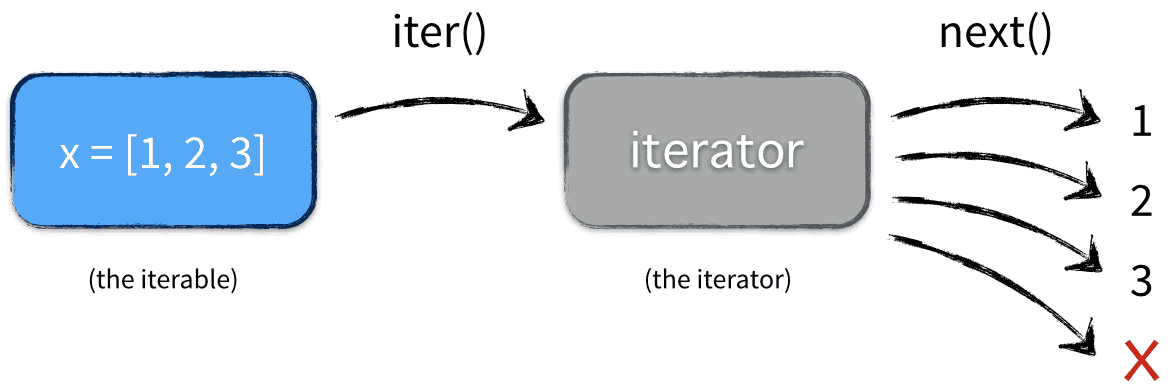
이터러블(iterables) 객체는 쉽게 말해서 for 반복문에서 값들의 순환 대상으로 사용될 수 있는 객체이다.
지금까지 살펴본 문자열, 리스트, 튜플, 사전, 집합을 포함해서, 아래에서
소개할 파일 객체 등도 이터러블 자료형이다.
단, 열려 있는 파일만 대상으로 한다.
이터러블 객체의 특징은 __iter__() 메서드를 지원하는가에 따라 결정된다.
예를 들어, 아래와 같이 리스트를 이용하여 for 반복문을 실행하면 리스트의 __iter__()
메서드가 호출된다.
for item in [1, 2, 3]:
print(item)
위 반복문을 실행하면 리스트의 __iter__() 메서드는 이터레이터(iterator) 객체를 반환한다.
그리고 이터레이터의 __next__() 메서드는 해당 리스트의 항목을 하나씩 item 변수에 전달하는
역할을 수행한다.
두 메서드가 사용되는 과정을 아래 그림이 잘 묘사한다.
사전을 for 반복문에 사용하면 키(key)를 대상으로 순회한다.
some_dict = {'a': 1, 'b': 2, 'c': 3}
for key in some_dict:
print(key)
a b c
사전 객체를 iter() 함수의 인자로 사용하면 생성되는 이터레이터를 확인할 수 있다.
단, 이터레이터는 항목을 바로 보여주지 않는다.
참고: iter() 함수를 호출하면 인자가 갖는 __iter__() 메서드를 호출한다.
따라서 iter() 함수에 이터러블 객체가 아닌 값을 인자로 사용하면 오류가 발생한다.
dict_iterator = iter(some_dict)
dict_iterator
<dict_keyiterator at 0x7fe1a8e4b2c0>
이터레이터의 항목은 리스트로 형변화면 쉽게 확인할 수 있으며, 키(key)로 구성되어 있음을 확인할 수 있다.
list(dict_iterator)
['a', 'b', 'c']
제너레이터(generator)는 특별한 이터레이터이다.
제너레이터는 __iter()__와 __next__() 메서드를 구체적으로 구현할 필요없이
매우 간단하게 이터레이터를 정의하는 도구이다.
이터레이터는 두 가지 방식으로 정의된다.
아래 코드는 1부터 10까지의 정수의 제곱을 생성하는 제너레이터를 정의한다.
함수 정의와 유사한 방식을 사용한다.
차이점은 return 예약어 대신 yield 예약어를 사용하여,
생성(yield)해야하는 값들을 지정한다.
def squares(n=10):
for i in range(1, n + 1):
yield i ** 2
제너레이터는 지정된 값들을 바로 생성하지 않으며 생성할 준비만 해 놓는다.
gen = squares()
gen
<generator object squares at 0x7fe1a8e38a50>
for 반복문에 사용하면 그제서야 필요한 항목을 하나씩 생성한다.
for x in gen:
print(x, end=' ')
1 4 9 16 25 36 49 64 81 100
주의사항: 제너레이터는 한 번만 사용될 수 있다.
앞서 언급한 __next()__ 메서드가 모든 항목을 순회하면 더 이상
가리키는 값이 없게 된다.
따라서 아래처럼 다시 한 번 for 반복문을 사용하면 아무 것도 출력하지 않는다.
for x in gen:
print(x, end=' ')
동일한 제너레이터를 다시 사용하려면 먼저 제너레이터러를 다시 생성해야 한다.
gen = squares()
for x in gen:
print(x, end=' ')
1 4 9 16 25 36 49 64 81 100
조건제시법 표현식을 소괄호로 감싸면 제너레이터가 된다. 예를 들어, 아래 코드는 0부터 99까지의 수의 제곱을 차례대로 생성하는 제너레이터이다.
주의사항: 튜플 자료형이 아니다.
gen = (x ** 2 for x in range(100))
gen
<generator object <genexpr> at 0x7fe1a8e38dd0>
위 제너레이터가 생성하는 처음 다서 개의 제곱수는 다음과 같다.
주의: 리스트로 형변환을 해야 항목을 보여준다.
list(gen)[:5]
[0, 1, 4, 9, 16]
gen이 가리키는 값을 함수형으로 정의하면 다음과 같다.
def _make_gen():
for x in range(100):
yield x ** 2
gen = _make_gen()
list(gen)[:5]
[0, 1, 4, 9, 16]
조건제시법 표현식 방식은 리스트를 인자로 받는 모든 함수와 함께 사용될 수 있다. 예를 들어, 0부터 99까지의 수의 제곱의 합은 아래와 같다.
sum(x ** 2 for x in range(100))
328350
0부터 4까지의 수를 키(key)로, 제곱을 값(value)으로 갖는 사전은 다음과 같이 정의할 수 있다.
dict((i, i ** 2) for i in range(5))
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
파이선의 표준 라이브러리인 itertools 모듈은 다양한 제너레이터를 제공한다.
아래에 가장 유용한 제너레이터를 언급하였으며, 우선은 그런 게 있다는 것만 기억해 두면 좋다.
필요한 경우
공식문서를 참고하여 활용하면 된다.
| 함수 | 기능 |
|---|---|
| combinations(iterable, k) | iterable에서 순서를 고려하지 않고 길이가 k인 모든 가능한 조합 생성 |
| permutations(iterable, k) | iterable에서 순서를 고려하여 길이가 k인 모든 가능한 조합 생성 |
| groupby(iterable, key=None]) | iterable에서 각각의 고유한 키에 따른 그룹 생성 |
| product(*iterables, repeat=1) | iterables를 이용한 데카르트 곱(Cartesian product) 계산 |
오류 없는 완벽한 프로그램은 현실적으로 불가능하며, 프로그램을 구현하고 실행하면 거의 항상 오류가 발생한다. 프로그래밍 단계에서부터 발생할 수 있는 오류(error)의 종류와 원인, 그리고 오류가 발생할 경우에 시스템이 다운되지 않도록 대비해야 한다.
발생할 수 있는 오류에 미리 대비하는 것을 예외 처리(exception handling)라 한다. 여기서는 함수에 적절하지 않은 인자가 사용될 때 발생하는 오류를 이용하여 예외 처리의 사용법을 간단하게 살펴본다.
파이썬 함수는 인자의 자료형을 명시하지 않기 때문에
자료형이 다른 인자를 사용하는 실수를 범하기 쉽다.
그리고 적절하지 않은 인자를 사용할 경우 ValueError가 발생한다.
예를 들어, float() 함수는 부동소수점 형식의 문자열만 부동소수점으로 변환한다.
float('1.2345')
1.2345
float('1.23e-45')
1.23e-45
float('12345')
12345.0
다른 형식의 문자열이 인자로 들어오면 ValueError를 발생시킨다.
float('123f2')
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-17-81f983ae5301> in <module> ----> 1 float('123f2') ValueError: could not convert string to float: '123f2'
float()를 사용할 때 오류가 발생하여 바로 실행이 멈추게 하는 것을 방지하려면
예외 처리를 해주면 된다.
예외 처리의 기본 형식은 다음과 같다.
try:
code1
except:
code2
code1 이 실행된다.
실행 과정 중에 오류가 발생하지 않으면 code2 부분은 건너 뛴다.code1 실행중에 오류가 발생하면 code2 를 실행한다.x = '123f2'
try:
print(float(x))
except:
print('부동소수점 모양의 문자열이 아닙니다.')
부동소수점 모양의 문자열이 아닙니다.
아래 함수는 부동소수점 모양이 아닌 문자열이 인자로 사용되면 해당 문자열을 그대로 반환하도록 한다.
def attempt_float(x):
try:
return float(x)
except:
return x
attempt_float('1.2345')
1.2345
attempt_float('부동소수점 모양의 문자열이 아닙니다.')
'부동소수점 모양의 문자열이 아닙니다.'
예외 처리 과정에서 특정 오류만 처리하도록 지정할 수 있다.
예를 들어, ValueError 만 처리하려면 다음과 같이 지정한다.
try:
code1
except ValueError:
code2
x = '123f2'
try:
print(float(x))
except ValueError:
print('부동소수점 모양의 문자열이 아닙니다.')
부동소수점 모양의 문자열이 아닙니다.
그런데 오류 종류를 명시하면 다른 종류의 오류는 처리하지 못한다.
x = (1, 2)
try:
print(float(x))
except ValueError:
print('부동소수점 모양의 문자열이 아닙니다.')
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-23-e3c8c4c378a2> in <module> 2 3 try: ----> 4 print(float(x)) 5 except ValueError: 6 print('부동소수점 모양의 문자열이 아닙니다.') TypeError: float() argument must be a string or a number, not 'tuple'
이번에 발생하는 오류는 TypeError 이기 때문이다.
즉, float() 함수는 기본적으로 문자열을 인자로 사용하도록 정의되었는데
완전히 다른 자료형(type)이 입력되었기 때문이다.
해결책은 오류를 명시하지 않거나 아래처럼 여러 오류를 처리하도록 설정하는 것이다.
x = (1, 2)
try:
print(float(x))
except (ValueError, TypeError):
print('사용된 인자에 문제가 있습니다.')
사용된 인자에 문제가 있습니다.
아래 코드는 TypeError 또는 ValueError가 발생하면 입력된 인자를 그대로 반환한다.
def attempt_float(x):
try:
return float(x)
except (TypeError, ValueError):
return x
attempt_float('12.3345')
12.3345
attempt_float((1, 2))
(1, 2)
attempt_float('123f2')
'123f2'
try 블록에서의 오류 발생 여부와 상관 없이 특정 코드를 실행하기 위해 finally 블록을 사용한다.
물론 오류가 발생하면 finally 블록 이후 실행이 바로 멈춘다.
x = (1, 2)
try:
print(float(x))
finally:
print('인자값의 자료형고 형식이 중요합니다.')
인자값의 자료형고 형식이 중요합니다.
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-30-966f6e98066e> in <module> 2 3 try: ----> 4 print(float(x)) 5 finally: 6 print('인자값의 자료형고 형식이 중요합니다.') TypeError: float() argument must be a string or a number, not 'tuple'
except 블록에서 예외 처리가 잘 되면 코드 실행은 이어진다.
x = (1, 2)
try:
print(float(x))
except:
print('사용된 인자에 문제가 있습니다.')
finally:
print('인자값의 자료형고 형식이 중요합니다.')
print("프로그램이 계속 실행됩니다.")
사용된 인자에 문제가 있습니다. 인자값의 자료형고 형식이 중요합니다. 프로그램이 계속 실행됩니다.
try 블록이 성공적으로 실행되었을 때만 특정 코드를 실행시키고자 할 때 else 블록을 사용한다.
x = '123.4567'
try:
print(float(x))
except:
print('사용된 인자에 문제가 있습니다.')
else:
print('올바른 입력값이 사용되었습니다.')
finally:
print('인자값의 자료형고 형식이 중요합니다.')
print("프로그램이 계속 실행됩니다.")
123.4567 올바른 입력값이 사용되었습니다. 인자값의 자료형고 형식이 중요합니다. 프로그램이 계속 실행됩니다.
앞으로 다룰 대부분의 데이터 파일은 csv 파일이며 기본적으로 pandas.read_csv() 함수를
이용하여 불러(loading)와서 데이터로 사용한다.
하지만 파일을 일반적으로 다루는 기본 방식을 이해하는 것도 중요하다.
주의사항: segismuldo.txt 파일이 examples 라는 하위 폴더에 있다고 가정한다.
이를 위해 먼저 해당 디렉토리를 생성하고 파일을 다운로드하도록 아래 코드를 먼저 실행해야한다.
아래 코드가 바로 이해되지 않아도 상관없다. 다만,
인터넷 상에 위치한 파일을 특정 디렉토리로 다운로드하는 함수가 필요한 경우 아래 코드를
수정하여 활용하면 된다는 사실은 기억해 두면 좋다.
import os
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/codingalzi/pydata/master/"
os.makedirs("examples", exist_ok=True)
filename = "segismundo.txt"
print("다운로드:", filename)
url = DOWNLOAD_ROOT + "notebooks/examples/" + filename
urllib.request.urlretrieve(url, "examples/" + filename)
다운로드: segismundo.txt
('examples/segismundo.txt', <http.client.HTTPMessage at 0x7fe1a8e7b640>)
텍스트 문서를 파일 데이터로 불러오려면 open()를 사용한다.
path = 'examples/segismundo.txt'
f = open(path)
segismundo.txt 파일엔 스페인어로 작성된 시를 저장되어 있으며 ñ, á 등의
특수 문자가 사용된다.
따라서 한글 윈도우 운영체제에서는 일부 표현이 깨질 수 있다.
for line in f:
print(line)
Sueña el rico en su riqueza, que más cuidados le ofrece; sueña el pobre que padece su miseria y su pobreza; sueña el que a medrar empieza, sueña el que afana y pretende, sueña el que agravia y ofende, y en el mundo, en conclusión, todos sueñan lo que son, aunque ninguno lo entiende.
이유는 한글 윈도우 운영체제가 파일을 열거나 생성할 때 기본적으로 cp949 인코딩 방식을 사용하는 반면에
스페인어 등에 사용되는 특수 문자는 기본적으로 utf-8 방식으로 인코딩되기 때문이다.
따라서 아래와 같이 인코딩 방식을 utf-8로 지정하여 파일을 열거나 생성하면 운영체제와 상관 없이
모든 유니코드 특수 문자를 제대로 처리한다.
path = 'examples/segismundo.txt'
f = open(path, encoding='utf-8')
for line in f:
print(line)
Sueña el rico en su riqueza, que más cuidados le ofrece; sueña el pobre que padece su miseria y su pobreza; sueña el que a medrar empieza, sueña el que afana y pretende, sueña el que agravia y ofende, y en el mundo, en conclusión, todos sueñan lo que son, aunque ninguno lo entiende.
주의사항: open() 함수의 반환값은 한 번만 순회할 수 있는 이터레이터이다.
따라서 open() 함수를 다시 사용하기 전에는 for 반복문을 사용해도 더 이상 읽을 내용이 없어서
아무 것도 보여주지 않는다.
for line in f:
print(line)
줄 간격이 너무 큰 것으로 보아 줄 끝에 줄바꿈 문자(\n)가 포함된 것으로 보인다.
이와 더불어 print() 함수는 기본적으로 줄바꿈을 넣어주기에 줄바꿈을 두 번하게 된다.
이런 경우 strip() 문자열 메서드를 이용하여 문자열 양 끝에 위치한 스페이스, 탭, 줄바꿈 등의 공백 기호를 제거하는 게 좋다.
f = open(path, encoding='utf-8')
for line in f:
print(line.strip())
Sueña el rico en su riqueza, que más cuidados le ofrece; sueña el pobre que padece su miseria y su pobreza; sueña el que a medrar empieza, sueña el que afana y pretende, sueña el que agravia y ofende, y en el mundo, en conclusión, todos sueñan lo que son, aunque ninguno lo entiende.
문자열의 오른쪽 끝에 위치한 공백 문자들을 제거하는 것으로 충분할 수 있다.
왼편과 오른편의 공백을 제거하는 문자열 메서드는 각각 lstrip() 과 rstrip() 이다.
f = open(path, encoding='utf-8')
for line in f:
print(line.rstrip())
Sueña el rico en su riqueza, que más cuidados le ofrece; sueña el pobre que padece su miseria y su pobreza; sueña el que a medrar empieza, sueña el que afana y pretende, sueña el que agravia y ofende, y en el mundo, en conclusión, todos sueñan lo que son, aunque ninguno lo entiende.
아래 코드는 리스트 조건제시법을 이용하여 파일의 내용을 행 단위의 문자열로 가져와 문자열들의 리스트를 생성한다.
f = open(path, encoding='utf-8')
lines = [x.strip() for x in f]
lines
['Sueña el rico en su riqueza,', 'que más cuidados le ofrece;', '', 'sueña el pobre que padece', 'su miseria y su pobreza;', '', 'sueña el que a medrar empieza,', 'sueña el que afana y pretende,', 'sueña el que agravia y ofende,', '', 'y en el mundo, en conclusión,', 'todos sueñan lo que son,', 'aunque ninguno lo entiende.', '']
저장되어 있는 파일 내용을 불러오고 더 이상 필요 없으면 해당 파일 자체는 닫아 주어야 한다. 그렇지 않으면 마치 편집기에 해당 파일이 열려 있는 것처럼 의도치 않은 수정이 파일에 가해질 수 있다.
f.close()
with ... as ... 형식¶파일을 불러와 일을 처리한 다음에 파일닫기를 자동으로 진행하게 하려면
아래에서 처럼 with ... as ... 형식을 사용한다.
with open(path, encoding='utf-8') as f:
lines = [x.strip() for x in f]
lines
['Sueña el rico en su riqueza,', 'que más cuidados le ofrece;', '', 'sueña el pobre que padece', 'su miseria y su pobreza;', '', 'sueña el que a medrar empieza,', 'sueña el que afana y pretende,', 'sueña el que agravia y ofende,', '', 'y en el mundo, en conclusión,', 'todos sueñan lo que son,', 'aunque ninguno lo entiende.', '']
닫은 파일은 더 이상 내용을 들여다 볼 수 없다.
for line in f:
print(line)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-44-b30473dbc152> in <module> ----> 1 for line in f: 2 print(line) ValueError: I/O operation on closed file.
열려 있는 파일이 이터레이터이기에 for 반복문으로 모든 줄을 순회하하면서 내용을 확인할 수 있었다.
반면에 아래 두 메서드를 이용하면 for 반복문 없이 줄 단위로 내용을 확인할 수 있다.
| 메서드 | 기능 |
|---|---|
readline() |
한 줄씩 읽어서 반환한다. 이터레이터의 __next__() 메서드 역할을 한다. |
readlines() |
모든 줄을 한꺼번에 읽어와서 각각의 줄을 항목으로 갖는 문자열의 리스스를 반환한다. |
f = open(path, encoding='utf-8')
readline() 메서드를 실행할 때마다 한 줄씩 읽어준다.
f.readline()
'Sueña el rico en su riqueza,\n'
f.readline()
'que más cuidados le ofrece;\n'
f.readline()
'\n'
f.close()
반면에 readlines() 메서드는 문자열의 리스트를 반환한다.
항목은 줄 단위로 가져온 문자열이다.
f = open(path, encoding='utf-8')
f.readlines()
['Sueña el rico en su riqueza,\n', 'que más cuidados le ofrece;\n', '\n', 'sueña el pobre que padece\n', 'su miseria y su pobreza;\n', '\n', 'sueña el que a medrar empieza,\n', 'sueña el que afana y pretende,\n', 'sueña el que agravia y ofende,\n', '\n', 'y en el mundo, en conclusión,\n', 'todos sueñan lo que son,\n', 'aunque ninguno lo entiende.\n', '\n']
참고: readlines()의 결과를 보면 각 줄의 끝에 줄바꿈 기호가 사용되었음을 볼 수 있다.
아래 두 가지 방식으로 파일을 생성하거나 작성할 수 있다.
open('파일명', 'w')open('파일명', 'x')아래 코드는 'segismundo.txt'의 파일 내용을 읽어들이자 마자 바로 'tmp.txt' 파일에 써버린다. 단, 빈줄은 무시한다.
| 메서드 | 기능 |
|---|---|
writelines() |
문자열들의 리스트, 튜플에 포함된 항목을 모두 파일에 순서대로 저장 |
write() |
지정된 문자열을 파일 맨 아랫줄에 추가 |
참고: open() 함수가 반환하는 파일 객체를 파일 핸들(file handle) 이라 부른다. 따라서
아래 코드에서처럼 파일 객체를 가리키는 변수로 handle, file_handle 등을 많이 사용한다.
with open('tmp.txt', 'w', encoding="utf-8") as handle:
handle.writelines([x for x in open(path, encoding="utf-8") if len(x) > 1])
handle.write("끝에서 둘째줄입니다.")
handle.write("마지막 줄입니다.")
내용을 다시 확인해보자.
with open('tmp.txt', encoding='utf-8') as handle:
lines = handle.readlines()
lines
['Sueña el rico en su riqueza,\n', 'que más cuidados le ofrece;\n', 'sueña el pobre que padece\n', 'su miseria y su pobreza;\n', 'sueña el que a medrar empieza,\n', 'sueña el que afana y pretende,\n', 'sueña el que agravia y ofende,\n', 'y en el mundo, en conclusión,\n', 'todos sueñan lo que son,\n', 'aunque ninguno lo entiende.\n', '끝에서 둘째줄입니다.마지막 줄입니다.']
그런데 마지막 두 줄이 구분되지 않는다. 이유는 끝에서 두번째 줄 끝에 줄바꿈 문자가 포함되지 않았기 때문이다. 아래처럼 하면 줄바꿈이 이루어진다.
with open('tmp.txt', 'w', encoding="utf-8") as handle:
handle.writelines([x for x in open(path, encoding="utf-8") if len(x) > 1])
handle.write("끝에서 둘째줄입니다.\n")
handle.write("마지막 줄입니다.")
with open('tmp.txt', encoding='utf-8') as handle:
lines = handle.readlines()
lines
['Sueña el rico en su riqueza,\n', 'que más cuidados le ofrece;\n', 'sueña el pobre que padece\n', 'su miseria y su pobreza;\n', 'sueña el que a medrar empieza,\n', 'sueña el que afana y pretende,\n', 'sueña el que agravia y ofende,\n', 'y en el mundo, en conclusión,\n', 'todos sueñan lo que son,\n', 'aunque ninguno lo entiende.\n', '끝에서 둘째줄입니다.\n', '마지막 줄입니다.']