감사말: 프랑소와 숄레의 Deep Learning with Python, Second Edition 5장에 사용된 코드에 대한 설명을 담고 있으며 텐서플로우 2.6 버전에서 작성되었습니다. 소스코드를 공개한 저자에게 감사드립니다.
tensorflow 버전과 GPU 확인
구글 코랩 설정: '런타임 -> 런타임 유형 변경' 메뉴에서 GPU 지정 후 아래 명령어 실행 결과 확인
!nvidia-smi사용되는 tensorflow 버전 확인
import tensorflow as tf
tf.__version__
tensorflow가 GPU를 사용하는지 여부 확인
tf.config.list_physical_devices('GPU')
훈련을 많이 할 수록 모델은 훈련 세트에 대해 보다 좋은 성능을 보이지만 새로운 데이터에 대한 성능은 점점 떨어지는 과대적합 현상이 언제나 발생한다. 머신러닝의 핵심 이슈는 모델 훈련의 최적화(optimization)와 모델 일반화(generalization) 사이의 관계를 적절히 조절하는 것이다.
과소적합
과대적합
과대적합을 발생시키는 요소는 크게 세 가지로 나뉜다.
소음이 전혀 없는 데이터라 하더라도 특정 특성 영역이 여러 레이블과 연관될 수 있음.
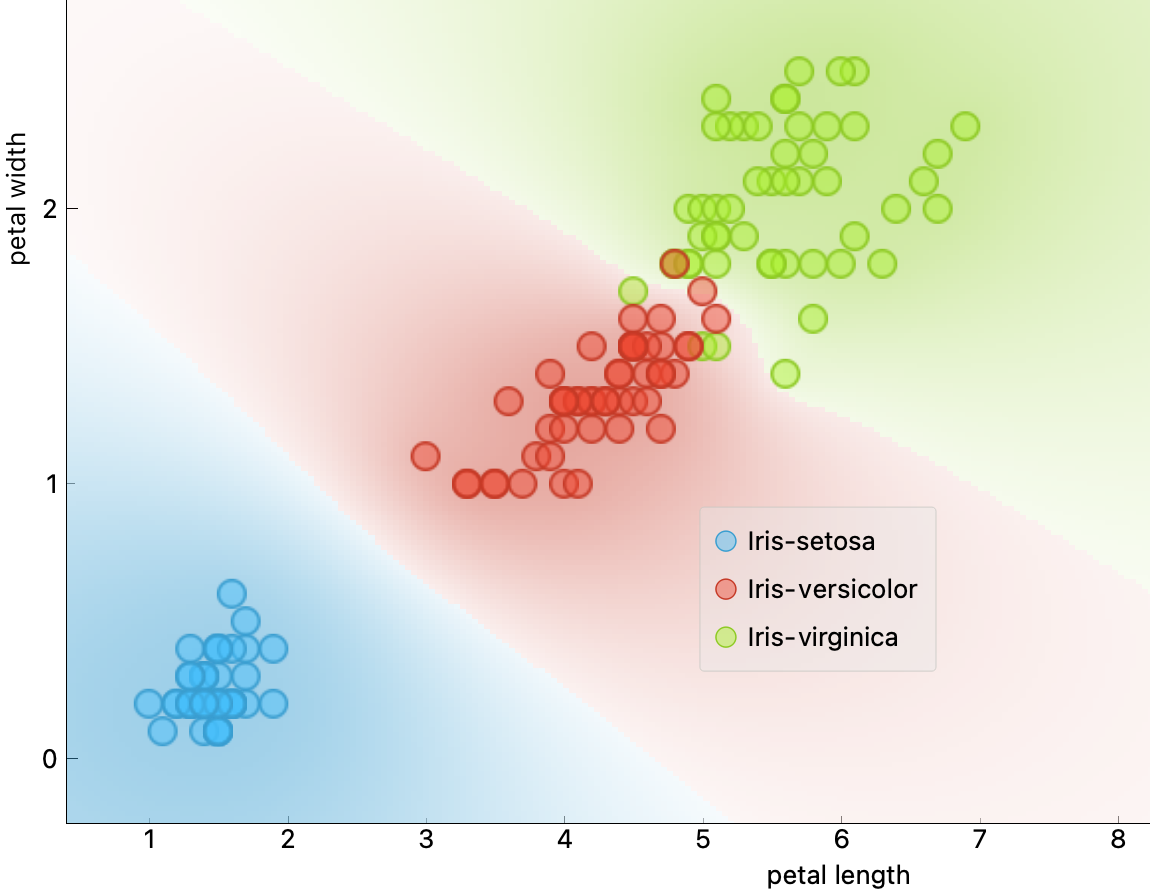
예제: 붓꽃 데이터의 꽃잎 길이와 너비를 활용한 버시컬러(versicolor) 품종과 버지니카(virginica) 품종의 완벽한 구분 불가능.
from tensorflow.keras.datasets import mnist
import numpy as np
# MNIST 데이터셋 적재 및 전처리
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
# 백색 소음 추가
train_images_with_noise_channels = np.concatenate(
[train_images, np.random.random((len(train_images), 784))], axis=1)
# 크기를 맞추기 위해 영 행렬 추가
train_images_with_zeros_channels = np.concatenate(
[train_images, np.zeros((len(train_images), 784))], axis=1)
train_images_with_noise_channels.shape
(60000, 1568)
train_images_with_zeros_channels.shape
(60000, 1568)
백색 소음이 들어간 샘플은 다음과 같이 보인다.
train_image_white4 = train_images_with_noise_channels[4].reshape((56, 28))
import matplotlib.pyplot as plt
digit = train_image_white4
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()

영 행렬이 추가된 샘플은 다음과 같이 보인다.
train_image_zeros4 = train_images_with_zeros_channels[4].reshape((56, 28))
import matplotlib.pyplot as plt
digit = train_image_zeros4
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()

모델 구성과 컴파일을 함수를 이용하여 지정한다.
sparse_categorical_crossentropy 지정해야 함.from tensorflow import keras
from tensorflow.keras import layers
def get_model():
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
return model
validation_split: 검증셋 비율 지정# 모델 생성 및 훈련
model = get_model()
history_noise = model.fit(
train_images_with_noise_channels, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10 375/375 [==============================] - 3s 7ms/step - loss: 0.6025 - accuracy: 0.8168 - val_loss: 0.3094 - val_accuracy: 0.9035 Epoch 2/10 375/375 [==============================] - 2s 6ms/step - loss: 0.2497 - accuracy: 0.9217 - val_loss: 0.2010 - val_accuracy: 0.9381 Epoch 3/10 375/375 [==============================] - 2s 6ms/step - loss: 0.1643 - accuracy: 0.9479 - val_loss: 0.1495 - val_accuracy: 0.9567 Epoch 4/10 375/375 [==============================] - 2s 6ms/step - loss: 0.1154 - accuracy: 0.9640 - val_loss: 0.1321 - val_accuracy: 0.9613 Epoch 5/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0859 - accuracy: 0.9730 - val_loss: 0.1296 - val_accuracy: 0.9624 Epoch 6/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0632 - accuracy: 0.9795 - val_loss: 0.1307 - val_accuracy: 0.9632 Epoch 7/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0468 - accuracy: 0.9851 - val_loss: 0.1216 - val_accuracy: 0.9658 Epoch 8/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0359 - accuracy: 0.9878 - val_loss: 0.1395 - val_accuracy: 0.9625 Epoch 9/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0283 - accuracy: 0.9912 - val_loss: 0.1347 - val_accuracy: 0.9655 Epoch 10/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0201 - accuracy: 0.9933 - val_loss: 0.1346 - val_accuracy: 0.9683
validation_split: 검증셋 비율 지정model = get_model()
history_zeros = model.fit(
train_images_with_zeros_channels, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10 375/375 [==============================] - 3s 6ms/step - loss: 0.2910 - accuracy: 0.9169 - val_loss: 0.1713 - val_accuracy: 0.9503 Epoch 2/10 375/375 [==============================] - 2s 6ms/step - loss: 0.1226 - accuracy: 0.9643 - val_loss: 0.1203 - val_accuracy: 0.9631 Epoch 3/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0791 - accuracy: 0.9764 - val_loss: 0.0982 - val_accuracy: 0.9708 Epoch 4/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0569 - accuracy: 0.9835 - val_loss: 0.0893 - val_accuracy: 0.9746 Epoch 5/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0431 - accuracy: 0.9871 - val_loss: 0.0765 - val_accuracy: 0.9780 Epoch 6/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0330 - accuracy: 0.9900 - val_loss: 0.0898 - val_accuracy: 0.9757 Epoch 7/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0246 - accuracy: 0.9926 - val_loss: 0.0832 - val_accuracy: 0.9781 Epoch 8/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0192 - accuracy: 0.9944 - val_loss: 0.0858 - val_accuracy: 0.9766 Epoch 9/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0146 - accuracy: 0.9961 - val_loss: 0.0806 - val_accuracy: 0.9792 Epoch 10/10 375/375 [==============================] - 2s 6ms/step - loss: 0.0110 - accuracy: 0.9969 - val_loss: 0.0894 - val_accuracy: 0.9783
import matplotlib.pyplot as plt
val_acc_noise = history_noise.history["val_accuracy"]
val_acc_zeros = history_zeros.history["val_accuracy"]
epochs = range(1, 11)
plt.plot(epochs, val_acc_noise, "b-",
label="Validation accuracy with noise channels")
plt.plot(epochs, val_acc_zeros, "b--",
label="Validation accuracy with zeros channels")
plt.title("Effect of noise channels on validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa39bef1610>

특성 선택
아래 예제에서 확인할 수 있듯이 딥러닝 모델은 어떤 무엇도 학습할 수 있다.
예제: MNIST 모델을 임의로 섞은 레이블과 함께 훈련시키기
아래 코드는 임의로 섞은 레이블을 이용하여 손글씨를 예측하는 모델을 훈련시킨다.
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
random_train_labels = train_labels[:]
np.random.shuffle(random_train_labels)
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history = model.fit(train_images, random_train_labels,
epochs=100,
batch_size=128,
validation_split=0.2)
Epoch 1/100 375/375 [==============================] - 2s 4ms/step - loss: 2.3160 - accuracy: 0.1028 - val_loss: 2.3059 - val_accuracy: 0.1075 Epoch 2/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2996 - accuracy: 0.1146 - val_loss: 2.3174 - val_accuracy: 0.1070 Epoch 3/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2908 - accuracy: 0.1272 - val_loss: 2.3171 - val_accuracy: 0.0995 Epoch 4/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2773 - accuracy: 0.1397 - val_loss: 2.3299 - val_accuracy: 0.1021 Epoch 5/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2598 - accuracy: 0.1543 - val_loss: 2.3369 - val_accuracy: 0.1011 Epoch 6/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2398 - accuracy: 0.1665 - val_loss: 2.3438 - val_accuracy: 0.1001 Epoch 7/100 375/375 [==============================] - 1s 4ms/step - loss: 2.2154 - accuracy: 0.1839 - val_loss: 2.3700 - val_accuracy: 0.0989 Epoch 8/100 375/375 [==============================] - 1s 4ms/step - loss: 2.1878 - accuracy: 0.1998 - val_loss: 2.3839 - val_accuracy: 0.1016 Epoch 9/100 375/375 [==============================] - 1s 4ms/step - loss: 2.1590 - accuracy: 0.2128 - val_loss: 2.3994 - val_accuracy: 0.0974 Epoch 10/100 375/375 [==============================] - 1s 4ms/step - loss: 2.1286 - accuracy: 0.2277 - val_loss: 2.4190 - val_accuracy: 0.1037 Epoch 11/100 375/375 [==============================] - 1s 4ms/step - loss: 2.0950 - accuracy: 0.2460 - val_loss: 2.4478 - val_accuracy: 0.1045 Epoch 12/100 375/375 [==============================] - 1s 4ms/step - loss: 2.0629 - accuracy: 0.2592 - val_loss: 2.4759 - val_accuracy: 0.0991 Epoch 13/100 375/375 [==============================] - 1s 4ms/step - loss: 2.0296 - accuracy: 0.2728 - val_loss: 2.5128 - val_accuracy: 0.1008 Epoch 14/100 375/375 [==============================] - 1s 4ms/step - loss: 1.9952 - accuracy: 0.2901 - val_loss: 2.5418 - val_accuracy: 0.1000 Epoch 15/100 375/375 [==============================] - 1s 4ms/step - loss: 1.9599 - accuracy: 0.3048 - val_loss: 2.5699 - val_accuracy: 0.0967 Epoch 16/100 375/375 [==============================] - 1s 4ms/step - loss: 1.9254 - accuracy: 0.3213 - val_loss: 2.6053 - val_accuracy: 0.0972 Epoch 17/100 375/375 [==============================] - 1s 4ms/step - loss: 1.8932 - accuracy: 0.3329 - val_loss: 2.6457 - val_accuracy: 0.0974 Epoch 18/100 375/375 [==============================] - 1s 4ms/step - loss: 1.8590 - accuracy: 0.3470 - val_loss: 2.6563 - val_accuracy: 0.0991 Epoch 19/100 375/375 [==============================] - 1s 4ms/step - loss: 1.8269 - accuracy: 0.3623 - val_loss: 2.7011 - val_accuracy: 0.1020 Epoch 20/100 375/375 [==============================] - 1s 4ms/step - loss: 1.7944 - accuracy: 0.3726 - val_loss: 2.7439 - val_accuracy: 0.1028 Epoch 21/100 375/375 [==============================] - 1s 4ms/step - loss: 1.7609 - accuracy: 0.3858 - val_loss: 2.7780 - val_accuracy: 0.0985 Epoch 22/100 375/375 [==============================] - 2s 4ms/step - loss: 1.7303 - accuracy: 0.3974 - val_loss: 2.7981 - val_accuracy: 0.1039 Epoch 23/100 375/375 [==============================] - 1s 4ms/step - loss: 1.6979 - accuracy: 0.4106 - val_loss: 2.8535 - val_accuracy: 0.1001 Epoch 24/100 375/375 [==============================] - 1s 4ms/step - loss: 1.6701 - accuracy: 0.4201 - val_loss: 2.8859 - val_accuracy: 0.0973 Epoch 25/100 375/375 [==============================] - 1s 4ms/step - loss: 1.6388 - accuracy: 0.4335 - val_loss: 2.9421 - val_accuracy: 0.0994 Epoch 26/100 375/375 [==============================] - 1s 4ms/step - loss: 1.6115 - accuracy: 0.4434 - val_loss: 2.9658 - val_accuracy: 0.1007 Epoch 27/100 375/375 [==============================] - 1s 4ms/step - loss: 1.5837 - accuracy: 0.4527 - val_loss: 3.0111 - val_accuracy: 0.0986 Epoch 28/100 375/375 [==============================] - 1s 4ms/step - loss: 1.5548 - accuracy: 0.4655 - val_loss: 3.0483 - val_accuracy: 0.1011 Epoch 29/100 375/375 [==============================] - 1s 4ms/step - loss: 1.5296 - accuracy: 0.4767 - val_loss: 3.1150 - val_accuracy: 0.1021 Epoch 30/100 375/375 [==============================] - 1s 4ms/step - loss: 1.5034 - accuracy: 0.4840 - val_loss: 3.1430 - val_accuracy: 0.1004 Epoch 31/100 375/375 [==============================] - 1s 4ms/step - loss: 1.4779 - accuracy: 0.4952 - val_loss: 3.1994 - val_accuracy: 0.1019 Epoch 32/100 375/375 [==============================] - 1s 4ms/step - loss: 1.4529 - accuracy: 0.5032 - val_loss: 3.2257 - val_accuracy: 0.0971 Epoch 33/100 375/375 [==============================] - 1s 4ms/step - loss: 1.4279 - accuracy: 0.5128 - val_loss: 3.3020 - val_accuracy: 0.1002 Epoch 34/100 375/375 [==============================] - 1s 4ms/step - loss: 1.4045 - accuracy: 0.5218 - val_loss: 3.3248 - val_accuracy: 0.1036 Epoch 35/100 375/375 [==============================] - 1s 4ms/step - loss: 1.3814 - accuracy: 0.5292 - val_loss: 3.3838 - val_accuracy: 0.1023 Epoch 36/100 375/375 [==============================] - 1s 4ms/step - loss: 1.3574 - accuracy: 0.5381 - val_loss: 3.4409 - val_accuracy: 0.1024 Epoch 37/100 375/375 [==============================] - 1s 4ms/step - loss: 1.3383 - accuracy: 0.5439 - val_loss: 3.4563 - val_accuracy: 0.1039 Epoch 38/100 375/375 [==============================] - 1s 4ms/step - loss: 1.3127 - accuracy: 0.5539 - val_loss: 3.5009 - val_accuracy: 0.0993 Epoch 39/100 375/375 [==============================] - 1s 4ms/step - loss: 1.2932 - accuracy: 0.5600 - val_loss: 3.5584 - val_accuracy: 0.1007 Epoch 40/100 375/375 [==============================] - 1s 4ms/step - loss: 1.2719 - accuracy: 0.5677 - val_loss: 3.6023 - val_accuracy: 0.1020 Epoch 41/100 375/375 [==============================] - 1s 4ms/step - loss: 1.2497 - accuracy: 0.5742 - val_loss: 3.6746 - val_accuracy: 0.1008 Epoch 42/100 375/375 [==============================] - 2s 4ms/step - loss: 1.2318 - accuracy: 0.5840 - val_loss: 3.7526 - val_accuracy: 0.1032 Epoch 43/100 375/375 [==============================] - 1s 4ms/step - loss: 1.2115 - accuracy: 0.5918 - val_loss: 3.7552 - val_accuracy: 0.1038 Epoch 44/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1919 - accuracy: 0.5969 - val_loss: 3.8143 - val_accuracy: 0.1023 Epoch 45/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1745 - accuracy: 0.6030 - val_loss: 3.8828 - val_accuracy: 0.1037 Epoch 46/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1547 - accuracy: 0.6113 - val_loss: 3.9233 - val_accuracy: 0.1002 Epoch 47/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1371 - accuracy: 0.6198 - val_loss: 3.9866 - val_accuracy: 0.1026 Epoch 48/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1208 - accuracy: 0.6220 - val_loss: 4.0294 - val_accuracy: 0.1018 Epoch 49/100 375/375 [==============================] - 1s 4ms/step - loss: 1.1018 - accuracy: 0.6288 - val_loss: 4.0804 - val_accuracy: 0.1069 Epoch 50/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0838 - accuracy: 0.6354 - val_loss: 4.1528 - val_accuracy: 0.1036 Epoch 51/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0685 - accuracy: 0.6414 - val_loss: 4.2166 - val_accuracy: 0.1053 Epoch 52/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0503 - accuracy: 0.6479 - val_loss: 4.2461 - val_accuracy: 0.1011 Epoch 53/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0350 - accuracy: 0.6546 - val_loss: 4.3196 - val_accuracy: 0.1028 Epoch 54/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0190 - accuracy: 0.6600 - val_loss: 4.3868 - val_accuracy: 0.1048 Epoch 55/100 375/375 [==============================] - 1s 4ms/step - loss: 1.0045 - accuracy: 0.6650 - val_loss: 4.4188 - val_accuracy: 0.1029 Epoch 56/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9895 - accuracy: 0.6708 - val_loss: 4.4720 - val_accuracy: 0.1023 Epoch 57/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9740 - accuracy: 0.6747 - val_loss: 4.5235 - val_accuracy: 0.1063 Epoch 58/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9603 - accuracy: 0.6778 - val_loss: 4.5799 - val_accuracy: 0.1044 Epoch 59/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9430 - accuracy: 0.6866 - val_loss: 4.6532 - val_accuracy: 0.1037 Epoch 60/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9299 - accuracy: 0.6905 - val_loss: 4.7384 - val_accuracy: 0.1014 Epoch 61/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9151 - accuracy: 0.6943 - val_loss: 4.7840 - val_accuracy: 0.1028 Epoch 62/100 375/375 [==============================] - 1s 4ms/step - loss: 0.9030 - accuracy: 0.7001 - val_loss: 4.8333 - val_accuracy: 0.1038 Epoch 63/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8879 - accuracy: 0.7061 - val_loss: 4.8799 - val_accuracy: 0.1019 Epoch 64/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8762 - accuracy: 0.7082 - val_loss: 4.9496 - val_accuracy: 0.1056 Epoch 65/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8650 - accuracy: 0.7137 - val_loss: 5.0574 - val_accuracy: 0.1032 Epoch 66/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8500 - accuracy: 0.7176 - val_loss: 5.0640 - val_accuracy: 0.1023 Epoch 67/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8376 - accuracy: 0.7221 - val_loss: 5.1021 - val_accuracy: 0.1015 Epoch 68/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8253 - accuracy: 0.7278 - val_loss: 5.2221 - val_accuracy: 0.1037 Epoch 69/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8137 - accuracy: 0.7297 - val_loss: 5.2617 - val_accuracy: 0.1047 Epoch 70/100 375/375 [==============================] - 1s 4ms/step - loss: 0.8006 - accuracy: 0.7341 - val_loss: 5.3177 - val_accuracy: 0.1013 Epoch 71/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7877 - accuracy: 0.7391 - val_loss: 5.3524 - val_accuracy: 0.1046 Epoch 72/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7775 - accuracy: 0.7440 - val_loss: 5.4909 - val_accuracy: 0.1028 Epoch 73/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7653 - accuracy: 0.7480 - val_loss: 5.5094 - val_accuracy: 0.1039 Epoch 74/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7567 - accuracy: 0.7520 - val_loss: 5.5627 - val_accuracy: 0.1053 Epoch 75/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7458 - accuracy: 0.7549 - val_loss: 5.6420 - val_accuracy: 0.1039 Epoch 76/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7335 - accuracy: 0.7588 - val_loss: 5.6773 - val_accuracy: 0.1026 Epoch 77/100 375/375 [==============================] - 2s 4ms/step - loss: 0.7234 - accuracy: 0.7625 - val_loss: 5.7440 - val_accuracy: 0.1040 Epoch 78/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7123 - accuracy: 0.7659 - val_loss: 5.8535 - val_accuracy: 0.1037 Epoch 79/100 375/375 [==============================] - 1s 4ms/step - loss: 0.7018 - accuracy: 0.7707 - val_loss: 5.9235 - val_accuracy: 0.1030 Epoch 80/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6916 - accuracy: 0.7747 - val_loss: 6.0144 - val_accuracy: 0.1032 Epoch 81/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6825 - accuracy: 0.7757 - val_loss: 6.0495 - val_accuracy: 0.1023 Epoch 82/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6737 - accuracy: 0.7799 - val_loss: 6.1352 - val_accuracy: 0.1003 Epoch 83/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6639 - accuracy: 0.7829 - val_loss: 6.1873 - val_accuracy: 0.1043 Epoch 84/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6540 - accuracy: 0.7865 - val_loss: 6.2577 - val_accuracy: 0.1028 Epoch 85/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6467 - accuracy: 0.7893 - val_loss: 6.2779 - val_accuracy: 0.1056 Epoch 86/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6351 - accuracy: 0.7924 - val_loss: 6.3430 - val_accuracy: 0.1041 Epoch 87/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6262 - accuracy: 0.7940 - val_loss: 6.4281 - val_accuracy: 0.1052 Epoch 88/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6204 - accuracy: 0.7968 - val_loss: 6.5041 - val_accuracy: 0.1043 Epoch 89/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6099 - accuracy: 0.8025 - val_loss: 6.5276 - val_accuracy: 0.1047 Epoch 90/100 375/375 [==============================] - 1s 4ms/step - loss: 0.6015 - accuracy: 0.8047 - val_loss: 6.6247 - val_accuracy: 0.1028 Epoch 91/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5915 - accuracy: 0.8077 - val_loss: 6.6883 - val_accuracy: 0.1027 Epoch 92/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5835 - accuracy: 0.8110 - val_loss: 6.8027 - val_accuracy: 0.1067 Epoch 93/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5754 - accuracy: 0.8109 - val_loss: 6.8185 - val_accuracy: 0.1057 Epoch 94/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5675 - accuracy: 0.8165 - val_loss: 6.9206 - val_accuracy: 0.1043 Epoch 95/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5616 - accuracy: 0.8196 - val_loss: 7.0149 - val_accuracy: 0.1042 Epoch 96/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5510 - accuracy: 0.8209 - val_loss: 7.0384 - val_accuracy: 0.1025 Epoch 97/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5458 - accuracy: 0.8233 - val_loss: 7.0988 - val_accuracy: 0.1061 Epoch 98/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5392 - accuracy: 0.8256 - val_loss: 7.1822 - val_accuracy: 0.1053 Epoch 99/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5303 - accuracy: 0.8281 - val_loss: 7.2305 - val_accuracy: 0.1041 Epoch 100/100 375/375 [==============================] - 1s 4ms/step - loss: 0.5235 - accuracy: 0.8327 - val_loss: 7.2792 - val_accuracy: 0.1055
훈련셋에 대한 성능은 훈련하면서 계속 향상되지만 검증셋에 성능은 전혀 향상되지 않는다.
import matplotlib.pyplot as plt
train_acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
epochs = range(1, 101)
plt.plot(epochs, train_acc, "b--",
label="Train accuracy")
plt.plot(epochs, val_acc, "b-",
label="Validation accuracy")
plt.title("Shuffled MNIST Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa39af6de90>

위 결과는 다음을 의미한다.
결론적으로 일반화가 모델 보다는 사용되는 데이터셋 내부에 존재하는 정보 구조와 보다 밀접히 관련된다고 볼 수 있다.
일반적인 데이터셋은 고차원상에 존재하는 (저차원의) 연속이며 미분가능한 다양체를 구성한다는 가설이 다양체 가설(manifold hypothesis)이다. 그리고 모델 훈련은 바로 이 다양체를 찾아가는 과정이다.
참고: 이런 의미에서 무작위로 섞은 레이블을 사용하는 위 MNIST 예제는 일반적인 데이터셋이 될 수 없다.
아래 이미지는 3차원 공간에 존재하는 2차원 다양체를 고차원 상의 다양체로 변환하여 선형 분류가 가능한 데이터셋을 구성하는 과정을 보여준다.
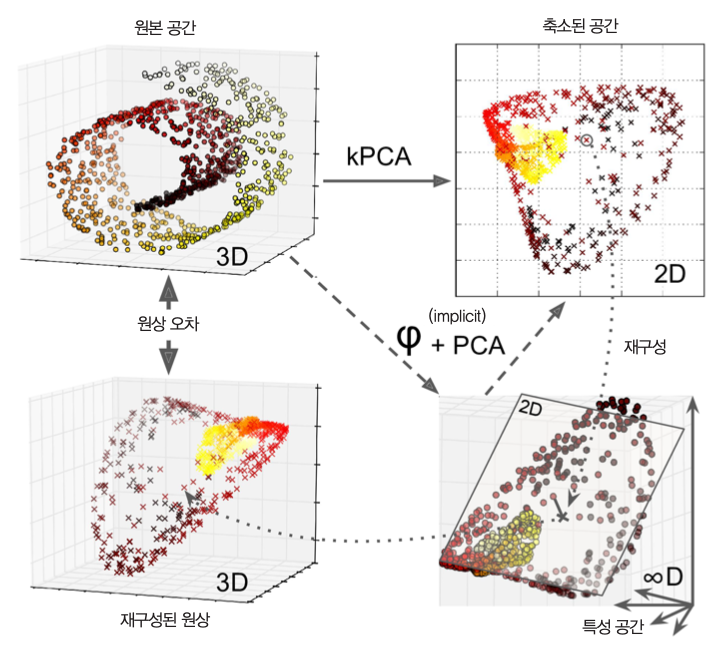
그림 출처: 핸즈온 머신러닝(2판), 8장
다양체 가설을 이용하면 적절하게 구성된 모델이 적절한 훈련셋으로 훈련받았을 때 새로운 데이터에 대해 적절한 예측을 할 수 있는 이유를 설명할 수 있다. 즉, 모델이 찾은 연속이며 미분가능한 다양체와 학습된 데이터 정보에 보간법을 적용하여 새로운 데이터에 대해 예측을 실행한다.
보간법(interpolation)은 모델 훈련에 사용된 훈련셋의 데이터와 새로운 데이터를 연결하는 다양체 상의 경로를 이용하여 예측값을 실행하는 것을 의미한다. 보다 큰 훈련셋을 사용할 수록 보간법이 보다 잘 작동하지만 차원의 저주(curse of dimensions)로 인해 충분한 크기의 훈련셋 구하기가 일반적으로 불가능하거나 매우 어렵다.
참고: 사람은 보간법 이외의 다른 능력을 사용하여 사물 예측과 구분, 주변 파악, 상황 판단 등 일반화를 실행한다.
충분히 큰 훈련셋을 준비하지 못하면 예측 과정에서 과대한 추측을 하게되어 과대적합이 발생할 가능성이 높다. 이를 방지하기 위해 일반적으로 두 가지 방법을 사용한다.
위 두 방법을 통해 데이터셋의 너무 세세한 패턴 보다는 가장 눈에 띄는 핵심적인 패턴에 모델이 집중하도록 한다. 이런식으로 과대적합을 방지하여 일반화를 향상시키는 기법을 정규화(regularization)이라 부른다.
모델의 일반화 능력을 향상시키려면 주어진 모델의 일반화 능력을 평가할 수 있어야 하며, 이를 위해 데이터셋을 훈련셋, 검증셋, 테스트셋으로 구분하는 이유를 먼저 알아야 한다.
훈련셋, 테스트셋 이외에 검증셋을 사용해야 하는 이유는 무엇보다도 최적의 모델을 구성할 때 검증셋에 대한 결과가 반영되기 때문이다.
테스트셋은 모델 구성과 훈련에 전혀 관여하지 않아야 한다. 따라서 구성된 모델의 성능을 평가하려면 테스트셋을 제외한 다른 데이터셋이 필요하고 이를 위해 훈련셋의 일부를 검증셋으로 활용한다. 검증셋은 훈련 과정 중에 일반화 성능을 테스트하는 용도로 사용되며 이를 통해 레이어 종류 및 개수, 레이어 별 유닛 개수 등 모델 구성에 필요한 하이퍼파라미터(hyperparameter)를 조정한다. 이것을 모델 튜닝(model tuning)이라 하며, 바로 이 모델 튜닝을 위해 검증셋이 사용되는 것이다.
모델 튜닝도 모델의 좋은 하이퍼파라미터를 찾아가는 일종의 학습이다. 따라서 튜닝을 많이 하게되면 검증셋에 대한 과대적합이 발생한다. 다시 말해, 검증셋에 특화된 튜닝을 하게 되어 모델의 일반화 성능이 떨어질 수 있게 된다. 이런 현상을 정보 유출이라 부르는데, 이유는 튜닝을 하면 할 수록 검증셋에 대한 보다 많은 정보가 모델로 흘려들어가기 때문이다.
참고: 하이퍼파라미터와 파라미터는 다르다. 파라미터(parameter)는 모델 훈련 중에 학습되는 가중치, 편향 등을 가리킨다.
데이터셋을 훈련셋, 검증셋, 테스트셋으로 분류하여 모델을 훈련을 진행하는 전형적인 방식 세 가지를 소개한다.
훈련셋의 일부를 검증셋으로 사용하는 가장 일반적인 방법이며, 모델 훈련 후에 테스트셋을 이용하여 모델의 일반화 성능을 확인한다. 하지만 그 이후에 모델 튜닝을 진행하지 않아야 한다.
홀드아웃 검증의 전형적인 패턴은 다음과 같다.
num_validation_samples = 10000
np.random.shuffle(data)
validation_data = data[:num_validation_samples]
training_data = data[num_validation_samples:]
model = get_model()
model.fit(training_data, ...)
validation_score = model.evaluate(validation_data, ...)
...
model = get_model()
model.fit(np.concatenate([training_data,
validation_data]), ...)
test_score = model.evaluate(test_data, ...)
모델의 성능이 사용되는 훈련셋에 따라 심하게 달라질 때 추천되는 검증기법이다.
K-겹 교차검증의 전형적인 패턴은 다음과 같다.
k = 3
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
validation_data = data[num_validation_samples * fold:
num_validation_samples * (fold + 1)]
training_data = np.concatenate(
data[:num_validation_samples * fold],
data[num_validation_samples * (fold + 1):])
model = get_model()
model.fit(training_data, ...)
validation_score = model.evaluate(validation_data, ...)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
model = get_model()
model.fit(data, ...)
test_score = model.evaluate(test_data, ...)
훈련셋의 크기가 너무 작거나 모델의 성능을 최대한 정확하게 평가하기 위해 사용된다.
K-겹 교차검증을 여러 번 실행한다. 대신 매번 훈련셋을 무작위로 섞은 뒤에
교차검증을 실행한다.
최종 결과는 각 교차검증의 평균값을 사용한다.
훈련 시간이 매우 오래 걸린다는 게 이 방법의 단점이다.
K-겹 교차 검증을 P번 반복하면 총 P * K 개의 모델을 훈련시키게 된다.
모델 훈련이 시작되면 평가지표(metrics)를 지켜보는 일 이외에 할 수 있는 게 없다. 따라서 검증셋에 대한 평가지표가 특정 기준선 이상인지를 아는 게 매우 중요하다.
기준선 예제
기준선을 넘는 모델을 생성하는 것이 기본 목표이어야 함. 그렇지 않다면 무언가 잘못된 모델을 또는 잘못된 접근법을 사용하고 있을 가능성이 큼.
최적화된 모델 훈련을 위해 아래 세 가지 사항을 준수하며 훈련셋, 검증셋, 테스트셋을 준비해야 한다.
모델 훈련을 최적화하려면 먼저 과대적합을 달성해야 한다. 이유는 과대적합이 나타나야만 과대적합의 경계를 알아내서 모델 훈련을 언제 멈추어야 하는지 알 수 있기 때문이다. 일단 과대적합의 경계를 찾은 다음에 일반화 성능을 목표로 삼아야 한다.
모델 훈련 중에 발생하는 문제는 크게 세 종류이다.
훈련셋의 손실값이 줄어들지 않거나 진동하는 등 훈련이 제대로 이루어지지 않는 경우는 기본적으로 학습률과 배치 크기를 조절하면 해결된다.
MNIST 모델 훈련: 매우 큰 학습률 사용
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1.),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10 375/375 [==============================] - 2s 4ms/step - loss: 1052.2745 - accuracy: 0.3604 - val_loss: 2.0373 - val_accuracy: 0.2853 Epoch 2/10 375/375 [==============================] - 1s 4ms/step - loss: 4.9106 - accuracy: 0.2501 - val_loss: 2.0671 - val_accuracy: 0.2453 Epoch 3/10 375/375 [==============================] - 1s 4ms/step - loss: 2.9203 - accuracy: 0.2402 - val_loss: 2.1236 - val_accuracy: 0.2192 Epoch 4/10 375/375 [==============================] - 1s 4ms/step - loss: 2.5024 - accuracy: 0.2362 - val_loss: 2.3967 - val_accuracy: 0.2854 Epoch 5/10 375/375 [==============================] - 1s 4ms/step - loss: 2.6780 - accuracy: 0.2364 - val_loss: 2.1830 - val_accuracy: 0.2910 Epoch 6/10 375/375 [==============================] - 1s 4ms/step - loss: 2.8584 - accuracy: 0.2582 - val_loss: 2.4019 - val_accuracy: 0.2674 Epoch 7/10 375/375 [==============================] - 1s 4ms/step - loss: 2.5525 - accuracy: 0.2406 - val_loss: 2.4998 - val_accuracy: 0.2412 Epoch 8/10 375/375 [==============================] - 1s 4ms/step - loss: 2.4591 - accuracy: 0.2324 - val_loss: 2.1182 - val_accuracy: 0.2267 Epoch 9/10 375/375 [==============================] - 1s 4ms/step - loss: 2.3558 - accuracy: 0.2535 - val_loss: 2.7957 - val_accuracy: 0.2347 Epoch 10/10 375/375 [==============================] - 1s 4ms/step - loss: 2.4698 - accuracy: 0.2403 - val_loss: 2.1845 - val_accuracy: 0.2557
<keras.callbacks.History at 0x7fa39afa9910>
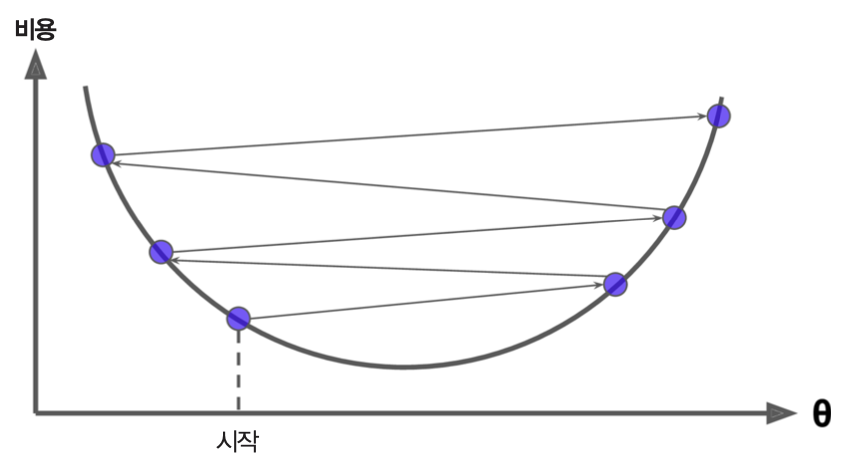
그림 출처: 핸즈온 머신러닝(2판), 4장
MNIST 모델 훈련: 매우 작은 학습률 사용
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-6),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10 375/375 [==============================] - 2s 4ms/step - loss: 2.2697 - accuracy: 0.1516 - val_loss: 2.2277 - val_accuracy: 0.1837 Epoch 2/10 375/375 [==============================] - 1s 4ms/step - loss: 2.1804 - accuracy: 0.2286 - val_loss: 2.1383 - val_accuracy: 0.2746 Epoch 3/10 375/375 [==============================] - 1s 4ms/step - loss: 2.0952 - accuracy: 0.3267 - val_loss: 2.0523 - val_accuracy: 0.3807 Epoch 4/10 375/375 [==============================] - 1s 4ms/step - loss: 2.0135 - accuracy: 0.4342 - val_loss: 1.9703 - val_accuracy: 0.4834 Epoch 5/10 375/375 [==============================] - 1s 4ms/step - loss: 1.9346 - accuracy: 0.5261 - val_loss: 1.8906 - val_accuracy: 0.5653 Epoch 6/10 375/375 [==============================] - 1s 4ms/step - loss: 1.8583 - accuracy: 0.5959 - val_loss: 1.8137 - val_accuracy: 0.6258 Epoch 7/10 375/375 [==============================] - 1s 4ms/step - loss: 1.7843 - accuracy: 0.6465 - val_loss: 1.7392 - val_accuracy: 0.6702 Epoch 8/10 375/375 [==============================] - 1s 4ms/step - loss: 1.7130 - accuracy: 0.6817 - val_loss: 1.6672 - val_accuracy: 0.6997 Epoch 9/10 375/375 [==============================] - 1s 4ms/step - loss: 1.6439 - accuracy: 0.7096 - val_loss: 1.5978 - val_accuracy: 0.7258 Epoch 10/10 375/375 [==============================] - 1s 4ms/step - loss: 1.5774 - accuracy: 0.7293 - val_loss: 1.5310 - val_accuracy: 0.7443
<keras.callbacks.History at 0x7fa385497250>
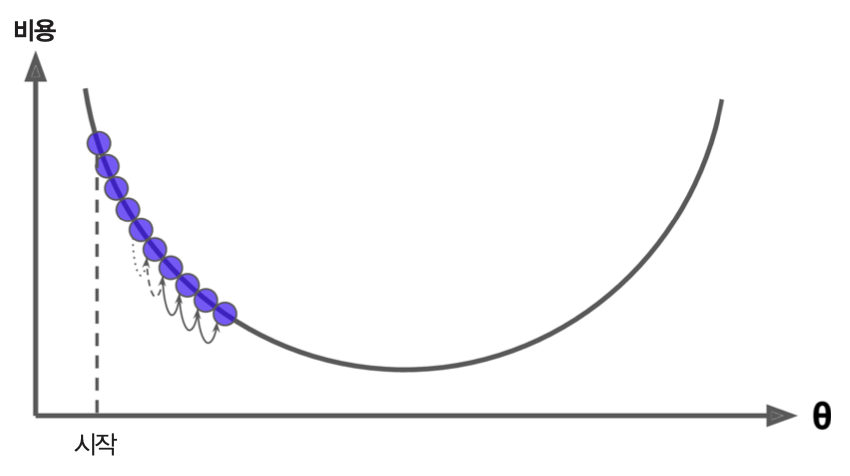
그림 출처: 핸즈온 머신러닝(2판), 4장
MNIST 모델 훈련: 적절한 학습률 사용
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10 375/375 [==============================] - 2s 4ms/step - loss: 0.3792 - accuracy: 0.9103 - val_loss: 0.1304 - val_accuracy: 0.9647 Epoch 2/10 375/375 [==============================] - 1s 4ms/step - loss: 0.1415 - accuracy: 0.9639 - val_loss: 0.1536 - val_accuracy: 0.9676 Epoch 3/10 375/375 [==============================] - 1s 4ms/step - loss: 0.1131 - accuracy: 0.9730 - val_loss: 0.2516 - val_accuracy: 0.9557 Epoch 4/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0985 - accuracy: 0.9783 - val_loss: 0.2125 - val_accuracy: 0.9607 Epoch 5/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0838 - accuracy: 0.9819 - val_loss: 0.1953 - val_accuracy: 0.9707 Epoch 6/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0710 - accuracy: 0.9849 - val_loss: 0.2379 - val_accuracy: 0.9707 Epoch 7/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0726 - accuracy: 0.9860 - val_loss: 0.2317 - val_accuracy: 0.9747 Epoch 8/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0578 - accuracy: 0.9883 - val_loss: 0.3087 - val_accuracy: 0.9679 Epoch 9/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0568 - accuracy: 0.9899 - val_loss: 0.2731 - val_accuracy: 0.9736 Epoch 10/10 375/375 [==============================] - 1s 4ms/step - loss: 0.0609 - accuracy: 0.9901 - val_loss: 0.3032 - val_accuracy: 0.9721
<keras.callbacks.History at 0x7fa3841ca210>
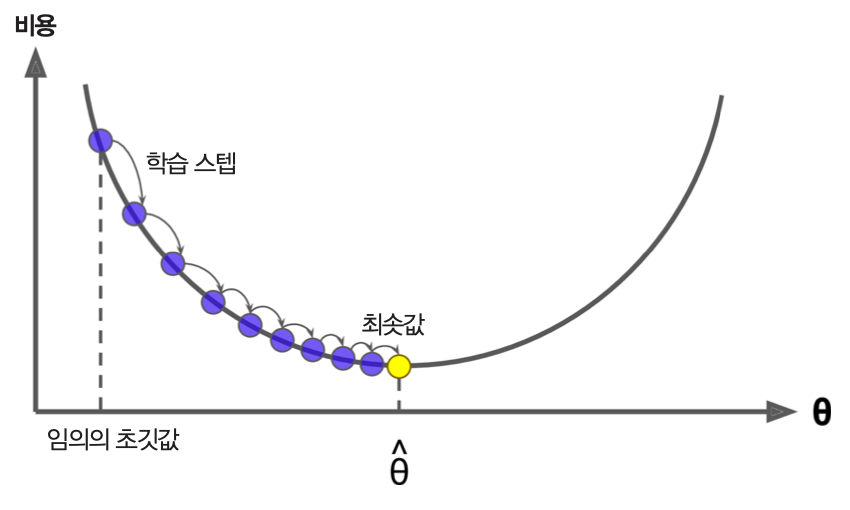
그림 출처: 핸즈온 머신러닝(2판), 4장
배치 크기 조정
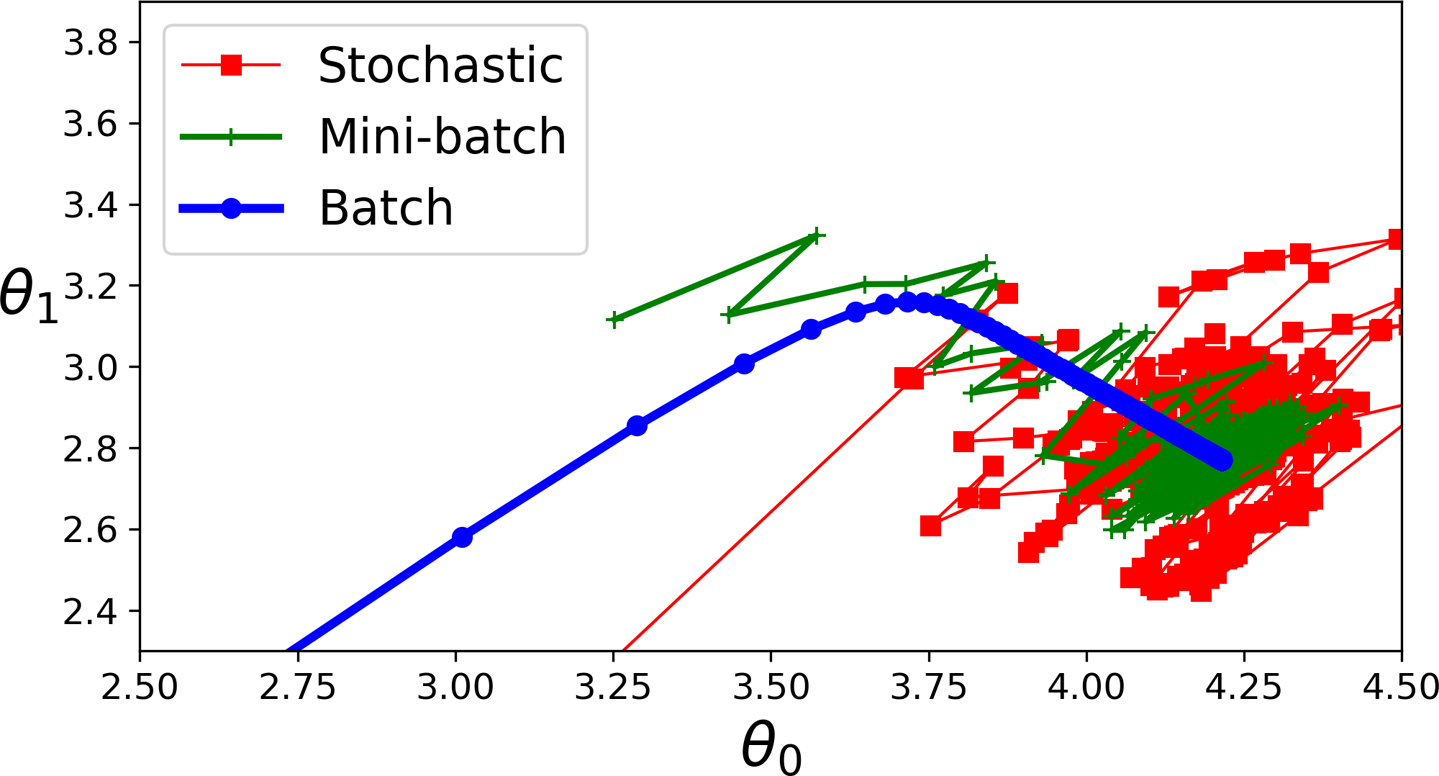
그림 출처: 핸즈온 머신러닝(2판), 4장
훈련은 잘 진행되는데 검증셋에 대한 성능이 좋아지지 않는다면 다음 두 가지 경우를 의심해 보아야 한다.
Sequential 모델을 사용하는 경우(나중에 확인할 것임)기본적으로, 문제 해결을 위한 적절한 가정을 사용하는 모델을 훈련시켜야 한다. 앞으로 다양한 문제에 적용되는 다양한 모델 구성과 훈련을 살펴볼 것이다.
모델의 훈련셋/검증셋의 평가지표가 계속 향상되지만 과대적합이 발생하지 않는 경우 기본적으로 모델의 정보 저장 능력을 키워야 한다.
먼저 아래 예제를 살펴보자.
MNIST 데이터셋 다중클래스 분류: 매우 단순한 모델
결론적으로 모델의 정보 저장/분석 능력이 떨어진다.
model = keras.Sequential([layers.Dense(10, activation="softmax")])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history_small_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)
Epoch 1/20 375/375 [==============================] - 1s 1ms/step - loss: 0.6539 - accuracy: 0.8410 - val_loss: 0.3580 - val_accuracy: 0.9057 Epoch 2/20 375/375 [==============================] - 0s 794us/step - loss: 0.3504 - accuracy: 0.9039 - val_loss: 0.3074 - val_accuracy: 0.9145 Epoch 3/20 375/375 [==============================] - 0s 868us/step - loss: 0.3152 - accuracy: 0.9126 - val_loss: 0.2907 - val_accuracy: 0.9184 Epoch 4/20 375/375 [==============================] - 0s 796us/step - loss: 0.2994 - accuracy: 0.9170 - val_loss: 0.2811 - val_accuracy: 0.9213 Epoch 5/20 375/375 [==============================] - 0s 788us/step - loss: 0.2896 - accuracy: 0.9194 - val_loss: 0.2757 - val_accuracy: 0.9234 Epoch 6/20 375/375 [==============================] - 0s 829us/step - loss: 0.2832 - accuracy: 0.9214 - val_loss: 0.2719 - val_accuracy: 0.9248 Epoch 7/20 375/375 [==============================] - 0s 1ms/step - loss: 0.2784 - accuracy: 0.9229 - val_loss: 0.2705 - val_accuracy: 0.9260 Epoch 8/20 375/375 [==============================] - 0s 773us/step - loss: 0.2741 - accuracy: 0.9237 - val_loss: 0.2677 - val_accuracy: 0.9266 Epoch 9/20 375/375 [==============================] - 0s 795us/step - loss: 0.2715 - accuracy: 0.9249 - val_loss: 0.2655 - val_accuracy: 0.9277 Epoch 10/20 375/375 [==============================] - 0s 801us/step - loss: 0.2689 - accuracy: 0.9253 - val_loss: 0.2642 - val_accuracy: 0.9294 Epoch 11/20 375/375 [==============================] - 0s 784us/step - loss: 0.2667 - accuracy: 0.9270 - val_loss: 0.2647 - val_accuracy: 0.9289 Epoch 12/20 375/375 [==============================] - 0s 790us/step - loss: 0.2649 - accuracy: 0.9272 - val_loss: 0.2628 - val_accuracy: 0.9287 Epoch 13/20 375/375 [==============================] - 0s 836us/step - loss: 0.2635 - accuracy: 0.9276 - val_loss: 0.2626 - val_accuracy: 0.9291 Epoch 14/20 375/375 [==============================] - 0s 874us/step - loss: 0.2619 - accuracy: 0.9283 - val_loss: 0.2614 - val_accuracy: 0.9296 Epoch 15/20 375/375 [==============================] - 0s 776us/step - loss: 0.2605 - accuracy: 0.9286 - val_loss: 0.2618 - val_accuracy: 0.9302 Epoch 16/20 375/375 [==============================] - 0s 780us/step - loss: 0.2595 - accuracy: 0.9287 - val_loss: 0.2607 - val_accuracy: 0.9293 Epoch 17/20 375/375 [==============================] - 0s 796us/step - loss: 0.2586 - accuracy: 0.9293 - val_loss: 0.2622 - val_accuracy: 0.9303 Epoch 18/20 375/375 [==============================] - 0s 798us/step - loss: 0.2571 - accuracy: 0.9298 - val_loss: 0.2624 - val_accuracy: 0.9294 Epoch 19/20 375/375 [==============================] - 0s 817us/step - loss: 0.2568 - accuracy: 0.9306 - val_loss: 0.2607 - val_accuracy: 0.9305 Epoch 20/20 375/375 [==============================] - 0s 789us/step - loss: 0.2556 - accuracy: 0.9304 - val_loss: 0.2611 - val_accuracy: 0.9310
import matplotlib.pyplot as plt
val_loss = history_small_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",
label="Validation loss")
plt.title("Effect of insufficient model capacity on validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
<matplotlib.legend.Legend at 0x7fa373fde310>

MNIST 데이터셋 다중클래스 분류: 보다 많은 저장/분석/표현 능력 모델
잘 훈련되며 과대적합이 발생한다.
model = keras.Sequential([
layers.Dense(96, activation="relu"),
layers.Dense(96, activation="relu"),
layers.Dense(10, activation="softmax"),
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history_large_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)
Epoch 1/20 375/375 [==============================] - 1s 2ms/step - loss: 0.3575 - accuracy: 0.9004 - val_loss: 0.1841 - val_accuracy: 0.9461 Epoch 2/20 375/375 [==============================] - 0s 1ms/step - loss: 0.1600 - accuracy: 0.9528 - val_loss: 0.1372 - val_accuracy: 0.9600 Epoch 3/20 375/375 [==============================] - 0s 1ms/step - loss: 0.1137 - accuracy: 0.9656 - val_loss: 0.1214 - val_accuracy: 0.9640 Epoch 4/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0875 - accuracy: 0.9734 - val_loss: 0.1049 - val_accuracy: 0.9674 Epoch 5/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0696 - accuracy: 0.9785 - val_loss: 0.1073 - val_accuracy: 0.9704 Epoch 6/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0565 - accuracy: 0.9831 - val_loss: 0.0958 - val_accuracy: 0.9728 Epoch 7/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0472 - accuracy: 0.9857 - val_loss: 0.0931 - val_accuracy: 0.9729 Epoch 8/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0400 - accuracy: 0.9873 - val_loss: 0.0988 - val_accuracy: 0.9732 Epoch 9/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0334 - accuracy: 0.9894 - val_loss: 0.0975 - val_accuracy: 0.9752 Epoch 10/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0286 - accuracy: 0.9912 - val_loss: 0.1008 - val_accuracy: 0.9754 Epoch 11/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0234 - accuracy: 0.9925 - val_loss: 0.1103 - val_accuracy: 0.9727 Epoch 12/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0198 - accuracy: 0.9938 - val_loss: 0.1063 - val_accuracy: 0.9741 Epoch 13/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0173 - accuracy: 0.9947 - val_loss: 0.1153 - val_accuracy: 0.9737 Epoch 14/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0146 - accuracy: 0.9955 - val_loss: 0.1081 - val_accuracy: 0.9772 Epoch 15/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0120 - accuracy: 0.9962 - val_loss: 0.1345 - val_accuracy: 0.9728 Epoch 16/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0107 - accuracy: 0.9963 - val_loss: 0.1362 - val_accuracy: 0.9732 Epoch 17/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0089 - accuracy: 0.9970 - val_loss: 0.1327 - val_accuracy: 0.9736 Epoch 18/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0072 - accuracy: 0.9975 - val_loss: 0.1242 - val_accuracy: 0.9777 Epoch 19/20 375/375 [==============================] - 1s 1ms/step - loss: 0.0077 - accuracy: 0.9976 - val_loss: 0.1291 - val_accuracy: 0.9761 Epoch 20/20 375/375 [==============================] - 0s 1ms/step - loss: 0.0058 - accuracy: 0.9982 - val_loss: 0.1379 - val_accuracy: 0.9747
8 에포크 정도 지나면서 일반화 성능이 떨어진다.
import matplotlib.pyplot as plt
val_loss = history_large_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",
label="Validation loss")
plt.title("Effect of insufficient model capacity on validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
<matplotlib.legend.Legend at 0x7fa3d8b79c90>

모델 훈련이 어느 정도 잘 진행되어 일반화 성능이 향상되고 과대적합이 발생하기 시작하면 일반화를 극대화하는 방법에 집중해야 한다. 이를 위해 아래 요소들이 제대로 작동하는지 확인해야 한다.
양질의 데이터셋을 모델 훈련에 사용해야 모델이 데이터셋에 잠재되어 있는 다양체를 보다 잘 찾아낼 수 있다. 양질의 데이터를 보다 많이 수집하는 일이 보다 적절한 모델을 찾으려는 노력보다 값어치가 높다.
양질의 데이터의 기준은 다음과 같다.
신경망 모델은 데이터셋에 잠재되어 있는 다양체를 찾기 위해 여러 층을 통해 데이터셋의 표현을 다양한 방식으로 변환시킨다. 그렇게 해서 변환된 데이터셋의 표현들에 내재된 보다 쉽게 다양체를 찾아낸다.
심층 신경망을 이용하는 이유가 모델 스스로 좋은 표현을 찾아내라고 유도하는 데에 있다. 즉, 모델 훈련에 가장 유용한 특성을 모델 스스로 직접 구성하도록 한다. 이런 점에서 적절한 심층 신경망을 구성하는 일이 중요하며 앞으로 다양한 문제를 다루면서 다양한 모델 구성과 훈련을 살펴볼 것이다.
그럼에도 불구하고 모델 훈련 시작 전에 유용한 특성으로 이루어진 데이터셋으로 변환할 수 있다면 모델의 성능을 더더욱 높일 수 있다.
이처럼 모델 훈련에 가장 유용한 특성을 구성하는 작업을 특성 공학(feature engineering)이라 한다.
모델 훈련 중에 검증셋에 대한 성능이 더 이상 좋아지지 않는 순간에 모델 훈련을 멈추는 것이 조기 종료(early stopping)이다. 이를 위해 에포크마다 모델의 성능을 측정하여 가장 좋은 성능의 모델을 기억해 두고, 더 이상 좋아지지 않으면 그때까지의 최적 모델을 사용하도록 한다.
케라스의 경우 EarlyStopping 이라는 콜백(callback) 객체를 사용하면 조기 종료 기능을
자동으로 수행한다. 콜백에 대해서는 나중에 자세히 다룬다.
훈련 중이 모델이 데이터셋에 너무 민감하지 않게 유도하는 것을 규제(regularization)라 부른다. 즉, 모델 훈련에 규제를 가하여 모델을 보다 더 균형 있고 규칙적으로 예측하도록 유도하여 모델의 일반화 성능을 높힌다.
여기서는 모델에 규제를 가하는 세 가지 기법을 IMDB 데이터셋을 이용하여 소개한다.
앞서 보았듯이 모델을 층, 유닛의 수를 줄여 모델을 단순화 하면 과대적합이 없거나 줄어든다. 이유는 모델에 저장될 수 있는 정보량이 줄어들어 세세한 정보를 낱낱이 기억하기 보다는 보다 압축된 정보를 활용하도록 유도된다.
모델이 너무 단순하면 아예 훈련이 제대로 되지 않을 수 있기에 적절하게 줄이도록 해야 한다. 하지만 이에 대한 이론적 기준은 없으며 실험을 통해 적절한 규제를 찾아내야 한다. 보통 적은 수의 층과 유닛을 사용하다가 점차 수를 늘려 나가는 것이 좋다.
아래 코드는 이전에 다루었던 IMDB 데이터셋을 이용한 모델 훈련이다.
from tensorflow.keras.datasets import imdb
(train_data, train_labels), _ = imdb.load_data(num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
train_data = vectorize_sequences(train_data)
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_original = model.fit(train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Epoch 1/20 30/30 [==============================] - 2s 39ms/step - loss: 0.5153 - accuracy: 0.7932 - val_loss: 0.3933 - val_accuracy: 0.8561 Epoch 2/20 30/30 [==============================] - 0s 13ms/step - loss: 0.3084 - accuracy: 0.9007 - val_loss: 0.3137 - val_accuracy: 0.8775 Epoch 3/20 30/30 [==============================] - 0s 11ms/step - loss: 0.2268 - accuracy: 0.9273 - val_loss: 0.2898 - val_accuracy: 0.8855 Epoch 4/20 30/30 [==============================] - 0s 11ms/step - loss: 0.1800 - accuracy: 0.9407 - val_loss: 0.2806 - val_accuracy: 0.8873 Epoch 5/20 30/30 [==============================] - 0s 11ms/step - loss: 0.1465 - accuracy: 0.9526 - val_loss: 0.2760 - val_accuracy: 0.8898 Epoch 6/20 30/30 [==============================] - 0s 11ms/step - loss: 0.1238 - accuracy: 0.9620 - val_loss: 0.2993 - val_accuracy: 0.8831 Epoch 7/20 30/30 [==============================] - 0s 11ms/step - loss: 0.1025 - accuracy: 0.9699 - val_loss: 0.3030 - val_accuracy: 0.8853 Epoch 8/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0886 - accuracy: 0.9744 - val_loss: 0.3294 - val_accuracy: 0.8827 Epoch 9/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0724 - accuracy: 0.9807 - val_loss: 0.3431 - val_accuracy: 0.8812 Epoch 10/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0627 - accuracy: 0.9832 - val_loss: 0.3993 - val_accuracy: 0.8739 Epoch 11/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0505 - accuracy: 0.9873 - val_loss: 0.3978 - val_accuracy: 0.8765 Epoch 12/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0426 - accuracy: 0.9895 - val_loss: 0.4389 - val_accuracy: 0.8716 Epoch 13/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0359 - accuracy: 0.9922 - val_loss: 0.5083 - val_accuracy: 0.8636 Epoch 14/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0290 - accuracy: 0.9936 - val_loss: 0.4953 - val_accuracy: 0.8722 Epoch 15/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0236 - accuracy: 0.9956 - val_loss: 0.5164 - val_accuracy: 0.8709 Epoch 16/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0194 - accuracy: 0.9965 - val_loss: 0.5585 - val_accuracy: 0.8672 Epoch 17/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0176 - accuracy: 0.9967 - val_loss: 0.5876 - val_accuracy: 0.8676 Epoch 18/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0124 - accuracy: 0.9984 - val_loss: 0.6221 - val_accuracy: 0.8671 Epoch 19/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0099 - accuracy: 0.9990 - val_loss: 0.6640 - val_accuracy: 0.8660 Epoch 20/20 30/30 [==============================] - 0s 11ms/step - loss: 0.0096 - accuracy: 0.9985 - val_loss: 0.6946 - val_accuracy: 0.8651
은닉층의 유닛수를 4로 만들어보자.
model = keras.Sequential([
layers.Dense(4, activation="relu"),
layers.Dense(4, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_smaller_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Epoch 1/20 30/30 [==============================] - 1s 21ms/step - loss: 0.6269 - accuracy: 0.6606 - val_loss: 0.5702 - val_accuracy: 0.7327 Epoch 2/20 30/30 [==============================] - 0s 11ms/step - loss: 0.5360 - accuracy: 0.7881 - val_loss: 0.5297 - val_accuracy: 0.7474 Epoch 3/20 30/30 [==============================] - 0s 11ms/step - loss: 0.4868 - accuracy: 0.8447 - val_loss: 0.4943 - val_accuracy: 0.8366 Epoch 4/20 30/30 [==============================] - 0s 11ms/step - loss: 0.4519 - accuracy: 0.8819 - val_loss: 0.4754 - val_accuracy: 0.8583 Epoch 5/20 30/30 [==============================] - 0s 11ms/step - loss: 0.4253 - accuracy: 0.9059 - val_loss: 0.4696 - val_accuracy: 0.8405 Epoch 6/20 30/30 [==============================] - 0s 11ms/step - loss: 0.4037 - accuracy: 0.9209 - val_loss: 0.4668 - val_accuracy: 0.8411 Epoch 7/20 30/30 [==============================] - 0s 10ms/step - loss: 0.3857 - accuracy: 0.9339 - val_loss: 0.4619 - val_accuracy: 0.8470 Epoch 8/20 30/30 [==============================] - 0s 11ms/step - loss: 0.3690 - accuracy: 0.9436 - val_loss: 0.4556 - val_accuracy: 0.8569 Epoch 9/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3540 - accuracy: 0.9533 - val_loss: 0.4547 - val_accuracy: 0.8581 Epoch 10/20 30/30 [==============================] - 0s 14ms/step - loss: 0.3408 - accuracy: 0.9603 - val_loss: 0.4411 - val_accuracy: 0.8714 Epoch 11/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3277 - accuracy: 0.9663 - val_loss: 0.4443 - val_accuracy: 0.8706 Epoch 12/20 30/30 [==============================] - 0s 11ms/step - loss: 0.3165 - accuracy: 0.9698 - val_loss: 0.4481 - val_accuracy: 0.8667 Epoch 13/20 30/30 [==============================] - 0s 11ms/step - loss: 0.3055 - accuracy: 0.9738 - val_loss: 0.4918 - val_accuracy: 0.8433 Epoch 14/20 30/30 [==============================] - 0s 11ms/step - loss: 0.2958 - accuracy: 0.9760 - val_loss: 0.4629 - val_accuracy: 0.8599 Epoch 15/20 30/30 [==============================] - 0s 10ms/step - loss: 0.2862 - accuracy: 0.9791 - val_loss: 0.4644 - val_accuracy: 0.8621 Epoch 16/20 30/30 [==============================] - 0s 11ms/step - loss: 0.2772 - accuracy: 0.9811 - val_loss: 0.5123 - val_accuracy: 0.8446 Epoch 17/20 30/30 [==============================] - 0s 10ms/step - loss: 0.2687 - accuracy: 0.9827 - val_loss: 0.5035 - val_accuracy: 0.8512 Epoch 18/20 30/30 [==============================] - 0s 10ms/step - loss: 0.2609 - accuracy: 0.9839 - val_loss: 0.4909 - val_accuracy: 0.8582 Epoch 19/20 30/30 [==============================] - 0s 10ms/step - loss: 0.2533 - accuracy: 0.9851 - val_loss: 0.4597 - val_accuracy: 0.8702 Epoch 20/20 30/30 [==============================] - 0s 10ms/step - loss: 0.2456 - accuracy: 0.9871 - val_loss: 0.5346 - val_accuracy: 0.8496
기존 모델과의 차이점은 다음과 같다.
이번엔 유닛 수를 크게 늘려보자.
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(512, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_larger_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Epoch 1/20 30/30 [==============================] - 3s 88ms/step - loss: 0.5572 - accuracy: 0.7635 - val_loss: 0.3305 - val_accuracy: 0.8637 Epoch 2/20 30/30 [==============================] - 2s 73ms/step - loss: 0.2560 - accuracy: 0.8967 - val_loss: 0.2690 - val_accuracy: 0.8922 Epoch 3/20 30/30 [==============================] - 2s 71ms/step - loss: 0.1563 - accuracy: 0.9407 - val_loss: 0.3348 - val_accuracy: 0.8725 Epoch 4/20 30/30 [==============================] - 2s 72ms/step - loss: 0.0597 - accuracy: 0.9795 - val_loss: 0.3978 - val_accuracy: 0.8843 Epoch 5/20 30/30 [==============================] - 2s 72ms/step - loss: 0.1047 - accuracy: 0.9769 - val_loss: 0.3745 - val_accuracy: 0.8896 Epoch 6/20 30/30 [==============================] - 2s 72ms/step - loss: 0.0034 - accuracy: 0.9995 - val_loss: 0.5210 - val_accuracy: 0.8879 Epoch 7/20 30/30 [==============================] - 2s 71ms/step - loss: 0.1402 - accuracy: 0.9781 - val_loss: 0.4680 - val_accuracy: 0.8837 Epoch 8/20 30/30 [==============================] - 2s 72ms/step - loss: 0.0015 - accuracy: 0.9999 - val_loss: 0.5193 - val_accuracy: 0.8873 Epoch 9/20 30/30 [==============================] - 2s 72ms/step - loss: 2.9514e-04 - accuracy: 1.0000 - val_loss: 0.6106 - val_accuracy: 0.8876 Epoch 10/20 30/30 [==============================] - 2s 72ms/step - loss: 7.8052e-05 - accuracy: 1.0000 - val_loss: 0.7125 - val_accuracy: 0.8858 Epoch 11/20 30/30 [==============================] - 2s 71ms/step - loss: 1.7741e-05 - accuracy: 1.0000 - val_loss: 0.8122 - val_accuracy: 0.8856 Epoch 12/20 30/30 [==============================] - 2s 71ms/step - loss: 6.3514e-06 - accuracy: 1.0000 - val_loss: 2.5362 - val_accuracy: 0.7682 Epoch 13/20 30/30 [==============================] - 2s 71ms/step - loss: 0.2807 - accuracy: 0.9818 - val_loss: 0.7594 - val_accuracy: 0.8817 Epoch 14/20 30/30 [==============================] - 2s 71ms/step - loss: 2.6955e-05 - accuracy: 1.0000 - val_loss: 0.7704 - val_accuracy: 0.8829 Epoch 15/20 30/30 [==============================] - 2s 73ms/step - loss: 1.2987e-05 - accuracy: 1.0000 - val_loss: 0.7956 - val_accuracy: 0.8840 Epoch 16/20 30/30 [==============================] - 2s 72ms/step - loss: 6.7362e-06 - accuracy: 1.0000 - val_loss: 0.8395 - val_accuracy: 0.8844 Epoch 17/20 30/30 [==============================] - 2s 73ms/step - loss: 3.1351e-06 - accuracy: 1.0000 - val_loss: 0.8974 - val_accuracy: 0.8858 Epoch 18/20 30/30 [==============================] - 2s 73ms/step - loss: 1.2273e-06 - accuracy: 1.0000 - val_loss: 0.9698 - val_accuracy: 0.8868 Epoch 19/20 30/30 [==============================] - 2s 73ms/step - loss: 4.4466e-07 - accuracy: 1.0000 - val_loss: 1.0506 - val_accuracy: 0.8864 Epoch 20/20 30/30 [==============================] - 2s 74ms/step - loss: 1.6740e-07 - accuracy: 1.0000 - val_loss: 1.1534 - val_accuracy: 0.8859
기존 모델과의 차이점은 다음과 같다.
주의사항: 검증셋이 너무 작아도 매우 불안정스러울 수 있다.
모델이 학습하는 파라미터(가중치와 편향)의 값이 작은 값을 갖도록 유도하는 기법이 가중치 규제(weight regularization)이며, 크게 두 종류가 있다.
참고: L1 규제가 적용된 라쏘 회귀(Lasso regression)과 L2 규제가 적용된 릿지 회귀(Ridge regression)
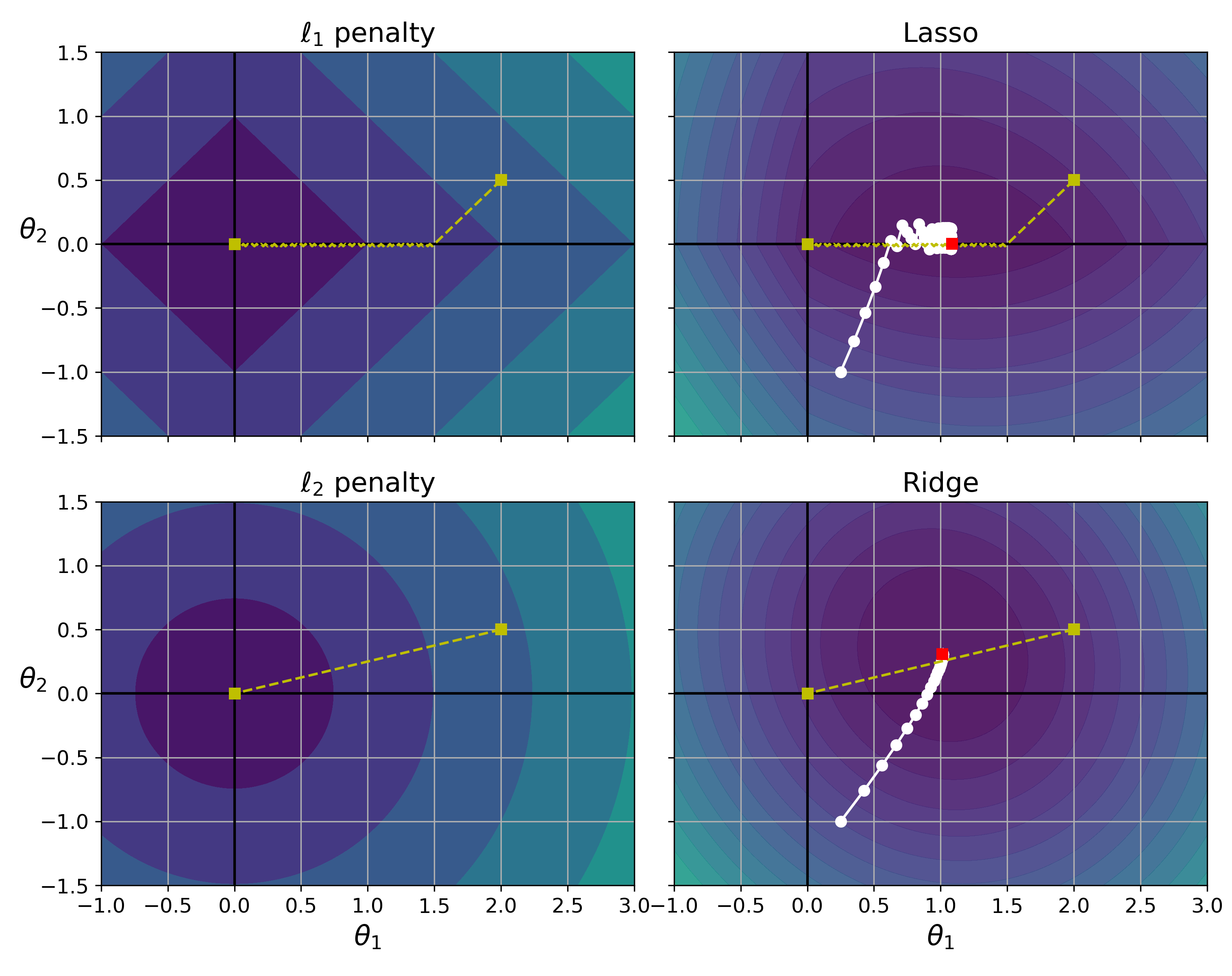
그림 출처: 핸즈온 머신러닝(2판), 4장
아래 코드는 IMDB 훈련 모델에 L2 규제를 가한 결과를 보여준다.
regularizers.l2(0.002): 각 가중치의 제곱에 0.002 곱하기from tensorflow.keras import regularizers
model = keras.Sequential([
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation="relu"),
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_l2_reg = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Epoch 1/20 30/30 [==============================] - 2s 34ms/step - loss: 0.6023 - accuracy: 0.7710 - val_loss: 0.4744 - val_accuracy: 0.8630 Epoch 2/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3990 - accuracy: 0.8978 - val_loss: 0.3953 - val_accuracy: 0.8819 Epoch 3/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3301 - accuracy: 0.9161 - val_loss: 0.4116 - val_accuracy: 0.8601 Epoch 4/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2985 - accuracy: 0.9259 - val_loss: 0.3822 - val_accuracy: 0.8756 Epoch 5/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2757 - accuracy: 0.9331 - val_loss: 0.3550 - val_accuracy: 0.8863 Epoch 6/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2655 - accuracy: 0.9389 - val_loss: 0.3583 - val_accuracy: 0.8848 Epoch 7/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2526 - accuracy: 0.9412 - val_loss: 0.3646 - val_accuracy: 0.8826 Epoch 8/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2470 - accuracy: 0.9414 - val_loss: 0.3651 - val_accuracy: 0.8850 Epoch 9/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2363 - accuracy: 0.9462 - val_loss: 0.3846 - val_accuracy: 0.8773 Epoch 10/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2326 - accuracy: 0.9497 - val_loss: 0.3980 - val_accuracy: 0.8732 Epoch 11/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2292 - accuracy: 0.9491 - val_loss: 0.3812 - val_accuracy: 0.8823 Epoch 12/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2202 - accuracy: 0.9539 - val_loss: 0.3925 - val_accuracy: 0.8779 Epoch 13/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2205 - accuracy: 0.9536 - val_loss: 0.4643 - val_accuracy: 0.8575 Epoch 14/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2200 - accuracy: 0.9526 - val_loss: 0.4036 - val_accuracy: 0.8766 Epoch 15/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2133 - accuracy: 0.9545 - val_loss: 0.4253 - val_accuracy: 0.8719 Epoch 16/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2178 - accuracy: 0.9529 - val_loss: 0.3995 - val_accuracy: 0.8770 Epoch 17/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2047 - accuracy: 0.9593 - val_loss: 0.4038 - val_accuracy: 0.8761 Epoch 18/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2102 - accuracy: 0.9541 - val_loss: 0.4136 - val_accuracy: 0.8750 Epoch 19/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2099 - accuracy: 0.9559 - val_loss: 0.4683 - val_accuracy: 0.8627 Epoch 20/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2031 - accuracy: 0.9602 - val_loss: 0.4488 - val_accuracy: 0.8668
L2 규제를 가한 결과는 다음과 같다.
l2 규제 대신에 l1, 또는 L1과 L2를 함께 사용하는 l1_l2 규제를 사용할 수 있다.
regularizers.l1(0.001)
regularizers.l1_l2(l1=0.001, l2=0.001)
참고: 가중치 규제 기법은 보다 작은 크기의 딥러닝 모델에 효과적이다. 큰 딥러닝 모델에 대해서는 드롭아웃 기법이 보다 잘 작동한다.
드롭아웃은 무작위로 선택된 일정한 비율의 유닛을 끄는 것을 의미한다. 즉, 해당 유닛에 저장된 값을 0으로 처리한다.
적절한 드롭아웃 비율을 답은 드롭아웃 층을 적절한 위치에 추가한다.
검증셋에 대해서는 드롭아웃을 적용하지 않는다. 대신 출력값을 지정된 비율만큼 줄인다. 그래야 층에서 층으로 전달되는 값의 크기가 훈련할 때와 비슷하게 유지되기 때문이다.
아래 코드는 IMDB 데이터셋에 드롯아웃을 적용하여 훈련한다.
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_dropout = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Epoch 1/20 30/30 [==============================] - 1s 35ms/step - loss: 0.6332 - accuracy: 0.6373 - val_loss: 0.5116 - val_accuracy: 0.8513 Epoch 2/20 30/30 [==============================] - 0s 12ms/step - loss: 0.5115 - accuracy: 0.7645 - val_loss: 0.4120 - val_accuracy: 0.8725 Epoch 3/20 30/30 [==============================] - 0s 12ms/step - loss: 0.4286 - accuracy: 0.8241 - val_loss: 0.3393 - val_accuracy: 0.8822 Epoch 4/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3633 - accuracy: 0.8619 - val_loss: 0.2936 - val_accuracy: 0.8875 Epoch 5/20 30/30 [==============================] - 0s 12ms/step - loss: 0.3172 - accuracy: 0.8840 - val_loss: 0.2843 - val_accuracy: 0.8866 Epoch 6/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2727 - accuracy: 0.9035 - val_loss: 0.2721 - val_accuracy: 0.8911 Epoch 7/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2486 - accuracy: 0.9129 - val_loss: 0.2784 - val_accuracy: 0.8914 Epoch 8/20 30/30 [==============================] - 0s 12ms/step - loss: 0.2167 - accuracy: 0.9263 - val_loss: 0.2902 - val_accuracy: 0.8904 Epoch 9/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1947 - accuracy: 0.9321 - val_loss: 0.3019 - val_accuracy: 0.8910 Epoch 10/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1727 - accuracy: 0.9411 - val_loss: 0.3191 - val_accuracy: 0.8859 Epoch 11/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1578 - accuracy: 0.9461 - val_loss: 0.3230 - val_accuracy: 0.8883 Epoch 12/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1472 - accuracy: 0.9523 - val_loss: 0.3525 - val_accuracy: 0.8882 Epoch 13/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1346 - accuracy: 0.9528 - val_loss: 0.3735 - val_accuracy: 0.8882 Epoch 14/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1237 - accuracy: 0.9561 - val_loss: 0.4016 - val_accuracy: 0.8887 Epoch 15/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1135 - accuracy: 0.9629 - val_loss: 0.4250 - val_accuracy: 0.8887 Epoch 16/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1029 - accuracy: 0.9625 - val_loss: 0.4592 - val_accuracy: 0.8888 Epoch 17/20 30/30 [==============================] - 0s 12ms/step - loss: 0.1005 - accuracy: 0.9665 - val_loss: 0.4858 - val_accuracy: 0.8880 Epoch 18/20 30/30 [==============================] - 0s 12ms/step - loss: 0.0940 - accuracy: 0.9679 - val_loss: 0.4944 - val_accuracy: 0.8860 Epoch 19/20 30/30 [==============================] - 0s 12ms/step - loss: 0.0872 - accuracy: 0.9675 - val_loss: 0.5313 - val_accuracy: 0.8887 Epoch 20/20 30/30 [==============================] - 0s 12ms/step - loss: 0.0854 - accuracy: 0.9676 - val_loss: 0.5591 - val_accuracy: 0.8858
50%의 드롭아웃을 적용한 결과는 다음과 같다.










