numpy 모듈과 시각화 도구 모듈인 matplotlib.pyplot에 대한 기본 설정을 지정한다.
# 넘파이
import numpy as np
# 램덤 시드
np.random.seed(12345)
# 어레이 사용되는 부동소수점들의 정확도 지정
np.set_printoptions(precision=4, suppress=True)
# 파이플롯
import matplotlib.pyplot as plt
# 도표 크기 지정
plt.rc('figure', figsize=(10, 6))
ndarray)¶리스트의 인덱스, 인덱싱, 슬라이싱 개념을 넘파이 어레이에 확장시킨다. 리스트의 경우보다 보다 다양한 기능을 제공하며 데이터 분석에서 매우 중요한 역할을 수행한다.
1차원 어레이의 경우 리스트의 경우와 거의 동일하게 작동한다.
arr = np.arange(10)
arr
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5]
5
arr[5:8]
array([5, 6, 7])
arr[5:8] = 12
arr
array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
주의사항: 위 기능은 리스트에서는 제공되지 않는다.
aList = list(arr)
aList
[0, 1, 2, 3, 4, 12, 12, 12, 8, 9]
aList[5:8] = 12
aList
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-14-f584977ee941> in <module> ----> 1 aList[5:8] = 12 2 aList TypeError: can only assign an iterable
아래와 같이 리스트를 값으로 지정하면 작동한다.
aList[5:8] = [12, 12, 12]
aList
[0, 1, 2, 3, 4, 12, 12, 12, 8, 9]
넘파이 어레이에 대해 슬라이싱을 실행하면 지정된 구간에 해당하는 어레이를 새로 생성하는 게 아니라 지정된 구간의 정보를 이용만 한다. 이렇게 작동하는 기능이 뷰(view)이다. 즉, 어레이를 새로 생성하지 않고 기존 어레이를 적절하게 활용한다.
참고: 넘파이 어레이와 관련된 많은 기능이 뷰 기능을 이용한다. 아래에서 소개하는 전치 어레이를 구하는 과정도 뷰를 이용한다.
arr_slice = arr[5:8]
arr_slice
array([12, 12, 12])
arr_slice[1] = 3450
arr
array([ 0, 1, 2, 3, 4, 12, 3450, 12, 8, 9])
어레이 전체 항목을 특정 값으로 한꺼번에 바꾸려면 [:]로 슬라이싱 한다.
arr_slice[:] = 64
arr_slice
array([64, 64, 64])
arr
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
copy() 메서드¶원본을 그대로 유지하고자 한다면 어레이를 새로 생성해서 사용해야 하며, 이를 위해 copy() 메서드를 활용한다.
arr_slice2 = arr[5:8].copy()
arr_slice2
array([64, 64, 64])
arr_slice2를 변경해도 arr은 영향받지 않는다.
arr_slice2[1] = 12
arr_slice2
array([64, 12, 64])
arr
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
2차원 이상의 다차원 어레이는 보다 다양한 인덱싱, 슬라이싱 기능을 제공한다.
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr2d
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
리스트의 인덱싱을 그대로 사용할 수 있다.
arr2d[0]
array([1, 2, 3])
arr2d[0][2]
3
위 인덱싱을 2차원 어레이 인덱싱 방식으로 아래와 같이 쉽게 할 수 있다.
arr2d[0, 2]
3
arr3d는 (2, 2, 3) 모양의 3차원 어레이다.
arr3d = np.array([[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]]])
arr3d
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d.shape
(2, 2, 3)
모양이 (2, 2, 3)인 3차원 어레이의 0번 인덱스 항목은 (2, 3) 크기의 2차원 어레이다.
arr3d[0]
array([[1, 2, 3],
[4, 5, 6]])
0번 인덱스 항목인 2차원 어레이의 항목을 일정한 값으로 바꾸기 위해 인덱싱을 활용할 수 있다.
# 기존 항목 기억해 두기
old_values = arr3d[0].copy()
arr3d[0] = 42
arr3d
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
# arr3d를 계속 사용하기 위해 원래 값으로 되돌린다.
arr3d[0] = old_values
arr3d
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
모양이 (2, 2, 3)인 3차원 행렬의 1번 행, 0번 열의 항목은 길이가 3인 1차원 어레이다.
arr3d[1, 0]
array([7, 8, 9])
실제로 아래 처럼 1번행과 1번 행의 0번 열의 값을 확인하면 동일한 값이 나온다.
x = arr3d[1]
x
array([[ 7, 8, 9],
[10, 11, 12]])
x[0]
array([7, 8, 9])
모양이 (2, 2, 3)인 3차원 행렬의 1번 행, 0번 열, 2번 인덱스의 항목은 길이가 정수 9이다.
arr3d[1, 0, 2]
9
실제로 아래 처럼 1번행과 1번 행, 0번 열, 2번 인덱스의 값을 확인하면 동일한 값이 나온다.
arr3d[1][0][2]
9
arr2d
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
리스트 슬라이싱 방식을 동일하게 적용할 수 있다.
arr2d[:1]
array([[1, 2, 3]])
arr2d[:2]
array([[1, 2, 3],
[4, 5, 6]])
arr2d[:3]
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
행과 열을 함께 슬라이싱하려면 행과, 열에 대한 슬라이싱을 동시에 지정한다.
arr2d[:2, 1:]
array([[2, 3],
[5, 6]])

인덱싱과 슬라이싱이 행과 열 각각에 대해 독립적으로 사용될 수 있다.
arr2d[1, :2]
array([4, 5])

주의사항: 인덱싱을 사용하는 만큼 결과 어레이의 차원이 기존 어레이의 차원보다 1씩 줄어든다.
arr2d[1, :2].shape
(2,)
동일한 항목을 사용하지만 인덱싱을 사용할 때와 아닐 때의 결과는 다른 모양의 어레이가 된다.
arr2d[1:2, :2]
array([[4, 5]])
모양은 사용되는 슬라이싱의 구간에 의존한다.
따라서 결과는 (1, 2) 모양의 어레이다.
arr2d[1:2, :2].shape
(1, 2)
arr2d[:, :2]
array([[1, 2],
[4, 5],
[7, 8]])

arr2d[:, :1]
array([[1],
[4],
[7]])
arr2d[:2, 1:] = 0
arr2d
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])
아래 그림 모양의 2차원 어레이를 생성한다.
참고: 아래에서는 길이가 36인 1차원 어레이를 (6, 6) 모양의 2차원 어레이로 항목을 재배열하기 위해
reshape() 함수를 사용한다.
reshape() 함수에 대한 자세한 설명은 뒤에서 이루어진다.
arr = np.arange(36).reshape((6, 6))
arr
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
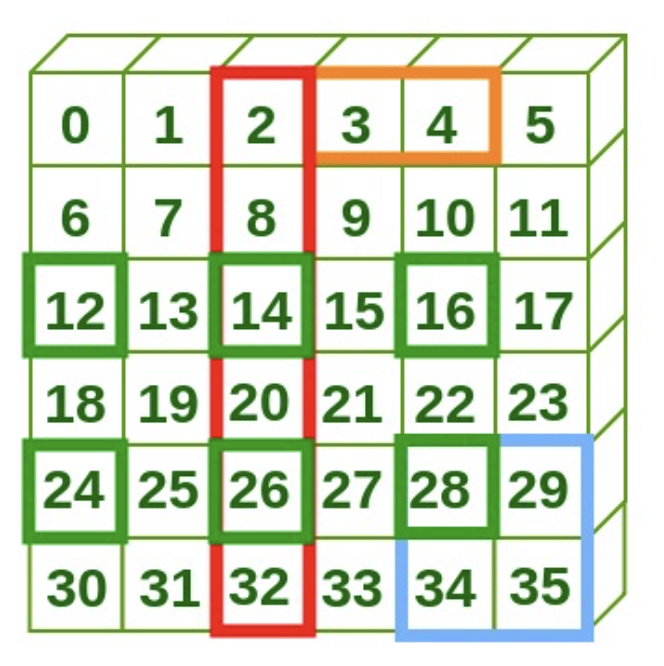
<그림 출처: geeksforgeeks>
위 그림에 색깔별로 표시된 어레이를 슬라이싱을 이용하여 구하라.
arr[0, 3:5]
array([3, 4])
arr[:, 2:3]
array([[ 2],
[ 8],
[14],
[20],
[26],
[32]])
만약에 열에 대해 슬라이싱 대신 인덱싱을 사용하면 1차원 어레이를 얻는다.
arr[:, 2]
array([ 2, 8, 14, 20, 26, 32])
리스트 슬라이싱의 경우처럼 스텝도 사용할 수 있다.
arr[2:5:2, 0::2]
array([[12, 14, 16],
[24, 26, 28]])
기본적으로 2차원 어레이 슬라이싱 기능과 동일하게 작동한다. 여기서는 칼라 이미지 데이터를 3차원 어레이로, 흑백 이미지를 2차원 어레이로 다루면서 인덱싱과 슬라이싱을 이용하여 이미지를 조작하는 간단한 방법을 설명한다.
먼저 너구리 얼굴 이미지를 가져온다. 아래 코드는 scipy 패키지에서 기본으로 제공하는 너구리 얼굴 사진을 3차원 어레이로 가져온다.
주의사항: 아래와 같은 코드가 있다는 정도 기억해 두기 바란다.
import scipy.misc
face = scipy.misc.face()
face는 너구리 얼굴 이미지를 3차원 어레이로 불러온다.
imshow() 함수는 3차원 이미지 어레이를 이미지로 보여주는 함수이다.show() 함수는 지정된 여러 개의 이미지를 동시에 화면에 띄우는 기능을 갖는 함수이다.plt.imshow(face)
plt.show()

face는 아래 모양의 3차원 어레이를 가리킨다.
face.shape
(768, 1024, 3)
위 이미지에서 세로, 가로 축에 보여지는 숫자가 픽셀 수를 보여주며 정확한 픽셀 수는 다음과 같다.
768x1024 개의 픽셀에 포함된 길이 3인 어레이는
R(빨강), G(초록), B(파랑) 색상에 대한 정보를 각각 담는다.
또한 색상 정보는 각각 0부터 255 사이의 값을 사용한다.
어레이에 사용된 값들의 정확한 자료형은 uint8, 즉, 8바이트로 표현된 양의 정수 자료형이다.
face.dtype
dtype('uint8')
face.min()
0
face.max()
255
여기서는 픽셀 정보를 0과 1사이의 부동소수점으로 변경해서 사용한다. 이유는 여러 이미지 변환을 시도할 때 0과 1사이의 부동소수점의 값들이 나올 때 정확하게 기능하기 때문이다.
RGB 정보의 최댓값이 255이기에 모든 항목을 255로 나누어 0과 1사이의 값으로 정규화시킨다.
face = face/255
흑백 이미지는 보통 하나의 RGB 정보만 가져오는 것으로 구할 수 있다. 예를 들어, 빨강색 정보만 가져오려면 아래처럼 3차원 인덱싱을 실행한다. 아래 코드는 이미지의 행과 열은 그대로 두고 RGB 정보에서 R(빨강)에 대한 정보만 인덱싱으로 가져온다.
face_gray_red = face[:,:,0]
흑백사진으로 보여주려면 imshow() 함수의 cmap 키워드 인자를 gray style 을 사용하도록 지정해야 한다.
참고: cmap 키워드: 색상 지도(color map)을 가리키는 매개변수이며,
'gray'를 사용하여 흑백사진으로 출력한다.
색상 지도에 대한 자세한 안내는
Matplotlib: Choosing Colormaps를
참조한다.
plt.imshow(face_gray_red, cmap='gray')
plt.show()

참고: 진정한 흑백사진으로 변경하려면 RGB 정보를 전부 이용하여 하나의 값을 계산해야 한다. 흑백 이미지의 명암을 구현하는 벡터 내적 수식은 다음과 같다.
$$ [R, G, B]\cdot[0.2989, 0.5870, 0.1140] = 0.2989 \cdot R + 0.5870 \cdot G + 0.1140 \cdot B $$벡터 내적 연산은 어레이의 내적 연산을 통해 쉽게 계산할 수 있다.
dot() 함수: 벡터 내적 계산face_gray = np.dot(face, [0.2989, 0.5870,0.114])
결과는 2차원 어레이며, 흑백 이미지의 정보를 모두 갖고 있다.
face_gray.shape
(768, 1024)
보다 선명한 명암을 보여주는 이미지가 결과로 나온다.
plt.imshow(face_gray, cmap=plt.get_cmap('gray'))
plt.show()

이미지 크기 조정은 픽셀 수를 조절하는 방식으로 이루어진다. 가장 단순한 방식은 행과 열에서 각각 2개씩 건너뛰며 픽셀을 선택하는 것이다. 일부 데이터가 상실되지만 작은 이미지에는 눈으로 보일 정도로 영향을 받지는 않는다.
아래 코드는 행과 열에 대해 모두 스텝 2를 지정하고 슬라이싱을 적용한다.
즉, 2x2 모양을 이루는 네 개의 픽셀 중에 상단 왼편에 있는 픽셀만 선택한다.

face_half_simple = face[::2, ::2,:]
행과 열의 픽셀 수가 모두 절반으로 줄었다.
face_half_simple.shape
(384, 512, 3)
이미지를 확인하면 살짝 흐려진 느낌을 받는다.
plt.imshow(face_half_simple)
plt.show()

가장 일반적으로 사용되는 이미지 변경 방법은 보간법(interpolation)이다. 이미지 크기 변경에 사용되는 다양한 보간법 기법이 있지만 여기서는 두 픽셀 사이의 평균값을 취하는 방식을 이용한다. 보간법의 다양한 방식에 대한 설명은 OpenCV 보간법을 참조한다.
아래 코드는 짝수 인덱스의 값과 홀수 인덱스의 값의 평균을 취하는 방식으로 보간법을 활용한다.

face_half_interpolation = (face[::2, ::2, :] + face[1::2, 1::2, :])/2
face_half_interpolation.shape
(384, 512, 3)
plt.imshow(face_half_interpolation)
plt.show()

4분의 1 크기의 두 이미지 데이터가 조금 다르기는 하지만 이미지 상으로 차이점을 발견하기 어렵다.
face_half_interpolation[:2]
array([[[0.4529, 0.4216, 0.4941],
[0.5686, 0.5353, 0.6176],
[0.5941, 0.5608, 0.6471],
...,
[0.4784, 0.5118, 0.3078],
[0.4588, 0.4863, 0.2784],
[0.5431, 0.5667, 0.3549]],
[[0.3333, 0.3118, 0.3804],
[0.4608, 0.4373, 0.5118],
[0.4961, 0.4706, 0.5549],
...,
[0.4216, 0.4667, 0.2588],
[0.4314, 0.4725, 0.2588],
[0.5059, 0.5451, 0.3275]]])
face_half_simple[:2]
array([[[0.4745, 0.4392, 0.5137],
[0.6 , 0.5647, 0.6471],
[0.6078, 0.5725, 0.6549],
...,
[0.5294, 0.5608, 0.3608],
[0.4549, 0.4824, 0.2784],
[0.5137, 0.5333, 0.3216]],
[[0.2863, 0.2588, 0.3294],
[0.451 , 0.4235, 0.4941],
[0.498 , 0.4667, 0.549 ],
...,
[0.4235, 0.4627, 0.2588],
[0.4078, 0.4471, 0.2392],
[0.5216, 0.5569, 0.3412]]])
참고: 4차원 이상의 어레이에 대해서는 기본적으로 2, 3차원 어레이 대상과 동일하게 작동한다. 하지만 시각화가 기본적으로 불가능하고, 사람이 직접 4차원 이상의 슬라이싱을 조작하는 것도 매우 어렵다. 따라서 2, 3차원 어레이 슬라이싱의 기본 아이디어만 이해했다면 그것으로 충분하다는 점만 언급한다.
부울 인덱싱은 앞서 설명한 인덱싱/슬라이싱 기법이 처리하지 못하는 인덱싱/슬라이싱을 지원한다.
1차원 부울 어레이를 이용한 인덱싱을 설명하기 위해 아래 두 개의 어레이를 이용한다.
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
names
array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
randn() 함수는 표준 정규 분포를 이용하여 임의의 부동소수점으로 이루어진 어레이 생성.data = np.random.randn(7, 4)
data
array([[-0.2047, 0.4789, -0.5194, -0.5557],
[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[ 0.275 , 0.2289, 1.3529, 0.8864],
[-2.0016, -0.3718, 1.669 , -0.4386],
[-0.5397, 0.477 , 3.2489, -1.0212],
[-0.5771, 0.1241, 0.3026, 0.5238]])
names에 포함된 이름이 Bob인지 여부를 확인하면 부울 값으로 이루어진 길이가 7인 어레이가 생성된다.
즉, 항목별 비교 연산이 이루어진다.
name_Bob = names == 'Bob'
name_Bob
array([ True, False, False, True, False, False, False])
이제부터 name_Bob이 가리키는 길이가 7인 1차원 어레이에서
True가 위치한 인덱스를 이용하여 data가 가리키는 2차원 어레이를 대상으로 부울 인덱싱이
작동하는 방법을 설명한다.
먼저, data 의 행의 길이가 7임에 주목하라.
이제 name_Bob에서 True가 위치한 인덱스에 해당하는 항목만 data에서 슬라이싱하려면
다음과 같이 부울 인덱싱을 사용한다.
결과는 data에서 0번행과 3번행만 가져온다.
이유는 name_Bob에서 0번, 3번 인덱스의 항목만 True이기 때문이다.
data[name_Bob]
array([[-0.2047, 0.4789, -0.5194, -0.5557],
[ 0.275 , 0.2289, 1.3529, 0.8864]])
이처럼 1차원 부울 어레이를 이용한 인덱싱은 하나의 축에 대해 슬라이싱을 적용하는 것과 동일하게 작동한다. 다만, 부울 어레이의 길이가 사용되는 축의 길이와 동일해야 한다. 따라서 부울 인덱싱과 일반 인덱싱, 슬라이싱을 혼합할 수 있다.
data[name_Bob, 2:]
array([[-0.5194, -0.5557],
[ 1.3529, 0.8864]])
data[name_Bob, 3]
array([-0.5557, 0.8864])
부울 연산자(~, &, |)를 사용하여 얻어진 부울 어레이 표현식을
부울 인덱싱에 직접 활용할 수 있다.
예를 들어, 이름이 Bob 아닌 이름이 위치한 인덱스에 해당하는 행만 가져오려면
== 대신에 ~=를 이용하거나 ==와 ~ 연산자를 함께 이용한다.
data[names != 'Bob']
array([[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[-2.0016, -0.3718, 1.669 , -0.4386],
[-0.5397, 0.477 , 3.2489, -1.0212],
[-0.5771, 0.1241, 0.3026, 0.5238]])
data[~name_Bob]
array([[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[-2.0016, -0.3718, 1.669 , -0.4386],
[-0.5397, 0.477 , 3.2489, -1.0212],
[-0.5771, 0.1241, 0.3026, 0.5238]])
다음은 Bob 또는 Will 이 위치한 인덱스에 해당하는 행만 가져온다.
mask = (names == 'Bob') | (names == 'Will')
mask
array([ True, False, True, True, True, False, False])
data[mask]
array([[-0.2047, 0.4789, -0.5194, -0.5557],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[ 0.275 , 0.2289, 1.3529, 0.8864],
[-2.0016, -0.3718, 1.669 , -0.4386]])
참고: 부울 인덱싱에 사용되는 부울 어레이를 마스크(mask)라고 한다. 따라서 mask 단어가 종종 부울 인덱싱에 사용되는 마스크 변수로 사용된다.
1차원 부울 배열을 이용하여 전체 행 또는 전체 열을 특정 값으로 변경할 수 있다.
아래 코드는 names에서 Joe가 사용되지 않은 항목의 인덱스에 해당하는 행에 포함된 항목을 모두 7로 변경한다.
mask = names != 'Joe'
mask
array([ True, False, True, True, True, False, False])
data[mask] = 7
data
array([[ 7. , 7. , 7. , 7. ],
[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[-0.5397, 0.477 , 3.2489, -1.0212],
[-0.5771, 0.1241, 0.3026, 0.5238]])
부울 인덱싱은 뷰를 이용하지 않고 항상 새로운 어레이를 생성한다.
data2 = data[names == 'Bob']
data2
array([[7., 7., 7., 7.],
[7., 7., 7., 7.]])
data2의 0번 행을 모두 -1로 변경해도 data는 변하지 않는다.
data2[0] = -1
data2
array([[-1., -1., -1., -1.],
[ 7., 7., 7., 7.]])
하지만 data는 변경되지 않았다.
data
array([[ 7. , 7. , 7. , 7. ],
[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[-0.5397, 0.477 , 3.2489, -1.0212],
[-0.5771, 0.1241, 0.3026, 0.5238]])
아래 표현식은 data와 동일한 모양의 부울 어레이를 생성한다.
이유는 부등호 연산이 항목별로 작동하기 때문이다.
mask = data < 0
mask
array([[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[ True, False, False, True],
[ True, False, False, False]])
이제 mask를 이용하여 모든 음수 항목을 0으로 변경할 수 있다.
방식은 리스트의 인덱싱을 이용하여 항목을 변경하는 방식과 매우 유사하다.
data[mask] = 0
data
array([[7. , 7. , 7. , 7. ],
[1.9658, 1.3934, 0.0929, 0.2817],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[0. , 0.477 , 3.2489, 0. ],
[0. , 0.1241, 0.3026, 0.5238]])