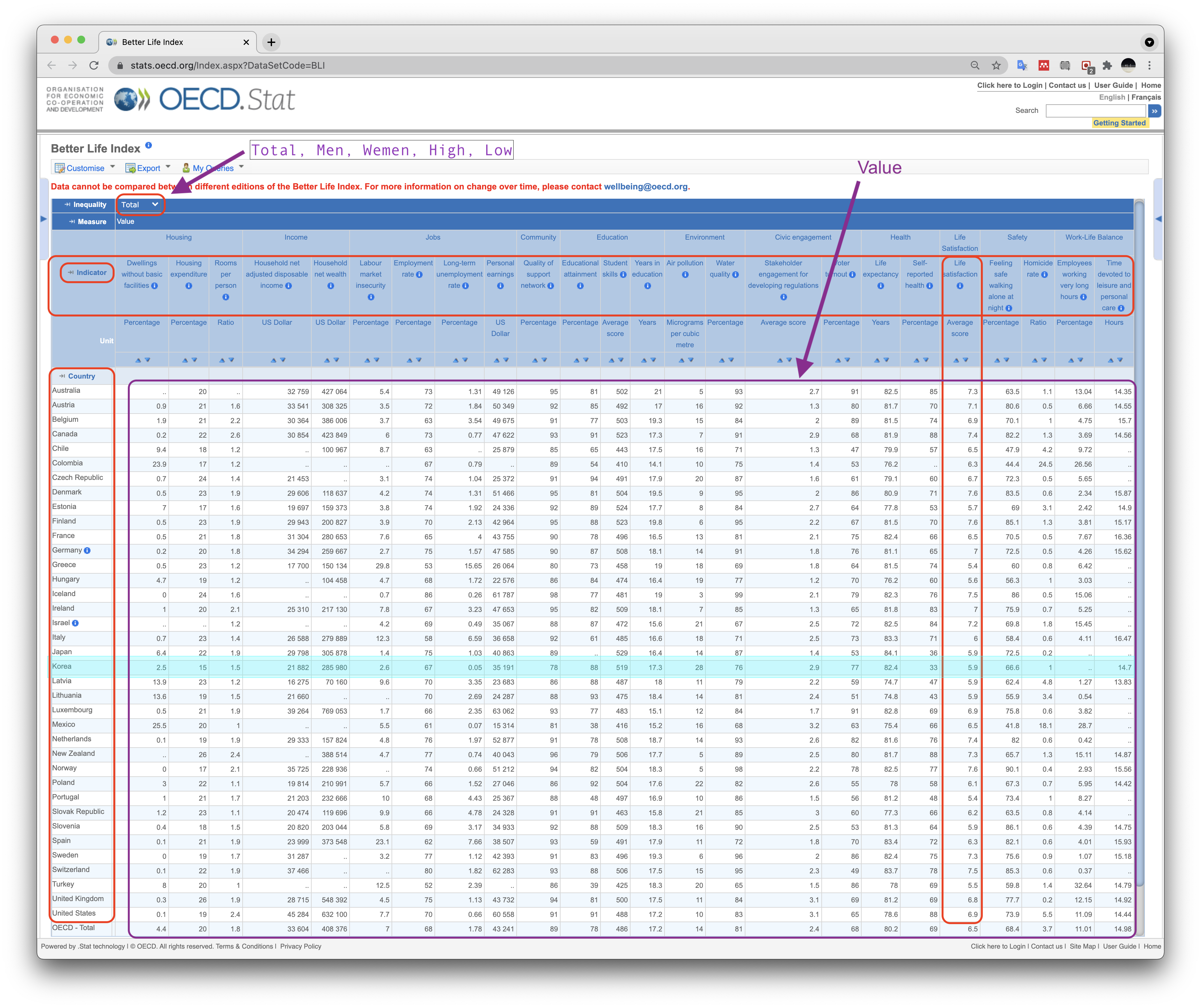
즉, '더 나은 삶의 지수'(BLI, Better Life Index) 자료(2021년 5월 18일 자)에서
볼 수 있는 아래 테이블 이미지와 같은 데이터프레임을 생성하고자 한다.
Country)Indicator)Value)이를 위해 국가명('Country' 열의 항목)을 행의 인덱스 이름으로,
'Indicator'의 항목을 열의 인덱스 이름으로 사용하는
데이터프레임을 생성한다.
해당 열과 항목에 해당하는 값은 'Value' 열에 포함된 값을 사용한다.
이 작업을 위한 전제조건으로 새로운 데이터프레임에 사용될 항목별 값을 유일하게 지정할 수 있어야 한다.
그런데 OECD의 원본 파일에는 각 측정지표의 값으로 국가별 소득 불평등('INEQUALITY')과 관련된 5가지
기준에 따라 다섯 개의 값이 포함되어 있다(위 이미지 좌상단 화살표 참조).
| 기준 | 기호 | 대상 |
|---|---|---|
| Total | TOT | 전체 인구 |
| Men | MN | 남성 |
| Wemen | WMN | 여성 |
| High | HGH | 상위 소득 |
| Low | LW | 하위 소득 |
oecd_bli.INEQUALITY.unique()
array(['TOT', 'MN', 'WMN', 'HGH', 'LW'], dtype=object)
각 기준별 행의 개수는 다음과 같다.
arr1 = oecd_bli.INEQUALITY.unique()
sum = 0
for ineq in arr1:
num_lines = (oecd_bli['INEQUALITY'] == ineq).sum()
sum += num_lines
print(f"{ineq:>3}:\t{num_lines}행")
print(f"\n 총:\t{sum}행")
TOT: 888행 MN: 881행 WMN: 881행 HGH: 328행 LW: 314행 총: 3292행
따라서 먼저 하나의 기준을 선택해서 해당 기준에 맞는 행들만 추출한다. 여기서는 전체 인구를 대상으로 하는 기준을 사용한다.
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
앞서 확인한 대로 총 888행으로 이루어진 데이터프레임이다.
oecd_bli.shape
(888, 17)
여기서 37 * 24 = 888이 성립함에 주목해야 한다.
왜냐하면 이는 위데이터프레임이 37개 OECD 회원국별로 24개의 지표를 조사한 데이터를 포함한다는 의미이기 때문이다.
또한 측정된 지표값은 'Value' 열에 포함되어 있다.
이제 데이터프레임 객체의 pivot() 메서드를 이용하여
'Indicator' 의 항목에 대한 각 국가별 수치만을 추출하기 위해
국가명('Country' 열의 항목)을 행의 인덱스 이름으로,
'Indicator'의 항목을 열의 인덱스 이름으로 사용하면서
해당 행과 열의 항목에는 'Value' 열에 포함된 값을 사용하는
데이터프레임을 아래와 같이 생성할 수 있다.
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
이제 총 37개 국가의 측정지표별 수치를 확인하면 다음과 같다.
oecd_bli
| Indicator | Air pollution | Assault rate | Consultation on rule-making | Dwellings without basic facilities | Educational attainment | Employees working very long hours | Employment rate | Homicide rate | Household net adjusted disposable income | Household net financial wealth | ... | Long-term unemployment rate | Personal earnings | Quality of support network | Rooms per person | Self-reported health | Student skills | Time devoted to leisure and personal care | Voter turnout | Water quality | Years in education |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | |||||||||||||||||||||
| Australia | 13.0 | 2.1 | 10.5 | 1.1 | 76.0 | 14.02 | 72.0 | 0.8 | 31588.0 | 47657.0 | ... | 1.08 | 50449.0 | 92.0 | 2.3 | 85.0 | 512.0 | 14.41 | 93.0 | 91.0 | 19.4 |
| Austria | 27.0 | 3.4 | 7.1 | 1.0 | 83.0 | 7.61 | 72.0 | 0.4 | 31173.0 | 49887.0 | ... | 1.19 | 45199.0 | 89.0 | 1.6 | 69.0 | 500.0 | 14.46 | 75.0 | 94.0 | 17.0 |
| Belgium | 21.0 | 6.6 | 4.5 | 2.0 | 72.0 | 4.57 | 62.0 | 1.1 | 28307.0 | 83876.0 | ... | 3.88 | 48082.0 | 94.0 | 2.2 | 74.0 | 509.0 | 15.71 | 89.0 | 87.0 | 18.9 |
| Brazil | 18.0 | 7.9 | 4.0 | 6.7 | 45.0 | 10.41 | 67.0 | 25.5 | 11664.0 | 6844.0 | ... | 1.97 | 17177.0 | 90.0 | 1.6 | 69.0 | 402.0 | 14.97 | 79.0 | 72.0 | 16.3 |
| Canada | 15.0 | 1.3 | 10.5 | 0.2 | 89.0 | 3.94 | 72.0 | 1.5 | 29365.0 | 67913.0 | ... | 0.90 | 46911.0 | 92.0 | 2.5 | 89.0 | 522.0 | 14.25 | 61.0 | 91.0 | 17.2 |
| Chile | 46.0 | 6.9 | 2.0 | 9.4 | 57.0 | 15.42 | 62.0 | 4.4 | 14533.0 | 17733.0 | ... | 1.59 | 22101.0 | 86.0 | 1.2 | 59.0 | 436.0 | 14.41 | 49.0 | 73.0 | 16.5 |
| Czech Republic | 16.0 | 2.8 | 6.8 | 0.9 | 92.0 | 6.98 | 68.0 | 0.8 | 18404.0 | 17299.0 | ... | 3.12 | 20338.0 | 85.0 | 1.4 | 60.0 | 500.0 | 14.98 | 59.0 | 85.0 | 18.1 |
| Denmark | 15.0 | 3.9 | 7.0 | 0.9 | 78.0 | 2.03 | 73.0 | 0.3 | 26491.0 | 44488.0 | ... | 1.78 | 48347.0 | 95.0 | 1.9 | 72.0 | 498.0 | 16.06 | 88.0 | 94.0 | 19.4 |
| Estonia | 9.0 | 5.5 | 3.3 | 8.1 | 90.0 | 3.30 | 68.0 | 4.8 | 15167.0 | 7680.0 | ... | 3.82 | 18944.0 | 89.0 | 1.5 | 54.0 | 526.0 | 14.90 | 64.0 | 79.0 | 17.5 |
| Finland | 15.0 | 2.4 | 9.0 | 0.6 | 85.0 | 3.58 | 69.0 | 1.4 | 27927.0 | 18761.0 | ... | 1.73 | 40060.0 | 95.0 | 1.9 | 65.0 | 529.0 | 14.89 | 69.0 | 94.0 | 19.7 |
| France | 12.0 | 5.0 | 3.5 | 0.5 | 73.0 | 8.15 | 64.0 | 0.6 | 28799.0 | 48741.0 | ... | 3.99 | 40242.0 | 87.0 | 1.8 | 67.0 | 500.0 | 15.33 | 80.0 | 82.0 | 16.4 |
| Germany | 16.0 | 3.6 | 4.5 | 0.1 | 86.0 | 5.25 | 73.0 | 0.5 | 31252.0 | 50394.0 | ... | 2.37 | 43682.0 | 94.0 | 1.8 | 65.0 | 515.0 | 15.31 | 72.0 | 95.0 | 18.2 |
| Greece | 27.0 | 3.7 | 6.5 | 0.7 | 68.0 | 6.16 | 49.0 | 1.6 | 18575.0 | 14579.0 | ... | 18.39 | 25503.0 | 83.0 | 1.2 | 74.0 | 466.0 | 14.91 | 64.0 | 69.0 | 18.6 |
| Hungary | 15.0 | 3.6 | 7.9 | 4.8 | 82.0 | 3.19 | 58.0 | 1.3 | 15442.0 | 13277.0 | ... | 5.10 | 20948.0 | 87.0 | 1.1 | 57.0 | 487.0 | 15.04 | 62.0 | 77.0 | 17.6 |
| Iceland | 18.0 | 2.7 | 5.1 | 0.4 | 71.0 | 12.25 | 82.0 | 0.3 | 23965.0 | 43045.0 | ... | 1.18 | 55716.0 | 96.0 | 1.5 | 77.0 | 484.0 | 14.61 | 81.0 | 97.0 | 19.8 |
| Ireland | 13.0 | 2.6 | 9.0 | 0.2 | 75.0 | 4.20 | 60.0 | 0.8 | 23917.0 | 31580.0 | ... | 8.39 | 49506.0 | 96.0 | 2.1 | 82.0 | 516.0 | 15.19 | 70.0 | 80.0 | 17.6 |
| Israel | 21.0 | 6.4 | 2.5 | 3.7 | 85.0 | 16.03 | 67.0 | 2.3 | 22104.0 | 52933.0 | ... | 0.79 | 28817.0 | 87.0 | 1.2 | 80.0 | 474.0 | 14.48 | 68.0 | 68.0 | 15.8 |
| Italy | 21.0 | 4.7 | 5.0 | 1.1 | 57.0 | 3.66 | 56.0 | 0.7 | 25166.0 | 54987.0 | ... | 6.94 | 34561.0 | 90.0 | 1.4 | 66.0 | 490.0 | 14.98 | 75.0 | 71.0 | 16.8 |
| Japan | 24.0 | 1.4 | 7.3 | 6.4 | 94.0 | 22.26 | 72.0 | 0.3 | 26111.0 | 86764.0 | ... | 1.67 | 35405.0 | 89.0 | 1.8 | 30.0 | 540.0 | 14.93 | 53.0 | 85.0 | 16.3 |
| Korea | 30.0 | 2.1 | 10.4 | 4.2 | 82.0 | 18.72 | 64.0 | 1.1 | 19510.0 | 29091.0 | ... | 0.01 | 36354.0 | 72.0 | 1.4 | 35.0 | 542.0 | 14.63 | 76.0 | 78.0 | 17.5 |
| Luxembourg | 12.0 | 4.3 | 6.0 | 0.1 | 78.0 | 3.47 | 66.0 | 0.4 | 38951.0 | 61765.0 | ... | 1.78 | 56021.0 | 87.0 | 2.0 | 72.0 | 490.0 | 15.12 | 91.0 | 86.0 | 15.1 |
| Mexico | 30.0 | 12.8 | 9.0 | 4.2 | 37.0 | 28.83 | 61.0 | 23.4 | 13085.0 | 9056.0 | ... | 0.08 | 16193.0 | 77.0 | 1.0 | 66.0 | 417.0 | 13.89 | 63.0 | 67.0 | 14.4 |
| Netherlands | 30.0 | 4.9 | 6.1 | 0.0 | 73.0 | 0.45 | 74.0 | 0.9 | 27888.0 | 77961.0 | ... | 2.40 | 47590.0 | 90.0 | 2.0 | 76.0 | 519.0 | 15.44 | 75.0 | 92.0 | 18.7 |
| New Zealand | 11.0 | 2.2 | 10.3 | 0.2 | 74.0 | 13.87 | 73.0 | 1.2 | 23815.0 | 28290.0 | ... | 0.75 | 35609.0 | 94.0 | 2.4 | 90.0 | 509.0 | 14.87 | 77.0 | 89.0 | 18.1 |
| Norway | 16.0 | 3.3 | 8.1 | 0.3 | 82.0 | 2.82 | 75.0 | 0.6 | 33492.0 | 8797.0 | ... | 0.32 | 50282.0 | 94.0 | 2.0 | 76.0 | 496.0 | 15.56 | 78.0 | 94.0 | 17.9 |
| OECD - Total | 20.0 | 3.9 | 7.3 | 2.4 | 75.0 | 12.51 | 65.0 | 4.0 | 25908.0 | 67139.0 | ... | 2.79 | 36118.0 | 88.0 | 1.8 | 68.0 | 497.0 | 14.97 | 68.0 | 81.0 | 17.7 |
| Poland | 33.0 | 1.4 | 10.8 | 3.2 | 90.0 | 7.41 | 60.0 | 0.9 | 17852.0 | 10919.0 | ... | 3.77 | 22655.0 | 91.0 | 1.1 | 58.0 | 521.0 | 14.20 | 55.0 | 79.0 | 18.4 |
| Portugal | 18.0 | 5.7 | 6.5 | 0.9 | 38.0 | 9.62 | 61.0 | 1.1 | 20086.0 | 31245.0 | ... | 9.11 | 23688.0 | 86.0 | 1.6 | 46.0 | 488.0 | 14.95 | 58.0 | 86.0 | 17.6 |
| Russia | 15.0 | 3.8 | 2.5 | 15.1 | 94.0 | 0.16 | 69.0 | 12.8 | 19292.0 | 3412.0 | ... | 1.70 | 20885.0 | 90.0 | 0.9 | 37.0 | 481.0 | 14.97 | 65.0 | 56.0 | 16.0 |
| Slovak Republic | 13.0 | 3.0 | 6.6 | 0.6 | 92.0 | 7.02 | 60.0 | 1.2 | 17503.0 | 8663.0 | ... | 9.46 | 20307.0 | 90.0 | 1.1 | 66.0 | 472.0 | 14.99 | 59.0 | 81.0 | 16.3 |
| Slovenia | 26.0 | 3.9 | 10.3 | 0.5 | 85.0 | 5.63 | 63.0 | 0.4 | 19326.0 | 18465.0 | ... | 5.15 | 32037.0 | 90.0 | 1.5 | 65.0 | 499.0 | 14.62 | 52.0 | 88.0 | 18.4 |
| Spain | 24.0 | 4.2 | 7.3 | 0.1 | 55.0 | 5.89 | 56.0 | 0.6 | 22477.0 | 24774.0 | ... | 12.96 | 34824.0 | 95.0 | 1.9 | 72.0 | 490.0 | 16.06 | 69.0 | 71.0 | 17.6 |
| Sweden | 10.0 | 5.1 | 10.9 | 0.0 | 88.0 | 1.13 | 74.0 | 0.7 | 29185.0 | 60328.0 | ... | 1.37 | 40818.0 | 92.0 | 1.7 | 81.0 | 482.0 | 15.11 | 86.0 | 95.0 | 19.3 |
| Switzerland | 20.0 | 4.2 | 8.4 | 0.0 | 86.0 | 6.72 | 80.0 | 0.5 | 33491.0 | 108823.0 | ... | 1.46 | 54236.0 | 96.0 | 1.8 | 81.0 | 518.0 | 14.98 | 49.0 | 96.0 | 17.3 |
| Turkey | 35.0 | 5.0 | 5.5 | 12.7 | 34.0 | 40.86 | 50.0 | 1.2 | 14095.0 | 3251.0 | ... | 2.37 | 16919.0 | 86.0 | 1.1 | 68.0 | 462.0 | 13.42 | 88.0 | 62.0 | 16.4 |
| United Kingdom | 13.0 | 1.9 | 11.5 | 0.2 | 78.0 | 12.70 | 71.0 | 0.3 | 27029.0 | 60778.0 | ... | 2.77 | 41192.0 | 91.0 | 1.9 | 74.0 | 502.0 | 14.83 | 66.0 | 88.0 | 16.4 |
| United States | 18.0 | 1.5 | 8.3 | 0.1 | 89.0 | 11.30 | 67.0 | 5.2 | 41355.0 | 145769.0 | ... | 1.91 | 56340.0 | 90.0 | 2.4 | 88.0 | 492.0 | 14.27 | 68.0 | 85.0 | 17.2 |
37 rows × 24 columns
참고로 대한민국의 측정지표별 수치는 다음과 같다(위 이미지 중간의 파란띠로 구분된 영역 참조).
oecd_bli.loc['Korea']
Indicator Air pollution 30.00 Assault rate 2.10 Consultation on rule-making 10.40 Dwellings without basic facilities 4.20 Educational attainment 82.00 Employees working very long hours 18.72 Employment rate 64.00 Homicide rate 1.10 Household net adjusted disposable income 19510.00 Household net financial wealth 29091.00 Housing expenditure 16.00 Job security 3.20 Life expectancy 81.30 Life satisfaction 5.80 Long-term unemployment rate 0.01 Personal earnings 36354.00 Quality of support network 72.00 Rooms per person 1.40 Self-reported health 35.00 Student skills 542.00 Time devoted to leisure and personal care 14.63 Voter turnout 76.00 Water quality 78.00 Years in education 17.50 Name: Korea, dtype: float64
알파벳 순으로 첫 5개 국가의 삶의 만족도는 "Life satisfaction" 열(column)에서 확인할 수 있다.
oecd_bli["Life satisfaction"].head()
Country Australia 7.3 Austria 6.9 Belgium 6.9 Brazil 7.0 Canada 7.3 Name: Life satisfaction, dtype: float64
앞서 살펴본 대로 1인당 GDP 데이터는 OECD 회원국 이상의 국가 데이터가 포함되어 있다. OECD 회원국으로 제한해서 1인당 GDP와 삶의 만족도 사이의 관계를 파악하기 위해 여기서는 앞서 구한 두 개의 데이터프레임을 하나로 병합하는 방식을 이용한다. 더 나은 삶의 지수에서는 삶의 만족도를, GDP 데이터에서는 1인당 GDP 열만 이용하며 국가명을 기준으로 하면 자연스럽게 OECD 회원국에 해당하는 행만 추출된다.
참고: OECD 회원국들만 대상으로 하기 위해
left_index=True와 right_index=True로 설정한다.
oecd_country_stats = pd.merge(left=gdp_per_capita['GDP per capita'],
right=oecd_bli['Life satisfaction'],
left_index=True, right_index=True)
1인당 GDP와 삶의 만족도 사이의 선형 관계를 확인하기 위해 국가를 1인당 GDP 기준 오름차순으로 정렬시킨다.
oecd_country_stats.sort_values(by="GDP per capita", inplace=True)
oecd_country_stats
| GDP per capita | Life satisfaction | |
|---|---|---|
| Country | ||
| Brazil | 8669.998 | 7.0 |
| Mexico | 9009.280 | 6.7 |
| Russia | 9054.914 | 6.0 |
| Turkey | 9437.372 | 5.6 |
| Hungary | 12239.894 | 4.9 |
| Poland | 12495.334 | 5.8 |
| Chile | 13340.905 | 6.7 |
| Slovak Republic | 15991.736 | 6.1 |
| Czech Republic | 17256.918 | 6.5 |
| Estonia | 17288.083 | 5.6 |
| Greece | 18064.288 | 4.8 |
| Portugal | 19121.592 | 5.1 |
| Slovenia | 20732.482 | 5.7 |
| Spain | 25864.721 | 6.5 |
| Korea | 27195.197 | 5.8 |
| Italy | 29866.581 | 6.0 |
| Japan | 32485.545 | 5.9 |
| Israel | 35343.336 | 7.4 |
| New Zealand | 37044.891 | 7.3 |
| France | 37675.006 | 6.5 |
| Belgium | 40106.632 | 6.9 |
| Germany | 40996.511 | 7.0 |
| Finland | 41973.988 | 7.4 |
| Canada | 43331.961 | 7.3 |
| Netherlands | 43603.115 | 7.3 |
| Austria | 43724.031 | 6.9 |
| United Kingdom | 43770.688 | 6.8 |
| Sweden | 49866.266 | 7.2 |
| Iceland | 50854.583 | 7.5 |
| Australia | 50961.865 | 7.3 |
| Ireland | 51350.744 | 7.0 |
| Denmark | 52114.165 | 7.5 |
| United States | 55805.204 | 7.2 |
| Norway | 74822.106 | 7.4 |
| Switzerland | 80675.308 | 7.5 |
| Luxembourg | 101994.093 | 6.9 |
아래 코드는 이어서 다룰 선형회귀 모델의 적합도를 설명하기 위해 고의로 7개 국가의 데이터를 데이터셋에서 제외시킨다.
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
제외된 7개 국가의 1인당 GDP와 삶의 만족도 데이터는 다음과 같다.
missing_data = oecd_country_stats.iloc[remove_indices]
missing_data
| GDP per capita | Life satisfaction | |
|---|---|---|
| Country | ||
| Brazil | 8669.998 | 7.0 |
| Mexico | 9009.280 | 6.7 |
| Chile | 13340.905 | 6.7 |
| Czech Republic | 17256.918 | 6.5 |
| Norway | 74822.106 | 7.4 |
| Switzerland | 80675.308 | 7.5 |
| Luxembourg | 101994.093 | 6.9 |
sample_data = oecd_country_stats.iloc[keep_indices]
아래 코드는 앞서 언급된 7개 국가의 데이터를 제외한 국가들의 1인당 GDP와 삶의 만족도 사이의 관계를 산점도로 나타낸다. 선형관계를 잘 보여주는 5개 국가는 빨간색 점으로 표시한다.
# 7개 국가를 제외한 국가들의 데이터 산점도
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.axis([0, 60000, 0, 10])
# 언급된 5개 국가명 명기 좌표
position_text = {
"Hungary": (5000, 1),
"Korea": (18000, 1.7),
"France": (29000, 2.4),
"Australia": (40000, 3.0),
"United States": (52000, 3.8),
}
# 5개 국가는 좌표를 이용하여 빨강색 점으로 표기
for country, pos_text in position_text.items():
pos_data_x, pos_data_y = sample_data.loc[country]
# 5개 국가명 표기
country = "U.S." if country == "United States" else country
plt.annotate(country, xy=(pos_data_x, pos_data_y), xytext=pos_text,
arrowprops=dict(facecolor='black', width=0.5, shrink=0.1, headwidth=5))
# 5개 국가 산점도 그리기
plt.plot(pos_data_x, pos_data_y, "ro")
plt.xlabel("GDP per capita (USD)")
plt.show()

언급된 5개 국가의 1인당 GDP와 삶의 만족도를 데이터에서 직접 확인하면 다음과 같다.
sample_data.loc[list(position_text.keys())]
| GDP per capita | Life satisfaction | |
|---|---|---|
| Country | ||
| Hungary | 12239.894 | 4.9 |
| Korea | 27195.197 | 5.8 |
| France | 37675.006 | 6.5 |
| Australia | 50961.865 | 7.3 |
| United States | 55805.204 | 7.2 |
위 산점도에 따르면 1인당 GDP와 삶의 만족도가 어느 정도 선형 관계에 있는 것처럼 보인다. 그런데 어떤 선형관계가 가장 적절한가를 판단해야 한다. 예를 들어, 아래 도표에서 그려진 세 개의 직선 중에서는 파랑색 실선이 선형 관계를 가장 적절하게 나타낸다.
import numpy as np
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.xlabel("GDP per capita (USD)")
plt.axis([0, 60000, 0, 10])
# 직서 그리기
X=np.linspace(0, 60000, 1000)
# 빨강 직선
plt.plot(X, 2*X/100000, "r")
plt.text(40000, 2.7, r"$\theta_0 = 0$", fontsize=14, color="r")
plt.text(40000, 1.8, r"$\theta_1 = 2 \times 10^{-5}$", fontsize=14, color="r")
# 초록 직선
plt.plot(X, 8 - 5*X/100000, "g")
plt.text(5000, 9.1, r"$\theta_0 = 8$", fontsize=14, color="g")
plt.text(5000, 8.2, r"$\theta_1 = -5 \times 10^{-5}$", fontsize=14, color="g")
# 파랑 직선
plt.plot(X, 4 + 5*X/100000, "b")
plt.text(5000, 3.5, r"$\theta_0 = 4$", fontsize=14, color="b")
plt.text(5000, 2.6, r"$\theta_1 = 5 \times 10^{-5}$", fontsize=14, color="b")
plt.show()

위 그림에서처럼 y축의 값이 x축의 값에 선형적으로 의존하는 관계를 선형관계라 하며, 그런 선형관계를 함수로 구현하는 모델을 선형회귀 모델(linear regression model)이라 하며, 여기서는 선형회귀 모델이 1인당 GDP 하나를 인자로 사용하는 1차 함수 형식으로 구현된다. 그리고 1차 함수 모델은 직선의 절편(y축과 만나는 점)과 기울기 두 개의 값을 알면 바로 구현할 수 있다. 절편과 기울기처럼 모델 구현에 사용되는 값들을 모델 파라미터(model parameters)라 하며, 바로 이런 값들을 찾아내는 것이 머신러닝 모델훈련의 주요 과제이다.
정리하면 다음과 같다. '1인당 GDP'와 '삶의 만족도' 사이의 선형관계를 최대한 잘 반영하는 선형회귀 모델은 아래 식을 만족시키는 적절한 절편 $\theta_0$과 기울기 $\theta_1$에 의해 결정된다.
$$ \text{'삶의만족도'} = \theta_0 + \theta_1 \cdot \text{'1인당GDP'} $$사이킷런(scikit-learn) 라이브러리는 머신러닝에서 사용되는 다양한 모델의 기본적인 틀(basic models)들을 제공한다.
선형회귀의 경우 LinearRegression 클래스의 객체를 생성하여 훈련시키면
최적의 절편과 기울기를 계산해준다.
모델을 지정하고 훈련시키는 과정은 다음과 같다.
linear_model 모듈에 포함된 LinearRegression 클래스의 객체를 선언한다.
선언된 모델은 아직 어떤 훈련도 하지 않은 상태이다. from sklearn import linear_model
lin1 = linear_model.LinearRegression()
Xsample = np.c_[sample_data["GDP per capita"]]
ysample = np.c_[sample_data["Life satisfaction"]]
입력 데이터 훈련 세트에 포함된 모든 데이터 샘플을 항목으로 갖는다. 여기서는 각 샘플 데이터가 1인당 GDP에 해당하는 한 개의 값으로 이루어져 있기에 길이가 일인 1차원 어레이로 표현된다. 일반적으로는 하나의 훈련 샘플 데이터는 다양한 특성을 가진, 즉, 길이가 1보다 큰 1차원 어레이로 표현된다. 따라서 모든 입력 데이터를 아래와 같은 $m$x$n$ 모양의 2차원 어레이로 표현할 수 있다.
처음 5개의 입력 데이터는 다음과 같다.
Xsample[:5]
array([[ 9054.914],
[ 9437.372],
[12239.894],
[12495.334],
[15991.736]])
타깃값 또한 여러 개의 값으로 이루어져 있는 경우가 있기 때문에 각 훈련 데이터 샘플에 대한 타깃도 1차원 어레이로 표현된다. 따라서 타깃 데이터 세트 역시 2차원 어레이로 다뤄진다.
처음 5개의 입력 데이터 샘플에 대한 타깃은 다음과 같다.
ysample[:5]
array([[6. ],
[5.6],
[4.9],
[5.8],
[6.1]])
LinearRegression 모델의 경우 fit() 메서드를 지정된 훈련 세트와 함께 호출하면 됨.
fit() 메서의 반환값은 훈련된 LinearRegression 객체다. lin1.fit(Xsample, ysample)
LinearRegression()
훈련된 모델이 알아낸 최적 선형 모델의 절편과 기울기는 아래 두 속성에 저장된다.
intercept_[0]: 직선의 절편coef_[0]: 직선의 기울기t0, t1 = lin1.intercept_[0], lin1.coef_[0][0]
print(f"절편:\t {t0}")
print(f"기울기:\t {t1}")
절편: 4.853052800266436 기울기: 4.911544589158483e-05
구해진 기울기와 절편을 이용하여 산점도와 함께 직선을 그리면 다음과 같다.
# 산점도
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.xlabel("GDP per capita (USD)")
plt.axis([0, 60000, 0, 10])
# 직선 그리기
X=np.linspace(0, 60000, 1000)
plt.plot(X, t0 + t1*X, "b")
# 직선의 절편과 기울기 정보 명시
plt.text(5000, 3.1, r"$\theta_0 = 4.85$", fontsize=14, color="b")
plt.text(5000, 2.2, r"$\theta_1 = 4.91 \times 10^{-5}$", fontsize=14, color="b")
plt.show()

훈련된 모델을 이용하여 한 국가의 삶의 만족도를 1인당 GDP를 이용하여 예측한다. 예를 들어, OECD 비회원국인 키프러스(Cyprus)의 1인당 GDP가 다음과 같이 알려져 있을 때 키프러스 국민의 삶의 만족도를 예측한다.
cyprus_gdp_per_capita = gdp_per_capita.loc["Cyprus"]["GDP per capita"]
cyprus_gdp_per_capita
22587.49
훈련된 모델의 predict() 메서드를 이용하면 키프러스 국민의 삶의 만족도는 5.96 정도로 예측된다.
cyprus_predicted_life_satisfaction = lin1.predict([[cyprus_gdp_per_capita]])[0, 0]
cyprus_predicted_life_satisfaction
5.96244744318815
아래 도표에서 확인할 수 있듯이 예측값은 정확하게 앞서 확인한 최적의 직선 위에 위치한다.
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3), s=1)
plt.xlabel("GDP per capita (USD)")
# 예측된 최적의 직선
X=np.linspace(0, 60000, 1000)
plt.plot(X, t0 + t1*X, "b")
plt.axis([0, 60000, 0, 10])
plt.text(5000, 7.5, r"$\theta_0 = 4.85$", fontsize=14, color="b")
plt.text(5000, 6.6, r"$\theta_1 = 4.91 \times 10^{-5}$", fontsize=14, color="b")
# 키프러스에 대한 삶의 만족도 예측값
# 빨간 점선 그리기
plt.plot([cyprus_gdp_per_capita, cyprus_gdp_per_capita], [0, cyprus_predicted_life_satisfaction], "r--")
plt.text(25000, 5.0, r"Prediction = 5.96", fontsize=14, color="b")
# 예측 지점 좌표 찍기(빨강생)
plt.plot(cyprus_gdp_per_capita, cyprus_predicted_life_satisfaction, "ro")
plt.show()

머신러닝 알고리즘을 훈련시키다보면 다양한 도전 과제에 부딛친다. 여기서는 대표성 없는 데이터가 훈련 세트에 포함될 때 발생할 수 있는 어려움을 앞서 살펴본 선형회귀 모델을 이용하여 설명한다.
앞서 7개 국가의 데이터를 훈련에서 제외시킨 후에 선형회귀 모델을 훈련시켰다. 이제 7개 국가를 포함해서 훈련시켜 보자. 제외된 7개 국가의 데이터는 다음과 같다.
missing_data
| GDP per capita | Life satisfaction | |
|---|---|---|
| Country | ||
| Brazil | 8669.998 | 7.0 |
| Mexico | 9009.280 | 6.7 |
| Chile | 13340.905 | 6.7 |
| Czech Republic | 17256.918 | 6.5 |
| Norway | 74822.106 | 7.4 |
| Switzerland | 80675.308 | 7.5 |
| Luxembourg | 101994.093 | 6.9 |
아래 좌표는 7개 국가명을 아래 도표에서 표기할 때 사용할 좌표이다.
position_text2 = {
"Brazil": (1000, 9.0),
"Mexico": (11000, 9.0),
"Chile": (25000, 9.0),
"Czech Republic": (35000, 9.0),
"Norway": (60000, 3),
"Switzerland": (72000, 3.0),
"Luxembourg": (90000, 3.0),
}
7개 국가를 포함한 전체 훈련 데이터셋을 이용하여 훈련한 결과를 7개 국가를 제외했을 때의 훈련 결과와 비교한다.
결론: 선형회귀 모델은 1인당 GDP와 삶의 만족도 사이의 관계를 모델링 하기에 부적합하다.
# 7개 국가를 제외한 국가들의 산점도 (파랑색 점)
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(8,3))
plt.axis([0, 110000, 0, 10])
# 7개 국가 산점도(빨강 점)
for country, pos_text in position_text2.items():
pos_data_x, pos_data_y = missing_data.loc[country]
# 7개 국가명 표기
plt.annotate(country, xy=(pos_data_x, pos_data_y), xytext=pos_text,
arrowprops=dict(facecolor='black', width=0.5, shrink=0.1, headwidth=5))
plt.plot(pos_data_x, pos_data_y, "rs")
# 7개 국가 제외 예측 선형 모델 그래프 (파랑 점선)
X=np.linspace(0, 110000, 1000)
plt.plot(X, t0 + t1*X, "b:")
# 7개 국가 포함 선형회귀 모델 훈련 및 예측
lin_reg_full = linear_model.LinearRegression()
Xfull = np.c_[oecd_country_stats["GDP per capita"]]
yfull = np.c_[oecd_country_stats["Life satisfaction"]]
lin_reg_full.fit(Xfull, yfull)
# 7개 국가 포함 예측 선형 모델 그래프(검정 실선)
t0full, t1full = lin_reg_full.intercept_[0], lin_reg_full.coef_[0][0]
X = np.linspace(0, 110000, 1000)
plt.plot(X, t0full + t1full * X, "k")
plt.xlabel("GDP per capita (USD)")
plt.show()

OECD 삶의 만족도 데이터와 IMF 1인당 GDP 데이터를 2020년 기준으로 업데이트하여 앞서 살펴본 과정과 동일한 과정을 수행하라. 2020년 기준 데이터는 아래 정보를 사용한다.
기본 다운로드 경로
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/codingalzi/handson-ml2/master/"
BLI 데이터 파일명: oecd_bli_2020.csv
1인당 GDP 데이터: gdp_per_capita_2020.xlsx
주의사항:
1인당 GDP 데이터는 엑셀 파일로 주어졌다. 팬다스의 read_csv() 대신에 read_excel() 파일을 사용한다.
rename() 메서드를 활용할 때 '2020' 문자열 대신에 2020 정수를 사용해야 한다.제외되는 7개 국가 정보는 다음과 같다.
제외 국가 인덱스
remove_indices = [1, 2, 4, 6, 37, 38, 39]
keep_indices = list(set(range(40)) - set(remove_indices))
제외 국가: Columbia(콜롬비아), Brazil(브라질), Mexico(멕시코), Chille(칠레), Ireland(아일랜드), Switzerland(스위스, Luxembourg(룩셈부르크)
언급된 5개 국가명 명기 좌표
position_text = {
"Hungary": (8000, 1),
"Korea": (26000, 1.7),
"France": (34000, 2.4),
"Australia": (44000, 3.0),
"United States": (60000, 3.8),
}