감사말: 프랑소와 숄레의 Deep Learning with Python, Second Edition 9장에 사용된 코드에 대한 설명을 담고 있으며 텐서플로우 2.6 버전에서 작성되었습니다. 소스코드를 공개한 저자에게 감사드립니다.
tensorflow 버전과 GPU 확인
구글 코랩 설정: '런타임 -> 런타임 유형 변경' 메뉴에서 GPU 지정 후 아래 명령어 실행 결과 확인
!nvidia-smi사용되는 tensorflow 버전 확인
import tensorflow as tf
tf.__version__
tensorflow가 GPU를 사용하는지 여부 확인
tf.config.list_physical_devices('GPU')
모델 아키텍처는 모델 설계방식을 의미하며 딥러닝 모델을 구성할 때 매우 중요하다. 주어진 데이터셋과 해결해야 문제에 따라 적절한 층을 적절하게 구성해서 모델을 구현해야 한다. 좋은 모델 아키텍처를 사용할 수록 적은 양의 데이터을 이용하여 보다 빠르게 좋은 성능의 모델을 얻을 가능성이 높아진다. 아쉽게도 좋은 모델 아키텍처와 관련된 이론은 없으며 많은 경험을 통한 직관이 보다 중요한 역할을 수행한다.
여기서는 실전에서 최고 성능을 발휘한 합성곱 신경망 몇 개를 이용하여 주요 합성곱 신경망 모델의 기본이 되는 아키텍처 3 개를 살펴본다.
모든 유명한 합성곱 신경망 모델은 블록(모듈)을 계층적으로 쌓아 올린 구조를 갖는다. 여기서 블록(모듈)은 여러 개의 층(레이어)으로 구성되며, 하나의 블록(모듈)이 여러 번 재활용되기도 한다. 예를 들어, 8장에서 다룬 VGG16 모델은 "Conv2D, Conv2D, MaxPooling2D" 로 구성된 블록(모듈)을 계층적으로 구성하였다.
대부분의 합성곱 신경망 모델의 또다른 특징는 특성 피라미드 형식의 계층적 구조를 사용하는 점이다. VGG16의 경우에 필터 수를 32, 64, 128 등으로 수를 늘리는 반면에 특성맵(feature maps)의 크기는 그에 상응하게 줄여 나간다(아래 그림 참조).
좁은 층 깊은 신경망 모델
일반적으로 많은 유닛이 포함된 층을 몇 게 쌓는 것보다 적은 유닛이 포함된 층을 높이 쌓을 때 모델의 성능이 좋아진다. 하지만 층을 높이 쌓을 수록 전달되어야 하는 손실값(오차)의 그레이디언트 소실 문제(vanishing gradient problem)가 발생하여 이를 극복해야 하는 아키텍처(설계방식)을 사용해야 한다. 이를 위한 대표적인 아키텍처는 잔차 연결(residual connections)이다.
참고: 층을 통과할 때 어쩔 수 없이 발생하는 노이즈(잡음) 때문에 그레이디언트 소실 문제가 발생한다.
블록(모듈)의 입력값을 블록을 통과하여 생성된 출력값과 합쳐서 다음 블록으로 전달하는 아키텍처이다(아래 그림 참조). 이 방식을 통해 블록의 입력값에 대한 정보가 보다 정확하게 상위 블록에 전달되어, 그레이디언트 소실 문제를 해결하는 데에 많은 도움을 준다. 실제로 잔차 연결을 이용하면 블록을 매우 높게 쌓아도 모델 훈련이 가능하다.
참고: 잔차 연결 아키텍처는 2015년에 소개된 ResNet 계열의 모델에서 처음 사용되었으며, 2015년 ILSVRC 이미지 분류 경진대회에서 1등을 차지했다.
잔차 연결 핵심: 모양(shape) 맞추기
잔차 연결을 사용할 때 주의해야할 기본사항은 블록의 입력텐서와 출력테서의 모양을 맞추는 일이다.
이때 맥스풀링 사용여부에 따라 보폭(strides)의 크기가 달라진다.
먼저, 맥스풀링을 사용하지 않는 경우엔 Conv2D에서 사용된 필터 수를 맞추는 데에만 주의하면 된다.
Conv2D 층: padding="same" 옵션을 사용하여 모양을 유지Conv2D 층을 이용하여 필터 수를 맞춤. 필터 크기는 1x1 사용.
활성화 함수는 없음.from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs)
residual = x
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) # padding 사용
residual = layers.Conv2D(64, 1)(residual) # 필터 수 맞추기
x = layers.add([x, residual])
맥스풀링을 사용하는 경우엔 보폭을 활용해야 한다.
Conv2D 층을 적용할 때 보폭 사용inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs)
residual = x
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.MaxPooling2D(2, padding="same")(x) # 맥스풀링
residual = layers.Conv2D(64, 1, strides=2)(residual) # 보폭 사용
x = layers.add([x, residual])
예제
아래 코드는 잔차 연결을 사용하는 활용법을 보여준다. 맥스풀링과 필터 수에 따른 구분을 사용함에 주의하라.
# 입력층
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Rescaling(1./255)(inputs)
# 은닉층
def residual_block(x, filters, pooling=False):
residual = x
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
if pooling: # 맥스풀링 사용하는 경우
x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(filters, 1, strides=2)(residual)
elif filters != residual.shape[-1]: # 필터 수가 변하는 경우
residual = layers.Conv2D(filters, 1)(residual)
x = layers.add([x, residual])
return x
x = residual_block(x, filters=32, pooling=True)
x = residual_block(x, filters=64, pooling=True)
x = residual_block(x, filters=128, pooling=False)
x = layers.GlobalAveragePooling2D()(x) # 채널 별로 하나의 값(채널 평균값) 선택
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델 설정
model = keras.Model(inputs=inputs, outputs=outputs)
모델 구성 요약은 다음과 같다.
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 32, 32, 3)] 0
__________________________________________________________________________________________________
rescaling (Rescaling) (None, 32, 32, 3) 0 input_3[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 32, 32, 32) 896 rescaling[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 32, 32, 32) 9248 conv2d_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 16, 16, 32) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 32) 128 rescaling[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 16, 16, 32) 0 max_pooling2d_1[0][0]
conv2d_8[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 64) 18496 add_2[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 16, 16, 64) 36928 conv2d_9[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 8, 8, 64) 0 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 8, 8, 64) 2112 add_2[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 8, 8, 64) 0 max_pooling2d_2[0][0]
conv2d_11[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 8, 8, 128) 73856 add_3[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 8, 8, 128) 147584 conv2d_12[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 8, 8, 128) 8320 add_3[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 8, 8, 128) 0 conv2d_13[0][0]
conv2d_14[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 128) 0 add_4[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1) 129 global_average_pooling2d[0][0]
==================================================================================================
Total params: 297,697
Trainable params: 297,697
Non-trainable params: 0
__________________________________________________________________________________________________
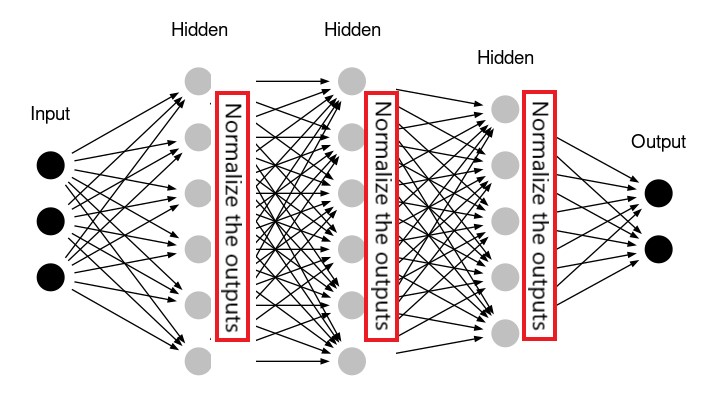
정규화(normalization)는 다양한 모양의 샘플을 정규화를 통해 보다 유사하게 만들어 모델의 학습을 도와주고 훈련된 모델의 일반화 성능을 올려준다. 지금까지 살펴 본 정규화는 모델의 입력 데이터를 전처리 과정에서 평균을 0으로, 표준편차를 1로 만드는 방식이었다. 이는 데이터셋이 정규분포를 따른다는 가정 하에 진행된 정규화였다. 아래 그림은 주택가격 예측 데이터의 특성 중에 주택가격과 건축년수를 정규화한 경우(오른편)와 그렇지 않는 경우(왼편)의 데이터 분포의 변화를 보여준다.
참고: 정규분포를 따르지 않는 데이터에 대한 분석은 기본적으로 머신러닝(딥러닝) 기법을 적용할 수 없다.
하지만 입력 데이터셋에 대한 정규화는 출력값의 정규화를 전혀 보장하지 않는다. 따라서 다음 층으로 넘겨주기 전에 정규화를 먼저 진행하면 보다 훈련이 잘 될 수 있다. 더 나아가 출력값을 먼저 정규화한 후에 활성화 함수를 적용할 때 보다 좋은 성능의 모델이 구현될 수 있음이 발혀지기도 했다.
배치 정규화(batch normalization)가 바로 앞서 설명한 기능을 대신 처리하며,
2015년에 발표된 한 논문에서 소개되었다.
케라스의 경우 layers.BatchNormalization 층이 배치 정규하를 지원한다.
배치 정규화로 인한 모델 성능 향상에 대한 구체적인 이론은 아직 존재하지 않는다. 다만 경험적으로 많은 합성곱 신경망 모델의 성능에 도움을 준다는 사실만 알려져 있을 뿐이다. 잔차 연결과 함께 배치 정규화 또한 모델 훈련과정에 그레이디언트 역전파에 도움을 주어 매우 깊은 딥러닝 모델의 훈련에 도움을 준다. 예를 들어, ResNet50, EfficientNet, Xception 모델 등은 배치 정규화 없이는 제대로 훈련되지 않는다.
배치 정규화 사용법
BatchNormalization 층을 Conv2D, Dense 등 임의의 층 다음에 사용할 수 있다.
주로 사용되는 형식은 다음과 같다.
x = ...
x = layers.Conv2D(32, 3, use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = ...
use_bias=False 옵션: 배치 정규화에 의해 어차피 데이터의 평균값을 0으로 만들기에 굳이 편향(bias) 파라미터를
훈련 과정 중에 따로 학습시킬 이유가 없다. 따라서 학습되어야 할 파라미터 수가 아주 조금 줄어들어
학습 속도가 그만큼 빨라진다.relu() 활성화 함수의 기능을 극대화할 수 있다(고 주장된다).모델 미세조정(fine-tuning)과 배치 정규화
배치 정규화 층이 포함된 모델을 미세조정할 때 해당 배치 정규화 층을 동결(freeze)할 것을 추천한다. 미세조정의 경우 모델 파라미터가 급격하게 변하지 않기에 배치 정규화에 사용된 평균값과 표준편차를 굳이 업데이트할 필요는 없기 때문이다(라고 추정된다).
예제
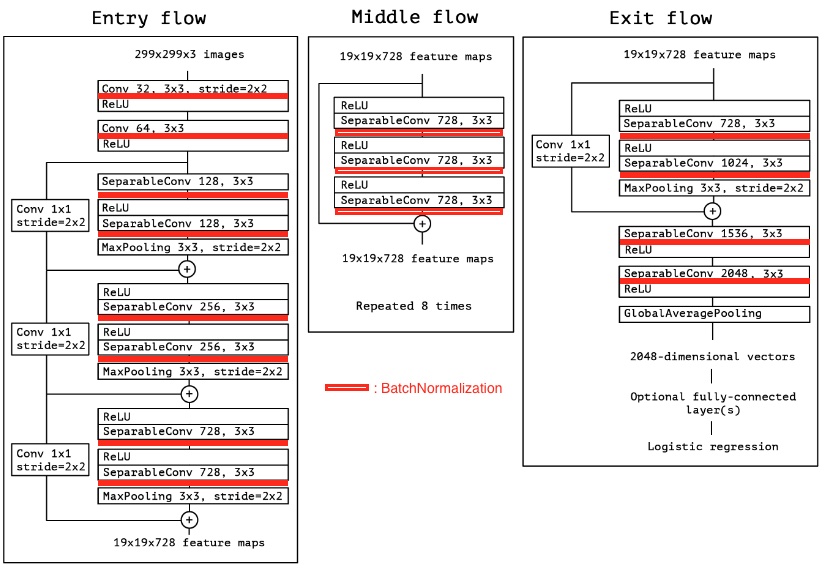
아래 그림은 2017년에 소개된 Xception 모델의 구조를 보여준다.
빨강색 사각형으로 표시된 부분에 BatchNormalization 층이 사용되었다.
케라스의 SeparableConv2D 층은 Conv2D 층보다
적은 수의 가중치 파라미터를 사용하여 보다 적은 양의 계산으로 성능이 좀 더 좋은 모델을 생성한다.
2017년 Xception 모델 논문에서 소개되었으며 당시 최고의 이미지 분류 성능을 보였다.
참고: 최신 이미지 분류 모델의 성능은 Image Classification on ImageNet을 참조한다.
SeparableConv2D 작동법
SeparableConv2D는 필터를 채널 별로 적용한 후
나중에 채널 별 결과를 합친다.
이렇게 작동하는 층이 채널 분리 합성곱(depthwise separable convolution) 층이며
아래 그림처럼 채널 별로 생성된 결과를 합친 후 1x1 합성곱 신경망을 통과시킨다.
SeparableConv2D 작동 원리
이미지에 저장된 정보가 채널 별로 서로 독립적이라는 가정을 사용한다.
따라서 채널 별로 서로 다른 필터를 사용한 후 결과들을 1x1 모양의 필터를 사용하여 합친다.
이때 원하는 종류의 채널 수 만큼의 1x1 모양의 필터를 사용하여
다양한 정보를 추출한다.
Conv2D와 SeparableConv2D의 서로 다른 작동과정은 다음과 같이 설명된다.
Conv2D 작동 원리padding="same" 옵션 사용한 경우
SeparableConv2D 작동 원리padding="same" 옵션 사용한 경우학습가능한 파라미터 수 비교
채널 분리 합성곱 신경망이 Conv2D 층을 사용하는 경우보다 몇 배 이상 적은 수의
파라미터를 사용한다.
경우 1(위 그림): 3x3 모양의 필터 64개를 3개의 채널을 갖는
입력 데이터에 사용할 경우 학습가능한 파라미터 수는 각각 다음과 같다.
Conv2D의 경우: 3*3*3*64 = 1,728SeparableConv2D의 경우: 3*3*3 + 3*64 = 219경우 2: 3x3 모양의 필터 64개를 10개의 채널을 갖는
입력 데이터에 사용할 경우 학습가능한 파라미터 수는 각각 다음과 같다.
Conv2D의 경우: 3*3*10*64 = 5,760SeparableConv2D의 경우: 3*3*10 + 10*64 = 730경우 2: 3x3 모양의 필터 64개를 64개의 채널을 갖는
입력 데이터에 사용할 경우 학습가능한 파라미터 수는 각각 다음과 같다.
Conv2D의 경우: 3*3*64*64 = 36,864SeparableConv2D의 경우: 3*3*64 + 64*64 = 4,672SeparableConv2D의 약점
채널 분리 합성곱에 사용되는 알고리즘이 CUDA에서 지원되지 않는다.
따라서 GPU를 사용하더라도 기존 Conv2D 층만을 사용한 모델에 비해
학습 속도에 별 차이가 없다.
즉 채널 분리 합성곱이 비록 훨씬 적은 수의 파라미터를 학습에 사용하지만
이로 인해 시간상의 이득은 주지 않는다.
하지만 적은 수의 파라미터를 사용하기에 일반화 성능이 보다 좋은 모델을
구현한다는 점이 매우 중요하다.
참고: CUDA와 cuDNN
예제: Xception 모델
케라스에서 지원하는 Xception 모델의 구성은 2017년 모델과 조금 다르지만
기본적으로 SeparableConv2D와 BatchNormalizaiton 층을 효율적으로 활용한
블록을 잔차 연결과 함께 사용하여 깊게 쌓은 모델이다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.applications.xception.Xception(
include_top=True, weights='imagenet', input_tensor=None,
input_shape=None, pooling=None, classes=1000,
classifier_activation='softmax'
)
model.summary()
Model: "xception"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_4 (InputLayer) [(None, 299, 299, 3) 0
__________________________________________________________________________________________________
block1_conv1 (Conv2D) (None, 149, 149, 32) 864 input_4[0][0]
__________________________________________________________________________________________________
block1_conv1_bn (BatchNormaliza (None, 149, 149, 32) 128 block1_conv1[0][0]
__________________________________________________________________________________________________
block1_conv1_act (Activation) (None, 149, 149, 32) 0 block1_conv1_bn[0][0]
__________________________________________________________________________________________________
block1_conv2 (Conv2D) (None, 147, 147, 64) 18432 block1_conv1_act[0][0]
__________________________________________________________________________________________________
block1_conv2_bn (BatchNormaliza (None, 147, 147, 64) 256 block1_conv2[0][0]
__________________________________________________________________________________________________
block1_conv2_act (Activation) (None, 147, 147, 64) 0 block1_conv2_bn[0][0]
__________________________________________________________________________________________________
block2_sepconv1 (SeparableConv2 (None, 147, 147, 128 8768 block1_conv2_act[0][0]
__________________________________________________________________________________________________
block2_sepconv1_bn (BatchNormal (None, 147, 147, 128 512 block2_sepconv1[0][0]
__________________________________________________________________________________________________
block2_sepconv2_act (Activation (None, 147, 147, 128 0 block2_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block2_sepconv2 (SeparableConv2 (None, 147, 147, 128 17536 block2_sepconv2_act[0][0]
__________________________________________________________________________________________________
block2_sepconv2_bn (BatchNormal (None, 147, 147, 128 512 block2_sepconv2[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 74, 74, 128) 8192 block1_conv2_act[0][0]
__________________________________________________________________________________________________
block2_pool (MaxPooling2D) (None, 74, 74, 128) 0 block2_sepconv2_bn[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 74, 74, 128) 512 conv2d_15[0][0]
__________________________________________________________________________________________________
add_5 (Add) (None, 74, 74, 128) 0 block2_pool[0][0]
batch_normalization[0][0]
__________________________________________________________________________________________________
block3_sepconv1_act (Activation (None, 74, 74, 128) 0 add_5[0][0]
__________________________________________________________________________________________________
block3_sepconv1 (SeparableConv2 (None, 74, 74, 256) 33920 block3_sepconv1_act[0][0]
__________________________________________________________________________________________________
block3_sepconv1_bn (BatchNormal (None, 74, 74, 256) 1024 block3_sepconv1[0][0]
__________________________________________________________________________________________________
block3_sepconv2_act (Activation (None, 74, 74, 256) 0 block3_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block3_sepconv2 (SeparableConv2 (None, 74, 74, 256) 67840 block3_sepconv2_act[0][0]
__________________________________________________________________________________________________
block3_sepconv2_bn (BatchNormal (None, 74, 74, 256) 1024 block3_sepconv2[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 37, 37, 256) 32768 add_5[0][0]
__________________________________________________________________________________________________
block3_pool (MaxPooling2D) (None, 37, 37, 256) 0 block3_sepconv2_bn[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 37, 37, 256) 1024 conv2d_16[0][0]
__________________________________________________________________________________________________
add_6 (Add) (None, 37, 37, 256) 0 block3_pool[0][0]
batch_normalization_1[0][0]
__________________________________________________________________________________________________
block4_sepconv1_act (Activation (None, 37, 37, 256) 0 add_6[0][0]
__________________________________________________________________________________________________
block4_sepconv1 (SeparableConv2 (None, 37, 37, 728) 188672 block4_sepconv1_act[0][0]
__________________________________________________________________________________________________
block4_sepconv1_bn (BatchNormal (None, 37, 37, 728) 2912 block4_sepconv1[0][0]
__________________________________________________________________________________________________
block4_sepconv2_act (Activation (None, 37, 37, 728) 0 block4_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block4_sepconv2 (SeparableConv2 (None, 37, 37, 728) 536536 block4_sepconv2_act[0][0]
__________________________________________________________________________________________________
block4_sepconv2_bn (BatchNormal (None, 37, 37, 728) 2912 block4_sepconv2[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 19, 19, 728) 186368 add_6[0][0]
__________________________________________________________________________________________________
block4_pool (MaxPooling2D) (None, 19, 19, 728) 0 block4_sepconv2_bn[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 19, 19, 728) 2912 conv2d_17[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 19, 19, 728) 0 block4_pool[0][0]
batch_normalization_2[0][0]
__________________________________________________________________________________________________
block5_sepconv1_act (Activation (None, 19, 19, 728) 0 add_7[0][0]
__________________________________________________________________________________________________
block5_sepconv1 (SeparableConv2 (None, 19, 19, 728) 536536 block5_sepconv1_act[0][0]
__________________________________________________________________________________________________
block5_sepconv1_bn (BatchNormal (None, 19, 19, 728) 2912 block5_sepconv1[0][0]
__________________________________________________________________________________________________
block5_sepconv2_act (Activation (None, 19, 19, 728) 0 block5_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block5_sepconv2 (SeparableConv2 (None, 19, 19, 728) 536536 block5_sepconv2_act[0][0]
__________________________________________________________________________________________________
block5_sepconv2_bn (BatchNormal (None, 19, 19, 728) 2912 block5_sepconv2[0][0]
__________________________________________________________________________________________________
block5_sepconv3_act (Activation (None, 19, 19, 728) 0 block5_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block5_sepconv3 (SeparableConv2 (None, 19, 19, 728) 536536 block5_sepconv3_act[0][0]
__________________________________________________________________________________________________
block5_sepconv3_bn (BatchNormal (None, 19, 19, 728) 2912 block5_sepconv3[0][0]
__________________________________________________________________________________________________
add_8 (Add) (None, 19, 19, 728) 0 block5_sepconv3_bn[0][0]
add_7[0][0]
__________________________________________________________________________________________________
block6_sepconv1_act (Activation (None, 19, 19, 728) 0 add_8[0][0]
__________________________________________________________________________________________________
block6_sepconv1 (SeparableConv2 (None, 19, 19, 728) 536536 block6_sepconv1_act[0][0]
__________________________________________________________________________________________________
block6_sepconv1_bn (BatchNormal (None, 19, 19, 728) 2912 block6_sepconv1[0][0]
__________________________________________________________________________________________________
block6_sepconv2_act (Activation (None, 19, 19, 728) 0 block6_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block6_sepconv2 (SeparableConv2 (None, 19, 19, 728) 536536 block6_sepconv2_act[0][0]
__________________________________________________________________________________________________
block6_sepconv2_bn (BatchNormal (None, 19, 19, 728) 2912 block6_sepconv2[0][0]
__________________________________________________________________________________________________
block6_sepconv3_act (Activation (None, 19, 19, 728) 0 block6_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block6_sepconv3 (SeparableConv2 (None, 19, 19, 728) 536536 block6_sepconv3_act[0][0]
__________________________________________________________________________________________________
block6_sepconv3_bn (BatchNormal (None, 19, 19, 728) 2912 block6_sepconv3[0][0]
__________________________________________________________________________________________________
add_9 (Add) (None, 19, 19, 728) 0 block6_sepconv3_bn[0][0]
add_8[0][0]
__________________________________________________________________________________________________
block7_sepconv1_act (Activation (None, 19, 19, 728) 0 add_9[0][0]
__________________________________________________________________________________________________
block7_sepconv1 (SeparableConv2 (None, 19, 19, 728) 536536 block7_sepconv1_act[0][0]
__________________________________________________________________________________________________
block7_sepconv1_bn (BatchNormal (None, 19, 19, 728) 2912 block7_sepconv1[0][0]
__________________________________________________________________________________________________
block7_sepconv2_act (Activation (None, 19, 19, 728) 0 block7_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block7_sepconv2 (SeparableConv2 (None, 19, 19, 728) 536536 block7_sepconv2_act[0][0]
__________________________________________________________________________________________________
block7_sepconv2_bn (BatchNormal (None, 19, 19, 728) 2912 block7_sepconv2[0][0]
__________________________________________________________________________________________________
block7_sepconv3_act (Activation (None, 19, 19, 728) 0 block7_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block7_sepconv3 (SeparableConv2 (None, 19, 19, 728) 536536 block7_sepconv3_act[0][0]
__________________________________________________________________________________________________
block7_sepconv3_bn (BatchNormal (None, 19, 19, 728) 2912 block7_sepconv3[0][0]
__________________________________________________________________________________________________
add_10 (Add) (None, 19, 19, 728) 0 block7_sepconv3_bn[0][0]
add_9[0][0]
__________________________________________________________________________________________________
block8_sepconv1_act (Activation (None, 19, 19, 728) 0 add_10[0][0]
__________________________________________________________________________________________________
block8_sepconv1 (SeparableConv2 (None, 19, 19, 728) 536536 block8_sepconv1_act[0][0]
__________________________________________________________________________________________________
block8_sepconv1_bn (BatchNormal (None, 19, 19, 728) 2912 block8_sepconv1[0][0]
__________________________________________________________________________________________________
block8_sepconv2_act (Activation (None, 19, 19, 728) 0 block8_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block8_sepconv2 (SeparableConv2 (None, 19, 19, 728) 536536 block8_sepconv2_act[0][0]
__________________________________________________________________________________________________
block8_sepconv2_bn (BatchNormal (None, 19, 19, 728) 2912 block8_sepconv2[0][0]
__________________________________________________________________________________________________
block8_sepconv3_act (Activation (None, 19, 19, 728) 0 block8_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block8_sepconv3 (SeparableConv2 (None, 19, 19, 728) 536536 block8_sepconv3_act[0][0]
__________________________________________________________________________________________________
block8_sepconv3_bn (BatchNormal (None, 19, 19, 728) 2912 block8_sepconv3[0][0]
__________________________________________________________________________________________________
add_11 (Add) (None, 19, 19, 728) 0 block8_sepconv3_bn[0][0]
add_10[0][0]
__________________________________________________________________________________________________
block9_sepconv1_act (Activation (None, 19, 19, 728) 0 add_11[0][0]
__________________________________________________________________________________________________
block9_sepconv1 (SeparableConv2 (None, 19, 19, 728) 536536 block9_sepconv1_act[0][0]
__________________________________________________________________________________________________
block9_sepconv1_bn (BatchNormal (None, 19, 19, 728) 2912 block9_sepconv1[0][0]
__________________________________________________________________________________________________
block9_sepconv2_act (Activation (None, 19, 19, 728) 0 block9_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block9_sepconv2 (SeparableConv2 (None, 19, 19, 728) 536536 block9_sepconv2_act[0][0]
__________________________________________________________________________________________________
block9_sepconv2_bn (BatchNormal (None, 19, 19, 728) 2912 block9_sepconv2[0][0]
__________________________________________________________________________________________________
block9_sepconv3_act (Activation (None, 19, 19, 728) 0 block9_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block9_sepconv3 (SeparableConv2 (None, 19, 19, 728) 536536 block9_sepconv3_act[0][0]
__________________________________________________________________________________________________
block9_sepconv3_bn (BatchNormal (None, 19, 19, 728) 2912 block9_sepconv3[0][0]
__________________________________________________________________________________________________
add_12 (Add) (None, 19, 19, 728) 0 block9_sepconv3_bn[0][0]
add_11[0][0]
__________________________________________________________________________________________________
block10_sepconv1_act (Activatio (None, 19, 19, 728) 0 add_12[0][0]
__________________________________________________________________________________________________
block10_sepconv1 (SeparableConv (None, 19, 19, 728) 536536 block10_sepconv1_act[0][0]
__________________________________________________________________________________________________
block10_sepconv1_bn (BatchNorma (None, 19, 19, 728) 2912 block10_sepconv1[0][0]
__________________________________________________________________________________________________
block10_sepconv2_act (Activatio (None, 19, 19, 728) 0 block10_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block10_sepconv2 (SeparableConv (None, 19, 19, 728) 536536 block10_sepconv2_act[0][0]
__________________________________________________________________________________________________
block10_sepconv2_bn (BatchNorma (None, 19, 19, 728) 2912 block10_sepconv2[0][0]
__________________________________________________________________________________________________
block10_sepconv3_act (Activatio (None, 19, 19, 728) 0 block10_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block10_sepconv3 (SeparableConv (None, 19, 19, 728) 536536 block10_sepconv3_act[0][0]
__________________________________________________________________________________________________
block10_sepconv3_bn (BatchNorma (None, 19, 19, 728) 2912 block10_sepconv3[0][0]
__________________________________________________________________________________________________
add_13 (Add) (None, 19, 19, 728) 0 block10_sepconv3_bn[0][0]
add_12[0][0]
__________________________________________________________________________________________________
block11_sepconv1_act (Activatio (None, 19, 19, 728) 0 add_13[0][0]
__________________________________________________________________________________________________
block11_sepconv1 (SeparableConv (None, 19, 19, 728) 536536 block11_sepconv1_act[0][0]
__________________________________________________________________________________________________
block11_sepconv1_bn (BatchNorma (None, 19, 19, 728) 2912 block11_sepconv1[0][0]
__________________________________________________________________________________________________
block11_sepconv2_act (Activatio (None, 19, 19, 728) 0 block11_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block11_sepconv2 (SeparableConv (None, 19, 19, 728) 536536 block11_sepconv2_act[0][0]
__________________________________________________________________________________________________
block11_sepconv2_bn (BatchNorma (None, 19, 19, 728) 2912 block11_sepconv2[0][0]
__________________________________________________________________________________________________
block11_sepconv3_act (Activatio (None, 19, 19, 728) 0 block11_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block11_sepconv3 (SeparableConv (None, 19, 19, 728) 536536 block11_sepconv3_act[0][0]
__________________________________________________________________________________________________
block11_sepconv3_bn (BatchNorma (None, 19, 19, 728) 2912 block11_sepconv3[0][0]
__________________________________________________________________________________________________
add_14 (Add) (None, 19, 19, 728) 0 block11_sepconv3_bn[0][0]
add_13[0][0]
__________________________________________________________________________________________________
block12_sepconv1_act (Activatio (None, 19, 19, 728) 0 add_14[0][0]
__________________________________________________________________________________________________
block12_sepconv1 (SeparableConv (None, 19, 19, 728) 536536 block12_sepconv1_act[0][0]
__________________________________________________________________________________________________
block12_sepconv1_bn (BatchNorma (None, 19, 19, 728) 2912 block12_sepconv1[0][0]
__________________________________________________________________________________________________
block12_sepconv2_act (Activatio (None, 19, 19, 728) 0 block12_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block12_sepconv2 (SeparableConv (None, 19, 19, 728) 536536 block12_sepconv2_act[0][0]
__________________________________________________________________________________________________
block12_sepconv2_bn (BatchNorma (None, 19, 19, 728) 2912 block12_sepconv2[0][0]
__________________________________________________________________________________________________
block12_sepconv3_act (Activatio (None, 19, 19, 728) 0 block12_sepconv2_bn[0][0]
__________________________________________________________________________________________________
block12_sepconv3 (SeparableConv (None, 19, 19, 728) 536536 block12_sepconv3_act[0][0]
__________________________________________________________________________________________________
block12_sepconv3_bn (BatchNorma (None, 19, 19, 728) 2912 block12_sepconv3[0][0]
__________________________________________________________________________________________________
add_15 (Add) (None, 19, 19, 728) 0 block12_sepconv3_bn[0][0]
add_14[0][0]
__________________________________________________________________________________________________
block13_sepconv1_act (Activatio (None, 19, 19, 728) 0 add_15[0][0]
__________________________________________________________________________________________________
block13_sepconv1 (SeparableConv (None, 19, 19, 728) 536536 block13_sepconv1_act[0][0]
__________________________________________________________________________________________________
block13_sepconv1_bn (BatchNorma (None, 19, 19, 728) 2912 block13_sepconv1[0][0]
__________________________________________________________________________________________________
block13_sepconv2_act (Activatio (None, 19, 19, 728) 0 block13_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block13_sepconv2 (SeparableConv (None, 19, 19, 1024) 752024 block13_sepconv2_act[0][0]
__________________________________________________________________________________________________
block13_sepconv2_bn (BatchNorma (None, 19, 19, 1024) 4096 block13_sepconv2[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 10, 10, 1024) 745472 add_15[0][0]
__________________________________________________________________________________________________
block13_pool (MaxPooling2D) (None, 10, 10, 1024) 0 block13_sepconv2_bn[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 10, 10, 1024) 4096 conv2d_18[0][0]
__________________________________________________________________________________________________
add_16 (Add) (None, 10, 10, 1024) 0 block13_pool[0][0]
batch_normalization_3[0][0]
__________________________________________________________________________________________________
block14_sepconv1 (SeparableConv (None, 10, 10, 1536) 1582080 add_16[0][0]
__________________________________________________________________________________________________
block14_sepconv1_bn (BatchNorma (None, 10, 10, 1536) 6144 block14_sepconv1[0][0]
__________________________________________________________________________________________________
block14_sepconv1_act (Activatio (None, 10, 10, 1536) 0 block14_sepconv1_bn[0][0]
__________________________________________________________________________________________________
block14_sepconv2 (SeparableConv (None, 10, 10, 2048) 3159552 block14_sepconv1_act[0][0]
__________________________________________________________________________________________________
block14_sepconv2_bn (BatchNorma (None, 10, 10, 2048) 8192 block14_sepconv2[0][0]
__________________________________________________________________________________________________
block14_sepconv2_act (Activatio (None, 10, 10, 2048) 0 block14_sepconv2_bn[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 2048) 0 block14_sepconv2_act[0][0]
__________________________________________________________________________________________________
predictions (Dense) (None, 1000) 2049000 avg_pool[0][0]
==================================================================================================
Total params: 22,910,480
Trainable params: 22,855,952
Non-trainable params: 54,528
__________________________________________________________________________________________________
미니 Xception 모델을 직접 구현하여 강아지-고양이 이항분류 작업을 실행해본다.
모델 구현에 사용되는 기법을 정리하면 다음과 같다.
참고: 여기서는 비록 이미지 분류 모델을 예제로 활용하지만 앞서 언급된 모든 기법은 컴퓨터 비전 프로젝트 일반에 적용될 수 있다. 예를 들어 DeepLabV3 모델은 Xception 모델을 이용하는 2021년 기준 최고의 이미지 분할 모델이다.
이미지 다운로드 및 데이터 적재
사용하는 데이터셋은 8장에서 사용한 캐글(kaggle)의 강아지-고양이 데이터셋이며, 이미지 다운로드와 훈련셋 등의 적재는 8장에서 사용한 방식과 동일하다.
# 구글 코랩: 캐글 인증서 업로드
if 'google.colab' in str(get_ipython()):
from google.colab import files
files.upload()
print('이어지는 코드는 kaggle.json 파일이 현재 디렉토리에 있다고 가정함.')
이어지는 코드는 kaggle.json 파일이 현재 디렉토리에 있다고 가정함. 아니면 직접 지정된 폴더에 kaggle.json 파일을 저장해야 함.
import os, shutil, pathlib
# kaggle 인증서 현재 저장 위치
where_kaggle_json = pathlib.Path("kaggle.json")
# kaggle 인증서를 사용자 홈디렉토리의 ".kaggle/" 디렉토리로 옮기기
if where_kaggle_json.is_file():
# 홈디렉토리 경로 지정
homeDir = pathlib.Path.home()
kaggleDir = homeDir / ".kaggle"
kaggleJsonFile = kaggleDir / "kaggle.json"
# ".kaggle" 디렉토리 존재 여부 확인. 없으면 생성.
if not kaggleDir.is_dir():
os.makedirs(kaggleDir)
# "kaggle.json" 파일 존재 여부 확인. 없으면 복사.
if not kaggleJsonFile.is_file():
shutil.copyfile(src=where_kaggle_json,
dst=kaggleJsonFile)
os.chmod(kaggleJsonFile, 0o600)
else:
print("kaggle.json 파일을 지정된 사용자 홈폴더의 '.kaggle' 폴더에 저장하세요!")
try:
!kaggle competitions download -c dogs-vs-cats
except:
!pip install kaggle
!kaggle competitions download -c dogs-vs-cats
Downloading dogs-vs-cats.zip to C:\Users\gslee\Documents\GitHub\dlp\notebooks\test
0%| | 0.00/812M [00:00<?, ?B/s] 0%| | 1.00M/812M [00:00<06:50, 2.07MB/s] 0%| | 2.00M/812M [00:00<04:24, 3.21MB/s] 0%| | 3.00M/812M [00:00<03:00, 4.70MB/s] 1%| | 5.00M/812M [00:00<01:56, 7.25MB/s] 1%| | 6.00M/812M [00:01<01:49, 7.72MB/s] 1%| | 8.00M/812M [00:01<01:23, 10.1MB/s] 1%|1 | 10.0M/812M [00:01<01:09, 12.0MB/s] 1%|1 | 12.0M/812M [00:01<01:03, 13.2MB/s] 2%|1 | 14.0M/812M [00:01<00:59, 14.0MB/s] 2%|1 | 16.0M/812M [00:01<00:56, 14.7MB/s] 2%|2 | 18.0M/812M [00:01<00:55, 15.0MB/s] 2%|2 | 20.0M/812M [00:02<00:55, 15.0MB/s] 3%|2 | 22.0M/812M [00:02<00:54, 15.2MB/s] 3%|2 | 24.0M/812M [00:02<00:53, 15.4MB/s] 3%|3 | 26.0M/812M [00:02<00:55, 14.9MB/s] 3%|3 | 28.0M/812M [00:02<00:58, 14.0MB/s] 4%|3 | 30.0M/812M [00:03<01:54, 7.17MB/s] 4%|3 | 32.0M/812M [00:03<01:42, 8.00MB/s] 4%|4 | 34.0M/812M [00:03<01:43, 7.90MB/s] 4%|4 | 35.0M/812M [00:03<02:06, 6.43MB/s] 4%|4 | 36.0M/812M [00:04<02:28, 5.48MB/s] 5%|4 | 37.0M/812M [00:04<02:16, 5.97MB/s] 5%|4 | 39.0M/812M [00:04<01:47, 7.57MB/s] 5%|5 | 41.0M/812M [00:04<01:26, 9.36MB/s] 5%|5 | 43.0M/812M [00:04<01:14, 10.9MB/s] 6%|5 | 45.0M/812M [00:04<01:06, 12.1MB/s] 6%|5 | 47.0M/812M [00:05<01:01, 13.1MB/s] 6%|6 | 49.0M/812M [00:05<00:56, 14.1MB/s] 6%|6 | 51.0M/812M [00:05<00:54, 14.7MB/s] 7%|6 | 53.0M/812M [00:05<00:52, 15.0MB/s] 7%|6 | 55.0M/812M [00:05<01:09, 11.4MB/s] 7%|7 | 57.0M/812M [00:05<01:02, 12.7MB/s] 7%|7 | 60.0M/812M [00:06<00:50, 15.6MB/s] 8%|7 | 63.0M/812M [00:06<00:41, 19.0MB/s] 8%|8 | 66.0M/812M [00:06<00:45, 17.4MB/s] 8%|8 | 68.0M/812M [00:06<01:02, 12.4MB/s] 9%|8 | 70.0M/812M [00:07<01:27, 8.84MB/s] 9%|9 | 74.0M/812M [00:07<01:10, 10.9MB/s] 9%|9 | 77.0M/812M [00:07<01:07, 11.4MB/s] 10%|9 | 81.0M/812M [00:07<00:57, 13.4MB/s] 10%|# | 83.0M/812M [00:08<01:51, 6.87MB/s] 10%|# | 85.0M/812M [00:08<01:37, 7.85MB/s] 11%|# | 87.0M/812M [00:08<01:26, 8.79MB/s] 11%|# | 89.0M/812M [00:09<01:19, 9.59MB/s] 11%|#1 | 91.0M/812M [00:09<02:11, 5.77MB/s] 11%|#1 | 93.0M/812M [00:10<01:51, 6.79MB/s] 12%|#1 | 95.0M/812M [00:10<01:37, 7.68MB/s] 12%|#1 | 97.0M/812M [00:10<01:49, 6.83MB/s] 12%|#2 | 98.0M/812M [00:10<02:13, 5.61MB/s] 12%|#2 | 99.0M/812M [00:11<02:08, 5.81MB/s] 12%|#2 | 100M/812M [00:11<01:58, 6.31MB/s] 12%|#2 | 101M/812M [00:11<01:46, 6.97MB/s] 13%|#2 | 103M/812M [00:11<01:24, 8.79MB/s] 13%|#2 | 105M/812M [00:11<01:09, 10.7MB/s] 13%|#3 | 107M/812M [00:11<00:57, 12.9MB/s] 14%|#3 | 110M/812M [00:11<00:44, 16.6MB/s] 14%|#3 | 113M/812M [00:11<00:36, 20.1MB/s] 14%|#4 | 116M/812M [00:12<00:54, 13.3MB/s] 15%|#4 | 120M/812M [00:12<00:39, 18.3MB/s] 15%|#5 | 123M/812M [00:13<01:35, 7.55MB/s] 15%|#5 | 125M/812M [00:13<01:21, 8.80MB/s] 16%|#5 | 127M/812M [00:13<01:12, 9.86MB/s] 16%|#5 | 129M/812M [00:13<01:24, 8.44MB/s] 16%|#6 | 131M/812M [00:14<01:50, 6.44MB/s] 16%|#6 | 133M/812M [00:14<01:32, 7.73MB/s] 17%|#6 | 135M/812M [00:14<01:18, 9.05MB/s] 17%|#6 | 137M/812M [00:14<01:06, 10.6MB/s] 17%|#7 | 139M/812M [00:15<01:07, 10.4MB/s] 17%|#7 | 141M/812M [00:15<01:01, 11.5MB/s] 18%|#7 | 143M/812M [00:15<00:56, 12.5MB/s] 18%|#7 | 145M/812M [00:16<02:26, 4.76MB/s] 18%|#8 | 147M/812M [00:16<01:55, 6.02MB/s] 18%|#8 | 149M/812M [00:16<01:33, 7.41MB/s] 19%|#8 | 151M/812M [00:16<01:18, 8.83MB/s] 19%|#8 | 153M/812M [00:17<02:31, 4.56MB/s] 19%|#9 | 155M/812M [00:17<01:59, 5.76MB/s] 19%|#9 | 157M/812M [00:18<01:36, 7.12MB/s] 20%|#9 | 159M/812M [00:18<01:22, 8.33MB/s] 20%|#9 | 161M/812M [00:18<01:28, 7.68MB/s] 20%|## | 163M/812M [00:18<01:37, 6.98MB/s] 20%|## | 164M/812M [00:19<02:06, 5.37MB/s] 20%|## | 165M/812M [00:19<01:58, 5.74MB/s] 20%|## | 166M/812M [00:19<01:47, 6.29MB/s] 21%|## | 167M/812M [00:19<02:21, 4.79MB/s] 21%|## | 168M/812M [00:20<02:31, 4.44MB/s] 21%|## | 169M/812M [00:20<02:13, 5.04MB/s] 21%|## | 170M/812M [00:20<01:54, 5.86MB/s] 21%|##1 | 172M/812M [00:20<01:26, 7.77MB/s] 21%|##1 | 174M/812M [00:20<01:05, 10.2MB/s] 22%|##1 | 177M/812M [00:20<00:48, 13.7MB/s] 22%|##2 | 180M/812M [00:20<00:37, 17.6MB/s] 23%|##2 | 184M/812M [00:21<00:30, 21.8MB/s] 23%|##3 | 187M/812M [00:21<00:56, 11.5MB/s] 23%|##3 | 189M/812M [00:21<01:06, 9.84MB/s] 24%|##3 | 193M/812M [00:22<00:49, 13.0MB/s] 24%|##4 | 195M/812M [00:22<01:06, 9.80MB/s] 24%|##4 | 197M/812M [00:22<01:18, 8.22MB/s] 25%|##4 | 201M/812M [00:23<00:52, 12.2MB/s] 25%|##4 | 203M/812M [00:23<01:11, 8.91MB/s] 25%|##5 | 207M/812M [00:23<00:49, 12.9MB/s] 26%|##5 | 210M/812M [00:24<01:10, 8.99MB/s] 26%|##6 | 214M/812M [00:24<00:50, 12.5MB/s] 27%|##6 | 217M/812M [00:25<01:14, 8.35MB/s] 27%|##7 | 220M/812M [00:25<00:59, 10.4MB/s] 27%|##7 | 223M/812M [00:25<00:48, 12.7MB/s] 28%|##7 | 226M/812M [00:25<00:54, 11.3MB/s] 28%|##8 | 228M/812M [00:25<01:08, 9.00MB/s] 28%|##8 | 230M/812M [00:26<00:59, 10.2MB/s] 29%|##8 | 232M/812M [00:26<00:54, 11.2MB/s] 29%|##8 | 234M/812M [00:26<00:49, 12.2MB/s] 29%|##9 | 236M/812M [00:26<00:47, 12.8MB/s] 29%|##9 | 238M/812M [00:26<00:44, 13.5MB/s] 30%|##9 | 240M/812M [00:26<00:42, 14.2MB/s] 30%|##9 | 242M/812M [00:26<00:40, 14.9MB/s] 30%|### | 244M/812M [00:27<00:39, 15.2MB/s] 30%|### | 246M/812M [00:27<00:38, 15.4MB/s] 31%|### | 248M/812M [00:27<00:37, 15.6MB/s] 31%|### | 250M/812M [00:27<00:38, 15.3MB/s] 31%|###1 | 252M/812M [00:27<00:38, 15.2MB/s] 31%|###1 | 254M/812M [00:27<00:37, 15.7MB/s] 32%|###1 | 257M/812M [00:28<00:46, 12.6MB/s] 32%|###2 | 260M/812M [00:28<00:36, 15.7MB/s] 32%|###2 | 263M/812M [00:28<00:30, 18.8MB/s] 33%|###2 | 266M/812M [00:28<00:36, 15.9MB/s] 33%|###2 | 268M/812M [00:28<00:35, 16.1MB/s] 33%|###3 | 270M/812M [00:28<00:34, 16.6MB/s] 33%|###3 | 272M/812M [00:28<00:34, 16.4MB/s] 34%|###3 | 275M/812M [00:28<00:29, 19.2MB/s] 34%|###4 | 278M/812M [00:29<00:25, 22.1MB/s] 35%|###4 | 281M/812M [00:29<00:32, 17.1MB/s] 35%|###5 | 285M/812M [00:29<00:24, 22.1MB/s] 36%|###5 | 289M/812M [00:29<00:33, 16.2MB/s] 36%|###6 | 293M/812M [00:29<00:26, 20.4MB/s] 37%|###6 | 297M/812M [00:30<00:35, 15.3MB/s] 37%|###7 | 301M/812M [00:30<00:27, 19.1MB/s] 38%|###7 | 305M/812M [00:30<00:34, 15.5MB/s] 38%|###8 | 309M/812M [00:30<00:28, 18.8MB/s] 39%|###8 | 313M/812M [00:31<00:33, 15.7MB/s] 39%|###8 | 316M/812M [00:31<00:31, 16.4MB/s] 39%|###9 | 319M/812M [00:31<00:29, 17.3MB/s] 40%|###9 | 322M/812M [00:31<00:29, 17.4MB/s] 40%|#### | 326M/812M [00:31<00:23, 21.5MB/s] 41%|#### | 329M/812M [00:32<00:31, 16.0MB/s] 41%|####1 | 333M/812M [00:32<00:24, 20.2MB/s] 41%|####1 | 337M/812M [00:32<00:35, 14.1MB/s] 42%|####1 | 341M/812M [00:32<00:27, 17.8MB/s] 43%|####2 | 346M/812M [00:33<00:21, 22.8MB/s] 43%|####3 | 350M/812M [00:33<00:18, 26.3MB/s] 44%|####3 | 354M/812M [00:33<00:18, 25.9MB/s] 44%|####4 | 358M/812M [00:33<00:16, 28.2MB/s] 45%|####4 | 362M/812M [00:33<00:15, 31.3MB/s] 45%|####5 | 366M/812M [00:33<00:13, 33.8MB/s] 46%|####5 | 370M/812M [00:33<00:15, 29.5MB/s] 46%|####6 | 374M/812M [00:33<00:14, 31.2MB/s] 47%|####6 | 378M/812M [00:34<00:13, 32.5MB/s] 47%|####7 | 382M/812M [00:34<00:14, 31.2MB/s] 48%|####7 | 386M/812M [00:34<00:14, 29.9MB/s] 48%|####7 | 389M/812M [00:34<00:17, 26.1MB/s] 48%|####8 | 392M/812M [00:34<00:18, 23.9MB/s] 49%|####8 | 395M/812M [00:34<00:19, 22.9MB/s] 49%|####9 | 398M/812M [00:34<00:18, 23.9MB/s] 49%|####9 | 401M/812M [00:35<00:17, 24.8MB/s] 50%|####9 | 404M/812M [00:35<00:16, 26.4MB/s] 50%|##### | 408M/812M [00:35<00:13, 30.3MB/s] 51%|##### | 412M/812M [00:35<00:13, 32.1MB/s] 51%|#####1 | 416M/812M [00:35<00:11, 34.7MB/s] 52%|#####1 | 420M/812M [00:35<00:11, 36.7MB/s] 52%|#####2 | 424M/812M [00:35<00:10, 38.1MB/s] 53%|#####2 | 428M/812M [00:35<00:14, 27.2MB/s] 53%|#####3 | 432M/812M [00:36<00:13, 30.4MB/s] 54%|#####3 | 436M/812M [00:36<00:20, 19.6MB/s] 54%|#####4 | 440M/812M [00:36<00:16, 23.0MB/s] 55%|#####4 | 443M/812M [00:36<00:23, 16.5MB/s] 55%|#####5 | 447M/812M [00:37<00:19, 20.1MB/s] 56%|#####5 | 451M/812M [00:37<00:16, 23.2MB/s] 56%|#####6 | 455M/812M [00:37<00:14, 25.9MB/s] 57%|#####6 | 459M/812M [00:37<00:17, 21.0MB/s] 57%|#####6 | 462M/812M [00:37<00:16, 22.0MB/s] 57%|#####7 | 465M/812M [00:38<00:37, 9.58MB/s] 58%|#####7 | 469M/812M [00:38<00:28, 12.6MB/s] 58%|#####8 | 473M/812M [00:38<00:21, 16.2MB/s] 59%|#####8 | 478M/812M [00:38<00:16, 21.5MB/s] 59%|#####9 | 482M/812M [00:39<00:17, 20.3MB/s] 60%|#####9 | 486M/812M [00:39<00:14, 24.0MB/s] 60%|###### | 490M/812M [00:39<00:12, 27.5MB/s] 61%|###### | 494M/812M [00:39<00:11, 29.6MB/s] 61%|######1 | 498M/812M [00:39<00:12, 27.1MB/s] 62%|######1 | 502M/812M [00:39<00:10, 30.3MB/s] 62%|######2 | 506M/812M [00:39<00:10, 31.9MB/s] 63%|######2 | 510M/812M [00:39<00:09, 34.3MB/s] 63%|######3 | 514M/812M [00:40<00:18, 17.1MB/s] 64%|######3 | 517M/812M [00:40<00:18, 16.7MB/s] 64%|######4 | 520M/812M [00:40<00:17, 17.2MB/s] 64%|######4 | 523M/812M [00:40<00:15, 19.6MB/s] 65%|######4 | 527M/812M [00:41<00:12, 23.2MB/s] 65%|######5 | 531M/812M [00:41<00:11, 26.2MB/s] 66%|######5 | 535M/812M [00:41<00:09, 29.8MB/s] 66%|######6 | 539M/812M [00:41<00:13, 22.0MB/s] 67%|######6 | 543M/812M [00:41<00:10, 25.7MB/s] 67%|######7 | 547M/812M [00:42<00:14, 18.6MB/s] 68%|######7 | 551M/812M [00:42<00:12, 22.4MB/s] 68%|######8 | 554M/812M [00:42<00:18, 14.9MB/s] 69%|######8 | 558M/812M [00:42<00:14, 18.7MB/s] 69%|######9 | 562M/812M [00:42<00:11, 22.2MB/s] 70%|######9 | 566M/812M [00:42<00:10, 25.7MB/s] 70%|####### | 570M/812M [00:43<00:10, 23.4MB/s] 71%|####### | 574M/812M [00:43<00:09, 25.9MB/s] 71%|#######1 | 578M/812M [00:43<00:08, 29.3MB/s] 72%|#######1 | 582M/812M [00:43<00:08, 30.0MB/s] 72%|#######2 | 586M/812M [00:43<00:08, 29.5MB/s] 73%|#######2 | 590M/812M [00:43<00:08, 25.9MB/s] 73%|#######3 | 593M/812M [00:43<00:09, 23.3MB/s] 73%|#######3 | 596M/812M [00:44<00:10, 21.8MB/s] 74%|#######3 | 599M/812M [00:44<00:09, 22.4MB/s] 74%|#######4 | 603M/812M [00:44<00:08, 25.3MB/s] 75%|#######4 | 607M/812M [00:44<00:07, 28.1MB/s] 75%|#######5 | 610M/812M [00:45<00:15, 13.4MB/s] 76%|#######5 | 614M/812M [00:45<00:12, 16.9MB/s] 76%|#######5 | 617M/812M [00:45<00:15, 13.5MB/s] 76%|#######6 | 620M/812M [00:45<00:13, 14.6MB/s] 77%|#######6 | 622M/812M [00:45<00:13, 14.9MB/s] 77%|#######6 | 624M/812M [00:46<00:13, 14.9MB/s] 77%|#######7 | 626M/812M [00:46<00:13, 14.8MB/s] 77%|#######7 | 628M/812M [00:46<00:13, 14.1MB/s] 78%|#######7 | 630M/812M [00:46<00:15, 11.9MB/s] 78%|#######7 | 632M/812M [00:47<00:31, 5.99MB/s] 78%|#######7 | 633M/812M [00:47<00:31, 6.02MB/s] 78%|#######8 | 634M/812M [00:47<00:28, 6.55MB/s] 78%|#######8 | 636M/812M [00:47<00:23, 7.87MB/s] 79%|#######8 | 638M/812M [00:47<00:18, 9.95MB/s] 79%|#######8 | 641M/812M [00:48<00:13, 13.5MB/s] 79%|#######9 | 644M/812M [00:48<00:10, 17.2MB/s] 80%|#######9 | 648M/812M [00:48<00:07, 22.5MB/s] 80%|######## | 652M/812M [00:48<00:06, 26.3MB/s] 81%|######## | 657M/812M [00:48<00:07, 22.0MB/s] 81%|########1 | 661M/812M [00:48<00:06, 25.9MB/s] 82%|########1 | 665M/812M [00:49<00:07, 20.4MB/s] 82%|########2 | 669M/812M [00:49<00:06, 23.6MB/s] 83%|########2 | 673M/812M [00:49<00:09, 15.2MB/s] 83%|########3 | 677M/812M [00:49<00:07, 18.4MB/s] 84%|########3 | 681M/812M [00:49<00:07, 19.1MB/s] 84%|########4 | 684M/812M [00:50<00:06, 21.1MB/s] 85%|########4 | 687M/812M [00:50<00:05, 22.4MB/s] 85%|########4 | 690M/812M [00:50<00:07, 17.5MB/s] 85%|########5 | 693M/812M [00:50<00:06, 18.7MB/s] 86%|########5 | 696M/812M [00:50<00:05, 21.2MB/s] 86%|########6 | 699M/812M [00:50<00:05, 23.4MB/s] 87%|########6 | 703M/812M [00:50<00:04, 27.7MB/s] 87%|########6 | 706M/812M [00:51<00:04, 23.6MB/s] 87%|########7 | 710M/812M [00:51<00:03, 27.8MB/s] 88%|########7 | 714M/812M [00:51<00:04, 21.7MB/s] 88%|########8 | 718M/812M [00:51<00:03, 25.7MB/s] 89%|########8 | 721M/812M [00:51<00:04, 23.4MB/s] 89%|########9 | 726M/812M [00:51<00:03, 28.6MB/s] 90%|########9 | 730M/812M [00:52<00:04, 19.2MB/s] 90%|######### | 733M/812M [00:52<00:04, 19.0MB/s] 91%|######### | 736M/812M [00:52<00:03, 20.1MB/s] 91%|######### | 739M/812M [00:52<00:04, 17.8MB/s] 91%|#########1| 743M/812M [00:52<00:03, 22.1MB/s] 92%|#########1| 747M/812M [00:52<00:02, 26.1MB/s] 92%|#########2| 751M/812M [00:53<00:02, 29.7MB/s] 93%|#########2| 755M/812M [00:53<00:01, 32.6MB/s] 93%|#########3| 759M/812M [00:53<00:01, 35.0MB/s] 94%|#########3| 763M/812M [00:53<00:01, 32.2MB/s] 94%|#########4| 767M/812M [00:53<00:01, 34.6MB/s] 95%|#########4| 771M/812M [00:53<00:01, 28.3MB/s] 96%|#########5| 776M/812M [00:53<00:01, 32.8MB/s] 96%|#########6| 780M/812M [00:54<00:01, 29.3MB/s] 97%|#########6| 785M/812M [00:54<00:00, 33.5MB/s] 97%|#########7| 790M/812M [00:54<00:00, 37.0MB/s] 98%|#########7| 795M/812M [00:54<00:00, 38.8MB/s] 99%|#########8| 800M/812M [00:54<00:00, 41.0MB/s] 99%|#########9| 805M/812M [00:54<00:00, 42.8MB/s] 100%|#########9| 810M/812M [00:54<00:00, 41.9MB/s] 100%|##########| 812M/812M [00:54<00:00, 15.5MB/s]
import zipfile
try:
with zipfile.ZipFile('train.zip', 'r') as zip_ref:
zip_ref.extractall('./')
except:
with zipfile.ZipFile('dogs-vs-cats.zip', 'r') as zip_ref:
zip_ref.extractall('./')
with zipfile.ZipFile('train.zip', 'r') as zip_ref:
zip_ref.extractall('./')
# 이미지셋 분류 저장 경로 지정
import os, shutil, pathlib
from tensorflow.keras.utils import image_dataset_from_directory
original_dir = pathlib.Path("train")
new_base_dir = pathlib.Path("cats_vs_dogs_small")
# 이미지셋 분류 저장
def make_subset(subset_name, start_index, end_index):
for category in ("cat", "dog"):
dir = new_base_dir / subset_name / category
os.makedirs(dir)
fnames = [f"{category}.{i}.jpg" for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=original_dir / fname,
dst=dir / fname)
make_subset("train", start_index=0, end_index=1000)
make_subset("validation", start_index=1000, end_index=1500)
make_subset("test", start_index=1500, end_index=2500)
# 데이터셋 적재
train_dataset = image_dataset_from_directory(
new_base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / "test",
image_size=(180, 180),
batch_size=32)
Found 2000 files belonging to 2 classes. Found 1000 files belonging to 2 classes. Found 2000 files belonging to 2 classes.
모델 구현
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
# 입력층
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
# 하나의 Conv2D 은닉층
x = layers.Conv2D(filters=32, kernel_size=5, use_bias=False)(x)
# SeparableConv2D, BatchNormalization, MaxPooling2D 층으로 구성된 블록 쌓기
# 잔차 연결 활용
for size in [32, 64, 128, 256, 512]: # 필터 수
residual = x
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# 잔차 연결
residual = layers.Conv2D(
size, 1, strides=2, padding="same", use_bias=False)(residual)
x = layers.add([x, residual])
# 마지막 은닉층은 GlobalAveragePooling2D과 Dropout
x = layers.GlobalAveragePooling2D()(x) # flatten 역할 수행(채널 별 평균값으로 구성)
x = layers.Dropout(0.5)(x)
# 출력층
outputs = layers.Dense(1, activation="sigmoid")(x)
# 모델 지정
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) [(None, 180, 180, 3) 0
__________________________________________________________________________________________________
sequential (Sequential) (None, 180, 180, 3) 0 input_5[0][0]
__________________________________________________________________________________________________
rescaling_1 (Rescaling) (None, 180, 180, 3) 0 sequential[0][0]
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 176, 176, 32) 2400 rescaling_1[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 176, 176, 32) 128 conv2d_19[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 176, 176, 32) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
separable_conv2d (SeparableConv (None, 176, 176, 32) 1312 activation[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 176, 176, 32) 128 separable_conv2d[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 176, 176, 32) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
separable_conv2d_1 (SeparableCo (None, 176, 176, 32) 1312 activation_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 88, 88, 32) 0 separable_conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_20 (Conv2D) (None, 88, 88, 32) 1024 conv2d_19[0][0]
__________________________________________________________________________________________________
add_17 (Add) (None, 88, 88, 32) 0 max_pooling2d_3[0][0]
conv2d_20[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 88, 88, 32) 128 add_17[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 88, 88, 32) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
separable_conv2d_2 (SeparableCo (None, 88, 88, 64) 2336 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 88, 88, 64) 256 separable_conv2d_2[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 88, 88, 64) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
separable_conv2d_3 (SeparableCo (None, 88, 88, 64) 4672 activation_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_4 (MaxPooling2D) (None, 44, 44, 64) 0 separable_conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_21 (Conv2D) (None, 44, 44, 64) 2048 add_17[0][0]
__________________________________________________________________________________________________
add_18 (Add) (None, 44, 44, 64) 0 max_pooling2d_4[0][0]
conv2d_21[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 44, 44, 64) 256 add_18[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 44, 44, 64) 0 batch_normalization_8[0][0]
__________________________________________________________________________________________________
separable_conv2d_4 (SeparableCo (None, 44, 44, 128) 8768 activation_4[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 44, 44, 128) 512 separable_conv2d_4[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 44, 44, 128) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
separable_conv2d_5 (SeparableCo (None, 44, 44, 128) 17536 activation_5[0][0]
__________________________________________________________________________________________________
max_pooling2d_5 (MaxPooling2D) (None, 22, 22, 128) 0 separable_conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_22 (Conv2D) (None, 22, 22, 128) 8192 add_18[0][0]
__________________________________________________________________________________________________
add_19 (Add) (None, 22, 22, 128) 0 max_pooling2d_5[0][0]
conv2d_22[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 22, 22, 128) 512 add_19[0][0]
__________________________________________________________________________________________________
activation_6 (Activation) (None, 22, 22, 128) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
separable_conv2d_6 (SeparableCo (None, 22, 22, 256) 33920 activation_6[0][0]
__________________________________________________________________________________________________
batch_normalization_11 (BatchNo (None, 22, 22, 256) 1024 separable_conv2d_6[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 22, 22, 256) 0 batch_normalization_11[0][0]
__________________________________________________________________________________________________
separable_conv2d_7 (SeparableCo (None, 22, 22, 256) 67840 activation_7[0][0]
__________________________________________________________________________________________________
max_pooling2d_6 (MaxPooling2D) (None, 11, 11, 256) 0 separable_conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_23 (Conv2D) (None, 11, 11, 256) 32768 add_19[0][0]
__________________________________________________________________________________________________
add_20 (Add) (None, 11, 11, 256) 0 max_pooling2d_6[0][0]
conv2d_23[0][0]
__________________________________________________________________________________________________
batch_normalization_12 (BatchNo (None, 11, 11, 256) 1024 add_20[0][0]
__________________________________________________________________________________________________
activation_8 (Activation) (None, 11, 11, 256) 0 batch_normalization_12[0][0]
__________________________________________________________________________________________________
separable_conv2d_8 (SeparableCo (None, 11, 11, 512) 133376 activation_8[0][0]
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 11, 11, 512) 2048 separable_conv2d_8[0][0]
__________________________________________________________________________________________________
activation_9 (Activation) (None, 11, 11, 512) 0 batch_normalization_13[0][0]
__________________________________________________________________________________________________
separable_conv2d_9 (SeparableCo (None, 11, 11, 512) 266752 activation_9[0][0]
__________________________________________________________________________________________________
max_pooling2d_7 (MaxPooling2D) (None, 6, 6, 512) 0 separable_conv2d_9[0][0]
__________________________________________________________________________________________________
conv2d_24 (Conv2D) (None, 6, 6, 512) 131072 add_20[0][0]
__________________________________________________________________________________________________
add_21 (Add) (None, 6, 6, 512) 0 max_pooling2d_7[0][0]
conv2d_24[0][0]
__________________________________________________________________________________________________
global_average_pooling2d_1 (Glo (None, 512) 0 add_21[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 512) 0 global_average_pooling2d_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 513 dropout[0][0]
==================================================================================================
Total params: 721,857
Trainable params: 718,849
Non-trainable params: 3,008
__________________________________________________________________________________________________
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="mini_xception.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=100,
validation_data=validation_dataset,
callbacks=callbacks)
Epoch 1/100 63/63 [==============================] - 32s 310ms/step - loss: 0.7129 - accuracy: 0.5650 - val_loss: 0.6934 - val_accuracy: 0.5000 Epoch 2/100
C:\Users\gslee\anaconda3\lib\site-packages\keras\utils\generic_utils.py:494: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument.
warnings.warn('Custom mask layers require a config and must override '
63/63 [==============================] - 19s 297ms/step - loss: 0.6554 - accuracy: 0.6060 - val_loss: 0.6946 - val_accuracy: 0.5000 Epoch 3/100 63/63 [==============================] - 19s 304ms/step - loss: 0.6460 - accuracy: 0.6355 - val_loss: 0.6951 - val_accuracy: 0.5000 Epoch 4/100 63/63 [==============================] - 19s 304ms/step - loss: 0.6223 - accuracy: 0.6575 - val_loss: 0.7169 - val_accuracy: 0.5000 Epoch 5/100 63/63 [==============================] - 19s 307ms/step - loss: 0.6103 - accuracy: 0.6760 - val_loss: 0.7466 - val_accuracy: 0.5000 Epoch 6/100 63/63 [==============================] - 19s 300ms/step - loss: 0.5881 - accuracy: 0.6965 - val_loss: 0.7633 - val_accuracy: 0.5000 Epoch 7/100 63/63 [==============================] - 19s 299ms/step - loss: 0.5711 - accuracy: 0.7045 - val_loss: 0.8972 - val_accuracy: 0.5000 Epoch 8/100 63/63 [==============================] - 19s 299ms/step - loss: 0.5621 - accuracy: 0.7125 - val_loss: 0.7046 - val_accuracy: 0.5520 Epoch 9/100 63/63 [==============================] - 19s 298ms/step - loss: 0.5559 - accuracy: 0.7155 - val_loss: 1.0341 - val_accuracy: 0.5340 Epoch 10/100 63/63 [==============================] - 19s 301ms/step - loss: 0.5153 - accuracy: 0.7515 - val_loss: 0.5501 - val_accuracy: 0.7080 Epoch 11/100 63/63 [==============================] - 19s 304ms/step - loss: 0.5170 - accuracy: 0.7450 - val_loss: 0.6464 - val_accuracy: 0.6460 Epoch 12/100 63/63 [==============================] - 19s 298ms/step - loss: 0.5260 - accuracy: 0.7520 - val_loss: 0.7382 - val_accuracy: 0.6200 Epoch 13/100 63/63 [==============================] - 19s 303ms/step - loss: 0.4875 - accuracy: 0.7715 - val_loss: 0.8880 - val_accuracy: 0.5800 Epoch 14/100 63/63 [==============================] - 19s 301ms/step - loss: 0.4555 - accuracy: 0.7880 - val_loss: 0.9598 - val_accuracy: 0.6070 Epoch 15/100 63/63 [==============================] - 20s 310ms/step - loss: 0.4575 - accuracy: 0.7800 - val_loss: 0.5213 - val_accuracy: 0.7610 Epoch 16/100 63/63 [==============================] - 19s 301ms/step - loss: 0.4592 - accuracy: 0.7900 - val_loss: 0.6380 - val_accuracy: 0.6850 Epoch 17/100 63/63 [==============================] - 19s 303ms/step - loss: 0.4333 - accuracy: 0.8015 - val_loss: 0.7936 - val_accuracy: 0.6900 Epoch 18/100 63/63 [==============================] - 19s 301ms/step - loss: 0.4172 - accuracy: 0.8145 - val_loss: 0.5306 - val_accuracy: 0.7480 Epoch 19/100 63/63 [==============================] - 19s 298ms/step - loss: 0.4157 - accuracy: 0.8100 - val_loss: 0.4632 - val_accuracy: 0.7750 Epoch 20/100 63/63 [==============================] - 19s 302ms/step - loss: 0.4120 - accuracy: 0.8035 - val_loss: 0.7216 - val_accuracy: 0.7040 Epoch 21/100 63/63 [==============================] - 19s 303ms/step - loss: 0.3788 - accuracy: 0.8330 - val_loss: 0.7511 - val_accuracy: 0.7210 Epoch 22/100 63/63 [==============================] - 19s 298ms/step - loss: 0.3869 - accuracy: 0.8350 - val_loss: 0.6418 - val_accuracy: 0.7690 Epoch 23/100 63/63 [==============================] - 19s 306ms/step - loss: 0.3816 - accuracy: 0.8275 - val_loss: 0.6153 - val_accuracy: 0.7330 Epoch 24/100 63/63 [==============================] - 19s 301ms/step - loss: 0.3535 - accuracy: 0.8505 - val_loss: 0.7222 - val_accuracy: 0.7490 Epoch 25/100 63/63 [==============================] - 19s 308ms/step - loss: 0.3350 - accuracy: 0.8500 - val_loss: 0.8011 - val_accuracy: 0.7400 Epoch 26/100 63/63 [==============================] - 19s 303ms/step - loss: 0.3388 - accuracy: 0.8575 - val_loss: 0.6957 - val_accuracy: 0.6610 Epoch 27/100 63/63 [==============================] - 20s 309ms/step - loss: 0.3401 - accuracy: 0.8440 - val_loss: 0.6324 - val_accuracy: 0.7670 Epoch 28/100 63/63 [==============================] - 20s 311ms/step - loss: 0.3171 - accuracy: 0.8735 - val_loss: 0.5255 - val_accuracy: 0.8070 Epoch 29/100 63/63 [==============================] - 19s 299ms/step - loss: 0.3008 - accuracy: 0.8600 - val_loss: 0.5955 - val_accuracy: 0.7930 Epoch 30/100 63/63 [==============================] - 19s 304ms/step - loss: 0.3283 - accuracy: 0.8535 - val_loss: 0.4400 - val_accuracy: 0.8030 Epoch 31/100 63/63 [==============================] - 19s 298ms/step - loss: 0.2950 - accuracy: 0.8755 - val_loss: 1.2714 - val_accuracy: 0.6500 Epoch 32/100 63/63 [==============================] - 19s 300ms/step - loss: 0.2868 - accuracy: 0.8780 - val_loss: 1.4175 - val_accuracy: 0.6620 Epoch 33/100 63/63 [==============================] - 19s 301ms/step - loss: 0.2983 - accuracy: 0.8740 - val_loss: 0.4471 - val_accuracy: 0.8210 Epoch 34/100 63/63 [==============================] - 19s 306ms/step - loss: 0.2807 - accuracy: 0.8770 - val_loss: 0.9578 - val_accuracy: 0.7620 Epoch 35/100 63/63 [==============================] - 19s 309ms/step - loss: 0.2694 - accuracy: 0.8850 - val_loss: 0.4311 - val_accuracy: 0.8500 Epoch 36/100 63/63 [==============================] - 19s 307ms/step - loss: 0.2759 - accuracy: 0.8830 - val_loss: 1.7197 - val_accuracy: 0.6460 Epoch 37/100 63/63 [==============================] - 19s 298ms/step - loss: 0.2675 - accuracy: 0.8855 - val_loss: 1.2854 - val_accuracy: 0.6600 Epoch 38/100 63/63 [==============================] - 19s 299ms/step - loss: 0.2604 - accuracy: 0.8960 - val_loss: 1.4749 - val_accuracy: 0.6000 Epoch 39/100 63/63 [==============================] - 19s 297ms/step - loss: 0.2517 - accuracy: 0.8890 - val_loss: 0.5740 - val_accuracy: 0.7980 Epoch 40/100 63/63 [==============================] - 19s 297ms/step - loss: 0.2540 - accuracy: 0.8985 - val_loss: 0.4637 - val_accuracy: 0.8220 Epoch 41/100 63/63 [==============================] - 19s 299ms/step - loss: 0.2475 - accuracy: 0.8930 - val_loss: 0.5131 - val_accuracy: 0.8330 Epoch 42/100 63/63 [==============================] - 19s 301ms/step - loss: 0.2567 - accuracy: 0.8870 - val_loss: 0.4671 - val_accuracy: 0.7900 Epoch 43/100 63/63 [==============================] - 19s 300ms/step - loss: 0.2445 - accuracy: 0.9025 - val_loss: 0.4743 - val_accuracy: 0.8270 Epoch 44/100 63/63 [==============================] - 19s 299ms/step - loss: 0.2091 - accuracy: 0.9165 - val_loss: 0.5560 - val_accuracy: 0.7940 Epoch 45/100 63/63 [==============================] - 19s 300ms/step - loss: 0.2424 - accuracy: 0.8995 - val_loss: 0.4657 - val_accuracy: 0.8050 Epoch 46/100 63/63 [==============================] - 19s 299ms/step - loss: 0.2272 - accuracy: 0.9070 - val_loss: 0.3562 - val_accuracy: 0.8420 Epoch 47/100 63/63 [==============================] - 19s 298ms/step - loss: 0.2073 - accuracy: 0.9095 - val_loss: 0.5141 - val_accuracy: 0.8060 Epoch 48/100 63/63 [==============================] - 19s 298ms/step - loss: 0.2014 - accuracy: 0.9155 - val_loss: 0.3395 - val_accuracy: 0.8540 Epoch 49/100 63/63 [==============================] - 19s 295ms/step - loss: 0.2110 - accuracy: 0.9155 - val_loss: 0.4573 - val_accuracy: 0.8480 Epoch 50/100 63/63 [==============================] - 19s 296ms/step - loss: 0.2056 - accuracy: 0.9175 - val_loss: 0.4650 - val_accuracy: 0.8490 Epoch 51/100 63/63 [==============================] - 19s 296ms/step - loss: 0.2066 - accuracy: 0.9110 - val_loss: 0.6371 - val_accuracy: 0.7700 Epoch 52/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1969 - accuracy: 0.9230 - val_loss: 0.5021 - val_accuracy: 0.8220 Epoch 53/100 63/63 [==============================] - 19s 300ms/step - loss: 0.2047 - accuracy: 0.9150 - val_loss: 0.5595 - val_accuracy: 0.7890 Epoch 54/100 63/63 [==============================] - 19s 299ms/step - loss: 0.2010 - accuracy: 0.9175 - val_loss: 0.3788 - val_accuracy: 0.8630 Epoch 55/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1921 - accuracy: 0.9210 - val_loss: 0.3993 - val_accuracy: 0.8410 Epoch 56/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1635 - accuracy: 0.9320 - val_loss: 0.4425 - val_accuracy: 0.8500 Epoch 57/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1878 - accuracy: 0.9235 - val_loss: 0.7252 - val_accuracy: 0.8080 Epoch 58/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1762 - accuracy: 0.9260 - val_loss: 0.4475 - val_accuracy: 0.8640 Epoch 59/100 63/63 [==============================] - 19s 299ms/step - loss: 0.1796 - accuracy: 0.9195 - val_loss: 0.3719 - val_accuracy: 0.8630 Epoch 60/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1767 - accuracy: 0.9245 - val_loss: 0.3220 - val_accuracy: 0.8700 Epoch 61/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1755 - accuracy: 0.9295 - val_loss: 0.4743 - val_accuracy: 0.8470 Epoch 62/100 63/63 [==============================] - 19s 296ms/step - loss: 0.1664 - accuracy: 0.9280 - val_loss: 0.4888 - val_accuracy: 0.8340 Epoch 63/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1621 - accuracy: 0.9370 - val_loss: 0.5812 - val_accuracy: 0.7950 Epoch 64/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1628 - accuracy: 0.9360 - val_loss: 1.2086 - val_accuracy: 0.7210 Epoch 65/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1589 - accuracy: 0.9350 - val_loss: 0.5746 - val_accuracy: 0.8360 Epoch 66/100 63/63 [==============================] - 19s 293ms/step - loss: 0.1534 - accuracy: 0.9395 - val_loss: 0.4577 - val_accuracy: 0.8480 Epoch 67/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1404 - accuracy: 0.9495 - val_loss: 1.6608 - val_accuracy: 0.6820 Epoch 68/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1406 - accuracy: 0.9435 - val_loss: 0.4108 - val_accuracy: 0.8510 Epoch 69/100 63/63 [==============================] - 19s 303ms/step - loss: 0.1431 - accuracy: 0.9430 - val_loss: 0.5181 - val_accuracy: 0.8550 Epoch 70/100 63/63 [==============================] - 19s 301ms/step - loss: 0.1616 - accuracy: 0.9340 - val_loss: 0.3000 - val_accuracy: 0.8740 Epoch 71/100 63/63 [==============================] - 19s 294ms/step - loss: 0.1462 - accuracy: 0.9375 - val_loss: 0.5359 - val_accuracy: 0.8040 Epoch 72/100 63/63 [==============================] - 19s 295ms/step - loss: 0.1479 - accuracy: 0.9455 - val_loss: 0.4031 - val_accuracy: 0.8640 Epoch 73/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1389 - accuracy: 0.9485 - val_loss: 1.3163 - val_accuracy: 0.7320 Epoch 74/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1297 - accuracy: 0.9505 - val_loss: 0.4890 - val_accuracy: 0.8590 Epoch 75/100 63/63 [==============================] - 19s 302ms/step - loss: 0.1232 - accuracy: 0.9485 - val_loss: 1.8173 - val_accuracy: 0.6710 Epoch 76/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1328 - accuracy: 0.9445 - val_loss: 0.3301 - val_accuracy: 0.8860 Epoch 77/100 63/63 [==============================] - 19s 301ms/step - loss: 0.1249 - accuracy: 0.9490 - val_loss: 0.3632 - val_accuracy: 0.8900 Epoch 78/100 63/63 [==============================] - 19s 299ms/step - loss: 0.1354 - accuracy: 0.9425 - val_loss: 0.3637 - val_accuracy: 0.8500 Epoch 79/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1280 - accuracy: 0.9460 - val_loss: 0.8541 - val_accuracy: 0.7390 Epoch 80/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1475 - accuracy: 0.9440 - val_loss: 0.3577 - val_accuracy: 0.8730 Epoch 81/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1424 - accuracy: 0.9405 - val_loss: 0.3227 - val_accuracy: 0.8740 Epoch 82/100 63/63 [==============================] - 19s 296ms/step - loss: 0.1201 - accuracy: 0.9520 - val_loss: 0.4930 - val_accuracy: 0.8210 Epoch 83/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1286 - accuracy: 0.9450 - val_loss: 0.4637 - val_accuracy: 0.8210 Epoch 84/100 63/63 [==============================] - 19s 299ms/step - loss: 0.1152 - accuracy: 0.9520 - val_loss: 0.4887 - val_accuracy: 0.8560 Epoch 85/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1039 - accuracy: 0.9570 - val_loss: 0.3485 - val_accuracy: 0.8960 Epoch 86/100 63/63 [==============================] - 19s 296ms/step - loss: 0.1274 - accuracy: 0.9505 - val_loss: 0.5519 - val_accuracy: 0.8370 Epoch 87/100 63/63 [==============================] - 19s 302ms/step - loss: 0.1034 - accuracy: 0.9610 - val_loss: 0.6313 - val_accuracy: 0.8520 Epoch 88/100 63/63 [==============================] - 19s 295ms/step - loss: 0.1348 - accuracy: 0.9510 - val_loss: 0.3381 - val_accuracy: 0.8860 Epoch 89/100 63/63 [==============================] - 19s 299ms/step - loss: 0.1049 - accuracy: 0.9625 - val_loss: 0.5969 - val_accuracy: 0.8400 Epoch 90/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1200 - accuracy: 0.9560 - val_loss: 1.1107 - val_accuracy: 0.7810 Epoch 91/100 63/63 [==============================] - 19s 300ms/step - loss: 0.1064 - accuracy: 0.9580 - val_loss: 0.4043 - val_accuracy: 0.8650 Epoch 92/100 63/63 [==============================] - 19s 295ms/step - loss: 0.1271 - accuracy: 0.9475 - val_loss: 0.4210 - val_accuracy: 0.8800 Epoch 93/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1072 - accuracy: 0.9640 - val_loss: 3.1291 - val_accuracy: 0.6350 Epoch 94/100 63/63 [==============================] - 19s 298ms/step - loss: 0.1159 - accuracy: 0.9560 - val_loss: 1.0338 - val_accuracy: 0.8030 Epoch 95/100 63/63 [==============================] - 19s 306ms/step - loss: 0.0948 - accuracy: 0.9630 - val_loss: 0.3869 - val_accuracy: 0.8850 Epoch 96/100 63/63 [==============================] - 19s 307ms/step - loss: 0.1107 - accuracy: 0.9595 - val_loss: 0.7990 - val_accuracy: 0.8250 Epoch 97/100 63/63 [==============================] - 19s 297ms/step - loss: 0.1261 - accuracy: 0.9535 - val_loss: 0.4372 - val_accuracy: 0.8690 Epoch 98/100 63/63 [==============================] - 19s 296ms/step - loss: 0.0960 - accuracy: 0.9625 - val_loss: 0.9833 - val_accuracy: 0.7720 Epoch 99/100 63/63 [==============================] - 19s 302ms/step - loss: 0.1064 - accuracy: 0.9560 - val_loss: 0.5434 - val_accuracy: 0.8610 Epoch 100/100 63/63 [==============================] - 19s 301ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.3944 - val_accuracy: 0.8860
과대적합은 50번 정도의 에포크 실행 후에 발생한다.
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
# 정확도 그래프
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
# 손실 그래프
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()


직접 구현한 모델이지만 테스트셋에 대한 정확도가 90% 정도 나온다. 8장에서 직접 구현해서 훈련시켰을 때의 성능인 83% 정도보다 훨씬 높게 나온다.
test_model = keras.models.load_model("mini_xception.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
63/63 [==============================] - 2s 19ms/step - loss: 0.3141 - accuracy: 0.8785 Test accuracy: 0.878
성능 높이기
보다 성능을 높이려면 하이퍼파라미터 미세조정 및 앙상블 학습을 활용해야 한다(13장 참조).